
Entwicklung eines Expert Advisors für mehrere Währungen (Teil 20): Ordnung in den Ablauf der automatischen Projektoptimierungsphasen bringen (I)
Einführung
In dieser Artikelserie versuchen wir, ein automatisches Optimierungssystem zu entwickeln, das es ermöglicht, gute Kombinationen von Parametern einer Handelsstrategie ohne menschliches Eingreifen zu finden. Diese Kombinationen werden dann zu einem endgültigen EA kombiniert. Das Ziel wird in Teil 9 und Teil 11 ausführlicher dargelegt. Der Prozess einer solchen Suche selbst wird von einem EA (optimizing EA) gesteuert, und alle Daten, die während des Betriebs gespeichert werden müssen, werden in der Hauptdatenbank festgelegt.
In der Datenbank gibt es Tabellen, in denen Informationen über verschiedene Klassen von Objekten gespeichert werden. Einige haben ein Statusfeld, das Werte aus einer festen Reihe von Werten annehmen kann („Queued“, „Process“, „Done“), aber nicht alle Klassen verwenden dieses Feld. Genauer gesagt, wird es derzeit nur für Optimierungsaufgaben (Task) verwendet. Unser optimierendes EA sucht in der Aufgabentabelle (Aufgaben) nach den Aufgaben in der Warteschlange, um die nächste auszuführende Aufgabe auszuwählen. Nach Abschluss jeder Aufgabe ändert sich ihr Status in der Datenbank auf Erledigt.
Versuchen wir, automatische Statusaktualisierungen nicht nur für Aufgaben, sondern auch für alle anderen Klassen von Objekten (Aufträge, Phasen, Projekte) zu implementieren und die automatische Ausführung aller erforderlichen Phasen bis zur Erlangung des endgültigen EA zu organisieren, der unabhängig ohne Verbindung zur Datenbank arbeiten kann.
Der Weg ist vorgezeichnet
Zunächst werden wir uns alle Klassen von Objekten in der Datenbank, die einen Status haben, genau ansehen und klare Regeln für die Änderung des Status formulieren. Wenn dies möglich ist, können wir diese Regeln als Aufrufe zusätzlicher SQL-Abfragen entweder vom optimierenden EA oder von den Stage EAs implementieren. Es wäre auch möglich, sie als Trigger in der Datenbank zu implementieren, die beim Auftreten bestimmter Datenänderungsereignisse aktiviert werden.
Als Nächstes müssen wir uns auf eine Methode zur Festlegung der Reihenfolge einigen, in der die Aufgaben erledigt werden. Das war vorher kein großes Problem, da wir während der Entwicklung jedes Mal auf einer neuen Datenbank trainierten und Projektphasen, Arbeiten und Aufgaben genau in der Reihenfolge hinzufügten, in der sie erledigt werden mussten. Wenn man jedoch dazu übergeht, Informationen über mehrere Projekte in der Datenbank zu speichern oder sogar automatisch neue Projekte hinzuzufügen, kann man sich nicht mehr auf diese Methode zur Bestimmung der Rangfolge von Aufgaben verlassen. Lassen Sie uns also etwas Zeit für dieses Thema aufwenden.
Um den Betrieb des gesamten Ablaufs zu testen, bei dem alle Aufgaben des Auto-Optimierungsprojekts nacheinander ausgeführt werden, müssen wir einige weitere Aktionen automatisieren. Vorher haben wir sie manuell durchgeführt. Nach Abschluss der zweiten Optimierungsphase haben wir beispielsweise die Möglichkeit, die besten Gruppen für die Verwendung im endgültigen EA auszuwählen. Wir haben diese Operation durchgeführt, indem wir die dritte Phase des EA manuell, d. h. außerhalb des automatischen Optimierungsprogramms, ausgeführt haben. Um die Startparameter für diesen EA festzulegen, haben wir auch die IDs der Durchgänge der zweiten Phase mit den besten Ergebnissen manuell ausgewählt, indem wir eine Datenbankzugangsschnittstelle eines Drittanbieters in Verbindung mit MQL5 verwendet haben. Wir werden versuchen, auch in diesem Bereich etwas zu tun.
Nach den Änderungen, die wir vorgenommen haben, erwarten wir, dass wir endlich einen vollständigen, fertigen Ablauf für die Durchführung von Auto-Optimierungsstufen erstellen können, um den endgültigen EA zu erhalten. Auf dem Weg dorthin werden wir auch einige andere Fragen im Zusammenhang mit der Steigerung der Arbeitseffizienz betrachten. Zum Beispiel scheint es, dass die zweite und die folgenden Phasen der EAs für verschiedene Handelsstrategien gleich sind. Prüfen wir, ob das stimmt. Wir werden auch sehen, was praktischer ist - die Erstellung verschiedener kleinerer Projekte oder die Erstellung einer größeren Anzahl von Phasen oder Arbeiten in einem größeren Projekt.
Regeln für Statusänderungen
Beginnen wir mit der Formulierung der Regeln für die Statusänderung. Wie Sie sich vielleicht erinnern, enthält unsere Datenbank Informationen über die folgenden Objekte, die ein Statusfeld (status) haben:
- Projekte. Kombiniert einen oder mehrere Abschnitte, die in der Tabelle projects gespeichert sind;
- Phasen. Kombiniert einen oder mehrere Aufträge, die in der Tabelle stages gespeichert sind;
- Job. Kombiniert eine oder mehrere Aufgaben, die in der jobs gespeichert sind;
- Aufgabe. Kombiniert in der Regel mehrere Testdurchläufe, die in der Tabelle tasks gespeichert werden.
Die möglichen Statuswerte sind für jede dieser vier Objektklassen gleich und können einen der folgenden Werte annehmen:
- Queued. Das Objekt wurde zur Bearbeitung in die Warteschlange gestellt.
- Process. Das Objekt wird gerade bearbeitet.
- Done. Die Objektbehandlung ist abgeschlossen oder wurde nicht gestartet.
Beschreiben wir die Regeln für die Änderung des Status von Objekten in der Datenbank in Übereinstimmung mit dem normalen Zyklus des Ablaufs für die automatische Projektoptimierung. Der Zyklus beginnt, wenn ein Projekt für die Optimierung in die Warteschlange gestellt wird, d.h. den Status „Queued“ erhält.
Wenn sich der Projektstatus in der Warteschlange ändert:
- setzen wir den Status aller Phasen dieses Projekts auf Queued.
Wenn sich der Status einer Phase in Warteschleife ändert:
- setzen wir den Status aller Aufträge in dieser Phase auf Queued.
Wenn der Auftragsstatus in der Warteschlange wechselt:
- setzen wir den Status aller Aufgaben dieses Auftrags auf Queued.
Wenn der Status der Aufgabe in der Warteschlange wechselt:
- löschen wir das Start- und Enddatum.
Die Änderung des Projektstatus auf „Queued“ führt also zu einer kaskadenartigen Aktualisierung der Status aller Phasen, Arbeiten und Aufgaben dieses Projekts auf „Queued“. Alle diese Objekte bleiben in diesem Status, bis die EA Optimization.ex5 gestartet wird.
Nach dem Start muss mindestens eine Aufgabe im Status „Queued“ gefunden werden. Später werden wir die Sortierreihenfolge bei mehreren Aufgaben betrachten. Der Status der Aufgabe ändert sich in Prozess. Dies führt zu den folgenden Aktionen:
Wenn der Status der Aufgabe auf „Process“ wechselt:
- setzen wir das Startdatum auf die aktuelle Uhrzeit;
- löschen wir alle zuvor im Rahmen der Aufgabe durchgeführten Durchgänge;
- setzen wir den Status des Auftrags, der mit dieser Aufgabe verbunden ist, auf Prozess.
Wenn der Auftragsstatus auf Prozess wechselt:
- setzen wir den Status der Phase, die mit diesem Auftrag verbunden ist, auf Prozess.
Wenn sich der Status einer Phase in Prozess ändert:
- setzen wir den Status des Projekts, das mit dieser Phase verbunden ist, auf Prozess.
Danach werden die Aufgaben im Rahmen der Projektphasen nacheinander ausgeführt. Weitere Statusänderungen können erst nach Abschluss der nächsten Aufgabe erfolgen. An diesem Punkt ändert sich der Aufgabenstatus in Erledigt und kann dazu führen, dass dieser Status an übergeordnete Objekte weitergegeben wird.
Wenn der Aufgabenstatus auf Done wechselt:
- setzen wir das Enddatum gleich der aktuellen Uhrzeit;
- rufen wir eine Liste aller Aufgaben in der Warteschlange ab, die Teil des Auftrags sind, in dem diese Aufgabe ausgeführt wird. Wenn es keine gibt, setzen wir den Status des mit dieser Aufgabe verbundenen Auftrags auf Done.
Wenn der Auftragsstatus auf Done wechselt:
- rufen wir eine Liste aller in der Warteschlange befindlichen Aufträge ab, die zu der Phase gehören, in der dieser Auftrag ausgeführt wird. Wenn es keine gibt, setzen wir den Status der mit dieser Arbeit verbundenen Phase auf Done.
Wenn der Status einer Phase auf Done wechselt:
- rufen wir eine Liste aller im Projekt enthaltenen Warteschlangenabschnitte ab, in denen dieser Abschnitt ausgeführt wird. Wenn es keine gibt, setzen wir den Status des mit dieser Phase verbundenen Projekts auf Done.
Wenn also die letzte Aufgabe des letzten Auftrags der letzten Phase abgeschlossen ist, wird das Projekt selbst in den Zustand completed übergehen.
Nachdem nun alle Regeln formuliert sind, können wir mit der Erstellung von Triggern in der Datenbank fortfahren, die diese Aktionen umsetzen.
Auslöser erstellen
Beginnen wir mit dem Auslöser für die Änderung des Projektstatus in der Warteschlange. Hier ist ein möglicher Weg, dies umzusetzen:
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
Nach der Fertigstellung werden auch die Projektphasen in die Warteschleife gestellt. Daher sollten wir die entsprechenden Auslöser für Phasen, Jobs und Aufgaben starten:
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END;
Der Start der Aufgabe wird durch den folgenden Auslöser abgewickelt, der das Startdatum der Aufgabe festlegt, die Durchlaufdaten des vorherigen Starts der Aufgabe löscht und den Auftragsstatus auf Prozess aktualisiert:
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
Anschließend werden die Phasen- und Projektstatus, innerhalb derer dieser Auftrag ausgeführt wird, an Process weitergegeben:
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
In dem Auslöser, der aktiviert wird, wenn der Aufgabenstatus auf Erledigt aktualisiert wird, d. h., wenn die Aufgabe erledigt ist, aktualisieren wir das Datum der Aufgabenerledigung und dann (je nach Vorhandensein oder Nichtvorhandensein anderer Aufgaben in der Warteschlange für die Ausführung innerhalb des aktuellen Aufgabenauftrags) aktualisieren wir den Auftragsstatus entweder auf Process oder Done:
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END;
Dasselbe gilt für den Status von Phasen und Projekten:
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
Wir werden auch die Möglichkeit bieten, alle Projektelemente in den Status „Erledigt“ zu versetzen, wenn dieser Status für das Projekt selbst gesetzt wird. Wir haben dieses Szenario nicht in die obige Liste der Regeln aufgenommen, da es sich nicht um eine obligatorische Aktion im normalen Verlauf der automatischen Optimierung handelt. In diesem Auslöser setzen wir den Status aller nicht ausgeführten oder laufenden Aufgaben auf Erledigt, was dazu führt, dass alle Projektaufträge und -phasen denselben Status erhalten:
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
Sobald alle diese Auslöser erstellt sind, müssen wir herausfinden, wie wir die Reihenfolge der Aufgabenausführung festlegen.
Ablauf
Da wir bisher nur mit einem Projekt in der Datenbank gearbeitet haben, wollen wir uns zunächst die Regeln für die Bestimmung der Reihenfolge der Aufgaben in diesem Fall ansehen. Sobald wir verstanden haben, wie die Reihenfolge der Aufgaben für ein Projekt festgelegt wird, können wir über die Reihenfolge der Aufgaben für mehrere gleichzeitig gestartete Projekte nachdenken.
Natürlich können Optimierungsaufgaben, die sich auf dieselbe Aufgabe beziehen und sich nur im Optimierungskriterium unterscheiden, in beliebiger Reihenfolge durchgeführt werden: der sequentielle Start der genetischen Optimierung für verschiedene Kriterien nutzt keine Informationen aus früheren Optimierungen. Um die Vielfalt der gefundenen guten Parameterkombinationen zu erhöhen, werden verschiedene Optimierungskriterien verwendet. Es wurde beobachtet, dass genetische Optimierungen mit denselben Bereichen von versuchten Eingaben, wenn auch mit unterschiedlichen Kriterien, zu unterschiedlichen Kombinationen konvergieren.
Daher ist es nicht erforderlich, der Aufgabentabelle ein Sortierfeld hinzuzufügen. Wir können die Reihenfolge verwenden, in der die Aufgaben eines Auftrags in die Datenbank aufgenommen wurden, d.h. wir können sie nach id_task sortieren.
Wenn es nur eine Aufgabe innerhalb eines Auftrags gibt, hängt die Reihenfolge der Ausführung von der Ausführungsreihenfolge der Aufträge ab. Die Aufträge wurden so konzipiert, dass sie Aufgaben gruppieren oder, genauer gesagt, in verschiedene Kombinationen von Symbolen und Zeitrahmen unterteilen. Betrachten wir ein Beispiel mit drei Symbolen (EURGBP, EURUSD, GBPUSD) und zwei Zeitrahmen (H1, M30) und zwei Phasen (Stage1, Stage2), dann können wir zwei mögliche Aufträge auswählen:
- Gruppierung nach Symbol und Zeitrahmen:
- EURGBP H1 Stage1
- EURGBP H1 Stage2
- EURGBP M30 Stage1
- EURGBP M30 Stage2
- EURUSD H1 Stage1
- EURUSD H1 Stage2
- EURUSD M30 Stage1
- EURUSD M30 Stage2
- GBPUSD H1 Stage1
- GBPUSD H1 Stage2
- GBPUSD M30 Stage1
- GBPUSD M30 Stage2
- Gruppierung nach Phasen:
- Stage1 EURGBP H1
- Stage1 EURGBP M30
- Stage1 EURUSD H1
- Stage1 EURUSD M30
- Stage1 GBPUSD H1
- Stage1 GBPUSD M30
- Stage2 EURGBP H1
- Stage2 EURGBP M30
- Stage2 EURUSD H1
- Stage2 EURUSD M30
- Stage2 GBPUSD H1
- Stage2 GBPUSD M30
Mit der ersten Methode der Gruppierung (nach Symbol und Zeitrahmen), nach jedem Abschluss der zweiten Phase, werden wir in der Lage sein, etwas fertig, das heißt, die endgültige EA zu erhalten. Sie enthält Sätze einzelner Kopien von Handelsstrategien für die Symbole und Zeitrahmen, die bereits beide Optimierungsstufen durchlaufen haben.
Bei der zweiten Methode der Gruppierung (durch die Phasen) kann der endgültige EA erst dann auftreten, wenn alle Arbeiten der ersten Phase und mindestens eine Arbeit der zweiten Phase abgeschlossen sind.
Bei Aufträgen, die nur die Ergebnisse der vorherigen Schritte für dasselbe Symbol und denselben Zeitrahmen verwenden, gibt es keinen Unterschied zwischen den beiden Methoden. Aber wenn wir ein wenig in die Zukunft blicken, wird es eine weitere Phase geben, in der die Ergebnisse der zweiten Phasen für verschiedene Symbole und Zeitrahmen kombiniert werden. Wir sind noch nicht so weit, sie als automatische Optimierungsstufe zu implementieren, aber wir haben bereits eine EA-Phase dafür vorbereitet und sie sogar gestartet, wenn auch manuell. Für diese Phase ist die erste Gruppierungsmethode nicht geeignet, sodass wir die zweite Methode verwenden werden.
Es sei darauf hingewiesen, dass es, wenn wir weiterhin die erste Methode verwenden wollen, vielleicht ausreicht, mehrere Projekte für jede Kombination von Symbol und Zeitrahmen zu erstellen. Aber im Moment scheinen die Vorteile unklar zu sein.
Wenn wir also mehrere Aufträge innerhalb einer Phase haben, kann die Reihenfolge ihrer Ausführung beliebig sein, und bei Aufträgen verschiedener Phasen wird die Reihenfolge durch die Reihenfolge der Priorität der Phasen bestimmt. Mit anderen Worten, wie bei den Aufgaben ist es nicht notwendig, der Tabelle der Aufträge ein Sortierfeld hinzuzufügen. Wir können die Reihenfolge verwenden, in der die Aufträge einer Phase in die Datenbank aufgenommen wurden, d.h. wir sortieren sie nach id_job.
Um die Reihenfolge der Phasen zu bestimmen, können wir auch die bereits in der Tabelle der Phasen (stages) vorhandenen Daten verwenden. Ich habe dieser Tabelle das Feld für die übergeordnete Phase (id_parent_stage) ganz am Anfang hinzugefügt, aber es wurde noch nicht verwendet. Wenn wir nur zwei Zeilen in der Tabelle für zwei Phasen haben, ist es kein Problem, sie in der richtigen Reihenfolge zu erstellen - zuerst eine Zeile für die erste Phase und dann für die zweite. Wenn es mehr davon gibt und Phasen für andere Projekte auftauchen, wird es schwieriger, die richtige Reihenfolge manuell einzuhalten.
Nutzen wir also die Gelegenheit, eine Hierarchie von Ausführungsstufen aufzubauen, bei der jede Phase nach Beendigung ihrer übergeordneten Phase ausgeführt wird. Mindestens eine Phase sollte keine übergeordnete Phase haben, um in der Hierarchie an erster Stelle zu stehen. Schreiben wir eine Test-SQL-Abfrage, die Daten aus den Tabellen Aufgaben, Aufträge und Phasen kombiniert und alle Aufgaben der aktuellen Phase anzeigt. Wir fügen alle Felder in die Spaltenliste dieser Abfrage ein, damit wir die vollständigsten Informationen sehen können.
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

Abbildung 1. Ergebnisse einer Abfrage zur Ermittlung von Aufgaben der aktuellen Phase nach dem Start einer Aufgabe
Später werden wir die Anzahl der angezeigten Spalten reduzieren, wenn wir eine ähnliche Abfrage verwenden, um eine andere Aufgabe zu finden. In der Zwischenzeit sollten wir sicherstellen, dass wir die nächste Etappe (mit den dazugehörigen Aufträgen und Aufgaben) korrekt erhalten. Die in Abbildung 1 gezeigten Ergebnisse entsprechen dem Zeitpunkt, zu dem die Aufgabe mit id_task=3 gestartet wurde. Dies ist die Aufgabe, die zu id_job=10 gehört, die Teil von id_stage=10 ist. Diese Phase heißt „First“, gehört zu dem Projekt mit id_project=1 und hat keine übergeordnete Phase (parent_stage=NULL). Wir sehen, dass eine laufende Aufgabe dazu führt, dass der Status Prozess sowohl für die Aufgabe als auch für das Projekt, in dem diese Aufgabe ausgeführt wird, angezeigt wird. Der andere Auftrag mit id_job=5 hat jedoch immer noch den Status „Queued“ (in der Warteschlange), da noch keine der Auftragsaufgaben gestartet wurde.
Versuchen wir nun, die erste Aufgabe zu erledigen (indem wir das Statusfeld in der Tabelle einfach auf Done setzen), und sehen wir uns die Ergebnisse der gleichen Abfrage an:

Abb. 2. Ergebnisse einer Abfrage zur Ermittlung von Aufgaben der aktuellen Phase nach Abschluss einer laufenden Aufgabe
Wie Sie sehen, ist die abgeschlossene Aufgabe aus der Liste verschwunden, und die oberste Zeile wird nun von einer anderen Aufgabe eingenommen, die als Nächstes gestartet werden kann. So weit ist alles korrekt. Starten und erledigen wir nun die ersten beiden Aufgaben aus dieser Liste, und starten wir die dritte Aufgabe mit id_task=7 zur Ausführung:

Abb. 3. Ergebnisse einer Abfrage, um die Aufgaben der aktuellen Phase zu erhalten, nachdem die Aufgaben des ersten Auftrags abgeschlossen sind und die nächste Aufgabe begonnen wurde
Jetzt hat der Auftrag mit id_job=5 den Status Process erhalten. Als Nächstes führen wir die drei Aufgaben aus, die jetzt in den Ergebnissen der letzten Abfrage angezeigt werden, und erledigen sie. Sie werden nach und nach aus den Abfrageergebnissen verschwinden. Nachdem die letzte Abfrage abgeschlossen ist, führen wir die Abfrage erneut aus und erhalten das folgende Ergebnis:

Abb. 4. Ergebnisse einer Abfrage, um die Aufgaben der aktuellen Phase zu erhalten, nachdem alle Aufgaben der ersten Phase erledigt sind
Die Abfrageergebnisse enthalten nun Aufgaben aus den Aufträgen der folgenden Phasen. id_stage=2 ist die Gruppierung der Ergebnisse der ersten Phase, während id_stage=3 die zweite Phase ist, auf der die Gruppierung der guten Beispiele für Handelsstrategien aus der ersten Phase erfolgt. In dieser Phase wird kein Clustering verwendet, sodass sie unmittelbar nach der ersten Phase durchgeführt werden kann. Es ist also kein Fehler, dass es auf dieser Liste steht. Beide Phasen haben eine übergeordnete Phase mit dem Namen First, die sich jetzt im Zustand Done befindet.
Simulieren wir den Start und den Abschluss der ersten beiden Aufgaben und betrachten wir die Abfrageergebnisse erneut:

Abb. 5. Ergebnisse einer Abfrage, um Aufgaben zu erhalten, nachdem alle Aufgaben der Clustering-Phase abgeschlossen sind
Die obersten Zeilen der Ergebnisse werden erwartungsgemäß von zwei Aufgaben der zweiten Phase (genannt „Second“) belegt, aber die letzten beiden Zeilen enthalten nun Aufgaben der zweiten Phase mit Clustering (genannt „Second with clustering“). Ihr Auftreten ist etwas unerwartet, widerspricht aber nicht der zulässigen Reihenfolge. Wenn wir das Clustering bereits abgeschlossen haben, können wir auch die Phase starten, in der die Ergebnisse des Clustering verwendet werden. Die beiden Schritte, die in den Abfrageergebnissen angezeigt werden, sind unabhängig voneinander, sodass sie in beliebiger Reihenfolge durchgeführt werden können.
Lassen Sie uns jede Aufgabe noch einmal ausführen und abschließen, wobei wir jeweils die oberste Aufgabe in den Ergebnissen auswählen. Die Liste der Aufgaben, die nach jeder Statusänderung empfangen wurde, verhielt sich wie erwartet, die Status von Aufträgen und Phasen änderten sich korrekt. Nach Abschluss der letzten Aufgabe waren die Abfrageergebnisse leer, da alle zugewiesenen Aufgaben aller Aufträge aller Phasen abgeschlossen waren und das Projekt in den Status Erledigt überging.
Lassen Sie uns diese Abfrage in den optimierenden EA integrieren.
Modifikation des optimierenden EA
Wir müssen Änderungen an der Methode zum Abrufen der ID der nächsten Optimierungsaufgabe vornehmen, wenn es bereits eine SQL-Abfrage gibt, die diese Aufgabe ausführt. Nehmen wir die oben entwickelte Abfrage und entfernen die zusätzlichen Felder, sodass nur id_task übrig bleibt. Wir können auch die Sortierung nach einigen Feldern der Jobtabelle (j.symbol, j.period) durch j.id_job ersetzen, da jeder Job nur einen Wert in diesen beiden Feldern hat. Am Ende fügen wir eine Begrenzung der Anzahl der zurückgegebenen Zeilen hinzu. Wir benötigen nur eine Zeile.
Die Methode GetNextTaskId() sieht nun wie folgt aus:
//+------------------------------------------------------------------+ //| Get the ID of the next optimization task from the queue | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... here we get the query result return res; }
Da wir uns entschieden haben, mit dieser Datei zu arbeiten, nehmen wir eine weitere Änderung vor: Wir entfernen die Übergabe des Status über den Methodenparameter aus der Methode zur Ermittlung der Anzahl der Aufgaben in der Warteschlange. In der Tat verwenden wir diese Methode nie, um die Anzahl der Aufgaben mit dem Status „Queued“ und „Process“ zu ermitteln, die dann einzeln und nicht als Summe verwendet werden. Ändern wir also die SQL-Abfrage in der Methode TotalTasks() so, dass sie immer die Gesamtzahl der Aufgaben mit diesen beiden Status zurückgibt, und entfernen wir die Statuseingabe der Methode:
//+------------------------------------------------------------------+ //| Get the number of tasks with the specified status | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Result int res = 0; // Request to get the number of tasks with the specified status string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... here we get the query result return res; }
Speichern wir die Änderungen in der Datei Optimizer.mqh des aktuellen Ordners.
Zusätzlich zu diesen Änderungen müssen wir auch die alte Statusbezeichnung „Processing“ in mehreren Dateien durch „Process“ ersetzen, da wir uns oben darauf geeinigt haben, sie zu verwenden.
Es wäre auch nützlich, die Möglichkeit zu haben, Informationen über Fehler zu erhalten, die während der Ausführung der Aufgabe, die das Python-Programm startet, aufgetreten sind. Wenn ein solches Programm abnormal beendet wird, bleibt der optimierende EA einfach in der Phase stecken, in der er darauf wartet, dass die Aufgabe abgeschlossen wird, oder genauer gesagt, dass Informationen über dieses Ereignis in der Datenbank erscheinen. Wenn das Programm mit einem Fehler endet, kann es den Aufgabenstatus in der Datenbank nicht aktualisieren. Dadurch kann sich der Ablauf in diesem Stadium nicht fortsetzen.
Bisher besteht die einzige Möglichkeit, dieses Hindernis zu überwinden, darin, das Python-Programm manuell mit den in der Aufgabe angegebenen Parametern erneut auszuführen, die Fehlerursachen zu analysieren, sie zu beseitigen und das Programm erneut auszuführen.
Änderungen von SimpleVolumesStage3.mq5
Als Nächstes planten wir, die dritte Phase zu automatisieren, in der wir für jeden Auftrag der zweiten Phase (die sich durch das verwendete Symbol und den Zeitrahmen unterscheiden) den besten Durchlauf zur Aufnahme in den endgültigen EA auswählen.
Bislang hat der EA für Phase 3 eine Liste von Phase-2-Pass-IDs als Eingabe verwendet, und wir mussten diese IDs irgendwie manuell aus der Datenbank auswählen. Abgesehen davon hat dieser EA nur die Erstellung, die Bewertung der Inanspruchnahme und die Speicherung einer Gruppe dieser Pässe in der Bibliothek durchgeführt. Die endgültige EA wurde nicht als Ergebnis des Starts der dritten Phase der EA erstellt, da eine Reihe anderer Maßnahmen erforderlich war. Wir werden später auf die Automatisierung dieser Aktionen zurückkommen, aber jetzt wollen wir erst einmal die dritte Phase des EA modifizieren.
Es gibt verschiedene Methoden, die zur automatischen Auswahl von Pass-IDs verwendet werden können.
Zum Beispiel können wir aus allen Ergebnissen der Durchgänge, die wir im Rahmen einer Arbeit der zweiten Phase erhalten haben, den besten im Hinblick auf den Indikator des normalisierten durchschnittlichen Jahresgewinns auswählen. Ein solcher Durchlauf wiederum ist das Ergebnis einer Gruppe von 16 einzelnen Instanzen von Handelsstrategien. Der endgültige EA wird dann eine Gruppe von mehreren Gruppen von Instanzen einzelner Strategien enthalten. Wenn wir drei Symbole und zwei Zeitrahmen nehmen, dann haben wir in der zweiten Phase 6 Aufträge. In der dritten Phase erhalten wir dann eine Gruppe, die 6 * 16 = 96 Kopien einzelner Strategien umfasst. Diese Methode ist am einfachsten zu realisieren.
Ein Beispiel für eine komplexere Auswahlmethode ist folgende: Für jeden Auftrag der zweiten Phase nehmen wir eine Anzahl der besten Durchgänge und versuchen verschiedene Kombinationen aus allen ausgewählten Durchgängen. Dies ist sehr ähnlich zu dem, was wir in der zweiten Phase gemacht haben, nur dass wir jetzt eine Gruppe nicht aus 16 einzelnen Instanzen rekrutieren, sondern aus 6 Gruppen, und in der ersten der sechs Gruppen nehmen wir einen der besten Durchgänge des ersten Jobs, in der zweiten - einen der besten Durchgänge des zweiten Jobs, und so weiter. Diese Methode ist komplizierter, aber es ist unmöglich, im Voraus zu sagen, dass sie die Ergebnisse erheblich verbessern wird.
Daher werden wir zunächst die einfachere Methode anwenden und die kompliziertere auf später verschieben.
In diesem Stadium brauchen wir die EA-Parameter nicht mehr zu optimieren. Dies wird nun ein einziger Durchgang sein. Dazu müssen wir die entsprechenden Parameter in den Phaseneinstellungen in der Datenbank angeben: Die Optimierungsspalte sollte 0 sein.

Abb. 6. Inhalt der Tabelle „stages“
Im EA-Code fügen wir die ID der Optimierungsaufgabe zu den Eingaben hinzu, damit dieser EA in der Förderanlage gestartet werden kann und die Ergebnisse des Durchlaufs korrekt in der Datenbank gespeichert werden:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "database911.sqlite"; // - File with the main database input group "::: Selection for the group" input string passes_ = ""; // - Comma-separated pass IDs input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
Der Parameter passes_ kann entfernt werden, aber ich lasse ihn vorsichtshalber noch stehen. Schreiben wir eine SQL-Abfrage, die eine Liste der besten Pass-IDs für die Aufträge der zweiten Phase liefert. Wenn der Parameter passes_ leer ist, werden die IDs der besten Pässe verwendet. Wenn der Parameter passes_ bestimmte IDs weitergibt, werden diese angewendet.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect(fileName_)) { // Form a request to receive passes with the specified IDs string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Successful initialization return(INIT_SUCCEEDED); }
Wir speichern die an der Datei SimpleVolumesStage3.mq5 vorgenommenen Änderungen im aktuellen Ordner.
Damit sind die Änderungen der dritten Phase der EA abgeschlossen. Verschieben wir das Projekt in der Datenbank in die Warteschlange und starten wir den optimierenden EA.
Optimierung der Ablaufergebnisse
Obwohl wir noch nicht alle geplanten Schritte umgesetzt haben, verfügen wir jetzt schon über ein Werkzeug, das automatisch einen fast fertigen EA liefert. Nach Abschluss der dritten Phase haben wir zwei Einträge in der Parameter-Bibliothek (Tabelle strategy_groups):

Der erste enthält die ID des Durchgangs, in dem die besten Gruppen der zweiten Phase ohne Clustering zusammengefasst werden. Die zweite ist die ID des Durchgangs, in dem die besten Gruppen der zweiten Phase mit Clustering zusammengefasst werden. Dementsprechend können wir für diese Pass-IDs die Initialisierungszeichenfolgen aus der Tabelle passes abrufen und die Ergebnisse dieser beiden Kombinationen betrachten.
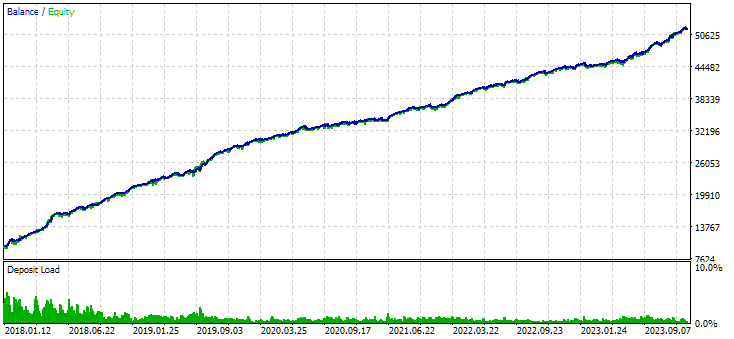
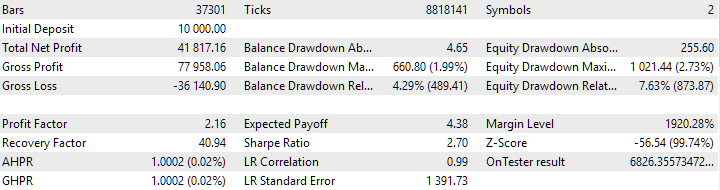
Abb. 7. Ergebnisse der kombinierten Gruppe von Instanzen, die ohne Clustering ermittelt wurden
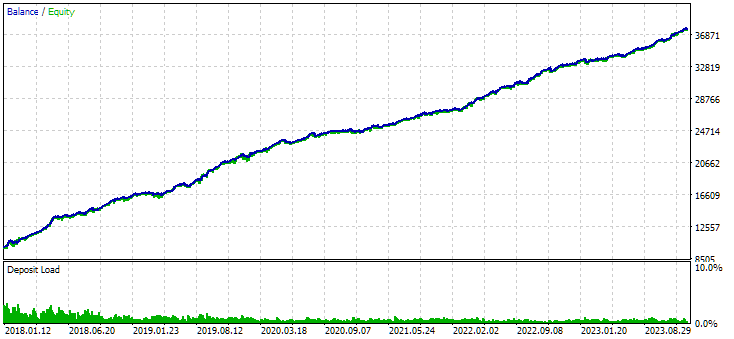
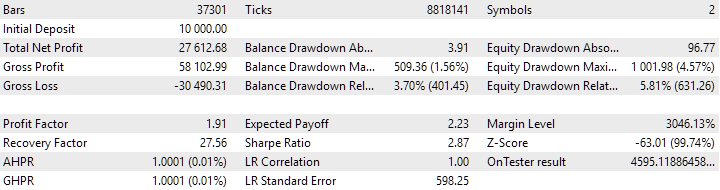
Abb. 8. Ergebnisse der kombinierten Gruppe von Instanzen, die durch Clustering erhalten wurden
Die Variante ohne Clustering zeigt den höheren Gewinn. Die Variante mit Clustering weist jedoch eine höhere Sharpe Ratio und eine bessere Linearität auf. Wir werden diese Ergebnisse jedoch vorerst nicht im Detail analysieren, da sie noch nicht endgültig sind.
Der nächste Schritt ist das Hinzufügen von Phasen für den Zusammenbau des endgültigen EA. Wir müssen die Bibliothek exportieren, um die Include-Datei ExportedGroupsLibrary.mqh im Datenordner zu erhalten. Dann sollten wir diese Datei in den Arbeitsordner kopieren. Dieser Vorgang kann entweder mit einem Python-Programm oder mit den Systemkopierfunktionen der DLL durchgeführt werden. In der letzten Phase müssen wir nur noch den endgültigen EA kompilieren und das Terminal mit der neuen EA-Version starten.
All dies erfordert eine beträchtliche Menge an Zeit für die Umsetzung, sodass wir die Beschreibung im nächsten Artikel fortsetzen werden.
Schlussfolgerung
Schauen wir uns also an, was wir haben. Wir haben die automatische Ausführung der ersten Phasen des automatischen OptimierungsAblaufs in Auftrag gegeben und deren korrekte Funktionsweise erreicht. Wir können uns die Zwischenergebnisse ansehen und z. B. entscheiden, den Schritt des Clusterns aufzugeben. Oder aber Sie lassen es und entfernen die Option ohne Clustering.
Mit einem solchen Instrument können wir in Zukunft Experimente durchführen und versuchen, schwierige Fragen zu beantworten. Nehmen wir zum Beispiel an, dass wir in der ersten Phase eine Optimierung für verschiedene Bereiche von Eingaben durchführen. Was ist besser - sie getrennt oder zusammen mit denselben Symbolen und Zeitrahmen zu kombinieren?
Durch das Hinzufügen von Phasen zum Ablauf können wir die schrittweise Montage von immer komplexeren EA realisieren.
Schließlich können wir die Frage der partiellen Re-Optimierung und sogar der kontinuierlichen Re-Optimierung durch die Durchführung eines entsprechenden Experiments prüfen. Re-Optimierung bedeutet hier die wiederholte Optimierung in einem anderen Zeitintervall. Aber dazu beim nächsten Mal mehr.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Wichtige Warnung
Alle in diesem Artikel und in allen vorangegangenen Artikeln dieser Reihe vorgestellten Ergebnisse beruhen lediglich auf historischen Testdaten und sind keine Garantie für zukünftige Gewinne. Die Arbeiten im Rahmen dieses Projekts haben Forschungscharakter. Alle veröffentlichten Ergebnisse können von jedermann auf eigenes Risiko verwendet werden.
Inhalt des Archivs
| # | Name | Version | Beschreibung | Jüngste Änderungen |
|---|---|---|---|---|
| MQL5/Experten/Artikel.16134 | ||||
| 1 | Advisor.mqh | 1.04 | EA-Basisklasse | Teil 10 |
| 2 | ClusteringStage1.py | 1.01 | Programm zum Clustern der Ergebnisse der ersten Optimierungsstufe | Teil 20 |
| 3 | Database.mqh | 1.07 | Klasse für den Umgang mit der Datenbank | Teil 19 |
| 4 | database.sqlite.schema.sql | 1.05 | Struktur der Datenbank | Teil 20 |
| 5 | ExpertHistory.mqh | 1.00. | Klasse für den Export der Handelshistorie in eine Datei | Teil 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Generierte Datei mit den Namen der Strategiegruppen und dem Array ihrer Initialisierungszeichenfolgen | Teil 17 |
| 7 | Factorable.mqh | 1.02 | Basisklasse von Objekten, die aus einer Zeichenkette erstellt werden | Teil 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Klasse für die Arbeit mit einer Bibliothek ausgewählter Strategiegruppen | Teil 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00. | EA für die Wiedergabe der Historie von Geschäften mit dem Risikomanager | Teil 16 |
| 10 | HistoryStrategy.mqh | 1.00. | Klasse der Handelsstrategie für die Wiederholung der Handelshistorie | Teil 16 |
| 11 | Interface.mqh | 1.00. | Basisklasse zur Visualisierung verschiedener Objekte | Teil 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA, der Initialisierungszeichenfolgen ausgewählter Durchläufe aus der Bibliothek in der Datei ExportedGroupsLibrary.mqh speichert | Teil 18 |
| 13 | Macros.mqh | 1.02 | Nützliche Makros für Array-Operationen | Teil 16 |
| 14 | Money.mqh | 1.01 | Grundkurs Geldmanagement | Teil 12 |
| 15 | NewBarEvent.mqh | 1.00. | Klasse zur Definition eines neuen Balkens für ein bestimmtes Symbol | Teil 8 |
| 16 | Optimization.mq5 | 1.03 | EA verwaltet die Einleitung von Optimierungsaufgaben | Teil 19 |
| 17 | Optimizer.mqh | 1.01 | Klasse für den Projektautooptimierungsmanager | Teil 20 |
| 18 | OptimizerTask.mqh | 1.01 | Klasse der Optimierungsaufgaben | Teil 20 |
| 19 | Receiver.mqh | 1.04 | Basisklasse für die Umwandlung von offenen Volumina in Marktpositionen | Teil 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00. | Vereinfachter EA für die Wiedergabe des Geschäftsverlaufs | Teil 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA für den parallelen Betrieb von mehreren Gruppen von Modellstrategien. Die Parameter werden aus der integrierten Gruppenbibliothek übernommen. | Teil 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Handelsstrategie Einzelinstanzoptimierung EA (Phase 1) | Teil 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Handelsstrategien Instanzen Gruppe Optimierung EA (Phase 2) | Teil 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | Der EA, der eine generierte standardisierte Gruppe von Strategien in einer Bibliothek von Gruppen mit einem bestimmten Namen speichert. | Teil 20 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Klasse der Handelsstrategie mit Tick-Volumen | Teil 15 |
| 26 | Strategy.mqh | 1.04 | Handelsstrategie-Basisklasse | Teil 10 |
| 27 | TesterHandler.mqh | 1.05 | Klasse zur Behandlung von Optimierungsereignissen | Teil 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Klasse des EA, der virtuelle Positionen (Aufträge) bearbeitet | Teil 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Grafische virtuelle Positionsklasse | Teil 18 |
| 30 | VirtualFactory.mqh | 1.04 | Objekt-Fabrik-Klasse | Teil 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00. | Die Klasse des EA zur Wiederholung des Handelsverlaufs | Teil 16 |
| 32 | VirtualInterface.mqh | 1.00. | EA GUI-Klasse | Teil 4 |
| 33 | VirtualOrder.mqh | 1.07 | Klasse der virtuellen Aufträge und Positionen | Teil 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Klasse für die Umwandlung von offenen Volumina in Marktpositionen (Empfänger) | Teil 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Klasse Risikomanagement (Risikomanager) | Teil 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Klasse einer Handelsstrategie mit virtuellen Positionen | Teil 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00. | Klasse der Handelsstrategien Gruppe(n) | Teil 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00. | Symbol-Empfängerklasse | Teil 3 |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16134
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo Yuriy
ich habe Google Translate benutzt, um zu Teil 20 zu gelangen. Googeln Sie "Google Translate" und öffnen Sie eine neue Registerkarte im Browser. In der Suchleiste ganz rechts wird ein Symbol angezeigt. Laden Sie die Seite in ihrer Muttersprache und drücken Sie auf das Symbol, um die Sprache des Artikels und die Sprache, in die übersetzt werden soll, auszuwählen. Und schon bin ich bei Teil 20! Die Übersetzung ist zwar nicht perfekt, aber zu 99 % nützlich.
Ich habe Ihre Archivquelle in Excel geladen und ein paar Spalten zum Sortieren hinzugefügt, um den Inhalt zu ordnen. Neben der Sortierung in Excel kann die Tabelle auch direkt in eine OutLook-Datenbank importiert werden.
Ich habe Probleme, den Startartikel für die Einrichtung der SQL-Datenbank zu identifizieren. Ich habe versucht, Simple Volume Stage 1 auszuführen und erhielt eine flache Linie, was mir zeigt, dass ich wahrscheinlich zurückgehen und eine andere SQL-Datenbank erstellen muss. Es wäre äußerst hilfreich, eine Tabelle mit der Reihenfolge der Ausführung der erforderlichen Programme zu haben, um ein funktionierendes System zu erhalten. Vielleicht könnte man sie in die Tabelle der Archivquellen aufnehmen.
Eine weitere kleine Bitte ist die Verwendung der <>-Option für Include-Dateispezifikationen anstelle von "". Ich halte Ihr System in meinen Verzeichnissen Experts und Include getrennt, #include <!!!! MultiCurrency\VirtualAdvisor.mqh>, so dass diese Änderung das Hinzufügen der Unterverzeichnisspezifikation/ erleichtern wird.
Vielen Dank für Ihren Beitrag
CapeCoddah
Hallo.
Über die anfängliche Befüllung der Datenbank mit Informationen über das Projekt, die Phasen, Arbeiten und Aufgaben können Sie in den Teilen 13, 18 und 19 lesen. Dies ist nicht das Hauptthema, so dass die Informationen, die Sie benötigen, irgendwo näher am Ende der Artikel zu finden sind. Zum Beispiel in Teil 18:
Oder in Teil 19:
Oder Sie warten auf den nächsten Artikel, der sich unter anderem mit der Erstbefüllung der Datenbank mit Hilfe eines Hilfsskripts befassen wird.
Die Umstellung auf die Verwendung des Include-Ordners für die Speicherung von Bibliotheksdateien ist geplant, aber es ist noch nicht so weit.
Vielen Dank
Hallo Yuriy,
Haben Sie den nächsten Artikel eingereicht oder wissen Sie, wann er veröffentlicht wird?