
Asesor experto de scalping Ilan 3.0 Ai con aprendizaje automático

Introducción
En el mundo del trading algorítmico, algunas estrategias, igual que estrellas eternas en el firmamento siempre cambiante de los mercados financieros, dejan una marca indeleble en la historia del trading. Entre ellas se encuentra Ilan, el otrora legendario asesor-gradador que cautivó las mentes y las cuentas de los tráders en la década de 2010 por su engañosa sencillez y su potencial eficacia en periodos de baja volatilidad.
Sin embargo, el mundo avanza a toda velocidad. En la era de la computación cuántica, las redes neuronales y el aprendizaje automático, las estrategias de ayer requieren un replanteamiento fundamental. ¿Y si combinamos la mecánica clásica de promediación de cuadrículas de Ilan con algoritmos avanzados de inteligencia artificial? ¿Y si, en lugar de reglas rígidas, dejamos que el sistema se adapte y mejore continuamente por sí mismo?
En este artículo, desafiaremos las nociones establecidas de los sistemas comerciales y haremos un ambicioso intento de revivir el clásico Ilan armándolo con aprendizaje profundo de refuerzo (DQN) y mecanismos dinámicos de tabla Q. Y no nos limitaremos a modificar el código existente: vamos a crear un sistema inteligente fundamentalmente nuevo, capaz de aprender de la experiencia, adaptarse a los cambios del mercado y optimizar las decisiones comerciales en tiempo real.
Nuestro viaje nos llevará por los laberintos del trading algorítmico, donde el rigor matemático se une a la elegancia computacional y las técnicas clásicas de martingale cobran nueva vida gracias a innovadores enfoques de aprendizaje automático. No importa si es usted un tráder algorítmico experimentado, un desarrollador de sistemas comerciales o simplemente un entusiasta de la tecnología financiera: este artículo le ofrecerá una perspectiva única sobre el futuro del trading automatizado.
Abróchese el cinturón; hoy nos embarcaremos en un apasionante viaje para crear Ilan 3.0 AI, donde la tradición se une a la innovación y el pasado evoluciona hacia el futuro.
Desmontando el clásico Ilan desde dentro
Antes de sumergirnos en el mundo de la inteligencia artificial, debemos entender qué hizo de Ilan un asesor tan popular en la década de 2010. La idea clave de su funcionamiento era el concepto de promediación de posiciones. Cuando el precio se movía en contra de la posición abierta, el asesor experto no cerraba la pérdida, sino que añadía nuevas órdenes, mejorando el precio medio de entrada.
A continuación le mostramos un fragmento de código simplificado que ilustra esta lógica:
// Упрощенная логика усреднения в оригинальном Ilan if(positionCount == 0) { // Открытие первой позиции по сигналу if(OpenSignal()) { OpenPosition(ORDER_TYPE_BUY, StartLot); } } else { // Вычисление уровня для усреднения double averagePrice = CalculateAveragePrice(); double gridLevel = averagePrice - GridSize * Point(); // Если цена достигла уровня сетки, добавляем позицию if(Bid <= gridLevel) { double newLot = StartLot * MathPow(LotMultiplier, positionCount); OpenPosition(ORDER_TYPE_BUY, newLot); } // Проверка на закрытие всех позиций по TP if(Bid >= averagePrice + TakeProfit * Point()) { CloseAllPositions(); } }
La magia del Martingale: por qué los tráders se enamoraron de Ilan
La popularidad de Ilan puede atribuirse a varios factores. En primer lugar, su funcionamiento era intuitivo incluso para los tráders principiantes. En un mercado lateral, el sistema mostraba resultados casi mágicos: cada fluctuación de precios se convertía en una fuente de beneficios. La promediación de posiciones permitía "salvar" transacciones inicialmente perdedoras, dando al tráder una sensación de invencibilidad del sistema.
Otro factor atractivo era la posibilidad de personalizar la estrategia con un conjunto mínimo de parámetros:
// Ключевые параметры советника Ilan input double StartLot = 0.01; // Начальный размер лота input double LotMultiplier = 1.5; // Множитель лота для каждой новой позиции input int GridSize = 30; // Шаг сетки в пунктах input int TakeProfit = 40; // Прибыль для закрытия всех позиций input int MaxPositions = 10; // Максимальное количество открываемых позиций
Esta sencillez de ajuste creaba una ilusión de control: un tráder podía experimentar con distintas combinaciones de parámetros y lograr resultados impresionantes con datos históricos.
Intentos de evolución: qué ha cambiado en Ilan 2.0
En Ilan 2.0, los desarrolladores intentaron resolver algunos de estos problemas. Añadieron el cálculo dinámico de los pasos de la cuadrícula en función de la volatilidad del mercado, el trabajo con varios pares de divisas y el análisis de su correlación, filtros adicionales para la apertura de posiciones y mecanismos de protección contra pérdidas excesivas.
// Динамический расчет шага сетки в Ilan 2.0 double CalculateGridStep(string symbol) { double atr = iATR(symbol, PERIOD_CURRENT, ATR_Period, 0); return atr * ATR_Multiplier; } // Защитный механизм для ограничения убытков bool EquityProtection() { double currentEquity = AccountInfoDouble(ACCOUNT_EQUITY); double maxAllowedDrawdown = AccountInfoDouble(ACCOUNT_BALANCE) * MaxDrawdownPercent / 100.0; if(AccountInfoDouble(ACCOUNT_BALANCE) - currentEquity > maxAllowedDrawdown) { CloseAllPositions(); return true; } return false; }
Estas mejoras hicieron que el sistema fuera más resistente, pero no resolvieron la falta fundamental de adaptabilidad. Ilan 2.0 seguía basándose en normas estáticas y no podía aprender de la experiencia ni adaptarse a las condiciones del mercado, en cambio constante.
Por qué los tráders siguieron recurriendo a Ilan
A pesar de las evidentes desventajas, muchos tráders siguieron usando Ilan y sus modificaciones. Esto se debe a una serie de factores psicológicos. Los que quebraban solían guardar silencio, mientras que las historias de éxito se publicitaban activamente. Los tráders se fijaban en los periodos de éxito e ignoraban las señales de advertencia. Parecía que afinando los ajustes se podían solucionar todos los problemas. Además, la estrategia de martingale activaba los mismos desencadenantes psicológicos que los juegos de azar.
Para ser justos, vale la pena señalar que en ciertas condiciones de mercado (especialmente durante los periodos de baja volatilidad y movimiento lateral), el asesor experto podría realmente funcionar de manera impresionante durante largos periodos de tiempo. El problema era que las condiciones del mercado cambiaban inevitablemente y el asesor no se adaptaba a esos cambios.
Por qué Ilan se rompía inevitablemente y vaciaba los depósitos
El verdadero problema de Ilan se desarrollaba a largo plazo. Una estrategia que funcionaba brillantemente en un mercado lateral resultó ser desastrosamente vulnerable a los movimientos de tendencia prolongados. Vamos a analizar un escenario típico de colapso.
Primero se abre la primera posición de compra. El mercado inicia entonces un movimiento bajista constante. El asesor experto añade posiciones aumentando los lotes de forma exponencial. Después de varios niveles de promediación, el tamaño de la posición llega a ser tan grande que incluso un pequeño movimiento adicional da lugar a un ajuste de márgenes.
Matemáticamente, este problema puede expresarse del siguiente modo: con una estrategia de martingale con un multiplicador de lotes de 1,5 y un lote inicial de 0,01, la décima posición consecutiva será de unos 0,57 lotes: 57 veces el lote inicial. El tamaño total de todas las posiciones abiertas será de aproximadamente 1,1 lotes, lo que para una cuenta de 1.000 $ con apalancamiento de 1:100 significará utilizar casi todo el margen disponible.
// Расчет общего размера позиций при мартингейле double totalVolume = 0; double currentLot = StartLot; for(int i = 0; i < MaxPositions; i++) { totalVolume += currentLot; currentLot *= LotMultiplier; } // При StartLot = 0.01 и LotMultiplier = 1.5 после 10 позиций // totalVolume будет около 1.1 лота!
Un problema clave era la falta de un mecanismo para determinar cuándo debía interrumpirse la estrategia de promediación. Ilan era como un jugador que no sabe cuándo parar y sigue apostando sin parar, con la esperanza de volver a ganar.
Por qué Ilan necesita la IA
Analizando los puntos fuertes y débiles de Ilan, está claro que su principal problema reside en su incapacidad para aprender y adaptarse. El asesor experto sigue las mismas reglas, independientemente de lo exitosas o desastrosas que hayan sido sus acciones anteriores.
Aquí es donde entra en escena la inteligencia artificial. ¿Y si mantuviéramos el mecanismo básico de funcionamiento de Ilan, pero añadiésemos la capacidad de analizar los resultados de nuestras acciones y ajustar nuestra estrategia? ¿Y si, en lugar de reglas rígidas, dejamos que el sistema encuentre por sí mismo los parámetros y puntos de entrada óptimos basándose en la experiencia?
Esta es la idea que subyace a nuestro proyecto de IA Ilan 3.0, en el que integramos una estrategia de promediación de eficacia comprobada con técnicas de aprendizaje automático de última generación. En la próxima sección veremos cómo la tecnología Q-learning puede implementar este concepto.
Cómo mejorará el Q-learning el asesor experto Ilan
El paso del modelo clásico de Ilan a un sistema inteligente capaz de aprender demanda un cambio fundamental en la arquitectura del asesor experto. En el corazón de Ilan 3.0 AI se encuentra el algoritmo Q-learning, una de las tecnologías más importantes en el campo del aprendizaje por refuerzo.
Los fundamentos del Q-learning en sus acciones
El aprendizaje Q se denomina así por la "función de calidad" (Quality function), que define el valor de una acción en un estado concreto. En nuestra aplicación, usamos una tabla Q, una estructura de datos que almacena las puntuaciones de cada par "estado-acción":
// Структура для Q-таблицы struct QEntry { string state; // Дискретизированное состояние рынка int action; // Действие (0-ничего, 1-покупка, 2-продажа) double value; // Q-значение }; // Глобальный массив для Q-таблицы QEntry QTable[]; int QTableSize = 0;Una característica clave del aprendizaje Q es la capacidad del sistema para aprender de la experiencia. Después de cada acción, el algoritmo recibe una recompensa (beneficio) o una penalización (pérdida) y ajusta su estimación del valor de dicha acción en una situación de mercado concreta:
// Обновление Q-значения по формуле Беллмана void UpdateQValue(string stateStr, int action, double reward, string nextStateStr, bool done) { double currentQ = GetQValue(stateStr, action); double nextMaxQ = 0; if(!done) { // Находим максимальное Q для следующего состояния nextMaxQ = GetMaxQValue(nextStateStr); } // Обновление Q-значения double newQ = currentQ + LearningRate * (reward + DiscountFactor * nextMaxQ - currentQ); // Сохранение обновленного значения SetQValue(stateStr, action, newQ); }
Esta fórmula, conocida como ecuación de Bellman, supone la piedra angular de nuestro sistema. El parámetro LearningRate determina la tasa de aprendizaje y DiscountFactor determina la importancia de las recompensas futuras en relación con las recompensas actuales.
Equilibrio entre la búsqueda de nuevas soluciones y el uso de la experiencia
Uno de los principales retos del aprendizaje por refuerzo es la necesidad de equilibrar la exploración de nuevas estrategias con la explotación de las soluciones óptimas ya conocidas. Para resolver este problema, usaremos una estrategia ε-greedy:
// Выбор действия с балансом между исследованием и использованием int SelectAction(string stateStr) { // С вероятностью epsilon выбираем случайное действие (исследование) if(MathRand() / (double)32767 < currentEpsilon) { return MathRand() % ActionCount; } // Иначе выбираем действие с максимальным Q-значением (использование) int bestAction = 0; double maxQ = GetQValue(stateStr, 0); for(int a = 1; a < ActionCount; a++) { double q = GetQValue(stateStr, a); if(q > maxQ) { maxQ = q; bestAction = a; } } return bestAction; }El parámetro currentEpsilon define la probabilidad de seleccionar una acción aleatoriamente. Su importancia disminuye con el tiempo, lo cual permite que el sistema pase de la investigación activa al uso preferente de los conocimientos acumulados:
// Уменьшение epsilon для постепенного перехода от исследования к использованию if(currentEpsilon > MinExplorationRate) currentEpsilon *= ExplorationDecay;
El órgano sensorial digital: cómo percibe el mercado un algoritmo
Para entrenar eficazmente nuestro algoritmo, es necesario "ver" el mercado, es decir, tener una representación formalizada de la situación actual. En Ilan 3.0 AI, usaremos un vector complejo de estados que incluye indicadores técnicos, métricas de posiciones abiertas y otros datos de mercado:
// Получение текущего состояния рынка для Q-обучения void GetCurrentState(string symbol, double &state[]) { ArrayResize(state, StateDimension); // Технические индикаторы double rsi = iRSI(symbol, PERIOD_CURRENT, RSI_Period, PRICE_CLOSE, 0); double cci = iCCI(symbol, PERIOD_CURRENT, CCI_Period, PRICE_TYPICAL, 0); double macd = iMACD(symbol, PERIOD_CURRENT, 12, 26, 9, PRICE_CLOSE, MODE_MAIN, 0); // Нормализация индикаторов double normalized_rsi = rsi / 100.0; double normalized_cci = (cci + 500) / 1000.0; // Метрики позиций int positions = (symbol == "EURUSD") ? euroUsdPositions : audUsdPositions; double normalized_positions = (double)positions / MaxTrades; // Расчет разницы цен double point = SymbolInfoDouble(symbol, SYMBOL_POINT); double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double avgPrice = CalculateAveragePrice(symbol); double price_diff = (currentBid - avgPrice) / (100 * point); // Заполнение вектора состояния state[0] = normalized_rsi; state[1] = normalized_cci; state[2] = normalized_positions; state[3] = price_diff; state[4] = macd / (100 * point); state[5] = AccountInfoDouble(ACCOUNT_EQUITY) / AccountInfoDouble(ACCOUNT_BALANCE); }Para trabajar con una tabla Q, deberemos discretizar los valores de estado continuos, es decir, convertirlos en una representación de cadena con un número finito de opciones:
// Преобразование состояния в строку для Q-таблицы string StateToString(double &state[]) { string stateStr = ""; for(int i = 0; i < ArraySize(state); i++) { // Округление до 2 десятичных знаков для дискретизации double discretized = MathRound(state[i] * 100) / 100.0; stateStr += DoubleToString(discretized, 2); if(i < ArraySize(state) - 1) stateStr += ","; } return stateStr; }
Este proceso de discretización permitirá al sistema generalizar la experiencia aplicándola a situaciones de mercado similares pero no idénticas.
El sistema de estímulos: el palo y la zanahoria en el mundo de la IADefinir correctamente el sistema de recompensas quizá sea el aspecto más crítico al construir un sistema eficaz de aprendizaje por refuerzo. En la IA Ilan 3.0, hemos desarrollado un sistema de estímulos multinivel que guía el desarrollo del algoritmo en la dirección deseada.
Economía de recompensas: cómo motivar a un algoritmo
Cuando las posiciones se cierran con beneficio, el sistema recibe una recompensa positiva proporcional al importe del beneficio:
// Награда при закрытии прибыльных позиций if(shouldClose) { if(ClosePositions(symbol, magic)) { if(isTraining) { double reward = profit; // Награда равна прибыли UpdateQValue(stateStr, action, reward, stateStr, true); // Статистика обучения episodeCount++; totalReward += reward; Print("Эпизод ", episodeCount, " завершен с наградой: ", reward, ". Средняя награда: ", totalReward / episodeCount); } } }Al promediar posiciones perdedoras, el sistema recibe una pequeña penalización, lo cual le anima a buscar puntos de entrada óptimos y evitar situaciones que requieran promediar:
// Штраф при усреднении позиций if(OpenPosition(symbol, ORDER_TYPE_BUY, CalculateLot(positionsCount, symbol), StopLoss, TakeProfit, magic)) { if(isTraining) { double reward = -1; // Небольшой штраф за усреднение UpdateQValue(stateStr, action, reward, stateStr, false); } }
La falta de recompensa inmediata al abrir la primera posición obliga al sistema a centrarse en los resultados a largo plazo y no en las acciones a corto plazo.
Equilibrio fino del sistema
La eficacia de un sistema de aprendizaje Q depende en gran medida del ajuste correcto de sus parámetros clave. En Ilan 3.0 AI, ofrecemos la posibilidad de configurar con precisión todos los aspectos del aprendizaje:
// Параметры обучения с подкреплением input double LearningRate = 0.01; // Скорость обучения input double DiscountFactor = 0.95; // Коэффициент дисконтирования input double ExplorationRate = 0.3; // Начальная вероятность исследования input double ExplorationDecay = 0.995; // Коэффициент уменьшения исследования input double MinExplorationRate = 0.01;// Минимальная вероятность исследования
LearningRate determina la velocidad a la que se actualizan los valores Q. Los valores altos llevan a un aprendizaje rápido pero pueden causar inestabilidad. Los valores bajos ofrecen un aprendizaje estable pero lento.
DiscountFactor determina la importancia de las futuras recompensas. Los valores más próximos a 1 hacen que el sistema busque la maximización del beneficio a largo plazo, sacrificando a veces los beneficios inmediatos.
Los parámetros de investigación controlan el equilibrio entre la búsqueda de nuevas estrategias y la explotación de soluciones óptimas conocidas. Con el tiempo, la probabilidad de exploración disminuye, lo cual permite al sistema confiar cada vez más en la experiencia acumulada.
De la teoría a la práctica: implementación
Para implantar la IA de Ilan 3.0 debemos integrar los mecanismos de aprendizaje Q con la lógica tradicional de los asesores comerciales. Un componente clave es la función de gestión comercial, que usa el aprendizaje Q para tomar decisiones:// Функция управления торговлей с использованием Q-обучения void ManagePairWithDQN(string symbol, int &positionsCount, CArrayDouble &trades, int magic, datetime &firstTradeTime) { // Получение текущих рыночных данных double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double currentAsk = SymbolInfoDouble(symbol, SYMBOL_ASK); double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Формирование текущего состояния double state[]; GetCurrentState(symbol, state); string stateStr = StateToString(state); // Выбор действия с помощью Q-таблицы int action = SelectAction(stateStr); // Преобразование действия в торговую операцию bool shouldTrade = (action > 0); ENUM_ORDER_TYPE orderType = (action == 1) ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; // Логика открытия и управления позициями if(shouldTrade) { // Логика открытия первой позиции или усреднения // ... } // Проверка необходимости закрытия позиций double profit = CalculatePositionsPnL(symbol, magic); if(profit > 0 && positionsCount > 0) { // Логика закрытия прибыльных позиций // ... } }
Almacenamiento de la experiencia del sistema
Para guardar la experiencia acumulada, implementamos un mecanismo para almacenar y cargar la tabla Q entre sesiones:
// Сохранение Q-таблицы в файл bool SaveQTable(string filename) { int handle = FileOpen(filename, FILE_WRITE|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для записи Q-таблицы: ", GetLastError()); return false; } // Запись размера таблицы FileWriteInteger(handle, QTableSize); // Запись значений for(int i = 0; i < QTableSize; i++) { FileWriteString(handle, QTable[i].state); FileWriteInteger(handle, QTable[i].action); FileWriteDouble(handle, QTable[i].value); } FileClose(handle); return true; } // Загрузка Q-таблицы из файла bool LoadQTable(string filename) { if(!FileIsExist(filename)) { Print("Файл Q-таблицы не существует: ", filename); return false; } int handle = FileOpen(filename, FILE_READ|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для чтения Q-таблицы: ", GetLastError()); return false; } // Чтение размера таблицы int size = FileReadInteger(handle); // Выделение памяти для таблицы if(size > ArraySize(QTable)) { ArrayResize(QTable, size); } // Чтение значений for(int i = 0; i < size; i++) { QTable[i].state = FileReadString(handle); QTable[i].action = FileReadInteger(handle); QTable[i].value = FileReadDouble(handle); QTableSize++; } FileClose(handle); return true; }
Echemos un vistazo a la prueba de este asesor experto. La prueba se obtiene en la simulación OHLC en un gráfico de 15 minutos, en AUDUSD y EURUSD para 2020-2025 (el símbolo principal es EURUSD, pero el asesor experto también carga AUDUSD).
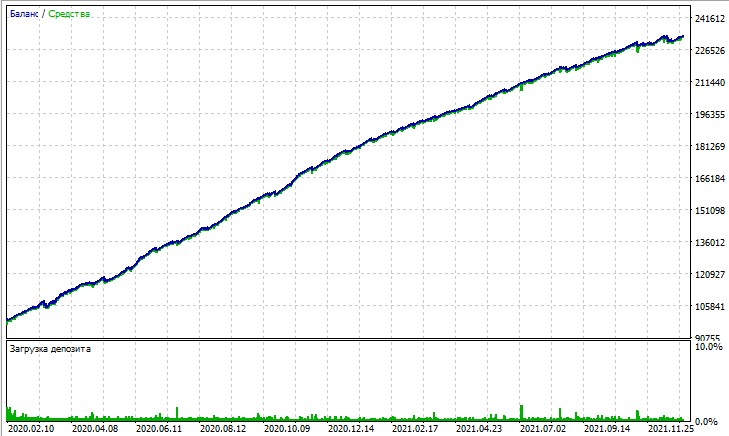
Por otro lado, la prueba de "Todos los ticks" pone claramente de manifiesto las grandes caídas que se producen debido al martingale. A pesar de las penalizaciones, el modelo cae a veces en una serie de operaciones de promediación. Quizá en futuras versiones eliminemos las reducciones con la gestión de riesgos DQN:
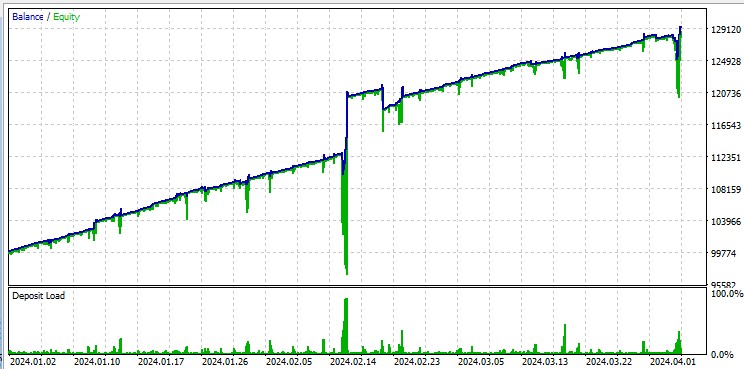
Por otra parte, vale la pena mencionar que el robot negocia grandes lotes, lo cual resulta útil para obtener reembolsos por volumen del bróker.
Formas de mejorar el algoritmo
A pesar de las importantes mejoras, la IA Ilan 3.0 supone solo el primer paso en la evolución de los sistemas comerciales inteligentes. Entre las áreas prometedoras para un mayor desarrollo se incluyen:
- Sustitución de la tabla Q por una red neuronal completa para generalizar mejor la experiencia
- Implementación de algoritmos de aprendizaje profundo por refuerzo (DQN, DDPG, PPO)
- Uso de técnicas de metaaprendizaje para adaptarse rápidamente a las nuevas condiciones del mercado.
- Integración con sistemas de análisis de noticias y datos fundamentales
Conclusión
La creación de Ilan 3.0 AI muestra un cambio fundamental en el planteamiento del trading algorítmico. Estamos pasando de sistemas estáticos basados en reglas fijas a algoritmos adaptativos capaces de aprender y evolucionar.
La integración de la estrategia clásica de Ilan con los métodos de aprendizaje automático modernos abre nuevos horizontes en el desarrollo de sistemas comerciales. En lugar de optimizar infinitamente los parámetros, creamos sistemas capaces de encontrar de manera autónoma estrategias óptimas y adaptarse a las cambiantes condiciones del mercado.
El futuro del trading algorítmico reside en enfoques híbridos que combinen estrategias comerciales probadas con técnicas innovadoras de inteligencia artificial. Ilan 3.0 AI no es solo una versión mejorada de un asesor experto clásico, sino una clase fundamentalmente nueva de sistemas comerciales inteligentes que pueden aprender, adaptarse y evolucionar con el mercado.
Estamos en el umbral de una nueva era del trading algorítmico, una era de sistemas que no se limitan a ejecutar reglas fijas, sino que evolucionan constantemente para encontrar estrategias óptimas en el siempre cambiante mundo de los mercados financieros.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17455
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¡lo he leido brevemente - a primera vista el articulo es super!
¡es necesario mirar y probar en diferentes simbolos - cuales son mejores y cuales son peores para ser entrenados por ilano!
Martin debe mucho.
Será interesante obtener un producto avanzado con una perspectiva de desarrollo.
Hola Yevgeniy
¿dónde está el código de CalculateAveragePrice(symbol)?
y también, ¿cómo puedo precalcular SL y TP de un precio medio entre 2 o más posiciones?
Gracias, Sabino.