Обсуждение статьи "Нейросети — это просто (Часть 28): Policy gradient алгоритм"
 Доброго времени суток.
Доброго времени суток.
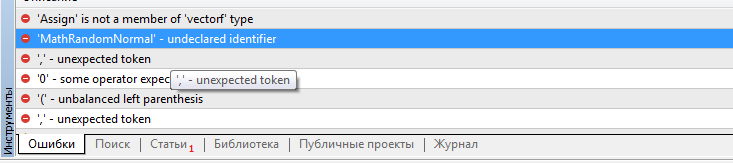
Дмитрий а где взять функции values.Assign и MathRandomNormal ? Ваши скрипты не собираются и ссылаются на отсутствие этих функций. Ругается на файл VAE.mqh
Доброго времени суток.
Дмитрий а где взять функции values.Assign и MathRandomNormal ? Ваши скрипты не собираются и ссылаются на отсутствие этих функций. Ругается на файл VAE.mqh
Добрый день, Виктор.
По поводу values.Assign попробуйте обновить терминал. Это встроенная функция недавно добавленная в MQL5. А MathRandomNormal входит в стандартную библиотеку из поставки терминала и добавлена в файле "\MQL5\Include\Math\Stat\Normal.mqh"
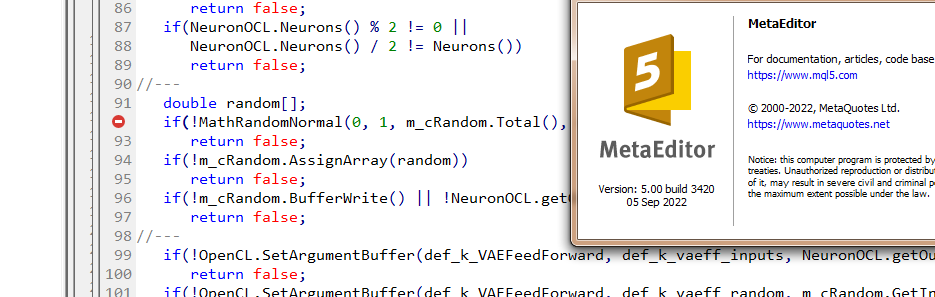
Дмитрий у меня терминал версии 3391 от 5 августа 2022 (последняя стабильная версия). Сейчас попробовал обновиться до бетта версии 3420 от 5 сентября 2022. Ошибка с values.Assign ушла. А вот с MathRandomNormal не уходит. Библиотечка с этой функцией есть у меня по пути как вы написали. Но в файле VAE.mqh у вас нет ссылки на эту библиотечку, а в файле NeuroNet.mqh у вас указывается эта библиотечка так:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Но так оно у меня не собирается. :(
PS: Если напрямую в файл VAE.mqh указать путь на библиотечку. Так можно сделать? Я не очень понимаю как у вас задана библиотечка в файле NeuroNet.mqh, не будет ли конфликта?
Я попробовал напрямую в файле VAE.mqh добавить строку #include <Math\Stat\Normal.mqh> Но это не дало результата. Компилятор всё равно пишет 'MathRandomNormal' - undeclared identifier VAE.mqh 92 8. При этом если эту функцию стереть и начать набирать заново, то появляется всплывающая подсказка с этой функцией, что как я понимаю , говорит о том что по идее она видна с файла VAE.mqh.
Вообще я уэе попробовал на другом компе с другой даже версией винды, и результат тот же - не видит функцию и не компилируется. мт5 последней версии бетта 3420 от 5 сентября 2022.
Дмитрий а у вас никаких настроек в редакторе не включено?
Я попробовал напрямую в файле VAE.mqh добавить строку #include <Math\Stat\Normal.mqh> Но это не дало результата. Компилятор всё равно пишет 'MathRandomNormal' - undeclared identifier VAE.mqh 92 8. При этом если эту функцию стереть и начать набирать заново, то появляется всплывающая подсказка с этой функцией, что как я понимаю , говорит о том что по идее она видна с файла VAE.mqh.
Вообще я уэе попробовал на другом компе с другой даже версией винды, и результат тот же - не видит функцию и не компилируется. мт5 последней версии бетта 3420 от 5 сентября 2022.
Дмитрий а у вас никаких настроек в редакторе не включено?
Попробуйте закомментировать строку "namespace Math"
Дмитрий у меня терминал версии 3391 от 5 августа 2022 (последняя стабильная версия). Сейчас попробовал обновиться до бетта версии 3420 от 5 сентября 2022. Ошибка с values.Assign ушла. А вот с MathRandomNormal не уходит. Библиотечка с этой функцией есть у меня по пути как вы написали. Но в файле VAE.mqh у вас нет ссылки на эту библиотечку, а в файле NeuroNet.mqh у вас указывается эта библиотечка так:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Но так оно у меня не собирается. :(
PS: Если напрямую в файл VAE.mqh указать путь на библиотечку. Так можно сделать? Я не очень понимаю как у вас задана библиотечка в файле NeuroNet.mqh, не будет ли конфликта?
3445 от 23 сентября - тоже самое.
 Здравствуйте.
Здравствуйте.
Нужен совет :) Только присоединился после переустановки терминал, хочу провести обучение и выдает ошибку
{kind=link}
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Нейросети — это просто (Часть 28): Policy gradient алгоритм:
Продолжаем изучение методов обучение с подкреплением. В предыдущей статье мы познакомились с методом глубокого Q-обучения. В котором мы обучаем модель прогнозирования предстоящей награды в зависимости от совершаемого действия в конкретной ситуации. И далее совершаем действие в соответствии с нашей политикой и ожидаемой наградой. Но не всегда возможно аппроксимировать Q-функцию. Или её аппроксимация не даёт желаемого результата. В таких случаях используют методы аппроксимации не функции полезности, а на прямую политику (стратегию) действий. Именно к таким методам относится policy gradient.
Первой мы протестировали модель DQN. И здесь нас ждал неожиданный сюрприз. Модель получила прибыль. Но при этом совершила только одну торговую операцию, которая была открыта на протяжении всего теста. График инструмента с совершенной сделкой представлен ниже.
Оценивая сделку на графике инструмента, нельзя не согласиться, что модель четко определила глобальный тренд и открыла сделку в его направлении. Сделка прибыльная, но открыт вопрос — сможет ли модель вовремя закрыть такую сделку? На самом деле мы обучали модель на исторических данных за 2 последних года. И все 2 года на рынке преобладает медвежий тренд по анализируемому инструменту. Поэтому возникает вопрос, сможет ли модель вовремя закрыть сделку.
И тут надо сказать, что при использовании жадной стратегии модель policy gradient дает схожие результаты. А помните, начиная изучение методов обучения с подкреплением, я неоднократно акцентировал внимание на необходимости правильного выбора политики вознаграждения. И тут я решил поэкспериментировать с политикой вознаграждения. В частности, чтобы исключить пересиживание в позиции убытков было принято решением о повышении штрафов за убыточность позиций. И, соответственно, дообучил модель policy gradient с учетом новой политик наград. После нескольких экспериментов с гиперпараметрами модели мне удалось добиться 60% прибыльных операций. График тестирования представлен ниже.
Среднее время удержания позиции составляет 1 час 40 минут.
Автор: Dmitriy Gizlyk