
Neuronale Netze leicht gemacht (Teil 28): Gradientbasierte Optimierung

Inhalt
- Einführung
- 1. Merkmale der Anwendung der Gradientbasierte Optimierung
- 2. Grundsätze des Lernens aus dem Gradientenmodell
- 3. Durchführung des Modelltraining
- 4. Testen des trainierten Modells mit dem Strategy Tester
- Schlussfolgerung
- Liste der Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir untersuchen weiterhin verschiedene Methoden des Verstärkungslernens. Im vorigen Artikel haben wir die Methode des Deep Q-Learning kennengelernt. Diese Methode approximiert die Handlungsnutzenfunktion mit Hilfe eines neuronalen Netzes. Als Ergebnis erhalten wir ein Instrument zur Vorhersage der erwarteten Belohnung bei der Durchführung einer bestimmten Handlung in einem bestimmten Systemzustand. Danach führt der Agent eine Aktion durch, die auf der Politik und der Höhe der erwarteten Belohnung basiert. Wir haben den Einsatz von Strategien nicht explizit erörtert, sondern sind davon ausgegangen, dass die Aktion mit der höchsten erwarteten Belohnung gewählt wird. Dies ergibt sich aus der Bellman-Formel und dem allgemeinen Ziel des Reinforcement Learning, das darin besteht, die Belohnungen für die analysierte Sitzung zu maximieren.
Beachten Sie auch, dass wir bei der Untersuchung von Methoden des Reinforcement Learning nie von einer Überanpassung des Modells gesprochen haben. Betrachtet man das Modell des verstärkenden Lernens, so besteht das Ziel des Agenten darin, die Umgebung so gut wie möglich zu erlernen. Je besser der Agent seine Umgebung kennt, desto besser ist seine Leistung.
Aber wenn wir es mit einem sich verändernden Umfeld zu tun haben, und das ist der Markt, dann merkt man manchmal, dass es keine Grenzen für seine Variabilität gibt. Auf dem Markt gibt es keine zwei identischen Zustände. Selbst wenn es ähnliche Zustände gibt, können wir im nächsten Schritt zu absolut entgegengesetzten Zuständen gelangen.
Die Approximation der Q-Funktion liefert nur die erwartete durchschnittliche Belohnung, ohne die Streuung der Werte und die Wahrscheinlichkeit einer positiven Belohnung zu berücksichtigen. Die Verwendung einer gierigen Strategie mit der Wahl der maximalen Belohnung führt immer zu einer eindeutigen Aktionsauswahl. Einerseits erleichtert dies die Arbeit des Agenten. Eine solche Strategie führt jedoch nur so lange zum gewünschten Ergebnis, solange sich unser Agent nicht in einer Art Konfrontation mit der Umwelt befindet. In diesem Fall werden seine Handlungen für die Umwelt vorhersehbar, und er kann Maßnahmen entwickeln, um den Handlungen des Agenten entgegenzuwirken und die Belohnungspolitik zu ändern. Der Agent wird jedoch weiterhin die zuvor angenäherte Q-Funktion verwenden, die nicht mehr der veränderten Umgebung entspricht.
Solche Probleme können mit Methoden gelöst werden, die sich nicht der Belohnungspolitik der Umwelt annähern, sondern ihre eigene Verhaltensstrategie entwickeln. Eine dieser Methoden ist der Politik-Gradient, den wir in diesem Artikel erörtern werden.
1. Merkmale der Anwendung der Gradientbasierte Optimierung
Als wir mit dem Erlernen von Methoden des Verstärkungslernens begannen, erwähnten wir, dass der Agent mit der Umgebung interagiert und Aktionen entsprechend seiner Strategie ausführt. Dies führt zu einem Übergang von einem Zustand in einen anderen. Für jeden Übergang erhält der Agent eine bestimmte Belohnung aus der Umwelt. Anhand des Belohnungswerts kann der Agent die Nützlichkeit der durchgeführten Aktion bewerten. Die Policy-Gradient-Methode setzt die Entwicklung einer Strategie für das Verhalten der Agenten voraus.
Natürlich legen wir die Strategie des Agenten nicht explizit fest, wie es im DQN zu sehen ist. Wir gehen lediglich von der Existenz einer bestimmten mathematischen Funktion der Politik P aus, die den aktuellen Zustand der Umwelt bewertet und die beste Aktion des Agenten zurückgibt. Mit diesem Ansatz entfallen alle Schwierigkeiten bei der Annäherung an die Q-Funktion sowie die Notwendigkeit, eine explizite Strategie für das Verhalten des Agenten festzulegen, z. B. die Auswahl einer Aktion mit maximalem erwarteten Gewinn (gierige Strategie).
Natürlich hat alles seinen Preis. Anstatt die Q-Funktion zu approximieren, müssen wir die P-Funktion der Politik unseres Agenten approximieren. Dieser Artikel konzentriert sich auf die stochastische Gradientenmethode für die Politik. Dabei wird davon ausgegangen, dass unsere Strategiefunktion bei der Bewertung des aktuellen Zustands der Umgebung die Wahrscheinlichkeitsverteilung für den Erhalt einer positiven Belohnung bei der Durchführung der entsprechenden Aktion liefert.
Gleichzeitig gehen wir davon aus, dass die Handlungen unseres Agenten gleichmäßig verteilt sind. Um eine bestimmte Aktion auszuwählen, kann der Agent einfach einen Wert aus einer Normalverteilung mit bestimmten Wahrscheinlichkeiten auswählen. Natürlich ist es möglich, eine gierige Strategie zu verwenden und eine Aktion mit der höchsten Wahrscheinlichkeit zu wählen. Aber es sind die Stichproben, die dem Verhalten des Agenten Variabilität verleihen. Je höher die Wahrscheinlichkeit, desto häufiger wird diese Aktion gewählt.
Erinnern Sie sich daran, dass wir vorhin beim Verstärkungslernen von Modellen einen Hyperparameter eingeführt haben, der für das Gleichgewicht zwischen Erkundung und Nutzung verantwortlich ist. Bei der stochastischen Gradientenmethode wird dieses Gleichgewicht durch das Modell im Lernprozess durch die Verwendung von wahrscheinlichkeitsbasierten Agentenaktionen reguliert. Zu Beginn des Modelltrainings sind die Wahrscheinlichkeiten aller Aktionen nahezu gleich. Dies ermöglicht eine möglichst vollständige Erkundung der Umgebung. Bei der Untersuchung der Umwelt werden die Wahrscheinlichkeiten von Handlungen erhöht, die zur Maximierung der Rentabilität führen. Die Wahrscheinlichkeit, andere Aktionen zu wählen, ist geringer. Das Gleichgewicht zwischen Erkundung und Ausbeutung ändert sich also zugunsten der Auswahl der rentabelsten Aktionen, was den Aufbau einer Strategie mit maximaler Rentabilität ermöglicht.
Zur Annäherung an die politische P-Funktion des Agenten wird ein neuronales Netz verwendet. Da wir die beste Aktion des Agenten auf der Grundlage der anfänglichen Daten des aktuellen Umgebungszustands bestimmen müssen, kann diese Aufgabe als ein Klassifizierungsproblem betrachtet werden. Jede Aktion ist eine eigene Klasse von Ausgangszuständen. Wie bereits erwähnt, sollte die Ausgabe der neuronalen Schicht eine probabilistische Darstellung liefern, zu welchem Zustand der Umweltzustand gehört.
Die probabilistische Darstellung erlegt dem resultierenden Wert einige Einschränkungen auf. Die Ergebnisse müssen im Bereich zwischen 0% und 100% normalisiert werden. Die Summe aller Wahrscheinlichkeiten muss gleich 100% sein. Beim maschinellen Lernen ist es üblich, Bruchteile von eins anstelle von Prozentsätzen zu verwenden. Daher sollte der Wertebereich von 0 bis 1 reichen, während die Summe aller Werte 1 sein sollte. Dieses Ergebnis kann mit Hilfe der SoftMax-Funktion erzielt werden, die die folgende mathematische Formel hat.

Wir haben diese Funktion schon einmal gesehen, als wir uns mit den Methoden der Datenclusterung beschäftigt haben. Bei der Untersuchung von Methoden des unüberwachten Lernens haben wir jedoch die Ähnlichkeiten in den Quelldaten untersucht, um die Klasse zu bestimmen. Diesmal werden wir die Umweltzustände in Abhängigkeit von der erhaltenen Belohnung in Aktionen (Klassen) aufteilen. Die SoftMax-Funktion erfüllt diese Anforderungen voll und ganz. Es ermöglicht die vollständige Übertragung der Ergebnisse der Operation des neuronalen Netzes in den Bereich der Wahrscheinlichkeiten und ist über die Werte hinweg differenzierbar. Das ist sehr wichtig für das Modelltraining.
2. Grundsätze des Lernens aus dem Politikmodell
Lassen Sie uns nun über die Grundsätze des Trainings des Modells zur Annäherung an die politische Funktion sprechen. Beim Training des DQN-Modells auf jeden neuen Zustand gab die Umgebung eine Belohnung zurück. Wir haben das Modell so trainiert, dass es die erwartete Belohnung mit minimalem Fehler vorhersagt. Dies unterschied sich nicht wesentlich von den bisher verwendeten Ansätzen des überwachten Lernens.
Wenn wir die P-Funktion der Agentenpolitik für jeden neuen Zustand approximieren, erhalten wir auch eine Belohnung von der Umwelt. Aber wir wollen die beste Aktion vorhersagen und nicht die Belohnung. Das Belohnungszeichen kann nur die Auswirkungen der aktuellen Handlung auf das Ergebnis anzeigen. Wir werden das Modell so trainieren, dass die Wahrscheinlichkeit, eine Handlung mit einer positiven Belohnung zu wählen, steigt und die Wahrscheinlichkeit, eine Handlung mit einer negativen Belohnung zu wählen, sinkt.
Aber wir trainieren das Modell, um die Wahrscheinlichkeit vorherzusagen. Wie bereits erwähnt, sind die Werte der vorhergesagten Wahrscheinlichkeiten auf den Bereich von 0 bis 1 begrenzt. Dies ist jedoch nicht vergleichbar mit der erhaltenen Belohnung, die sowohl positiv als auch negativ sein kann. Gehen wir hier von folgender Logik aus. Da wir die Wahrscheinlichkeit maximieren müssen, Aktionen mit einer positiven Belohnung zu wählen, ist der Zielwert für solche Aktionen 1. Der Modellfehler wird definiert als die Abweichung der vorhergesagten Wahrscheinlichkeit einer Handlung von 1. Die Verwendung der Abweichung/Varianz ermöglicht es, die bereits entwickelte Gradientenabstiegsmethode zu nutzen, um das Modell zur Annäherung an die Politikfunktion zu trainieren, da durch die Minimierung der Varianz von 1 die Wahrscheinlichkeit der Wahl einer Aktion mit einer positiven Belohnung maximiert wird.
Bitte beachten Sie die Wahl der Verlustfunktion für das Modell. Hier können wir auch auf Methoden des überwachten Lernens zurückgreifen und uns daran erinnern, dass die Kreuzentropiefunktion für Klassifizierungsprobleme verwendet wird:

wobei p(y) die wahren Werte der Verteilung und p(y') die vorhergesagten Werte des Modells sind.
Die Verwendung des Logarithmus ist auch für die Vorhersage aufeinander folgender Ereignisse von großer Bedeutung. Aus der Wahrscheinlichkeitstheorie wissen wir, dass die Wahrscheinlichkeit, dass zwei aufeinander folgende Ereignisse eintreten, gleich dem Produkt der Ereigniswahrscheinlichkeiten ist. Für Logarithmen gilt Folgendes:
![]()
Dies ermöglicht den Übergang vom Produkt der Wahrscheinlichkeiten zur Summe ihrer Logarithmen. Dadurch wird das Modelltraining stabiler.
Ähnlich wie beim DQN-Training durchläuft der Agent, um die Belohnungen zu erhalten, eine Sitzung mit festen Parametern. Wir speichern die Zustände, Aktionen und Belohnungen im Puffer. Dann führen wir den Backpropagation-Durchgang unter Verwendung der akkumulierten Daten durch.
Da wir keine Aktionsnutzenfunktion haben, ersetzen wir sie durch die Summe der Werte, die wir während des Sitzungsdurchgangs erhalten haben. Für jeden Zustand ist der Wert der Q-Funktion die Summe der nachfolgenden Belohnungen bis zum Ende der Sitzung.
Das Modelltraining wird so lange wiederholt, bis die gewünschte Fehlerquote oder die maximale Anzahl von Trainingseinheiten erreicht ist.
3. Durchführung des Modelltrainings
Wir haben die theoretischen Aspekte erörtert und kommen nun zur Umsetzung mit MQL5. Beginnen wir mit der Funktion SoftMax. Wir haben sie aufgrund ihrer besonderen Funktionsweise nicht als Aktivierungsfunktion implementiert. Um also zu vermeiden, dass kardinale Änderungen an zuvor erstellten Objekten vorgenommen werden, werden wir sie als separate Schicht des Modells implementieren.
3.1 Implementieren von SoftMax
Wir erstellen also eine neue Klasse CNeuronSoftMaxOCL die von der Basisklasse der Neuronen abgeleitet ist CNeuronBaseOCL.
class CNeuronSoftMaxOCL : public CNeuronBaseOCL { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CNeuronSoftMaxOCL(void) {}; ~CNeuronSoftMaxOCL(void) {}; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); virtual bool calcOutputGradients(CArrayFloat *Target, float error) override; //--- virtual int Type(void) override const { return defNeuronSoftMaxOCL; } };
Für die neue Klasse müssen keine separaten Puffer angelegt werden. Außerdem werden nicht alle Puffer der übergeordneten Klasse verwendet, worauf wir später noch eingehen werden. Aus diesem Grund sind der Konstruktor und der Destruktor leer. Aus demselben Grund ist es auch nicht notwendig, die Initialisierungsmethode unserer Klasse zu überschreiben. Eigentlich müssen wir nur den Vorwärtsdurchgang feedForward und die Fehlergradienten-Methoden calcOutputGradients überschreiben.
Da wir eine neue Verlustfunktion verwenden, muss auch die Methode zur Berechnung des Modellfehlers und des Gradienten überschrieben werden calcOutputGradients.
Und natürlich werden wir die Methode zur Identifizierung der Klasse außer Kraft setzen Typ.
Beginnen wir mit der Implementierung des Verfahrens zum Vorwärtsdurchgang. Auch hier werden alle Rechenoperationen im Multi-Thread-Modus mit OpenCL durchgeführt. Erstellen wir also den neuen Kernel SoftMax_FeedForward in OpenCL. In den Kernel-Parametern werden wir Zeiger auf die anfänglichen Daten- und Ergebnispuffer sowie die Puffergröße übergeben. Die Funktionsberechnung erfordert keine zusätzlichen Parameter.
Im Kernelkörper definieren wir den Thread-Identifikator, der als Zeiger auf das entsprechende Element des Ausgangsdaten- und Ergebnis-Arrays dient. Da es sich um eine Implementierung der Aktivierungsfunktion handelt, sind die Größen des Ausgangsdatenpuffers und des Ergebnispuffers gleich. Daher ist der Zeiger auf die Elemente dieser beiden Puffer identisch.
__kernel void SoftMax_FeedForward(__global float *inputs, __global float *outputs, const ulong total) { uint i = (uint)get_global_id(0); uint l = (uint)get_local_id(0); uint ls = min((uint)get_local_size(0), (uint)256); //--- __local float temp[256];
Beachten Sie, dass zur Berechnung der SoftMax-Funktion die Summe der Exponentialwerte aller Elemente des Eingangsdatenpuffers ermittelt werden muss. Es wäre nicht gut, die Berechnung dieses Wertes bei jedem Thread zu wiederholen. Darüber hinaus wäre es gut, den Prozess der Parameterberechnung auf mehrere Threads zu verteilen. Hier stellt sich jedoch das Problem der Synchronisierung der Arbeit mehrerer Threads und des Datenaustauschs zwischen ihnen. Die OpenCL-Technologie erlaubt es nicht, Daten von einem Thread zu einem anderen zu senden. Es ermöglicht jedoch die Erstellung gemeinsamer Variablen und Arrays im lokalen Speicher innerhalb getrennter Arbeitsgruppen. Um die Arbeit von Threads innerhalb der Workgroup zu synchronisieren, gibt es eine spezielle Funktion barriere(CLK_LOCAL_MEM_FENCE). Dies werden wir verwenden.
Daher werden wir zusammen mit der Definition der Thread-ID im globalen Aufgabenraum auch die Thread-ID in der Gruppe definieren. Außerdem werden wir ein Array im lokalen Speicher deklarieren. Sie wird für den Datenaustausch zwischen den Arbeitsgruppen-Threads bei der Berechnung der Gesamtsumme der Exponentialwerte verwendet.
Das Problem dabei ist, dass OpenCL die Verwendung von dynamischen Arrays im lokalen Speicher nicht zulässt. Daher sollte die Array-Größe bereits bei der Erstellung des Kernels festgelegt werden. Diese Größe begrenzt die Anzahl der Threads, um die exponentielle Werte zu summieren.
Der Prozess der Summierung von Exponentialwerten besteht aus 2 aufeinander folgenden Schleifen. Im Hauptteil der ersten Schleife durchläuft jeder an der Summierung beteiligte Thread den gesamten Vektor der Anfangswerte mit einem Schritt, der der Anzahl der Summierungs-Threads entspricht, und sammelt seinen Anteil an der Summe der Exponentialwerte. Wir werden also den gesamten Summierungsprozess gleichmäßig auf alle Threads verteilen. Jeder von ihnen speichert seinen Wert in dem entsprechenden Element des lokalen Arrays.
uint count = 0; if(l < 256) do { uint shift = count * ls + l; temp[l] = (count > 0 ? temp[l] : 0) + (count * ls + l < total ? exp(inputs[shift]) : 0); count++; } while((count * ls + l) < total); barrier(CLK_LOCAL_MEM_FENCE);
In diesem Stadium synchronisieren wir die Threads nach Abschluss der Schleifeniterationen.
Als Nächstes müssen wir die Summe aller Elemente des lokalen Arrays zu einem einzigen Wert zusammenfassen. Dies wird in der zweiten Schleife umgesetzt. Hier teilen wir die Größe des lokalen Arrays in zwei Hälften und addieren die Werte paarweise. Jede Operation, die mit der Addition zweier Werte zusammenhängt, wird von einem separaten Thread ausgeführt. Danach wiederholen wir die Iterationen der Schleife: Wir halbieren die Anzahl der Elemente und addieren die Elemente paarweise. Die Schleifenwiederholungen werden so lange wiederholt, bis die Gesamtsumme der Werte im Array-Element mit dem Index 0 erreicht ist.
count = ls; do { count = (count + 1) / 2; if(l < 256) temp[l] += (l < count && (l + count) < total ? temp[l + count] : 0); barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Wie wir sehen können, kann jede neue Iteration der Schleife erst beginnen, wenn die Operationen aller beteiligten Threads abgeschlossen sind. Daher wird die Synchronisierung nach jeder Iteration der Schleife durchgeführt.
Bitte beachten Sie, dass die OpenCL-Architektur nur eine vollständige Synchronisierung von Threads ermöglicht. Alle Elemente der Arbeitsgruppe müssen also den entsprechenden „Barriere“-Operator erreichen. Andernfalls friert das Programm ein. Daher müssen wir bei der Organisation des Programms sehr sorgfältig auf die Thread-Synchronisationspunkte achten. Es wird nicht empfohlen, sie in den Körpern von bedingten Operatoren zu implementieren, wenn der Programmalgorithmus mindestens einem Thread erlaubt, die Synchronisationspunkte zu umgehen.
Sobald die Iterationen der obigen Schleifen abgeschlossen sind, erhalten wir die Summe aller Exponentialwerte der ursprünglichen Daten und können den Prozess der Datennormalisierung abschließen. Zu diesem Zweck wird eine weitere Schleife erstellt, in der der anfängliche Datenpuffer mit den entsprechenden Werten gefüllt wird.
float sum = temp[0]; if(sum != 0) { count = 0; while((count * ls + l) < total) { uint shift = count * ls + l; outputs[shift] = exp(inputs[shift]) / (sum + 1e-37f); count++; } } }
Damit sind die Operationen mit dem Feedforward-Kernel abgeschlossen. Als Nächstes werden die Backpropagation-Kernel erstellt.
Wir beginnen mit der Erstellung des Backpropagation-Kernels, indem wir den Gradienten durch die Funktion softmax aufteilen. Achten Sie darauf, dass das Hauptmerkmal dieser Funktion die Normalisierung der Summe aller Ergebniswerte auf 1 ist. Daher führt die Änderung von nur einem Wert am Eingang der Aktivierungsfunktion zur Neuberechnung aller Werte des Ergebnisvektors. In ähnlicher Weise muss bei der Weitergabe des Fehlergradienten jedes Element der Eingabedaten seinen Anteil am Fehler von jedem Element des Ergebnisvektors erhalten. Die mathematische Formel für den Einfluss der einzelnen Ausgangsdaten auf das Ergebnis wird im Folgenden dargestellt. Dies werden wir im Kernel SoftMax_HiddenGradient implementieren.
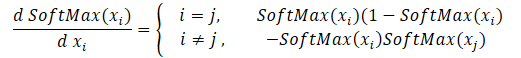
In den Parametern erhält der Kernel Zeiger auf 3 Datenpuffer: Ergebnisse nach einem Feedforward-Durchgang, Gradienten aus einer vorherigen Schicht oder aus einer Verlustfunktion. Außerdem erhält er den Gradientenpuffer der vorherigen Schicht, in den wir die Ergebnisse dieses Kernels schreiben werden.
Im Kernelkörper definieren wir den Thread-Identifikator und die Gesamtzahl der Threads Sie verweisen auf ein Array-Element, um das Ergebnis des aktuellen Threads und die Puffergrößen aufzuzeichnen.
Als Nächstes müssen wir zwei private Variablen vorbereiten. Wir kopieren den Wert des entsprechenden Elements des Feedforward-Ergebnisvektors in eines dieser Elemente. Der zweite sollte deklariert werden, um die Ergebnisse der aktuellen Thread-Operation zu sammeln. Aufgrund der spezifischen Architektur von OpenCL-Geräten verwenden wir private Variablen. Der Zugriff auf private Variablen ist viel schneller als ähnliche Operationen mit Puffern im globalen Speicher. Dieser Ansatz verbessert also die Gesamtleistung des Kernels.
Anschließend werden alle Ergebniselemente in einer Schleife durchlaufen, um den Fehlergradienten gemäß der obigen Formel zu ermitteln. Nach Abschluss der Schleifenoperationen wird der akkumulierte Gradientenwert an das entsprechende Element des Gradientenpuffers der vorherigen Schicht übergeben und der Kernel geschlossen.
__kernel void SoftMax_HiddenGradient(__global float* outputs, __global float* output_gr, __global float* input_gr) { size_t i = get_global_id(0); size_t outputs_total = get_global_size(0); float output = outputs[i]; float result = 0; for(int j = 0; j < outputs_total; j++) result += outputs[j] * output_gr[j] * ((float)(i == j ? 1 : 0) - output); input_gr[i] = result; }
Es gibt den letzten Kernel — den zur Bestimmung des Fehlergradienten der Verlustfunktion SoftMax_OutputGradient. In diesem Artikel verwenden wir LogLoss als Verlustfunktion.
Da die Gradienten auf die Elemente der entsprechenden Einwirkung verteilt werden, wird auch die Ableitung Element für Element berechnet. Dies ermöglicht die Aufteilung des Fehlergradienten auf mehrere Threads. Aus dem Schulmathematikunterricht wissen wir, dass die Ableitung des Logarithmus gleich dem Verhältnis von 1 zum Argument der Funktion ist. Die Ableitung der Verlustfunktion lautet daher wie folgt.
![]()
Nun müssen wir die obige mathematische Formel in den OpenCL-Programmkern implementieren. Der Code ist recht einfach und besteht aus nur zwei Zeilen.
__kernel void SoftMax_OutputGradient(__global float* outputs, __global float* targets, __global float* output_gr) { size_t i = get_global_id(0); output_gr[i] = -targets[i] / (outputs[i] + 1e-37f); }
Damit ist der Betrieb auf der OpenCL-Programmseite abgeschlossen. Jetzt können wir mit dem Hauptprogramm weiterarbeiten. Wir müssen Konstanten für die Arbeit mit neuen Kernel hinzufügen, eine Deklaration der neuen Kernel hinzufügen und Methoden für deren Aufruf erstellen.
#define def_k_SoftMax_FeedForward 36 #define def_k_softmaxff_inputs 0 #define def_k_softmaxff_outputs 1 #define def_k_softmaxff_total 2 //--- #define def_k_SoftMax_HiddenGradient 37 #define def_k_softmaxhg_outputs 0 #define def_k_softmaxhg_output_gr 1 #define def_k_softmaxhg_input_gr 2 //--- #define def_k_SoftMax_OutputGradient 38 #define def_k_softmaxog_outputs 0 #define def_k_softmaxog_targets 1 #define def_k_softmaxog_output_gr 2
Die Aufrufverfahren der Kernel wiederholen die zuvor verwendeten Algorithmen ähnlicher Verfahren vollständig. Der vollständige Code des EAs befindet sich im Anhang.
Die fehlende SoftMax-Funktion ist nun fertig, und wir können zum Expert Advisor übergehen, wo wir das Policy-Gradientenmodell implementieren und trainieren werden.
3.2 Aufbau eines EA zum Trainieren des Modells
Um das Modell zur Approximation der Agentenpolitikfunktion zu trainieren, wird ein neuer Expert Advisor in der Datei REINFORCE.mq5 erstellt. Die Grundfunktionalität wird von Q-learning.mq5 geerbt, das wir im letzten Artikel zum Trainieren des DQN-Modells erstellt haben. Im Gegensatz zum DQN-Modell wird der neue Expert Advisor jedoch nur ein neuronales Netz verwenden. Für die korrekte Umsetzung des Algorithmus müssen wir drei Stapel erstellen: Umgebungszustände, durchgeführte Aktionen und erhaltene Belohnungen.
CNet StudyNet; CArrayObj States; vectorf vActions; vectorf vRewards;
Die externen Parameter des EA werden entsprechend den Anforderungen des Algorithmus leicht verändert.
input int SesionSize = 24 * 22; input int Iterations = 1000; input double DiscountFactor = 0.999;
Die EA-Initialisierungsmethode ist fast dieselbe. Wir haben nur eine Stapelinitialisierung hinzugefügt, um die durchgeführten Aktionen und erhaltenen Belohnungen zu sammeln.
if(!vActions.Resize(SesionSize) || !vRewards.Resize(SesionSize)) return INIT_FAILED;
Der Trainingsprozess wird mit der Funktion Trainieren durchgeführt. Betrachten wir das genauer.
Wie üblich legen wir zu Beginn der Funktion den Bereich der Trainingsstichprobe entsprechend den vorgegebenen äußeren Parametern fest.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
Nachdem wir den Trainingszeitraum festgelegt haben, laden wir die Trainingsprobe.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- int total = bars - (int)(HistoryBars + 2 * SesionSize);
Die oben genannten Vorgänge unterscheiden sich nicht von denen, die in früheren EAs verwendet wurden. Es folgt ein System von Modelltrainingsschleifen. Das System implementiert die wichtigsten Ansätze für das Modelltraining.
Die äußere Schleife ist für die Iteration über die Trainingseinheiten des Modells verantwortlich. Zu Beginn des Zyklus bestimmen wir zufällig den Anfangsbalken der Sitzung im allgemeinen Pool des geladenen Verlaufs.
CBufferFloat* State; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0,1,error_code)),1) * (total) + SesionSize); States.Clear();
Dann implementieren wir eine Schleife, in der unser Agent Schritt für Schritt die gesamte Sitzung durchläuft. Im Hauptteil der Schleife füllen wir zunächst den Puffer des aktuellen Systemzustands mit historischen Daten für den analysierten Zeitraum. Ein ähnlicher Vorgang wurde beim Training früherer Modelle vor jedem direkten Durchgang durchgeführt.
for(int batch = 0; batch < SesionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; } int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) break; }
Als Nächstes implementieren wir den Modell-Vorwärtsdurchlauf.
if(IsStopped()) { ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) continue; if(!StudyNet.feedForward(GetPointer(State), 12, true)) { ExpertRemove(); return; }
Auf der Grundlage der Ergebnisse des Feed-Forward-Durchlaufs erhalten wir eine Wahrscheinlichkeitsverteilung der Aktionen und entnehmen die nächste Aktion aus der Normalverteilung, wobei wir die erhaltene Wahrscheinlichkeitsverteilung berücksichtigen. Die Stichprobenziehung wird von einer separaten Funktion durchgeführt GetActiondurchgeführt; die Wahrscheinlichkeitsverteilung wird in deren Parametern übergeben.
StudyNet.getResults(TempData); int action = GetAction(TempData); if(action < 0) { ExpertRemove(); return; }
Nach dem Sampling der Aktion bestimmen wir die Belohnung für die ausgewählte Aktion auf der Grundlage der Größe der nächsten Kerze. Die Belohnungspolitik ist diejenige, die wir im vorherigen Artikel verwendet haben.
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -2; break; case 1: if(reward > 0) reward *= -2; else reward *= -1; break; default: reward = -fabs(reward); break; }
Wir speichern die gesamte Stichprobe auf dem Stapel. Bitte beachten Sie, dass die Zustände und Aktionen einfach zum Stapel hinzugefügt werden. Aber die Belohnungen werden unter Berücksichtigung eines Abwertungsfaktors eingespeichert. Daher müssen wir in der Entwurfsphase festlegen, wie die Belohnungen abgewertet werden sollen. Für die Abwertung gibt es zwei Möglichkeiten. Wir können frühe Belohnungen abwerten, indem wir späteren Belohnungen mehr Gewicht beimessen. Dieser Ansatz wird häufig verwendet, wenn der Agent während des Durchlaufs der Sitzung Zwischenbelohnungen erhält. Die Hauptaufgabe des Agenten besteht jedoch darin, das Ende der Sitzung zu erreichen, wo er die maximale Belohnung erhält.
Der zweite Ansatz ist umgekehrt: Die ersten Belohnungen werden stärker gewichtet. Spätere Belohnungen werden dann abgewertet. Diese Option ist akzeptabel, wenn wir die maximale und schnellste Belohnung anstreben. Ich habe den zweiten Ansatz gewählt, weil es wichtig ist, sofort den maximalen Gewinn zu erzielen und nicht mit Verlusten zu warten, während sich der Markt nach dem Abschluss umkehrt.
Und noch eine Sache. Nach Abschluss des Sitzungsdurchlaufs müssen wir die kumulative Belohnung für jeden Zustand bis zum Ende der Sitzung berechnen. MQL5-Vektoroperationen erlauben nur die Berechnung der direkten kumulativen Summe. Deshalb speichern wir einfach alle Belohnungswerte in umgekehrter Reihenfolge in einem Vektor. Nach dem Ende der Schleife wird mit einer Vektoroperation die kumulierte Summe berechnet.
if(!States.Add(State)) { ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)(reward * pow(DiscountFactor, (double)batch)); vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
Nachdem wir die Daten gespeichert haben, fahren wir mit der nächsten Iteration der Schleife fort. Wir sammeln also Daten für die gesamte Sitzung.
Nach allen Iterationen der Schleife berechnen wir die Gesamtbelohnung für die Sitzung unter Berücksichtigung des Rabatts, den Vektor der kumulativen Belohnungen von jedem Zustand bis zum Ende der Sitzung und den Wert der Verlustfunktion.
Wir speichern auch das aktuelle Modell, aber nur, wenn die maximale Belohnung aktualisiert wird.
float cum_reward = vRewards.Sum(); vRewards = vRewards.CumSum(); vRewards = vRewards / fmax(vRewards.Max(), fabs(vRewards.Min())); float loss = (vRewards * MathLog(vProbs) * (-1)).Sum(); if(MaxProfit < cum_reward) { if(!StudyNet.Save(FileName + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false)) return; MaxProfit = cum_reward; }
Da wir nun die Werte der Belohnungen entlang des Sitzungspfads des Agenten haben, können wir eine Trainingsschleife für das Richtlinienfunktionsmodell implementieren. Dies wird in einer weiteren Schleife umgesetzt. In dieser Schleife extrahieren wir die Umgebungszustände aus unserem Puffer und führen den Modellvorlauf durch. Dies ist notwendig, um alle internen Werte des Modells für den entsprechenden Zustand der Umgebung wiederherzustellen.
Danach bereiten wir einen Vektor von Referenzwerten für den aktuellen Zustand der Umgebung vor. Wie wir uns erinnern, maximieren wir die Wahrscheinlichkeit, eine Handlung mit einer positiven Belohnung zu wählen, und minimieren die Wahrscheinlichkeiten der anderen. Wenn wir also nach der Aktionsausführung einen positiven Wert erhalten, füllen wir den Vektor der Referenzwahrscheinlichkeiten mit Nullwerten. Und nur für die ausgeführte Aktion setzen wir die Wahrscheinlichkeit auf 1. Wenn eine negative Belohnung zurückgegeben wird, wird der Vektor der Referenzwahrscheinlichkeiten mit Einsen aufgefüllt. In diesem Fall wird für die ausgeführte Aktion Null gesetzt.
for(int batch = 0; batch < SessionSize; batch++) { State = States.At(batch); if(!StudyNet.feedForward(State)) { ExpertRemove(); return; } if((vRewards[SessionSize - batch - 1] >= 0 ? (!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], 1)) : (!TempData.BufferInit(Actions, 1) || !TempData.Update((int)vActions[batch], 0)) )) { ExpertRemove(); return; } if(!StudyNet.backProp(TempData)) { ExpertRemove(); return; } }
Als Nächstes führen wir den Backpropagation-Durchlauf durch, um die Modellgewichte zu aktualisieren. Wie wiederholen die Iterationen für alle gespeicherten Umgebungszustände.
Wenn alle Iterationen der Schleife abgeschlossen sind, geben wir eine Meldung in das Protokoll ein und fahren mit der nächsten Sitzung fort.
PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, cum_reward, loss); } Comment(""); //--- ExpertRemove(); }
Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen. Nach dem erfolgreichen Abschluss aller Iterationen beenden wir die Funktion und erzeugen ein Schließereignis im Terminal. Der vollständige Code des EAs befindet sich im Anhang.
Beachten Sie auch, dass wir zur Annäherung an die Politikfunktion unseres Modells ein neuronales Netz mit einer Architektur verwendet haben, die der des Q-Funktions-Trainings aus dem letzten Artikel ähnelt. Außerdem verwenden wir das trainierte Modell aus dem letzten Artikel und ersetzen den Entscheidungsblock darin, indem wir SoftMax als letzte Schicht des neuronalen Netzes hinzufügen, um die Daten zu normalisieren.
Der Prozess des Modelltrainings ist ganz ähnlich wie bei jedem anderen Modell. Jeder Artikel dieser Serie enthält eine Vielzahl von Beispielen. Um die geleistete Arbeit zusammenzufassen, habe ich beschlossen, vom üblichen Artikelformat abzuweichen. Sehen wir uns stattdessen an, wie die trainierten Modelle im Strategietester laufen.
4. Testen des trainierten Modells mit dem Strategy Tester
Im vorherigen Artikel haben wir ein DQN-Modell trainiert. In diesem Artikel haben wir das Modell einer Gradientbasierte Optimierung erstellt und trainiert. Ich schlage vor, Expert Advisors zum Testen zu erstellen, mit denen wir die Leistung der Modelle im Strategietester überprüfen können. Lassen Sie uns also zwei EAs erstellen: Q-learning-test.mq5 und REINFORCE-test.mq5. Die Namen spiegeln die von den einzelnen EA getesteten Modelle wider.
Die EAs haben die gleiche Struktur. Werfen wir also einen Blick auf einen von ihnen. Wie auch immer, den vollständigen Code beider EAs finden Sie im Anhang.
Der neue EA „REINFORCE-test.mq5“ wird auf der Grundlage des oben beschriebenen EA "REINFORCE.mq5" erstellt. Da der EA das Modell jedoch nicht trainiert, wurde die Funktion Train entfernt. Die grundlegende Funktionalität wurde in die Funktion OnTick verlagert, die jedes neue Tick-Ereignis verarbeitet.
Das trainierte Modell wertet die Umgebungszustände auf der Grundlage geschlossener Kerzenständer aus. Prüfen wir daher im Hauptteil der Funktion OnTick die Eröffnung einer neuen Kerze. Die übrigen Operationen der Funktion werden nur ausgeführt, wenn eine neue Kerze erscheint.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if(lastBar >= iTime(Symb.Name(), TimeFrame, 0)) return;
Wenn eine neue Kerze erscheint, laden wir die neuesten historischen Daten und füllen den Puffer für die Beschreibung des Systemzustands aus.
int bars = CopyRates(Symb.Name(), TimeFrame, 0, HistoryBars+1, Rates); if(!ArraySetAsSeries(Rates, true)) return; RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = (int)HistoryBars - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) break; }
Anschließend prüfen wir, ob die Daten korrekt ausgefüllt sind, und führen den Vorwärtsdurchlauf des Modells durch.
if(State1.Total() < (int)(HistoryBars * 12)) return; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; StudyNet.getResults(TempData); if(!TempData) return;
Als Ergebnis des Vorwärtsdurchlaufs erhalten wir eine Wahrscheinlichkeitsverteilung möglicher Aktionen, aus der wir eine zufällige Aktion auswählen.
lastBar = Rates[0].time; int action = GetAction(TempData); delete TempData;
Anschließend sollte die ausgewählte Aktion ausgeführt werden. Bevor wir jedoch eine neue Position eröffnen, sollten wir prüfen, ob es bereits offene Positionen gibt. Dazu müssen wir 2 Flags definieren: Kaufen und Verkaufen. Wenn wir die Variablen deklarieren, setzen wir sie auf false.
Danach implementieren wir eine Schleife über alle Werte. Wenn eine offene Position für das analysierte Symbol gefunden wird, ändern wir den Wert des entsprechenden Flags.
bool Buy = false; bool Sell = false; for(int i = 0; i < PositionsTotal(); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((ENUM_POSITION_TYPE)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: Buy = true; break; case POSITION_TYPE_SELL: Sell = true; break; } }
Danach folgt der Handelsblock. Hier verwenden wir die ‚switch‘-Anweisung, um den Blockalgorithmus je nach der durchgeführten Aktion zu verzweigen. Wenn er eine neue Position eröffnet, prüfen wir die Flags der offenen Positionen. Wenn eine offene Position in der betreffenden Richtung besteht, lassen wir sie einfach im Markt und warten auf die Eröffnung einer neuen Kerze.
Wenn zum Zeitpunkt der Entscheidung eine offene Gegenposition gefunden wird, schließen wir zuerst die offene Position und eröffnen erst dann eine neue.
switch(action) { case 0: if(!Buy) { if((Sell && !Trade.PositionClose(Symb.Name())) || !Trade.Buy(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 1: if(!Sell) { if((Buy && !Trade.PositionClose(Symb.Name())) || !Trade.Sell(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 2: if(Buy || Sell) if(!Trade.PositionClose(Symb.Name())) { lastBar = 0; return; } break; } //--- }
Wenn der Agent alle Positionen schließen muss, rufen wir die Funktion zum Schließen von Positionen für das aktuelle Symbol auf. Die Funktion wird nur aufgerufen, wenn es mindestens eine offene Position gibt.
Vergessen wir nicht, die Ergebnisse bei jedem Schritt zu kontrollieren.
Der vollständige Code des EAs befindet sich im Anhang.
Das erste getestete Modell war DQN. Und es gibt eine unerwartete Überraschung. Das Modell erwirtschaftete einen Gewinn. Es wurde jedoch nur ein einziger Handelsvorgang ausgeführt, der während des gesamten Tests offen war. Das Symboldiagramm mit dem abgeschlossenen Geschäft ist unten abgebildet.

Wenn wir die Position auf dem Symbolchart auswerten, können wir sehen, dass das Modell den globalen Trend klar erkannt und eine Position in dessen Richtung eröffnet hat. Die Position gewinnt, aber die Frage ist, ob das Modell in der Lage sein wird, eine solche Position rechtzeitig abzuschließen? Wir haben das Modell anhand der historischen Daten der letzten 2 Jahre trainiert. In den letzten 2 Jahren wurde der Markt von einem Abwärtstrend für das analysierte Instrument beherrscht. Deshalb fragen wir uns, ob das Modell die Geschäft rechtzeitig schließen kann.
Bei Verwendung der gierigen Strategie führt das Gradientenmodell zu ähnlichen Ergebnissen. Erinnern wir uns, als wir anfingen, Methoden des Verstärkungslernens zu studieren, habe ich wiederholt betont, wie wichtig die richtige Wahl der Belohnungspolitik ist. Also beschloss ich, mit der Belohnungspolitik zu experimentieren. Um insbesondere ein zu langes Halten von Verlustpositionen auszuschließen, habe ich beschlossen, die Strafen für unrentable Positionen zu erhöhen. Zu diesem Zweck habe ich zusätzlich das Gradientenmodell mit der neuen Belohnungspolitik trainiert. Nach einigen Experimenten mit den Hyperparametern des Modells ist es mir gelungen, 60 % der Operationen mit Gewinn zu beenden. Das Testdiagramm ist unten abgebildet.
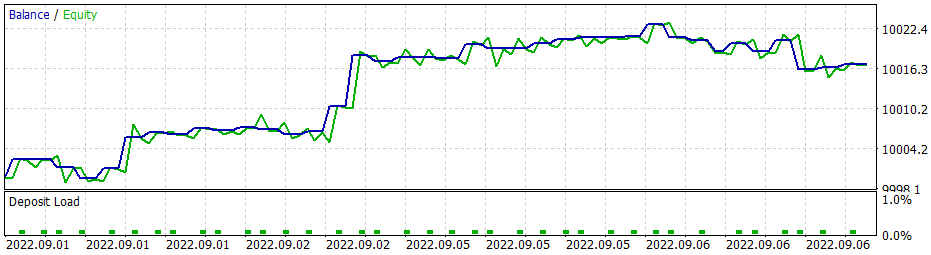
Die durchschnittliche Haltedauer einer Position beträgt 1 Stunde und 40 Minuten.
Schlussfolgerung
In diesem Artikel haben wir einen anderen Algorithmus der Methoden des verstärkten Lernens untersucht. Wir haben ein Modell für die Gradientbasierte Optimierung erstellt und trainiert.
Im Gegensatz zu anderen Artikeln in dieser Reihe haben wir in diesem Artikel die Modelle im Strategietester trainiert und getestet. Aus den Testergebnissen können wir schließen, dass die Modelle Signale für die Durchführung profitabler Handelsgeschäfte erzeugen können. Gleichzeitig möchte ich noch einmal betonen, dass es wichtig ist, die richtige Belohnungspolitik und Verlustfunktion zu wählen, um das gewünschte Ergebnis zu erzielen.
Liste der Referenzen
- Neuronale Netze leicht gemacht (Teil 25): Praxis des Transfer-Learnings
- Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
- Neuronale Netze leicht gemacht (Teil 27): Tiefes Q-Learning (DQN)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | REINFORCE.mq5 | EA | Ein Expert Advisor zum Trainieren des Modells |
| 2 | REINFORCE-test.mq5 | EA | Ein Expert Advisor zum Testen des Modells im Strategy Tester |
| 1 | Q-learning-test.mq5 | EA | Ein Expert Advisor zum Testen des DQN-Modells im Strategy Tester |
| 2 | NeuroNet.mqh | Klassenbibliothek | Bibliothek zur Erstellung neuronaler Netzmodelle |
| 3 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Erstellung neuronaler Netzwerkmodelle |
…
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11392
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic
Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich habe versucht, die Zeile #include <Math\Stat\Normal . mqh> direkt in die Datei VAE .mqh einzufügen , aber es hat nicht funktioniert. Der Compiler schreibt immer noch 'MathRandomNormal' - nicht deklarierter Bezeichner VAE.mqh 92 8. Wenn Sie diese Funktion löschen und erneut eingeben, erscheint ein Tooltip mit dieser Funktion, was meines Erachtens bedeutet, dass sie in der Datei VAE.mqh zu sehen ist.
Im Allgemeinen habe ich versucht, auf einem anderen Computer mit einem anderen sogar Version der vinda, und das Ergebnis ist das gleiche - nicht sehen, die Funktion und nicht kompilieren. mt5 neueste Version betta 3420 von 5 September 2022.
Dmitry, haben Sie irgendwelche Einstellungen im Editor aktiviert?
Im Allgemeinen habe ich es auf einem anderen Computer mit einer anderen Version von Windows versucht, und das Ergebnis ist das gleiche - es sieht die Funktion nicht und kompiliert nicht. mt5 neueste Version betta 3420 vom 5. September 2022.
Dmitry, haben Sie irgendwelche Einstellungen im Editor aktiviert?
Versuchen Sie, die Zeile"Namespace Math" auszukommentieren
Dmitry Ich habe Terminalversion 3391 vom 5. August 2022 (letzte stabile Version). Jetzt habe ich versucht, auf die Beta-Version 3420 vom 5. September 2022 zu aktualisieren. Der Fehler mit values.Assign ist verschwunden. Aber der Fehler mit MathRandomNormal ist nicht verschwunden. Ich habe eine Bibliothek mit dieser Funktion auf dem Pfad, wie Sie geschrieben haben. Aber in der Datei VAE.mqh gibt es keinen Verweis auf diese Bibliothek, aber in der Datei NeuroNet.mqh wird diese Bibliothek wie folgt angegeben:
Namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Aber so bekomme ich es nicht zum Laufen. :(
PS: Wenn direkt in der Datei VAE.mqh der Pfad zur Bibliothek angegeben wird. Ist es möglich, das zu tun? Ich verstehe nicht ganz, wie man die Bibliothek in der Datei NeuroNet.mqh festlegt , wird es da nicht einen Konflikt geben?
3445 vom 23. September - dieselbe Sache.
Brauche Rat :) Ich bin gerade nach der Neuinstallation in das Terminal eingestiegen, möchte trainieren und erhalte eine Fehlermeldung
Hallo.
Brauche Rat :) Ich bin gerade nach der Neuinstallation in das Terminal eingestiegen, möchte trainieren und erhalte eine Fehlermeldung