
Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)

Introducción
El transformador de decisiones y todas sus modificaciones que hemos conocido en artículos recientes pertenecen a los métodos de Clonación Conductual (Behavioral Сloning — BC). Es decir, entrenamos a los modelos para que repitan acciones a partir de trayectorias "expertas" según el entorno y los objetivos. Así, enseñamos al modelo a imitar el comportamiento del experto en el estado actual del entorno para alcanzar el objetivo marcado.
No obstante, en condiciones reales, las evaluaciones de distintos expertos sobre la misma condición del entorno divergen bastante. Y a veces suponen todo lo contrario. Además, no debemos olvidar que en los artículos anteriores no hemos contado con expertos para crear nuestra muestra de entrenamiento. Hemos usado diferentes métodos para muestrear las acciones del Agente y seleccionado las mejores trayectorias, que no siempre resultaban óptimas.
Aquí debemos reconocer que en el proceso de muestreo de trayectorias en un espacio continuo de acciones y episodios, resulta casi imposible preservar todas las variantes posibles. Y solo una pequeña fracción de las trayectorias muestreadas puede cumplir, al menos parcialmente, nuestros requisitos. Dichas trayectorias son más bien valores atípicos que el modelo puede descartar durante el entrenamiento.
Para salir de esta situación, hemos usado el método Go-Explore, y secuencialmente hemos compuesto una trayectoria exitosa a partir de pequeñas piezas. Estas trayectorias pueden denominarse subóptimas: se acercan a nuestras expectativas, pero su optimalidad sigue sin demostrarse.
Y, obviamente, podemos marcar "a mano" la trayectoria óptima sobre datos históricos. Este enfoque nos acercará al aprendizaje supervisado, con todos sus pros y sus contras.
Al mismo tiempo, la selección de pasadas óptimas pondrá al modelo en condiciones ideales, lo cual puede provocar un sobreentrenamiento del modelo, cuando el modelo, tras aprender el recorrido de la muestra de entrenamiento, no sea capaz de generalizar la experiencia a nuevos estados del entorno.
El segundo problema de los métodos de clonación conductual es el establecimiento de objetivos para el modelo (Return To Go). Ya hemos abordado esta cuestión en artículos anteriores. Algunos trabajos recomiendan usar el coeficiente hasta el máximo resultado de la muestra de entrenamiento, que a menudo ofrece mejores resultados. Pero este enfoque solo resulta aplicable a problemas estáticos, y el coeficiente se seleccionará para cada tarea por separado. El método de Dichotomy of Control nos ofrece otra opción para resolver este problema. También existen otros enfoques.
Los autores del artículo «Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning» investigan el problema enunciado más arriba. Y para su solución ofrecen un método bastante interesante: ConserWeightive Behavioral Cloning (CWBC), que es aplicable no solo a los modelos de la familia Decision Transformer.
1. Algoritmo
Para identificar los factores que influyen en la fiabilidad de los métodos de aprendizaje por refuerzo dependientes de recompensas objetivo, los autores del artículo «Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning» realizaron dos experimentos ilustrativos.
En el primer experimento, se ejecutaron modelos de diferentes arquitecturas en conjuntos de trayectorias de diferentes niveles de rendimiento, que iban de casi aleatorio a experto y subóptimo. Los resultados del experimento demostraron que la fiabilidad del modelo depende en gran parte de la calidad de los datos de la muestra de entrenamiento. Al entrenar los modelos con datos de trayectorias de rentabilidad medias y expertas, el modelo funciona de forma fiable en condiciones de objetivos elevados. Al mismo tiempo, cuando el modelo se entrena con trayectorias de resultados bajos, su rendimiento disminuye rápidamente a partir de cierto momento de aumento de RTG. Esto se debe a que los datos de baja calidad no ofrecen suficiente información para entrenar la política condicionada a grandes recompensas. Y esto influye negativamente en la fiabilidad del modelo resultante.
