
Neuronale Netze leicht gemacht (Teil 29): Der Algorithmus Advantage Actor Critic

Inhalt
- Einführung
- 1. Vorteile der zuvor diskutierten Methoden des Reinforcement Learning
- 2. Vorteil des Advantage Actor Critic-Algorithmus
- 3. Umsetzung
- 4. Tests
- Schlussfolgerung
- Liste der Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir studieren weiterhin das Verstärkungslernen, das Reinforcement Learning. In früheren Artikeln haben wir Methoden zur Annäherung an die Q-Learning-Belohnungsfunktion und das Erlernen der Policy-Gradientenfunktion diskutiert. Jede Methode hat ihre eigenen Vor- und Nachteile. Es wäre schön, wenn man ihre Vorteile bei der Erstellung und Ausbildung von Modellen optimal nutzen könnte. Bei der Suche nach Methoden, die die Unzulänglichkeiten der verwendeten Algorithmen minimieren, versuchen wir oft, bestimmte Konglomerate aus verschiedenen bekannten Algorithmen und Methoden zu bilden. In diesem Artikel werden wir über eine Möglichkeit sprechen, die beiden oben genannten Algorithmen in einer einzigen Modelltrainingsmethode zu kombinieren, dem Algorithmus Advantage Actor Criticzu deutsch Vorteil von Akteur und sein Kritiker.
1. Vorteile der zuvor diskutierten Methoden des Reinforcement Learning
Doch bevor wir mit der Kombination der Algorithmen fortfahren, wollen wir noch einmal auf ihre besonderen Merkmale, Stärken und Schwächen zurückkommen.
Wenn der Agent mit der Umwelt interagiert, führt er eine Aktion aus, die die Umwelt beeinflusst. Infolge des Einflusses externer Faktoren und der Aktionen des Agenten ändert sich der Zustand der Umwelt. Nach jeder Zustandsänderung informiert die Umwelt den Agenten, indem sie eine Belohnung anbietet. Die Belohnungen können positiv oder negativ sein. Die Größe und das Vorzeichen der Belohnung zeigen an, wie nützlich der neue Zustand für den Agenten ist. Der Agent weiß nicht, wie sich die Belohnungen zusammensetzen. Das Ziel des Agenten ist es, zu lernen, solche Handlungen auszuführen, damit er im Prozess der Interaktion mit der Umwelt die höchstmögliche Belohnung erhält.
Wir haben zunächst den Algorithmus zur Annäherung an die Belohnungsfunktion untersucht Q-learning. Wir haben das Modell so trainiert, dass es lernt, die bevorstehende Belohnung vorherzusagen, nachdem eine bestimmte Handlung in einem bestimmten Zustand der Umgebung ausgeführt wurde. Danach führt der Agent eine Aktion aus, die auf der vorhergesagten Belohnung und den Verhaltensregeln des Agenten basiert. In der Regel wird hier die gierige oder ɛ-greedy Strategie verwendet. Bei der gierigen Strategie wählen wir die Aktion mit der höchsten vorhergesagten Belohnung. Sie wird am häufigsten in der praktischen Arbeit des Agenten verwendet.
Die zweite ɛ-greedy-Strategie ähnelt der gierigen Strategie nicht nur im Namen. Es geht auch darum, die Handlung mit der höchsten vorausgesagten Belohnung zu wählen. Aber es erlaubt eine zufällige Aktion mit der Wahrscheinlichkeit ɛ. Sie wird in der Phase der Modellschulung verwendet, um die Umwelt besser zu untersuchen. Andernfalls wird das Modell, nachdem es einmal eine positive Belohnung erhalten hat, dieselbe Handlung ständig wiederholen, ohne andere Optionen zu erkunden. In diesem Fall wird er nie erfahren, wie optimal die Aktion war oder ob es andere Aktionen gibt, die zu einer höheren Belohnung führen könnten. Aber wir wollen, dass der Agent die Umgebung so weit wie möglich erkundet und das Beste aus ihr herausholt.
Die Vorteile der Q-Learning-Methode liegen auf der Hand. Das Modell wird trainiert, um Belohnungen vorherzusagen. Es ist die Belohnung, die wir von der Umwelt erhalten. Es besteht also ein direkter Zusammenhang zwischen den Werten der Modellbetriebsergebnisse und den aus der Umwelt erhaltenen Referenzwerten. In dieser Auslegung ähnelt das Lernen den überwachten Lernmethoden. Beim Training des Modells haben wir den Standardfehler als Verlustfunktion verwendet.
Dabei sollten Sie auf Folgendes achten. Das trainierte Modell liefert die durchschnittliche kumulative Belohnung bis zum Ende der Sitzung, wobei der Rabattfaktor berücksichtigt wird, den der Agent von der Umwelt erhalten hat, nachdem er beim Trainieren des Modells eine bestimmte Aktion in einem ähnlichen Zustand der Umwelt ausgeführt hat. Aber die Umwelt gibt eine Belohnung für jeden spezifischen Übergang in einen neuen Zustand. Hier sehen wir die Lücke, die geschlossen wird, nachdem der Agent die Episode beendet hat.
Zu den Nachteilen des Algorithmus gehört die Komplexität der Modellschulung. Beim letzten Mal mussten wir einige Tricks anwenden, um das Modell zu trainieren. Zunächst einmal korrelieren die aufeinander folgenden Zustände der Umwelt stark miteinander. Meistens unterscheiden sie sich nur in kleinen Details. Ein direktes Training mit solchen Daten führt zu einer ständigen Nachschulung des Modells, um es an den aktuellen Zustand anzupassen. Dadurch verliert das Modell die Fähigkeit, Daten zu verallgemeinern. Daher mussten wir einen Puffer mit historischen Daten anlegen, auf denen das Modell trainiert wurde. Beim Training des Modells wählten wir zufällig Zustände aus dem historischen Datenspeicher, wodurch die Korrelation zwischen zwei Zuständen, die beim Training nacheinander verwendet wurden, reduziert werden konnte.
Durch das Training des Modells mit den tatsächlichen Daten der von der Umgebung erhaltenen Belohnung erhalten wir ein Modell mit geringer Datenvarianz. Die Streuung der vom Modell für jeden Zustand ermittelten Werte ist akzeptabel gering. Dies ist ein positiver Faktor. Aber die Umwelt gibt die Belohnung für jeden spezifischen Übergang zurück. Wir wollen jedoch den Gewinn für den gesamten Zeitraum maximieren. Um sie zu berechnen, muss der Agent die gesamte Sitzung absolvieren. Durch die Verwendung eines historischen Datenpuffers und die Hinzufügung eines Modells für die Vorhersage zukünftiger Belohnungen ist es uns gelungen, einen Algorithmus zu entwickeln, der das Modell im Laufe seiner praktischen Anwendung zusätzlich trainieren kann. Der Lernprozess läuft also im „Online“-Modus. Aber wir mussten dafür mit einem Fehler bei der Vorhersage der Belohnungen bezahlen.
Bei der Verwendung des zweiten Modells zur Vorhersage künftiger Gewinne waren wir uns der Fehlerhaftigkeit solcher Vorhersagen voll bewusst und nahmen das Risiko in Kauf. Aber jeder Fehler wurde beim Training des Modells berücksichtigt und beeinflusste alle nachfolgenden Vorhersagen. So erhielten wir ein Modell, das in der Lage ist, Ergebnisse mit einer geringen Varianz, aber einem großen Bias vorherzusagen. Dies kann bei der Verwendung einer gierigen Strategie vernachlässigt werden. Um die maximale Belohnung zu wählen, vergleichen wir sie nur mit anderen Belohnungen. Ein Bias oder Skalierung der Werte hat in diesem Fall keinen Einfluss auf das Endergebnis der Aktionsauswahl.

Bei der Verwendung von Q-learning wird das Modell nur für die Vorhersage von Belohnungen trainiert. Um die Aktionen auszuwählen, müssen wir die Verhaltenspolitik (Strategie) des Agenten in der Phase der Modellerstellung festlegen. Die Verwendung der gierigen Strategie ermöglicht jedoch nur in deterministischen Umgebungen eine erfolgreiche Arbeit. Dies ist bei der Entwicklung stochastischer Strategien völlig unangebracht.
Die Verwendung des Policy-Gradientenist es dagegen nicht erforderlich, die Verhaltenspolitik (Strategie) des Agenten in der Phase der Modellerstellung zu bestimmen. Diese Methode ermöglicht es dem Agenten, seine Verhaltensregeln zu erstellen. Sie kann entweder gierig oder stochastisch sein.
Das mit der Policy-Gradient-Methode trainierte Modell liefert die Wahrscheinlichkeitsverteilung für das Erreichen des gewünschten Ergebnisses bei der Wahl der einen oder anderen Aktion in jedem spezifischen Zustand der Umgebung.
Beim Training des Modells verwenden wir auch die von der Umwelt erhaltenen Belohnungen. Um die optimale Strategie in jedem Zustand der Umgebung zu wählen, wird eine kumulative Belohnung bis zum Ende der Sitzung verwendet. Um die Gewichte des Modells zu aktualisieren, muss der Agent natürlich die gesamte Sitzung durchlaufen. Vielleicht ist dies der größte Nachteil dieser Methode. Wir können kein Online-Trainingsmodell erstellen, weil wir die zukünftigen Belohnungen nicht kennen.
Gleichzeitig wird durch die Verwendung der tatsächlichen kumulativen Belohnung der konstante Fehler des Bias der vorhergesagten Daten von ihrem tatsächlichen Wert minimiert. Dies war das Problem beim Q-Learning, das auf der Verwendung vorhergesagter Werte für zukünftige Belohnungen beruht.
Beim Policy Gradient trainieren wir das Modell jedoch so, dass es nicht die erwartete Belohnung vorhersagt, sondern die Wahrscheinlichkeitsverteilung für das Erreichen des gewünschten Ergebnisses, wenn der Agent eine bestimmte Aktion in einem bestimmten Zustand der Umgebung ausführt. Als Verlustfunktion verwenden wir die logarithmische Funktion.

Um die Richtung der Fehlerminimierung analytisch zu bestimmen, verwenden wir die Ableitung der Verlustfunktion. In diesem Fall liegt die Bequemlichkeit in der Eigenschaft der Ableitung des Logarithmus.

Indem wir die Ableitung der Verlustfunktion mit der positiven Belohnung multiplizieren, erhöhen wir die Wahrscheinlichkeit, eine solche Handlung zu wählen. Und wenn wir die Ableitung der Verlustfunktion mit einer negativen Belohnung multiplizieren, passen wir unsere Gewichte in die entgegengesetzte Richtung an. Dadurch verringert sich die Wahrscheinlichkeit, diese Aktion zu wählen. Und der Moduluswert der Belohnung bestimmt den Schritt zur Anpassung der Gewichte.
Wie Sie sehen können, werden die Belohnungen bei der Aktualisierung der Gewichtsmatrix des Modells indirekt verwendet. Daher erhalten wir ein Modell, dessen Ergebnisse im Vergleich zu den realen Daten ein geringes Bias, aber eine ziemlich große Varianz der Werte aufweisen.

Zu den positiven Aspekten der Methode gehört die Möglichkeit, die Umwelt zu erkunden. Bei der Verwendung von Q-Learning und der ɛ-greedy-Strategie haben wir das Gleichgewicht zwischen Forschung und Ausbeutung mithilfe von ɛ bestimmt, während der Policy-Gradient eine Stichprobe von Aktionen aus einer bestimmten Verteilung verwendet.
Zu Beginn des Modelltrainings sind die Wahrscheinlichkeiten aller Aktionen nahezu gleich. Und das Modell untersucht die Umwelt bis zum Maximum und wählt die eine oder andere Aktion des Agenten mit gleicher Wahrscheinlichkeit. Im Laufe des Modelltrainings ändert sich die Wahrscheinlichkeitsverteilung der Aktionen. Die Wahrscheinlichkeit, profitable Aktionen zu wählen, steigt, während sie bei unprofitablen Aktionen sinkt. Dadurch wird die Tendenz des Modells zur Exploration verringert. Das Gleichgewicht verschiebt sich in Richtung Ausbeutung.
Achten Sie auf einen weiteren Punkt. Mit der kumulativen Belohnung konzentrieren wir uns darauf, am Ende der Sitzung ein Ergebnis zu erzielen. Und wir bewerten nicht die Auswirkungen der einzelnen Schritte. Ein solcher Ansatz kann den Agenten zum Beispiel darauf trainieren, unrentable Positionen zu halten und auf eine Trendwende zu warten. Oder der Agent kann lernen, eine große Anzahl von Verlustgeschäften zu tätigen, deren Verluste durch seltene profitable Geschäfte gedeckt werden, die hohe Gewinne abwerfen. Da das Modell am Ende der Sitzung den endgültigen Gewinn erhält und diesen als positives Ergebnis betrachtet, steigt die Wahrscheinlichkeit solcher Operationen. Natürlich sollte eine große Anzahl von Iterationen diesen Faktor minimieren, da die Fähigkeit der Methode, die Umgebung zu erkunden, dem Modell helfen sollte, die optimale Strategie zu finden. Dies führt jedoch zu einem langwierigen Modellbildungsprozess.
Fassen wir zusammen. Q-Learning-Modelle haben eine geringe Varianz, aber eine hohes Bias. Der Policy-Gradient hingegen ermöglicht das Training des Modells mit einem kleinen Bias und einer großen Varianz. Was wir brauchen, ist die Möglichkeit, das Modell mit minimaler Varianz und Bias zu trainieren.
Policy Gradient bildet eine ganzheitliche Strategie, ohne die Auswirkungen der einzelnen Schritte zu berücksichtigen. Wir müssen bei jedem Schritt den maximalen Gewinn erzielen, was mit Q-Learning möglich ist. Denken Sie an die Bellman-Funktion. Dabei wird davon ausgegangen, dass bei jedem Schritt die beste Aktion ausgewählt wird.
Die Verwendung von Q-Funktions-Approximationsmethoden erfordert die Definition der Verhaltenspolitik des Agenten in der Phase der Modellerstellung. Aber wir wollen, dass das Modell die Strategie selbst bestimmt, basierend auf den Erfahrungen der Interaktion mit der Umwelt. Und natürlich möchten wir uns nicht auf deterministische Verhaltensstrategien beschränken. Dies kann mit Hilfe von Schulungsmethoden umgesetzt werden.
Es liegt auf der Hand, dass die Lösung darin besteht, zwei Trainingsmethoden zu kombinieren, um die besten Ergebnisse zu erzielen.
2. Der Algorithmus Advantage Actor Critic
Die erfolgreichsten Versuche, Belohnungsfunktionsapproximation und Methoden des Policy Learning zu kombinieren, sind die Methoden der Actor-Critic-Familie. Machen wir uns heute mit dem Algorithmus Advantage Actor Critic vertraut.
Die Familie der Methoden von Actor Critic umfasst zwei Modelle. Eines der Modelle, der Actor, ist für die Auswahl der Aktionen des Agenten zuständig und wird mit Methoden zur Annäherung der Politikfunktion trainiert. Das zweite Modell, der Kritiker, wird durch Q-Learning-Methoden trainiert und bewertet die vom Akteur gewählten Aktionen.
Als erstes muss die Datenvarianz im Politikmodell reduziert werden. Werfen wir noch einen Blick auf die Verlustfunktion unseres Politikmodells. Jedes Mal multiplizieren wir den Logarithmus der vorhergesagten Wahrscheinlichkeit der gewählten Handlung mit der Höhe der kumulativen Belohnung, wobei die Diskontierung berücksichtigt wird. Der Wert der vorhergesagten Wahrscheinlichkeit ist im Bereich [0, 1] normalisiert.
![]()
Um die Varianz zu reduzieren, können wir den Wert der kumulativen Belohnung verringern. Sie sollte jedoch den Einfluss der Maßnahmen auf das Gesamtergebnis nicht beeinträchtigen. Gleichzeitig muss die Vergleichbarkeit der Daten für verschiedene Agententrainingseinheiten gewährleistet sein. Wir können zum Beispiel immer eine feste Konstante oder die durchschnittliche Belohnung für die gesamten Sitzungen abziehen.
![]()
Anschließend können wir das Modell trainieren, um den Beitrag jeder einzelnen Aktion zu bewerten. Die scheinbar einfache Idee, die kumulative Belohnung zu entfernen und nur die Belohnung für den aktuellen Übergang für das Training zu verwenden, kann einen unangenehmen Effekt haben. Zunächst einmal garantiert uns eine große Belohnung in der jetzigen Phase nicht die gleiche große Belohnung in der Zukunft. Wir können eine große Belohnung für den Übergang in einen ungünstigen Zustand erhalten. Man kann es mit „Käse in der Mausefalle“ vergleichen.
Andererseits hängt die Belohnung nicht immer von der Handlung ab. In den meisten Fällen hängt die Belohnung mehr vom Zustand der Umgebung ab als von der Fähigkeit des Agenten, diesen Zustand zu bewerten. Wenn der Agent beispielsweise Geschäfte in Richtung des globalen Trends tätigt, kann er Korrekturen gegen den Trend aussitzen und so lange warten, dass sich der Preis wieder in die richtige Richtung bewegt. Dazu muss der Agent den aktuellen Zustand nicht im Detail analysieren, um Trends zu erkennen. Es reicht aus, den globalen Trend richtig zu bestimmen. In diesem Fall besteht eine hohe Wahrscheinlichkeit, eine Position nicht zum besten Preis einzugehen. Mit einer detaillierten Analyse könnte er die Korrektur abwarten und zu einem besseren Preis einsteigen. Das Risiko von Verlusten ist jedoch viel höher, wenn sich die Korrektur zu einem Trendwechsel entwickelt. In diesem Fall führt die offene Position zu großen Verlusten, da es keine Umkehrung gibt.
Daher wäre es sinnvoll, die kumulierte Belohnung mit einem bestimmten Benchmark-Ergebnis zu vergleichen. Aber wie kann man auf diesen Wert zugreifen? Hier setzen wir Critic, den Kritiker, ein. Wir werden ihn nutzen, um die Arbeit des Akteurs zu bewerten.
Die Idee ist, dass das Critic-Modell darauf trainiert wird, den aktuellen Zustand der Umgebung zu bewerten. Dies ist die potenzielle Belohnung, die der Akteur im aktuellen Zustand vor dem Ende der Sitzung erhalten kann. Gleichzeitig lernt der Akteur, Handlungen auszuwählen, die potenziell überdurchschnittliche Belohnungen aus früheren Trainingseinheiten bringen. Wir ersetzen also die Konstante in der obigen Formel der Verlustfunktion durch die Zustandsschätzung.
![]()
wobei V(s) die Umweltzustandsbewertungsfunktion ist.
Zum Trainieren der Zustandsschätzungsfunktion verwenden wir wieder den mittleren quadratischen Fehler.
![]()
Es gibt verschiedene Ansätze zur Erstellung eines Modells mit diesem Algorithmus. Wir verwenden zwei getrennte neuronale Netze: eines für Actor, den Akteur, und das andere für Critic, dem Kritiker. Häufig wird jedoch eine Architektur mit einem neuronalen Netz und zwei Ausgängen verwendet. Es handelt sich um das so genannte „zweiköpfige“ neuronale Netz. Ein Teil der neuronalen Schichten in diesem Netz wird gemeinsam genutzt - sie sind für die Verarbeitung der Ausgangsdaten zuständig. Mehrere Entscheidungsebenen sind in Richtungen unterteilt. Einige von ihnen sind für die Modellpolitik zuständig (Actor, der Akteur). Andere sind für die Bewertung des Zustands zuständig (Critic). Sowohl der Akteur als auch der Kritiker arbeiten mit demselben Zustand der Umwelt. Daher können sie die gleiche Funktion der Zustandserkennung haben.
Es gibt auch Implementierungen für das Online-Training von Advantage Actor-Critic-Modellen. Ähnlich wie beim Q-Learning wird die kumulative Belohnung in ihnen durch die Summe der beim letzten Übergang erhaltenen Belohnung ersetzt, und der nachfolgende Zustand wird unter Berücksichtigung des Diskontierungsfaktors bewertet. In diesem Fall sehen die Verlustfunktionen wie folgt aus:
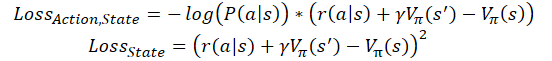
wobei ɣ der Diskontfaktor ist.
Aber die Online-Schulung hat ihren Preis. Ein solches Modell hat einen größeren Fehler und ist schwieriger zu trainieren.
3. Umsetzung
Nachdem wir uns nun mit den theoretischen Aspekten der Methode befasst haben, können wir zum praktischen Teil dieses Artikels übergehen und den Modellbildungsprozess mit Hilfe der MQL5-Tools aufbauen. Um den beschriebenen Algorithmus zu implementieren, benötigen wir keine grundlegenden Änderungen an der Architektur unserer Modelle. Wir werden kein zweigleisiges Modell bauen. Wir werden zwei neuronale Netze, Actor und Critic, mit den vorhandenen Mitteln aufbauen.
Außerdem werden wir nicht das gesamte Training der neuen Modelle durchführen. Stattdessen werden wir zwei Modelle aus den letzten beiden Artikeln verwenden. Als Kritiker wird das Modell aus dem Artikel über das Q-Learning verwendet. Und das Modell prom der Policy Gradient Artikel wird als Akteur dienen.
Bitte beachten Sie geringfügige Abweichungen von dem oben dargestellten theoretischen Material. Das Akteur-Modell entspricht vollständig den Anforderungen des betrachteten Algorithmus. Das von uns verwendete Kritiker-Modell unterscheidet sich jedoch geringfügig von der oben beschriebenen Funktion zur Schätzung des Umweltzustands. Die Bewertung des Umweltzustands hängt nicht von der vom Agenten durchgeführten Aktion ab. Der Wert eines Zustands ist der maximale Nutzen, den unser Agent aus diesem Zustand ziehen kann. Gemäß der Q-Funktion, die wir zuvor trainiert haben, sind die Kosten des Zustands gleich dem maximalen Wert aus dem Ergebnisvektor dieser Funktion. Für ein korrektes Modelltraining müssen wir jedoch die vom Agenten im analysierten Zustand durchgeführten Aktionen berücksichtigen.
Schauen wir uns nun den Code der Methodenimplementierung an. Um das Modell zu trainieren, erstellen wir einen EA namens Actor_Critic.mq5. Der EA verwendet eine Vorlage aus früheren Artikeln. Wir werden also zwei vortrainierte Modelle verwenden. Die Modelle wurden separat trainiert und in verschiedenen Dateien gespeichert. Daher werden wir zunächst Dateien zum Laden der Modelle definieren. Ihre Namen sind ein Hinweis auf die früheren Artikel.
#define ACTOR Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_REINFORCE" #define CRITIC Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_Q-learning"
Für zwei Modelle benötigen wir zwei Instanzen der Klasse Neuronales Netz. Um den Code übersichtlich zu halten, verwenden wir die mit den Namen korrespondierenden Rollen der Modelle im Algorithmus.
CNet Actor; CNet Critic;
Bei der EA-Initialisierungsmethode laden wir die Modelle und vergleichen sofort die Größen der Schichten der Ausgangsdaten und der Ergebnisse. Wenn wir die Modelle laden, können wir die Vergleichbarkeit der Modelle nicht bewerten, indem wir sie auf vergleichbaren Stichproben trainieren. Wir müssen jedoch die Vergleichbarkeit der Modellarchitekturen überprüfen. Insbesondere prüfen wir die Größe der Quelldatenschicht. So können wir sicher sein, dass beide Modelle dasselbe Zustandsbeschreibungsmuster zur Bewertung des Umweltzustands verwenden.
Anschließend überprüfen wir die Ergebnisschichten beider Modelle, was uns einen Vergleich der Diskretion der Handlungsmöglichkeiten der Agenten ermöglicht.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ................ ................ ................ //--- float temp1, temp2; if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) || !Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)) return INIT_FAILED; //--- if(!Actor.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; Actor.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; if(!vActions.Resize(SessionSize) || !vRewards.Resize(SessionSize) || !vProbs.Resize(SessionSize)) return INIT_FAILED; //--- if(!Critic.GetLayerOutput(0, TempData)) return INIT_FAILED; if(HistoryBars != TempData.Total() / 12) return INIT_PARAMETERS_INCORRECT; Critic.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; //--- ................ ................ ................ //--- return(INIT_SUCCEEDED); }
Vergessen wir nicht, den Prozess der Durchführung der Operationen zu kontrollieren und die erforderlichen Daten in den entsprechenden Variablen zu speichern. Wir speichern insbesondere die Anzahl der Kerzen eines analysierten Musters, die der Größe der Ausgangsdatenschicht der geladenen Modelle entspricht.
Der Trainingsprozess wird mit der Funktion Trainieren durchgeführt. Zu Beginn der Funktion legen wir wie immer den Bereich der Trainingsstichprobe fest.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
Laden historischer Daten. Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Bewertung der Menge der geladenen Daten und Vorbereitung der lokalen Variablen.
int total = bars - (int)(HistoryBars + SessionSize+2); //--- CBufferFloat* State; float loss = 0; uint count = 0;
Als Nächstes organisieren wir ein System von Modelltrainingsschleifen. Die äußere Schleife zählt die Anzahl der Trainingsepochen. Im Schleifenkörper legen wir also den Startpunkt der Sitzung fest. Sie wird nach dem Zufallsprinzip aus den geladenen historischen Daten ausgewählt. Bei der Wahl dieses Punktes sind 2 Faktoren zu berücksichtigen. Erstens müssen dem Startpunkt der Sitzung historische Daten vorausgehen, die ausreichen, um ein Muster zu bilden. Zweitens sollten vom Startpunkt der Sitzung bis zum Ende der Trainingsstichprobe genügend historische Daten vorhanden sein, um die Sitzung abzuschließen.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0, 1, error_code)), 1) * (total) + SessionSize);
Ich habe den Online-Lernalgorithmus nicht implementiert, da wir das Modell mit historischen Daten trainieren. Bei einer vollständigen Sitzung werden in der Regel bessere Ergebnisse erzielt. Gleichzeitig ist die Arbeit auf dem Markt aber auch endlos. Daher haben wir eine Batch-Implementierung des Algorithmus. Die Größe der Sitzung ist durch die Größe der Datenaktualisierungscharge begrenzt. Dieser Wert wird vom Nutzer mit dem externen Parameter SessionSize angegeben.
Erstellen wir dann eine verschachtelte Schleife für die erste Iteration der Sitzung. Im Hauptteil dieser Schleife legen wir zunächst ein Objekt an, das die Parameter der Systemzustandsbeschreibung aufnimmt. Vergessen wir nicht, das Ergebnis der Erstellung des neuen Objekts zu überprüfen.
States.Clear(); for(int batch = 0; batch < SessionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; }
Danach speichern wir die Parameter des aktuellen Umgebungszustands. So bereiten wir ein Muster für die Analyse im aktuellen Schritt des Algorithmus vor.
int r = i + (int)HistoryBars; if(r > bars) { delete State; continue; } for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) { delete State; continue; } //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) { delete State; break; } }
Wir überprüfen die Vollständigkeit der gespeicherten Daten und rufen die Methode für den Vorwärtsdurchlauf des Richtlinienmodells auf.
if(IsStopped()) { delete State; ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) { delete State; continue; } if(!Actor.feedForward(GetPointer(State), 12, true)) { delete State; ExpertRemove(); return; }
Aus der sich ergebenden Verteilung wird dann eine Stichprobe für die Aktion des Agenten gezogen.
Actor.getResults(TempData); int action = GetAction(TempData); if(action < 0) { delete State; ExpertRemove(); return; }
Bestimmen wir die Belohnung für die gewählte Aktion. Die Belohnungspolitik hat sich seit den letzten Versuchen im letzten Artikel nicht geändert. Daher plane ich, vergleichbare Testergebnisse der Methode zu erhalten. So können wir die Auswirkungen von Änderungen am Lernalgorithmus auf das Endergebnis des Modells im Vergleich zu früheren Tests vergleichen.
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -20; else reward *= 1; break; case 1: if(reward > 0) reward *= -20; else reward *= -1; break; default: if(batch == 0) reward = -fabs(reward); else { switch((int)vActions[batch - 1]) { case 0: reward *= -1; break; case 1: break; default: reward = -fabs(reward); break; } } break; }
Wir speichern die erhaltenen Werte in Puffern, um sie später zur Aktualisierung der Modellgewichte zu verwenden.
if(!States.Add(State)) { delete State; ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)reward; vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
Damit sind die Iterationen der ersten geschachtelten Schleife, in der Informationen über die Sitzung gesammelt werden, abgeschlossen. Nachdem wir alle Sitzungszustände durchlaufen haben, erhalten wir einen vollständigen Datensatz für die Aktualisierung der Modelle.
Dann berechnen wir die kumulierte, diskontierte Belohnung für jeden Zustand der Umgebung.
vectorf rewards = vectorf::Full(SessionSize, 1); rewards = MathAbs(rewards.CumSum() - SessionSize); rewards = (vRewards * MathPow(vectorf::Full(SessionSize, DiscountFactor), rewards)).CumSum(); rewards = rewards / fmax(rewards.Max(), fabs(rewards.Min()));
Berechnen wir nun den Wert der Verlustfunktion und speichern das Modell, wenn die besten Ergebnisse erzielt wurden.
loss = (fmin(count, 9) * loss + (rewards * MathLog(vProbs) * (-1)).Sum() / SessionSize) / fmin(count + 1, 10); count++; float total_reward = vRewards.Sum(); if(BestLoss >= loss) { if(!Actor.Save(ACTOR + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false) || !Critic.Save(CRITIC + ".nnw", Critic.getRecentAverageError(), 0, 0, Rates[shift - SessionSize].time, false)) return; BestLoss = loss; }
Bitte beachten Sie, dass wir die Modelle speichern, bevor wir die Gewichtsmatrizen aktualisieren. Denn dies sind die Parameter, mit denen das Modell die Ergebnisse erzielt, die wir mit der Verlustfunktion geschätzt haben. Nach der Aktualisierung der Matrizen erhält das Modell aktualisierte Parameter, und wir werden die Ergebnisse der neuen Parameter erst nach Abschluss der nächsten Sitzung sehen.
Am Ende der Iterationen der Lernepoche implementieren wir eine weitere verschachtelte Schleife, in der wir die Aktualisierung der Modellparameter organisieren. Hier werden wir die Umgebungszustände aus dem Puffer holen und beide Modelle durchlaufen, wobei der Zustand entfernt wird. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
for(int batch = SessionSize - 1; batch >= 0; batch--) { State = States.At(batch); if(!Actor.feedForward(State) || !Critic.feedForward(State)) { ExpertRemove(); return; }
Bitte beachten Sie, dass die Implementierung des Vorwärtsdurchgangs für jedes Modell obligatorisch ist. Auch wenn wir alle erforderlichen Daten in den Puffern gespeichert haben. Während des Backpropagation-Durchgangs verwendet der Lernalgorithmus nämlich Zwischendaten aus den Berechnungen der neuronalen Schichten. Um den Fehlergradienten korrekt zu verteilen und die Gewichte zu aktualisieren, benötigen wir eine klare Anordnung der kompletten Kette aller Zwischenwerte des Modells für jeden Zustand.
Aktualisieren wir dann den Parameter Critic. Achten Sie darauf, dass die Modellaktualisierung nur für die vom Agenten ausgewählte Aktion gilt. Die Steigung der verbleibenden Einwirkungen wird mit Null angesetzt. Dieser Unterschied zu dem zuvor beschriebenen theoretischen Material wird durch die Verwendung der vortrainierten Q-Funktion verursacht, die die vorhergesagte Belohnung in Abhängigkeit von der vom Agenten gewählten Aktion zurückgibt. Das von den Autoren der Methode vorgeschlagene Training der Zustandsschätzungsfunktion hängt nicht von der durchgeführten Aktion ab und erfordert keine derartigen Details.
Critic.getResults(TempData); float value = TempData.At(TempData.Maximum(0, 3)); if(!TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1])) { ExpertRemove(); return; } if(!Critic.backProp(TempData)) { ExpertRemove(); return; }
Nachdem wir die Parameter des Critic erfolgreich aktualisiert haben, aktualisieren wir in gleicher Weise die Parameter des Actor. Wie bereits erwähnt, verwenden wir zur Bewertung der vom Agenten gewählten Aktion den maximalen Wert des Ergebnisvektors der Q-Funktion für den analysierten Zustand der Umgebung.
if(!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1] - value)) { ExpertRemove(); return; } if(!Actor.backProp(TempData)) { ExpertRemove(); return; } } PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, total_reward, loss); }
Nach Abschluss aller Iterationen zur Aktualisierung der Modellparameter wird dem Nutzer eine Informationsmeldung angezeigt, und es wird mit der nächsten Epoche fortgefahren.
Das Modelltraining endet, wenn alle Epochen abgeschlossen sind, es sei denn, die Ausführung wird vom Nutzer früher unterbrochen.
Comment(""); //--- ExpertRemove(); }
Die Funktionsoperationen werden durch das Löschen des Kommentarfeldes und den Aufruf der Expert Advisor Shutdown-Funktion abgeschlossen.
Den vollständigen Code des Expert Advisors finden Sie im Anhang.
4. Tests
Nachdem ich die EAs erstellt und die Modelle trainiert hatte, testete ich die Methode Advantage Actor Critic vollständig. Zunächst beginnen wir mit dem Modelltraining. Es handelt sich vielmehr um ein zusätzliches Training der Modelle aus den beiden vorangegangenen Artikeln.
Das Training wurde mit EURUSD-Daten mit dem Zeitrahmen H1 durchgeführt, wobei die Historie der letzten zwei Jahre geladen wurde. Die Indikatoren wurden mit Standardparametern verwendet. Es ist zu erkennen, dass die Trainingsparameter der Modelle über die gesamte Artikelserie hinweg fast unverändert verwendet werden.
Der Vorteil des zusätzlichen Trainings der Modelle aus früheren Artikeln ist, dass wir Test-EAs aus dem vorherigen Artikel verwenden können, um die Ergebnisse ihres Trainings zu überprüfen. So habe ich das gemacht. Nach dem Training des Modells nahm ich das zusätzlich trainierte Politikmodell und startete den „REINFORCE-test.mq5“ EA im Strategietester unter Verwendung des genannten Modells. Sein Algorithmus wurde im vorigen Artikel beschrieben. Der vollständige Code des EAs befindet sich im Anhang.
Unten sehen Sie ein Salden-Diagramm des EAs während des Tests. Sie können sehen, dass der Saldo während des Tests gleichmäßig zunahm. Beachten Sie, dass das Modell an Daten außerhalb der Trainingsstichprobe getestet wurde. Dies zeigt die Konsistenz des Ansatzes zum Aufbau eines Handelssystems. Um nur das Modell zu testen, wurden alle Operationen mit einem festen Mindestlot durchgeführt, ohne Stop-Loss und Take-Profit zu verwenden. Es wird dringend davon abgeraten, einen solchen EA für den echten Handel zu verwenden. Er demonstriert lediglich die Arbeit des trainierten Modells.

Auf dem Preischart können Sie sehen, wie schnell Verlustgeschäfte geschlossen werden und gewinnbringende Positionen eine Zeit lang gehalten werden. Alle Operationen werden bei der Eröffnung einer neuen Kerze durchgeführt. Sie können auch mehrere Handelsoperationen beobachten, die fast bei der Eröffnung von Umkehrkerzen (Fraktale) durchgeführt werden.

Im Allgemeinen zeigte der EA während des Testprozesses einen Gewinnfaktor von 2,20. Der Anteil der gewinnbringenden Transaktionen lag bei über 56 %. Der durchschnittliche Gewinn überstieg den durchschnittlichen Verlust um 70 %.

Gleichzeitig wird davor gewarnt, diesen EA für den realen Handel zu verwenden, da er nur für Modelltests verwendet wurde. Erstens ist die Testphase des EA zu kurz und nicht ausreichend, um eine Entscheidung über seine Verwendung im realen Handel zu treffen. Zweitens verfügt der EA über keine Geldmanagement- oder Risikomanagementblöcke. Bei den Handelsoperationen gibt es keine Stop-Loss- und Take-Profits, was im realen Handel nicht zu empfehlen ist.
Schlussfolgerung
In diesem Artikel haben wir einen weiteren Algorithmus der Reinforcement-Learning-Methoden kennengelernt: Advantage Actor Critic. Dieser Algorithmus kombiniert bereits untersuchte Ansätze, Q-Learning und Policy Gradient, auf das Beste. Auf diese Weise lassen sich die Ergebnisse des Verstärkungstrainings von Modellen verbessern. Wir haben den betrachteten Algorithmus unter Verwendung von MQL5 entwickelt, trainiert und das Modell an realen historischen Daten getestet. Die Testergebnisse zeigen, dass das Modell in der Lage ist, Gewinne zu erwirtschaften, sodass wir zu dem Schluss kommen können, dass es möglich ist, mit diesem Modell-Trainingsalgorithmus Handelssysteme zu erstellen.
Unter den gegebenen Bedingungen liefert die Familie der Actor Critic-Algorithmen wahrscheinlich die besten Ergebnisse aller Methoden des Reinforcement Learning. Bevor die Modelle jedoch für den realen Handel eingesetzt werden, müssen sie lange trainiert und gründlich getestet werden. Einschließlich verschiedener Stresstests.
Liste der Referenzen
- Asynchronous Methods for Deep Reinforcement Learning
- Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
- Neuronale Netze leicht gemacht (Teil 27): Tiefes Q-Learning (DQN)
- Neuronale Netze leicht gemacht (Teil 28): Policy Gradient Algorithmus
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Actor-Critic.mq5 | EA | Ein Expert Advisor zum Trainieren des Modells |
| 2 | REINFORCE-test.mq5 | EA | Ein Expert Advisor zum Testen des Modells im Strategy Tester |
| 3 | NeuroNet.mqh | Klassenbibliothek | Bibliothek zur Erstellung neuronaler Netzmodelle |
| 4 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Erstellung neuronaler Netzwerkmodelle |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11452
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Lernen Sie, wie man ein Handelssystem mit dem Accelerator Oscillator entwickelt
Lernen Sie, wie man ein Handelssystem mit dem Accelerator Oscillator entwickelt
 Neuronale Netze leicht gemacht (Teil 28): Gradientbasierte Optimierung
Neuronale Netze leicht gemacht (Teil 28): Gradientbasierte Optimierung
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
...Nun aus irgendeinem Grund die Normal lib ist unerreichbar auf VAE.mqh, wenn es von NeuroNet aufgerufen wird, ich weiß wirklich nicht, warum (ich versuchte auf 2 verschiedenen Builds)...
Also habe ich das Problem gelöst, indem ich den Aufruf von Normal direkt auf VAE und Neuronet hinzugefügt habe, aber ich musste den Math-Space auf dem FQF loswerden:
seltsam... aber es hat funktioniert:
Die Initialisierung schlug fehl, weil keine EURUSD_PERIOD_H1_REINFORCE.nnw vorhanden war, als die folgenden Anweisungen ausgeführt wurden
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
INIT_FAILED zurückgeben;
Wie lässt sich dieses Problem lösen? Vielen Dank!
Eine andere Lösung für die Warnung "... hidden method calling ..."
In Zeile 327 von Actor_Critic.mq5:
Ich erhalte die Warnung "deprecated behavior, hidden method calling will be disabled in a future MQL compiler version":
Dies bezieht sich auf den Aufruf von "Maximum(0, 3)", der in geändert werden muss:
In diesem Fall müssen wir also "CArrayFloat::" hinzufügen, um die gewünschte Methode anzugeben. Die Maximum()-Methode wird von der Klasse CBufferFloat überschrieben, aber diese hat keine Parameter.
Obwohl der Aufruf eindeutig sein sollte, weil er zwei Parameter hat, will der Compiler, dass wir uns dessen bewusst sind ;-)
Die Initialisierung ist fehlgeschlagen, weil es keine EURUSD_PERIOD_H1_REINFORCE.nnw gibt, wenn die folgenden Anweisungen ausgeführt werden
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
return INIT_FAILED;
Wie lässt sich dieses Problem lösen? Danke!
In diesen Zeilen wird die Netzstruktur geladen, die trainiert werden soll. Sie müssen das Netz aufbauen und in der genannten Datei speichern , bevor Sie diesen EA starten. Sie können z.B. das Modellbildungstool in Artikel Nr. 23 verwenden
https://www.mql5.com/de/articles/11273
Können Sie den Code zur Berechnung der Prämie näher erläutern? Weil in Teil 27, die Belohnung Politik wie unten, es unterscheiden sich mit dem Code oben: