Artículos con ejemplos de programación de robots comerciales en el lenguaje MQL5
En el ámbito del trading automático los Asesores Expertos es la cima de la programación y objetivo deseable de cada desarrollador. Usted puede escribir su propio Asesor Experto utilizando los artículos de esta sección. Paso a paso los principiantes podrán pasar todas las fases de creación, depuración y simulación de los sistemas automáticos de trading.
Los artículos no sólo enseñarán a programar en el lenguaje MQL5, sino mostrarán cómo implementar cualquier idea y técnica comercial. Usted conocerá cómo programar el Trailing Stop, cómo realizar la gestión del capital, cómo obtener el valor del indicador y muchas cosas más.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Redes neuronales: así de sencillo (Parte 36): Modelos relacionales de aprendizaje por refuerzo (Relational Reinforcement Learning)
En los modelos de aprendizaje por refuerzo analizados anteriormente, usamos varias opciones de redes convolucionales que pueden identificar varios objetos en los datos originales. La principal ventaja de las redes convolucionales es su capacidad de identificar objetos independientemente de la ubicación de estos. Al mismo tiempo, las redes convolucionales no siempre son capaces de hacer frente a diversas deformaciones de los objetos y al ruido. Pero estos problemas pueden resolverse usando el modelo relacional.

Teoría de categorías en MQL5 (Parte 7): Dominios múltiples, relativos e indexados
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.

Redes neuronales: así de sencillo (Parte 54): Usamos un codificador aleatorio para una exploración eficiente (RE3)
Siempre que analizamos métodos de aprendizaje por refuerzo, nos enfrentamos al problema de explorar eficientemente el entorno. Con frecuencia, la resolución de este problema hace que el algoritmo se complique, llevándonos al entrenamiento de modelos adicionales. En este artículo veremos un enfoque alternativo para resolver el presente problema.

Experimentos con redes neuronales (Parte 4): Patrones
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Experimentos con redes neuronales (Parte 5): Normalización de parámetros de entrada para su transmisión a una red neuronal
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Operar con noticias de manera sencilla (Parte 3): Ejecución de operaciones
En este artículo, nuestro experto en negociación de noticias comenzará a abrir operaciones basándose en el calendario económico almacenado en nuestra base de datos. Además, mejoraremos los gráficos del experto para mostrar información más relevante sobre los próximos acontecimientos del calendario económico.

Desarrollo de un factor de calidad para los EAs
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).

Características del Wizard MQL5 que debe conocer (Parte 16): Método de componentes principales con vectores propios
En este artículo analizaremos el método de componentes principales, una técnica de reducción de la dimensionalidad para el análisis de datos, y cómo podemos aplicar este utilizando valores propios y vectores. Como siempre, intentaremos desarrollar un prototipo de la clase de señales del asesor experto que se pueda utilizar en el Wizard MQL5.

Redes neuronales: así de sencillo (Parte 89): Transformador de descomposición de la frecuencia de señal (FEDformer)
Todos los modelos de los que hemos hablado anteriormente analizan el estado del entorno como una secuencia temporal. Sin embargo, las propias series temporales también pueden representarse como características de frecuencia. En este artículo, presentaremos un algoritmo que utiliza las características de frecuencia de una secuencia temporal para predecir los estados futuros.

Creación de un modelo de restricción de tendencia de velas (Parte 9): Asesor Experto de múltiples estrategias (III)
¡Bienvenidos a la tercera entrega de nuestra serie sobre tendencias! Hoy profundizaremos en el uso de la divergencia como estrategia para identificar puntos de entrada óptimos dentro de la tendencia diaria predominante. También presentaremos un mecanismo de bloqueo de ganancias personalizado, similar a un stop-loss dinámico, pero con mejoras únicas. Además, actualizaremos el asesor experto Trend Constraint a una versión más avanzada, incorporando una nueva condición de ejecución comercial para complementar las existentes. A medida que avanzamos, continuaremos explorando la aplicación práctica de MQL5 en el desarrollo algorítmico, brindándole información más detallada y técnicas prácticas.
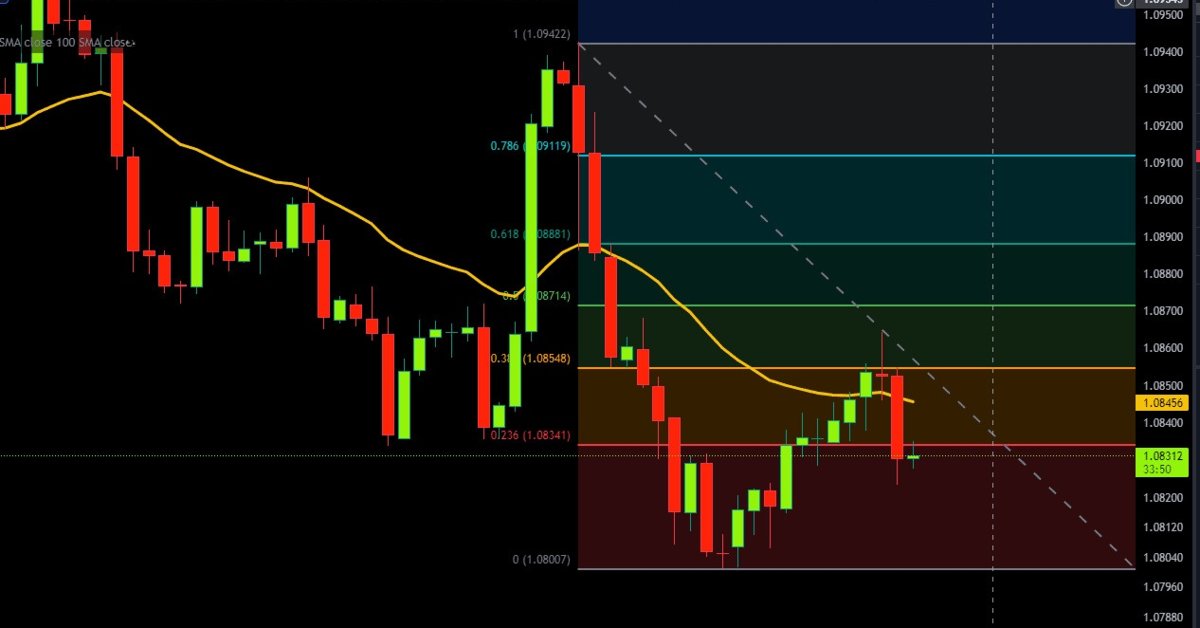
Automatización de estrategias de trading en MQL5 (Parte 11): Desarrollo de un sistema de negociación de cuadrícula multinivel
En este artículo, desarrollamos un sistema EA de trading de cuadrícula multinivel utilizando MQL5, centrándonos en la arquitectura y el diseño del algoritmo que hay detrás de las estrategias de trading de cuadrícula. Exploramos la implementación de una lógica de red multicapa y técnicas de gestión de riesgos para hacer frente a las condiciones variables del mercado. Por último, ofrecemos explicaciones detalladas y consejos prácticos para guiarle en la creación, prueba y perfeccionamiento del sistema de negociación automatizado.

Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución
A medida que el modelo se entrena con el búfer de reproducción de experiencias, la política actual del Actor se aleja cada vez más de los ejemplos almacenados, lo cual reduce la eficacia del entrenamiento del modelo en general. En este artículo, analizaremos un algoritmo para mejorar la eficiencia del uso de las muestras en los algoritmos de aprendizaje por refuerzo.

De novato a experto: Sistema de análisis autogeométrico
Los patrones geométricos ofrecen a los operadores una forma concisa de interpretar la acción del precio. Muchos analistas dibujan líneas de tendencia, rectángulos y otras formas a mano y luego basan sus decisiones comerciales en las formaciones que ven. En este artículo exploramos una alternativa automatizada: aprovechar MQL5 para detectar y analizar los patrones geométricos más populares. Desglosaremos la metodología, discutiremos los detalles de implementación y destacaremos cómo el reconocimiento de patrones automatizado puede agudizar el conocimiento del mercado de un comerciante.

Redes neuronales: así de sencillo (Parte 43): Dominando las habilidades sin función de recompensa
El problema del aprendizaje por refuerzo reside en la necesidad de definir una función de recompensa, que puede ser compleja o difícil de formalizar. Para resolver esto, se están estudiando enfoques basados en la variedad de acciones y la exploración del entorno que permiten aprender habilidades sin una función de recompensa explícita.
De novato a experto: Sistema de análisis autogeométrico
Los patrones geométricos ofrecen a los operadores una forma concisa de interpretar la acción del precio. Muchos analistas dibujan líneas de tendencia, rectángulos y otras formas a mano y luego basan sus decisiones comerciales en las formaciones que ven. En este artículo exploramos una alternativa automatizada: aprovechar MQL5 para detectar y analizar los patrones geométricos más populares. Desglosaremos la metodología, discutiremos los detalles de implementación y destacaremos cómo el reconocimiento de patrones automatizado puede agudizar el conocimiento del mercado de un comerciante.

Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline
El entrenamiento offline del modelo se realiza sobre los datos de una muestra de entrenamiento previamente preparada. Esto nos ofrecerá una serie de ventajas, pero la información sobre el entorno estará muy comprimida con respecto al tamaño de la muestra de entrenamiento, lo que, a su vez, limitará el alcance del estudio. En este artículo, querríamos familiarizarnos con un método que permite llenar la muestra de entrenamiento con los datos más diversos posibles.

Aplicación de la teoría de juegos a algoritmos comerciales
Hoy crearemos un asesor comercial adaptativo de autoaprendizaje basado en DQN de aprendizaje automático, con inferencia causal multivariante, que negociará con éxito simultáneamente en 7 pares de divisas, con agentes de diferentes pares intercambiando información entre sí.

Ejemplo de análisis de redes de causalidad (Causality Network Analysis, CNA) y modelo de autoregresión vectorial para la predicción de eventos de mercado
Este artículo presenta una guía completa para implementar un sistema comercial sofisticado utilizando análisis de red de causalidad (CNA) y autorregresión vectorial (Vector autoregression, VAR) en MQL5. Abarca los fundamentos teóricos de estos métodos, ofrece explicaciones detalladas de las funciones clave del algoritmo de negociación e incluye código de ejemplo para su aplicación.

Creación de un Panel de administración de operaciones en MQL5 (Parte IX): Organización del código (I)
Este debate profundiza en los retos que se plantean al trabajar con grandes bases de código. Exploraremos las mejores prácticas para la organización del código en MQL5 e implementaremos un enfoque práctico para mejorar la legibilidad y la escalabilidad del código fuente de nuestro Panel de administración de operaciones. Además, nuestro objetivo es desarrollar componentes de código reutilizables que puedan beneficiar a otros desarrolladores en el desarrollo de sus algoritmos. Sigue leyendo y únete a la conversación.

Ejemplo de Análisis de Redes de Causalidad (CNA), Control Óptimo de Modelos Estocásticos (SMOC) y la Teoría de Juegos de Nash con Aprendizaje Profundo (Deep Learning)
Agregaremos Deep Learning a esos tres ejemplos que se publicaron en artículos anteriores y compararemos los resultados con los anteriores. El objetivo es aprender cómo agregar DL (Deep Learning) a otro EA.
Perceptrón multicapa y algoritmo de retropropagación (Parte 3): Integración con el simulador de estrategias - Visión general (I)
El perceptrón multicapa es una evolución del perceptrón simple, capaz de resolver problemas separables no linealmente. Junto con el algoritmo de retropropagación, es posible entrenar eficientemente esta red neuronal. En la tercera parte de la serie sobre el perceptrón multicapa y la retropropagación, mostraremos cómo integrar esta técnica con el simulador de estrategias. Esta integración permitirá utilizar análisis de datos complejos y tomar mejores decisiones para optimizar las estrategias de negociación. En este resumen, analizaremos las ventajas y los retos de la aplicación de esta técnica.
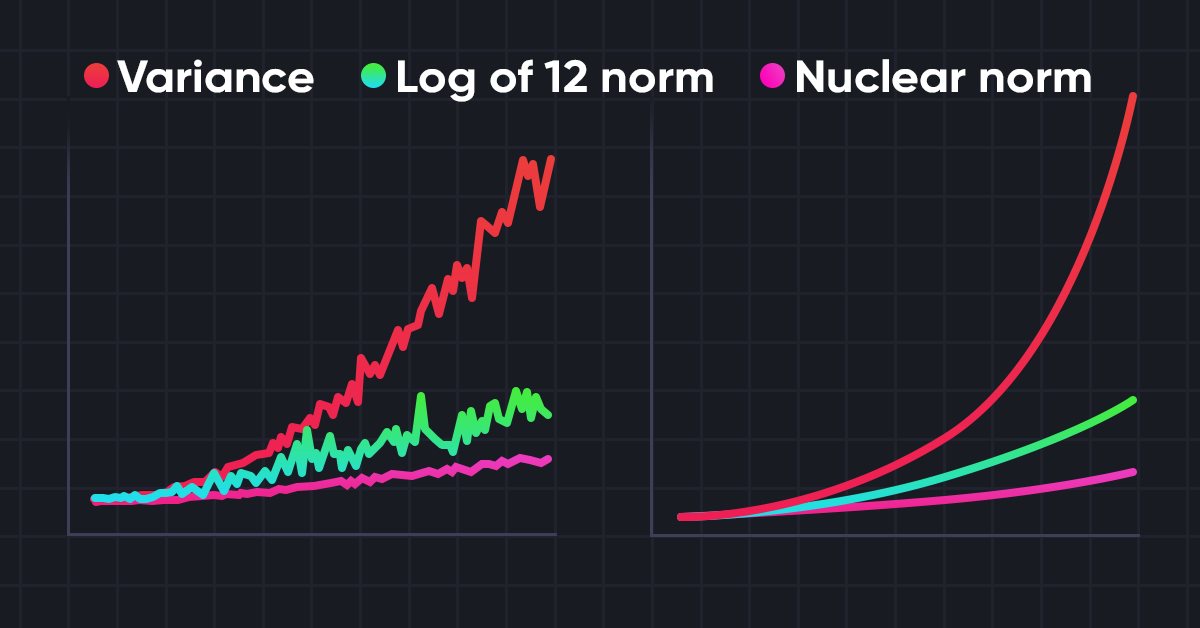
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.
Desarrollo de asesores expertos autooptimizables en MQL5 (Parte 3): Estrategias dinámicas de seguimiento de tendencias y reversión a la media
Los mercados financieros suelen clasificarse en dos tipos: los que se mueven dentro de un rango y los que siguen una tendencia. Esta visión estática del mercado puede facilitarnos las operaciones a corto plazo. Sin embargo, está desconectado de la realidad del mercado. En este artículo, buscamos comprender mejor cómo se mueven exactamente los mercados financieros entre estos dos modos posibles y cómo podemos utilizar nuestra nueva comprensión del comportamiento del mercado para ganar confianza en nuestras estrategias de negociación algorítmica.

Trading de arbitraje en Forex: Un bot market-maker simple de sintéticos para comenzar
Hoy vamos a desmontar mi primer robot de arbitraje: un proveedor de liquidez (si lo podemos llamar así) en activos sintéticos. Hoy en día este bot está funcionando con éxito como un módulo en un gran sistema de aprendizaje automático, pero he puesto en marcha un viejo robot de arbitraje de divisas de la nube, así que le propongo echarle un vistazo, y pensar en lo que podemos hacer con él hoy.

Optimización de portafolios en Fórex: Síntesis de VaR y la teoría de Markowitz
¿Cómo funciona la negociación de portafolios en Fórex? ¿Cómo pueden sintetizarse la teoría de portafolios de Markowitz para optimizar las proporciones de los portafolios y el modelo VaR para optimizar el riesgo de los portafolios? Hoy crearemos un código de teoría de portafolios en el que, por un lado, obtendremos un riesgo bajo y, por otro, una rentabilidad aceptable a largo plazo.

Teoría de Categorías en MQL5 (Parte 10): Grupos monoidales
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Hoy analizaremos los grupos monoidales como un medio que normaliza conjuntos de monoides y los hace más comparables entre una gama más amplia de conjuntos de monoides y tipos de datos.
Trabajando con las series temporales en la biblioteca DoEasy (Parte 57): Objeto de datos del búfer de indicador
En este artículo, vamos a desarrollar el objeto que incluirá todos los datos de un búfer de un indicador. Estos objetos serán necesarios para almacenar los datos de serie de los búferes de indicadores, a través de los cuales será posible ordenar y comparar los datos de los búferes de cualquier indicador, así como otros datos parecidos.

Desarrollamos un Asesor Experto multidivisas (Parte 3): Revisión de la arquitectura
Ya hemos avanzado bastante en el desarrollo del asesor multidivisa con varias estrategias funcionando en paralelo. Basándonos en nuestra experiencia, revisaremos la arquitectura de nuestra solución y trataremos de mejorarla antes de avanzar demasiado.

Operar con noticias de manera sencilla (Parte 2): Gestión de riesgos
En este artículo, se introducirá la herencia en nuestro código anterior. Se implementará un nuevo diseño de base de datos para brindar eficiencia. Además, se creará una clase de gestión de riesgos para abordar los cálculos de volumen.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.

Redes neuronales: así de sencillo (Parte 39): Go-Explore: un enfoque diferente sobre la exploración
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.

Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.

Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.

Desarrollo de asesores expertos autooptimizables en MQL5
Construya asesores expertos que miren hacia delante y se ajusten a cualquier mercado.
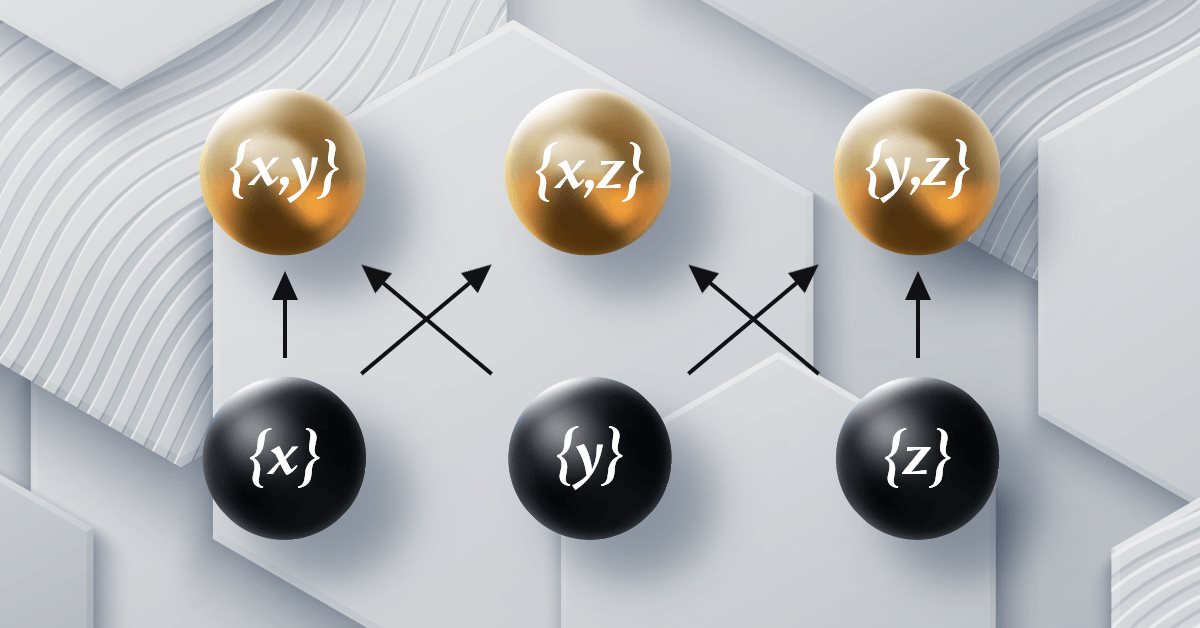
Teoría de categorías en MQL5 (Parte 12): Orden
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.

Redes neuronales en el trading: Modelos de difusión direccional (DDM)
Hoy proponemos al lector familiarizarse con los modelos de difusión direccional que explotan el ruido anisotrópico y direccional dependiente de los datos durante la difusión directa para capturar representaciones gráficas significativas.

Redes neuronales en el trading: Modelos "ligeros" de pronóstico de series temporales
Los modelos ligeros de pronóstico de series temporales logran un alto rendimiento utilizando un número mínimo de parámetros, lo que, a su vez, reduce el consumo de recursos computacionales y agiliza la toma de decisiones. De este modo consiguen una calidad de previsión comparable a la de modelos más complejos.

Redes neuronales en el trading: Inyección de información global en canales independientes (InjectTST)
La mayoría de los métodos modernos de pronóstico de series temporales multimodales utilizan el enfoque de canales independientes. Esto ignora la dependencia natural de los diferentes canales de la misma serie temporal. Un uso coherente de ambos enfoques (canales independientes y mixtos) es la clave para mejorar el rendimiento de los modelos.

Modelo matricial de pronóstico basado en cadenas de Márkov
Hoy vamos a crear un modelo matricial de pronóstico basado en las cadenas de Márkov. ¿Qué son las cadenas de Márkov y cómo se puede usar una cadena de Márkov para negociar en Forex?