
Redes neuronales en el trading: Segmentación guiada

Introducción
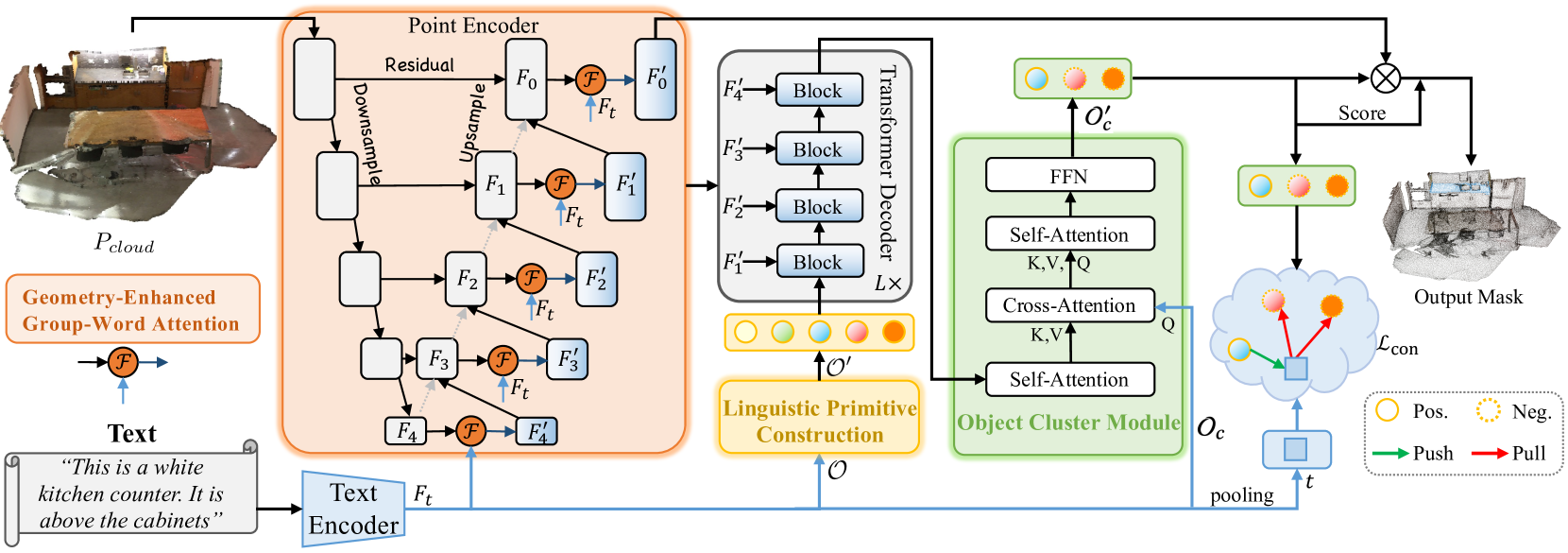
La tarea de segmentación guiada implica seleccionar de la nube puntos de región a partir de la descripción proporcionada del objeto de destino mediante lenguaje natural. Durante su solución, el modelo realiza un análisis detallado de las complejas dependencias semánticas de grano fino y construye una máscara de puntos del objeto de destino. Para resolver esta tarea, en el artículo "RefMask3D: Language-Guided Transformer for 3D Referring Segmentation" se presenta un marco integrado eficiente que hace un uso exhaustivo de la información lingüística. El método RefMask3D propuesto mejora los algoritmos de interacción y comprensión multimodal.
Los autores del método proponen usar niveles tempranos de codificación de funciones para extraer un contexto multimodal rico. Para ello, introducen el módulo Geometry-Enhanced Group-Word Attention, en el que se implementa una atención intermodal entre las descripciones en lenguaje natural de un objeto y los grupos locales de puntos (subnubes) en cada paso de su codificación de características. Esta integración no solo reduce el ruido inherente a la correlación directa entre puntos y palabras, que a menudo surge de la naturaleza dispersa e irregular de las nubes de puntos, sino que también explota las relaciones geométricas intrínsecas y la estructura fina de la nube de puntos, lo cual mejora enormemente la capacidad del modelo para interactuar con datos lingüísticos y geométricos.
Además, los autores del método añaden un token "de fondo" entrenado para evitar que las características lingüísticas irrelevantes se entremezclen con las características locales del grupo. Este enfoque garantiza que los objetos puntuales se enriquezcan con información lingüística semántica, manteniendo una conciencia continua y dependiente del contexto lingüístico relevante en cada grupo u objeto de la nube de puntos analizada.
Combinando las funciones de la visión artificial y el análisis del lenguaje natural, los autores del método desarrollan una estrategia para identificar eficazmente el objeto de destino en el descodificador, denominada Linguistic Primitives Construction (LPC). Se propone inicializar un conjunto de primitivas diversas, cada una diseñada para representar un atributo semántico diferente, como la forma, el color, el tamaño, la relación, la ubicación, etc. Al interactuar con determinada información lingüística, estas primitivas son capaces de adquirir atributos relevantes.
El uso de primitivas enriquecidas semánticamente en el descodificador mejora el enfoque del modelo en la variada semántica de la nube de puntos, mejorando así enormemente la capacidad de localizar e identificar con precisión el objeto de destino.
Para recopilar información holística y generar incorporaciones de objetos, los autores del marco RefMask3D proponen el módulo de clúster de objetos (Object Cluster Module OCM). Las primitivas lingüísticas están diseñadas para crear énfasis en determinadas partes de la nube de puntos que se correlacionan con sus atributos semánticos. No obstante, el objetivo final es identificar un objeto de destino a partir de una descripción dada. Y esto requiere una comprensión holística del lenguaje. Dicha tarea se resuelve implementando el módulo de clúster de objetos. Este módulo analiza en primer lugar las relaciones entre primitivas lingüísticas para identificar características comunes y las diferencias en sus ámbitos centrales. A partir de esta información, se inician las consultas basadas en el lenguaje natural. Así se captan las características comunes identificados que forman la incorporación final, crucial para la identificación del objeto de destino.
El módulo de clúster de objetos propuesto ayuda enormemente al modelo a profundizar en la comprensión holística de la información lingüística y visual.
1. El algoritmo RefMask3D
el método refmask3d crea una máscara de puntos del objeto de destino basándose en los resultados del análisis del escenario de la nube de puntos original y en la descripción textual de las características buscadas. El escenario analizado consta de un total de n puntos, cada uno de los cuales contiene información de coordenadas 3D P y una función auxiliar f que describe el color, la forma y otras características.
En primer lugar, se usa un codificador textual que genera incorporaciones de la descripción textual Ft. A continuación, se extraen las características de los puntos usando un codificador de puntos que construye una interacción profunda entre la forma observada y la descripción textual usando el módulo Geometry-Enhanced Group-Word Attention. El codificador de puntos supone una línea troncal similar a U-Net 3D.
El constructor de primitivas lingüísticas crea primitivas 𝒪′ para representar diversos atributos semánticos mediante claves lingüísticas informativas, lo que mejora la capacidad del modelo para localizar e identificar objetivos con precisión usando la interacción con información lingüística específica.
Las primitivas lingüísticas 𝒪′, los objetos puntuales multiescala {𝑭1′,𝑭2′,𝑭3′,𝑭4′} y las funciones lingüísticas 𝑭t constituyen los datos de entrada del Decodificador cruzado modal de cuatro capas creado mediante la arquitectura del Transformer.
Las primitivas lingüísticas enriquecidas con ayuda del Decodificador y las consultas de objetos 𝒪c se introducen en el módulo de clúster de objetos para analizar las relaciones entre las primitivas lingüísticas con el fin de unificar su comprensión e identificar características comunes.
El módulo de fusión de modalidades se instala sobre las líneas troncales de la visión artificial o de los modelos lingüísticos. Los autores del método integran la fusión multimodal en el codificador de puntos. La fusión temprana de funciones cruzadas modales mejora la eficacia del proceso de fusión. El mecanismo Geometry-Enhanced Group-Word Attention procesa de forma innovadora los grupos locales de puntos (subnubes) con los geométricamente vecinos. Esta metodología no solo reduce el ruido asociado a las correlaciones directas entre características puntuales y las palabras, sino que también aprovecha las relaciones geométricas inherentes a las nubes de puntos, mejorando la capacidad del modelo para integrar con precisión la información lingüística y la estructura 3D.
En la atención intermodal vainilla, suele plantearse un problema cuando se trata de situaciones en las que no hay palabras correspondientes conectadas a un punto. Para resolver este problema, los autores del método proponen aplicar los tokens de función de fondo entrenados. Esta estrategia permite que los puntos sin información textual relevante se centren en la incorporación global del token de fondo, reduciendo la distorsión potencial causada por texto no relacionado en el objeto punto.
La inclusión de objetos puntuales sin elementos lingüísticos coincidentes para resaltar el objeto de fondo reduce la influencia del objeto irrelevante. Así, obtendremos características puntuales que representarán características lingüísticos refinadas asociadas a centroides locales sin influencia de palabras irrelevantes. La incorporación de fondo es un parámetro entrenado diseñado para captar la distribución general del conjunto de datos y representar eficazmente la información de fondo. Esta incorporación solo se usa durante el cálculo de la atención. Al usar la incorporación de fondo, los autores del método promueven interacciones intermodales más precisas que no se ven influidas negativamente por palabras irrelevantes.
Los enfoques existentes suelen usar consultas con las coordenadas del centroide tomadas de la nube de puntos original. No obstante, una de las principales limitaciones de este enfoque es que no tiene en cuenta la información lingüística, que es vital para una segmentación precisa. El muestreo exclusivo de los puntos más alejados suele dar lugar a predicciones que se desvían de los objetos de destino, especialmente en escenarios dispersos, lo que dificulta la convergencia o provoca la pérdida de objetos. Esto resulta especialmente problemático cuando los puntos seleccionados no representan con precisión el objeto de destino o cuando todos ellos están asignados a una sola palabra. Para abordar el problema anterior, los autores del marco proponen un framework de primitivas lingüísticas para incorporar contenido semántico que entrena diferentes primitivas lingüísticas para encontrar objetos asociados a propiedades semánticas relevantes.
Las primitivas entrenadas se inicializarán mediante su muestra a partir de diferentes distribuciones gaussianas. Cada una de ellas define una propiedad semántica distinta. Se supone que estas primitivas contienen diferentes semánticas, como forma, color, tamaño, material, relación y ubicación. Cada primitiva añade características lingüísticas individuales y extrae información relevante. Las primitivas lingüísticas se han diseñado para demostrar patrones semánticos. El suministro de estas primitivas al Descodificador del Transformer le permite extraer información lingüística diversa, lo que facilita la identificación precisa de los objetos de destino en una fase posterior.
Cada primitiva lingüística se centra en distintos patrones semánticos de una nube de puntos determinada que se correlacionan con sus atributos lingüísticos. No obstante, el objetivo final a partir de un texto dado es identificar un objeto de destino único. Y esto requiere un análisis y una comprensión exhaustivos de la descripción textual del objeto de destino. Para lograr este objetivo, los autores del método usan el módulo de clúster de objetos, que permite analizar las dependencias entre primitivas lingüísticas, identificando características comunes y diferencias en sus principales dominios. Esto contribuye a una comprensión más profunda de las descripciones de objetos presentadas. Los autores del método usan el mecanismo de Self-Attention para extraer características comunes de las primitivas lingüísticas. El proceso de descodificación introduce las consultas de objetos, procesándolas como Query, y las características genéricas enriquecidas con primitivas lingüísticas como Key-Value. Esta configuración permite al Descodificador combinar la inferencia lingüística a partir de primitivas lingüísticas en consultas sobre objetos, identificando y agrupando eficazmente las consultas sobre objetos especificadas en 𝒪c′, logrando así una identificación precisa de los objetos.
Aunque el módulo de clúster de objetos propuesto ayuda a identificar los objetos de destino, no elimina las ambigüedades encontradas en otras implementaciones. Dichas ambigüedades pueden dar lugar a falsos positivos en la fase de inferencia. Los autores de RefMask3D usan el aprendizaje contrastivo para distinguir el token objetivo de otros tokens. Esto se logra maximizando la similitud entre el token objetivo y la expresión correspondiente y minimizando la similitud con los pares no objetivo (negativos).
A continuación, podemos ver la visualización del método RefMask3D por el parte del autor de este artículo.
2. Implementación con MQL5
Tras repasar los aspectos teóricos del método RefMask3D, pasaremos a la parte práctica de nuestro artículo. En ella, haremos realidad nuestra visión de los enfoques propuestos usando MQL5.
En la descripción presentada anteriormente, los autores del método RefMask3D dividen el complejo algoritmo en varios bloques funcionales. Y creo que será bastante lógico construir nuestras implementaciones como los módulos correspondientes.
2.1 Geometry-Enhanced Group-Word Attention
Y empezaremos nuestro trabajo con la construcción del Codificador de puntos, en el que los autores del método han construido el módulo Geometry-Enhanced Group-Word Attention. Implementaremos el algoritmo de este módulo en una nueva clase CNeuronGEGWA. Como se menciona en la descripción teórica del método RefMask3D, el codificador de puntos se construye como una red troncal U-Net. Por lo tanto, hemos elegido como clase padre CNeuronUShapeAttention, que proporcionará a nuestro objeto la funcionalidad básica. A continuación, le mostramos la estructura de la nueva clase,
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
Cabe destacar aquí que la mayor parte de las variables y objetos que nos permitirán organizar la línea troncal de U-Net se heredan de la clase padre. Sin embargo, añadiremos objetos de construcción de atención intermodal.
Todos los objetos se declaran de forma estática, lo que nos permitirá dejar vacíos el constructor y el destructor de la clase, mientras que la inicialización de todos los objetos heredados y añadidos se realizará en el método Init. Como ya sabrá, en los parámetros de este método obtendremos constantes que dan una comprensión inequívoca de la arquitectura requerida del objeto a crear.
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
En el cuerpo del método, llamaremos directamente al método homónimo de la capa CNeuronBaseOCL básica totalmente conectada, que es el antepasado inicial de todos nuestros objetos de capa neuronal.
Nota, en este caso estaremos llamando al método de la clase básica, no al método directo de la clase padre. Esto se debe a algunas características de la arquitectura que usamos para construir la línea troncal U-Net. En concreto, usaremos la creación recursiva de objetos para construir el "cuello". Y aquí tendremos que usar objetos de una clase diferente.
A continuación, inicializaremos los objetos de atención primaria y de escalado.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
Seguido de un algoritmo para crear el "cuello". El tipo de objeto "cuello" dependerá de su tamaño. En el caso general, crearemos un objeto similar al actual. Solo reduciremos en "1" el tamaño del "cuello" interior.
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Y para la última capa, usaremos un bloque de atención cruzada.
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
A continuación, inicializaremos el módulo de atención repetida y escalado inverso.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
Después, añadiremos una capa de enlace residual y un módulo de atención cruzada multimodal.
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
También inicializaremos un búfer auxiliar de almacenamiento temporal de datos.
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
Y al final del método de inicialización, organizaremos el intercambio de punteros a los búferes de datos para minimizar las operaciones de copiado de información.
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
Y retornaremos el resultado lógico de las operaciones del método al programa que realiza la llamada.
Una vez que hayamos terminado de inicializar el nuevo objeto, pasaremos a construir el algoritmo de pasada directa, que se implementará en el método feedForward. A diferencia de la clase padre, nuestro nuevo objeto requerirá de dos fuentes de datos. Por lo tanto, hemos redefinido el método heredado para trabajar con una única fuente de datos con un "stub" negativo. Y el nuevo método se ha escrito, podría decirse, "desde cero".
En los parámetros del método obtendremos los punteros a los dos objetos de los datos de origen. Sin embargo, en este caso, no probaremos ninguno de ellos.
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Primero pasaremos el puntero a una única fuente de datos al método homónimo interno de la capa de atención primaria. La comprobación del puntero ya estará organizada dentro de este método. Solo necesitaremos comprobar el resultado lógico de las operaciones del método llamado. Y luego escalaremos los resultados del bloque de atención.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
En el "cuello" pasaremos los datos escalados y el puntero al objeto de la segunda fuente de datos.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
Luego pasaremos el resultado obtenido por el segundo bloque de atención y realizaremos el escalado inverso de datos.
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
A continuación, añadiremos los enlaces residuales y realizaremos el análisis de dependencia intermodal.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
Hay un punto que debemos discutir antes de empezar a trabajar en los métodos de pasada inversa. Echemos un vistazo al siguiente extracto de la visualización de autor del método RefMask3D.
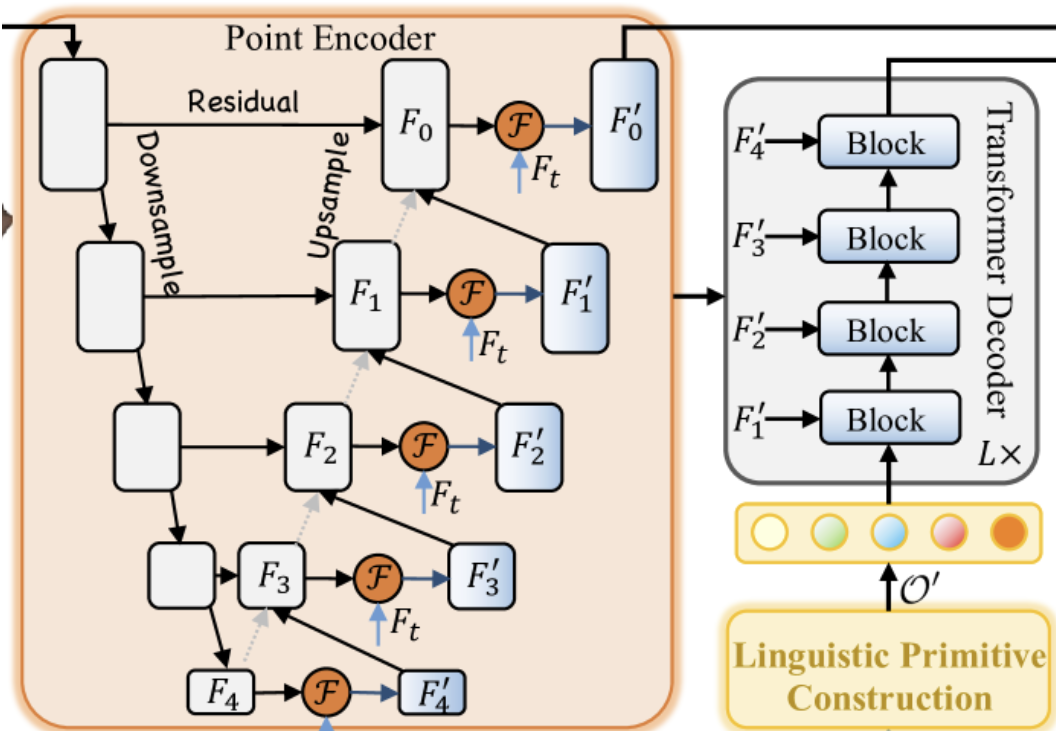
La cuestión es que el Decodificador ejecuta la atención intermodal de las primitivas entrenadas y de los resultados intermedios de nuestro Codificador de puntos. Esta operación aparentemente sencilla implica el flujo correspondiente de gradientes de error. Obviamente, habrá que organizar las interfaces adecuadas. Pero resulta fácil adivinar que durante la organización de la distribución del gradiente de error a través de nuestro bloque genérico RefMask3D, primero calcularemos los gradientes del Decodificador y luego del Codificador de puntos. Y con el modelo clásico de construcción de métodos de distribución de gradiente de error, simplemente perderemos los datos recibidos del Decodificador. No obstante, somos conscientes de que este uso del bloque supone un caso especial. Por ello, en el método calcInputGradients ofreceremos 2 variantes de trabajo: con eliminación de los gradientes previamente guardados (algoritmo clásico) y sin esta (caso especial). Para ello, hemos añadido una variable de bandera interna bAddNeckGradient y un método para modificarla, AddNeckGradient.
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
Pero volvamos al algoritmo de pasada inversa. En los parámetros del método calcInputGradients obtendremos los punteros a los tres objetos y la constante de función de la función de activación de la segunda fuente de datos.
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
En el cuerpo del método, solo comprobaremos la relevancia del puntero a la primera fuente de datos. Los otros punteros se comprobarán en el cuerpo de los métodos de distribución de gradiente de error de las capas internas.
Debido a la sustitución de los punteros por los búferes de datos que hemos organizado antes, el algoritmo de asignación del gradiente de error partirá de la capa interna de atención intermodal.
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
A continuación, realizaremos el escalado de los gradientes de error.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Y luego implementaremos la ramificación del algoritmo según la necesidad de almacenar el gradiente de error acumulado previamente. Si el almacenamiento se hace necesario, intercambiaremos el búfer de gradiente de error en el "cuello" con un búfer de gradiente similar de la primera capa de escalado de datos. Aquí explotaremos la propiedad de que los tamaños de los tensores de resultado de la capa de escalado especificada y del "cuello" son iguales, y pasaremos el gradiente de error a esta capa más tarde. Por lo tanto, en este caso, su funcionamiento será seguro.
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
A continuación, obtendremos el gradiente de error en el nivel del "cuello" usando el método clásico. Luego sumaremos los resultados de los dos flujos de información y retornaremos los punteros a los objetos.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
Si el gradiente de error acumulado previamente no es importante para nosotros, simplemente obtendremos el gradiente de error usando los métodos estándar.
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
A continuación tendremos que dibujar el gradiente de error a través del objeto "cuello". Aquí usaremos el método clásico, solo que obtendremos el gradiente de error de la segunda fuente de datos en el búfer de almacenamiento temporal de datos. Para continuar, tenemos que resumir los valores obtenidos del módulo de atención intermodal del objeto actual y del cuello.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
A continuación, haremos descender el gradiente de error hasta el nivel de la primera fuente de los datos originales.
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Después pasaremos el gradiente del error de enlace residual por la derivada de la función de activación y sumaremos la información de los dos flujos.
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
El método updateInputWeights, encargado de actualizar los parámetros del modelo, es bastante sencillo. Aquí solo llamaremos a los métodos homónimos de las capas internas que contienen los parámetros a entrenar. Por lo tanto, le sugiero que lo estudie por su cuenta. Le recuerdo que encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
Ahora diremos unas palabras sobre la creación de una interfaz para acceder a los objetos "cuello". Para implementar esta funcionalidad, crearemos el método GetInsideLayer, en cuyos parámetros pasaremos el índice de la capa requerida.
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
La obtención de un índice negativo supondrá una señal de error y el método retornará un puntero NULL. Un valor nulo indicará que se está accediendo a la capa actual. Por lo tanto, el método retornará un puntero al objeto "cuello".
if(layer == 0) return cNeck;
En caso contrario, el cuello deberá ser un objeto de la clase correspondiente y llamaremos recursivamente a este método con el índice de capa requerido disminuido en 1.
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 Construcción de primitivas lingüísticas
El siguiente paso consistirá en crear un objeto del módulo de construcción de primitivas lingüísticas en la clase CNeuronLPC. A continuación le presentamos la visualización que el autor ha implementado de este método.
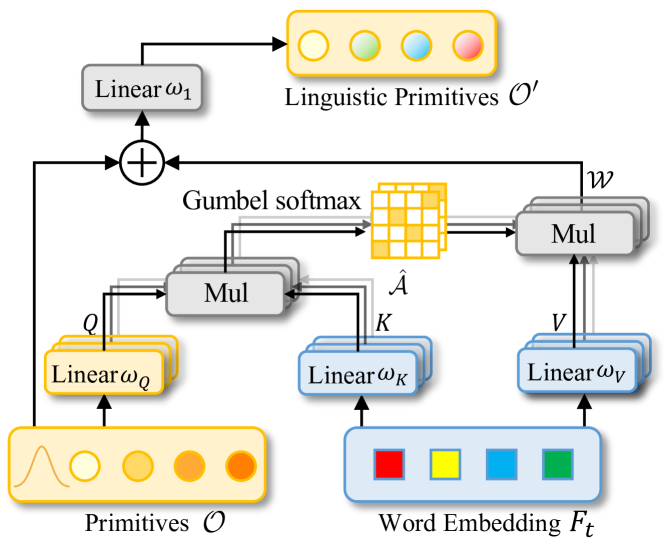
En él se pueden ver las similitudes con el clásico bloque de atención cruzada, que supuso el impulso para elegir la clase padre. En este caso, usaremos el objeto de atención cruzada CNeuronMLCrossAttentionMLKV. A continuación se indicará la estructura de la nueva clase.
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Como habrá notado, en el caso anterior añadimos las fuentes de datos de origen para las pasadas directa e inversa, pero en este caso es al contrario. Aunque el módulo de atención cruzada requiere dos fuentes de datos, en esta aplicación solo usaremos una. Esto se debe a que la generación de la segunda fuente de datos (primitivas) se realizará dentro de este objeto.
Para generar las primitivas entrenadas, crearemos 2 objetos internos de capas totalmente conectadas. Ambos objetos se declararán estáticamente, lo cual permitirá dejar el constructor y el destructor de la clase "vacíos". La inicialización de los objetos declarados y heredados se realizará en el método Init.
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
En los parámetros de este método, como siempre, obtendremos las constantes que nos permitirán definir inequívocamente la arquitectura del objeto creado. Y en el cuerpo del método llamaremos directamente al método homónimo de la clase padre, en el que ya estará organizado el control de los parámetros obtenidos y la inicialización de los objetos heredados.
Tenga en cuenta que usaremos los parámetros de las primitivas generadas como información sobre la fuente de datos primaria.
A continuación, generaremos una única capa totalmente conectada formada por un único elemento.
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
Y luego inicializaremos la capa de generación con una primitiva.
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
Observe que en este caso no estaremos usando una capa de codificación de posición. Al fin y al cabo, según la lógica de los autores del método, algunas primitivas son responsables de la posición del objeto, mientras que otras acumulan sus características.
El método de pasada directa feedForward de este método será igual de sencillo. En los parámetros del método obtendremos el puntero al objeto de datos de origen y comprobaremos inmediatamente la relevancia del puntero obtenido, lo cual, tengo que decir, no se ve a menudo en los métodos de pasada directa recientes.
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Cada vez estamos más acostumbrados a que este tipo de comprobaciones se realicen usando los métodos de los objetos anidados. Sin embargo, en este caso, utilizaremos como contexto los datos obtenidos del programa externo. Y esto significará que al llamar a métodos de los objetos internos, tendremos que hacer referencia a los objetos anidados de nuestra fuente de datos. Por lo tanto, nos veremos obligados a comprobar el puntero resultante.
A continuación, generaremos el tensor de características.
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
Y aquí debemos decir que para reducir el tiempo de decisión, esta operación se realizará solo durante el proceso de entrenamiento del modelo. En el modo de explotación, el tensor primitivo permanecerá estático y no necesitaremos generarlo en cada iteración.
Y la llamada al método de la clase padre homónimo completará las operaciones de pasada directa, al que transmitiremos el tensor primitivo como fuente de datos primaria, y la información recibida del programa externo como contexto.
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
En el método de distribución de gradientes de error calcInputGradients, realizaremos las operaciones en estricta concordancia con el algoritmo de pasada directa, solo que en orden inverso.
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Aquí, también comprobaremos primero el puntero resultante al objeto de datos de origen. Y luego llamaremos al método homónimo de la clase padre con la distribución del gradiente de error entre las primitivas y el contexto de origen.
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
Después añadiremos el gradiente del error de diversificación de primitivas.
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
La distribución del gradiente de error hasta el nivel de la capa unitaria no tendrá ningún valor, por lo que omitiremos esta operación. Dejaremos que el lector estudie por su cuenta el algoritmo del método de actualización de parámetros. Encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
El siguiente bloque en el algoritmo RefMask3D será el bloque del Decodificador vainilla del Transformer, que implementará un algoritmo de atención cruzada multimodal para la nube de puntos y las primitivas entrenadas. Podemos abarcar esta funcionalidad con los recursos ya disponibles. Por lo tanto, no nos molestaremos en crear un nuevo bloque.
Y un módulo más que tendremos que implementar es el módulo de clúster de objetos. Implementaremos el algoritmo para este módulo en la clase CNeuronOCM. Es un módulo bastante completo. Combina 2 bloques de primitivas de Self-Attention y funciones semánticas, que se complementan con un bloque de atención cruzada. A continuación, le mostramos la estructura de la nueva clase,
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
Creo que ya habrá adivinado que los métodos de esta clase tienen algoritmos bastante complejos. Su descripción requiere una explicación. Sin embargo, el formato del artículo es bastante limitado. Por lo tanto, con el fin de revelar completa y cualitativamente los algoritmos implementados, le propongo discutir más a fondo la implementación en el próximo artículo. También se presentarán los resultados de las pruebas de los modelos con el uso de los enfoques propuestos en datos reales.
Conclusión
En este artículo, nos hemos familiarizado con el método RefMask3D, diseñado para analizar la interacción multimodal compleja y la comprensión de características. El método analizado puede suponer una innovación importante en el ámbito del trading. Usando datos multidimensionales, es capaz de considerar las pautas actuales e históricas de los datos de mercado. RefMask3D usa una serie de mecanismos para centrarse en las características clave y minimizar el impacto del ruido y los datos irrelevantes.
En la parte práctica del artículo, hemos comenzado a implementar los enfoques propuestos usando herramientas MQL5 y hemos construido los objetos de los dos módulos propuestos. No obstante, el volumen de trabajo realizado supera el marco de un solo artículo, así que continuaremos el trabajo iniciado en otro.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16038
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso