
Redes neuronales en el trading: Segmentación guiada (Final)

Introducción
En el artículo anterior nos familiarizamos con el método RefMask3D, desarrollado para realizar un análisis exhaustivo de la interacción multimodal y comprender las características de la nube de puntos considerada. RefMask3D es un marco completo que incluye varios módulos:
- Un Codificador de puntos con módulo integrado Geometry-Enhanced Group-Word Attention. En este se realiza una atención intermodal entre la descripción en lenguaje natural de un objeto y los grupos locales de puntos (subnubes) en cada etapa de su codificación de características. La arquitectura de bloques propuesta por los autores del método reduce el impacto del ruido inherente a la correlación directa entre puntos y palabras, y convierte las relaciones geométricas internas en una estructura fina de nube de puntos. Todo ello mejora sustancialmente la capacidad del modelo para interactuar con datos lingüísticos y geométricos.
- El modelo lingüístico transforma la descripción textual resultante del objeto de destino en una estructura de tokens usada por el modelo para identificar el objeto.
- Un conjunto de primitivas lingüísticas entrenable (Linguistic Primitives Construction — LPC), diseñado para representar diversos atributos semánticos como la forma, el color, el tamaño, la relación, la ubicación, etc. Al interactuar con determinada información lingüística, estas primitivas son capaces de adquirir atributos relevantes.
- El Descodificador, que usa la arquitectura del Transformer, mejora el enfoque del modelo en la semántica diversa de la nube de puntos, mejorando así significativamente la capacidad de localizar e identificar con precisión el objeto de destino.
- El módulo de clúster de objetos (Object Cluster Module — OCM) realiza las funciones de recopilación de información holística y generación de incorporaciones de objetos.
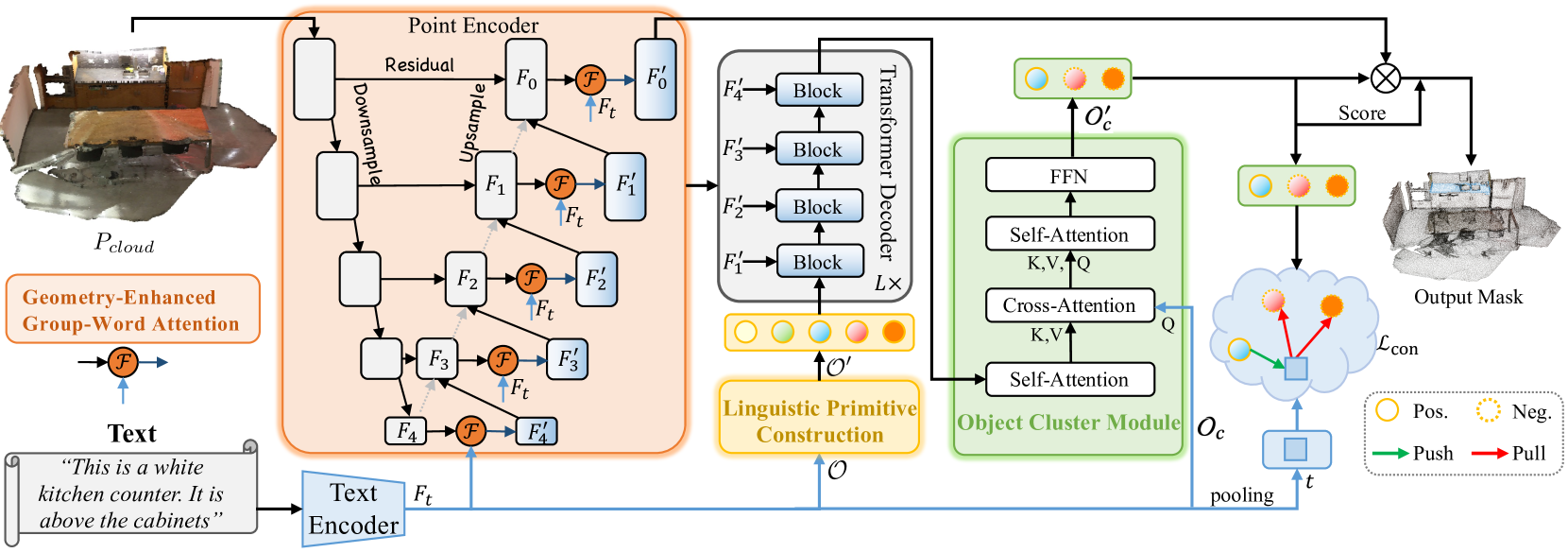
En el artículo anterior, realizamos gran parte del trabajo de aplicación del marco propuesto. En concreto, implementamos el algoritmo de los módulos Geometry-Enhanced Group-Word Attention y Linguistic Primitives Construction en sus respectivas clases. También comentamos que la funcionalidad del descodificador puede abarcarse con los desarrollos existentes de varias implementaciones de bloques de atención cruzada. Y nos detuvimos en la construcción de los algoritmos del módulo de clúster de objetos. Este es el punto a partir del cual proseguiremos.
1. Implementación del módulo de clúster de objetos
Como ya hemos mencionado, el módulo de clúster de objetos está diseñado para recopilar información holística y generar incorporaciones de objetos. A continuación le mostramos la visualización del módulo realizada por el autor.
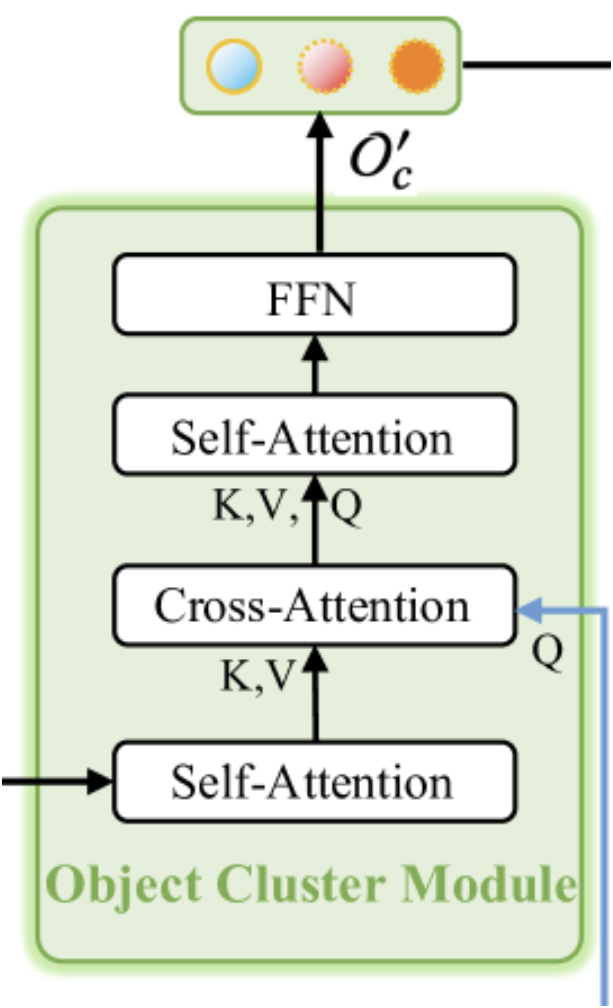
Como podemos observar en la visualización presentada, el módulo de clúster de objetos consta de dos bloques de Self-Attention, uno de Cross-Attention entre ellos, y un bloque FFN en la salida, que será un MLP totalmente conectado. Este tipo de arquitectura modular puede evocar diferentes asociaciones. Por un lado, se parece al Descodificador del Transformer vainilla con un bloque adicional de Self-Attention después del bloque de Cross-Attention. Pero aquí deberemos prestar atención a la funcionalidad modificada del bloque de atención cruzada. Y entonces se me ocurre el método SPFormer. En esta interpretación, el primer bloque de Self-Attention realiza la funcionalidad del módulo de extracción de características puntuales.
Sin embargo, también podemos encontrar una copia en miniatura del Transformer vainilla en la arquitectura presentada. Aquí tenemos una copia "despojada" del codificador, sin el bloque FeedForward, y un decodificador con los bloques de Cross-Attention y Self-Attention reorganizados. Sin duda, esto hace que este módulo sea complejo e importante en el marco general de RefMask3D, lo cual confirman los experimentos realizados por los autores del método. La aplicación del módulo de clúster de objetos mejora la eficacia del modelo en un 1,57%.
La entrada del módulo de clúster de objetos recibe datos de dos fuentes. Inicialmente, los resultados del Decodificador, que son incorporaciones de primitivas enriquecidas con información sobre la nube de puntos analizada, pasan por el primer bloque de Self-Attention y sirven de contexto para el bloque de atención cruzada posterior. La principal fuente de información para el bloque de atención cruzada son las incorporaciones de la descripción textual del objeto de destino. Precisamente sobre su base se forman las entidades Query del bloque de atención cruzada. Y además, los resultados del bloque de Cross-Attention se introducen en el segundo de Self-Attention y FeedForward.
Implementaremos el algoritmo descrito anteriormente en la clase CNeuronOCM, cuya estructura se muestra a continuación.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
Heredamos la funcionalidad básica de la capa neuronal de la CNeuronBaseOCL totalmente conectada que usamos como clase padre.
En la nueva estructura de clases presentada anteriormente, podemos observar el conjunto ya familiar de métodos redefinidos y una serie de objetos y variables internos declarados. Nos familiarizaremos con su funcionalidad durante la implementación de los métodos de la clase. Ahora vale la pena señalar que todos los objetos internos han sido declarados como estáticos, lo que significa que podremos dejar el constructor y el destructor de la clase vacíos. La inicialización de todos los objetos internos declarados y heredados se realizará en el método Init. Como ya sabrá, en los parámetros del método especificado obtendremos un conjunto de constantes que nos permitirán interpretar sin ambigüedades la arquitectura del objeto creado.
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
En el cuerpo del método, por tradición, primero llamaremos al método homónimo de la clase padre, que implementará los algoritmos de control mínimo necesario de los parámetros recibidos y de inicialización de los objetos heredados. Y controlaremos la ejecución de las operaciones del método de la clase padre según el valor lógico retornado.
Una vez ejecutadas con éxito las operaciones de los métodos de la clase padre, almacenaremos los valores de las constantes obtenidas en las variables internas de nuestra clase.
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
Y limpiaremos los arrays dinámicos de objetos internos.
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
Luego inicializaremos los objetos de los bloques internos. Según el algoritmo descrito anteriormente, el primer bloque será el bloque de Self-Attention, del análisis de dependencias entre primitivas.
Aquí quiero recordar que a la entrada del módulo recibiremos primitivas que han sido enriquecidas con información sobre la nube de puntos analizada en el Decodificador. Por ello, la tarea de este bloque consistirá en identificar las primitivas relevantes para la nube de puntos analizada.
Primero crearemos los objetos de generación de entidades Query, Key y Value. Después usaremos capas de convolución con parámetros idénticos para generar todas las entidades. Los punteros a los objetos inicializados los añadiremos a los arrays dinámicos denominados en consonancia con las entidades generadas.
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
A continuación, añadiremos una capa completamente conectada para registrar los resultados de la atención multicabeza.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Y utilizaremos la capa de convolución para escalar los resultados de la atención multicabeza al tamaño del tensor de datos de origen.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Y completando el bloque de Self-Attention habrá una capa totalmente conectada de enlaces residuales.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Resulta fácil ver que la estructura de los objetos del bloque de atención presentada anteriormente es universal. Y puede usarse tanto para el bloque de Self-Attention como para el bloque de Cross-Attention. A mi parecer, resulta obvio que para implementar el algoritmo del siguiente bloque de Cross-Attention crearemos objetos similares y añadiremos punteros a ellos en los mismos arrays dinámicos. La única diferencia estará en las fuentes de datos para formar las entidades Query, Key y Value. Al formar una entidad Query, usaremos como entrada la información de contexto.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
Mientras que los resultados del bloque de Self-Attention precedente se usarán para formar las entidades Key y Value. Aquí tendremos un tamaño de tensor idéntico al de las primitivas entrenadas.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
A continuación, añadiremos una capa de resultados de atención múltiple.
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Luego añadiremos una capa convolucional de escalado.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Y completando el bloque de Cross-Attention habrá una capa de enlaces residuales.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
El siguiente paso consistirá en crear otro bloque de Self-Attention. Esta vez analizando las dependencias contextuales. Aquí repetiremos de nuevo la creación de objetos similares del bloque de atención, con punteros a los objetos creados añadidos a los mismos arrays dinámicos. Solo que ahora todas las entidades se forman en función de los resultados del bloque de atención cruzada. Por lo tanto, el tensor de datos inicial tendrá la dimensionalidad del contexto analizado.
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Luego añadiremos una capa de resultados de atención multicabeza.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Seguida de una capa convolucional de escalado.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Pues bien, al final del bloque, al igual que antes, se usará una capa de enlaces residuales.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Y ahora solo nos quedará añadir los objetos del bloque FeedForward. De forma similar al Transformador vainilla, en este bloque usaremos 2 capas de convolución con activación LReLU entre ellas.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
Como capa de acoplamiento residual en este caso usaremos los búferes de nuestra clase heredados de la clase padre. Sin embargo, organizaremos el intercambio de punteros a los búferes de gradiente de error para reducir las operaciones de copiado de datos.
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Y al final del método retornaremos el resultado lógico de las operaciones al programa que realiza la llamada.
Tenga en cuenta que no hemos creado objetos de búferes de datos para registrar los coeficientes de atención. Los datos del búfer solo se crearán en el contexto de OpenCL. Y su creación se colocará en un método separado CreateBuffers, con el cual le sugiero que se familiarice en el archivo adjunto.
Una vez completado el método de inicialización de objetos, pasaremos a construir algoritmos de pasada directa que implementamos en el método feedForward. Y aquí debemos señalar que nos hemos apartado un poco del formato habitual de los métodos de pasada directa usados anteriormente. Mientras que en artículos anteriores utilizábamos el puntero a un objeto de capa neuronal como primera fuente de datos de entrada y el puntero a un búfer de datos como segunda, aquí usaremos objetos de capa neuronal en ambos casos. Sin embargo, en esta fase, tal implementación solo será posible para los objetos internos usados en la construcción de algoritmos para el funcionamiento del objeto superior de la capa neuronal. Lo cual nos parece bien.
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
En el cuerpo del método, crearemos algunas variables locales para almacenar temporalmente los punteros a los objetos de la capa neuronal. E inmediatamente en ellos escribiremos los punteros a los objetos de formación de entidades para el primer bloque de atención. Después comprobaremos la relevancia de los punteros a objetos y generaremos las entidades necesarias partiendo del tensor de primitivas obtenido del programa externo.
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
Pasaremos las entidades resultantes al bloque de atención múltiple para el análisis de dependencias.
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Luego escalaremos y resumiremos los resultados obtenidos con los datos de origen correspondientes. Después normalizaremos los resultados.
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
En la entrada del primer bloque de Self-Attention hemos suministrado las primitivas enriquecidas con información sobre la nube de puntos analizada. Y añadido las dependencias internas en el cuerpo del bloque. De este modo queremos contrastar las primitivas relevantes para el escenario analizado. En esencia, este paso puede compararse con la realización de una tarea de segmentación de nubes de puntos. Pero en este caso, nuestra tarea consistirá en encontrar el objeto de destino descrito por la expresión textual. Por lo tanto, pasaremos a la siguiente fase de atención cruzada, donde compararemos las incorporaciones de la descripción del objeto de destino y las primitivas inherentes a la nube de puntos analizada. Para ello, tomaremos las capas neuronales de formación de entidades de atención cruzada de nuestros arrays de objetos. Comprobaremos si los punteros recibidos están actualizados. Y generaremos las entidades que necesitamos.
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
No olvide que Query se generará a partir de las incorporaciones de la descripción del objeto de destino. Los resultados del bloque anterior de Self-Attention servirán como datos de entrada para la formación de Key y Value. Luego usaremos el mecanismo de la atención múltiple.
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
A continuación, escalaremos los resultados obtenidos y los complementaremos con enlaces residuales.
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Cabe señalar que como enlaces residuales usaremos el tensor del contexto original. Luego normalizaremos los resultados de la suma de los dos tensores en términos de los elementos individuales de la secuencia.
A la salida del bloque de Cross-Attention, esperamos obtener las incorporaciones de la descripción del objeto de destino enriquecidas con información de la nube de puntos analizada. En otras palabras, queremos "destacar" las incorporaciones de la descripción del objeto de destino relevantes para el escenario analizado.
Obsérvese que en este caso no compararemos directamente la nube de puntos analizada con la descripción del objeto de destino. Sin embargo, en los pasos anteriores del marco RefMask3D, realizamos la selección de primitivas en la nube de puntos original, mientras que en el bloque de atención cruzada, extraemos las primitivas encontradas en la nube de puntos de origen a partir de la descripción dada del objeto de destino. Y luego montaremos la "imagen completa" enriqueciendo las incorporaciones resaltadas con conexiones mutuas en el subsiguiente bloque de Self-Attention.
Como antes, extraeremos las siguientes capas de formación de entidades de los arrays dinámicos internos y comprobaremos la relevancia de los punteros resultantes.
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
Después generaremos las entidades Query, Key y Value. En este caso, los datos iniciales para la formación de todas las entidades serán los resultados del bloque de atención cruzada anterior.
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
También usaremos el algoritmo de atención multicabeza para detectar interdependencias en la secuencia de datos analizada.
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Luego escalaremos los resultados obtenidos y añadiremos enlaces residuales seguidos de la normalización de los datos.
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Y a continuación tendremos que pasar el tensor de contexto enriquecido por el bloque FeedForward. A los resultados obtenidos, les añadiremos enlaces residuales y luego normalizaremos los datos. Después escribiremos los valores obtenidos en el búfer de resultados de nuestra clase CNeuronOCM. Este objeto ha sido heredado de la clase padre.
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
Al final del método de pasada directa, solo tendremos que retornar el resultado lógico de las operaciones al programa que realiza la llamada.
Tras completar nuestro trabajo sobre la construcción de los métodos de pasada directa, pasaremos a organizar los procesos de pasada inversa. Como es habitual, dividiremos la funcionalidad de la pasada inversa en 2 pasos: la asignación de los gradientes de error a todos los elementos según su influencia en el rendimiento global del modelo y la optimización de los parámetros entrenados. Como consecuencia, construiremos un método diferente para cada paso: calcInputGradients y updateInputWeights. El primero invertirá completamente las operaciones de pasada directa, mientras que en el segundo, solo llamaremos secuencialmente a los métodos de los objetos internos homónimos que contienen los parámetros a entrenar. Le sugiero que se familiarice con los algoritmos de construcción de los métodos mencionados. Encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
2. Creación del marco RefMask3D
Hemos trabajado mucho en la implementación de los módulos individuales del marco RefMask3D y ahora tendremos que reunirlo todo en un único objeto, combinando los bloques individuales en una estructura bien alineada. Para ello, crearemos una nueva clase CNeuronRefMask, cuya estructura mostramos a continuación.
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
En la estructura presentada, resulta fácil observar los objetos de los módulos que hemos implementado. Pero junto a ellos también hay objetos de arrays dinámicos, con cuya funcionalidad nos familiarizaremos durante la implementación de los métodos de la nueva clase.
Todos los objetos internos se declararán estáticamente, lo que nos permitirá dejar el constructor y el destructor de la clase "vacíos". La inicialización de todos los objetos declarados y heredados, a su vez, se realizará en el método Init.
Como ya sabrá, en los parámetros de este método obtendremos las constantes que nos permitirán identificar unívocamente la arquitectura del objeto que se está creando. Sin embargo, el gran número de objetos internos complejos provocará una gran variabilidad en la arquitectura del objeto. Y, como consecuencia, aumentarán los parámetros para la descripción de estas soluciones arquitectónicas. En mi opinión, un número excesivo de parámetros solo complicará la clase. Por ello, hemos decidido unificar los parámetros de los objetos internos, lo que nos ha permitido reducir considerablemente el número de parámetros externos. Se trata de dejar en los parámetros del método de inicialización solo las constantes que definen los parámetros de los datos de origen y los resultados. Y para los objetos internos, si es posible, utilizaremos parámetros similares de los datos externos. Por ejemplo, solo especificamos el tamaño de ventana de un elemento de la secuencia para los datos de origen. Sin embargo, usaremos este parámetro tanto para generar las incorporaciones de las primitivas entrenadas como para determinar el tamaño de la incorporación contextual. Así, para construir los tensores de las primitivas y el contexto, solo tendremos que especificar los tamaños de secuencia correspondientes.
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
Como es habitual, la primera operación del cuerpo del método será la llamada al método homónimo de la clase padre, que ya implementará la funcionalidad de control mínimo necesario de los parámetros recibidos y de inicialización de los objetos heredados. A continuación procederemos a la inicialización de los objetos declarados. Y aquí inicializaremos primero el codificador de nubes de puntos en forma de módulo Geometry-Enhaced Group-Word Attention, que creamos anteriormente.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
Aquí hay dos puntos a considerar. En primer lugar, al especificar el tamaño de la secuencia contextual, añadiremos 3 elementos al tamaño de incorporación de la descripción del objeto de destino. Obviamente, al igual que en trabajos anteriores, no especificaremos una descripción textual del objeto de destino. En su lugar, generaremos varios tokens a partir del vector que describe el estado de la cuenta y las posiciones abiertas. Aquí seguiremos el mismo enfoque que en la creación de varios tokens diferentes con una descripción del estado de la cuenta; esto nos permitirá hacer un análisis exhaustivo de la situación actual del mercado. Sin embargo, no descartaremos la presencia de ruido y valores atípicos en los datos de origen. Y para eliminar su influencia, introduciremos 3 tokens entrenados adicionales para acumular valores irrelevantes. Se trata esencialmente del token "de fondo" propuesto por los autores del marco RefMask3D.
El segundo punto: en nuestro codificador de puntos usaremos bloques de atención de dos capas en todas las etapas, mientras que el parámetro de capas internas layers, obtenido a partir de un programa externo, indicará el número de incorporaciones de "cuello" de nuestro módulo en forma de U.
Asimismo, activaremos la función de suma de gradientes de error para los objetos de cuello.
A continuación viene el codificador contextual. Para este módulo, no hemos creado una cara separada. Sin embargo, usted ya conoce su arquitectura. Reproduce por completo el codificador de la expresión de referencia del método 3D-GRES. Primero crearemos una capa completamente conectada para registrar un vector de descripción del estado de la cuenta.
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Y luego añadiremos una capa completamente conectada que generará un número determinado de incorporaciones del tamaño deseado.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Aquí también añadiremos otra capa en la que escribiremos el tensor concatenado de tokens de contexto y de "fondo".
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
En el siguiente paso, crearemos un modelo de generación tensorial de tokens de fondo entrenados. Aquí también usaremos un MLP de dos capas. Su primera capa será estática y contendrá un "1", mientras que el segundo generará un tensor del tamaño deseado basándose en los parámetros entrenados.
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
A continuación, añadiremos el módulo de primitivas lingüísticas.
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
Seguido de un descodificador. Aquí nos hemos desviado ligeramente de la estructura propuesta por los autores del método y hemos sustituido las capas del decodificador del Transformer vainilla por los objetos del módulo de clúster de objetos creado anteriormente. Arriba ya hemos hablado de las similitudes y diferencias en la arquitectura de estos módulos. Así que esperamos que este enfoque nos permita mejorar un poco más la eficacia del modelo que estamos creando.
También cabe destacar que, según la estructura propuesta por los autores del marco RefMask3D, cada capa del descodificador analizará las dependencias con una capa distinta del codificador de puntos en forma de U. Para aplicar este enfoque, organizaremos un ciclo con recuperación secuencial de objetos relevantes.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
Solo nos quedará inicializar el módulo de clúster de objetos.
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
Y sustituir los punteros por búferes de datos, lo cual nos permitirá reducir el número de operaciones de copiado de valores.
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
Al final del método, retornaremos el resultado lógico de las operaciones al programa que realiza la llamada. Con esto completaremos la construcción del método de inicialización del objeto de clase y pasaremos a organizar los algoritmos de pasada inversa, que implementaremos en el método feedForward. En los parámetros de este método, obtendremos los punteros a los dos objetos de datos de origen. El primero se representará como un puntero al objeto de la capa neuronal, y el segundo como un búfer de datos. Este será el esquema para el que hemos organizado las interfaces dentro de nuestro modelo básico.
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
En el cuerpo del método, comprobaremos la relevancia del puntero obtenido a la segunda fuente de los datos de origen y, de ser necesario, realizaremos la sustitución del puntero por un búfer de resultados en la primera capa del codificador contextual.
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
A continuación, generaremos una incorporación contextual basada en los datos proporcionados.
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
Obsérvese que las operaciones de pasada directa comenzarán precisamente con la generación de la incorporación contextual. Al fin y al cabo, el codificador de puntos usará esta información como segunda fuente de datos de entrada.
A continuación, generaremos el tensor de tokens de fondo.
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
Y lo concatenaremos con el tensor de incorporación contextual.
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
El tensor concatenado lo transmitiremos a nuestro codificador de puntos junto con el puntero a la primera fuente de datos de entrada del programa externo.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
Asimismo, transmitiremos la incorporación contextual al módulo de generación de primitivas lingüísticas. Solo que en este caso usaremos un tensor sin tokens de fondo.
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
Cabe señalar que las tokens de fondo solo se usarán en el codificador de puntos para filtrar el ruido y los valores atípicos.
En esta fase, ya hemos generado los tensores de incorporación de las primitivas lingüísticas y la nube de puntos original. El siguiente paso consistirá en compararlos en nuestro descodificador, lo que ayudará a identificar las primitivas lingüísticas inherentes al escenario analizado. Aquí primero compararemos los resultados del codificador de puntos con nuestras primitivas.
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Y después enriqueceremos las incorporaciones de las primitivas lingüísticas con los resultados intermedios del codificador de puntos. Para ello, organizaremos un ciclo en el que extraeremos secuencialmente las capas subsiguientes del descodificador y los objetos correspondientes del codificador de puntos, con la posterior comparación de datos.
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
Los resultados del descodificador los pasaremos a través del módulo de clúster de objetos.
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
Después finalizaremos el método de pasada directa transmitiendo el resultado lógico de las operaciones al programa que realiza la llamada.
Vale la pena decir que el algoritmo implementado no será una copia completa del marco RefMask3D del autor. En el algoritmo del autor, también se multiplicarán los resultados del codificador de puntos por la salida del módulo de clúster de objetos con la adición de una cabeza para determinar las probabilidades de asignar un punto a un objeto concreto. Y la razón de tal "corte" del algoritmo residirá en la diferencia de los problemas a resolver. No necesitaremos resaltar visualmente los objetos individuales del escenario analizado. Para tomar una decisión sobre una operación comercial, bastará con conocer la presencia de los patrones y sus parámetros. Por lo tanto, hemos decidido aplicar el marco propuesto de esta forma. Y sus resultados serán analizados por el modelo del Actor.
Bueno, sigamos adelante. A la implementación de algoritmos de pasada directa le seguirá la construcción de los métodos para implementar los procesos de pasada inversa. Y en este caso, debemos decir unas palabras sobre el método de distribución de gradientes de error calcInputGradients. Como siempre, en él hemos invertido completamente las operaciones de pasada directa. Pero conviene señalar que en el proceso de pasada directa generamos una serie de entidades que tienen un impacto clave en el rendimiento del modelo. Entre ellas podemos mencionar las primitivas entrenables, las incorporaciones contextuales y los tokens de fondo. Y, por supuesto, nos gustaría formar la máxima variedad de estas entidades para abarcar el mayor espacio de la escenario observado de la situación del mercado. Y aunque ya hemos implementado esta funcionalidad en el módulo de generación de primitivas lingüísticas, aún debemos crearla para otras entidades. Por ello, le propongo dedicar unos minutos a repasar el algoritmo usado para construir el método de distribución del gradiente de error.
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
En los parámetros del método obtendremos los punteros a tres objetos: una capa neuronal y dos búferes de datos. Como ya sabe, el objeto de capa neural contiene los búferes para los resultados y los gradientes de error de la primera fuente. Pero para la segunda fuente de datos, obtendremos búferes separados de los datos de origen y los gradientes de error correspondientes. Aquí también hay un puntero a la función de activación de la segunda fuente de datos.
En el cuerpo del método, comprobaremos inmediatamente la pertinencia de los punteros obtenidos a la primera fuente de datos y el gradiente de error de la segunda. La ausencia de un puntero correcto al búfer de la segunda fuente de datos no será crítica para nosotros, porque guardaremos el puntero comprobado al realizar una pasada directa.
A continuación, realizaremos la sustitución para almacenar los gradientes de error en nuestro objeto interno de la segunda fuente de datos, si es necesario.
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
Aquí terminaremos el trabajo preparatorio y procederemos a las operaciones directas de distribución del gradiente de error.
Debido a la sustitución de los punteros del búfer de datos realizada durante la inicialización del objeto, el gradiente de error procedente de la capa posterior se escribirá directamente en el búfer del módulo de clúster de objetos. Por lo tanto, omitiendo la operación redundante de copiado de datos, iniciaremos las operaciones distribuyendo el gradiente de error a través del objeto OCM.
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
Nótese que en este caso estaremos pasando el gradiente a la última capa del decodificador y a la penúltima capa del codificador contextual. De hecho, la última capa del codificador contextual contendrá el tensor de incorporación concatenado de los tokens de contexto y de fondo, que solo se usará para el codificador de puntos.
A continuación, pasaremos el gradiente de error a través del descodificador. Para ello, organizaremos un ciclo inverso de enumeración de capas del descodificador.
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Nótese que pasaremos el gradiente de error a las capas internas del codificador de puntos mientras distribuimos el gradiente de error. Precisamente para almacenar estos valores implementamos antes el algoritmo de suma de gradientes de error para los objetos de cuello.
La segunda fuente de datos del decodificador será el módulo de generación de primitivas LPC. Luego distribuiremos sobre este el gradiente de error obtenido hasta el módulo interno de generación de primitivas e incorporación contextual sin tokens de fondo. Pero el último búfer ya contendrá los datos de operaciones anteriores. Por lo tanto, sustituiremos temporalmente el puntero del búfer de gradiente de incorporación contextual por un búfer no usado que heredamos de la clase padre. Y solo entonces llamaremos al método de distribución del gradiente de error del módulo LPC. Y luego sumaremos los valores de los dos búferes de datos.
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
A continuación, pasaremos el gradiente de error por el codificador de puntos. Y esta vez, distribuiremos el gradiente de error entre la primera fuente de los datos de origen y la incorporación contextual con tokens de fondo.
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
Resulta importante señalar aquí que necesitaremos realizar una diversificación conjunta de tokens de contexto y fondo. Al fin y al cabo, no es difícil adivinar que los tokens de fondo y el contexto pertenecen al mismo subespacio. Por otra parte, además de diversificar los tokens de contexto y de fondo, necesitaremos construir una distinción clara entre estas entidades. Por lo tanto, primero añadiremos un error de diversificación para el tensor concatenado de contexto y fondo.
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
Y luego distribuiremos el gradiente de error resultante entre los búferes correspondientes de las entidades especificadas. Después ajustaremos el gradiente del contexto usando la derivada de la función de activación y añadiremos los valores resultantes a los valores acumulados anteriormente. Después insertaremos el puntero al búfer de datos correspondiente. A continuación, podremos reducir el gradiente de error al nivel de la segunda fuente de datos.
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
Recordemos que ya hemos almacenado el puntero al búfer de gradiente de error en el objeto correspondiente de la capa neuronal interna. Por lo tanto, la operación de transferencia de valores entre búferes de datos se volverá redundante.
En esta fase, hemos distribuido el gradiente de error a las dos fuentes de los datos originales y a casi todos los objetos internos. "Casi" porque nos queda distribuir el gradiente de error a través del modelo de generación de tokens de fondo. Ahora corregiremos el gradiente de error obtenido anteriormente mediante la derivada de la función de activación y organizaremos un ciclo de capas MLP inverso.
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
Y al final del método de distribución del gradiente de error, devolveremos el resultado lógico de las operaciones al programa que realiza la llamada.
Con esto concluirá nuestra revisión de los algoritmos para implementar el marco RefNask3D. Podrá ver por su cuenta el código completo de todas las clases presentadas y sus métodos en el archivo adjunto. Allí encontrará también la arquitectura de los modelos entrenados y todos los programas utilizados en la elaboración de este artículo.
Solo hemos realizado modificaciones puntuales en la arquitectura de los modelos entrenados, que consisten en cambiar una capa del codificador de la descripción del estado del entorno. Los programas de interacción con el entorno y de entrenamiento de los modelos se han mantenido de trabajos anteriores y no se han modificado en absoluto. Por lo tanto, no nos detendremos a analizarlos, sino que pasaremos a la parte final de nuestro artículo: el entrenamiento de los modelos y la comprobación de los resultados.
3. Simulación
Como ya hemos mencionado, la introducción de cambios en la arquitectura de los modelos no ha modificado la estructura de los datos de entrada ni de los resultados. Y esto significa que podremos usar la muestra de entrenamiento recogida previamente para el entrenamiento inicial de los modelos. Permítame recordarle que, para entrenar los modelos, usaremos los datos históricos reales del instrumento EURUSD para todo el año 2023 en el marco temporal H1. Los parámetros de todos los indicadores analizados se han usado por defecto.
El entrenamiento de los modelos se realizará offline. Sin embargo, para mantener la muestra de entrenamiento al día, realizaremos actualizaciones periódicas de la muestra de entrenamiento con la adición de pasadas dentro de la política actual del Actor. Las iteraciones de entrenamiento de los modelos y la actualización de la muestra de entrenamiento se repetirán hasta alcanzar el resultado deseado.
Como parte de la preparación de este artículo, hemos obtenido una política del Actor bastante interesante. A continuación le presentamos los resultados de nuestras pruebas con los datos históricos de enero de 2024.
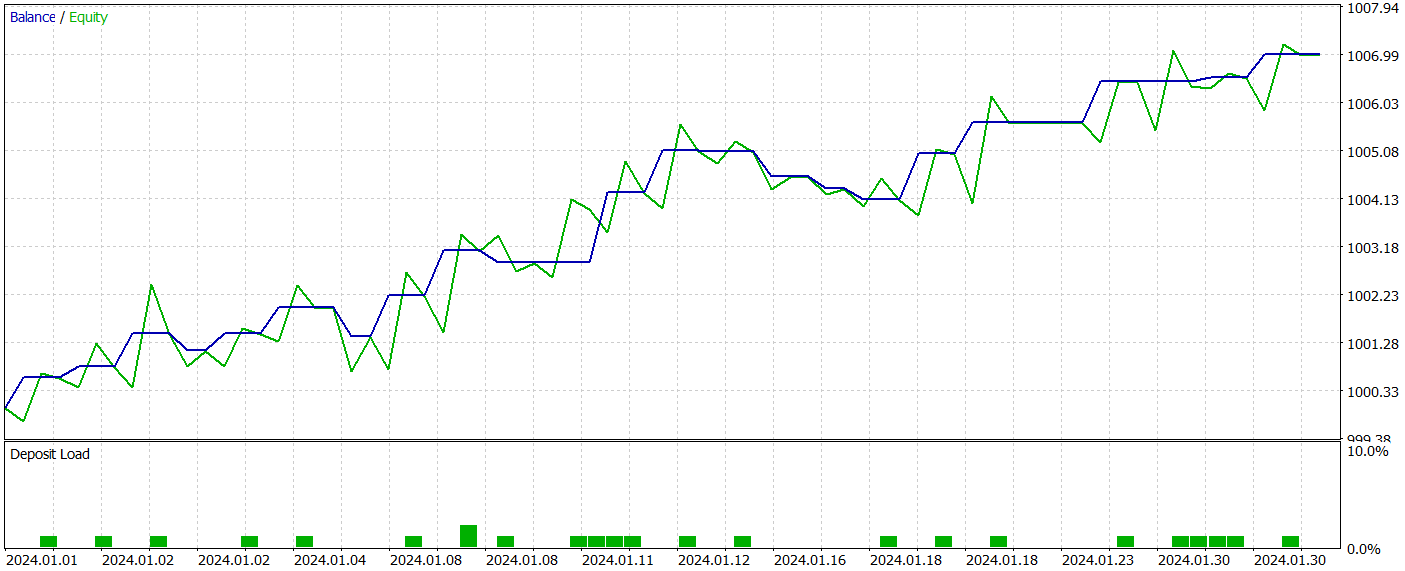
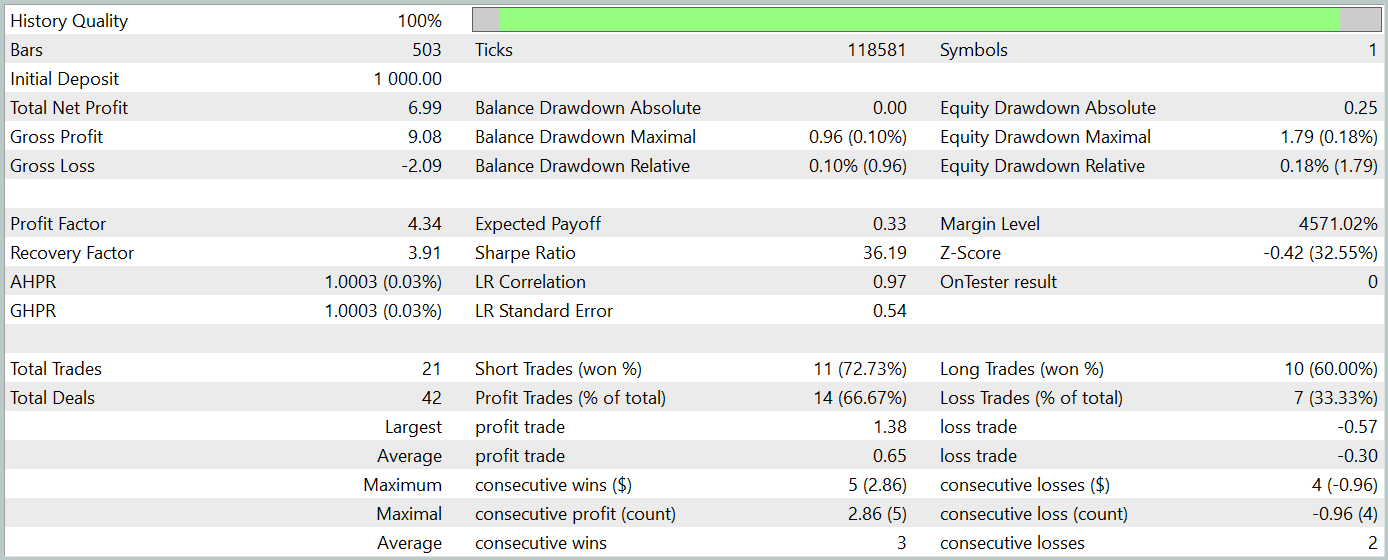
Resulta sencillo ver que el periodo de prueba no está incluido en la muestra de entrenamiento. Este método de prueba crea un entorno de condiciones lo más semejante posible al uso real del modelo.
Durante el periodo de prueba, el modelo ha realizado 21 transacciones comerciales y 14 de ellas se han cerrado con beneficio, lo que supone más del 66%. Cabe señalar que la proporción de transacciones rentables supera la proporción de transacciones perdedoras tanto para las posiciones cortas como para las largas. Además, la media de transacciones rentables es 2 veces superior a la media de transacciones perdedoras. Y el indicador similar sobre la transacción máxima rentable se acerca a la marca del triple. Al mismo tiempo, el gráfico de balance tiene una tendencia claramente definida.
Obviamente, el reducido número de transacciones comerciales realizadas no nos permite afirmar que el modelo se eficaz a largo plazo. No obstante, resulta evidente que el planteamiento propuesto tiene potencial y merece ser investigado.
Conclusión
Durante los dos últimos artículos, hemos trabajado duramente para implementar los enfoques propuestos por los autores del método RefMask3D usando herramientas MQL5. Está claro que la aplicación presentada muestra algunas desviaciones respecto al marco del autor. No obstante, los resultados obtenidos demuestran el potencial del enfoque propuesto.
Aun así, querría recordarle que todos los programas presentados en este artículo son de carácter demostrativo y no están listos para su uso en condiciones reales de mercado.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16057
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola Dmitry. Tengo este error durante el entrenamiento:
¿Qué significa?
Por cierto, al compilar aparecen estas 2 advertencias:
Los archivos del artículo no se modifican.
Excelente artículo. Voy a descargarlo y probar a utilizarlo este fin de semana. Hay dos cosas que el informe de backtest no muestra. El par de divisas utilizado y el marco temporal. ¿Puedes proporcionar esta información o hacer referencia a un artículo anterior que lo identifique? Acabo de encontrar las respuestas. Es EURUSD y H1
Viktor, he tenido el mismo memo error en Deprecated behavior. En mi caso, estaba desarrollando una clase y sin querer llamé a una función visible a la que le faltaba un parámetro pero la clase contenía los parámetros correctos. Añadiendo el parámetro se solucionó mi problema. el probram se ejecutó correctamente usando el deprecated behavior que es por lo que es un memo error.