
Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)

Introducción
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. Y nos detuvimos en que, según los resultados de las pruebas prácticas de 2 artículos, hemos percibido un crecimiento bastante bueno de la rentabilidad de los resultados del modelo entrenado al principio del periodo de pruebas. Además, la eficacia del modelo disminuye y se observa un número de transacciones perdedoras, lo cual provoca pérdidas. El importe de las pérdidas obtenidas puede superar los beneficios percibidos anteriormente.
En tal situación, resulta probable que el reentrenamiento periódico del modelo pueda ayudar. No obstante, este enfoque complica enormemente el proceso de funcionamiento del modelo, y resulta perfectamente razonable plantearse el entrenamiento de modelos online. Pero aquí nos enfrentamos a una serie de retos que superar.
Una de las opciones para implementar el entrenamiento online del Decision Transformer se presenta en el artículo "Online Decision Transformer" (febrero de 2022). Cabe destacar de entrada que el método propuesto utiliza el entrenamiento offline inicial del DT clásico. El entrenamiento online se aplica en la posterior puesta a punto del modelo. Los resultados experimentales presentados en el artículo del autor demuestran que el ODT es capaz de competir con los líderes en rendimiento absoluto en la muestra de prueba D4RL. Al hacerlo, muestra una mejora mucho más sustancial en el proceso de ajuste.
Vamos a analizar el método propuesto en el contexto de la resolución de nuestros problemas.
1. Algoritmo ODT
Antes de explorar el algoritmo de ODT, le propongo recordar brevemente el Transformador de Decisión clásico. El DT trata la trayectoria τ como una secuencia de múltiples tokens de entrada: Return-to-Go (RTG), estados y acciones. En concreto, el valor inicial del RTG es igual al rendimiento de toda la trayectoria. En el paso de tiempo t, el DT usa los tokens K de los últimos pasos de tiempo para generar la acción At. En este caso, K supone un hiperparámetro que define la longitud del contexto para el transformador. Debemos señalar que la longitud del contexto puede ser menor durante la explotación que durante el entrenamiento.
DT se entrena con una política determinista π(At|St, RTGt), donde St supone una secuencia de K últimos estados desde t-K+1 hasta t Del mismo modo, RTGt personifica el K del último Return-to-Go. Se trata de un modelo autorregresivo de orden K. La política del Agente se entrena para predecir acciones usando la función de pérdida estándar MSE (Mean Square Error).
Durante la explotación, especificaremos el rendimiento RTGinit deseado y el estado inicial S0. DT generará entonces la acción A0. Tras generar la acción At, la ejecutaremos y observaremos el siguiente estado St+1, recibiendo la recompensa rt. Esto nos dará la siguiente RTGt+1.
![]()
Como antes, DT genera la acción A1 basada en la trayectoria que incluye A0, S0, S1 y RTG0, RTG1. Este proceso se repetirá hasta el final del episodio.
Las políticas entrenadas solo con conjuntos de datos offline suelen resultar subóptimas debido a lo limitado de los datos de la muestra de entrenamiento. Las trayectorias offline pueden tener un rendimiento bajo y cubrir solo una parte limitada del espacio de estados y acciones. Una estrategia natural para mejorar el rendimiento sería entrenar previamente a los Agentes RL en la interacción online con el entorno. Pero el método estándar del Decision Transformer es insuficiente para el aprendizaje online.
El algoritmo Decision Transformer online introduce modificaciones clave en el Decision Transformer para permitir un aprendizaje online eficaz. Y el primer paso será un objetivo de aprendizaje probabilístico generalizado. En este contexto, el objetivo consistirá en entrenar una política estocástica que maximice la probabilidad de repetir una trayectoria.
Una propiedad clave de un algoritmo de RL online será su capacidad para equilibrar el compromiso entre exploración y explotación. Incluso con políticas estocásticas, la formulación del DT tradicional no tiene en cuenta el exploración. Para abordar este problema, los autores del método ODT definen la exploración a través de la entropía de la política, que depende de la distribución de los datos en la trayectoria. Esta distribución es estática durante el entrenamiento offline previo, pero dinámica durante el ajuste online, ya que depende de los nuevos datos adquiridos durante la interacción con el entorno.
Al igual que muchos algoritmos de RL de entropía máxima existentes, como Soft Actor Critic, los autores del método ODT definen explícitamente un límite inferior en la entropía de la política para fomentar la exploración.
La diferencia entre la función de pérdida ODT y SAC y otros métodos clásicos de RL es que en el ODT la función de pérdida es la verosimilitud logarítmica negativa en lugar del retorno descontado. Básicamente, nos centramos solo en aprender del patrón de la secuencia de acciones, en lugar de maximizar explícitamente el rendimiento, y la función objetivo se adapta automáticamente para la política Actor correspondiente tanto en el aprendizaje offline como online. Durante el aprendizaje offline, la entropía cruzada controla el grado de desajuste de la distribución, mientras que durante el aprendizaje online dirige la política de exploración.
Otra diferencia importante respecto a los métodos clásicos de RL de entropía máxima es que en el ODT la entropía de la política se define a nivel de secuencias y no de transiciones. Mientras que el SAC impone un límite inferior β a la entropía de la política en todos los pasos temporales, el ODT limita la entropía promediada en K pasos temporales consecutivos. Así, la restricción solo requerirá que la entropía promediada sobre una secuencia de K pasos temporales sea superior al valor establecido de β. Por lo tanto, cualquier política que cumpla la restricción a nivel de transición también satisfará la restricción a nivel de secuencia. Así, el espacio de políticas admisibles será mayor cuando K > 1. Cuando K = 1, la restricción a nivel de secuencia se reducirá a una restricción a nivel de transición similar a SAC.
El proceso de entrenamiento del modelo usa un búfer de reproducción para registrar la experiencia previa con actualizaciones periódicas. Para la mayoría de los algoritmos de RL existentes, el búfer de reproducción de experiencias consta de transiciones. Después de cada paso de interacción online dentro de una época, la política del Agente y la función Q se actualizarán usando el descenso de gradiente. A continuación, se ejecutará la política para recopilar nuevas transiciones y añadirlas al búfer de reproducción de experiencias. En el caso de la ODT, el búfer de reproducción de experiencias se compondrá de trayectorias, no de transiciones. Tras el entrenamiento offline previo, inicializaremos el búfer de reproducción de experiencias con las trayectorias con los máximos resultados del conjunto de datos offline. Cada vez que interactuemos con el entorno, ejecutaremos íntegramente el episodio político en curso. A continuación, actualizaremos el búfer de reproducción de experiencias utilizando la trayectoria recopilada en orden FIFO. A continuación, actualizaremos la política del Agente y ejecutaremos un nuevo episodio. La evaluación de políticas usando la acción media suele dar lugar a mayores recompensas, pero resulta útil utilizar la acción aleatoria para la exploración online, ya que genera trayectorias y patrones de comportamiento más diversos.
Además, el algoritmo ODT necesita un hiperparámetro en forma de RTG inicial para recopilar datos online adicionales. Diversos trabajos demuestran que el rendimiento real estimado del DT offline tiene una fuerte correlación con el RTG inicial de forma empírica y a menudo puede extrapolar valores de RTG más allá de los rendimientos máximos observados en el conjunto de datos offline. Los autores de ODT descubrieron que es mejor establecer este hiperparámetro con una pequeña escala fija partiendo de los resultados disponibles del experto. Los autores del método usan un escalado doble en su trabajo. El artículo original presenta resultados experimentales con valores mucho mayores, así como valores que cambian durante el entrenamiento (por ejemplo, los cuantiles del mejor rendimiento estimado en conjuntos de datos offline y online). Pero en la práctica han demostrado no ser tan eficaces como la RTG a escala fija.
Al igual que DT, el algoritmo ODT usa un procedimiento de muestreo en dos pasos para garantizar que las subtrayectorias de longitud K se muestrean uniformemente en el búfer de reproducción. Primero muestrearemos una trayectoria con probabilidad proporcional a su longitud. Entonces elegiremos una subtrayectoria de longitud K con igual probabilidad.
Nos familiarizaremos con la aplicación práctica del método en la siguiente sección del presente artículo.
2. Implementación usando MQL5
Tras familiarizarnos con los aspectos teóricos del método, pasaremos a su aplicación práctica. En esta sección presentaremos nuestra propia visión de la aplicación de los planteamientos propuestos, complementada con los avances de los artículos anteriores. En concreto, el algoritmo ODT implica el entrenamiento del modelo en dos etapas:
- Entrenamiento offline previo.
- Ajuste del modelo durante la interacción online con el entorno.
Para nuestros objetivos en el marco de este artículo, utilizaremos el modelo preentrenado del artículo anterior. Por lo tanto, nos saltaremos la primera etapa de entrenamiento offline que ya se ha realizado antes, y pasaremos directamente a la segunda parte del proceso de entrenamiento del modelo.
También hay que señalar aquí que al considerar el método DoC en el artículo anterior, construimos y entrenamos offline 2 modelos:
- uno de generación de RTG;
- y otro de la política del Actor.
El uso del modelo de generación de RTG se aleja del algoritmo ODT del autor, que propone el uso de la escala de juicio de expertos para el RTG inicial y luego ajustar el objetivo a los resultados reales obtenidos.
Además, usar modelos previamente entrenados no nos permite cambiar la arquitectura de los modelos. Pero veamos si la arquitectura de los modelos usados es coherente con el algoritmo ODT.
Los autores del método proponen usar la política estocástica del Actor. Este es el que hemos utilizado en artículos anteriores. En ese sentido, estamos cumpliendo.
El ODT propone utilizar un búfer de reproducción de experiencias de las trayectorias en lugar de trayectorias individuales. Este es exactamente el tipo de búfer con el que estamos trabajando: aquí también coincidimos.
Debemos decir que en el entrenamiento de los modelos no utilizamos el componente de entropía de la función de pérdida para estimular la exploración del entorno. No lo añadiremos en esta fase y aceptaremos los posibles riesgos. Esperamos que la política estocástica de Actor y el modelo de generación RTG ofrezcan suficiente exploración en la interacción online con el entorno.
Otro punto que hemos excluido de la aplicación se refiere al búfer de reproducción de experiencias. Los autores del método proponen que, tras el aprendizaje offline, se seleccione un cierto número de las trayectorias más rentables para usarlas en las primeras etapas del entrenamiento online. En cambio, inicialmente hemos limitado el número de trayectorias en el búfer de reproducción de experiencias. Y al pasar al entrenamiento online, utilizaremos todo el búfer disponible de reproducción de experiencias, al que añadiremos nuevas trayectorias a medida que interactuemos con el entorno. De este modo, no eliminaremos de inmediato las trayectorias más antiguas al añadir otras nuevas. Limitaremos el tamaño del búfer utilizando los medios creados anteriormente al guardar los datos en un archivo una vez finalizada la pasada.
Así pues, dada la aceptación de los posibles riesgos, bien podemos utilizar los modelos entrenados en el artículo anterior. Además, trataremos de mejorar su rendimiento perfeccionándolos con el entrenamiento de modelos online mediante enfoques ODT.
Hay algunas cuestiones constructivas que debemos abordar aquí. El proceso comercial, por su naturaleza, es condicionalmente infinito. Condicionalmente, porque sigue siendo finito por varias razones, pero la probabilidad de que se produzca es tan pequeña en un futuro previsible que la consideramos infinita. En consecuencia, realizaremos el proceso de entrenamiento previo no al final de un episodio, como sugieren los autores del método, sino con cierta periodicidad.
Y aquí me gustaría recordarle que en nuestra implementación de DT, solo los datos de la última barra se suministrarán a la entrada del modelo. El volumen completo del contexto de datos históricos se almacenará en el búfer de resultados de la capa de incorporación. Este enfoque nos ha permitido reducir el consumo de recursos en el reprocesamiento de datos redundantes, pero esto se convierte en uno de los "escollos" del entrenamiento online. La cuestión es que los datos del búfer de incorporación se almacenan en una estricta secuencia histórica, y el uso del modelo en el proceso periódico de entrenamiento previo lleva a saturar el búfer con datos históricos de otras trayectorias o de la misma trayectoria pero con una historia diferente, lo cual sesgará los datos al seguir interactuando con el entorno después de haber preentrenado los modelos.
En realidad, existen varias soluciones para este problema. Todas tienen diferente complejidad de aplicación y consumo de recursos durante su funcionamiento. A primera vista, lo más simple es crear una copia del búfer y devolverla al estado anterior al inicio del proceso de entrenamiento, antes de continuar con el proceso de interacción con el entorno. Sin embargo, cuando observamos el proceso con detalle, nos damos cuenta de que solo se maneja la clase de modelo de nivel superior en el lado del modelo principal, sin acceso a los búferes de las capas neuronales individuales. Y en este contexto, el simple proceso de copiado de datos de un búfer fuera del modelo y dentro del modelo de vuelta provoca una serie de cambios en el diseño. Lo que hace que este método sea mucho más difícil de aplicar.
Sin prácticamente introducir cambios constructivos en el modelo, podemos volver a secuenciar todo el conjunto de datos históricos en el modelo una vez finalizado el proceso de entrenamiento previo. Pero esto provocará una cantidad significativa de repeticiones de pasadas directas de modelo. Y el volumen de dichas operaciones aumentará a medida que crezca el tamaño del contexto, lo que hará que este enfoque resulte ineficaz. El consumo de tiempo y recursos informáticos para el reprocesamiento de los datos puede superar el ahorro que se logre almacenando la historia de incorporaciones en el búfer de la capa neuronal.
Otra opción para resolver el problema sería usar modelos duplicados. Uno para interactuar con el entorno, mientras que el otro se usaría durante el entrenamiento previo. Este enfoque es más costoso en cuanto a recursos de memoria, pero resuelve completamente el problema con los datos en el búfer de la capa de incorporación. Sin embargo, se plantea la cuestión del intercambio de datos entre modelos. De hecho, tras el entrenamiento previo, el modelo de interacción con el entorno deberá utilizar la política actualizada del Agente. Del mismo modo actúa el modelo de generación RTG. Y aquí podemos recordar el método Soft Actor-Critic con su actualización suave de los modelos objetivo. Por extraño que parezca, éste es el mecanismo que nos permitirá transmitir pesos actualizados entre los modelos sin cambiar el resto de los búferes. Incluido el búfer de resultados de la capa de incorporación.
Para utilizar este enfoque, deberemos añadir un método de intercambio de pesos a la capa de incorporación, que no se ha utilizado anteriormente en la implementación de SAC.
Aquí debemos decir que al añadir un método, solo realizaremos adiciones directamente a la clase CNeuronEmbeddingOCL, ya que todas las APIs necesarias para su funcionamiento ya las establecimos e implementamos antes en forma de método virtual de la clase básica de la capa neuronal CNeuronBaseOCL. También debemos señalar que el funcionamiento de nuestro modelo no generará ningún error sin esta modificación. Después de todo, el método de la clase padre se usará por defecto, pero ese trabajo en este caso no sería completo ni correcto.
Para preservar la herencia y redefinir correctamente los métodos virtuales, declaramos un método con preservación de parámetros. En el cuerpo del método, llamaremos inmediatamente al método análogo de la clase padre.
bool CNeuronEmbeddingOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(!CNeuronBaseOCL::WeightsUpdate(source, tau)) return false;
Como hemos dicho muchas veces, este enfoque nos permite realizar todos los controles necesarios en una sola acción sin duplicidades innecesarias y realizar las operaciones necesarias sobre los objetos heredados.
Tras ejecutar con éxito las operaciones del método de la clase padre, comenzaremos a trabajar sobre los objetos declarados directamente en nuestra clase de incorporación. Pero para acceder a objetos similares de la clase donante deberemos redefinir el tipo del objeto recibido.
//---
CNeuronEmbeddingOCL *temp = source;
A continuación tendremos que transferir los parámetros del búfer WeightsEmbedding. Pero antes de continuar con las operaciones, compararemos los tamaños de búfer del objeto actual y del objeto donante,
if(WeightsEmbedding.Total() != temp.WeightsEmbedding.Total()) return false;
y luego transferiremos el contenido de un búfer a otro. Sin embargo, debemos recordar que todas las operaciones de búferes se realizan en el lado del contexto OpenCL. Por ello, realizaremos la migración de datos también en el lado del contexto. Hemos usado deliberadamente la expresión "migración de datos" en lugar de "copia", ya que dejo la posibilidad de un "copiado suave" con el coeficiente como lo proporciona el algoritmo SAC para los modelos objetivo. Antes ya hemos creado núcleos de programas OpenCL. Y ahora todo lo que tenemos que hacer es organizar su llamada.
Definiremos el espacio de tareas del kernel en el tamaño del búfer de coeficientes de peso.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {WeightsEmbedding.Total()};
A continuación, el algoritmo se ramificará en función del algoritmo de actualización de parámetros utilizado. La ramificación es necesaria porque necesitaremos más búferes e hiperparámetros si usamos el método Adam, lo cual llevará al uso de diversos kernels.
Primero crearemos una ramificación del método Adam. Para utilizarla, deberán cumplirse 2 condiciones:
- la indicación del método correspondiente para actualizar los parámetros al crear un objeto, ya que de ello dependerá la creación de objetos de los búferes de datos correspondientes;
- el coeficiente de actualización deberá ser distinto de 1, ya que de lo contrario se requerirá un copiado completo de los datos, independientemente del método de actualización de parámetros utilizado.
if(tau != 1.0f && optimization == ADAM) { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, FirstMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, SecondMomentumEmbed.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
Después enviaremos el kernel SoftUpdateAdam a la cola de ejecución.
Realizaremos una operación análoga en la segunda ramificación del algoritmo, pero para el kernel SoftUpdate.
else { if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_target, WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdate, def_k_su_source, temp.WeightsEmbedding.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdate, def_k_su_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdate, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
El problema constructivo está resuelto y podemos pasar a la aplicación práctica del método de entrenamiento online. El proceso de interacción con el entorno y el entrenamiento adicional simultáneo de los modelos se organizará en el asesor ".../\DoC\OnlineStudy.mq5". Este asesor es una especie de simbiosis de los asesores de recopilación de datos discutidos en artículos anteriores y el entrenamiento directo del modelo offline. Contiene todos los parámetros externos necesarios para interactuar con el entorno, concretamente, los parámetros de los indicadores. Pero, en este caso, añadiremos parámetros para especificar la frecuencia y el número de iteraciones del entrenamiento online. El asesor utiliza por defecto datos subjetivos. He especificado una periodicidad de entrenamiento de 120 velas, que en el marco temporal H1 se corresponde aproximadamente con 1 semana (5 días * 24 horas). Durante la optimización, podremos seleccionar los valores más óptimos para nuestros modelos.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod= 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int StudyIters = 5; //Iterations to Study input int StudyPeriod = 120; //Bars between Studies
En el método de inicialización del asesor, primero cargaremos el búfer de reproducción de experiencias creado previamente. Luego realizaremos acciones similares en los asesores "Study.mql5" de varios métodos de aprendizaje offline, solo que ahora no terminaremos el asesor cuando falle la carga de datos. A diferencia del modo offline, solo permitiremos que los modelos se entrenen con los nuevos datos que se recojan interactuando con el entorno.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { LoadTotalBase();
A continuación, prepararemos los indicadores, al igual que hicimos anteriormente en los asesores de interacción con el entorno.
if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Luego cargaremos los modelos y comprobaremos su coherencia en cuanto al tamaño de las capas de datos de origen y resultados. Si fuera necesario, crearemos nuevos modelos con una arquitectura predefinida. Esto va un poco más allá del entrenamiento previo de modelos, pero dejaremos que sea el usuario quien realice el entrenamiento online desde cero.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true) || !AgentStudy.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTGStudy.Load(FileName + "RTG.nnw", dtStudied, true)) { PrintFormat("Can't load pretrained models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent, rtg)) { delete agent; delete rtg; PrintFormat("Can't create description of models"); return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg) || !AgentStudy.Create(agent) || !RTGStudy.Create(rtg)) { delete agent; delete rtg; PrintFormat("Can't create models"); return INIT_FAILED; } delete agent; delete rtg; //--- } //--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } AgentResult = vector<float>::Zeros(NActions); //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear(); RTG.Clear();
Tenga en cuenta que cargaremos (o inicializaremos) 2 copias de cada modelo. Una para interactuar con el entorno. Y otra que se utilizará durante el entrenamiento. Los modelos entrenados han recibido el sufijo Study.
A continuación, inicializaremos las variables globales y finalizaremos el método.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del asesor, guardaremos los modelos entrenados y el búfer acumulado de reproducción de experiencias.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- AgentStudy.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTGStudy.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; int total = ArraySize(Buffer); printf("Saving %d", MathMin(total + 1, MaxReplayBuffer)); SaveTotalBase(); Print("Saved"); }
Tenga en cuenta que son los modelos entrenados los que se guardarán, dado que sus búferes contienen toda la información necesaria para el posterior entrenamiento y funcionamiento de los modelos.
El proceso de interacción con el entorno se organizará en el método de gestión de ticks OnTick. Al principio del método comprobaremos la aparición del evento de apertura de una nueva barra y actualizaremos los parámetros del indicador si fuera necesario. Y también cargaremos los datos sobre el movimiento de los precios.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Asimismo, prepararemos los datos recibidos del terminal para transmitirlos al modelo de interacción con el entorno como datos de entrada.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Completaremos el búfer de datos con información sobre el estado de la cuenta.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
A continuación, crearemos una marca temporal.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Y añadiremos un vector de acciones recientes del Agente que nos han llevado al estado actual.
//--- Prev action
bState.AddArray(AgentResult);
Los datos recogidos serán suficientes para realizar una pasada directa del modelo de generación RTG.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
De hecho, a nuestro vector de datos de entrada solo le faltarán estos datos para predecir las acciones óptimas del Agente en el intervalo de tiempo actual. Por ello, después de la pasada directa exitosa del primer modelo, añadiremos los resultados obtenidos al búfer de datos de origen y llamaremos al método de pasada directa de nuestro Actor. Asegúrese de comprobar el resultado de las operaciones.
RTG.getResults(Result); bState.AddArray(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Tras ejecutar con éxito una pasada directa de los modelos, descodificaremos sus resultados y realizaremos la acción seleccionada en el entorno. Este proceso es totalmente coherente con el algoritmo discutido anteriormente en los modelos de interacción con el entorno.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Estimamos la recompensa del entorno según la transición al estado actual. Y toda la información recopilada se transmitirá para formar la trayectoria actual.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove();
Así se completará el proceso de interacción con el entorno. Pero antes de salir del método, comprobaremos si es necesario realizar el proceso de entrenamiento previo del modelo. Para comprobar la eficacia del método, hemos usado probablemente el control más sencillo. Simplemente hemos comprobado la multiplicidad del tamaño de la historia completa en el instrumento en el marco temporal analizado de la periodicidad de entrenamiento. En un entorno comercial, resulta deseable usar enfoques más deliberados para desplazar el proceso de entrenamiento previo a los periodos de cierre del mercado o de volatilidad reducida para el instrumento. Además, podría ser útil retrasar el proceso de actualización de los parámetros del modelo hasta que todas las posiciones estén cerradas. En general, para su uso en modelos del mundo real, yo recomendaría un enfoque más deliberado y sensato a la hora de elegir la frecuencia y el momento del entrenamiento previo del modelo.
//--- if((Bars(_Symbol, TimeFrame) % StudyPeriod) == 0) Train(); }
A continuación, nos centraremos en el método de entrenamiento de modelos Train. A este respecto, cabe señalar que el entrenamiento previo se lleva a cabo considerando la experiencia adquirida en la interacción actual con el entorno. En el método de procesamiento de tics, hemos reunido toda la información recibida del entorno en una trayectoria separada. No obstante, esta trayectoria no se añadirá al búfer de reproducción de experiencias. Antes, solo realizábamos una operación de este tipo al final del episodio. Pero este enfoque no resulta aceptable en nuestro caso con actualizaciones periódicas de los parámetros. De hecho, nos acerca al aprendizaje offline, en el que la política del Agente se aprende solo partiendo de trayectorias fijas de una experiencia previa. Por lo tanto, antes de iniciar el proceso de entrenamiento, añadiremos los datos recogidos al búfer de reproducción de experiencias.
Para evitar el registro de trayectorias demasiado cortas y poco informativas, limitaremos el tamaño mínimo de la trayectoria guardada. En el ejemplo anterior, hemos limitado el tamaño mínimo de la trayectoria del periodo de actualización de los parámetros del modelo.
Si el tamaño de la trayectoria acumulada cumple los requisitos mínimos, la añadiremos al búfer de reproducción de experiencias y recalcularemos las recompensas acumuladas.
Tenga en cuenta que solo recalcularemos la recompensa acumulada para el copiado de la trayectoria transmitida al búfer de reproducción de experiencias. La recompensa deberá permanecer sin calcular en el búfer de acumulación inicial sobre la información de la trayectoria actual. Al fin y al cabo, la trayectoria se verá aumentada en posteriores interacciones con el entorno, y, por tanto, cuando la trayectoria actualizada se añada de nuevo, el recálculo de la recompensa acumulada dará lugar a un retroceso de los datos. Y para evitarlo, siempre mantendremos una recompensa sin calcular en el búfer de acumulación de trayectorias.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); if(Base.Total >= StudyPeriod) if(ArrayResize(Buffer, total_tr + 1) == (total_tr + 1)) { Buffer[total_tr] = Base; Buffer[total_tr].CumRevards(); total_tr++; }
Entonces deberemos recordar que el tamaño del búfer de acumulación de trayectorias está limitado por la constante Buffer_Size. Y para evitar un error de desbordamiento del array, comprobaremos que haya suficientes celdas libres en el búfer de acumulación de trayectorias para registrar los pasos antes del siguiente almacenamiento de trayectoria. De ser necesario, eliminaremos algunos de los pasos más antiguos.
Tenga en cuenta que estamos eliminando los datos del búfer de acumulación de trayectorias primario. Al mismo tiempo, esta información se almacena en el copiado de trayectoria que guardamos en el búfer de reproducción de experiencias.
Al especificar las constantes y los parámetros del modelo, deberemos considerar que el tamaño del búfer de trayectorias permita guardar la historia de al menos un periodo entre los entrenamientos adicionales del modelo.
int clear = Base.Total + StudyPeriod - Buffer_Size; if(clear > 0) Base.ClearFirstN(clear);
Luego hemos añadido un control adicional que puede parecer innecesario. Yo suelo comprobar el búfer de reproducción de experiencias en busca de trayectorias cortas y las borro si las encuentro. A primera vista, la presencia de estas trayectorias resulta poco probable debido a la presencia de un control similar antes de que la trayectoria se añada al búfer de reproducción de experiencias. Pero sigo considerando la posibilidad de que se produzcan algunos fallos al leer y escribir las trayectorias en el archivo. Y precisamente para excluir errores posteriores realizaremos esta comprobación.
//--- int count = 0; for(int i = 0; i < (total_tr + count); i++) { if(Buffer[i + count].Total < StudyPeriod) { count++; i--; continue; } if(count > 0) Buffer[i] = Buffer[i + count]; } if(count > 0) { ArrayResize(Buffer, total_tr - count); total_tr = ArraySize(Buffer); }
A continuación, organizaremos un sistema de ciclos de entrenamiento de modelos. Este proceso resulta muy parecido al del artículo anterior. El ciclo externo está organizado según el número de iteraciones de entrenamiento del modelo especificado en los parámetros externos del asesor.
En el cuerpo del ciclo, seleccionaremos aleatoriamente una trayectoria y un elemento de esa trayectoria a partir de los cuales comenzar la siguiente iteración del entrenamiento del modelo.
uint ticks = GetTickCount(); //--- bool StopFlag = false; for(int iter = 0; (iter < StudyIters && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
A continuación, borraremos los búferes de incorporación del modelo y el vector de acciones anteriores del Actor.
vector<float> Actions = vector<float>::Zeros(NActions); AgentStudy.Clear(); RTGStudy.Clear();
Llegados a este punto, hemos completado el trabajo preparatorio y podemos iniciar las operaciones de entrenamiento directo de modelos. Organizamos un ciclo anidado de entrenamiento.
En el cuerpo del ciclo repetiremos el proceso de preparación del búfer de datos de origen, similar al descrito anteriormente en el método de procesamiento de ticks. La secuencia de escritura de datos en el búfer se repetirá por completo, solo que si antes solicitábamos los datos al terminal, ahora los tomaremos del búfer de reproducción de experiencias.
for(int state = i; state < MathMin(Buffer[tr].Total - 2, int(i + HistoryBars * 1.5)); state++) { //--- History data bState.AssignArray(Buffer[tr].States[state].state); //--- Account description float prevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float prevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); bState.Add((Buffer[tr].States[state].account[0] - prevBalance) / prevBalance); bState.Add(Buffer[tr].States[state].account[1] / prevBalance); bState.Add((Buffer[tr].States[state].account[1] - prevEquity) / prevEquity); bState.Add(Buffer[tr].States[state].account[2]); bState.Add(Buffer[tr].States[state].account[3]); bState.Add(Buffer[tr].States[state].account[4] / prevBalance); bState.Add(Buffer[tr].States[state].account[5] / prevBalance); bState.Add(Buffer[tr].States[state].account[6] / prevBalance); //--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(Actions);
Tras recoger la primera parte de los datos de origen, realizaremos una pasada directa del modelo de generación RTG. Y luego realizaremos una pasada directa para minimizar el error a la recompensa real recibida. De este modo, construiremos un modelo autorregresivo para predecir posibles recompensas a partir de la trayectoria previa de estados y acciones.
//--- Return to go if(!RTGStudy.feedForward(GetPointer(bState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } Result.AssignArray(Buffer[tr].States[state + 1].rewards); if(!RTGStudy.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Con el fin de entrenar la política del Agente, indicaremos la recompensa real recibida en el búfer de datos de origen en lugar de la RTG predicha y realizaremos una pasada directa.
//--- Policy Feed Forward bState.AddArray(Buffer[tr].States[state + 1].rewards); if(!AgentStudy.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
La política del Agente se entrenará para minimizar el error entre la acción predicha y la acción realmente realizada que ha dado lugar a la recompensa.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; AgentStudy.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!AgentStudy.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Esto permitirá construir un modelo autorregresivo de selección óptima de acciones para obtener la recompensa deseada en el contexto de los estados visitados previamente y las acciones realizadas del Agente.
Después de ejecutar con éxito las iteraciones de entrenamiento del modelo, informaremos al usuario sobre el progreso de las operaciones de entrenamiento y procederemos a la siguiente iteración del ciclo de entrenamiento del modelo.
Una vez completadas todas las iteraciones del sistema de ciclos anidados del proceso de entrenamiento del modelo, eliminaremos el campo de comentarios del gráfico y transferiremos los parámetros de los modelos entrenados a los modelos de interacción con el entorno. En el ejemplo anterior, copiamos completamente los datos de los coeficientes de peso. De este modo emularemos el uso de un único modelo para el entrenamiento y la explotación. No obstante, también se permiten experimentos con diferentes proporciones de copiado de datos.
Comment(""); //--- Agent.WeightsUpdate(GetPointer(AgentStudy), 1.0f); RTG.WeightsUpdate(GetPointer(RTGStudy), 1.0f); //--- }
Con esto concluimos nuestra revisión del algoritmo del asesor de entrenamiento Online Decision Transformer; encontrará el código completo del asesor y todos sus métodos en el archivo adjunto.
Tenga en cuenta que el asesor "...\DoC\OnlineStudy.mq5" se encuentra en el subdirectorio "DoC" con los asesores del artículo anterior. No lo hemos dejado en un subdirectorio aparte, porque funcionalmente realiza un entrenamiento adicional de los modelos entrenados por los asesores offline del artículo anterior. De este modo, preservaremos la integridad del conjunto de archivos de entrenamiento del modelo.
Además, en el archivo adjunto encontrará todos los programas usados en el artículo actual y en los anteriores.
3. Simulación
Más arriba hemos revisado los aspectos teóricos del método del Decision Transformer online y hemos construido nuestra propia interpretación, un tanto libre, del método propuesto. El siguiente paso será comprobar el trabajo realizado. De hecho, realizaremos el ajuste fino de los modelos del artículo anterior. Para ello, realizaremos un ciclo de ejecuciones individuales de nuestro nuevo asesor sobre la historia de datos de entrenamiento en el simulador de estrategias.
Recordemos que en el artículo anterior hicimos un entrenamiento offline del modelo con datos históricos de los 7 primeros meses de 2023. Precisamente en este segmento de la historia afinaremos los modelos.
En el proceso de puesta a punto de los modelos, ODT ha mejorado la rentabilidad global de los mismos. En la muestra de prueba correspondiente a agosto de 2023, el modelo ha obtenido un beneficio del 10%. El gráfico de rendimiento no es perfecto, pero ya muestra algunas tendencias.

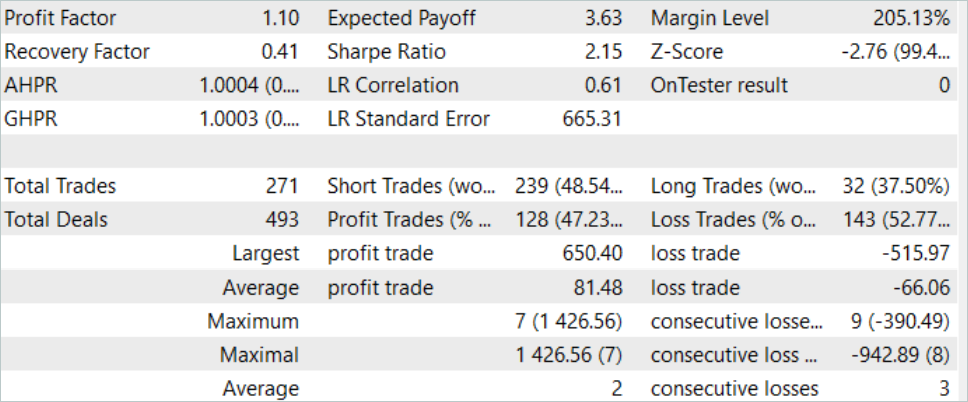
Los resultados de las pruebas realizadas con el modelo entrenado se presentan más arriba. Durante el periodo de prueba hemos realizado un total de 271 transacciones. Y 128 de ellas se han cerrado con beneficios, lo cual supone más del 47%. Como podemos ver, la proporción de transacciones rentables es ligeramente inferior a la proporción de perdedoras, pero la operación rentable máxima es un 26% superior a la pérdida máxima, mientras que la media de transacciones rentables es más de un 20% superior a la media de transacciones perdedoras. Todo ello ha aumentado el factor de beneficio del rendimiento del modelo a 1,10.
Conclusión
En este artículo, hemos seguido explorando opciones para mejorar la eficacia del método de Decision Transformer y hemos introducido el algoritmo de Online Decision Transformer (ODT) para el ajuste fino de los modelos en el entrenamiento online. Este método mejora el rendimiento de los modelos entrenados offline y permite a los Agentes adaptarse a un entorno cambiante, mejorando así sus políticas mediante la interacción con el entorno.
En la parte práctica del artículo, hemos implementado el método utilizando las herramientas MQL5 y el entrenamiento online de los modelos del artículo anterior. Cabe señalar aquí que la optimización de los modelos solo se obtiene aplicando el método ODT analizado. En el proceso de entrenamiento online, hemos utilizado los modelos que se entrenaron offline en el artículo anterior. No hemos introducido cambios estructurales en la arquitectura de los modelos, solo hemos realizado el entrenamiento previo online, y esto ha mejorado la eficacia de los modelos, lo cual en sí mismo confirma la eficacia del uso del método Online Decision Transformer.
Una vez más, me gustaría recordarle que todos los programas presentados en este artículo están destinados únicamente a la demostración tecnológica y no están listos para su uso en el comercio real.
Enlaces
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Online Decision Transformer
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Redes neuronales: así de sencillo (Parte 34): Función cuantílica totalmente parametrizada
- Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer-DT)
- Redes neuronales: así de sencillo (Parte 59): Dicotomía de control (DoC)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | OnlineStudy.mq5 | Asesor | Asesor de entrenamiento previo para agentes online |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13596
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
Experimentos con redes neuronales (Parte 7): Transmitimos indicadores
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso