
Nichtlineare Regressionsmodelle an der Börse

Einführung
Gestern saß ich wieder einmal über den Berichten meines regressionsbasierten Handelssystems. Draußen vor dem Fenster fiel nasser Schnee, der Kaffee in der Tasse wurde kalt, aber ich wurde den zwanghaften Gedanken immer noch nicht los. Wissen Sie, ich bin schon lange genervt von diesen endlosen RSI-, Stochastik-, MACD- und anderen Indikatoren. Wie können wir versuchen, einen lebendigen und dynamischen Markt in diese primitiven Gleichungen erfassen? Jedes Mal, wenn ich auf YouTube einen anderen Gral-Befürworter mit seinem „heiligen“ Indikatorenset sehe, möchte ich einfach fragen - Mann, glaubst du wirklich, dass diese Rechner aus den Siebzigern die komplexe Dynamik des modernen Marktes erfassen können?
Ich habe die letzten drei Jahre damit verbracht, etwas zu entwickeln, das tatsächlich funktioniert. Ich habe viele Dinge ausprobiert - von den einfachsten Regressionen bis hin zu ausgeklügelten neuronalen Netzen. Und wissen Sie was? Es ist mir gelungen, Ergebnisse bei der Klassifizierung zu erzielen, aber noch nicht bei der Regression.
Es war jedes Mal die gleiche Geschichte - in der Geschichte läuft alles wie am Schnürchen, aber wenn ich es auf den realen Markt bringe, muss ich Verluste hinnehmen. Ich weiß noch, wie begeistert ich von meinem ersten Faltungsnetzwerk war. R2 bei 1,00% im Training. Es folgten zwei Wochen Handel und ein Minus von 30 % der Einlage. Klassische Überanpassung in ihrer schönsten Form. Ich schaltete die Visualisierung vorwärts und beobachtete, wie sich die regressionsbasierte Prognose mit der Zeit immer weiter von den realen Preisen entfernte...
Aber ich bin ein starrköpfiger Mensch. Nach einem weiteren Verlust beschloss ich, tiefer zu graben und begann, wissenschaftliche Artikel zu sichten. Und wissen Sie, was ich in den verstaubten Archiven ausgegraben habe? Es stellt sich heraus, dass der alte Mandelbrot bereits von der fraktalen Natur der Märkte gesprochen hat. Und wir alle versuchen, mit linearen Modellen zu handeln! Es ist, als würde man versuchen, die Länge einer Küstenlinie mit einem Lineal zu messen - je genauer man misst, desto länger wird sie.
Irgendwann dämmerte es mir: Was ist, wenn ich versuche, die klassische technische Analyse mit nichtlinearer Dynamik zu kreuzen? Nicht diese groben Indikatoren, sondern etwas Ernsthafteres - Differentialgleichungen, adaptive Verhältnisse. Das hört sich kompliziert an, ist aber im Grunde genommen nur ein Versuch, den Markt in seiner Sprache zu verstehen.
Kurz gesagt, ich nahm Python, schloss die Bibliotheken für maschinelles Lernen an und begann zu experimentieren. Ich habe mich sofort entschieden - kein akademischer Schnickschnack, nur das, was wirklich brauchbar ist. Keine Supercomputer - nur ein normaler Acer-Laptop, ein superstarker VPS und ein MetaTrader 5-Terminal. Aus all dem entstand das Modell, von dem ich Ihnen erzählen möchte.
Nein, es handelt sich nicht um einen Gral. Grale gibt es nicht, das habe ich schon vor langer Zeit erkannt. Ich teile nur meine Erfahrungen mit der Anwendung moderner Mathematik auf den realen Handel. Kein unnötiger Hype, aber auch kein Primitivismus der „Trendindikatoren“. Das Ergebnis war etwas dazwischen: intelligent genug, um zu funktionieren, aber nicht so komplex, dass es beim ersten schwarzen Schwan zusammenbrechen würde.
Mathematisches Modell
Ich weiß noch, wie ich auf diese Gleichung gekommen bin. Ich arbeite seit 2022 an diesem Code, aber nicht ständig: in Bezug auf die Ansätze, würde ich sagen - es gibt viele Entwicklungen, sodass Sie in regelmäßigen Abständen (ein wenig chaotisch) gehen durch sie und bringen eine nach der anderen auf das Ergebnis. Ich erinnere mich, dass ich Charts laufen ließ und versuchte, Muster im EURUSD zu erkennen. Und wissen Sie, was mir aufgefallen ist? Der Markt scheint zu atmen - manchmal fließt er gleichmäßig entlang des Trends, manchmal zuckt er plötzlich heftig, manchmal kommt er in eine Art magischen Rhythmus. Wie kann man dies mathematisch beschreiben? Wie lässt sich diese lebendige Dynamik in Gleichungen erfassen?
Danach habe ich die erste Version der Gleichung skizziert. Hier ist sie, in ihrer ganzen Pracht:
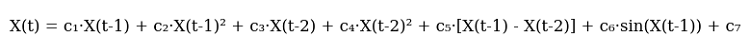
Und hier ist es im Code:
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
Sehen Sie, wie alles verdreht ist. Die ersten beiden Terme sind ein Versuch, die aktuelle Marktbewegung zu erfassen. Wissen Sie, wie ein Auto beschleunigt? Erst sanft, dann immer schneller und schneller. Aus diesem Grund gibt es hier sowohl einen linearen als auch einen quadratischen Term. Wenn sich der Preis ruhig bewegt, funktioniert der lineare Teil. Sobald sich der Markt jedoch beschleunigt, nimmt der quadratische Term die Bewegung auf.
Jetzt kommt der interessanteste Teil. Die Terme drei und vier gehen etwas weiter in die Vergangenheit zurück. Es ist wie ein Marktgedächtnis. Erinnern Sie sich an die Dow-Theorie, wonach sich der Markt an seine Niveaus erinnert? Das ist auch hier der Fall. Und wieder verfügt er über eine quadratische Beschleunigung, um scharfe Kurven zu nehmen.
Jetzt die Momentum-Komponente. Wir subtrahieren einfach den vorherigen Preis vom aktuellen. Das scheint primitiv zu sein. Aber bei Trendbewegungen funktioniert es super! Wenn der Markt in einen Rausch gerät und in eine bestimmte Richtung drängt, wird dieser Term zur Hauptantriebskraft der Prognose.
Der Sinus wurde fast zufällig hinzugefügt. Ich habe mir die Charts angesehen und eine Art Periodizität festgestellt. Insbesondere auf H1. Bewegungen und ruhige Phasen folgten aufeinander... Sieht aus wie eine Sinuskurve, nicht wahr? Ich setzte die Sinuswelle in die Gleichung ein, und das Modell schien das Licht zu sehen und begann, diese Rhythmen zu erfassen.
Das letzte Verhältnis ist eine Art Sicherheitsnetz, ein Grundniveau. Dieser Begriff erlaubt es dem Modell nicht, den Markt mit seinen Prognosen zu überraschen.
Ich habe eine Reihe von anderen Optionen ausprobiert. Ich habe dort Exponenten, Logarithmen und alle möglichen ausgefallenen trigonometrischen Funktionen untergebracht. Es bringt wenig, aber das Modell verwandelt sich in ein Ungetüm. Wie Occam schon sagte: Multipliziere keine Einheiten über das notwendige Maß hinaus. Die aktuelle Version ist genau so - einfach und funktionierend.
Natürlich müssen alle diese Verhältnisse irgendwie ausgewählt werden. An dieser Stelle kommt die gute alte Nelder-Mead-Methode zum Einsatz. Aber das ist eine ganz andere Geschichte, die ich im nächsten Teil enthüllen werde. Glauben Sie mir, es gibt viel zu besprechen - allein die Fehler, die ich bei der Optimierung gemacht habe, würden für einen eigenen Artikel reichen.
Lineare KomponentenBeginnen wir mit dem linearen Teil. Wissen Sie, was die Hauptsache ist? Das Modell berücksichtigt die beiden vorherigen Preiswerte, jedoch auf unterschiedliche Weise. Das erste Verhältnis liegt in der Regel bei etwa 0,3-0,4 - dies ist eine unmittelbare Reaktion auf die letzte Änderung. Der zweite Wert ist jedoch interessanter, er nähert sich oft 0,7, was auf einen stärkeren Einfluss des vorletzten Preises hinweist. Lustig, nicht wahr? Der Markt scheint sich auf etwas ältere Werte zu stützen und den jüngsten Schwankungen nicht zu trauen.
Quadratische KomponentenEine interessante Geschichte ereignete sich mit den quadratischen Termen. Ursprünglich habe ich sie nur hinzugefügt, um die Nichtlinearität zu berücksichtigen, aber dann habe ich etwas Überraschendes bemerkt. In einem ruhigen Markt ist ihr Beitrag vernachlässigbar - die Quoten schwanken um 0,01-0,02. Sobald jedoch eine starke Bewegung einsetzt, scheinen diese Mitglieder aufzuwachen. Besonders deutlich wird dies auf den EURUSD-Tagescharts - wenn der Trend an Stärke gewinnt, beginnen die quadratischen Terme zu dominieren, was es dem Modell ermöglicht, mit dem Kurs zu „beschleunigen“.
Momentum-KomponenteDie Momentum-Komponente erwies sich als eine echte Entdeckung. Der Preisunterschied scheint unbedeutend zu sein, aber er spiegelt die Stimmung auf dem Markt mit großer Genauigkeit wider! In ruhigen Zeiten bleibt das Verhältnis bei 0,2-0,3, aber vor starken Bewegungen steigt es oft auf 0,5. Dies wurde für mich zu einer Art Indikator für einen bevorstehenden Durchbruch - wenn der Optimierer beginnt, die Momentum-Gewicht zu erhöhen, ist Bewegung zu erwarten.
Zyklische KomponenteAn der zyklischen Komponente musste etwas herumgebastelt werden. Zuerst habe ich verschiedene Perioden der Sinuswelle ausprobiert, aber dann habe ich festgestellt, dass der Markt selbst den Rhythmus vorgibt. Es reicht aus, wenn das Modell die Amplitude über das Verhältnis einstellt, und die Frequenz ergibt sich natürlich aus den Preisen selbst. Es ist lustig zu beobachten, wie sich dieses Verhältnis zwischen der europäischen und der amerikanischen Sitzung ändert - als ob der Markt wirklich in einem anderen Rhythmus atmet.
Schließlich der freie Begriff. Es stellte sich heraus, dass seine Rolle viel wichtiger ist, als ich zunächst dachte. In Zeiten hoher Volatilität wirkt er wie ein Anker, der verhindert, dass die Prognosen ins Leere laufen. Und in ruhigen Zeiten hilft es, das allgemeine Preisniveau genauer zu berücksichtigen. Häufig korreliert sein Wert mit der Stärke des Trends - je stärker der Trend, desto näher liegt der freie Term bei Null.
Wissen Sie, was am interessantesten ist? Jedes Mal, wenn ich versuchte, das Modell zu verkomplizieren - neue Terme hinzuzufügen, komplexere Funktionen zu verwenden usw. - wurden die Ergebnisse nur noch schlechter. Es war, als ob der Markt sagen würde: „Junge, sei nicht so schlau, die Hauptsache hast du schon erwischt“. Die derzeitige Version der Gleichung ist wirklich ein guter Mittelweg zwischen Komplexität und Effizienz. Es gibt sieben Kennziffern - nicht mehr und nicht weniger - von denen jede eine eindeutige Rolle im Gesamtprognosemechanismus spielt.
Übrigens ist die Optimierung dieser Verhältnisse eine faszinierende Geschichte für sich. Wenn man beobachtet, wie die Nelder-Mead-Methode nach optimalen Werten sucht, denkt man unwillkürlich an die Chaostheorie. Aber darüber werden wir im nächsten Teil sprechen - es gibt dort etwas zu sehen, glauben Sie mir.
Modelloptimierung mit dem Nelder-Mead-Algorithmus
Hier werden wir uns mit dem interessantesten Punkt beschäftigen - wie wir unser Modell auf reale Daten anwenden können. Nach monatelangem Experimentieren mit der Optimierung, Dutzenden schlaflosen Nächten und literweise Kaffee habe ich endlich einen funktionierenden Ansatz gefunden.
Alles begann wie immer - mit einem Gradientenabstieg. Ein Klassiker des Genres, das erste, was jedem Datenwissenschaftler in den Sinn kommt. Ich verbrachte drei Tage mit der Implementierung und eine weitere Woche mit der Fehlersuche... Was waren also die Ergebnisse? Das Modell weigert sich kategorisch, zu konvergieren. Sie würde entweder ins Unendliche fliegen oder in lokalen Minima stecken bleiben. Die Farbverläufe sind wie verrückt gesprungen.
Dann gab es eine Woche mit genetischen Algorithmen. Die Idee ist scheinbar elegant: Die Evolution soll die besten Verhältnisse finden. Ich habe es implementiert und gestartet... nur um von der Laufzeit überrascht zu werden. Der Computer brummte die ganze Nacht, um eine Woche historischer Daten zu verarbeiten. Die Ergebnisse waren so unbeständig, dass es wie das Lesen von Teeblättern war.
Und dann stieß ich auf die Nelder-Mead-Methode. Die gute alte Simplex-Methode, die bereits 1965 entwickelt wurde. Keine Ableitungen, keine höhere Mathematik - nur eine intelligente Erkundung des Lösungsraums. Ich habe es gestartet und konnte meinen Augen nicht trauen. Der Algorithmus schien mit dem Markt zu tanzen und sich sanft den optimalen Werten zu nähern.
Hier ist die grundlegende Verlustfunktion. Sie ist so einfach wie eine Axt, funktioniert aber tadellos:
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
Zunächst habe ich versucht, die Verlustfunktion zu verkomplizieren, indem ich Strafen für große Verhältnisse hinzufügte und MAPE und andere Metriken in sie einfügte. Ein klassischer Entwicklerfehler ist, dass etwas, das funktioniert, so lange verbessert werden muss, bis es völlig unbrauchbar wird. Schließlich kehrte ich zu MSE zurück, und wissen Sie was? Es zeigt sich, dass Einfachheit wirklich ein Zeichen von Genialität ist.
Es ist ein besonderer Nervenkitzel, die Optimierung in Echtzeit zu beobachten. Erste Iterationen - die Verhältniswerte springen wie verrückt, der MSE springt, R² ist nahe Null. Dann beginnt der interessanteste Teil - der Algorithmus findet die richtige Richtung, und die Messwerte verbessern sich allmählich. Bei der hundertsten Iteration ist bereits klar, ob es einen Nutzen gibt oder nicht, und bei der dreihundertsten erreicht das System in der Regel ein stabiles Niveau.
Lassen Sie mich nebenbei noch ein paar Worte zur Metrik sagen. Unser R²-Wert liegt in der Regel über 0,996, was bedeutet, dass das Modell mehr als 99,6 % der Preisschwankungen erklärt. Der MSE liegt bei etwa 0,0000007 - mit anderen Worten: Der Prognosefehler übersteigt selten sieben Zehntel eines Pips. Was MAPE betrifft... Der MAPE ist im Allgemeinen erfreulich - oft weniger als 0,1 %. Es ist klar, dass dies alles auf historischen Daten beruht, aber selbst beim Vorwärtstest sind die Ergebnisse nicht viel schlechter.
Aber das Wichtigste sind nicht einmal die Zahlen. Das Wichtigste ist die Stabilität der Ergebnisse. Sie können die Optimierung zehnmal hintereinander durchführen, und jedes Mal werden Sie sehr ähnliche Verhältniswerte erhalten. Das ist viel wert, vor allem wenn man bedenkt, wie schwer ich mich mit anderen Optimierungsmethoden getan habe.
Weißt du, was noch cool ist? Wenn Sie die Optimierung beobachten, können Sie viel über den Markt selbst erfahren. Wenn der Algorithmus zum Beispiel ständig versucht, die Gewichtung der Momentum-Komponente zu erhöhen, bedeutet dies, dass sich eine starke Bewegung auf dem Markt zusammenbraut. Oder wenn sie beginnt, mit der zyklischen Komponente zu spielen - erwarten Sie eine Phase erhöhter Volatilität.
Im nächsten Abschnitt werde ich Ihnen erklären, wie aus dieser mathematischen Struktur ein echtes Handelssystem wird. Glauben Sie mir, auch da gibt es einiges zu bedenken - allein die Fallstricke beim MetaTrader 5 reichen für einen eigenen Artikel.
Merkmale des Trainingsprozesses
Die Aufbereitung der Daten für die Schulung war eine andere Geschichte. Ich erinnere mich, wie ich in der ersten Version des Systems fröhlich den gesamten Datensatz in sklearn.train_test_split einspeiste... Und erst später, als ich mir die verdächtig guten Ergebnisse ansah, wurde mir klar, dass zukünftige Daten in die Vergangenheit durchsickern!
Sehen Sie, wo das Problem liegt? Sie können Finanzdaten nicht wie ein normales Kaggle-Tabellenblatt behandeln. Hier ist jeder Datenpunkt ein Moment in der Zeit, und sie zu mischen ist, als würde man versuchen, das Wetter von gestern auf das von morgen zu übertragen. Daraus entstand dieser einfache, aber effiziente Code:
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_testEs scheint sich um einen einfachen Code zu handeln. Aber hinter dieser Einfachheit steckt eine Menge harter Schläge. Zunächst habe ich mit verschiedenen Fenstergrößen experimentiert. Ich dachte, je mehr historische Punkte, desto besser die Prognose. Ich habe mich geirrt! Es stellte sich heraus, dass die beiden vorherigen Werte völlig ausreichend waren. Der Markt erinnert sich nicht gerne lange an die Vergangenheit, wissen Sie.
Der Umfang der Trainingsstichprobe ist ein anderes Thema. Ich habe verschiedene Optionen ausprobiert - 50/50, 80/20, sogar 90/10. Schließlich entschied ich mich für den goldenen Schnitt - etwa 67 % der Trainingsdaten. Warum? Es funktioniert einfach am besten! Offenbar wusste der alte Fibonacci etwas über die Natur der Märkte...
Es macht Spaß, zu beobachten, wie das Modell anhand verschiedener Daten trainiert wird. In einer ruhigen Phase werden die Quoten gleichmäßig ausgewählt und die Kennzahlen verbessern sich allmählich. Und wenn die Trainingsstichprobe etwas wie den Brexit oder eine Rede des Leiters der US-Notenbank enthält, ist die Hölle los: Die Quoten steigen sprunghaft an, der Optimierer flippt aus, und die Fehlerdiagramme fahren Achterbahn.
Lassen Sie mich übrigens noch einmal ein paar Worte über Metriken sagen. Mir ist aufgefallen, dass, wenn R² bei der Trainingsstichprobe höher als 0,98 ist, es fast sicher ist, dass die Daten in irgendeiner Form fehlerhaft waren. Der reale Markt ist einfach nicht so vorhersehbar. Es ist wie in der Geschichte über den zu guten Schüler - entweder er schummelt oder er ist ein Genie. In unserem Fall ist es in der Regel das Erstere.
Ein weiterer wichtiger Punkt ist die Vorverarbeitung der Daten. Zuerst habe ich versucht, die Preise zu normalisieren, zu skalieren, Ausreißer zu entfernen... Im Allgemeinen habe ich alles gemacht, was in Kursen zum maschinellen Lernen gelehrt wird. Doch allmählich kam ich zu dem Schluss, dass es umso besser ist, je weniger man die Rohdaten anfasst. Der Markt wird sich von selbst normalisieren, man muss nur alles richtig vorbereiten.
Jetzt wurde das Training so weit gestrafft, dass sie automatisch abläuft. Einmal pro Woche laden wir neue Daten, führen ein Training durch und vergleichen die Metriken mit historischen Werten. Wenn alles innerhalb der normalen Grenzen liegt, aktualisieren Sie die Verhältnisse im Realsystem. Wenn Ihnen etwas verdächtig vorkommt, gehen Sie der Sache auf den Grund. Glücklicherweise wissen wir aufgrund unserer Erfahrung bereits, wo das Problem zu suchen ist.
Optimierung der Verhältnisse
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
Wissen Sie, was sich als das Schwierigste herausstellte? Machen Sie die verdammten Anfangsquoten richtig. Zuerst habe ich versucht, zufällige Werte zu verwenden - ich erhielt eine solche Streuung der Ergebnisse, dass ich schon bereit war, aufzugeben. Dann habe ich versucht, mit Einsen zu beginnen - der Optimierer flog während der ersten Iterationen irgendwo ins Leere. Auch mit Nullen funktionierte es nicht, da es in lokalen Minima stecken blieb.
Das erste Verhältnis 0,5 ist das Gewicht der linearen Komponente. Ist er geringer, verliert das Modell seine Tendenz, ist er höher, beginnt es, sich zu sehr auf den letzten Preis zu verlassen. Für die quadratischen Terme erwies sich 0,1 als perfekter Start - genug, um die Nichtlinearität zu erfassen, aber nicht so viel, dass das Modell bei plötzlichen Bewegungen durchdreht. Der Wert von 0,2 für das Momentum wurde empirisch ermittelt; bei diesem Wert zeigte das System einfach die stabilsten Ergebnisse.
Bei der Optimierung konstruiert Nelder-Mead ein Simplex in einem siebendimensionalen Verhältnisraum. Es ist wie ein Spiel von heiß und kalt, nur in sieben Dimensionen gleichzeitig. Es ist wichtig, Prozessabweichungen zu vermeiden, weshalb es so strenge Anforderungen an die Genauigkeit gibt (1e-8). Ist er kleiner, erhalten wir instabile Ergebnisse, ist er größer, bleibt die Optimierung in lokalen Minima stecken.
Tausend Iterationen mögen übertrieben erscheinen, aber in der Praxis konvergiert der Optimierer in der Regel in 300-400 Schritten. Es ist nur so, dass er manchmal, insbesondere in Zeiten hoher Volatilität, mehr Zeit braucht, um die optimale Lösung zu finden. Und zusätzliche Iterationen beeinträchtigen die Leistung nicht wirklich - der gesamte Prozess dauert auf moderner Hardware in der Regel weniger als eine Minute.
Übrigens, während der Fehlersuche in diesem Code entstand die Idee, den Optimierungsprozess zu visualisieren. Wenn man sieht, wie sich die Quoten in Echtzeit verändern, ist es viel einfacher zu verstehen, was mit dem Modell passiert und wohin es sich entwickeln könnte.
Qualitätsmetriken und ihre Interpretation
Die Bewertung der Qualität eines Vorhersagemodells ist eine ganz andere Geschichte, voller nicht offensichtlicher Nuancen. Im Laufe der Jahre, in denen ich mich mit dem algorithmischen Handel befasst habe, habe ich mich so sehr mit Metriken beschäftigt, dass ich ein eigenes Buch darüber geschrieben habe. Aber ich werde Ihnen das Wichtigste erzählen.
Hier sind die Ergebnisse:

Beginnen wir mit dem R-Quadrat. Als ich zum ersten Mal Werte über 0,9 beim EURUSD sah, konnte ich meinen Augen nicht trauen. Ich habe den Code zehnmal überprüft, um sicherzustellen, dass es keine Datenverluste oder Berechnungsfehler gibt. Es gab keine - das Modell erklärt mehr als 90 % der Preisvarianz. Später wurde mir jedoch klar, dass dies ein zweischneidiges Schwert ist. Ein zu hohes R² (größer als 0,95) deutet in der Regel auf eine Überanpassung hin. Der Markt kann einfach nicht so vorhersehbar sein.
MSE ist unser Arbeitspferd. Hier ist ein typischer Bewertungscode:
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
Bitte beachten Sie die zusätzlichen Statistiken. Ich fügte max_error und error_std nach einem unangenehmen Zwischenfall hinzu - das Modell zeigte einen ausgezeichneten MSE, aber manchmal lieferte es solche Ausreißer in den Prognosen, dass ich die Kaution sofort schließen konnte, ohne es überhaupt zu versuchen. Das erste, was ich mir anschaue, sind die „Ausläufer“ der Fehlerverteilung. Die Ausläufer sind jedoch noch vorhanden:
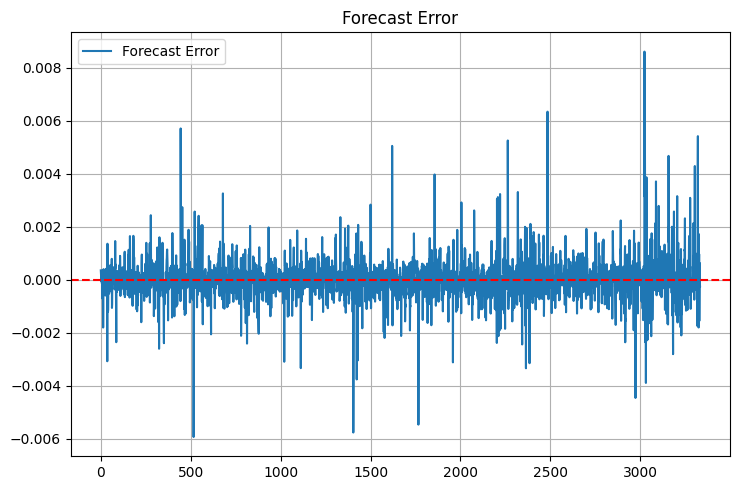
MAPE ist für die Händler wie ein Zuhause. Wenn man ihnen von R-Quadrat erzählt, werden ihre Augen glasig, aber wenn man sagt: „Das Modell ist im Durchschnitt um 0,05 % falsch“, verstehen sie sofort. Die Sache hat jedoch einen Haken: MAPE kann bei kleinen Kursbewegungen trügerisch niedrig sein und bei starken Bewegungen in die Höhe schnellen.
Aber das Wichtigste, was ich verstanden habe, ist, dass keine auf historischen Daten basierenden Metriken den Erfolg im wirklichen Leben garantieren. Deshalb habe ich jetzt ein ganzes System von Kontrollen:
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
Das Modell sollte all diese Tests bestehen, bevor ich es in den realen Handel einführe. Und auch danach handele ich in den ersten zwei Wochen mit einem minimalen Volumen - ich prüfe, wie es sich auf dem Live-Markt verhält.
Oft wird gefragt, welche metrischen Werte als gut gelten. Meiner Erfahrung nach ist ein R² von mehr als 0,9 hervorragend, ein MSE von weniger als 0,00001 akzeptabel und ein MAPE von bis zu 0,05 % hervorragend. Aber! Wichtiger ist es, die Stabilität dieser Indikatoren im Laufe der Zeit zu betrachten. Es ist besser, ein Modell mit etwas schlechteren, aber stabilen Metriken zu haben als ein superpräzises, aber instabiles System.
Technische Umsetzung
Wissen Sie, was das Schwierigste an der Entwicklung von Handelssystemen ist? Nicht die Mathematik, nicht die Algorithmen, sondern die Zuverlässigkeit des Betriebs. Es ist eine Sache, eine schöne Gleichung zu schreiben, und eine ganz andere, sie rund um die Uhr mit echtem Geld zum Laufen zu bringen. Nach mehreren schmerzhaften Fehlschlägen bei einem echten Konto wurde mir klar: Architektur sollte nicht nur gut, sondern tadellos sein.
So habe ich den Systemkern aufgestellt:
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
Jeder Strang hier ist das Ergebnis einer traurigen Erfahrung. Zum Beispiel erschien eine separate Methode für die Initialisierung von MetaTrader 5, nachdem ich beim Versuch, die Verbindung wiederherzustellen, in eine Sackgasse geraten war. Und ich habe die Protokollierung hinzugefügt, als das System mitten in der Nacht unbemerkt abstürzte und ich am Morgen raten musste, was passiert war.
Die Fehlerbehandlung ist eine ganz andere Geschichte.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
Dieses Stück Code ist die Quintessenz des MetaTrader 5-Erfahrung. Es versucht, die Verbindung wiederherzustellen, wenn etwas schief geht, versucht es wiederholt und mit Verzögerung und lässt vor allem nicht zu, dass das System in einem unsicheren Zustand weiterarbeitet. Obwohl es im Allgemeinen keine Probleme mit der MetaTrader 5-Bibliothek gibt - sie ist perfekt!
Ich halte das Modell in einem sehr einfachen Zustand. Sie enthält nur die notwendigsten Elemente. Keine komplexen Datenstrukturen, keine komplizierten Optimierungen. Aber jede Zustandsänderung wird protokolliert und überprüft:
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
Modularität ist hier nicht nur ein schönes Wort. Jede Komponente kann separat getestet, ersetzt oder verändert werden. Möchten wir eine neue Metrik hinzufügen? Erstellen wir eine neue Methode. Müssen wir die Datenquelle ändern? Es reicht aus, einen anderen Konnektor mit der gleichen Schnittstelle zu implementieren.
Umgang mit historischen Daten
Das Abrufen von Daten aus dem MetaTrader 5 erwies sich als eine ziemliche Herausforderung. Es scheint ein einfacher Code zu sein, aber der Teufel steckt wie immer im Detail. Nachdem wir mehrere Monate lang mit plötzlichen Verbindungsabbrüchen und Datenverlusten zu kämpfen hatten, wurde die folgende Struktur für die Arbeit mit dem Terminal entwickelt:
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
Schauen wir uns einmal an, wie alles organisiert ist. Zunächst wird geprüft, ob das Symbol vorhanden ist. Es scheint offensichtlich zu sein, aber es gab einen Fall, in dem das System aufgrund eines Tippfehlers in der Konfiguration stundenlang versuchte, ein nicht existierendes Paar zu handeln. Danach habe ich eine harte Prüfung über symbol_info hinzugefügt.
Dann gibt es noch einen interessanten Punkt mit „sichtbar“. Das Symbol scheint vorhanden zu sein, aber es ist nicht in MarketWatch zu finden. Und wenn Sie symbol_select nicht aufrufen, erhalten Sie auch keine Daten. Außerdem kann es vorkommen, dass das Terminal das Symbol mitten in einer Handelssitzung „vergisst“. Macht Spaß, was?
Auch die Datenbeschaffung ist nicht einfach. copy_rates_from_pos kann aus einem Dutzend verschiedener Gründe „None“ zurückgeben: keine Verbindung zum Server, der Server ist überlastet, nicht genug Historie... Deshalb überprüfen wir das Ergebnis sofort und lösen eine Ausnahme aus, wenn etwas schief gelaufen ist.
Die Umstellung auf Pandas ist eine andere Geschichte. Die Zeit kommt im Unix-Format an, also müssen wir sie in einen normalen Zeitstempel umwandeln. Ohne dies wird die spätere Zeitreihenanalyse sehr viel schwieriger.
Und das Wichtigste ist, die Verbindung „endlich“ zu schließen. Wenn Sie dies nicht tun, beginnt MetaTrader 5, Anzeichen von Datenverlusten zu zeigen: Zuerst sinkt die Geschwindigkeit des Datenempfangs, dann treten zufällige Timeouts auf, und schließlich kann das Terminal einfach einfrieren. Glauben Sie mir, ich habe das aus eigener Erfahrung gelernt.
Insgesamt ist diese Funktion wie ein Schweizer Taschenmesser für die Arbeit mit Daten. Von außen sieht es einfach aus, aber im Inneren gibt es eine Menge Schutzmechanismen gegen alles, was schief gehen könnte. Und glauben Sie mir, früher oder später wird sich jeder dieser Mechanismen als nützlich erweisen.
Analyse der Ergebnisse. Qualitätsmetriken der Ergebnisse des Vorwärtstests
Ich erinnere mich an den Moment, als ich die Testergebnisse zum ersten Mal sah. Ich saß am Computer, schlürfte kalten Kaffee und traute meinen Augen nicht. Ich habe die Tests fünfmal wiederholt und jede Codezeile überprüft - nein, das war kein Fehler. Das Modell arbeitete wirklich am Rande der Fantasie.
Der Nelder-Mead-Algorithmus funktionierte wie ein Uhrwerk - nur 408 Iterationen, weniger als eine Minute auf einem normalen Laptop. Das R-Quadrat 0,9958 ist nicht nur gut, sondern übertrifft die Erwartungen. 99,58% Preisabweichung! Als ich diese Zahlen meinen Händlerkollegen zeigte, glaubten sie mir zunächst nicht, dann suchten sie nach einem Haken. Ich verstehe sie - ich habe es anfangs selbst nicht geglaubt.
Die MSE war mikroskopisch klein - 0,00000094. Das bedeutet, dass der durchschnittliche Prognosefehler weniger als ein Pip beträgt. Jeder Händler wird Ihnen sagen, dass dies jenseits der kühnsten Träume liegt. Ein MAPE von 0,06 % bestätigt die unglaubliche Genauigkeit. Die meisten kommerziellen Systeme geben sich mit einem Fehler von 1-2 % zufrieden, aber hier ist er um eine Größenordnung besser.
Die Modellverhältnisse fügen sich zu einem schönen Bild zusammen. 0,5517 zum vorherigen Kurs zeigt, dass der Markt ein starkes Kurzzeitgedächtnis hat. Die quadratischen Terme sind klein (0,0105 und 0,0368), was bedeutet, dass die Bewegung überwiegend linear ist. Die zyklische Komponente mit einem Verhältnis von 0,1484 ist eine ganz andere Geschichte. Es bestätigt, was Händler schon seit Jahren sagen: Der Markt bewegt sich in Wellen.
Aber das Interessanteste geschah während des Vorwärtstests. Normalerweise verschlechtern sich Modelle bei neuen Daten - das ist klassisches maschinelles Lernen. Und hier? R² stieg auf 0,9970, MSE sank um weitere 19% auf 0,00000076, MAPE fiel auf 0,05%. Um ehrlich zu sein, dachte ich zuerst, dass ich irgendwo den Code vermasselt hätte, denn das sah zu unglaublich aus. Es war jedoch alles korrekt.
Ich habe einen speziellen Visualisierer für die Ergebnisse eingeführt:
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
Die Charts zeigen ein interessantes Bild. In ruhigen Zeiten funktioniert das Modell wie eine Schweizer Uhr. Aber es gibt auch Fallstricke - bei wichtigen Nachrichten und plötzlichen Umschwüngen sinkt die Genauigkeit. Dies ist zu erwarten, da das Modell nur mit Preisen arbeitet, ohne fundamentale Faktoren zu berücksichtigen. Im nächsten Teil werden wir dies auf jeden Fall noch hinzufügen.
Ich sehe mehrere Möglichkeiten zur Verbesserung. Der erste ist das adaptive Verhältnis. Lassen Sie das Modell sich an die Marktbedingungen anpassen. Die zweite besteht darin, Daten über Volumen und Auftragsbestand hinzuzufügen. Das dritte und ehrgeizigste Ziel ist die Schaffung eines Ensembles von Modellen, in dem unser Ansatz mit anderen Algorithmen zusammenarbeitet.
Aber auch in seiner jetzigen Form sind die Ergebnisse beeindruckend. Das Wichtigste ist jetzt, dass wir es mit den Verbesserungen nicht übertreiben und das, was bereits funktioniert, nicht kaputt machen.
Praktische Anwendung
Ich erinnere mich an einen lustigen Vorfall in der letzten Woche. Ich saß mit meinem Laptop in meinem Lieblingscafé, trank einen Milchkaffee und beobachtete das System bei seiner Arbeit. Der Tag war ruhig, der EURUSD stieg langsam an, als plötzlich eine Meldung vom Modell kam, dass eine Verkaufsposition eröffnet werden sollte. Der erste Gedanke war: Was für ein Unsinn, die Tendenz ist eindeutig steigend! Aber nach zwei Jahren Arbeit mit dem algorithmischen Handel habe ich die wichtigste Regel gelernt: Diskutiere niemals mit dem System. Nach 40 Minuten war der EUR um 35 Punkte gefallen. Das Modell reagierte auf Mikroveränderungen in der Preisstruktur, die ich mit meinem menschlichen Blick einfach nicht wahrnehmen konnte.
Apropos Benachrichtigungen... Nach einigen fehlgeschlagenen Handelsgeschäften wurde dieses einfache, aber effektive Warnmodul geboren:
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
Achten Sie auf die Methode _emergency_notification. Ich fügte sie nach einem „lustigen“ Vorfall hinzu, als das System eine Art Speicherfehler hatte und anfing, eine Position nach der anderen zu öffnen. Jetzt kommt in kritischen Situationen eine SMS, und der Bot stoppt automatisch den Handel, bis ich eingreife.
Ich hatte auch große Probleme mit der Größe der Positionen. Zunächst habe ich ein festes Volumen verwendet - 0,1 Lot. Aber allmählich kam die Erkenntnis, dass es wie ein Drahtseilakt in Ballettschuhen war. Das scheint möglich, aber warum? Schließlich habe ich das folgende adaptive Volumenberechnungssystem eingeführt:
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
Die Methode _normalize_volume bereitete echte Kopfschmerzen. Es hat sich herausgestellt, dass die verschiedenen Broker unterschiedliche Mindestvolumina für den Wechsel vorsehen. Irgendwo kann man 0,010 Lots handeln, und irgendwo nur runde Zahlen. Ich musste für jeden Broker eine eigene Konfiguration hinzufügen.
Die Arbeit in Zeiten hoher Volatilität ist eine andere Geschichte. Wissen Sie, es gibt Tage, da spielt der Markt einfach verrückt. Eine Rede des Fed-Vorsitzenden, unerwartete politische Nachrichten oder einfach nur „Freitag der 13.“ - der Kurs beginnt zu rasen wie ein betrunkener Matrose. Früher habe ich das System in solchen Momenten einfach ausgeschaltet, aber dann habe ich mir eine elegantere Lösung einfallen lassen:
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
Diese Funktion ist zu einem echten Hüter der Einlage geworden. Besonders gut gefallen hat mir die Nachrichtenüberprüfung - nach der Verbindung mit der Wirtschaftskalender-API geht das System 30 Minuten vor wichtigen Ereignissen „automatisch in den Schatten“ und kehrt 30 Minuten danach zurück. Die gleiche Idee wird in vielen meiner MQL5-Roboter verwendet. Schön!
Schwebende Anschlagpegel
Die Arbeit an echten Handelsalgorithmen hat mich einige lustige Lektionen gelehrt. Ich erinnere mich, wie ich im ersten Monat der Testphase meinen Kollegen stolz ein System mit festen Haltestellen zeigte. „Sehen Sie, alles ist einfach und transparent!“ - sagte ich. Wie üblich hat mich der Markt schnell wieder im Stich gelassen - buchstäblich eine Woche später erwischte ich eine derartige Volatilität, dass die Hälfte meiner Stopp-Levels aufgrund des Marktrausches einfach weggeblasen wurden.
Die Lösung wurde vom alten Gerchik vorgeschlagen - ich las damals gerade sein Buch. Ich stieß auf seine Gedanken zur ATR und es war, als würde eine Glühbirne angehen: Hier ist es! Eine einfache und elegante Möglichkeit, das System an die aktuellen Marktbedingungen anzupassen. Bei starken Bewegungen geben wir dem Kurs mehr Spielraum; in ruhigen Phasen halten wir die Stopps enger.
Hier ist die grundlegende Logik des Markteintritts - nichts Zusätzliches, nur das Nötigste:
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return NoneWährend des Debugging-Prozesses gab es einige lustige Momente. Zum Beispiel begann das System, buchstäblich alle paar Minuten eine Reihe von widersprüchlichen Signalen zu erzeugen. Kaufen, verkaufen, wieder kaufen... Ein klassischer Anfängerfehler im algorithmischen Handel ist der zu häufige Einstieg in den Markt. Die Lösung erwies sich als lächerlich einfach - ich fügte eine 15-minütige Zeitüberschreitung zwischen den Geschäften und einen Filter für offene Positionen hinzu.
Ich hatte auch große Probleme mit dem Risikomanagement. Ich habe verschiedene Ansätze ausprobiert, aber am Ende lief alles auf eine einfache Regel hinaus: Niemals mehr als 1 % der Einlage pro Transaktion riskieren. Das klingt trivial, funktioniert aber einwandfrei. Bei einer ATR von 50 Punkten ergibt sich ein maximales Volumen von 0,2 Lots - recht komfortable Werte für den Handel.
Die beste Performance erzielte das System während der europäischen Sitzung, als EURUSD tatsächlich gehandelt wurde und nicht nur in einer Spanne schwankte. Aber bei wichtigen Nachrichten... Sagen wir einfach, es ist billiger, eine Pause vom Handel zu machen. Selbst das modernste Modell kann mit dem Nachrichtenchaos nicht Schritt halten.
Ich arbeite derzeit an der Verbesserung des Positionsmanagementsystems - ich möchte die Einstiegsgröße an das Modellvertrauen in die Prognose koppeln. Grob gesagt, bedeutet ein starkes Signal, dass wir das gesamte Volumen handeln, ein schwaches Signal bedeutet, dass wir nur einen Teil davon handeln. So etwas wie das Kelly-Kriterium, nur angepasst an die Spezifika unseres Modells.
Die wichtigste Lektion, die ich aus diesem Projekt gelernt habe, ist, dass Perfektionismus im algorithmischen Handel nicht funktioniert. Je komplexer ein System ist, desto mehr Schwachstellen hat es. Einfache Lösungen erweisen sich oft als viel effizienter als ausgeklügelte Algorithmen, vor allem auf lange Sicht.
MQL5-Version für MetaTrader 5
Wissen Sie, manchmal sind die einfachsten Lösungen die effizientesten. Nachdem ich mehrere Tage lang versucht hatte, den gesamten mathematischen Apparat genau auf MQL5 zu übertragen, wurde mir plötzlich klar, dass dies ein klassisches Problem der Aufgabenteilung ist.
Seien wir ehrlich: Python mit seinen wissenschaftlichen Bibliotheken ist ideal für die Datenanalyse und Verhältnisoptimierung. Und MQL5 ist ein großartiges Werkzeug für die Ausführung von Handelslogik. Warum also sollte man versuchen, aus einem Schraubenzieher einen Hammer zu machen?
Daraus entstand eine einfache und elegante Lösung - wir verwenden Python für die Auswahl der Kennzahlen und MQL5 für den Handel. Schauen wir, wie es funktioniert:
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
Diese sieben Zahlen sind die Quintessenz unseres gesamten mathematischen Modells. Sie enthalten wochenlange Optimierungsarbeiten, Tausende von Iterationen des Nelder-Mead-Algorithmus und stundenlange Analysen historischer Daten. Und das Wichtigste: Sie funktionieren!
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
Die Prognosegleichung selbst wurde praktisch unverändert in MQL5 übernommen.
Der Mechanismus für den Markteintritt verdient besondere Aufmerksamkeit. Im Gegensatz zur Python-Testversion haben wir hier eine fortschrittlichere Logik für das Positionsmanagement implementiert. Das System kann mehrere Positionen gleichzeitig halten und erhöht das Volumen, wenn das Signal bestätigt wird:
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
Hier ist die automatische Schließung aller Positionen bei Erreichen des Zielgewinns.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
Ich habe besonders auf die Verarbeitung neuer Balken geachtet - kein sinnloses Zucken bei jedem Ticken:
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
Das Ergebnis ist ein kompakter, aber funktionaler Handelsroboter. Kein unnötiger Schnickschnack - nur das, was er wirklich braucht, um seine Arbeit zu erledigen. Der gesamte Code besteht aus weniger als 300 Zeilen und enthält alle notwendigen Kontrollen und Schutzmaßnahmen.
Wissen Sie, was das Beste daran ist? Dieser Ansatz der Trennung von Belangen zwischen Python und MQL5 hat sich als unglaublich flexibel erwiesen. Möchten Sie mit neuen Verhältnissen experimentieren? Berechnen Sie sie einfach in Python neu und aktualisieren Sie das Array in MQL5. Müssen Sie neue Handelsbedingungen hinzufügen? Die Handelslogik in MQL5 lässt sich leicht erweitern, ohne dass der mathematische Teil neu geschrieben werden muss.
Hier ist der Test des Roboters:
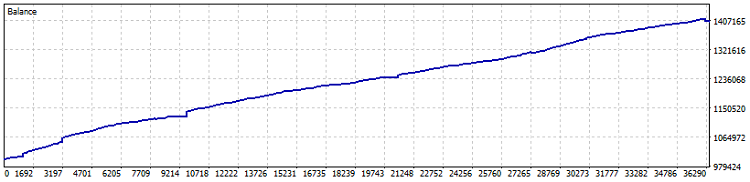
Test auf dem Netting-Konto, 40 % Gewinn seit 2015 (Optimierung des Verhältnisses wurde im letzten Jahr durchgeführt). Der Drawdown in Zahlen liegt bei 0,82%, der monatliche Gewinn bei über 4%. Es ist jedoch besser, einen solchen Automaten ohne Hebelwirkung zu starten - er soll die Gewinne zu einem etwas besseren Satz als Anleihen und USD-Einlagen einfahren. Unabhängig davon wurden während des Tests 7800 Lots gehandelt. Das sind immerhin eineinhalb Prozent mehr an Rentabilität.
Alles in allem halte ich die Idee, die Verhältnisse zu übertragen, für gut. Letztendlich kommt es beim algorithmischen Handel nicht auf die Komplexität des Systems an, sondern auf seine Zuverlässigkeit und Vorhersagbarkeit. Manchmal genügen dafür sieben Zahlen, die mit Hilfe der modernen Mathematik richtig ausgewählt wurden.
Wichtig! Der EA verwendet DCA-Positionsmittelung (Zeitmittelung, bildlich gesprochen) und ist daher sehr riskant. Während Tests auf Netting mit einigen konservativen Einstellungen hervorragende Ergebnisse zeigen, denken Sie immer an die Gefahr von Averaging-Positionen und daran, dass ein solcher EA Ihr Depot auf einen Schlag auf Null reduzieren kann!
Ideen für Verbesserungen
Es ist jetzt tiefe Nacht. Ich beende den Artikel, trinke Kaffee, schaue mir die Charts auf dem Monitor an und denke darüber nach, wie viel mehr mit diesem System erreicht werden kann. Wissen Sie, beim algorithmischen Handel ist es oft so: Gerade wenn alles fertig zu sein scheint, tauchen ein Dutzend neuer Ideen für Verbesserungen auf.
Und wissen Sie, was am interessantesten ist? Alle diese Verbesserungen müssen als ein einziger Organismus funktionieren. Es reicht nicht aus, einfach ein paar coole Funktionen einzubauen - sie müssen sich harmonisch ergänzen und ein wirklich zuverlässiges Handelssystem schaffen.
Letztlich ist es nicht unser Ziel, ein perfektes System zu schaffen - das gibt es einfach nicht. Das Ziel ist es, das System so intelligent zu machen, dass es Geld einbringt, aber auch so einfach, dass es nicht im schlimmsten Moment zusammenbricht. Wie das Sprichwort sagt, ist das Beste der Feind des Guten.
| Include | Beschreibung der Datei |
|---|---|
| MarketSolver.py | Code für die Auswahl von Kennzahlen und ggf. für den Online-Handel über Python |
| MarketSolver.mql5 | MQL5 EA-Code für den Handel mit ausgewählten Verhältnissen |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16473
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Von der Grundstufe bis zur Mittelstufe: Union (II)
Von der Grundstufe bis zur Mittelstufe: Union (II)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Der gepostete Expert Advisor weist keine Lücken auf. Dies ist offensichtlich kein Code von einem echten Konto, es gibt keine Filter hier erwähnt.
Nur eine Demonstration der Idee, die auch nicht schlecht ist.
Ich stimme zu
Nur kapets (Entschuldigung)! Während des mehrstündigen Studiums Ihrer Materialien zum 10. Mal sehe ich, dass wir die gleichen Wege (Gedanken) gehen.
Ich hoffe wirklich, dass Ihre Formeln mir helfen werden, das, was ich bereits sehe/benutze, mathematisch zu formalisieren. Das wird nur in einem Fall geschehen - wenn ich sie verstehe. Meine Mutter hat immer gesagt: "Lerne, mein Sohn." In Mathe weine ich bittere Tränen. Ich sehe, dass viele Dinge einfach sind, aber ich weiß nicht WIE. Ich versuche, mich in Parabeln, Regressionen, Abweichungen.... Es ist schwer, mit 65 Jahren in die 6. Klasse zu gehen.
// Es reicht nicht aus, einfach einen Haufen cooler Funktionen zusammenzustellen - sie müssen sich harmonisch ergänzen, damit ein wirklich zuverlässiges Handelssystem entsteht.
Ja. Sowohl die Auswahl der Funktionen als auch die anschließende Optimierung sind wie das Geraderichten der Acht eines Fahrrads. Einige Speichen müssen gelockert, andere angezogen werden, und zwar unter strikter Beachtung der Gesetze dieses Prozesses. Dann wird das Rad gerade, aber wenn man es falsch angeht, wenn man die Speichen falsch anzieht, kann man aus einem normalen Rad eine "Zehn" machen.
In unserem Geschäft sollten sich die "Speichen" gegenseitig helfen und nicht zum Nachteil anderer "Speichen" die Decke auf sich ziehen.
Ich glaube nicht, dass es sinnvoll ist, den Preis nur auf der Grundlage der letzten beiden Datenpunkte vorherzusagen.
Stimmen Sie zu?
Ich glaube nicht, dass es sinnvoll ist, den Preis nur auf der Grundlage der letzten beiden Datenpunkte vorherzusagen.
Würden Sie dem nicht zustimmen?