Redes neuronales en el trading: Superpoint Transformer (SPFormer)

Introducción
La segmentación de objetos es una tarea difícil para la comprensión de escenas que tiene como objetivo no solo detectar objetos en una nube de puntos dispersa, sino también proporcionar una máscara distinta para cada objeto.
Los métodos actuales pueden dividirse en 2 grupos:
- basados en suposiciones;
- basados en la agrupación.
Los métodos basados en suposiciones abordan la segmentación de objetos 3D como un pipeline descendente. Primero generan las regiones inferidas y luego definen las máscaras de los objetos de estas regiones. Sin embargo, dichos métodos suelen resultar ineficaces debido a la dispersión de las nubes de puntos. En los campos 3D, el rectángulo delimitador posee más grados de libertad, lo que aumenta la complejidad de la aproximación. Además, los puntos suelen existir solo en partes de la superficie del objeto, lo cual hace que no se detecten los centros geométricos del objeto, mientras que las sugerencias de regiones de baja calidad afectan al emparejamiento bipartido basado en bloques y degradan aún más el rendimiento del modelo.
En cambio, los métodos basados en la agrupación usan un pipeline ascendente. Estos estudian las etiquetas semánticas puntuales y el desplazamiento del centro de instancia. A continuación, usan los puntos desplazados y las predicciones semánticas para la agregación a las instancias. Sin embargo, también existen desventajas. Estos métodos dependen de los resultados de la segmentación semántica, lo cual puede dar lugar a predicciones incorrectas. Además, el paso intermedio de agregación de datos aumenta el tiempo de entrenamiento e inferencia.
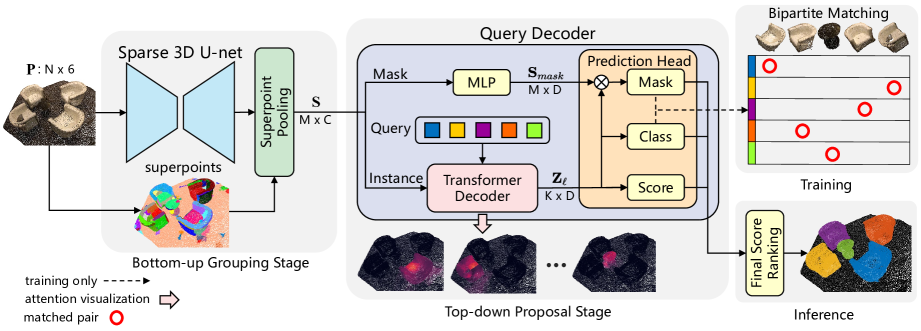
Para minimizar el impacto de estas desventajas y beneficiarse de ambos enfoques, los autores del artículo "Superpoint Transformer for 3D Scene Instance Segmentation" proponen un nuevo método de segmentación de instancias de escenas 3D en dos etapas basado en el Superpoint Transformer (SPFormer). El SPFormer agrupa objetos potenciales ascendentes a partir de nubes de puntos en Superpoints y sugiere instancias según los vectores de consulta como un pipeline descendente.
En el paso de agrupación ascendente, se usa una 3D U-net dispersa para extraer los objetos de abajo a arriba por los puntos. Se propone una sencilla capa de agrupación de puntos para agrupar los posibles objetos puntuales en superpoints. Los superpoints utilizan patrones geométricos para representar puntos vecinos homogéneos. Los objetos potenciales resultantes evitan los objetos supervisores usando etiquetas semánticas indirectas y etiquetas de distancia central. Los autores del método analizan superpoint como una representación potencial de nivel medio de una escena 3D y utilizan directamente etiquetas de instancia para entrenar el modelo completo.
En la fase de suposición de arriba a abajo, se propone un nuevo Descodificador del Transformer con solicitudes. Los autores del método usan vectores de consulta entrenados para proponer una predicción de instancias basada en posibles funciones superpoint potenciales como un pipeline descendente. El vector de consulta entrenado puede capturar información de una instancia usando el mecanismo de atención cruzada respecto a los superpoints. Con la ayuda de los vectores de consulta que contienen información sobre la instancia y la función superpoint, el descodificador de consultas generará directamente las predicciones de la clase, la puntuación y la máscara de instancia. Y con el emparejamiento bipartido basado en máscaras de superpoints, el SPFormer puede implementar el aprendizaje de extremo a extremo sin un paso de agregación que consuma mucho tiempo. Además, el SPFormer no requiere postprocesado, lo que aumenta aún más la velocidad del modelo.
1. El algoritmo de SPFormer
La arquitectura del modelo propuesto por los autores del método SPFormer se divide lógicamente en bloques. En primer lugar, se utiliza una 3D U-net dispersa para extraer objetos puntuales ascendentes. Suponiendo que la nube de puntos original tenga N puntos. Cada punto tendrá colores RGB y coordenadas XYZ. Los autores del método proponen voxelizar la nube de puntos para regularizar los datos de origen y usar una línea troncal de tipo U-net consistente en una convolución dispersa para extraer las características de los puntos P′. A diferencia de los métodos basados en la agrupación, el enfoque propuesto no añade una rama semántica adicional.
Para crear un marco completo, los autores del método SPFormer inyectan directamente las funciones de puntos P' en la capa de agrupación de superpoints basándose en los puntos precalculados. La capa del pool de superpoints simplemente recupera los objetos de S usando el promedio de puntos dentro de cada uno de los superpoints. En particular, la capa de agrupación de superpoints reduce considerablemente la discretización de la nube de puntos original, lo que disminuye significativamente el coste computacional del procesamiento posterior y optimiza las capacidades de representación del modelo completo.
El descodificador de consultas consta de dos ramas Instance y Mask. En la rama de enmascaramiento, un perceptrón multicapa simple (MLP) está destinado extraer las características que apoyen la máscara 𝐒. La rama Instance se compone de varias capas decodificadoras Transformer. Estas descodifican los vectores de consulta aprendidos usando la atención cruzada Superpoint.
Supongamos que tenemos K vectores de consulta entrenables. Predefiniremos las propiedades de los vectores de consulta para cada capa del descodificador del Transformer como Zl.
Considerando el desorden y la incertidumbre cuantitativa del superpoint, los autores del método han introducido la estructura del Transformer para procesar los datos de origen de longitud variable. La característica potencial de Superpoint y los vectores de consulta entrenados se usan como entrada para el descodificador del Transformer. En la siguiente figura se muestra la arquitectura detallada de la capa del decodificador del Transformer modificada.
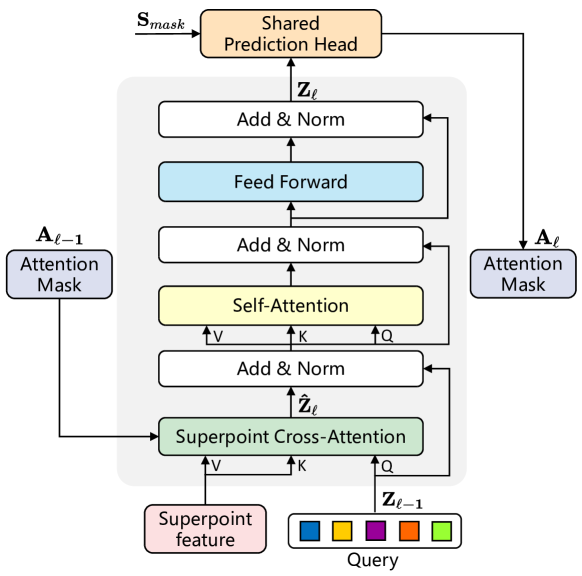
Los vectores de consulta se inicializan aleatoriamente antes del entrenamiento, mientras que la información de la instancia de cada nube de puntos solo puede obtenerse mediante la atención cruzada respecto a Superpoint. Por lo tanto, la capa del descodificador del Transformer propuesta invierte el orden de la capa de Self-Attention y la capa de Cross-Attention en comparación con el descodificador del Transformer estándar. Además, como los datos de origen suponen características potenciales de Superpoint, los autores del método han eliminado la codificación posicional.
Para captar la información contextual usando el mecanismo de atención cruzada SuperPoint, se aplican máscaras de atención Aij, que consideran la influencia de superpoint j en la solicitud i. Dadas las máscaras Superpoint de la rama Mask Ml, las máscaras de atención Superpoint Al se determinan mediante el filtro umbral τ. De manera experimental, los autores del método han establecido τ igual a 0,5.
Con las capas superpuestas del descodificador del Transformer, las máscaras de atención Superpoint Al restringen de forma adaptativa la atención cruzada en el primer plano.
A partir de los vectores de consulta Zl de la rama Instance, los autores del método usan dos MLP independientes para predecir y clasificar cada vector de consulta y evaluar la calidad de las sugerencias. Concretamente, añaden una previsión con una probabilidad "sin objeto" para asignar una credibilidad razonable a las proposiciones usando comparaciones bidireccionales y tratan las demás proposiciones como previsiones negativas.
Además, la clasificación de las frases influye mucho en los resultados de la segmentación de instancias, mientras que en la práctica la mayoría de las frases se consideran frases de fondo debido al estilo de correspondencia uno a uno, lo cual provoca incoherencias en la clasificación de calidad de las frases. Así, los autores del método desarrollan una rama de evaluación que estima la calidad de la predicción de la máscara Superpoint, lo cual permite compensar los desplazamientos.
Dada la lenta convergencia de los modelos basados en la arquitectura del Transformer, los autores del método suministran cada salida de la capa del decodificador del Transformer a la cabeza común de predicción para generar sugerencias. Durante el entrenamiento, asignan una confianza verdadera a todas las salidas de una cabeza de predicción común con distintas capas de entrada. Esto mejora el rendimiento del modelo y la función del vector de consulta, que se actualizará capa por capa.
Durante la muestra, dada una nube de puntos fuente, el SPFormer predice directamente K objetos con clasificación y las correspondientes máscaras de superpoints. Los autores del método obtienen además una puntuación de máscara promediando una probabilidad superpoint por encima de 0,5 en cada máscara. El SPFormer no posee supresión máxima en el procesamiento posterior, lo cual garantiza su alta velocidad de muestra.
A continuación le presentamos la visualización del autor del método SPFormer.
2. Implementación con MQL5
Tras repasar los aspectos teóricos del método SPFormer, como es habitual, abordaremos la parte práctica de nuestro artículo, donde implementaremos nuestra visión de los enfoques propuestos utilizando las herramientas de MQL5. Y debemos decir que hoy tenemos mucho trabajo por hacer. Así que iremos directamente al grano.
2.1 Incorporación de un programa OpenCL
Empezaremos nuestro trabajo modernizando nuestro programa OpenCL. Los autores del método SPFormer proponen un nuevo algoritmo de enmascaramiento basado en máscaras de objetos predichas. La esencia de este sistema consiste en emparejar las consultas individuales solo con superpoints pertinentes. Esto resulta muy diferente del enfoque basado en la posición de los datos de entrada que usamos anteriormente y que propusimos en el Transformer vainilla. Por consiguiente, tendremos que construir nuevos kernels de Cross-Attention y de pasada inversa. Primero implementaremos el kernel de pasada directa MHMaskAttentionOut, cuyo algoritmo tomará prestado gran parte del kernel del método vainilla. Sin embargo, realizaremos modificaciones para aplicar el nuevo algoritmo de enmascaramiento.
En los parámetros del kernel obtendremos los punteros a los búferes globales de las entidades Query, Key y Value cuyo valor se ha generado anteriormente. Los punteros a las búferes de atención y de resultados también aparecerán allí. Además, añadiremos un puntero al búfer de enmascaramiento global y un valor de umbral de enmascaramiento.
__kernel void MHMaskAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global const float *mask, ///<[in] Mask Matrix __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const float mask_level ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
Al igual que antes, planeamos llamar el kernel en un espacio de tareas tridimensional (Query, Key, Heads). Al hacerlo, crearemos grupos de trabajo locales que nos permitirán compartir datos entre flujos de ejecución Query individuales por cabezas de atención. En el cuerpo del método, identificaremos directamente el flujo actual de transacciones en el espacio de tareas y definiremos inmediatamente los parámetros del espacio de tareas.
En el siguiente paso, determinaremos los desplazamientos en los búferes de datos y escribiremos los valores resultantes en las variables locales.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
Después calcularemos la máscara real del flujo actual y otras constantes auxiliares.
const bool b_mask = (mask[shift_s] < mask_level); const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
Aquí también crearemos un array en la memoria local para el intercambio de datos entre los flujos del grupo de trabajo.
__local float temp[LOCAL_ARRAY_SIZE];
A continuación, primero determinaremos la suma de los valores exponenciales de las relaciones de dependencia dentro de un mismo Query. Para ello, primero organizaremos un ciclo con el cálculo secuencial de sumas individuales y su escritura en un array de datos local.
//--- sum of exp uint count = 0; if(k < ls) { temp[k] = 0; do { if(b_mask || q_id >= (count * ls + k)) if((count * ls) < (kunits - k)) { float sum = 0; int sh_k = 2 * dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k] = temp[k] + sum; } count++; } while((count * ls + k) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
Y, a continuación, sumaremos todos los valores del array de datos local.
do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Nótese que la suma local ha calculado los valores considerando la máscara. Y ahora podremos calcular los valores normalizados de los coeficientes de atención teniendo en cuenta el enmascaramiento.
//--- score float sum = temp[0]; float sc = 0; if(b_mask || q_id >= (count * ls + k)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
Durante el cálculo de los coeficientes de atención, eliminaremos los valores de los elementos enmascarados. De ahí que sigamos usando el algoritmo vainilla para calcular los resultados del bloque de Cross-Attention.
for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
La modernización del kernel MHMaskAttentionInsideGradients de pasada inversa será menos global. Podríamos decir que es puntual. La cuestión es que la reducción a cero de los coeficientes de dependencia en el pasada anterior nos permite usar el algoritmo vainilla para distribuir el gradiente de error entre las entidades Query, Key y Value. Sin embargo, no nos permite transmitir el gradiente de error a la máscara. Por lo tanto, añadiremos un gradiente de ajuste de máscara al algoritmo vainilla.
__kernel void MHMaskAttentionInsideGradients(__global const float *q, __global float *q_g, __global const float *kv, __global float *kv_g, __global const float *mask, __global float *mask_g, __global const float *scores, __global const float *gradient, const int kunits, const int heads_kv, const float mask_level ) { ........ ........ //--- Mask's gradient for(int k = q_id; k < kunits; k += qunits) { float m = mask[shift_s + k]; if(m < mask_level) mask_g[shift_s + k] = 0; else mask_g[shift_s + k] = 1 - m; } }
Tenga en cuenta que nuestro objetivo es que las etiquetas de enmascaramiento reales sean "1". Y para las máscaras irrelevantes, resetearemos el gradiente de error a cero, ya que no tienen ningún efecto sobre el resultado del modelo.
Con esto completaremos nuestro trabajo con el programa OpenCL. Podrá leer el código completo de los nuevos kernels en el archivo adjunto.
2.2 Creación de la clase del método SPFormer
Una vez completada la actualización del programa OpenCL, comenzaremos con la parte del programa principal. Aquí, crearemos la nueva clase CNeuronSPFormer que heredará la funcionalidad básica de la capa CNeuronBaseOCL totalmente conectada. La escala de los ajustes es tan grande que no heredaremos de los bloques de atención cruzada creados anteriormente. A continuación, le mostramos la estructura de la nueva clase,
class CNeuronSPFormer : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cSPKeyValue; CLayer cMask; CArrayInt cScores; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cQKeyValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempSelfKV; CBufferFloat cTempCrossKV; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSPFormer(void) {}; ~CNeuronSPFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSPFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
En la estructura de clases presentada vemos un gran número de variables y objetos anidados cuyos nombres coinciden con los que utilizamos anteriormente al implementar varias clases de atención. Y esto no es de extrañar. Nos familiarizaremos con la funcionalidad de todos los objetos en el proceso de implementación.
Aquí cabe señalar que todos los objetos internos se declararán estáticamente, lo cual nos permitirá dejar vacíos el constructor y el destructor de la clase. La inicialización de todos los objetos heredados y declarados se realizará en el método Init. Como ya sabe, en los parámetros de este método obtenemos las constantes principales que definen inequívocamente la arquitectura del objeto creado.
bool CNeuronSPFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
En el cuerpo del método, llamaremos directamente al método homónimo de la clase padre, que inicializa los objetos y variables heredados.
Después guardaremos inmediatamente las constantes obtenidas en las variables internas de la clase.
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
Y la siguiente etapa consistirá en inicializar un pequeño MLP para generar el vector de consultas entrenadas.
//--- Init Querys CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
A continuación, crearemos un bloque de extracción de Superpoint. Aquí generaremos un bloque de 4 capas neuronales consecutivas cuya arquitectura se adaptará al tamaño de la secuencia original. Si la longitud de la secuencia a la entrada de la siguiente capa es un múltiplo de 2, utilizaremos un bloque de convolución con enlace residual que reducirá el tamaño de la secuencia en un factor de 2.
//--- Init SuperPoints for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; }
De lo contrario, utilizaremos una capa de convolución simple que analiza 2 elementos de secuencia adyacentes en incrementos de 1 elemento. De este modo, la longitud de la secuencia se reducirá en 1.
else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } }
En este paso, inicializaremos los objetos de preprocesamiento de datos. Y a continuación procederemos a inicializar las capas internas del descodificador del Transformer modificado. Para ello crearemos variables locales para el almacenamiento temporal de los punteros a los objetos y organizaremos un ciclo con el número de iteraciones igual al número dado de capas internas del decodificador.
CNeuronConvOCL *conv = NULL; CNeuronTransposeOCL *transp = NULL; for(uint l = 0; l < iLayers; l++) { //--- Cross Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 6, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 7, OpenCL, iSPWindow, iSPWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKeyValue.Add(conv)) return false; }
Aquí inicializaremos primero las capas internas de generación de entidades Query, Key y Value. En este caso, el tensor Key-Value solo se generará cuando sea necesario.
Aquí es también donde añadiremos la capa de generación de máscaras. Para ello, utilizaremos una capa de convolución que generará coeficientes de enmascaramiento para todas las consultas de cada elemento individual de la secuencia de Superpoint. Y como estamos utilizando un algoritmo de atención multicabeza, generaremos coeficientes para cada cabezal de atención. Para normalizar los valores, utilizaremos la función de activación sigmoidal.
//--- Mask conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 8, OpenCL, iSPWindow, iSPWindow, iUnits * iHeads, iSPUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cMask.Add(conv)) return false;
Aquí debemos señalar que, al ejecutar la atención cruzada, necesitaremos los coeficientes de atención de las consultas a Superpoint. Por ello, realizaremos una transposición del tensor de enmascaramiento resultante.
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, l * 14 + 9, OpenCL, iSPUnits, iUnits * iHeads, optimization, iBatch)) return false; if(!cMask.Add(transp)) return false;
Y el siguiente paso consistirá en preparar los objetos para registrar los resultados de la atención cruzada. Primero, multicabeza.
//--- MH Cross Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 10, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false;
Y luego de valores comprimidos.
//--- Cross Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 11, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false;
Después añadiremos una capa para sumar con los datos de origen.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 12, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
A continuación tenemos el bloque de Self-Attention. Aquí también generaremos entidades Query, Key y Value, pero ya sobre los resultados de la atención cruzada.
//--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+13, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+14, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKeyValue.Add(conv)) return false; }
Y añadiremos los objetos para registrar los resultados de la atención multicabeza y los valores comprimidos.
//--- MH Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 15, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; //--- Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 16, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false;
Luego añadiremos una capa de suma con los resultados de la atención cruzada.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 17, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
Y añadiremos un bloque FeedForward con un enlace residual.
//--- FeedForward conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 18, OpenCL, iWindow, iWindow, iWindow * 4, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 19, OpenCL, iWindow * 4, iWindow * 4, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; //--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 20, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; if(!base.SetGradient(conv.getGradient())) return false;
Obsérvese que para evitar transacciones innecesarias de copiado de datos, combinaremos las búferes de gradiente de error de la última capa del bloque FeedForward y de la capa de enlace residual. Después realizaremos una operación similar para el búfer de resultados y los gradientes de error de nivel superior en la última capa interna.
if(l == (iLayers - 1)) { if(!SetGradient(conv.getGradient())) return false; if(!SetOutput(base.getOutput())) return false; } }
Cabe señalar que, durante el proceso de inicialización del objeto, no crearemos el búfer de datos del coeficiente de atención. Hemos colocado su creación, así como la inicialización de los objetos internos en un método separado.
//--- SetOpenCL(OpenCL); //--- return true; }
Tras inicializar los objetos internos, pasaremos a construir los métodos de pasada directa. El algoritmo con los métodos de llamada a los kernels creados anteriormente quedará para el estudio individual por parte del lector, ya que no hay mucha novedad en ellos. Nos centraremos únicamente en el algoritmo del método feedForward de nivel superior, donde construiremos una secuencia clara de acciones del algoritmo SPFormer.
bool CNeuronSPFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *superpoints = NeuronOCL; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = NULL, *kv_self = NULL;
En los parámetros del método, obtendremos el puntero al objeto de datos de origen. Y en el cuerpo del método declararemos una serie de variables locales para almacenar temporalmente los punteros a los objetos.
A continuación, pasaremos los datos de origen obtenidos por el modelo de extracción Superpoint.
//--- Superpoints for(int l = 0; l < cSuperPoints.Total(); l++) { neuron = cSuperPoints[l]; if(!neuron || !neuron.FeedForward(superpoints)) return false; superpoints = neuron; }
Y generaremos un vector de consultas.
//--- Query neuron = cQuery[1]; if(!neuron || !neuron.FeedForward(cQuery[0])) return false;
Con esto completaremos el trabajo preparatorio y crearemos el ciclo de iteración de las capas neuronales internas de nuestro descodificador.
inputs = neuron; for(uint l = 0; l < iLayers; l++) { //--- Cross Attentionn q = cQuery[l * 2 + 2]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !kv_cross.FeedForward(superpoints)) return false; }
Aquí prepararemos primero las entidades Query, Key y Value.
Luego generaremos las máscaras.
neuron = cMask[l * 2]; if(!neuron || !neuron.FeedForward(superpoints)) return false; neuron = cMask[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cMask[l * 2])) return false;
Y ejecutaremos el algoritmo de atención cruzada considerando el enmascaramiento.
if(!AttentionOut(q, kv_cross, cScores[l * 2], cMHCrossAttentionOut[l], neuron, iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Después reduciremos los resultados de la atención multicabeza al tamaño del tensor de consulta.
neuron = cCrossAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHCrossAttentionOut[l])) return false;
A continuación, realizaremos la suma y normalización de los datos de los dos flujos de información.
q = inputs; inputs = cResidual[l * 3]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Detrás del bloque Cross-Attention, construiremos el algoritmo de Self-Attention. Aquí volveremos a generar entidades Query, Key y Value, pero ya basándonos en los resultados de la atención cruzada.
//--- Self-Attention q = cQuery[l * 2 + 3]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !kv_self.FeedForward(inputs)) return false; }
En esta fase no se utilizará enmascaramiento. Por lo tanto, al llamar al método de atención, especificaremos NULL en lugar del objeto de máscaras.
if(!AttentionOut(q, kv_self, cScores[l * 2 + 1], cMHSelfAttentionOut[l], NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Luego reduciremos los resultados de la atención multicabeza al tamaño del tensor de consulta.
neuron = cSelfAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHSelfAttentionOut[l])) return false;
Y realizaremos la suma con el vector de resultados de atención cruzada y normalizaremos los datos.
q = inputs; inputs = cResidual[l * 3 + 1]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
A continuación, de forma similar al Transformer vainilla, efectuaremos la transferencia de datos a través del bloque FeedForward. Después pasaremos a la siguiente iteración del ciclo de capas internas.
//--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(inputs)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; q = inputs; inputs = cResidual[l * 3 + 2]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; } //--- return true; }
Observe que antes de pasar a la siguiente iteración del ciclo, almacenaremos un puntero al último objeto de la capa interna actual en la variable inputs.
Una vez ejecutadas con éxito todas las iteraciones del ciclo de enumeración de las capas internas del descodificador, devolveremos el resultado lógico de las transacciones del método al programa que realiza la llamada.
A continuación construiremos los métodos de pasada inversa. Y lo que más nos interesa es el método de distribución del gradiente de error a todos los elementos de nuestro modelo según su influencia en el resultado global del modelo calcInputGradients.
bool CNeuronSPFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
En los parámetros del método, obtendremos el puntero al objeto de la capa neuronal anterior que nos ha dado los datos de origen en la pasada directa. Y ahora tendremos que pasarle el gradiente de error de acuerdo con la influencia de los datos de origen en el resultado del modelo.
En el cuerpo del método comprobaremos directamente la relevancia del puntero obtenido, porque de lo contrario todo el trabajo posterior del método carecerá de sentido.
A continuación, declararemos una serie de variables locales para almacenar temporalmente los punteros a los objetos.
CNeuronBaseOCL *superpoints = cSuperPoints[cSuperPoints.Total() - 1]; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = cSPKeyValue[cSPKeyValue.Total() - 1], *kv_self = cQKeyValue[cQKeyValue.Total() - 1];
Luego restableceremos los búferes de almacenamiento temporal de los datos intermedios.
if(!cTempSP.Fill(0) || !cTempSelfKV.Fill(0) || !cTempCrossKV.Fill(0)) return false;
Y organizaremos un ciclo inverso de capas internas de nuestro decodificador.
for(int l = int(iLayers - 1); l >= 0; l--) { //--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
Como recordará, al inicializar el objeto de clase, sustituimos los punteros por los búferes de datos de gradiente de error de nivel superior y la capa de enlace residual con la última capa del bloque FeedForward. Esto nos permite iniciar la distribución del gradiente de error desde el bloque FeedForward en esta etapa, obviando la transferencia de datos desde el búfer de gradiente de error de nivel superior y desde la capa de enlace residual a la última capa del bloque FeedForward.
A continuación, descenderemos el gradiente de error hasta la capa de enlace residual del bloque de Self-Attention.
neuron = cResidual[l * 3 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
Luego sumaremos el gradiente de error de los dos flujos de información y lo transmitiremos a la capa de resultados de Self-Attention.
if(!SumAndNormilize(((CNeuronBaseOCL*)cResidual[l * 3 + 2]).getGradient(), neuron.getGradient(), ((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Después distribuiremos el gradiente de error resultante entre las cabezas de atención.
//--- Self-Attention neuron = cMHSelfAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cSelfAttentionOut[l])) return false;
Y obtendremos los punteros a los búferes de las entidades Query, Key y Value del bloque Self-Attention. Y de ser necesario, pondremos a cero el búfer de acumulación de valores intermedios.
q = cQuery[l * 2 + 3]; if(((l + 1) % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !cTempSelfKV.Fill(0)) return false; }
Y les transmitiremos el gradiente de error según la influencia del resultado del modelo.
if(!AttentionInsideGradients(q, kv_self, cScores[l * 2 + 1], neuron, NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Aquí vale la pena recordar que hemos contemplado la posibilidad de utilizar un tensor Key-Value para varias capas internas del descodificador. Por ello, dependiendo del índice de la capa interna actual, sumaremos el valor resultante con el gradiente de error acumulado previamente en el búfer temporal de acumulación de datos o en el búfer de gradiente de la capa Key-Value correspondiente.
if(iLayersSP > 1) { if((l % iLayersSP) == 0) { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), kv_self.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), GetPointer(cTempSelfKV), iWindowKey, false, 0, 0, 0, 1)) return false; } }
Y descenderemos el gradiente de error a la capa de enlace residual del bloque de atención cruzada. Aquí transmitiremos primero el gradiente de error de la entidad Query.
inputs = cResidual[l * 3]; if(!inputs || !inputs.calcHiddenGradients(q, NULL)) return false;
Y luego, de ser necesario, añadiremos un gradiente de error a partir del flujo de información Key-Value.
if((l % iLayersSP) == 0) { CBufferFloat *temp = inputs.getGradient(); if(!inputs.SetGradient(GetPointer(cTempQ), false)) return false; if(!inputs.calcHiddenGradients(kv_self, NULL)) return false; if(!SumAndNormilize(temp, GetPointer(cTempQ), temp, iWindow, false, 0, 0, 0, 1)) return false; if(!inputs.SetGradient(temp, false)) return false; }
A continuación, añadiremos el gradiente de error del flujo de enlace residual del bloque de Self-Attention y pasaremos el valor resultante al bloque de atención cruzada.
if(!SumAndNormilize(((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Y ahora tendremos que pasar el gradiente de error por el bloque de Cross-Attention. En primer lugar, distribuiremos el gradiente de error por las cabezas de atención.
//--- Cross Attention neuron = cMHCrossAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cCrossAttentionOut[l])) return false;
Al igual que sucede con Self-Attention, obtendremos los punteros a los objetos de las entidades Query, Key y Value.
q = cQuery[l * 2 + 2]; if(((l + 1) % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !cTempCrossKV.Fill(0)) return false; }
Y pasaremos el gradiente de error por el bloque de atención. Sin embargo, en este caso añadiremos el puntero al objeto de enmascaramiento.
if(!AttentionInsideGradients(q, kv_cross, cScores[l * 2], neuron, cMask[l * 2 + 1], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Y pasaremos el gradiente de error de la entidad Query a la anterior capa del decodificador o al vector de consulta. La elección del objeto dependerá de la capa actual del descodificador.
inputs = (l == 0 ? cQuery[1] : cResidual[l * 3 - 1]); if(!inputs.calcHiddenGradients(q, NULL)) return false;
Aquí añadiremos el gradiente de error en el flujo de información del enlace residual.
if(!SumAndNormilize(inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), inputs.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
En este punto, hemos completado la transmisión de datos a través de la línea troncal de vectores de solicitud. Sin embargo, aún tendremos que pasar el gradiente de error a la línea troncal de Superpoint. Aquí verificamos primero la necesidad de la transferencia de datos del tensor Key-Value. De ser necesario, añadiremos los valores obtenidos al búfer del gradiente de error acumulado anteriormente.
if((l % iLayersSP) == 0) { if(!superpoints.calcHiddenGradients(kv_cross, NULL)) return false; if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
Y luego distribuiremos el gradiente de error del modelo de generación de máscaras.
neuron = cMask[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cMask[l * 2 + 1]) || !DeActivation(neuron.getOutput(), neuron.getGradient(), neuron.getGradient(), neuron.Activation())) return false; if(!superpoints.calcHiddenGradients(neuron, NULL)) return false;
Y así añadiremos el valor obtenido al gradiente de error acumulado anteriormente. Pero merece la pena prestar atención a la actual capa del decodificador.
if(l == 0) { if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), superpoints.getGradient(), iSPWindow, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
Si analizamos la primera capa del decodificador (en nuestro caso la última iteración del ciclo), almacenaremos el gradiente total en el búfer de la última capa del modelo Superpoint. En caso contrario, acumularemos el gradiente de error en el búfer de almacenamiento temporal de datos.
Y pasaremos a la siguiente iteración de nuestro ciclo de iteración inversa de las capas internas del decodificador.
Después de pasar con éxito el gradiente de error por todas las capas internas del descodificador del Transformer, nos quedará distribuir el gradiente de error por las capas del modelo Supperpoint. Aquí tenemos la estructura lineal del modelo. Por consiguiente, nos bastará con organizar un ciclo de iteración inversa de las capas del modelo especificado.
for(int l = cSuperPoints.Total() - 2; l >= 0; l--) { superpoints = cSuperPoints[l]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[l + 1])) return false; }
Al final de las transacciones del método, pasaremos el gradiente de error a la capa de datos de origen desde el modelo Superpoint y devolveremos el resultado lógico de las transacciones del método al programa que realiza la llamada.
if(!NeuronOCL.calcHiddenGradients(superpoints, NULL)) return false; //--- return true; }
En esta fase, aplicaremos el proceso de distribución del gradiente de error a todos los objetos internos y los datos de entrada en función de su influencia en el resultado global del modelo. Y luego deberemos optimizar los parámetros entrenados del modelo para minimizar el error global. Estas transacciones se realizarán en el método updateInputWeights.
Aquí vale la pena decir que todos los parámetros entrenados del modelo se almacenarán en objetos internos de nuestra clase. Y que su algoritmo de optimización ya estará implementado en estos objetos. Por lo tanto, dentro del método de actualización de parámetros, solo tendremos que llamar a los métodos homónimos de los objetos anidados uno por uno. Le sugiero que se familiarice con el algoritmo de este método. Permítame recordarle que el código completo de nuestra nueva clase y todos sus parámetros se pueden encontrar en el archivo adjunto.
La arquitectura de los modelos entrenados, así como todos sus programas de entrenamiento y su interacción con el entorno, se han tomado al completo de artículos anteriores. Solo hemos realizado modificaciones puntuales en la arquitectura del modelo de Codificador. Le sugiero que se familiarice con ellos. El código completo de todas las clases de programas usados en la elaboración de este artículo figura en el anexo. Vamos a pasar ahora a la fase final de nuestro trabajo: el entrenamiento de los modelos y la prueba de los resultados obtenidos.
3. Simulación
Como parte de este artículo, hemos realizado una gran cantidad de trabajo para implementar nuestra visión de los enfoques propuestos por los autores del método SPFormer. Y ahora llegamos a la fase del entrenamiento de los modelos y la prueba de la política del Actor resultante con datos históricos reales.
Para entrenar los modelos, utilizaremos datos históricos reales del instrumento EURUSD para todo el año 2023, con el marco temporal H1. Los parámetros de todos los indicadores analizados se han usado por defecto.
El algoritmo para entrenar los modelos se ha tomado prestado de artículos anteriores, junto con los programas utilizados para entrenarlos y probarlos.
La prueba de la política del Actor entrenada se ha llevado a cabo en el simulador de estrategias de MetaTrader 5 con datos históricos reales para enero de 2024 con todos los demás parámetros conservados. Ahora le presentamos los resultados de las mismas.
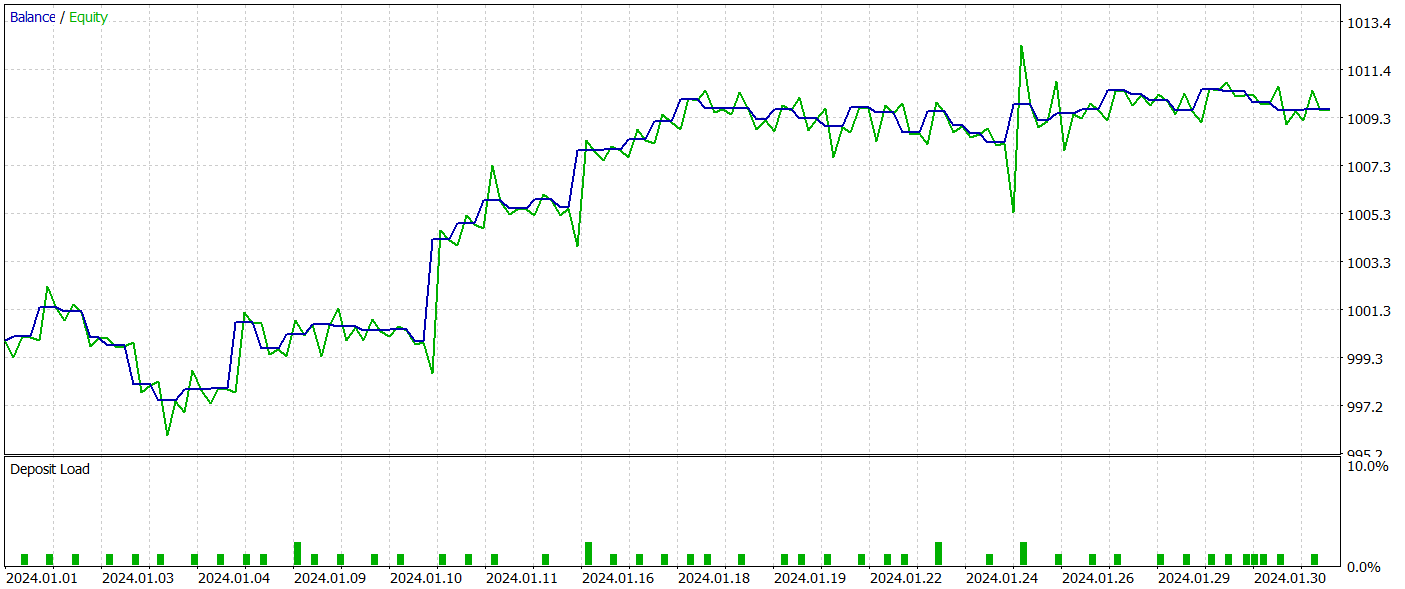
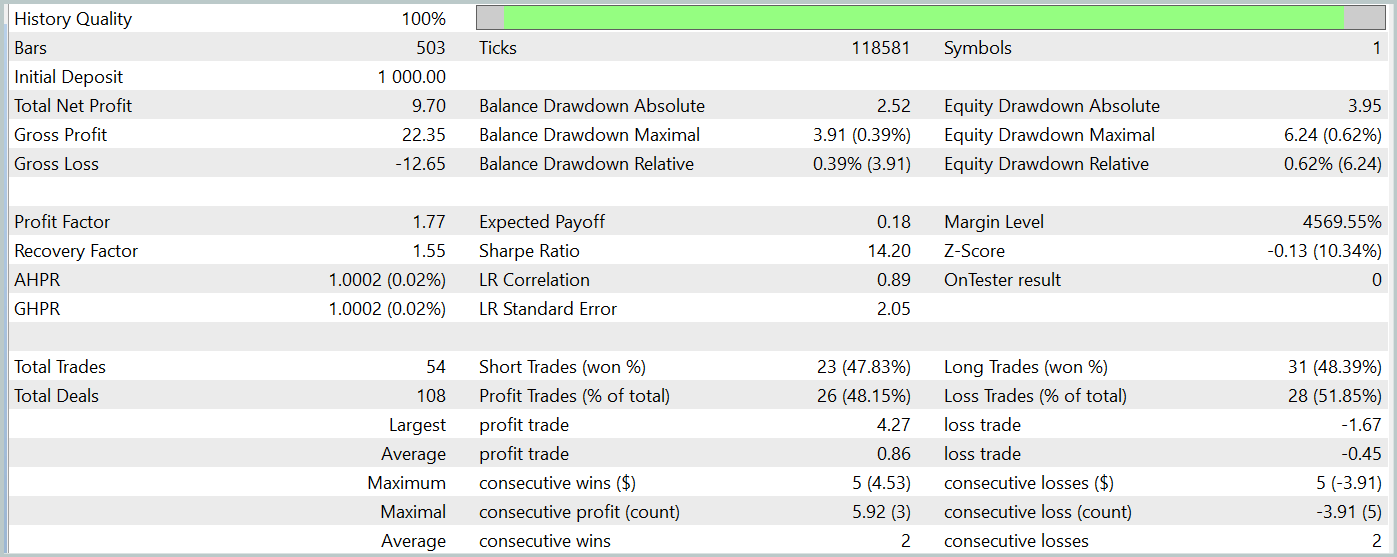
Durante el periodo de prueba, el modelo ha realizado 54 transacciones, 26 de las cuales se han cerrado con beneficios, lo cual supone el 48% de todas las transacciones. Al mismo tiempo, la media de transacciones rentables es 2 veces superior al mismo indicador de transacciones perdedoras. Esto ha permitido que el modelo obtenga beneficios durante el periodo de prueba.
Sin embargo, debemos señalar que el reducido número de transacciones comerciales realizadas durante el periodo de prueba no nos permite juzgar sobre el funcionamiento estable del modelo durante un periodo de tiempo más largo.
Conclusión
El método SPFormer puede adaptarse a aplicaciones comerciales, especialmente para segmentar datos de mercado actuales y predecir señales de mercado. En lugar de los modelos tradicionales, que a menudo dependen de pasos intermedios y pueden perder precisión debido a los datos ruidosos, este enfoque podría trabajar directamente con los datos de Superpoint. En este caso, el uso de transformadores para predecir patrones de mercado evitará la necesidad de complejos procesamientos intermedios y aumentará tanto la precisión como la rapidez de las decisiones comerciales.
En la parte práctica, hemos presentado nuestra visión de la aplicación de los enfoques propuestos mediante MQL5. Asimismo, hemos entrenado los modelos utilizando los enfoques propuestos y hemos probado su rendimiento con datos históricos reales. Según los resultados de las pruebas, el modelo ha sido capaz de obtener beneficios, lo cual indica el potencial del uso de los planteamientos descritos. Sin embargo, en este artículo solo presentamos ciertos programas para mostrar una determinada tecnología. Antes de utilizar el modelo en los mercados reales, deberá entrenarlo en un horizonte temporal más largo con pruebas exhaustivas.
Referencias Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15928
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 HTTP y Connexus (Parte 2): Comprensión de la arquitectura HTTP y el diseño de bibliotecas
HTTP y Connexus (Parte 2): Comprensión de la arquitectura HTTP y el diseño de bibliotecas
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¡Amigo esto es muy interesante pero muy avanzado para mi!
Gracias por compartir, aprender paso a paso.