
知っておくべきMQL5ウィザードのテクニック(第07回):樹状図
はじめに
この記事はMQL5ウィザードの使い方に関する連載の一部で、樹状図(英語)について見ます。MQL5ウィザードを通じて、線形判別分析、マルコフ連鎖、フーリエ変換、その他いくつかの、トレーダーに役立ついくつかのアイデアをすでに検討しました。この記事では、MetaQuotesによって翻訳された広範なALGLIBコードを、内蔵のMQL5ウィザードの使用とともに活用する方法を検討することで、この試みをさらに推し進め、新しいアイデアを効率的にテストし開発することを目指す。
階層クラスタリング(英語)というと難しく聞こえますが、実際はとてもシンプルです。わかりやすく言えば、まず基本的な個々のクラスタ、次にそれらを体系的に一段階ずつグループ化し、データセット全体を一つのソートされた単位として見ることができるようにすることで、データセットのさまざまな部分を関連付ける手段です。このプロセスの出力は、一般に樹状図と呼ばれる階層図です。
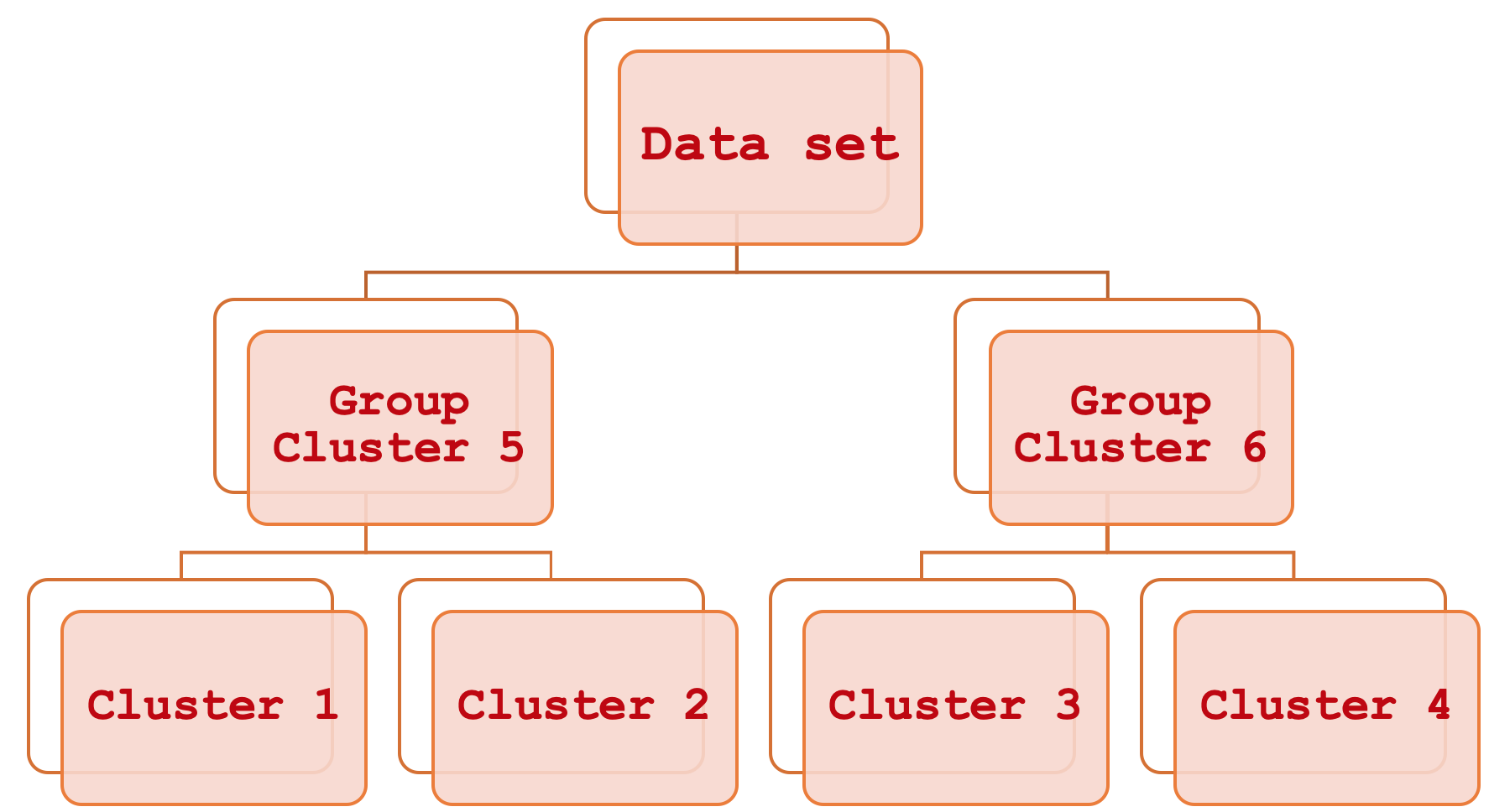
この記事では、これらの構成要素クラスタをどのように評価し、それによって価格バーの範囲を予測するために使用できるかに焦点を当てますが、トレーリングストップの調整に役立てるためにおこなっていた過去とは異なり、ここでは資金管理やポジションサイジングの目的で検討します。この記事で採用するスタイルは、読者がMetaTraderプラットフォームとMQL5プログラミング言語の比較的初心者であることを想定しています。
正確な価格帯予測の重要性は、主観的な部分が大きい。なぜなら、その重要性はトレーダーの戦略と全体的な取引手法に依存することがほとんどだからです。それがあまり重要でなくなるのはいつだろう?例えば、取引のセットアップにおいて、まずレバレッジを最小からゼロにし、明確なストップロスを設定し、数ヶ月に及ぶ長期にわたってポジションを保有する傾向があり、固定証拠金のポジションサイジング(あるいは固定ロットアプローチ)をおこなっている場合です。この場合、エントリシグナルとエグジットシグナルのスクリーニングに集中する間、価格バーのボラティリティは後回しにすることができます。一方、イントラデイトレーダー、多額のレバレッジをかける人、週末にポジションを持たない人、マーケットへの露出に関して中短期の視野を持つ人であれば、価格バーレンジに注意を払う必要があります。ExpertMoneyクラスのカスタムインスタンスを作成することで、これが資金管理にどのように役立つかを見てみますが、この応用は資金管理だけにとどまらず、リスク管理にも広がる可能性があります。バーの値幅を理解し、合理的に予測する能力が、ポジションを追加するタイミングや、逆に減らすタイミングを決定するのに役立つと考えれば、この応用は可能でしょう。
ボラティリティ
取引における価格バーレンジ(本記事ではボラティリティを定量化する方法)とは、一定の時間枠内における取引銘柄の価格の高値と安値の差のことです。したがって、日次の時間枠を考えて、1日に取引された銘柄の価格がHまで上昇し、Hを超えず、Lまで下落し、再びLを下回らない場合、本稿でのこの目的のための範囲は
H – L
です。しばしばボラティリティクラスタリング(英語)と呼ばれることから、ボラティリティに注目することは間違いなく重要です。これは、ボラティリティの高い時期が続くとボラティリティが高くなり、逆にボラティリティの低い時期が続くとボラティリティが低くなるという現象です。というのも、ほとんどのトレーダーが知っているように、ボラティリティが高いと、エントリシグナルが間違っていたからではなく、ボラティリティが高すぎたために口座がストップアウトしてしまうことがあるからです。そして、ポジションに適切なストップロスがあったとしても、ほとんどの人はそれを高く評価するでしょう。ストップロス価格が利用できない場合があります。2015年1月のスイスフランの大失敗を例に挙げると、その場合、ポジションは次に良い利用可能な価格でブローカーによってクローズされ、多くの場合ストップロスよりも悪い価格になります。なぜなら、指値注文だけが価格を保証し、逆指値注文やストップロスは保証しないからです。
そのため、バーレンジは市場環境の全体的な感覚を提供するだけでなく、エントリやエグジット価格レベルの指針としても役立ちます。戦略にもよりますが、例えば特定の銘柄をロングしている場合、価格バーレンジの見通し(何を予測しているか)によって、エントリ価格やテイクプロフィットをどこに置くかが簡単に決まったり、少なくとも目安になったりします。
平凡に聞こえるかもしれませんが、それは非常に基本的な価格のローソク足の種類のいくつかを強調し、また、それぞれの範囲を示すのに役立つかもしれません。より顕著なタイプは、弱気、強気、ハンマー、塔婆、足長、トンボです。もっと多くの種類があることは確かですが、価格チャートに直面したときに遭遇する可能性の高いものを網羅していることは間違いありません。以下の図に示すように、これらすべての場合において、価格帯は単純に高値から安値を引いたものです。
凝集型階層分類
凝集型階層分類(AHC)は、データをあらかじめ設定された数のクラスタに分類し、樹状図(英語)と呼ばれるものを介して、これらのクラスタを体系的な階層的方法で関連付ける手法です。この利点は、分類されるデータが多次元的であることが多いため、1つのデータポイントに含まれる多くの変数を考慮する必要があり、比較をおこなう際に対処が容易ではないことに起因します。例えば、顧客から得た情報に基づいて顧客を格付けしようとする企業は、この情報を活用することができます。なぜなら、この情報は過去の消費習慣、年齢、性別、住所など、顧客の生活のさまざまな側面をカバーしているに違いないからです。AHCは、顧客ごとにこれらすべての変数を定量化することで、各データポイントの見かけ上の中心点からクラスタを作成します。しかしそれ以上に、これらのクラスタは体系的な関係のために階層にグループ化されます。例えば、ある分類が5つのクラスタを求めたとすると、AHCはそれらの5つのクラスタを並び替えた形式で提供します。このクラスタ比較は二次的なものですが、複数のデータポイントを比較する必要があり、それらが別々のクラスタにあることが判明した場合に便利です。クラスタ順位は、それぞれのクラスタ間の分離の大きさを使うことで、2つの点がどの程度離れているかを知らせます。
AHCによる分類は教師無し学習、つまり異なる分類器の下でも予測に使用できます。ここでの場合はバーの値幅を予測していますが、同じ訓練されたクラスタを持つ他の誰かが、終値の変化や、その人の取引に関連する別の側面を予測するために使うことができます。これは、教師あり学習で特定の分類器で学習させた場合よりも柔軟性があります。なぜなら、その場合、モデルは分類されたものについてのみ予測に使用されるからです。つまり、別の目的のために予測をおこなうには、その新しいデータセットでモデルを再学習する必要があります。
ツールとライブラリ
MQL5プラットフォームでは、IDEの助けを借りて、予想どおりカスタムEAをゼロから開発することができます。ここで共有されているものを紹介するために、仮説としてそのルートを取ることができます。しかし、その選択肢は、同じコンセプトの導入に直面したとき、別のトレーダーが別の方法を取ったかもしれない取引システムに関して、多くの決断を下すことになります。また、そのような実装のコードはカスタマイズされすぎていて、さまざまな状況に応じて簡単に変更することができません。だからこそ、MQL5ウィザードが提供する他の「標準的な」EAクラスの一部として私たちのアイデアを組み立てることは、説得力のあるケースなのです。デバッグの手間が省けるだけでなく(MQL5のビルトインクラスにも時折バグはありますが、それほど多くはない)、標準クラスのインスタンスとして保存することで、MQL5ウィザードにある他のさまざまなクラスと組み合わせて使用することができ、より包括的なテストベッドを提供するさまざまなEAを作成することができます。
MQL5のライブラリコードにはAlgLibのクラスが用意されており、本連載でも以前に参照しましたが、この記事でも再び使用します。具体的には、DATAANALYSIS.MQHファイル内で、CClusteringクラスと、価格系列データのAHC分類を考え出す他のいくつかの関連クラスに依存します。私たちの主な関心事はバーの価格帯であるため、訓練データは過去の期間からそのような範囲で構成されることになります。データ分析インクルードファイルからデータ訓練クラスを使用する場合、通常、このデータはXY行列に配置され、Xは独立変数を表し、Yは分類子またはモデルが訓練される「ラベル」を表します。両者は通常、同じ行列で提供されます。
訓練データの準備
しかしこの記事では、教師なし学習をおこなっているため、入力データはX個の独立変数のみで構成されています。これらは過去の価格帯となります。しかし同時に、最終的なバーの価格帯という別の関連データの流れも考慮して予測を立てたいと思います。これは先ほどのYに相当します。教師なし学習の柔軟性を維持しながら、これら2つのデータセットを融合させるために、以下のようなデータ構造を採用することができます。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CMoneyAHC : public CExpertMoney { protected: double m_decrease_factor; int m_clusters; // clusters int m_training_points; // training points int m_point_featues; // point featues ... public: CMoneyAHC(void); ~CMoneyAHC(void); virtual bool ValidationSettings(void); //--- virtual double CheckOpenLong(double price,double sl); virtual double CheckOpenShort(double price,double sl); //--- void DecreaseFactor(double decrease_factor) { m_decrease_factor=decrease_factor; } void Clusters(int value) { m_clusters=value; } void TrainingPoints(int value) { m_training_points=value; } void PointFeatures(int value) { m_point_featues=value; } protected: double Optimize(double lots); double GetOutput(); CClusterizerState m_state; CAHCReport m_report; struct Sdata { CMatrixDouble x; CRowDouble y; Sdata(){}; ~Sdata(){}; }; Sdata m_data; CClustering m_clustering; CRowInt m_clustering_index; CRowInt m_clustering_z; };
そのため、過去の価格帯は新しいバーごとに新しいバッチとして収集されます。MQL5ウィザードによって生成されたEAは、新しいバーごとに取引判断を実行する傾向があり、私たちのテスト目的にはこれで十分です。何ヶ月、あるいは何年にもわたる大きなバッチを取得し、テストから、モデルのクラスタが最終的に低ボラティリティの価格バーと高ボラティリティのバーをどの程度分離できるかを調べるなど、別のアプローチも確かにあります。また、3つのクラスタしか使っていないことに留意してください。1つの極端なクラスタはボラティリティが非常に高いバー、1つはボラティリティが非常に低いバー、1つはボラティリティが中程度のバーです。この場合も、例えば5つのクラスタで調査することは可能ですが、原理は同じです。クラスタを最終的なボラティリティの大きい順から小さい順に並べ、現在のデータポイントがどのクラスタにあるかを特定します。
データの入力
新しいバーごとに最新のバー範囲を取得し、カスタム構造体に入力するコードは次のようになります。
m_data.x.Resize(m_training_points,m_point_featues); m_data.y.Resize(m_training_points-1); m_high.Refresh(-1); m_low.Refresh(-1); for(int i=0;i<m_training_points;i++) { for(int ii=0;ii<m_point_featues;ii++) { m_data.x.Set(i,ii,m_high.GetData(StartIndex()+ii+i)-m_low.GetData(StartIndex()+ii+i)); } }
訓練ポイントの数は、訓練データセットの大きさを定義します。これはカスタマイズ可能な入力パラメータであるため、データポイントの特徴パラメータとなります。しかし、このパラメータは、各データポイントが持つ「次元」の数を定義します。つまり、このケースでは、デフォルトで4つになっていますが、これは単に、任意のデータポイントを定義するために、直近の4つのバー価格帯を使用していることを意味します。ベクトルに似ています。
クラスタの生成
そこで、カスタム構造体にデータを格納したら、次のステップは、AlgLibAHCモデル生成器でそれをモデル化することです。このモデルは、コードリストではstateと呼ばれ、そのためにモデルの名前はm_stateとなっています。これは2段階のプロセスです。まず、提供された訓練データに基づいてモデルポイントを生成し、AHC生成器を実行します。ポイントを設定することは、モデルを初期化し、すべての主要なパラメータが適切に定義されていることを確認することと考えることができます。このコードは次のように呼び出されます。
m_clustering.ClusterizerSetPoints(m_state, m_data.x, m_training_points, m_point_featues, 20);
2つ目の重要なステップは、モデルを実行して、訓練データセット内の提供された各データポイントのクラスタを定義することです。これは、以下のように'ClusterizerRunAHC'関数を呼び出すことで実行されます。
m_clustering.ClusterizerRunAHC(m_state, m_report);
AlgLib側から見ると、これは必要なクラスタを生成するための肉と芋です。この関数は、いくつかの簡単な前処理をおこない、その後、重い仕事をするプロテクト(非公開)関数ClusterizerRunAHCInternalを呼び出します。このソースはすべてinclude\math\AlgLib\dataanalysis.mqhにあり、22463行目から始まります。ここで注目すべきは、cidx出力配列における樹状図の生成です。この配列は、多くのクラスタ情報をひとつの配列に巧みに凝縮しています。その前に、すべての訓練データ点について、そのセントロイドを利用して距離行列を生成する必要があります。距離行列の値からクラスタインデックスへの写像は、この配列によって捕捉され、学習ポイントの総数までの最初の値は各ポイントのクラスタを表し、それ以降のインデックスは樹状図を形成するためにこれらのクラスタを結合することを表します。
同様に注目すべきは、距離行列の生成に使われた距離タイプでしょう。チェビシェフ距離、ユークリッド距離、そしてスピアマン順位相関まで、9つのオプションが用意されています。これらの選択肢にはそれぞれインデックスが割り当てられており、前述のセットポイント関数を呼び出す際に設定します。距離の種類の選択は、生成されるクラスタの性質と種類に非常に敏感であるため、これに注意を払う必要があります。ユークリッド距離(そのインデックスは2である)を使用すると、他の距離タイプとは異なり、ウォードの方法が使用できるため、AHCアルゴリズムを設定する際に、より柔軟な実装が可能になります。
クラスタの取得
クラスタを検索するのも、クラスタを生成するのと同じくらい簡単です。単に1つの関数ClusterizerGetKClustersを呼び出すだけで、先に呼び出した(AHCを実行する)クラスタ生成関数の出力レポートから2つの配列を取得します。この配列は、クラスタインデックス配列とクラスタz配列で、クラスタがどのように定義されるかだけでなく、クラスタから樹状図をどのように形成するかも示しています。この関数は、以下に示すように単純に呼び出されます。
m_clustering.ClusterizerGetKClusters(m_report, m_clusters, m_clustering_index, m_clustering_z);
私たちの場合、訓練データセットを3つのクラスタに分類しただけなので、結果として得られるクラスタの構造は非常に単純です。つまり、樹状図内の結合は3レベル以下ということになります。もしより多くのクラスタを使用していたら、私たちの樹状図はより複雑なものになり、n-1個の結合レベルを持っていた可能性があります。ここで、nはモデルで使用されるクラスタの数です。
データポイントのラベリング
予測に役立てるための訓練データポイントのポストラベリングが続きます。私たちはデータセットを単純に分類することに興味があるのではなく、それらを利用したいのです。したがって、「ラベル」は、各訓練データポイントの後の最終的なバー価格帯となります。最終的なボラティリティが不明な現在のデータポイントを含む新しいデータセットを、新しいバーごとにフェッチします。そのため、以下のコードに示すように、ラベリング時には0をインデックスとするデータポイントをスキップします。
for(int i=0;i<m_training_points;i++) { if(i>0)//assign classifier only for data points for which eventual bar range is known { m_data.y.Set(i-1,m_high.GetData(StartIndex()+i-1)-m_low.GetData(StartIndex()+i-1)); } }
もちろん、このラベリングプロセスの他の実装を使用することもできます。たとえば、次のバーの値幅だけに注目するのではなく、これらのバーの全体的な値幅をy値として、次の5本や10本のバーの値幅を見ることで、マクロ的な見方をすることもできます。このアプローチは、より「正確」で不規則性の少ない値を導くことができ、実際、ラベルが価格の方向(終値の変化)である場合、同じ見通しを使用することができます。いずれにせよ、最初のインデックスの最終的な値を持っていないためにスキップしたので、n本のバーをスキップすることになります(ここでnは、予測しようとしている先のバー)。このような長い目で見るアプローチでは、nが大きくなるにつれてかなりのラグが生じることになりますが、その反面、ラグが大きければ、目標y値まであと1バーしかないため、プロジェクションとの安全な比較が可能になります。
ボラティリティの予測
学習済みデータセットの「ラベリング」が終わると、モデルで定義されたクラスタの中で、現在のデータポイントがどのクラスタに属するかを確定することができます。これは、モデリングレポートの出力配列を簡単に繰り返し、現在のデータポイントのクラスタインデックスと他の訓練データポイントのクラスタインデックスを比較することによっておこなわれます。一致すれば、同じクラスタに属することになります。以下はその簡単なコードです。
if(m_report.m_terminationtype==1) { int _clusters_by_index[]; if(m_clustering_index.ToArray(_clusters_by_index)) { int _output_count=0; for(int i=1;i<m_training_points;i++) { //get mean target bar range of matching cluster if(_clusters_by_index[0]==_clusters_by_index[i]) { _output+=(m_data.y[i-1]); _output_count++; } } // if(_output_count>0){ _output/=_output_count; } } }
一致が見つかったら、そのクラスタ内の全訓練データ点の平均Y値の計算を同時に進めます。平均値を求めるのは粗雑とも言えますが、ひとつの方法です。中央値を求めることもできるし、最頻値を求めることもできますが、どの方法を選択しても、クラスタ内の他のデータ点から現在の点のY値のみを求めるという同じ原則が適用されます。
樹状図の使用
これまでソースコードの共有について示してきたのは、どのように作成された個々のクラスタを分類し、予測するために使用できることです。では、樹状図の役割とは何でしょうか。それぞれのクラスタがどれだけ違うかを数値化することが、なぜ重要なのでしょうか。この質問に答えるために、私たちがおこなったように1つのデータだけを分類するのではなく、2つの訓練データを比較することも考えられます。このシナリオでは、ボラティリティに関する限り、重要な変曲点(価格の方向性を予測するのであれば、これは価格変動における重要なフラクタルとなり得ますが、この記事ではボラティリティに注目しています)で履歴からデータポイントを得ることができます。両ポイントのクラスタがあれば、その距離から現在のデータポイントが過去の変曲点にどれだけ近いかがわかります。
ケーススタディ
資金管理クラスのカスタマイズされたインスタンスを利用するウィザードで組み立てられたEAを使って、いくつかのテストを実行しました。シグナルクラスは、ライブラリが提供する素晴らしいオシレーターに基づいており、銘柄EURUSDに対して2022.10.01から2023.10.01までの4時間足で実行し、以下のようなレポートを得ました。

コントロールとして、資金管理がライブラリ提供の固定証拠金オプションであることを除き、上記と同じ条件でテストも実行したところ、以下のようなレポートが得られました。

この2つのレポートから得られた簡単なテストの意味は、銘柄の実勢ボラティリティに応じて出来高を調整する可能性があるということです。EAと制御に使用されている設定もそれぞれ以下に示されています。

そして

明らかなように、ほとんどの場合、同じような設定が使用されましたが、唯一の例外はEAで、カスタムマネーマネージメントをより多く使用する必要がありました。
結論
要約すると、樹状図の助けを借りて、凝集型階層分類がどのように異なるデータ集合を識別し、サイズ分けするのに役立つか、そしてこの分類がどのように投影をおこなうのに使用できるかを探求した。ここではこのテーマについての詳細を確認できます。また、いつも通り、共有されているアイデアとソースコードは、特に異なるアプローチと組み合わせた場合に、アイデアをテストするためのものです。このため、MQL5ウィザードクラスのコードフォーマットが採用されています。
添付ファイルに関する注意事項
添付のコードは、シグナルクラスファイルと末尾のクラスファイルを含むアセンブリの一部として、MQL5ウィザードでアセンブルするためのものです。この記事のシグナルファイルは、素晴らしいオシレーター(SignalAO.mqh)です。ウィザードの使い方の詳細はこちらをご覧ください。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13630
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
 独自のLLMをEAに統合する(第2部):環境展開例
独自のLLMをEAに統合する(第2部):環境展開例
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
AlgLibライブラリの機能をカバーしているのは非常に良い!
デンドログラムを可視化するコードは、この記事では非常に不足しています。