Artículos con ejemplos de programación de robots comerciales en el lenguaje MQL5
En el ámbito del trading automático los Asesores Expertos es la cima de la programación y objetivo deseable de cada desarrollador. Usted puede escribir su propio Asesor Experto utilizando los artículos de esta sección. Paso a paso los principiantes podrán pasar todas las fases de creación, depuración y simulación de los sistemas automáticos de trading.
Los artículos no sólo enseñarán a programar en el lenguaje MQL5, sino mostrarán cómo implementar cualquier idea y técnica comercial. Usted conocerá cómo programar el Trailing Stop, cómo realizar la gestión del capital, cómo obtener el valor del indicador y muchas cosas más.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Introducción a MQL5 (Parte 26): Creación de un EA basado en zonas de soporte y resistencia
Este artículo te enseña cómo crear un Asesor Experto MQL5 que detecta automáticamente las zonas de soporte y resistencia y ejecuta operaciones basándose en ellas. Aprenderás a programar tu EA para identificar estos niveles clave del mercado, monitorear las reacciones de los precios y tomar decisiones de trading sin intervención manual.
Introducción a MQL5 (Parte 25): Creación de un asesor experto (EA) que opere a partir de objetos del gráfico (II)
Este artículo explica cómo crear un Asesor Experto (EA) que interactúe con los objetos del gráfico, en particular con las líneas de tendencia, para identificar y operar con oportunidades de ruptura y reversión. Aprenderás cómo el Asesor Experto (EA) confirma las señales válidas, gestiona la frecuencia de las operaciones y mantiene la coherencia con las estrategias seleccionadas por el usuario.

Redes neuronales en el trading: Modelo multidimensional de extremo a extremo para la previsión de series temporales (Final)
Les presentamos la parte final de la serie dedicada a GinAR, un framework de red neuronal para la predicción de series temporales. En este artículo, vamos a analizar los resultados de las pruebas realizadas al modelo con datos nuevos y a evaluar su robustez en condiciones reales de mercado.

Redes neuronales en el trading: Modelo multidimensional de extremo a extremo para la previsión de series temporales (Componentes principales)
Hoy les invitamos a explorar una nueva implementación de los componentes clave del framework GinAR, un algoritmo adaptativo para trabajar con series temporales de grafos. El artículo ofrece un análisis paso a paso de la arquitectura y los algoritmos de propagación directa e inversa del error.

Automatización de estrategias de trading en MQL5 (Parte 18): Estrategia de scalping «Trend Bounce» con envolventes: Ejecución de operaciones y gestión del riesgo (Parte II)
En este artículo, implementamos la ejecución de operaciones y la gestión de riesgos para la estrategia de scalping Envelopes Trend Bounce en MQL5. Implementamos la apertura de órdenes y controles de riesgo, como la orden de stop-loss y el dimensionamiento de posiciones. Concluimos con el backtesting y la optimización, partiendo de los fundamentos de la Parte 18.

De novato a experto: Utilidad de control de parámetros
Imagínese transformar las propiedades de entrada tradicionales de un EA o indicador en una interfaz de control en tiempo real directamente en el gráfico. Este análisis se basa en nuestro trabajo fundamental sobre el indicador Market Periods Synchronizer, lo que supone una evolución significativa en la forma en que visualizamos y gestionamos las estructuras de mercado en marcos temporales superiores (HTF). Aquí, convertimos ese concepto en una herramienta totalmente interactiva: un panel de control que ofrece control dinámico y una visualización mejorada de la acción del precio en múltiples períodos directamente en el gráfico. Acompáñanos a explorar cómo esta innovación transforma la manera en que los traders interactúan con sus herramientas.

Introducción a MQL5 (Parte 23): Automatización de la estrategia de ruptura del rango de apertura (ORB)
Este artículo explora cómo crear un Asesor Experto de Ruptura de Rango de Apertura (ORB, por sus siglas en inglés) en MQL5. Explica cómo el Asesor Experto (EA) identifica las rupturas del rango inicial del mercado y abre operaciones en consecuencia. También aprenderás a controlar el número de posiciones abiertas y a establecer una hora límite específica para detener las operaciones automáticamente.

Motor de decisión Multi-IA para MQL5 (Parte 4): ¿El multi-IA le gana a una sola IA? Diario, scorecard y costo
Esta parte añade la capa de evaluación al motor multi-IA. Cada ciclo queda registrado en un diario con la señal y la confianza de cada proveedor y el voto combinado; al vencer el horizonte, se califica a cada IA como si la siguiéramos sola y se compara en igualdad de condiciones. Además, se estima el costo de las llamadas y se muestra un cuadro de mando en el gráfico y un CSV para decidir si el conjunto aporta y qué modelo conviene podar o ajustar.

Motor de decisión Multi-IA para MQL5 (Parte 3): Darle a las IA el contexto correcto — régimen de mercado y noticias
Tercera parte de la serie: le damos al motor multi-IA el contexto donde un modelo de lenguaje sí aporta. Leemos el régimen de mercado en el código (tendencia o rango con ADX, volatilidad con el ATR contra su promedio, dirección con la pendiente de una EMA) y definimos ventanas de noticias de alto impacto configurables, sin depender del calendario del broker. Ambos entran en un prompt más rico que le pide a cada IA razonar el contexto —no el próximo tick— y devolver una bandera de riesgo. Un gating de dos capas, por horario y por consenso de las IA, mantiene al motor fuera del mercado cuando el contexto pesa más que la señal.
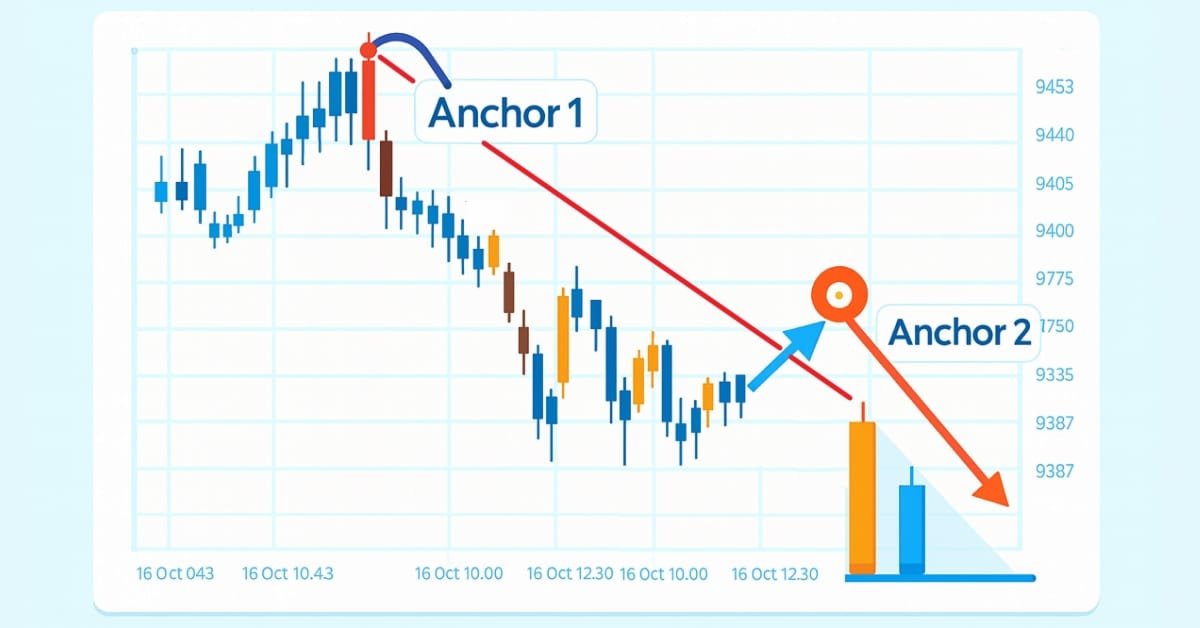
De novato a experto: Noticias animadas utilizando MQL5 (XI): Correlación en el trading con noticias
En este artículo, analizaremos cómo se puede aplicar el concepto de correlación financiera para mejorar la eficiencia en la toma de decisiones a la hora de operar con varios símbolos durante el anuncio de acontecimientos económicos importantes. El objetivo es abordar el desafío que supone la mayor exposición al riesgo provocada por la creciente volatilidad durante la publicación de noticias.

Motor de decisión Multi-IA para MQL5 (Parte 2): Voto ponderado que aprende en cuál IA confiar, más gestión de riesgo
Esta segunda parte convierte el motor multi-IA en un sistema que aprende en qué modelos confiar. Se registra cada predicción, se evalúa su acierto tras un horizonte y se actualiza un hit-rate por proveedor (EMA), para ponderar el voto por confianza × acierto real. Además, se añade gestión de riesgo: SL/TP basada en ATR con ratio recompensa-riesgo fijado en el código y tamaño de posición escalado por la confianza. Útil para pruebas de demostración.
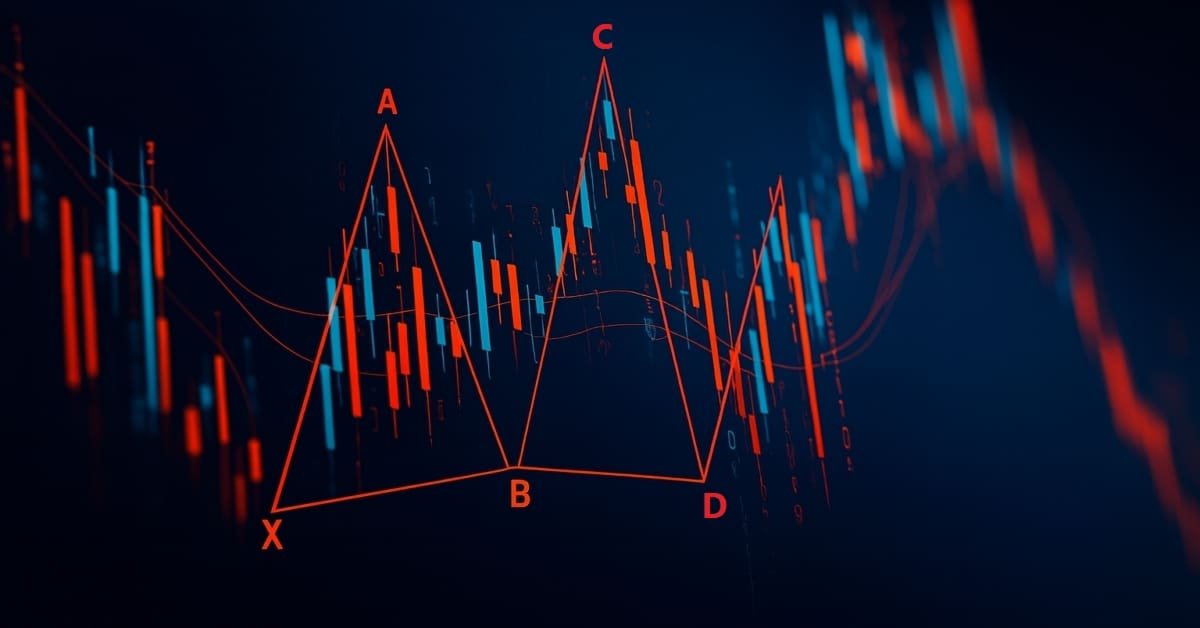
Introducción a MQL5 (Parte 21): Automatización de la detección de patrones armónicos
Aprende a detectar y visualizar el patrón armónico de Gartley en MetaTrader 5 utilizando MQL5. Este artículo explica cada paso del proceso, desde la identificación de los puntos de oscilación hasta la aplicación de las proporciones de Fibonacci y el trazado del patrón completo en el gráfico para obtener una confirmación visual clara.

De novato a experto: Noticias animadas utilizando MQL5 (X) Vista multigráfico de múltiples símbolos para el trading de noticias
Hoy vamos a desarrollar un sistema de visualización de varios gráficos utilizando objetos de gráfico. El objetivo es mejorar el trading basado en noticias mediante la aplicación de algoritmos MQL5 que ayudan a reducir el tiempo de reacción de los operadores en períodos de alta volatilidad, como los momentos en que se publican noticias importantes. En este caso, ofrecemos a los traders una forma integrada de supervisar múltiples símbolos principales a través de una única herramienta integral de trading basada en noticias. Nuestro trabajo sigue avanzando con News Headline EA, que ahora cuenta con un conjunto cada vez mayor de funciones que aportan un valor real tanto a los operadores que utilizan sistemas totalmente automatizados como a aquellos que prefieren el trading manual asistido por algoritmos. Descubre más conocimientos, ideas prácticas y observaciones continuando la lectura y sumándote a esta discusión.

Introducción a MQL5 (Parte 20): Introducción a los patrones armónicos
En este artículo, analizamos los fundamentos de los patrones armónicos, sus estructuras y cómo se aplican en el trading. Aprenderás sobre los retrocesos y las extensiones de Fibonacci, así como a implementar la detección de patrones armónicos en MQL5, sentando así las bases para crear herramientas de trading avanzadas y asesores expertos.

De novato a experto: Noticias animadas utilizando MQL5 (IX) Gestión de múltiples símbolos en un único gráfico para el trading de noticias
El trading basado en noticias suele requerir la gestión de múltiples posiciones y símbolos en muy poco tiempo debido al aumento de la volatilidad. En este artículo, abordamos los retos que plantea el trading con múltiples símbolos mediante la integración de esta función en nuestro EA «News Headline». En este artículo veremos cómo el trading algorítmico con MQL5 hace que el trading con múltiples símbolos sea más eficiente y eficaz.

Formulación de un Asesor Experto Multipar Dinámico (Parte 4): Ajuste de volatilidad y riesgo
Esta fase permite ajustar con precisión tu EA multipar para adaptar el tamaño de las operaciones y el riesgo en tiempo real utilizando indicadores de volatilidad como el ATR, lo que mejora la consistencia, la protección y el rendimiento en diversas condiciones de mercado.

De novato a experto: Noticias animadas utilizando MQL5 (VIII) Botones de operación rápida para trading de noticias
Aunque los sistemas de trading algorítmico gestionan las operaciones de forma automatizada, muchos traders que operan en función de las noticias y los scalpers prefieren mantener un control activo durante noticias de alto impacto y en condiciones de mercado de ritmo acelerado, lo que exige una rápida ejecución y gestión de las órdenes. Esto pone de relieve la necesidad de contar con herramientas front-end intuitivas que integren fuentes de noticias en tiempo real, datos del calendario económico, análisis de indicadores, análisis basados en inteligencia artificial y controles de trading ágiles y de respuesta inmediata.

Redes neuronales en el trading: Modelo multivariado de extremo a extremo para la predicción de series temporales (GinAR)
Le invitamos a explorar un enfoque innovador para la previsión de series temporales con datos faltantes usando el framework GinAR. El artículo muestra la implementación de componentes clave en OpenCL, lo que garantiza un alto rendimiento. En este artículo, analizaremos con detalle la integración de estas soluciones en MQL5. Esto nos permitirá comprender cómo aplicar el método en la práctica en el trading.
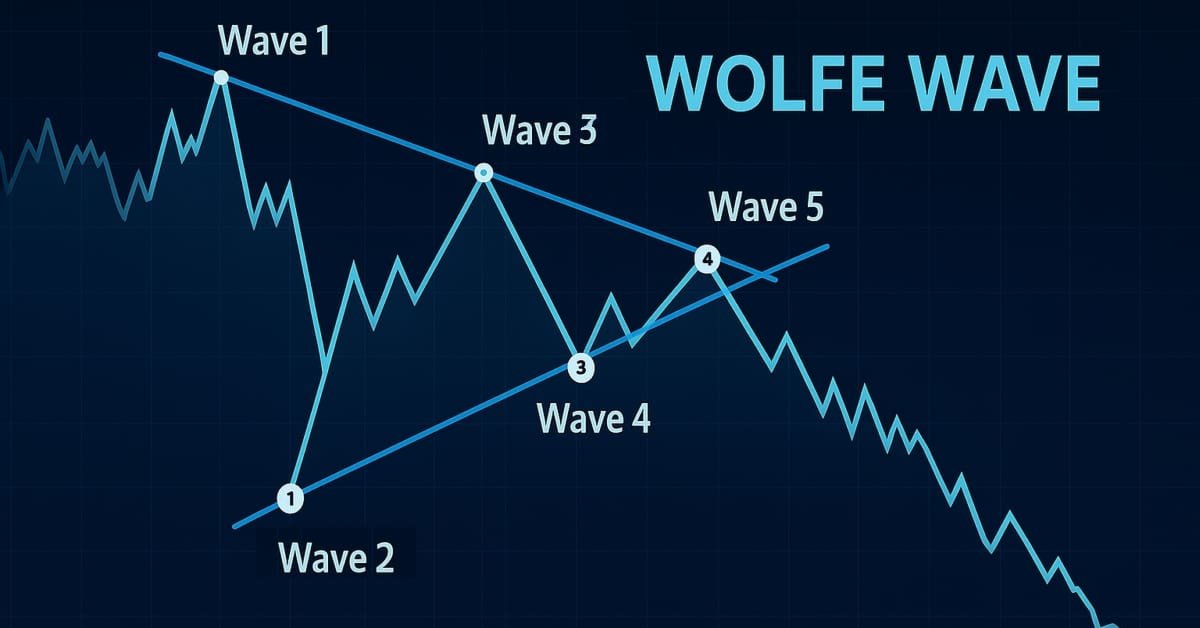
Introducción a MQL5 (Parte 19): Automatización de la detección de las ondas de Wolfe
Este artículo explica cómo identificar mediante programación los patrones de onda de Wolfe alcistas y bajistas y cómo operar con ellos utilizando MQL5. Veremos cómo identificar las estructuras de la onda de Wolfe mediante programación y cómo ejecutar operaciones basadas en ellas utilizando MQL5. Esto incluye detectar puntos de inflexión clave, validar las reglas de los patrones y preparar el EA para que actúe en función de las señales que detecte.

Redes neuronales en el trading: Previsión probabilística de series temporales (Final)
Le invitamos a explorar el framework K²VAE y a descubrir cómo integrar los enfoques propuestos en su sistema de negociación. Hoy aprenderá cómo el enfoque híbrido Koopman-Kalman-VAE ayuda a construir modelos adaptativos e interpretables. Al final del artículo le presentaremos los resultados prácticos del uso de las soluciones implementadas.

De novato a experto: Noticias animadas utilizando MQL5 (V) Sistema de recordatorio de eventos
En esta discusión, exploraremos nuevas mejoras a medida que integramos una lógica mejorada de alertas de eventos para los acontecimientos del calendario económico que muestra el EA «News Headline». Esta mejora es fundamental, ya que garantiza que los usuarios reciban notificaciones oportunas poco antes de que tengan lugar eventos importantes. Acompáñanos en este análisis para descubrir más.

Red neuronal cuántica en MQL5 (Parte I): Creamos un archivo de inclusión
El artículo presenta un nuevo enfoque para la creación de sistemas de negociación basados en principios cuánticos e inteligencia artificial. El autor describe el desarrollo de una red neuronal única que va más allá del aprendizaje automático clásico al integrar la mecánica cuántica con las arquitecturas de inteligencia artificial modernas.

Redes neuronales en el trading: Previsión probabilística de series temporales (Codificador)
Le invitamos a explorar un nuevo enfoque que combina métodos clásicos y redes neuronales modernas para el análisis de series temporales. El artículo ofrece una descripción detallada de la arquitectura y los principios de funcionamiento del modelo K²VAE.
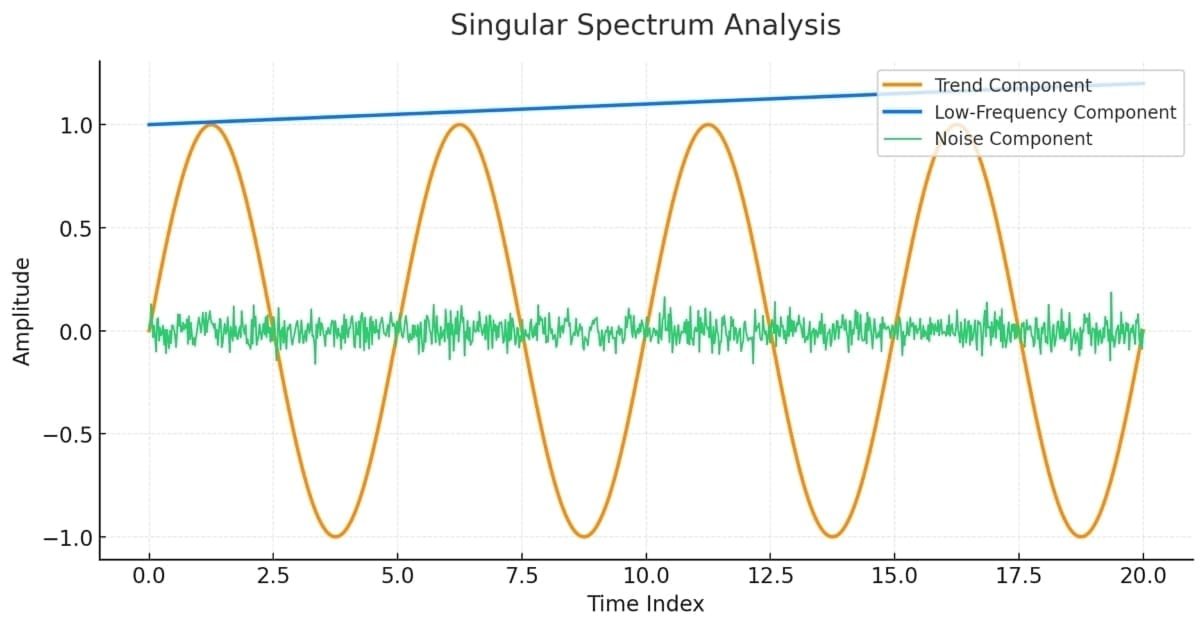
Análisis de espectro singular (SSA) en MQL5
Este artículo pretende servir de guía para aquellas personas que no estén familiarizadas con el concepto de análisis de espectro singular (SSA) y que deseen adquirir los conocimientos necesarios para poder aplicar las herramientas integradas disponibles en MQL5.
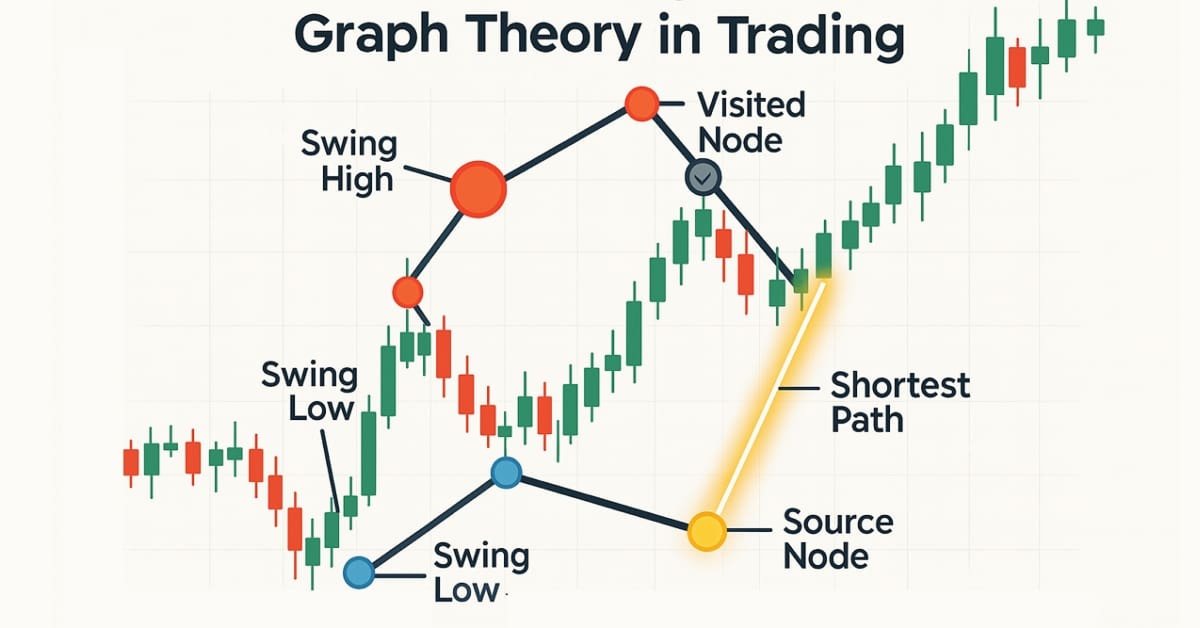
Teoría de grafos: Aplicación del algoritmo de Dijkstra al trading
El algoritmo de Dijkstra, una solución clásica para hallar el camino más corto en la teoría de grafos, puede optimizar las estrategias de trading mediante la modelización de las redes de mercado. Los traders pueden utilizarlo para encontrar las rutas más eficientes en los datos del gráfico de velas.

Formulación de un Asesor Experto Multipar Dinámico (Parte 3): Estrategias de reversión a la media y de impulso
En este artículo, analizaremos la tercera parte de nuestro proceso de creación de un asesor experto (EA) dinámico para múltiples pares, centrándonos específicamente en la integración de las estrategias de trading de reversión a la media y momentum. Analizaremos cómo detectar y reaccionar ante las desviaciones de los precios respecto a la media (puntuación Z), y cómo medir el impulso en varios pares de divisas para determinar la dirección de la operación.
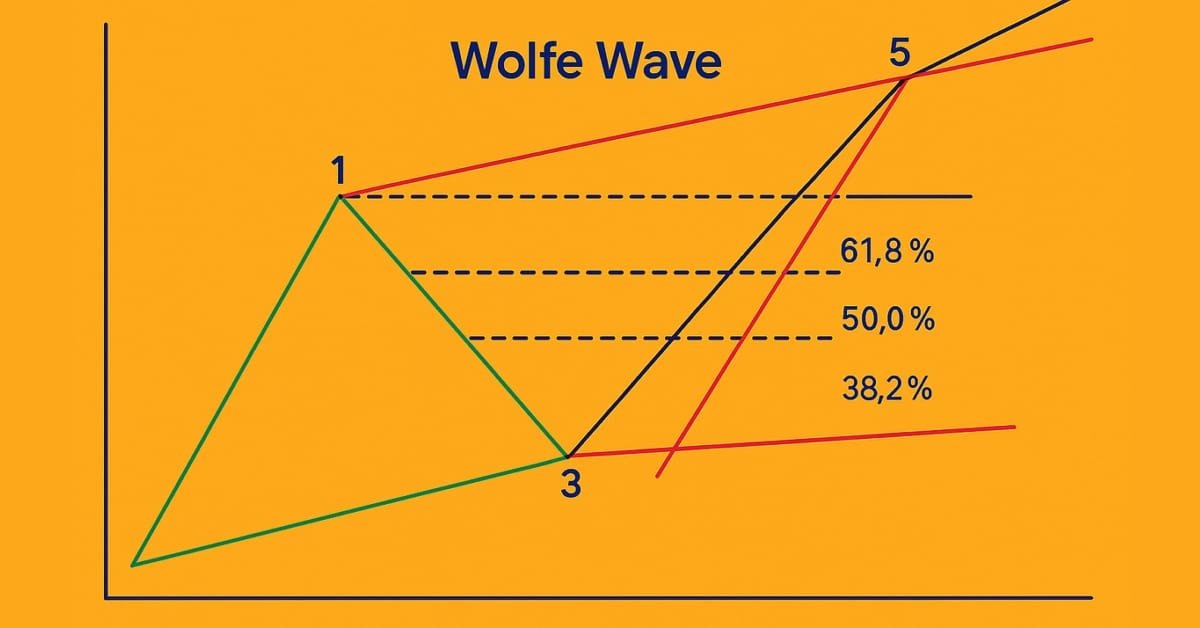
Introducción a MQL5 (Parte 18): Introducción al patrón de onda de Wolfe
En este artículo se explica en detalle el patrón de la onda de Wolfe, abordando tanto la variante bajista como la alcista. Además, desglosa paso a paso la lógica utilizada para identificar configuraciones válidas de compra y venta basadas en este patrón gráfico avanzado.

Redes neuronales en el trading: Previsión probabilística de series temporales (K2VAE)
Le invitamos a explorar la implementación original del framework K²VAE, un modelo flexible capaz de aproximar linealmente dinámicas complejas en el espacio latente. Este artículo le mostraremos cómo implementar componentes clave en MQL5, incluidas las matrices parametrizadas y su gestión fuera de las capas estándar de redes neuronales. Este material resultará útil a quienes busquen un enfoque práctico para crear modelos de series temporales interpretables.

De novato a experto: Noticias animadas utilizando MQL5 (IV) Análisis de mercado sobre modelos de IA alojados localmente
En esta discusión, analizaremos cómo autoalojar modelos de IA de código abierto y utilizarlos para obtener información sobre el mercado. Esto forma parte de nuestro esfuerzo continuo por ampliar el News Headline EA, con la introducción de una franja «AI Insights» que lo convierte en una herramienta de asistencia con múltiples integraciones. La versión mejorada del Asesor Experto (EA) tiene como objetivo mantener informados a los operadores a través de eventos del calendario, noticias financieras de última hora, indicadores técnicos y, ahora, perspectivas de mercado generadas por IA, ofreciendo así un apoyo oportuno, variado e inteligente para la toma de decisiones de trading. Únete a la conversación mientras exploramos estrategias prácticas de integración y cómo MQL5 puede colaborar con recursos externos para crear un terminal de trabajo para trading potente e inteligente.

Redes neuronales en el trading: Segmentación periódica adaptativa (Final)
Le propongo sumergirse en el apasionante mundo de LightGTS, un framework de predicción de series temporales ligero pero potente que combina la convolución adaptativa y la codificación RoPE con métodos de atención innovadores. En el artículo de hoy, encontrará una descripción detallada de todos los componentes, desde la creación de parches hasta una compleja combinación de asesores expertos en un decodificador, listo para su integración en proyectos MQL5. ¡Descubra cómo LightGTS lleva el trading automatizado al siguiente nivel!
Creación de un Panel de administración de operaciones en MQL5 (Parte XII): Integración de una calculadora de valores Forex
El cálculo preciso de los valores clave de las operaciones es una parte indispensable del flujo de trabajo de cualquier operador. En este artículo, analizaremos la integración de una potente herramienta —la calculadora de Forex— en el Panel de gestión de operaciones, lo que amplía aún más la funcionalidad de nuestro sistema «Trading Administrator» de múltiples paneles. A la hora de realizar operaciones, es fundamental determinar de forma eficaz el riesgo, el tamaño de la posición y el beneficio potencial, y esta nueva función está diseñada para que ese proceso sea más rápido e intuitivo dentro del panel. Veamos cómo se aplica MQL5 en la creación de paneles de trading avanzados.

Redes neuronales en el trading: Segmentación periódica adaptativa (Generación de tokens)
Le invitamos a embarcarse en un apasionante viaje por el mundo del análisis adaptativo de series temporales financieras y a aprender cómo transformar el análisis espectral complejo y la convolución flexible en señales de trading reales. Hoy verá cómo LightGTS escucha el ritmo del mercado, adaptándose a sus cambios con un paso de ventana variable, y cómo la aceleración OpenCL convierte la computación en la vía más rápida para tomar decisiones rentables.

Redes neuronales en el trading: Segmentación periódica adaptativa (LightGTS)
Les invitamos a explorar la innovadora técnica de segmentación adaptativa, una forma de segmentar series temporales de forma flexible en función de su periodicidad inherente. Además, se usan técnicas de codificación eficientes que permiten preservar características semánticas importantes al trabajar con datos de diferentes escalas. Estos métodos descubren nuevas posibilidades para procesar con precisión datos complejos a múltiples escalas, típicos de los mercados financieros, y mejoran significativamente la estabilidad y la validez de las previsiones.
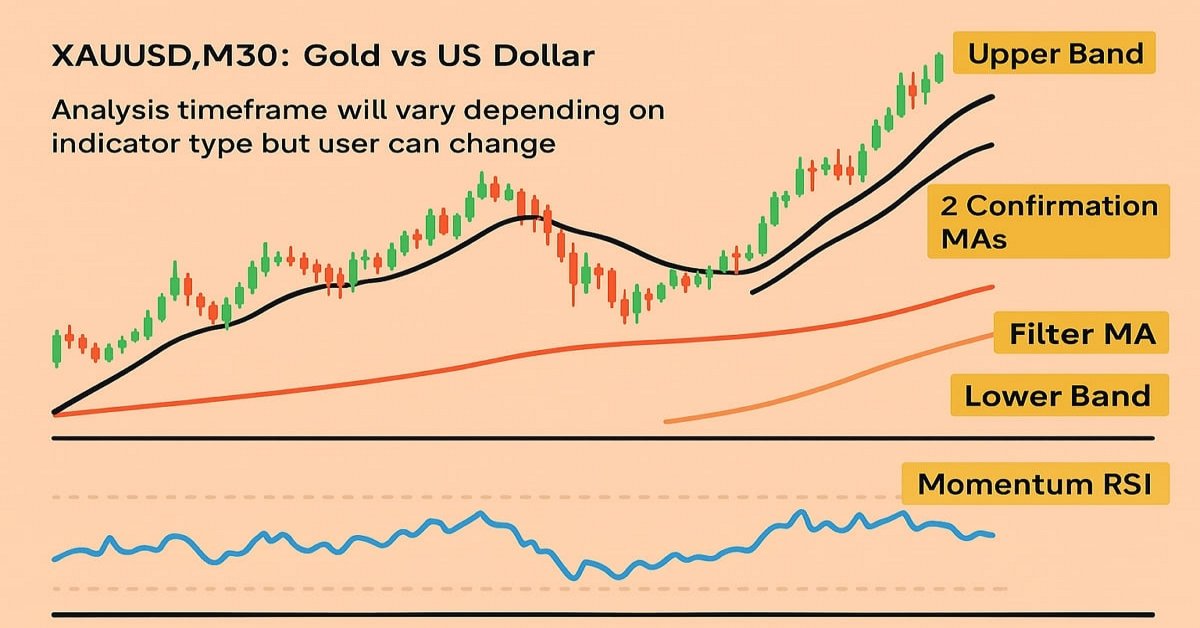
Automatización de estrategias de trading en MQL5 (Parte 18): Estrategia de scalping «Trend Bounce» con envolventes: infraestructura básica y generación de señales (Parte I)
En este artículo, desarrollamos la infraestructura básica del asesor experto «Envelopes Trend Bounce Scalping» en MQL5. Inicializamos las envolventes y otros indicadores para la generación de señales. Preparamos el entorno de backtesting para preparar la ejecución de operaciones en la siguiente parte.
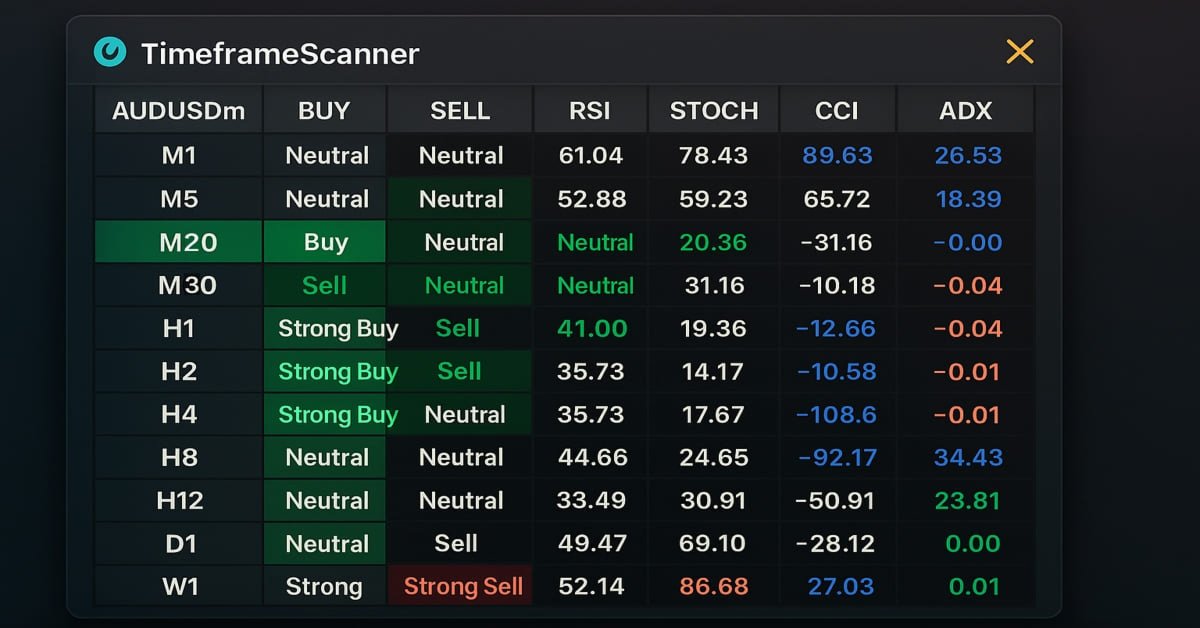
Herramientas de trading de MQL5 (Parte 3): Creación de un panel de control con análisis de múltiples marcos temporales para el trading estratégico
En este artículo, creamos un panel de escáner multitemporal en MQL5 para mostrar señales de trading en tiempo real. Diseñamos una interfaz de cuadrícula interactiva, implementamos el cálculo de señales con múltiples indicadores y añadimos un botón de cierre. El artículo concluye con los beneficios del backtesting y el trading estratégico.
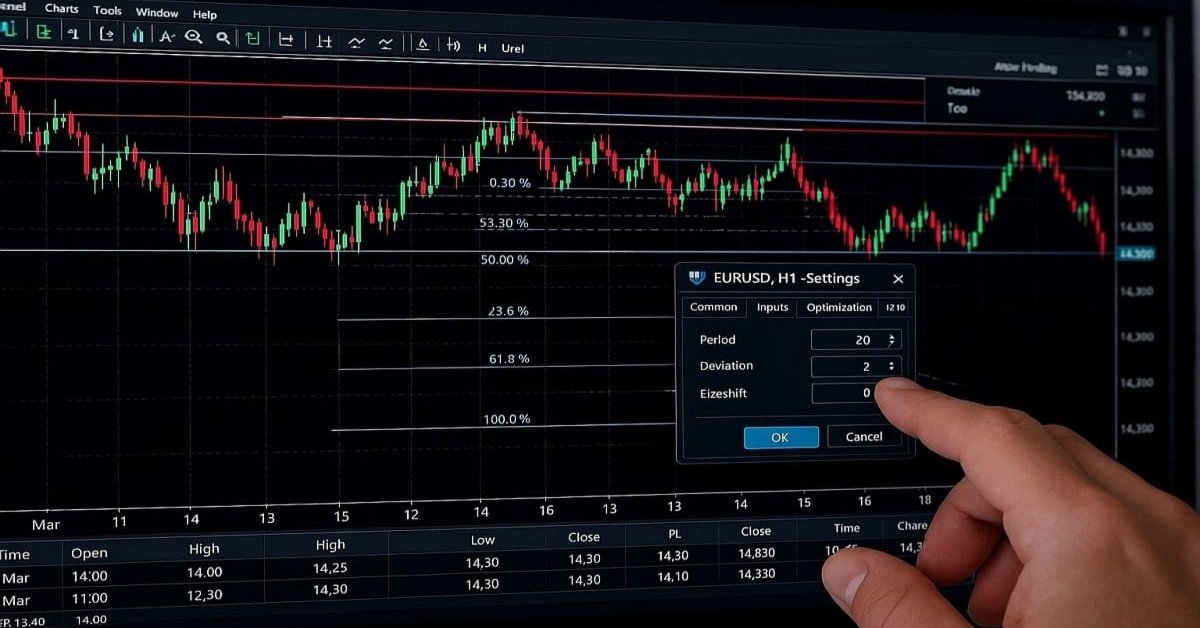
Operando con el Calendario Económico MQL5 (Parte 10): Panel arrastrable y efectos al pasar el cursor para una navegación fluida por las noticias
En este artículo, mejoramos el Calendario Económico de MQL5 mediante la incorporación de un panel de control arrastrable que nos permite reubicar la interfaz para mejorar la visibilidad del gráfico. Implementamos efectos al pasar el cursor por los botones para mejorar la interactividad y garantizar una navegación fluida con una barra de desplazamiento posicionada dinámicamente.

Redes neuronales en el trading: Pipeline inteligente de predicciones (Final)
Este artículo ofrecerá una visión fascinante de cómo la incorporación de SwiGLU revela patrones de mercado ocultos y cómo la escasa combinación de expertos dentro de Decoder-Only Transformer hace que las predicciones sean más precisas a un coste computacional razonable. En este trabajo, analizaremos con detalle la integración de Time-MoE en MQL5 y OpenCL, describiendo la configuración y el entrenamiento del modelo paso a paso.

Redes neuronales en el trading: Pipeline de pronóstico inteligente (Time-MoE)
Le invitamos a familiarizarse con el moderno framework Time-MoE, adaptado para tareas de previsión de series temporales. En este artículo, explicaremos los componentes clave de la arquitectura, ofreciendo explicaciones y ejemplos prácticos. Este enfoque permitirá no solo comprender los principios de funcionamiento del modelo, sino también aplicarlos a tareas de negociación del mundo real.

Redes neuronales en el trading: Pipeline inteligente de previsiones (Mezcla dispersa de expertos)
Hoy le proponemos familiarizarnos con la implementación práctica de un bloque de mezcla dispersa de expertos para series temporales en el entorno de computación OpenCL. Este artículo explica paso a paso el funcionamiento de la convolución multiventana enmascarada, así como la organización del aprendizaje de gradientes en condiciones de múltiples flujos de información.

Operando con el Calendario Económico MQL5 (Parte 9): Mejorando la interacción con noticias mediante una barra dinámica y un diseño pulido
En este artículo, mejoramos el Calendario Económico MQL5 con una barra de desplazamiento dinámica para una navegación intuitiva por las noticias. Garantizamos una visualización impecable de los eventos y unas actualizaciones eficientes. Validamos la barra de desplazamiento adaptable y el panel de control pulido mediante pruebas.