
Redes neuronales: así de sencillo (Parte 66): Problemática de la exploración en el entrenamiento offline

Introducción
Desde los primeros artículos del estudio de los métodos de aprendizaje por refuerzo, hemos planteado la cuestión del equilibrio entre la exploración del entorno y la explotación de la política aprendida. Ya hemos debatido varios métodos para incentivar al Agente a explorar, pero a menudo, los algoritmos que funcionan bien en el entrenamiento online no son tan eficaces en el entrenamiento offline. El problema es que, en el modo offline, la información del entorno está limitada por el tamaño de la muestra de entrenamiento, y la mayoría de las veces, los datos seleccionados para el entrenamiento del modelo tienen un enfoque limitado porque se recogen en el pequeño subespacio de la tarea en cuestión. De esta forma se obtiene una visión aún más tenue del entorno. No obstante, para encontrar una solución óptima, el Agente necesitará una comprensión más completa del entorno y sus patrones. Ya hemos señalado que los resultados del entrenamiento dependen con frecuencia de la muestra de entrenamiento.
Además, bastante a menudo en el proceso de aprendizaje, el Agente toma decisiones fuera del subespacio de muestras de entrenamiento. Y en tales casos, resulta difícil predecir los resultados posteriores. Por eso, tras el preentrenamiento del modelo, recogeremos más trayectorias en la muestra de entrenamiento que sean capaces de ajustar el proceso de aprendizaje.
La formación online de modelos de entorno puede a veces mitigar los problemas anteriores. Pero, por desgracia, por diversas causas, no siempre resulta posible entrenar un modelo de entorno. Con frecuencia, entrenar un modelo puede resulta incluso más caro que entrenar la política de un agente, y a veces simplemente no es posible.
La segunda dirección obvia sería ampliar la muestra de entrenamiento. Pero aquí nos vemos limitados principalmente por el tamaño físico de los recursos disponibles y el límite de coste del estudio del entrono.
En este artículo le propongo familiarizarnos con el marco Exploratory data for Offline RL (ExORL), presentado en el artículo "Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning". Los resultados presentados en este artículo demuestran que un enfoque correcto de recogida de datos tiene un impacto significativo en los resultados finales del aprendizaje. También resulta esencial la elección del algoritmo de aprendizaje y la arquitectura del modelo.
1. El método Exploratory data for Offline RL (ExORL)
Debemos decir de entrada que los autores del método Exploratory data for Offline RL (ExORL) no ofrecen nuevos algoritmos de aprendizaje ni arquitecturas de modelos. Por el contrario, toda la atención se centra en el proceso de recopilación de datos para la entrenamiento de modelos. A continuación, se realizan experimentos con cinco métodos de entrenamiento diferentes para evaluar el efecto del contenido de la muestra de entrenamiento en el resultado del aprendizaje.
El método ExORL puede dividirse en 3 etapas esenciales. La primera consiste en recoger datos de exploración sin etiquetar. Para ello, podemos utilizar diversos algoritmos de aprendizaje no supervisado. Los autores del método no limitan la gama de algoritmos usados. Para ello, utilizaremos una política π que dependerá de la historia de interacciones previas al interactuar con el entorno en cada episodio. Cada episodio se almacenará en el conjunto de datos como una secuencia del estado St, de la acción At y del consecuente estado St+1 Los datos de entrenamiento se recogerán hasta que la muestra de entrenamiento cuyo tamaño está organizado por la tarea técnica o los recursos disponibles, esté completamente llena.
En la práctica, los autores del artículo evalúan nueve algoritmos distintos de recogida de datos no supervisados:
- Una línea básica simple que siempre produce una política de selección aleatoria uniforme;
- Métodos basados en la maximización del error del modelo predictivo: ICM, Disagreement, RND;
- Algoritmos que maximizan alguna valoración de la cobertura del espacio de estados: APT y Proto-RL;
- Algoritmos basados en competencias que entrenan un conjunto diverso de habilidades: DIAYN, SMM, y APS.
Una vez recogido un conjunto de datos de estados y acciones, se reevaluarán utilizando una función de recompensa determinada. En esta fase, simplemente se tratará de estimar la recompensa de cada tupla del conjunto de datos.
Los autores del método utilizan en sus experimentos funciones de recompensa estándar o manuales. Cabe señalar que el marco propuesto también permitirá entrenar la función de recompensa, es decir, realizar un RL inverso.
El último paso de ExORL será el entrenamiento del modelo. El entrenamiento de las políticas se realizará usando algoritmos de aprendizaje por refuerzo offline con un conjunto de datos etiquetados. El entrenamiento offline se realizará íntegramente con datos de muestra de entrenamiento offline, seleccionando tuplas al azar. A continuación, se estimará la política final en el entorno real.
Luego le mostraremos la visualización del método por parte de los autores.
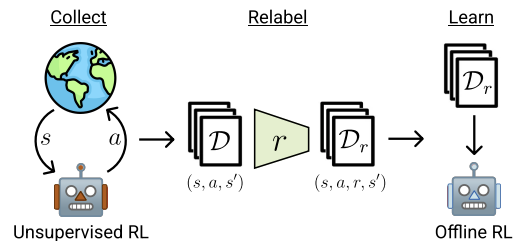
En el artículo, los autores demuestran los resultados de cinco algoritmos diferentes de aprendizaje por refuerzo offline. Se usa como caso básico la clonación simple de comportamientos. También se presentan los resultados de tres algoritmos de aprendizaje por refuerzo offline de última generación, cada uno de los cuales usa un mecanismo diferente para evitar la extrapolación más allá de las acciones de los datos. Y el clásico TD3 se presenta como prueba de referencia para evaluar el impacto del modo offline en métodos diseñados originalmente para el entrenamiento online que carecen de un mecanismo explícitamente diseñado para evitar la extrapolación más allá de la muestra de entrenamiento.
Basándose en los resultados de sus experimentos, los autores del método concluyen que el uso de datos diversos puede simplificar sustancialmente los algoritmos de aprendizaje por refuerzo offline, eliminando la necesidad de luchar con el problema de la extrapolación. Los resultados demuestran que los datos exploratorios mejoran la eficacia del aprendizaje por refuerzo offline en múltiples tareas. Además, los algoritmos de aprendizaje por refuerzo offline desarrollados antes funcionan bien con datos orientados a tareas, pero son inferiores a TD3 en datos ExORL sin etiquetar. Lo ideal sería que los algoritmos de aprendizaje por refuerzo offline se adaptaran automáticamente al conjunto de datos usado para recuperar lo mejor de ambos enfoques.
2. Implementación usando MQL5
Como se desprende de la descripción anterior, los autores del método Exploratory data for Offline RL (ExORL) ofrecen una dirección general para la construcción del marco. Al hacerlo, ellos mismos experimentan con distintos métodos de entrenamiento de modelos; así, en la parte práctica del artículo hemos decidido construir una implementación de ExORL lo más parecida posible al modelo del artículo anterior. Pero debemos tener en cuenta un aspecto del diseño. El algoritmo DWSL consiste en ponderar las acciones del estado S según su Ventaja. Recordemos que en nuestra implementación encontramos los estados más próximos de todas las trayectorias según su incorporación, y ponderamos las acciones en los estados seleccionados según su efecto en el resultado.
El método ExORL, en cambio, supone la máxima diversidad en el comportamiento del Agente, y en este sentido, necesitaremos determinar la distancia entre acciones en estados individuales. El uso de la distancia hasta el par Estado-Acción más cercano como recompensa incentivará al Agente a explorar el entorno. Por ello, definiremos la incorporación del estado dada la acción.
Otra posibilidad sería determinar la distancia entre estados sucesivos. Y existe cierto grado de racionalidad a la hora de enfrentarse a un entorno estocástico, cuando realizar una acción con cierta probabilidad puede conducir a diferentes estados posteriores. Sin embargo, el uso de tales algoritmos nos separará aún más del método DWSL, que utilizamos como método básico para nuestra implementación, y unos ajustes mínimos del algoritmo básico nos permitirán evaluar mejor el impacto del marco ExORL específicamente en el resultado del entrenamiento del modelo.
Así que nos hemos decantado por la primera opción y aumentado el tamaño de la capa de datos de origen del modelo del Codificador por el vector de acción del Actor. Por lo demás, la arquitectura de los modelos permanecerá inalterada. Usted mismo puede familiarizarse con ella en el archivo adjunto. Archivo "...\ExORL\Trajectory.mqh", método CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
El proceso de recopilación de datos de entrenamiento se organizará en el asesor "...\ExORL\ResearchExORL.mq5".
Observe la indicación del marco en el nombre del archivo. La cuestión es que en el archivo adjunto, usted encontrará el archivo "...\ExORL\Research.mq5", que ha sido transferido desde el artículo anterior sin ningún cambio. Así que no nos detendremos a analizar su algoritmo.
Ambos asesores están diseñados para completar la muestra de entrenamiento, y por extraño que pueda parecer, utilizaremos ambos asesores en nuestro entrenamiento. Pero hablaremos de eso un poco más tarde. Ahora volvamos al algoritmo del asesor "...\ExORL\ResearchExORL.mq5".
Los parámetros externos del asesor se transferirán sin cambios desde el asesor básico de Interacción con el entorno,
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
salvo que enseñaremos la política de exploración del entorno para el Actor en la interacción. Y en el proceso de aprendizaje, necesitaremos los modelos del Crítico y el Codificador. Para reducir el coste de entrenamiento de la política de exploración y, en consecuencia, aumentar la velocidad de recopilación de los datos de entrenamiento, hemos decidido utilizar solo un Crítico.
CNet Actor; CNet Critic; CNet Convolution;
Además, añadiremos a la lista de variables globales la bandera para cargar las trayectorias recorridas anteriormente y su matriz de incorporaciones.
bool BaseLoaded; matrix<float> state_embeddings;
En el método OnInit de inicialización del asesor, primero inicializaremos los indicadores analizados.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Luego especificaremos el tipo de orden de las operaciones comerciales,
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
y cargaremos los modelos preentrenados. Si no hay ninguno disponible, crearemos nuevos modelos inicializados con pesos aleatorios. En este asesor, hemos decidido dividir la carga de modelos en diferentes bloques, lo cual nos permitirá utilizar un Crítico previamente entrenado en ausencia de un Actor o Codificador entrenados.
Nótese que antes siempre hemos hablado de la necesidad de un conjunto completo de modelos sincronizados. ,Y en este caso usamos deliberadamente un Crítico entrenado aparte del Actor. y hay una razón para ello. He estado pensando durante mucho tiempo acerca de la construcción de un algoritmo para sincronizar los coeficientes de peso entre modelos en diferentes agentes de prueba de MetaTrader 5. Pero he abandonado esta idea y decidido crear varios modelos paralelos entrenados del Actor de exploración. Una vez inicializados con parámetros aleatorios, estos modelos se entrenarán en paralelo con datos históricos, y a pesar de tener del mismo tramo histórico, cada modelo del Actor de exploración seguirá su propio camino de aprendizaje individual, ampliando así el subespacio explorado del entorno, mientras que el uso de un único búfer de trayectorias recorridas previamente minimizará la repetición de trayectorias.
Para identificar los modelos del Actor de exploración, añadiremos el sufijo "Ex" y el número del agente de los parámetros externos al nombre del archivo del modelo, y la optimización de este parámetro nos permitirá ejecutar varios Actores de exploración en paralelo en el Simulador de Estrategias de MetaTrader 5.
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
Al mismo tiempo, utilizaremos un único modelo de Crítico para organizar condiciones de aprendizaje idénticas para todos los Actores de la exploración. Por eso es importante que carguemos un modelo de Crítico preentrenado, incluso en ausencia de modelos de Actor de exploración.
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Utilizar un único modelo de codificador para todos los agentes también nos permitirá organizar la comparación de los estados y acciones en un único subespacio. Sin embargo, no será fundamental para el proceso de aprendizaje, dado que cada Agente realiza de forma independiente la codificación de las trayectorias recorridas previamente, lo cual nos permite estimar correctamente las distancias y diversificar el comportamiento del Actor.
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Estoy de acuerdo en que el código presentado parece engorroso, y probablemente sería lógico separar la descripción de la arquitectura de los modelos por métodos diferentes, pero esto solo simplificaría el código de este asesor, complicando a su vez el código de otros programas utilizados en el artículo. Por este motivo hemos abandonado el método de división para describir la arquitectura de los modelos.
En cambio, hemos trasladado todos los modelos a un único contexto OpenCL, lo cual nos permitirá sincronizar su trabajo y reducir la cantidad de datos que se copian entre la memoria principal y la memoria de contexto OpenCL.
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Tenga en cuenta que hemos desactivado el modo de aprendizaje del Crítico. Antes hemos hablado de la importancia de crear el mismo entorno de entrenamiento para todos los Agentes de exploración de entorno, y mantener el Crítico en un estado fijo desempeñará un papel importante en este proceso.
A continuación, implementaremos el control mínimo ya estándar de la arquitectura del modelo,
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
e inicializaremos las variables globales.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
Una vez completadas con éxito todas las operaciones anteriores, finalizaremos el método de inicialización del asesor.
En el método de inicialización del programa, no cargaremos las trayectorias recorridas anteriormente, y no crearemos sus incorporaciones. Esto se debe a que el proceso de creación de incorporaciones de estados previamente transmitidos puede resultar bastante laborioso y llevar mucho tiempo. Su duración dependerá del número de estados visitados.
Como ya hemos mencionado, a diferencia de los asesores de interacción con el entorno comentados anteriormente, en este caso entrenaremos al Actor de exploración. Y al final de cada pasada, guardaremos el modelo entrenado.
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
A continuación, debemos decir unas palabras sobre los métodos de apoyo establecidos. En primer lugar, el proceso de codificación de los estados y acciones lo hemos trasladado al método CreateEmbeddings. Este método no tiene parámetros y retorna una matriz de incorporaciones de estado.
En el cuerpo del método, primero crearemos las variables locales.
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
A continuación, intentaremos cargar la base de datos de trayectorias recopilada previamente, y en caso de error en la carga de datos, retornaremos una matriz vacía al programa que ha realizado la llamada.
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
Cuando la base de datos de trayectorias se haya cargado correctamente, contaremos el número total de estados en todas las trayectorias y redimensionaremos la matriz para rellenarla.
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
Luego irá un sistema de ciclos anidados para codificar los estados y acciones. En el ciclo exterior, iteraremos por las trayectorias cargadas. Y en un ciclo anidado, por los estados.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
En el cuerpo del sistema del ciclo anterior, primero crearemos un búfer de datos iniciales para describir el estado del entorno. En el búfer especificado transferiremos los datos históricos del movimiento de los precios y de los indicadores analizados.
Después añadiremos una descripción del estado de la cuenta y de las posiciones abiertas.
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
Y añadiremos una marca temporal en forma de vector armónico,
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
además del vector de acción del Actor.
State.AddArray(Buffer[tr].States[st].action);
Luego transmitiremos el tensor recogido al Codificador para su codificación y llamaremos al método de pasada directa. Y añadiremos la incorporación resultante a la matriz de resultados.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
A continuación, pasaremos al siguiente estado desde el búfer de trayectorias.
Una vez completadas todas las iteraciones del sistema de ciclo de codificación de estados, reduciremos el tamaño de la matriz de resultados al número real de incorporaciones almacenadas y vaciaremos el búfer de trayectorias cargadas previamente. En el futuro solo trabajaremos con incorporaciones.
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
El resultado obtenido lo retornaremos al programa que realiza la llamada y finalizaremos el método.
//--- return result; }
A continuación, construiremos un método para generar la recompensa interna ResearchReward. Cabe destacar aquí que para crear un sistema de exploración eficaz del entorno a la hora de entrenar a los Actores de exploración, solo utilizaremos recompensas intrínsecas destinadas a incentivar al Agente para que realice acciones variadas y no repetitivas. Por lo tanto, en esta fase no necesitaremos datos marcados ni una recompensa externa que pueda limitar el espacio de entorno por explorar. A este respecto, deberemos prestar especial atención al desarrollo de la recompensa interna.
En los parámetros del método ResearchReward, transmitiremos:
- el cuantil de los estados y acciones más próximos utilizados para generar la recompensa intrínseca;
- la incorporación del estado analizado;
- la matriz de incorporaciones de estados generada con la ayuda del método anteriormente presentado.
En el cuerpo del método, prepararemos un vector cero de resultados y comprobaremos si el tamaño de la incorporación del estado analizado se corresponde con las incorporaciones de la matriz creada previamente.
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
Después de transmitir con éxito el bloque de control, inicializaremos las variables locales.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
El siguiente paso consistirá en calcular la distancia entre el par Estado-Acción analizado y almacenado previamente en el búfer de reproducción de experiencias. Utilizaremos la función LogSumExp, propuesta por los autores del método DWSL, para obtener una estimación suave de las distancias.
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
A continuación, seleccionaremos el número necesario de incorporaciones de los pares Estado-Acción más cercanos,
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
y utilizando el algoritmo de normas nucleares, generaremos una recompensa intrínseca para la acción elegida y el estado latente del Actor.
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
El resultado se retornará al programa que realiza la llamada.
Observe que en el vector de resultados, los elementos de recompensa externa se dejarán con valores cero, lo cual es bastante coherente con el marco ExORL. El asesor que nos ocupa está concebido para organizar exploraciones no controladas de entornos. Y, como ya hemos dicho, utilizar una recompensa externa en esta fase solo limitará el subespacio investigado.
El proceso inmediato de interacción con el entorno y el aprendizaje de la política del Actor de exploración se organizará en el método de gestión de ticks OnTick. Debemos decir que en esta fase el proceso de entrenamiento se ha simplificado al máximo. Como ya hemos dicho, en el proceso de entrenamiento solo se utiliza 1 Crítico. Además, no hemos abandonado el uso del búfer de reproducción de experiencias en el entrenamiento del modelo Actor de exploración. Potencialmente, su ausencia se compensará con pasadas adicionales en el simulador de estrategias.
Realizaremos una pasada inversa en cada vela. Esto ajustará los parámetros según la última acción del Actor.
Puede que este enfoque no sea el más eficaz, pero es el más fácil de aplicar, y resulta totalmente aplicable al evaluar la eficacia del método.
En el cuerpo del método, como siempre, primero comprobaremos si ha sucedido el evento de apertura de nueva barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Después descargaremos los datos históricos.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, generaremos los búferes de datos de origen de nuestro Actor de exploración. En primer lugar, rellenaremos el búfer de descripción del estado del entorno con los datos históricos obtenidos.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
A continuación, comprobaremos el estado actual de la cuenta y las posiciones abiertas.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
A partir de los datos obtenidos, crearemos un búfer de descripción del estado de la cuenta,
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
al que luego añadimos el vector de armónicos de la marca temporal.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Los datos generados bastarán para realizar la pasada directa del Actor.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Si la pasada directa del Actor ha tenido éxito, obtendremos un vector de acciones predictivas que desencriptaremos y transmitiremos al entorno.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
En primer lugar, interactuaremos con el entorno dentro de una posición larga,
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
y repetiremos las operaciones para la corta.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Luego reuniremos los resultados de nuestras interacciones con el entorno en una estructura de descripciones de estados y acciones. Complementaremos con una recompensa externa, y la añadiremos a la trayectoria que se añadirá al búfer de reproducción de experiencias según los resultados de la pasada.
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
Aquí merece la pena prestar atención al vector de recompensas. Antes hemos hablado de una exploración incontrolada, y hemos rellenado el vector con recompensas externas. Al mismo tiempo, dejaremos los elementos de la recompensa interna con valores cero. Aquí tenemos que darnos cuenta de que las trayectorias almacenadas se usarán para entrenar la política del Actor principal en la fase 3 del marco ExORL, mientras que el rellenado del búfer de recompensas supondrá la implementación de la segunda etapa del método que nos ocupa: la reevaluación de los estados y acciones. Por tanto, todas nuestras acciones encajarán en el marco del algoritmo ExORL.
Como podemos ver, el algoritmo presentado anteriormente repite casi por completo los métodos de interacción con el entorno que hemos considerado anteriormente, pero aquí no finalizaremos el método como antes, sino que pasaremos a la aplicación del proceso de entrenamiento de la política del Actor de exploración.
En primer lugar, necesitaremos una incorporación del estado actual y la acción realizada. Para ello, completaremos el búfer de estado del entorno actual con información sobre el estado de la cuenta y la acción realizada del Actor. Luego introduciremos el búfer obtenido en la entrada del codificador y llamaremos al método de pasada directa.
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
Como resultado de las operaciones realizadas con éxito, obtendremos una incorporación del estado actual.
A continuación, comprobaremos la presencia de los datos cargados sobre trayectorias recorridas anteriormente y, si fuera necesario, los codificaremos llamando al método CreateEmbeddings presentado anteriormente.
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
Tenga en cuenta que, independientemente del resultado de las operaciones, estableceremos el indicador de carga de datos en true. Esto nos permitirá eliminar futuros reintentos de cargar la base de estados pasados.
A continuación, comprobaremos el tamaño de la matriz de incorporación de estados. El tamaño cero de esta matriz puede indicar la ausencia de trayectorias recorridas anteriormente. En este caso, no tendremos datos para actualizar los parámetros del modelo en esta fase, y simplemente añadiremos la incorporación del estado actual a la matriz. Después esperaremos a que se abra la siguiente vela.
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
Si en la matriz de incorporación de los estados pasados hay datos, generaremos una recompensa interna y aumentaremos la matriz con la incorporación del estado actual.
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
Será esencial añadir la incorporación del estado actual en la matriz de incorporaciones de estados pasados solo después de generar la recompensa interna. De lo contrario, la incorporación actual se contabilizará dos veces en el cálculo de la recompensa interna, lo que podría sesgar los datos.
No obstante, eliminar por completo el proceso de adición de incorporaciones a la matriz no permitirá considerar los estados de la pasada actual a la hora de generar la recompensa interna.
Así, transmitiremos la recompensa interna generada al búfer de datos, y luego realizaremos una pasada directa e inversa del Crítico, seguida de una pasada inversa del Actor de exploración.
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
Tenga en cuenta que en este caso, estamos haciendo una llamada secuencial a los métodos de pasada directa e inversa del Crítico dentro de una misma operación. La cuestión es que en este caso no estamos entrenando al Crítico ni evaluando los resultados de su pasada directa. Solo lo necesitaremos para transmitir el gradiente de error al Actor. Por lo tanto, ambos métodos se llamarán como parte de la organización del procedimiento de pasada inversa del Actor. Esto ha dado lugar a una disposición sumamente inusual de las llamadas a los métodos que, no obstante, no afecta al resultado final.
Con esto damos por concluidas las descripciones del método de interacción con el entorno y el entrenamiento online de la política del Actor de exploración. Los otros métodos del asesor se han mantenido sin cambios, así que podrá familiarizarse con ellos en el anexo.
Vamos a pasar a los ajustes del asesor de entrenamiento del modelo. Aunque los autores del método han usado técnicas básicas de entrenamiento de modelos en sus experimentos, la aplicación de nuestro enfoque aún requiere algunas modificaciones del asesor de entrenamiento del artículo anterior. Las modificaciones introducidas se deben principalmente a un cambio en la arquitectura del codificador, que ha obligado a ajustar los momentos de interacción con el modelo. Pero lo primero es lo primero.
Los cambios realizados no son globales. Por ello, solo nos centraremos en analizar el método de entrenamiento directo del modelo Train. En el cuerpo del método, comprobaremos el número de trayectorias cargadas.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
A continuación, calcularemos el número total de estados en estas trayectorias,
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
y prepararemos las variables locales.
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
Después organizaremos un sistema de ciclos de codificación de los estados previamente transmitidos con la compilación de la matriz de incorporaciones. Este proceso será similar al descrito anteriormente, pero hay un matiz a considerar.
Como antes, en el cuerpo del sistema de ciclo, rellenaremos el búfer del estado actual del entorno.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Lo completaremos con el estado de la cuenta y las posiciones abiertas.
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
Luego rellenaremos los armónicos de la marca temporal.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Pero en lugar del vector de acciones, pasaremos un vector cero de la longitud correspondiente.
State.AddArray(vector<float>::Zeros(NActions));
Esta solución nos permitirá excluir el efecto de las acciones realizadas en la incorporación de los estados, y con ello regresaremos a la implementación del método DWSL del último artículo, nivelando los cambios en la arquitectura del Codificador. Así pues, tal y como recomiendan los autores del método ExORL, utilizaremos los métodos de entrenamiento de modelos no modificados. En este caso, se utilizará un único codificador estado-acción en el proceso de entrenamiento de todos los modelos, lo cual nos permitirá entrenar tanto las políticas del Actor de exploración como la política del Actor principal de la forma más correcta posible.
A continuación, realizaremos una pasada directa del Codificador. Y añadiremos el resultado de las operaciones como incorporación de estado a la matriz.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
Aquí rellenaremos de forma sincrónica las matrices de acciones y recompensas que se utilizarán en el proceso de entrenamiento según el algoritmo DWSL. Al igual que antes, la matriz de recompensas se rellenará con los valores de los beneficios de las acciones realizadas.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
Luego informaremos al usuario del progreso de la codificación de los estados y pasaremos a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
Tras completar con éxito todas las iteraciones de codificación de los estados, reduciremos el tamaño de las matrices a la cantidad de datos realmente almacenados. Sin embargo, a diferencia del método de codificación CreateEmbeddings comentado anteriormente, no borraremos la matriz de trayectorias, ya que la seguiremos necesitando al entrenar los modelos.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
} Después vendrá la organización del proceso de entrenamiento propiamente dicho. En primer lugar, crearemos variables locales y formaremos un vector de probabilidades de la selección de trayectorias.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
Después organizaremos un ciclo de entrenamiento. En el cuerpo del ciclo, muestrearemos la trayectoria y el estado en ella.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
A continuación, comprobaremos la necesidad de generar recompensas hasta el final del episodio. Y rellenaremos el búfer del estado del entorno posterior si fuera necesario.
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
Aquí es donde llenaremos el búfer que describe el estado posterior de la cuenta y las posiciones abiertas.
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Y lo complementaremos con armónicos de la marca temporal.
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Los datos generados serán suficientes para realizar una pasada directa del Actor, que generará una acción de acuerdo con la política actualizada.
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
La acción resultante será evaluada por los 2 Críticos objetivo.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
Utilizaremos la menor de las estimaciones como recompensa esperada. Y la complementaremos con la entropía del estado latente.
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
El siguiente paso será entrenar los modelos Crítico. Para ello, formaremos un vector que describa el estado actual del entorno.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Formaremos un vector que describa el estado de la cuenta y las posiciones abiertas, complementado por los armónicos de la marca temporal.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Después de lo cual realizaremos una pasada directa del Actor.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Como recordará, para entrenar a los Críticos utilizamos las acciones reales realizadas en la interacción con el entorno. Sin embargo, necesitaremos el pasada directa del Actor para formar un estado latente.
A continuación, copiaremos las acciones reales de la muestra de entrenamiento en el búfer de datos y realizaremos una pasada directa del Crítico.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Luego añadiremos los datos del estado de la cuenta y el vector nulo al búfer de descripción del estado del entorno actual, para sustituir las acciones del Actor, y generar una incorporación del estado de entorno analizado.
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
A partir de la incorporación resultante, generaremos una estructura objetivo para el entrenamiento del modelo. El algoritmo del método de entrenamiento de valores objetivo se describe en el artículo anterior.
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
En esta fase tenemos todos los datos que necesitamos para la pasada inversa de los Críticos. Pero como corregiremos el vector de gradiente de error utilizando el método CAGrad, entrenaremos los modelos secuencialmente.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A continuación pasaremos a enseñar la política básica del Actor. Como antes, utilizaremos combinaciones de enfoques para el aprendizaje de políticas. Primero usaremos el algoritmo DWSL y entrenaremos al Actor para que repita acciones ponderadas por su impacto en el resultado final.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Y luego ajustaremos las acciones del Actor para aumentar la rentabilidad. Solo se recurrirá a la segunda fase del entrenamiento cuando exista suficiente confianza en la corrección de la evaluación de las acciones por parte del Crítico.
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
Al final de las iteraciones del proceso de aprendizaje, ajustaremos los parámetros de los modelos objetivo.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Luego informaremos al usuario sobre el progreso del proceso de aprendizaje y pasaremos a la siguiente iteración del ciclo de aprendizaje.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completado el ciclo completo de entrenamiento del modelo, borraremos el campo de comentarios del gráfico. Enviaremos los resultados del entrenamiento al registro e iniciaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluiremos la descripción de los algoritmos de los programas utilizados. El código completo de todos los programas utilizados en este artículo se encuentra en el archivo adjunto. Ahora pasaremos a la fase de comprobación del trabajo realizado.
3. Simulación
En las secciones anteriores de este artículo, hemos aprendido sobre el método Exploratory data for Offline RL e implementado nuestra visión del método presentado utilizando herramientas MQL5. Ahora es el momento de evaluar los resultados del trabajo realizado. Como siempre, el entrenamiento y las pruebas del modelo se llevarán a cabo con los datos históricos del instrumento EURUSD, marco temporal H1. Los parámetros de todos los indicadores se utilizarán por defecto. Los modelos se entrenarán con los datos históricos de los 7 primeros meses de 2023. Las pruebas de los modelos entrenados se realizarán con los datos de agosto de 2023.
El algoritmo presentado en este artículo permitirá entrenar modelos completamente nuevos. Desde cero, por así decirlo. Sin embargo, el método también permitirá afinar los modelos previamente entrenados. Hemos decidido probar precisamente la segunda opción de uso del método. Como hemos mencionado al principio de nuestro trabajo, los asesores del artículo anterior se han utilizado como base de nuestro trabajo. Optimizaremos este modelo en concreto. Primero deberemos cambiar el nombre de los archivos de los modelos.
| DWSL.bd. | ==> | ExORL.bd. |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
No estamos trasladando el modelo Codificador ya que hemos cambiado su arquitectura.
Tras renombrar los archivos, ejecutaremos el asesor "ResearchExORL.mq5" para seguir explorando el entorno con los datos de entrenamiento. En nuestro trabajo, hemos recopilado 100 pasadas adicionales de 5 agentes de prueba.
La experiencia práctica demuestra que es posible utilizar en paralelo en un mismo búfer de reproducción lo recogido por distintos métodos. Hemos utilizado las trayectorias recogidas por el asesor "Research.mq5" y el asesor "ResearchExORL.mq5". La primera señala las ventajas e inconvenientes de la política de aprendizaje del actor. La segunda permite explorar al máximo el entorno y evaluar las oportunidades no aprovechadas.
En el proceso de entrenamiento iterativo del modelo, hemos logrado mejorar su rendimiento.


A pesar de haber reducido el número de transacciones durante el periodo de prueba en 3 veces (56 frente a 176), el beneficio ha aumentado prácticamente en 3 veces. El importe de la transacción más rentable se ha multiplicado por más de 2, mientras que la media de transacciones rentables se ha multiplicado por 5. Al mismo tiempo, hemos visto crecer el balance a lo largo del periodo de pruebas. Como resultado, el factor de beneficio del modelo ha aumentado de 1,3 a 2,96.
Conclusión
En este artículo, hemos introducido un nuevo método de datos exploratorios para RL offline, que hace hincapié principalmente en el enfoque de recopilación de datos para la muestra de entrenamiento en el entrenamiento de modelos offline. Los experimentos realizados por los autores del método hacen del problema de la selección de los datos iniciales una de las cuestiones clave, que influye en el resultado al mismo nivel que la elección de la arquitectura del modelo y su método de entrenamiento.
En la parte práctica de nuestro artículo, hemos implementado nuestra visión del método propuesto y la hemos probado con los datos históricos del Simulador de Estrategias de MetaTrader 5. Las pruebas realizadas confirman las conclusiones de los autores del método sobre la influencia del algoritmo de recogida de muestras de entrenamiento en el resultado del entrenamiento del modelo. Prácticamente con solo cambiar el enfoque de recopilación de las trayectorias de entrenamiento hemos podido optimizar el rendimiento del modelo del artículo anterior.
Sin embargo, una vez más me gustaría llamar su atención sobre el hecho de que todos los programas presentados en este artículo tienen fines únicamente demostrativos y no están optimizados para el comercio real.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchExORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método ExORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13819
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
No sé cómo MetaTrader Tester selecciona entradas para cada núcleo. La idea principal en el estudio online es usar el modelo preentrenado de una pasada a otra. Pero si Tester ejecutar Optimithation 1..4 al Agente 1 en una sola pasada el que todos utilizan al azar (no pre-entrenado) modelo.
No sé cómo MetaTrader Tester selecciona entradas para cada núcleo. La idea principal en el estudio en línea es utilizar el modelo pre-entrenado de una pasada a otra. Pero si Tester ejecutar Optimithation 1..4 al Agente 1 en una sola pasada el que todos utilizan al azar (no pre-entrenado) modelo.
También he añadido algunos indicadores y parámetros, total 27 BarDescr.... Momentum, Bandas & Ichimoku Kinko Hyo =)
int OnInit()
{
Establecer símbolo y actualizar
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Inicializar el indicador Ichimoku Kinko Hyo
if (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod)))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. ¡BufferResize(HistoryBars) || ! ¡CCI.BufferResize(HistoryBars) ||| !
¡! ATR. ¡BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
return;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Tipos, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Actualizar();
MACD. Actualizar();
Symb.Refresh();
Momentum.Refresh();
Bandas.Actualizar();
Symb.RefreshRates();
Actualiza los valores de Ichimoku para la barra actual
Ichimoku.Refresh();
--- Datos históricos
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Tasas[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Main(b);
float macd = (float)MACD. Principal(b);
float señal = (float)MACD. Señal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bandas.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Utiliza el valor calculado
float kijun = (float)Ichimoku.KijunSen(1); Usar el valor calculado
float senkasa = (float)Ichimoku.SenkouSpanA(2); Utilice el valor calculado
float senkb = (float)Ichimoku.SenkouSpanB(3); Usar el valor calculado
Comprobar EMPTY_VALUE y división por cero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 | senkb == 0.0)
{
continuar;
}
Asegúrese de que los buffers no se redimensionan dentro del bucle
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
Momentum.Refresh();
Bandas.Actualizar();
Symb.RefreshRates();
// Actualizar los valores de Ichimoku para la barra actual
Ichimoku.Refresh();
//---
Print("Estado 0: ", sEstado.estado[shift]);
Print("Estado 1: ", sEstado.estado[shift + 1]);
Print("Estado 2: ", sEstado.estado[shift + 2]);
Print("Estado 3: ", sEstado.estado[turno + 3]);
Print("Estado 4: ", sEstado.estado[turno + 4]);
Print("Estado 5: ", sEstado.estado[turno + 5]);
Print("Estado 6: ", sEstado.estado[turno + 6]);
Print("Estado 7: ", sEstado.estado[turno + 7]);
Print("Estado 8: ", sEstado.estado[turno + 8]);
Print("Estado 9: ", sEstado.estado[turno + 9]);
Print("Estado 10: ", sEstado.estado[turno + 10]);
Print("Estado 11: ", sEstado.estado[turno + 11]);
Print("Estado 12: ", sEstado.estado[turno + 12]);
Print("Estado 13: ", sEstado.estado[turno + 13]);
Print("Estado 14: ", sEstado.estado[turno + 14]);
Print("Estado 15: ", sEstado.estado[turno + 15]);
Print("Estado 16: ", sEstado.estado[turno + 16]);
Print("Estado 17: ", sEstado.estado[turno + 17]);
Print("Estado 18: ", sEstado.estado[turno + 18]);
Print("Estado 19: ", sEstado.estado[turno + 19]);
Print("Estado 20: ", sEstado.estado[turno + 20]);
Print("Estado 21: ", sEstado.estado[turno + 21]);
Print("Estado 22: ", sEstado.estado[turno + 22]);
Print("Estado 23: ", sEstado.estado[turno + 23]);
Print("Estado 24: ", sEstado.estado[turno + 24]);
Print("Estado 25: ", sEstado.estado[turno + 25]);
Print("Estado 26: ", sEstado.estado[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
También he añadido algunos indicadores y parámetros, total 27 BarDescr.... Momentum, Bandas y Ichimoku Kinko Hyo =)
int OnInit()
{
Establecer símbolo y actualizar
if(! Símbolo.Nombre(_Símbolo))
return INIT_FAILED;
Symb.Actualizar();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Inicializar el indicador Ichimoku Kinko Hyo
If (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. ¡BufferResize(HistoryBars) || ! CCI.BufferResize(HistoryBars) ||| CCI.
¡! ATR. ¡BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
vuelve;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Tasas, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Actualizar();
MACD. Refresh();
Symb.Refresh();
Momentum.Refresh();
Bandas.Actualizar();
Symb.RefreshRates();
Actualiza los valores de Ichimoku para la barra actual
Ichimoku.Refresh();
--- Datos históricos
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Tarifas[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Principal(b);
float macd = (float)MACD. Main(b);
float señal = (float)MACD. Señal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bandas.Superior(b);
float bandzb = (float)Bandas.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Utilizar el valor calculado.
float kijun = (float)Ichimoku.KijunSen(1); Usar el valor calculado
float senkasa = (float)Ichimoku.SenkouSpanA(2); Usar el valor calculado
float senkb = (float)Ichimoku.SenkouSpanB(3); Usar el valor calculado
Comprobar EMPTY_VALUE y división por cero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
continuar;
}
Asegurarse de que los buffers no se redimensionan dentro del bucle.
int desplazamiento = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Actualizar();
ATR.Actualizar();
MACD.Actualizar();
Symb.Refresh();
Momentum.Refresh();
Bandas.Actualizar();
Symb.RefreshRates();
// Refresca los valores de Ichimoku para la barra actual
Ichimoku.Refresh();
//---
Print("Estado 0: ", sEstado.estado[shift]);
Print("Estado 1: ", sEstado.estado[shift + 1]);
Print("Estado 2: ", sEstado.estado[shift + 2]);
Print("Estado 3: ", sEstado.estado[turno + 3]);
Print("Estado 4: ", sEstado.estado[turno + 4]);
Print("Estado 5: ", sEstado.estado[turno + 5]);
Print("Estado 6: ", sEstado.estado[turno + 6]);
Print("Estado 7: ", sEstado.estado[turno + 7]);
Print("Estado 8: ", sEstado.estado[turno + 8]);
Print("Estado 9: ", sEstado.estado[turno + 9]);
Print("Estado 10: ", sEstado.estado[turno + 10]);
Print("Estado 11: ", sEstado.estado[turno + 11]);
Print("Estado 12: ", sEstado.estado[turno + 12]);
Print("Estado 13: ", sEstado.estado[turno + 13]);
Print("Estado 14: ", sEstado.estado[turno + 14]);
Print("Estado 15: ", sEstado.estado[turno + 15]);
Print("Estado 16: ", sEstado.estado[turno + 16]);
Print("Estado 17: ", sEstado.estado[turno + 17]);
Print("Estado 18: ", sEstado.estado[turno + 18]);
Print("Estado 19: ", sEstado.estado[turno + 19]);
Print("Estado 20: ", sEstado.estado[turno + 20]);
Print("Estado 21: ", sEstado.estado[turno + 21]);
Print("Estado 22: ", sEstado.estado[turno + 22]);
Print("Estado 23: ", sEstado.estado[turno + 23]);
Print("Estado 24: ", sEstado.estado[turno + 24]);
Print("Estado 25: ", sEstado.estado[turno + 25]);
Print("Estado 26: ", sEstado.estado[turno + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
JimReaper - ¿Cuántos ciclos estudiaste tu versión antes de obtener el resultado de tu foto? (recopilación de datos - entrenamiento). ¿Y cuánto tiempo te llevó?
¿Cuál es la configuración de tu ordenador (procesador, tarjeta de vídeo, RAM)?
Muchas gracias
entonces establecer agente a 5 y Optimización a 20
Total de 100...
Veo que el código hace referencia al agente, pero no a la optimización. ¿Has añadido algo al código para utilizar este nuevo parámetro?
Gracias
Paul