
Aplicación de la teoría de juegos a algoritmos comerciales

En un entorno en el que la rapidez en la toma de decisiones resulta fundamental y el mercado se caracteriza por un alto grado de incertidumbre, se requiere un enfoque diferente para el diseño de sistemas comerciales.
AdaptiveQ Enhanced es un asesor comercial desarrollado sobre la base del aprendizaje profundo por refuerzo (DQN), la teoría de juegos y el análisis causal. El asesor experto analiza el mercado simulando 531.441 estados únicos, considerando las interrelaciones entre los siete principales pares de divisas. El elemento clave del algoritmo es el equilibrio de Nash usado para seleccionar la estrategia óptima bajo la influencia mutua de los instrumentos.
La nueva versión del sistema cuenta con un conjunto ampliado de acciones: además de las operaciones estándar de compra y venta, se han añadido funciones de creación de posiciones y cierre selectivo de transacciones rentables. Esto garantiza la adaptabilidad y flexibilidad en distintos escenarios de mercado. El artículo analiza la aplicación práctica de estos enfoques en MQL5 y demuestra cómo la combinación de aprendizaje adaptativo, teoría de juegos e IA permite construir estrategias comerciales más precisas y sostenibles.
Antecedentes teóricos: del aprendizaje por refuerzo al equilibrio de Nash
Aprendizaje profundo por refuerzo (DQN)
Antes de sumergirnos en los aspectos técnicos del código, debemos sentar una base teórica. Nuestro sistema se basa en Deep Q-Network (DQN), una versión moderna del algoritmo de aprendizaje por refuerzo que ha demostrado su eficacia no solo en juegos, sino también en la resolución de problemas financieros complejos.
En el aprendizaje por refuerzo clásico, el agente (en nuestro caso, el sistema comercial) interactúa con el entorno (el mercado) realizando determinadas acciones (apertura/cierre de posiciones). Por cada acción, el agente recibe una recompensa y pasa a un nuevo estado. El objetivo del agente consiste en maximizar la recompensa agregada a lo largo del tiempo.
Matemáticamente, esto se expresa a través de una función Q que estima la utilidad esperada de la acción a en el estado s:
Q(s, a) = r + γ max Q(s', a')
donde r es la recompensa inmediata, γ es el factor de descuento (cuánto valoramos las recompensas futuras), s' es el nuevo estado y a' son las acciones posibles en el nuevo estado.
Teoría de juegos y equilibrio de Nash
Los sistemas comerciales tradicionales analizan cada instrumento de forma aislada. Nuestro enfoque es fundamentalmente distinto: nosotros aplicamos la teoría de juegos para explicar las interrelaciones entre pares de divisas.
El equilibrio de Nash es un estado en el que ningún jugador puede mejorar su resultado cambiando unilateralmente su estrategia. En el contexto de nuestro sistema, esto implica que encontramos la estrategia óptima para cada par de divisas, considerando las estrategias de todos los demás pares.
Esto se implementa en el código a través de la función DetermineActionNash(), que ahora trabaja con un espacio ampliado de seis acciones posibles. Cada acción se evalúa no solo según los datos de un par de divisas concreto, sino también considerando las correlaciones con otros instrumentos:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Получаем базовые оценки действий из Q-матрицы for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Корректировка на основе корреляции с другими символами (Нэш) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Учитываем корреляцию только если есть значимая связь if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
Preste atención al ajuste fino: la correlación solo se tiene en cuenta si su valor absoluto es superior a 0,3. Esto le permite filtrar el "ruido" y centrarse en las relaciones realmente significativas entre pares de divisas.
Inferencia causal en un espacio de acción multidimensional
En AdaptiveQ Enhanced, nuestro sistema ha recibido un arsenal ampliado de posibles acciones:
- Abrir una posición de compra
- Apertura de posición de venta
- Añadir volumen a las posiciones de compra existentes
- Añadir volumen a las posiciones de venta existentes
- Cerrar solo las posiciones de compra rentables
- Cerrar solo las posiciones de venta rentables
Y esto enriquece considerablemente el potencial estratégico del sistema. Ahora no solo podemos abrir y cerrar posiciones, sino también aumentar los volúmenes cuando la tendencia se desarrolla en la dirección correcta, además de fijar beneficios de forma selectiva, dejando abiertas las posiciones no rentables en previsión de una inversión del mercado.
Resulta especialmente interesante la implementación del cierre solo de posiciones rentables, pues este mecanismo permite al sistema fijar beneficios sin realizar pérdidas, lo que mejora significativamente la rentabilidad global:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Закрываем только если позиция в прибыли if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
Implementación técnica: la anatomía de AdaptiveQ Enhanced
Enorme espacio de estados y análisis multinivel
Una de las principales características de nuestro sistema es su enorme espacio de estados (nada menos que 531.441 estados únicos). Esto hace posible un análisis detallado de las condiciones del mercado y permite al sistema adaptarse a una amplia gama de escenarios.
En la versión actualizada, cada Estado resulta aún más informativo. Ahora el sistema analiza el mercado no solo en el marco temporal actual, sino simultáneamente en tres marcos temporales distintos: M15, H1 y H4. Este enfoque de marco temporal múltiple permite a AdaptiveQ Enhanced obtener una visión completa de la dinámica del mercado, desde las fluctuaciones a corto plazo hasta las tendencias a medio plazo.
Para cada marco temporal, el sistema monitorea toda una serie de parámetros:
- La diferencia entre el precio y 20 medias móviles (MA10 a MA200)
- Las banderas binarias sobre la posición del precio en relación con los niveles clave de la MA
- Los valores de los indicadores técnicos RSI y Stochastic
- El impulso (momentum) del movimiento de los precios
Todos estos datos se convierten en un índice de estado único, que luego se usa para referirse a la matriz Q:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Базовые компоненты из цен int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Базовый индекс из основных компонентов int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Добавляем компоненты из разницы с MA для текущего таймфрейма int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Добавляем компоненты из индикаторов для каждого таймфрейма ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Бинарные флаги для MA: выбираем ключевые МА (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Хэшируем вместе базовый индекс и индикаторы ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Приводим к диапазону TOTAL_STATES через хэш return (int)(hash % TOTAL_STATES); }
Eche un vistazo a esta función. Aquí se produce una transformación sorprendente: el espacio multidimensional de los parámetros del mercado se convierte en un identificador de estado único. Es como si creáramos un mapa multidimensional del mercado en el que cada punto se corresponde con una combinación concreta de precios e indicadores y, a continuación, lo convirtiéramos en un índice unidimensional usando una función hash.
Almacenamiento en la caché y optimización del rendimiento
Dada la complejidad computacional del sistema, hemos prestado especial atención a la optimización. La nueva versión añade el almacenamiento en la caché no solo de los precios y las correlaciones, sino también de los valores de todos los indicadores utilizados:
// Кэш для цен и корреляций (оптимизация быстродействия) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Кэш для Point // Кэш для индикаторов double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Además, ahora el sistema guarda los manejadores de los indicadores entre llamadas, lo cual evita crearlos varias veces:
// Хендлы для индикаторов, чтобы избежать многократного создания int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Y para ahorrar recursos informáticos, hemos añadido un mecanismo de actualización periódica de los indicadores:
// Время последнего обновления индикаторов datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Обновлять индикаторы каждую минуту void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... код обновления индикаторов ... lastIndicatorsUpdate = currentTime; }
Esta técnica puede parecer trivial, pero en la práctica ofrece un aumento significativo del rendimiento, lo que resulta fundamental para un sistema que trabaja simultáneamente con siete pares de divisas en tres marcos temporales.
Aprendizaje adaptativo con un mecanismo de coste de oportunidad
El corazón de nuestro sistema es el mecanismo de aprendizaje adaptativo, que ahora es todavía más avanzado. A diferencia del Q-learning clásico, el AdaptiveQ Enhanced utiliza el concepto de coste de oportunidad (opportunity cost), que permite al sistema aprender más rápido de sus errores.
Cuando el sistema toma una decisión, no solo evalúa la recompensa real de la acción seleccionada, sino que también simula el resultado potencial de acciones alternativas. Si resulta que una acción distinta podría haber reportado mayores beneficios, el sistema ajustará su estrategia de forma más agresiva:// Проверяем, привело ли действие к убытку и можно ли было получить прибыль с альтернативным действием bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Применяем адаптивную скорость обучения для случаев упущенной выгоды if(wasLoss && couldProfit) { // Увеличиваем скорость обучения для быстрой адаптации к неправильным решениям double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Дополнительно уменьшаем Q-значение пропорционально упущенной выгоде newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
Esto resulta similar a cómo un tráder experimentado no solo aprende de sus errores, sino que también analiza las oportunidades perdidas, ajustando su estrategia de forma más agresiva cuando ve que una solución alternativa habría sido mucho mejor. Con el parámetro adaptiveMultiplier, el usuario puede configurar la intensidad con la que el sistema aprende de las oportunidades perdidas.
Otro aspecto innovador del aprendizaje es la influencia causal entre pares de divisas:
// Обновляем Q-значения для других символов на основе корреляции (каузальное обучение) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Применяем обновление только если корреляция значима if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
Cuando el sistema adquiere experiencia en un par de divisas, puede transferirla a otros instrumentos relacionados, considerando el grado de correlación entre ellos. Se crea así un efecto de "aprendizaje cruzado" que acelera sustancialmente el proceso de adaptación del sistema a las condiciones del mercado.
Aspectos prácticos del uso de AdaptiveQ Enhanced
Capacidades avanzadas de personalización y gestión de riesgos
AdaptiveQ Enhanced ofrece una impresionante gama de parámetros para configurar el sistema a las preferencias de cada tráder:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // Режим работы системы input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Стратегия закрытия input POSITION_MODE PositionMode = MODE_MULTI; // Режим позиций input double TradeVolume = 0.01; // Базовый объем сделки input double AddVolumePercent = 50.0; // Процент от базового объема для добавления к позиции input int TakeProfit = 2500; // Take Profit (пункты) input int StopLoss = 1500; // Stop Loss (пункты) input double LearningRate = 0.1; // Скорость обучения input double DiscountFactor = 0.9; // Фактор дисконтирования input double AdaptiveMultiplier = 1.5; // Множитель адаптивной скорости обучения input double OpportunityCostWeight = 0.2; // Вес упущенной выгоды input int MaxPositionsPerSymbol = 5; // Максимальное количество позиций на один символ
El sistema puede funcionar en tres modos de posiciones: MODE_SINGLE permite solo una posición por símbolo, MODE_MULTI permite hasta MaxPositionsPerSymbol posiciones unidireccionales, y MODE_OPPOSITE permite tener posiciones simultáneas en direcciones opuestas.
Especial atención merece el parámetro AddVolumePercent, que define cuánto volumen se añadirá a la posición existente durante las acciones ACTION_ADD_BUY y ACTION_ADD_SELL. Esto ofrece la oportunidad de aplicar una estrategia de creación de posiciones en la que el sistema añade volumen en la dirección de una tendencia acertada.
Gestión inteligente de posiciones
La posibilidad de cerrar selectivamente solo las posiciones rentables es una de las innovaciones más interesantes de AdaptiveQ Enhanced. Esto permite al sistema fijar los beneficios y dar a las posiciones perdedoras la oportunidad de recuperarse:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Закрываем только прибыльные позиции BUY ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
Combinado con la capacidad de abrir múltiples posiciones, esto crea una dinámica interesante: el sistema puede acumular posiciones gradualmente cuando se desarrolla una tendencia y, a continuación, fijar parcialmente los beneficios a los primeros signos de retroceso, manteniendo algunas posiciones para una posible continuación del movimiento.
Guardado periódico y carga del modelo entrenado
Lo más destacado de nuestro sistema sigue siendo su capacidad de almacenar y cargar una matriz Q entrenada. En la nueva versión, este mecanismo resulta aún más robusto, gracias al guardado automático periódico:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Периодическое сохранение Q-матрицы..."); SaveQMatrix(); } }
El sistema comprueba la aparición de una nueva barra y guarda periódicamente los conocimientos acumulados, lo cual protege contra la pérdida de datos de entrenamiento en caso de finalización inesperada.
Así funciona todo el sistema:
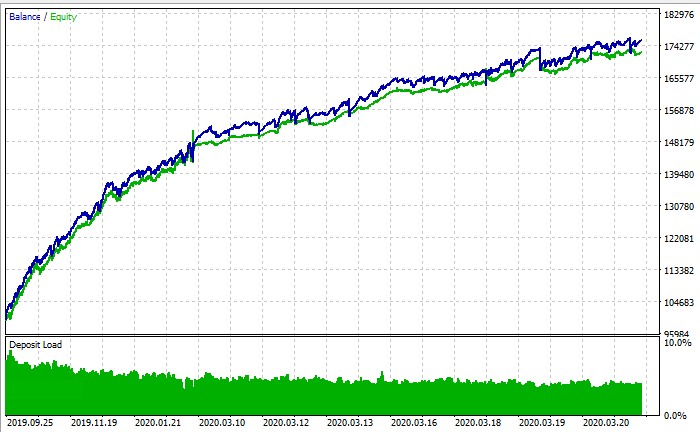
Conclusión: nuevos horizontes para el trading algorítmico
El asesor experto AdaptiveQ Enhanced no es una herramienta más para el trading algorítmico, sino un enfoque fundamentalmente nuevo del análisis y la previsión de los mercados financieros. Combinando el aprendizaje profundo por refuerzo, la teoría de juegos y la inferencia causal con un avanzado arsenal de acciones comerciales y análisis de múltiples marcos temporales, hemos creado un sistema capaz de captar las complejas relaciones entre distintos pares de divisas y tomar decisiones comerciales óptimas.
El mecanismo de la tasa de aprendizaje adaptativa ha demostrado ser especialmente eficaz a la hora de contabilizar la pérdida de beneficios. Cuando el sistema toma una decisión equivocada y una acción alternativa podría haber resultado rentable, aumenta la tasa de aprendizaje según el AdaptiveMultiplier (1,5 veces por defecto). Se trata de una especie de "lección con mayor intensidad": el sistema aprende más rápido de sus errores que de sus aciertos, lo cual también concuerda con la psicología humana.
El futuro del trading algorítmico reside precisamente en el ámbito de los sistemas adaptativos que pueden aprender y evolucionar con el mercado. Y AdaptiveQ Enhanced no es solo un experimento, sino una herramienta de trabajo que abre nuevos horizontes a la investigación y el desarrollo. El código presentado en este artículo está disponible para su experimentación y mejora por parte de los usuarios. Invito a la comunidad MQL5 a participar en el desarrollo de este concepto y en la creación de sistemas comerciales aún mejores basados en la inteligencia artificial y la teoría de juegos.
El mundo de las finanzas es cada vez más complejo e interconectado, y solo los sistemas capaces de absorber y adaptarse a esta complejidad podrán competir con éxito en los mercados del futuro. AdaptiveQ Enhanced supone un paso en esa dirección, un paso hacia un trading algorítmico más inteligente, más adaptable y, en última instancia, más rentable.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17546
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Saludos, estoy muy interesado en su proyecto, pero soy nuevo en este campo. No puedo entender cómo ejecutar el Asesor Experto en el probador de estrategias. Según tengo entendido es imposible configurarlo completamente y entrenarlo a través del tester? ¿O estoy haciendo algo mal? Agradecería el SO
¿Dónde tengo parientes en los Países Bajos? 👀
Cómo es que tengo parientes en Holanda 👀.
Ahahahahah, no en los Países Bajos)))) VPN es una cosa)))))
PS: línea de fondo en el probador de estrategia es posible ejecutar la formación o no? Según la captura de pantalla del gráfico de balance es un probador de estrategias, pero haga lo que haga ni me acerco al + en él
El autor presenta "AdaptiveQ Enhanced", un EA de FX multisímbolo que afirma combinar DQN, equilibrio de Nash, análisis causal, siete pares de divisas principales, seis acciones y 531.441 estados. El conjunto de acciones incluye comprar, vender, añadir a la compra, añadir a la venta y cerrar sólo las compras o ventas rentables.
Mi principal problema: el artículo utiliza más etiquetas rimbombantes que sustancia real. Su "equilibrio de Nash" no es una solución de equilibrio real; se trata simplemente de tomar las puntuaciones Q de un símbolo y mezclarlas con las puntuaciones Q de otros símbolos ponderadas por la correlación rodante cuando |corr| > 0,3 . Eso no es teoría de juegos en ningún sentido serio. El mismo problema existe con el lenguaje "causal": la actualización cruzada de símbolos se basa literalmente en la recompensa por correlación cuando |corr| > 0,2 . La correlación no es causalidad.
El diseño del estado también parece inestable. El artículo dice que construye un rico estado multi-marco de tiempo de los precios, las diferencias de MA, RSI, estocástico, y las banderas de MA, a continuación, hash que la información multidimensional y lo reduce con hash % TOTAL_STATES . Así que diferentes situaciones de mercado pueden colapsar en el mismo cubo. Llamar a eso "531.441 estados únicos" suena más impresionante de lo que realmente es.
La lógica de posición es la parte más fea. El EA puede funcionar en modo multiposición o posición opuesta, añadir volumen a las posiciones existentes, permitir hasta 5 posiciones por símbolo, y cerrar selectivamente sólo las posiciones rentables dejando abiertas las perdedoras "para recuperar". Para mí, eso no es gestión inteligente de inventarios; es un camino disfrazado hacia una exposición fea.
Lo que es bueno: el lado de la ingeniería es más serio que el promedio MQL5 pelusa. Almacenamiento en caché indicador maneja, actualizaciones periódicas, y guardar / cargar la matriz Q son detalles prácticos de implementación.
Así que en mi opinión un experimento interesante y débil diseño comercial. Demasiado branding alrededor de "AI / teoría del juego / inferencia causal", no hay suficientes pruebas de que tiene una ventaja real. Yo no me basaría directamente en esta lógica.