La calidad de los datos no es la única razón de la fiabilidad del modelo. La arquitectura del modelo también desempeña un papel esencial. En los experimentos realizados, el DT muestra fiabilidad en los tres conjuntos de datos. Se supone que la fiabilidad DT se consigue usando la arquitectura del Transformer. Como la política de predicción de la siguiente acción del Agente se basa en una secuencia de estados del entorno y etiquetas RTG, las capas de atención pueden ignorar las etiquetas RTG fuera de la distribución de la muestra de entrenamiento. Así se consigue una buena precisión de predicción. Al mismo tiempo, los modelos basados en la arquitectura MLP, que obtienen el estado actual y el rendimiento objetivo como entradas para generar acciones, no pueden ignorar la información sobre la recompensa deseada. Para probar esta hipótesis, los autores experimentan con una versión ligeramente modificada del DT, que concatena los vectores de estado del entorno y RTG en cada paso temporal. Por tanto, el modelo no puede ignorar la información del RTG en la secuencia. Los resultados experimentales demuestran una rápida disminución de la fiabilidad de dicho modelo una vez que el RTG queda fuera de la distribución de la muestra de entrenamiento, lo cual confirma la suposición anterior.
Para optimizar el proceso de entrenamiento del modelo y minimizar el impacto de los factores mencionados arriba, los autores del artículo proponen utilizar el marco de Clonación Conductual ConserWeightive (CWBC), que es una forma bastante sencilla y eficaz de mejorar la solidez de los métodos existentes de entrenamiento de modelos de clonación conductual. El CWBC consta de dos componentes:
- La ponderación de la trayectoria.
- La regularización RTG conservadora
La ponderación de trayectorias ofrece una forma sistemática de transformar la distribución subóptima de datos para estimar mejor la distribución óptima aumentando el peso de las trayectorias de alto rendimiento, mientras que el regularizador de pérdidas conservador anima a las políticas a mantenerse cerca de la distribución de datos original sujeta a grandes objetivos.
1.1 Ponderación de las trayectorias
Sabemos que la distribución offline óptima de trayectorias es simplemente la distribución de demostraciones generada por la política óptima. Normalmente, la distribución offline de las trayectorias estará desplazada con respecto a la distribución óptima. Durante el entrenamiento, esto provocará una desconexión entre el entrenamiento y la prueba, ya que queremos condicionar nuestro Agente para maximizar los rendimientos durante la estimación y la explotación del modelo, pero tenemos que minimizar el riesgo empírico en la distribución desplazada de los datos durante el entrenamiento.
La idea básica del método consiste en transformar la muestra de trayectorias de entrenamiento en una nueva distribución que estime mejor la trayectoria óptima. La nueva distribución debería centrarse en las trayectorias de rentabilidad alta, lo que intuitivamente mitigaría la brecha entre el entrenamiento y las pruebas. Y como esperamos que el conjunto de datos original contenga muy pocas trayectorias de alta rentabilidad, la simple eliminación de las trayectorias de baja rentabilidad eliminará la mayor parte de los datos de entrenamiento. Esto provocará una disminución de la capacidad de generalización del modelo entrenado. Y los autores del método sugieren ponderar las trayectorias según su rentabilidad.
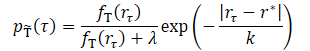
donde λ, k son dos hiperparámetros que determinan la forma de la distribución transformada.
El parámetro de suavizado k controlará la ponderación de las trayectorias en función de su rendimiento. Intuitivamente, un k más pequeño dará más peso a las trayectorias con mayor puntuación, y, a medida que aumente el valor del parámetro, la distribución transformada se volverá más uniforme. Los autores proponen fijar el valor de k como la diferencia entre el valor máximo y el percentil z de los resultados de la muestra de entrenamiento.
![]()
Esto permite adaptar el valor real de k a distintos conjuntos de datos. Los autores del método probaron cuatro valores de z del conjunto {99, 90, 50, 0} que se corresponden con cuatro valores crecientes de k. Según los resultados experimentales de cada conjunto de datos, la distribución transformada usando un k pequeño estará muy concentrada en las recompensas altas. A medida que aumente k, aumentará la densidad de las trayectorias de baja recompensa y la distribución se volverá más uniforme. Con valores relativamente pequeños de k basados en el percentil del conjunto {99, 90, 50}, el modelo mostrará un buen rendimiento en todos los conjuntos de datos. Sin embargo, los valores grandes de k basados en el percentil 0 degradarán el rendimiento para el conjunto de datos con trayectorias expertas.
El parámetro λ también influirá en la distribución transformada. Cuando λ = 0, la distribución transformada se concentrará en las recompensas altas. A medida que λ aumente, la distribución transformada tenderá hacia la distribución original, pero seguirá estando ponderada hacia la región de alta recompensa debido a la influencia del miembro exponencial. El rendimiento real de los modelos con distintos valores de λ mostrará resultados similares que son mejores o comparables al entrenamiento con el conjunto de datos original.
1.2 Regularización conservadora
Como ya hemos mencionado, la arquitectura también desempeña un papel importante en la robustez del modelo entrenado. Un escenario perfecto resulta difícil y a veces incluso imposible de realizar. Pero los autores del método CWBC pretenden obtener una política cercana a la distribución original de los datos para evitar la pérdida catastrófica de especificar RTG fuera de la distribución. En otras palabras, la política debe ser conservadora. No obstante, el conservadurismo no tiene por qué proceder necesariamente de la arquitectura, sino que también puede surgir de una función de pérdida de aprendizaje del modelo correcta, como suele hacerse en los métodos conservadores basados en la estimación de costes de estado y transición.
Los autores del método proponen un nuevo regularizador conservador para los métodos de clonación conductual dependientes de RTG, que animará explícitamente a la política a mantenerse cerca de la distribución original de los datos. La idea es garantizar que se pronostiquen acciones cercanas a la distribución original incluso al especificar grandes valores de RTG fuera de la distribución de la muestra de entrenamiento. Esto se consigue añadiendo ruido positivo al RTG para las trayectorias con alta recompensa real y penalizando la distancia L2 entre la acción predicha y la real partiendo de la muestra de entrenamiento. Para garantizar la generación de grandes valores de RTG fuera de la distribución, generaremos ruido de forma que el valor de RTG corregido resulte al menos tan alto como la mayor recompensa de la muestra de entrenamiento.
Así, le proponemos aplicar una regularización conservadora a las trayectorias cuyos rendimientos superen el q-ésimo percentil de las recompensas en la muestra de entrenamiento. Esto garantizará que cuando el RTG se especifique fuera de la distribución de aprendizaje, la política se comporte de forma similar a las trayectorias de alta recompensa en lugar de una trayectoria aleatoria. Añadiremos ruido y desplazaremos el RTG en cada paso temporal.
Los experimentos realizados por los autores del método demuestran que el uso del percentil 95 suele funcionar bien en diversos entornos y conjuntos de datos.
Los autores del método señalan que el regularizador conservador propuesto se distingue de otros componentes conservadores para los métodos RL offline basados en la estimación de costes de estado y transición; mientras que estos últimos suelen intentar ajustar la estimación de la función de coste para evitar el error de extrapolación, el método propuesto distorsiona las recompensas objetivo para crear condiciones fuera de la distribución y regular la predicción de acciones.
Cuando la ponderación de la trayectoria se usa junto con un regularizador conservador, obtenemos la Clonación Conductual ConserWeightive (CWBC), que combina lo mejor de ambos componentes.
2. Implementación de MQL5
Tras repasar los aspectos teóricos del método de Clonación Conductual ConserWeightive, vamos a poner en práctica nuestra interpretación de los planteamientos propuestos. En este artículo, entrenaremos 2 modelos:
- Un Agente (Decision Transformer) para predecir acciones.
- Un modelo para estimar el valor de las condiciones del entorno actuales para la generación de RTG.
En este caso, además, añadiremos una ponderación de la trayectoria y una regularización conservadora para optimizar el proceso de aprendizaje. Los autores del método CWBC afirman que los algoritmos propuestos pueden mejorar la eficacia del entrenamiento del DT en un 8% de media.
Debemos señalar de entrada que el proceso de entrenamiento del modelo es independiente. Y existe la posibilidad de organizar su entrenamiento paralelo, que es lo que vamos a hacer. Pero antes, describiremos la arquitectura de los modelos. Y aquí dividiremos el proceso de descripción de la arquitectura en dos métodos separados. En el método CreateDescriptions crearemos una descripción de la arquitectura del Agente, que recibirá como entrada un paso de la secuencia analizada que constará de 5 entidades:
- los datos históricos de los movimientos de precio y los indicadores analizados;
- el estado de la cuenta y las posiciones abiertas;
- la marca temporal;
- la última acción del agente;
- el RTG.
Esto es lo que reflejaremos en la capa de datos de entrada del modelo.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Como es habitual, los datos obtenidos se preprocesarán en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
A continuación, convertiremos todas las entidades a una forma comparable. Para ello, primero utilizaremos una capa de incorporación que reúna todos los datos en un único espacio de N dimensiones. Aquí me gustaría recordar que la capa de incorporación que hemos creado contiene en la memoria los datos obtenidos previamente para la profundidad de la historia analizada. Los nuevos datos se añadirán a la secuencia recopilada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Y después, con una capa SoftMax, llevaremos todas las incorporaciones a una distribución comparable. Tenga en cuenta que SoftMax se aplicará en cada incorporación.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Después de poner todas las incorporaciones en una forma comparable, usaremos un bloque de atención que analizará la secuencia resultante.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
A esto le seguirá un bloque de 2 capas de convolución que buscará patrones estables en los datos y reducirá simultáneamente la dimensionalidad de los datos en un factor de 2.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Tenga en cuenta que hasta ahora hemos realizado el procesamiento de datos dentro de una única incorporación. Y finalizaremos este paso haciendo que todas las entidades sean comparables usando la función SoftMax, que también aplicaremos a cada entidad de la secuencia por separado.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Los datos, así procesados y totalmente comparables, pasarán a una unidad de decisión formada por capas totalmente conectadas, con la generación de acciones predictivas del Agente como salida.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
A continuación, crearemos una descripción de la arquitectura del modelo de estimación de costes del estado del entorno en el método CreateRTGDescriptions. Este modelo recibirá en la entrada una secuencia de datos históricos de variaciones de precios e indicadores analizados. Cabe señalar que en este caso se trata de una secuencia de varias barras.
bool CreateRTGDescriptions(CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- RTG rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Los datos resultantes también se someterán a un procesamiento inicial en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
A continuación, crearemos una incorporación de cada barra usando la capa de convolución y la función SoftMax. En este caso, no utilizaremos la capa de incorporación porque la estructura de datos de cada barra es la misma y no necesitaremos realizar la acumulación de los datos recibidos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count + BarDescr - 1) / BarDescr; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Los datos procesados se transferirán a la unidad de atención.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
A continuación, los datos se introducirán en el bloque de la capa de convolución y la posterior normalización SoftMax, de forma similar al modelo comentado anteriormente.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Después crearemos un bloque de decisión a partir de las capas totalmente conectadas.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
En la salida del modelo, implementaremos la estocasticidad de la política de generación de RTG utilizando un bloque de autocodificador variacional. De esta forma, imitaremos la estocasticidad del entorno y los costes de las posibles transiciones dentro de la distribución aprendida.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Tras crear una descripción de la arquitectura del modelo, pasaremos a trabajar en los asesores de entrenamiento del modelo. Para la recogida inicial de la muestra de entrenamiento, seleccionaremos las mejores trayectorias aleatorias muestreadas con el asesor "...{CWBC\Faza1.mq5". El algoritmo de este asesor y los principios de recopilación de datos se describen en el artículo dedicado al Control Transformer.
A continuación, crearemos un asesor para entrenar a nuestro Agente "...\CWBC\StudyAgent.mq5". Debemos decir que este asesor ha heredado en gran medida la estructura del asesor de entrenamiento original del Decision Transformer. Sin embargo, lo complementaremos con los planteamientos del método CWBC. Primero crearemos un método de ponderación de trayectorias GetProbTrajectories, que nos devolverá un vector con las sumas acumulativas de las probabilidades para el muestreo de trayectorias. E inmediatamente en el cuerpo del método, determinaremos la recompensa máxima en el búfer de reproducción de experiencias, el nivel de cuantiles requerido y el vector de desviaciones estándar de las recompensas. Necesitaremos estos datos para realizar posteriormente la regularización conservadora.
En los parámetros del método, transmitiremos el búfer de reproducción de experiencias y las variables necesarias.
vector<float> GetProbTrajectories(STrajectory &buffer[], float &max_reward, float &quantile, vector<float> &std, double quant, float lanbda) { ulong total = buffer.Size();
En el cuerpo del método, determinaremos inmediatamente el número de trayectorias en el búfer de reproducción y preparamos una matriz para recoger las recompensas en las pasadas.
matrix<float> rewards = matrix<float>::Zeros(total, NRewards); vector<float> result;
Recordemos aquí que cuando guardamos una trayectoria en el búfer de reproducción, recalcularemos la recompensa acumulada hasta el final de la pasada. Por lo tanto, la recompensa total de toda la pasada se almacenará en el elemento con el índice 0. Luego organizaremos un ciclo y copiaremos la recompensa total de cada pasada en una matriz que hemos preparado.
for(ulong i = 0; i < total; i++) { result.Assign(buffer[i].States[0].rewards); rewards.Row(result, i); }
Realizando operaciones matriciales, obtendremos la desviación típica de cada elemento del vector de recompensa.
std = rewards.Std(0);
Vector de recompensas totales de cada pasada y valor de la recompensa máxima.
result = rewards.Sum(1);
max_reward = result.Max();
Tenga en cuenta que hemos utilizado una simple suma del vector de recompensas en cada pasada. No obstante, es posible que se produzcan variaciones en el valor medio de las recompensas descompuestas, así como de las opciones ponderadas de la suma o la media. El uso del enfoque depende de la tarea específica que estemos realizando.
A continuación, tendremos que determinar el nivel de cuantiles necesario. La documentación de MQL5 sobre la operación vectorial Quantile indica que se requiere un vector secuencial ordenado para su correcto cálculo. Así, crearemos una copia del vector de recompensas totales y lo clasificaremos en orden ascendente.
vector<float> sorted = result; bool sort = true; int iter = 0; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { float temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } iter++; } quantile = sorted.Quantile(quant);
A continuación, llamaremos a la función vectorial Quantile y guardaremos el resultado.
Una vez recogidos los datos necesarios para las operaciones posteriores, pasaremos directamente a determinar los pesos de cada trayectoria. Y aquí deberemos darnos cuenta de que para unificar el uso del coeficiente λ necesitaremos un algoritmo que lleve todas las muestras posibles de recompensas a la misma distribución. Para ello, normalizaremos todas las recompensas en el intervalo (0, 1].
Nótese que no incluimos "0" en el rango de valores normalizados, ya que cada trayectoria deberá tener una probabilidad distinta de "0". Por lo tanto, reduciremos el valor mínimo del rango de recompensa en un 10% de la recompensa mediana.
El uso máximo de los valores relativos permitirá unificar realmente nuestro cálculo.
float min = result.Min() - 0.1f * std.Sum();
Sin embargo, seguirá habiendo una pequeña probabilidad de obtener valores de recompensa idénticos en todas las pasadas. Las razones pueden ser diversas. No obstante, a pesar de la escasa probabilidad de que esto suceda, crearemos un control. En la rama principal de nuestro algoritmo, primero calcularemos el componente exponencial. Y luego normalizaremos las recompensas y recalcularemos los pesos de las trayectorias.
if(max_reward > min) { vector<float> multipl=exp(MathAbs(result - max_reward) / (result.Percentile(90)-max_reward)); result = (result - min) / (max_reward - min); result = result / (result + lanbda) * multipl; result.ReplaceNan(0); }
Para el caso especial de recompensas iguales, rellenaremos el vector de probabilidades con un valor constante.
else result.Fill(1);
A continuación, llevaremos la suma de todas las probabilidades hasta "1" y calcularemos el vector de sumas acumulativas.
result = result / result.Sum(); result = result.CumSum(); //--- return result; }
Para muestrear la trayectoria en cada iteración, utilizaremos el método SampleTrajectory, al que transmitiremos en los parámetros el vector de probabilidades acumulativas obtenido anteriormente. Y el resultado de las iteraciones será el índice de la trayectoria en el búfer de reproducción de experiencias.
int SampleTrajectory(vector<float> &probability) { //--- check ulong total = probability.Size(); if(total <= 0) return -1;
En el cuerpo del método, comprobaremos el tamaño del vector de probabilidades resultante y, si está vacío, devolveremos inmediatamente un índice no válido "-1".
A continuación, generaremos un número aleatorio en el intervalo [0, 1] a partir de una distribución uniforme y buscaremos un elemento cuyo intervalo de probabilidad de selección incluya el valor aleatorio resultante.
Primero comprobaremos los extremos (el primer y el último elemento del vector de probabilidad.
//--- randomize float rnd = float(MathRand() / 32767.0); //--- search if(rnd <= probability[0] || total == 1) return 0; if(rnd > probability[total - 2]) return int(total - 1);
Si el valor muestreado no entra dentro de los rangos de los extremos, habrá que buscar el valor deseado entre los elementos del vector.
Intuitivamente, podemos suponer que la distribución de probabilidad de las trayectorias tenderá a ser uniforme. Y, comenzando la búsqueda de elementos desde la mitad del vector cuando se mueve en la dirección correcta resultará mucho más rápido que buscar en todo el array desde el principio. Por lo tanto, multiplicaremos el valor muestreado por el tamaño del vector y obtendremos algún índice de elemento. Luego comprobaremos la probabilidad del elemento seleccionado con el valor de la muestra. Y si su probabilidad es menor, aumentaremos el índice en el ciclo hasta encontrar el elemento deseado. Si no, haremos lo mismo, solo que reduciremos el índice.
int result = int(rnd * total); if(probability[result] < rnd) while(probability[result] < rnd) result++; else while(probability[result - 1] >= rnd) result--; //--- return result return result; }
El resultado se devolverá al programa de llamada.
Otra función auxiliar que necesitaremos en el proceso de implementación del método CWBC será la función de generación de ruido. En los parámetros de la función, transmitiremos un vector de desviaciones estándar de los elementos del vector de recompensa y un coeficiente escalar que definirá el nivel máximo de ruido. Luego retornaremos el vector de ruido de la función.
vector<float> Noise(vector<float> &std, float multiplyer) { //--- check ulong total = std.Size(); if(total <= 0) return vector<float>::Zeros(0);
En el cuerpo de la función, primero comprobaremos el tamaño del vector de desviación estándar. Y si está vacío, también devolveremos un vector de ruido vacío.
Después de pasar con éxito el bloque de control, crearemos un vector de valores nulos. Y luego, en un ciclo, generaremos un valor de ruido distinto para cada elemento del vector de recompensa.
vector<float> result = vector<float>::Zeros(total); for(ulong i = 0; i < total; i++) { float rnd = float(MathRand() / 32767.0); result[i] = std[i] * rnd * multiplyer; } //--- return result return result; }
Ya hemos creado bloques separados para implementar el método CWBC y ahora pasaremos a implementar el algoritmo completo de entrenamiento del modelo del Agente, que se implementará en el método Train.
En el cuerpo del método declararemos las variables locales necesarias y llamaremos al método de ponderación de trayectorias GetProbTrajectories.
void Train(void) { float max_reward = 0, quantile = 0; vector<float> std; vector<float> probability = GetProbTrajectories(Buffer, max_reward, quantile, std, 0.95, 0.1f); uint ticks = GetTickCount();
A continuación, organizaremos un sistema de ciclos de entrenamiento de modelos. En el cuerpo del ciclo, primero llamaremos al método SampleTrajectory para muestrear la trayectoria y, a continuación, seleccionaremos aleatoriamente un estado en la trayectoria seleccionada para iniciar el proceso de entrenamiento.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
A continuación, organizaremos un ciclo anidado en el que el modelo se entrenará directamente sobre estados sucesivos del entorno. Permítanme recordarles que para el correcto entrenamiento y funcionamiento del modelo del Decision Transformer necesitaremos utilizar los acontecimientos en estricta conformidad con su secuencia histórica. El modelo recogerá los datos recibidos a medida que llegan a un búfer interno y generará una secuencia histórica para su análisis.
Actions = vector<float>::Zeros(NActions); Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
En el cuerpo del ciclo, recogeremos los datos en el búfer de datos de origen. En primer lugar, cargaremos los datos históricos de los movimientos de los precios y los indicadores analizados.
A continuación vendrá la información sobre el estado de la cuenta y las posiciones abiertas.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Después, formaremos una marca temporal.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Y añadiremos los últimos vectores de acción del Agente al búfer.
//--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Después, solo tendremos que añadir la orientación en forma de RTG al búfer. En este bloque, no utilizaremos la orientación hasta el final de la pasada, sino solo para un pequeño segmento local. Y aquí organizaremos el proceso de regularización conservadora. Para ello, primero comprobaremos la rentabilidad de la trayectoria utilizada y, de ser necesario, generaremos un vector de ruido. Recordemos que, según el método CWBC, solo se añadirá ruido a las pasadas más rentables.
//--- Return to go vector<float> target, result; vector<float> noise = vector<float>::Zeros(NRewards); target.Assign(Buffer[tr].States[0].rewards); if(target.Sum() >= quantile) noise = Noise(std, 100);
A continuación, calcularemos los rendimientos reales en el intervalo histórico local. Luego añadiremos el vector de ruido obtenido y añadiremos los valores obtenidos al búfer de datos de origen.
target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars) + noise; State.AddArray(target);
Ahora que hemos generado el conjunto completo de datos requeridos realizaremos una pasada directa del Agente para generar el vector de acción.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Tras realizar con éxito la pasada directa, llamaremos al método de pasada inversa del Agente para minimizar la discrepancia entre las acciones previstas y las reales del Agente. Este proceso será similar al entrenamiento del DT original.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Solo tendremos que informar al usuario sobre el progreso del proceso de entrenamiento del modelo y pasaremos a la siguiente iteración de nuestro sistema de ciclos de entrenamiento del modelo.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez completado el ciclo completo de iteraciones de entrenamiento del modelo, borraremos el campo de comentarios del gráfico. Luego enviaremos los resultados del entrenamiento al registro e iniciaremos la finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluiremos nuestra introducción al algoritmo de aprendizaje del Agente. El entrenamiento del modelo de estimación del entorno se basará en un principio similar en el asesor "...\CWBC\StudyRTG.mq5" y le sugiero que se familiarice con él en el archivo adjunto. Allí encontrará también todos los programas usados en este artículo.
Y me gustaría hacer un comentario más. Hemos generado una muestra inicial de entrenamiento seleccionando la mejor de las trayectorias muestreadas. Pueden clasificarse condicionalmente como subóptimas, ya que cumplen algunos de nuestros requisitos, y además nos gustaría optimizar la política del Agente entrenado con esos datos. Para ello, necesitaremos probar el rendimiento del modelo entrenado con datos históricos y, paralelamente, recabar información sobre la viabilidad de la optimización de políticas. De esta forma, en la siguiente pasada en el simulador de estrategias sobre el segmento histórico de la muestra de entrenamiento, realizaremos acciones dentro de un determinado intervalo de confianza respecto a las predichas por el Agente y añadiremos los resultados de dichas pasadas a nuestro búfer de reproducción de experiencias. Después, iteraremos el entrenamiento previo de los modelos.
Luego implementaremos la funcionalidad de recopilación de pasadas adicionales en el asesor "...\CWBC\Research.mq5". La exposición completa de todos los métodos del asesor queda fuera del alcance de este artículo. Consideraremos solo el método de procesamiento de ticks OnTick, que implementará la interacción con el entorno.
Como es habitual, en el cuerpo del método comprobaremos la aparición de un nuevo evento de apertura de barra y, de ser necesario, cargaremos los datos históricos.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A partir de los datos obtenidos, generaremos primero un vector de datos de entrada para la estimación del coste del estado y llamaremos la pasada directa del modelo correspondiente.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars - 1; b >= 0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!RTG.feedForward(GetPointer(bState), 1, false)) return;
A continuación, formaremos el tensor de datos inicial de nuestro Agente. Para ello, seguiremos la secuencia de datos utilizada en el entrenamiento del modelo. Solo que en lugar de un búfer de reproducción de experiencias, utilizaremos los datos del entorno.
for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Paralelamente, recopilaremos los datos utilizados en una estructura que se almacenará en el búfer de reproducción de experiencias.
Aquí es donde sondearemos el entorno (consultas al terminal) para recabar información sobre el estado de las cuentas y las posiciones abiertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
La marca temporal se generará respetando plenamente el algoritmo del proceso de entrenamiento.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Al final del proceso inicial de recopilación de vectores de datos, añadiremos las últimas acciones del Agente y las orientaciones generadas por nuestro modelo.
//--- Prev action bState.AddArray(AgentResult); //--- Latent representation RTG.getResults(Result); bState.AddArray(Result);
Los datos recogidos se pasarán al método de pasada directa de nuestro Agente para generar un vector de acciones de seguimiento.
//--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
Distorsionaremos ligeramente el vector de acción predictivo del Agente añadiendo ruido aleatorio. Al hacerlo, estimularemos la exploración del entorno en algún entorno de acciones previstas.
Agent.getResults(AgentResult); for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Después guardaremos los datos necesarios en las siguientes velas en variables locales.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Y corregiremos el solapamiento de volúmenes de las posiciones multidireccionales.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
Luego descodificaremos el vector de acciones del Agente resultante. Y las implantaremos en el entorno.
//--- buy control if(AgentResult[0] < 0.9*min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(AgentResult[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(AgentResult[3] < 0.9*min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(AgentResult[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Después nos quedará recibir la recompensa del entorno por la transición al estado actual (las acciones previas del Agente) y transferir los datos recogidos al búfer de reproducción de experiencias.
int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
El código completo del asesor y todos sus métodos se encuentran en el archivo adjunto.
El asesor para probar el modelo entrenado "...\CWBC\Test.mq5" será creado por un algoritmo similar, salvo por la distorsión del vector de acciones predichas por el Agente. Su código también se ofrece en el archivo adjunto al artículo.
Y después de crear todos los programas necesarios, pasaremos a probar el trabajo realizado.
3. Simulación
En la parte práctica de nuestro artículo, hemos trabajado bastante para implementar nuestra visión del método de clonación conductual ConserWeightive usando herramientas MQL5. Y ahora es el momento de evaluar el resultado de nuestro esfuerzo en la práctica. Como siempre, entrenaremos y probaremos nuestros modelos con los datos históricos del marco temporal H1 de EURUSD. Usaremos como datos de entrenamiento el periodo histórico de los 7 primeros meses de 2023. Y realizaremos las pruebas con los datos de agosto de 2023.
Como ya hemos mencionado, realizaremos el entrenamiento inicial con los datos muestreados en el artículo Control Transformer. Por lo tanto, omitiremos este proceso y pasaremos directamente al proceso de entrenamiento del modelo.
Arriba hemos creado 2 asesores para entrenar los dos modelos. Esto nos permitirá implementar el entrenamiento paralelo de los 2 modelos. El proceso puede realizarse de forma independiente en distintos dispositivos.
Tras el entrenamiento inicial de los modelos, comprobaremos el rendimiento del modelo entrenado en la muestra de entrenamiento y recogeremos trayectorias adicionales ejecutando los asesores "...\CWBC\Research.mq5" y "...\CWBC\Test.mq5" en el simulador de estrategias en el periodo histórico de la muestra de entrenamiento. En este caso, la secuencia de inicio de los asesores no influirá en el proceso de entrenamiento del modelo.
A continuación, realizaremos un entrenamiento previo de los modelos con los datos del búfer de reproducción de experiencias actualizado.
Debemos señalar aquí que, en nuestro caso, la mejora del rendimiento del modelo solo se ha observado tras la primera iteración del entrenamiento previo. Las iteraciones posteriores de recogida de trayectorias adicionales y el entrenamiento previo del modelo han fracasado. Pero este puede ser un caso especial.
Durante el entrenamiento, hemos conseguido que el modelo generara beneficios en el segmento histórico de la muestra de entrenamiento.


Durante el periodo de estudio, el modelo ha completado 141 transacciones. Alrededor del 40% se han cerrado con beneficios. La transacción rentable máxima ha superado en más de 4 veces la pérdida máxima. Y la media de transacciones rentables ha sido casi 2 veces superior a la media de pérdidas. Además, la transacción rentable media ha sido un 13% superior a la pérdida máxima. Todo ello ha ofrecido un factor de beneficio de 1,11. Se observan resultados similares en los nuevos datos.
Pero hay también un punto desagradable en los resultados. El modelo solo ha ejecutado posiciones largas, lo cual en general coincide con la tendencia global en este intervalo histórico. Como consecuencia, la línea de balance se asemeja mucho al gráfico del instrumento.

El análisis detallado de las pruebas muestra pérdidas en febrero y mayo de 2023 que se solapan en los meses siguientes. El mes de marzo ha resultado ser el más rentable. Y en el contexto de la semana, la máxima rentabilidad se ha demostrado el miércoles.
Conclusión
En este artículo, nos hemos familiarizado con el método ConserWeightive Behavioral Cloning (CWBC), que combina la ponderación de trayectorias y la regularización conservadora para mejorar la robustez de las estrategias entrenadas. Hemos implementado el método propuesto usando las herramientas MQL5 y lo hemos probado con datos históricos reales.
Nuestros resultados muestran que el CWBC exhibe un grado bastante alto de estabilidad en el entrenamiento offline de modelos. En particular, el método se adapta con éxito a condiciones en las que las trayectorias con alta rentabilidad constituyen una pequeña fracción del conjunto de datos de entrenamiento. Cabe destacar lo importante que resulta ajustar cuidadosamente los hiperparámetros necesarios: este hecho desempeña un papel esencial en la eficacia de la CWBC.
Enlaces
Programas utilizados en el artículo:
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Faza1.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Research.mq5 | Asesor | Asesor para recopilar trayectorias adicionales |
| 3 | StudyAgentmq5 | Asesor | Asesor para entrenar al modelo de política local |
| 4 | StudyRTG.mq5 | Asesor | Funciones de valor del asesor de entrenamiento |
| 5 | Test.mq5 | Asesor | Asesor para probar el modelo |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de la descripción del estado del sistema |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13742
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso