Diskussion zum Artikel "Neuronale Netze leicht gemacht (Teil 28): Gradientbasierte Optimierung"
 Guten Tag!
Guten Tag!
Dmitry, wo kann man die Funktionen values.Assign und MathRandomNormal bekommen? Ihre Skripte sind nicht gebaut und verweisen auf das Fehlen dieser Funktionen. Die Datei VAE.mqh wird abgelehnt.
Guten Tag.
Dmitry, wo kann man die Funktionen values.Assign und MathRandomNormal bekommen? Ihre Skripte sind nicht gebaut und verweisen auf das Fehlen dieser Funktionen. Die Datei VAE.mqh wird abgelehnt.
Guten Tag, Victor.
Was values.Assign betrifft , versuchen Sie, das Terminal zu aktualisieren. Dies ist eine eingebaute Funktion, die kürzlich zu MQL5 hinzugefügt wurde. MathRandomNormal ist in der Standardbibliothek des Terminals enthalten und wird in der Datei "\MQL5\Include\Math\Stat\Normal.mqh" hinzugefügt .
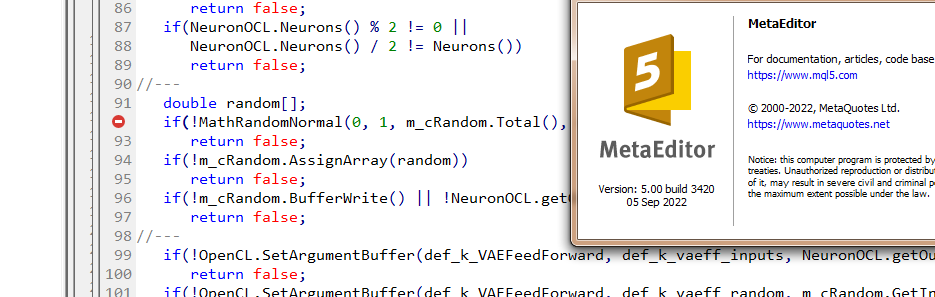
Dmitry Ich habe Terminalversion 3391 vom 5. August 2022 (letzte stabile Version). Jetzt habe ich versucht, auf die Beta-Version 3420 vom 5. September 2022 zu aktualisieren. Der Fehler mit values.Assign ist verschwunden. Aber der Fehler mit MathRandomNormal ist nicht verschwunden. Ich habe eine Bibliothek mit dieser Funktion auf dem Pfad, wie Sie geschrieben haben. Aber in der Datei VAE.mqh gibt es keinen Verweis auf diese Bibliothek, aber in der Datei NeuroNet.mqh wird diese Bibliothek wie folgt angegeben:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Aber so ist es bei mir nicht aufgebaut. :(
PS: Wenn ich den Pfad zur Bibliothek direkt in der VAE.mqh-Datei angebe. Ist es möglich, das zu tun? Ich verstehe nicht ganz, wie Sie die Bibliothek in der Datei NeuroNet.mqh festlegen , wird es da nicht einen Konflikt geben?
Ich habe versucht, die Zeile #include <Math\Stat\Normal . mqh> direkt in die Datei VAE .mqh einzufügen , aber es hat nicht funktioniert. Der Compiler schreibt immer noch 'MathRandomNormal' - nicht deklarierter Bezeichner VAE.mqh 92 8. Wenn Sie diese Funktion löschen und erneut eingeben, erscheint ein Tooltip mit dieser Funktion, was meines Erachtens bedeutet, dass sie in der Datei VAE.mqh zu sehen ist.
Im Allgemeinen habe ich versucht, auf einem anderen Computer mit einem anderen sogar Version der vinda, und das Ergebnis ist das gleiche - nicht sehen, die Funktion und nicht kompilieren. mt5 neueste Version betta 3420 von 5 September 2022.
Dmitry, haben Sie irgendwelche Einstellungen im Editor aktiviert?
Im Allgemeinen habe ich es auf einem anderen Computer mit einer anderen Version von Windows versucht, und das Ergebnis ist das gleiche - es sieht die Funktion nicht und kompiliert nicht. mt5 neueste Version betta 3420 vom 5. September 2022.
Dmitry, haben Sie irgendwelche Einstellungen im Editor aktiviert?
Versuchen Sie, die Zeile"Namespace Math" auszukommentieren
Dmitry Ich habe Terminalversion 3391 vom 5. August 2022 (letzte stabile Version). Jetzt habe ich versucht, auf die Beta-Version 3420 vom 5. September 2022 zu aktualisieren. Der Fehler mit values.Assign ist verschwunden. Aber der Fehler mit MathRandomNormal ist nicht verschwunden. Ich habe eine Bibliothek mit dieser Funktion auf dem Pfad, wie Sie geschrieben haben. Aber in der Datei VAE.mqh gibt es keinen Verweis auf diese Bibliothek, aber in der Datei NeuroNet.mqh wird diese Bibliothek wie folgt angegeben:
Namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Aber so bekomme ich es nicht zum Laufen. :(
PS: Wenn direkt in der Datei VAE.mqh der Pfad zur Bibliothek angegeben wird. Ist es möglich, das zu tun? Ich verstehe nicht ganz, wie man die Bibliothek in der Datei NeuroNet.mqh festlegt , wird es da nicht einen Konflikt geben?
3445 vom 23. September - dieselbe Sache.
 Hallo.
Hallo.
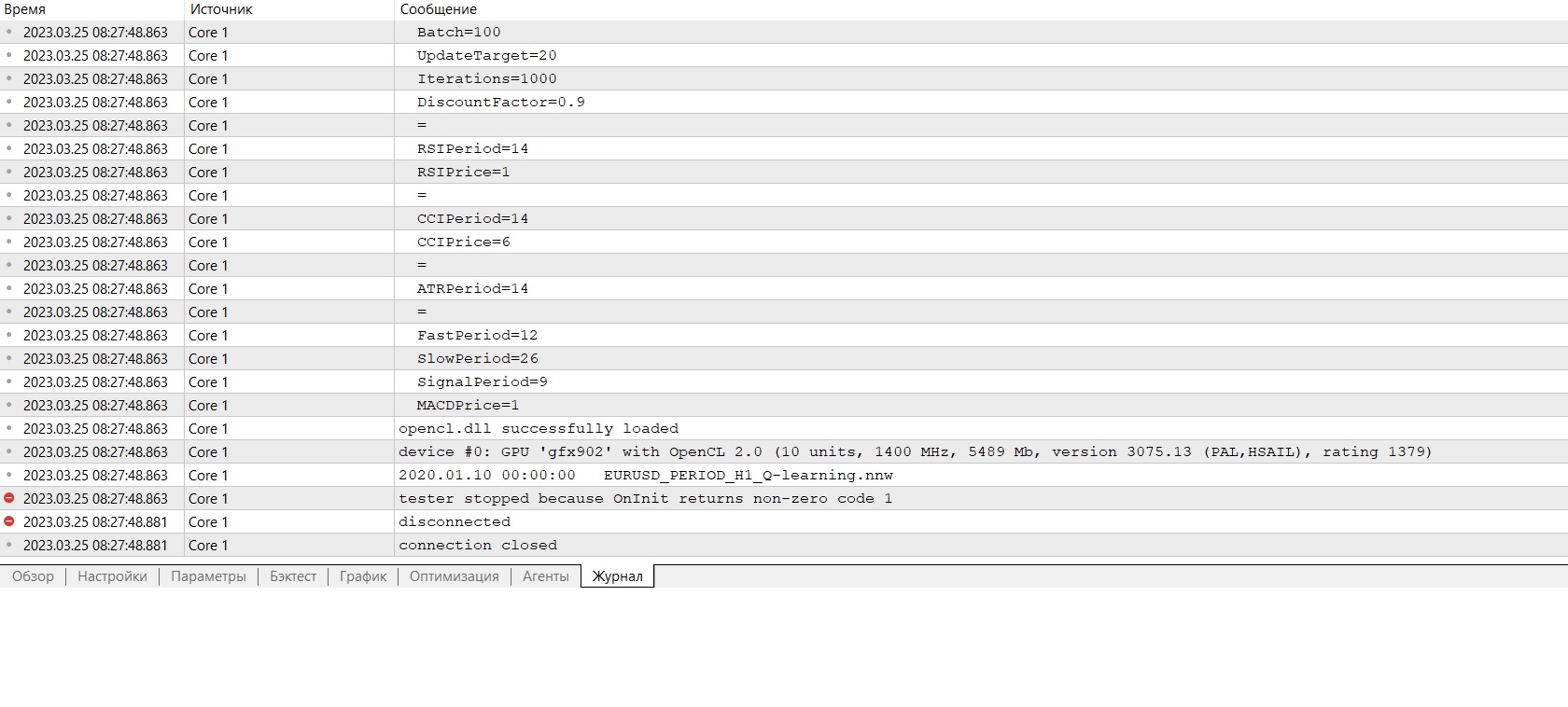
Brauche Rat :) Ich bin gerade nach der Neuinstallation in das Terminal eingestiegen, möchte trainieren und erhalte eine Fehlermeldung
{kind=link}
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Neuronale Netze leicht gemacht (Teil 28): Gradientbasierte Optimierung :
Wir studieren weiterhin das Verstärkungslernen, das Reinforcement Learning. Im vorigen Artikel haben wir die Methode des Deep Q-Learning kennengelernt. Bei dieser Methode wird das Modell so trainiert, dass es die bevorstehende Belohnung in Abhängigkeit von der in einer bestimmten Situation durchgeführten Aktion vorhersagt. Dann wird eine Aktion entsprechend der Strategie und der erwarteten Belohnung durchgeführt. Es ist jedoch nicht immer möglich, die Q-Funktion zu approximieren. Manchmal führt die Annäherung nicht zu dem gewünschten Ergebnis. In solchen Fällen werden Näherungsmethoden nicht auf Nutzenfunktionen, sondern auf eine direkte Handlungspolitik (Strategie) angewendet. Eine dieser Methoden ist die Gradientbasierte Optimierung, engl. „Policy Gradient“.
Das erste getestete Modell war DQN. Und es gibt eine unerwartete Überraschung. Das Modell erwirtschaftete einen Gewinn. Es wurde jedoch nur ein einziger Handelsvorgang ausgeführt, der während des gesamten Tests offen war. Das Symboldiagramm mit dem abgeschlossenen Geschäft ist unten abgebildet.
Wenn wir die Position auf dem Symbolchart auswerten, können wir sehen, dass das Modell den globalen Trend klar erkannt und eine Position in dessen Richtung eröffnet hat. Die Position gewinnt, aber die Frage ist, ob das Modell in der Lage sein wird, eine solche Position rechtzeitig abzuschließen? Wir haben das Modell anhand der historischen Daten der letzten 2 Jahre trainiert. In den letzten 2 Jahren wurde der Markt von einem Abwärtstrend für das analysierte Instrument beherrscht. Deshalb fragen wir uns, ob das Modell die Geschäft rechtzeitig schließen kann.
Bei Verwendung der gierigen Strategie führt das Gradientenmodell zu ähnlichen Ergebnissen. Erinnern wir uns, als wir anfingen, Methoden des Verstärkungslernens zu studieren, habe ich wiederholt betont, wie wichtig die richtige Wahl der Belohnungspolitik ist. Also beschloss ich, mit der Belohnungspolitik zu experimentieren. Um insbesondere ein zu langes Halten von Verlustpositionen auszuschließen, habe ich beschlossen, die Strafen für unrentable Positionen zu erhöhen. Zu diesem Zweck habe ich zusätzlich das Gradientenmodell mit der neuen Belohnungspolitik trainiert. Nach einigen Experimenten mit den Hyperparametern des Modells ist es mir gelungen, 60 % der Operationen mit Gewinn zu beenden. Das Testdiagramm ist unten abgebildet.
Die durchschnittliche Haltedauer einer Position beträgt 1 Stunde und 40 Minuten.
Autor: Dmitriy Gizlyk