
ニューラルネットワークが簡単に(第28部):方策勾配アルゴリズム

内容
はじめに
さまざまな強化学習法の研究を続けます。前回は、Deep Q-Learning手法に触れました。この手法は、行動効用関数をニューラルネットワークで近似するものです。その結果、特定のシステム状態で特定のアクションを実行したときに期待される報酬を予測するためのツールを得ることができるます。その後、エージェントは方策と期待される報酬の量に基づいて行動をとります。方策の利用については明示的には議論しませんが、最も期待報酬の高い行動を選択することを想定しています。これは、ベルマンの公式と、分析されたセッションの報酬を最大化するという強化学習の全体的な目標から導かれます。
また、強化学習法を研究する際にモデルの過剰適応については一切触れなかったことにも留意していただきたいと思います。実際、強化学習モデルを見ると、エージェントの目標はできるだけ環境を学習することです。エージェントは、環境をよく知るほど、より良いパフォーマンスを発揮します。
しかし、市場という環境の変化を相手にすると、その変動に限界があることに気づくことがあります。市場には、同じ状態のものは2つとありません。似たような状態があっても、次のステップで全く逆の状態になることがあります。
Q関数の近似は、値の広がりや正の報酬が得られる確率を考慮せず、期待される平均報酬を提供するだけです。最大報酬の選択を伴う貪欲な戦略の使用は、常に曖昧さのない行動選択を与えます。一方で、これはエージェントの仕事を容易にするものでもありますが、このような戦略から望ましい結果を得ることができるのは、エージェントが環境と何らかの対立をしていないときに限られます。この場合、その行動は環境に対して予測可能になり、エージェントの行動に対抗する手段を開発したり、報酬の方針を変更したりすることができるようになります。しかし、エージェントは以前に近似したQ関数を使い続けることになり、環境の変化に対応できなくなります。
このような問題は、環境の報酬方策に近似せず、独自の行動戦略を展開する手法で解決することが可能です。その1つが、今回取り上げる方策勾配です。
1.方策勾配アプリケーション機能
強化学習法の学習を始めるにあたってエージェントが環境と相互作用し、その戦略に沿った行動をとると述べました。その結果、ある状態から別の状態へ遷移することになります。各遷移に対して、エージェントは環境からある報酬を受け取ります。報酬をもとに、エージェントはとった行動の有用性を評価することができます。方策勾配法では、エージェントの行動戦略の策定が示唆されます。
もちろん、DQNに見られるように、エージェントの戦略を明示的に設定することはありません。環境の現在の状態を評価し、エージェントがとるべき最適な行動を返す、方策Pのある数学的関数の存在について仮定するだけです。このアプローチにより、Q関数の近似の難しさや、最大期待報酬の行動(貪欲戦略)の選択など、エージェントの行動方針を明示的に指定する必要性をすべて取り除くことができます。
もちろん、何事にも値段はつきものです。Q関数を近似する代わりに、エージェントの方策のP関数を近似する必要があります。今回は、確率的方策勾配法に焦点をあてます。これは、方策関数が、現在の環境の状態を評価するときに、対応する行動をとったときに正の報酬を受け取る確率分布を返すと仮定します。
同時に、エージェントの行動は均等に配分されていると仮定します。特定の行動を選択するために、エージェントは単純に与えられた確率で正規分布から値をサンプリングすることができます。もちろん、貪欲な戦略で、最も確率の高い行動を選択することも可能ですが、エージェントの行動にバラツキを持たせるのがサンプリングです。確率が高いほど、この特定の行動を選択する頻度が高くなります。
先ほど、モデルの強化学習において、探索と活用のバランスを司るハイパーパラメータを導入したことを思い出してください。さて、確率的方策勾配法を用いる場合、このバランスは、確率に基づくエージェント行動のサンプリングを用いることにより、学習過程においてモデルによって調節されます。モデル訓練の初期には、すべての行動の確率はほぼ等しくなります。これにより、最も完全な環境の探索が可能になります。環境を学習する過程で、収益性の最大化につながる行動の確率が高まります。他の行動を選択する確率が下がります。このように、探索と開発のバランスが、最も収益性の高い行動を選択するように変化することで、最大の収益性を持つ戦略を構築することが可能になります。
エージェントの方策P関数を近似するために、ニューラルネットワークを用いることにします。現在の環境状態の初期データに基づいて、エージェントの最適な行動を決定する必要があるため、このタスクは分類問題と考えることができます。各行動は、初期状態の別クラスです。前述したように、ニューラル層の出力は、環境状態がどの特定の状態に属しているかを確率的に表現する必要があります。
確率的表現では、得られる値にいくつかの制約が課されます。結果は0%~100%の範囲で正規化する必要があります。すべての確率の和は100%にならなければなりません。機械学習では、百分率の代わりに1の端数を使うのが一般的です。したがって、値の範囲は0から1までとし、すべての値の和は1とします。この結果は、以下の数式を持つSoftMax関数を使用することで得ることができます。

この関数は、以前、データのクラスタリング手法を研究する際に、すでに見たことがあります。しかし、教師なし学習の手法を研究する際には、元データの類似性を調べてクラスを決定していました。今回は、受け取った報酬に応じて、環境の状態を行動(クラス)に振り分けることにします。SoftMax関数は、これらの要件を十分に満たしています。ニューラルネットワークの演算結果を確率の領域に完全に移行させることができ、値の全域で微分可能です。これは、モデルの訓練にとって非常に重要なことです。
2.方策モデルの学習原理
では、方策関数近似モデルの訓練原理について説明します。新しい状態に対してDQNモデルを訓練すると、環境から報酬が返ってきます。期待される報酬を最小限の誤差で予測できるようにモデルを訓練しました。これは、これまで使われてきた教師あり学習のアプローチと大差はありませんでした。
新しい状態ごとにエージェントの方策P関数を近似するとき、環境からの報酬も受け取ることができます。ただし、私たちが予想したいのは、報酬ではなく最善の行動です。報酬の符号は、現在の行動が結果に与える影響しか示すことができません。報酬が正の行動を選択する確率を上げ、報酬が負の行動を選択する確率を下げるようにモデルを訓練することになりますが、
その確率を予測するモデルを訓練するのです。前述したように、予測確率の値は0から1の範囲に限定されますが、これは、正にも負にもなり得る受け取った報酬の比ではありません。ここでは次のような論理で考えてみましょう。正の報酬を得る行動を選択する確率を最大化する必要があるため、そのような行動の目標値は1とします。モデル誤差は、ある行動の予測確率の1からの偏差として定義されます。偏差/分散を用いることで,方策関数近似モデルを訓練するために既に構築されている勾配降下法を利用することができます。なぜなら,1からの分散を最小化することにより,正の報酬を持つ行動を選択する確率を最大化することができるからです。
モデルの損失関数の選択にご注意ください。ここで、教師あり学習法の話に戻り、分類問題にはクロスエントロピー関数が使われることを思い出してもいいでしょう。

ここでp(y)は分布の真の値であり p(y')はモデルの予測値です。
また、対数の利用は、連続する事象を予測する上で非常に重要です。確率論から、2つの事象が連続して起こる確率は、事象の確率の積に等しいことが分かっています。対数については次のことが言えます。
![]()
これによって、確率の積からその対数の和に移行することができるので、モデルの訓練がより安定するようになります。
DQN訓練と同様に、報酬を受け取るために、エージェントは固定されたパラメータを持つセッションを通過します。状態、行動、報酬をバッファに保存します。そして、蓄積されたデータを使ってバックプロパゲーションパスを実行します。
なお、行動効用関数がないので、セッションパスで得られた値の合計に置き換えています。各状態について、Q関数の値は、セッションの終了までの後続の報酬の合計です。
モデルの訓練は、望ましい誤差レベルまたは訓練セッションの最大数に達するまで繰り返されます。
3.モデル訓練の実装
ここまで理論的な部分を説明してきましたが、ここからはMQL5を使った実装に移ります。まずは、SoftMax関数から見ていきましょう。その動作の特殊性から、これまで活性化関数としては実装していません。そこで、以前に作成したオブジェクトに基幹的な変更を加えることを避けるため、モデルの別の層として実装することにします。
3.1 SoftMaxの実装
ニューロンのCNeuronSoftMaxOCL基本クラスから派生する新しいCNeuronBaseOCLクラスを作成します。
class CNeuronSoftMaxOCL : public CNeuronBaseOCL { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CNeuronSoftMaxOCL(void) {}; ~CNeuronSoftMaxOCL(void) {}; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); virtual bool calcOutputGradients(CArrayFloat *Target, float error) override; //--- virtual int Type(void) override const { return defNeuronSoftMaxOCL; } };
新しいクラスでは、個別のバッファを作成する必要はありません。さらに、少し後で説明する親クラスのバッファをすべて使用するわけでもありません。そのため、コンストラクタとデストラクタは空になっています。同じ理由で、クラスの初期化メソッドをオーバーライドする必要はありません。実際にオーバーライドする必要があるのはfeedForwardフィードフォワードパスとcalcOutputGradients誤差勾配メソッドだけです。
また、新しい損失関数を使うので、モデル誤差と勾配を計算するcalcOutputGradientsメソッドをオーバーライドする必要があります。
そしてもちろん、Typeクラス識別メソッドをオーバーライドします。
まずは、フィードフォワードパス処理を実装してみましょう。ここでも、すべての演算処理はOpenCLを用いたマルチスレッドモードで実行されます。では、新しいカーネルであるSoftMax_FeedForwardをOpenCLで作成してみましょう。カーネルパラメータには、初期データと結果バッファへのポインタと、バッファサイズを渡します。関数計算には、追加のパラメータは必要ありません。
カーネル本体で、初期データと結果配列の対応する要素へのポインタとなるスレッド識別子を定義します。これは活性化関数の実装なので、初期データバッファと結果バッファのサイズは等しくなっています。したがって、これら2つのバッファの要素へのポインタは同じになります。
__kernel void SoftMax_FeedForward(__global float *inputs, __global float *outputs, const ulong total) { uint i = (uint)get_global_id(0); uint l = (uint)get_local_id(0); uint ls = min((uint)get_local_size(0), (uint)256); //--- __local float temp[256];
なお、SoftMax関数を計算するためには、入力データバッファの全要素の指数値の総和を求める必要があります。この値を各スレッドで繰り返し計算するのは良くないと思います。さらに、パラメータの計算処理を複数のスレッドに分散させるのも良いでしょう。しかしここで、複数のスレッドの作業を同期させ、スレッド間でデータをやり取りするという問題が発生します。OpenCLの技術では、スレッド間でデータを送ることはできませんが、別々のワークグループ内で共通の変数や配列をローカルメモリに作成することはできます。ワークグループ内のスレッドの作業を同期させるために、特殊な関数 barrier(CLK_LOCAL_MEM_FENCE)があります。これがここで使用するものです。
そこで、グローバルタスク空間でのスレッドIDの定義と合わせて、グループ内でのスレッドIDも定義することにしました。また、ローカルメモリに配列を宣言します。指数値の総和を計算する際に、ワークグループのスレッド間でデータをやり取りするために使用される予定です。
ここで難しいのは、OpenCLではローカルメモリに動的配列を使用することができないことです。そのため、カーネル作成段階で配列サイズを決定しておく必要があります。このサイズは、指数値を加算するために使用されるスレッドの数を制限します。
指数値の加算処理は、連続する2つのループで構成されています。最初のループの本体では、加算処理に参加する各スレッドが、加算スレッドの数に等しいステップで初期値のベクトル全体を繰り返し、指数値の和の部分を収集することになります。従って、全スレッドに均等に総和処理を振り分けることになります。それぞれ、ローカル配列の対応する要素にその値が格納されます。
uint count = 0; if(l < 256) do { uint shift = count * ls + l; temp[l] = (count > 0 ? temp[l] : 0) + (count * ls + l < total ? exp(inputs[shift]) : 0); count++; } while((count * ls + l) < total); barrier(CLK_LOCAL_MEM_FENCE);
この段階では、ループの反復が完了した後にスレッドを同期させる。
次に、ローカル配列の全要素の合計値を1つの値にまとめる必要があります。これは2番目のループで実装されます。ここでは、ローカル配列のサイズを半分に分割し、2つ1組で値を加算しています。2つの値の加算に関連する各操作は、別々のスレッドで実行されます。その後、要素の数を半分に割る、要素をペアにして加算するというループの繰り返しをおこないます。インデックス0を持つ配列要素の値の総和が得られるまで、ループの反復が繰り返されます。
count = ls; do { count = (count + 1) / 2; if(l < 256) temp[l] += (l < count && (l + count) < total ? temp[l + count] : 0); barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
このように、ループの新しい繰り返しは、参加しているすべてのスレッドの操作が完了した後にのみ開始することができます。そのため、ループの各反復の後に同期がおこなわれます。
ここで、OpenCLアーキテクチャは、スレッドの完全な同期のみを提供することに注意してください。つまり、ワークグループ内のすべての要素が、関連する「バリア」演算子に到達する必要があります。さもないと、プログラムがフリーズします。そのため、プログラムを編成する際には、スレッドの同期点に十分注意する必要があります。プログラムのアルゴリズム上、少なくとも1つのスレッドが同期ポイントを迂回することが可能な場合、条件演算子の本体に実装することは推奨されません。
上記のループの繰り返しが終了すると、元データの指数値の総和が得られ、データの正規化処理を完了することができます。そのために、別のループを作り、その中で初期データバッファを対応する値で埋めることにします。
float sum = temp[0]; if(sum != 0) { count = 0; while((count * ls + l) < total) { uint shift = count * ls + l; outputs[shift] = exp(inputs[shift]) / (sum + 1e-37f); count++; } } }
これでフィードフォワードカーネルの作業は終了です。次に、バックプロパゲーションカーネルの作成に移ります。
softmax関数を通して勾配を分配し、バックプロパゲーションカーネルを作成することから始めます。この関数の主な特徴は、すべての結果値の合計を1に正規化することであることに注意してください。そのため、活性化関数の入力の1つの値だけが変化すると、結果ベクトルのすべての値が再計算されます。同様に、誤差勾配を伝播させる場合、入力データの各要素は、結果ベクトルの各要素から誤差の分け前を受け取らなければなりません。各初期データ要素が結果に与える影響の数式を以下に示します。これはSoftMax_HiddenGradientカーネルに実装するものです。
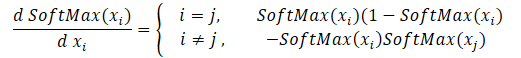
パラメータでは、カーネルは3つのデータバッファへのポインタ(フィードフォワードパス後の結果、前の層からの勾配、損失関数からの勾配)を受け取ります。また、前の層の勾配バッファを受け取り、そこにこのカーネルの結果を書き込むことになります。
カーネル本体には、スレッド識別子と実行中のスレッド総数を定義します。これらは、現在のスレッドの結果とバッファのサイズを記録するための配列要素を指すことになります。
次に、private変数を2つ用意します。フィードフォワード結果ベクトルの対応する要素の値を、そのうちの1つにコピーします。2つ目は、現在のスレッドの操作結果を収集するために宣言します。private変数を使用するのは、OpenCLデバイスの特殊なアーキテクチャのためです。private変数へのアクセスは、グローバルメモリ上のバッファを使用した同様の操作よりもはるかに高速なので、この方法はカーネル全体のパフォーマンスを向上させます。
そして、すべての結果要素をループして、上式に従って誤差勾配を収集します。ループ処理が終了したら、蓄積された勾配値を前の層の勾配バッファの対応する要素に渡し、カーネルを閉じます。
__kernel void SoftMax_HiddenGradient(__global float* outputs, __global float* output_gr, __global float* input_gr) { size_t i = get_global_id(0); size_t outputs_total = get_global_size(0); float output = outputs[i]; float result = 0; for(int j = 0; j < outputs_total; j++) result += outputs[j] * output_gr[j] * ((float)(i == j ? 1 : 0) - output); input_gr[i] = result; }
最後のカーネルは、SoftMax_OutputGradient損失関数の誤差勾配を決定するためのものです。今回は、損失関数としてLogLossを使用します。
勾配は対応するアクションの要素に分配されるため、微分も要素ごとに計算されることになります。これにより、スレッド間で誤差勾配を分割することができます。学校の数学の授業から、対数の微分は、関数の引数に対する1の比に等しいことが分かっています。したがって、損失関数の微分は次のようになります。
![]()
では、上記の数式をOpenCLのプログラムカーネルに実装する必要があります。そのコードは非常にシンプルで、わずか2行で済みます。
__kernel void SoftMax_OutputGradient(__global float* outputs, __global float* targets, __global float* output_gr) { size_t i = get_global_id(0); output_gr[i] = -targets[i] / (outputs[i] + 1e-37f); }
これでOpenCLプログラム側の動作は完了です。次に、メインプログラムの作業に移ることができます。新しいカーネルを扱うための定数を追加し、新しいカーネルの宣言を追加し、それらを呼び出すためのメソッドを作成する必要があります。
#define def_k_SoftMax_FeedForward 36 #define def_k_softmaxff_inputs 0 #define def_k_softmaxff_outputs 1 #define def_k_softmaxff_total 2 //--- #define def_k_SoftMax_HiddenGradient 37 #define def_k_softmaxhg_outputs 0 #define def_k_softmaxhg_output_gr 1 #define def_k_softmaxhg_input_gr 2 //--- #define def_k_SoftMax_OutputGradient 38 #define def_k_softmaxog_outputs 0 #define def_k_softmaxog_targets 1 #define def_k_softmaxog_output_gr 2
カーネル呼び出し方式は、類似の方式で以前に使用されたアルゴリズムを完全に繰り返します。完全なEAコードは添付ファイルにあります。
SoftMax関数の準備が整なったので、エキスパートアドバイザー(EA)に移り、方策勾配モデルの実装と訓練を開始します。
3.2 モデルを訓練するためのEAの構築
エージェント方策関数近似モデルを訓練するために、REINFORCE.mq5ファイルに新しいEAを作成します。基本的な機能は、前回作成したDQNモデルを訓練するためのQ-learning.mq5を継承しています。ただし、DQNモデルとは異なり、新しいEAは1つのニューラルネットワークのみを使用します。アルゴリズムを正しく実装するためには、環境の状態、とった行動、受け取った報酬の3つのスタックを作成する必要があります。
CNet StudyNet; CArrayObj States; vectorf vActions; vectorf vRewards;
EAの外部パラメータは、アルゴリズムの要求に応じて若干変更されます。
input int SesionSize = 24 * 22; input int Iterations = 1000; input double DiscountFactor = 0.999;
EAの初期化方法はほぼ同じです。とった行動と受け取った報酬を蓄積するためのスタック初期化のみを追加します。
if(!vActions.Resize(SesionSize) || !vRewards.Resize(SesionSize)) return INIT_FAILED;
訓練処理は、Train機能で実装されています。もう少し詳しく考えてみましょう。
通常通り,関数の最初に,与えられた外部パラメータに従って訓練用サンプルの範囲を決定します.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
訓練期間を決定後、訓練サンプルを読み込みます。
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- int total = bars - (int)(HistoryBars + 2 * SesionSize);
上記の操作は、以前のEAで使用したものと変わりはありません。この後、モデルの訓練ループのシステムが続きます。本システムは、モデルの訓練の主なアプローチを実装しています。
外側のループは、モデルの訓練セッションを繰り返し実行する役割を担っています。サイクル開始時に、読み込まれた履歴の一般的なプールでセッション開始バーをランダムに決定します。
CBufferFloat* State; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0,1,error_code)),1) * (total) + SesionSize); States.Clear();
そして、エージェントがステップバイステップでセッションを完全に通過するループを実装します。ループの本体では、まず現在のシステム状態のバッファを分析期間の履歴データで満たします。以前のモデルを訓練する際にも、各ダイレクトパスの前に同様の操作がおこなわれました。
for(int batch = 0; batch < SesionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; } int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) break; }
次に、モデルのフィードフォワードパスを実装します。
if(IsStopped()) { ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) continue; if(!StudyNet.feedForward(GetPointer(State), 12, true)) { ExpertRemove(); return; }
フィードフォワードパスの結果をもとに、行動の確率分布を求め、また、得られた確率分布を考慮して、正規分布から次の行動をサンプリングします。サンプリングは,別のGetAction関数によっておこなわれ,そのパラメータに確率分布が渡されます。
StudyNet.getResults(TempData); int action = GetAction(TempData); if(action < 0) { ExpertRemove(); return; }
行動をサンプリングした後、次のローソク足の大きさから、選択したアクションに対する報酬を決定します。報酬の方針は、前回の記事で使用したものです。
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -2; break; case 1: if(reward > 0) reward *= -2; else reward *= -1; break; default: reward = -fabs(reward); break; }
サンプル全体をスタックに保存します。なお、状態と行動は単にスタックに追加されるだけですが、報酬は割引率を考慮して保存されています。そのため、設計の段階で、報酬をどのように割り引くかを決めておく必要があります。割引には2つのオプションがあります。後の報酬に価値を与えることで、初期の報酬を割り引くことができます。この方法は、エージェントがセッションを進めながら中間報酬を受け取る場合によく使われますが、エージェントの主な仕事は、最大の報酬を受け取ることができるセッションの終了までたどり着くことです。
2番目のアプローチは逆で、最初の報酬をより重視するものです。後の報酬がその後で割引されます。このオプションは、最大かつ最速の報酬を目指す場合に許容されます。取引後に相場が反転するのを損失覚悟で待つのではなく、すぐに最大限の利益を得ることが重要なので、2番目の方法を使いました。
そして、ちょっと待ってください。セッションパスが完了したら、セッション終了までの各状態からの累積報酬を計算する必要があります。MQL5のベクトル演算では、直接の累積和のみを計算することができるので、単純にすべての報酬値を逆順にベクトルに格納することにします。ループ終了後、ベクトル演算で累積和を計算します。
if(!States.Add(State)) { ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)(reward * pow(DiscountFactor, (double)batch)); vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
データを保存した後、次のループの繰り返しに移ります。したがって、セッション全体のデータを収集することになります。
ループのすべての反復の後、割引を考慮したセッションの総報酬、セッションの終わりまでの各状態からの累積報酬のベクトル、および損失関数の値を計算します。
また、現在のモデルを保存しますが、最大報酬が更新された場合のみです。
float cum_reward = vRewards.Sum(); vRewards = vRewards.CumSum(); vRewards = vRewards / fmax(vRewards.Max(), fabs(vRewards.Min())); float loss = (vRewards * MathLog(vProbs) * (-1)).Sum(); if(MaxProfit < cum_reward) { if(!StudyNet.Save(FileName + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false)) return; MaxProfit = cum_reward; }
エージェントのセッション経路に沿った報酬の値が得られたので,方策関数モデルの訓練ループを実装することができます。これは別のループで実装されます。このループでは、バッファから環境状態を取り出し、モデルのフィードフォワードパスを実行します。これは、対応する環境の状態に対して、モデルの内部値をすべて復元するために必要です。
その後、現在の環境の状態に対する基準値のベクトルを用意します。覚えていらっしゃるように、私たちは正の報酬が得られる行動を選択する確率を最大化し、その他の確率を最小化しています。したがって、アクション実行後に正の値を受け取った場合は、参照確率のベクトルに0を記入します。そして、実行されたアクションに対してのみ、確率を1に設定します。負の報酬が返された場合、参照確率のベクトルを 1 で埋めます。この場合、実行されたアクションにはゼロが設定されます。
for(int batch = 0; batch < SessionSize; batch++) { State = States.At(batch); if(!StudyNet.feedForward(State)) { ExpertRemove(); return; } if((vRewards[SessionSize - batch - 1] >= 0 ? (!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], 1)) : (!TempData.BufferInit(Actions, 1) || !TempData.Update((int)vActions[batch], 0)) )) { ExpertRemove(); return; } if(!StudyNet.backProp(TempData)) { ExpertRemove(); return; } }
次に、バックプロパゲーションパスを実行し、モデルの重みを更新します。保存されたすべての環境状態について、この繰り返しをおこないます。
ループのすべての繰り返しが終了したら、ログにメッセージを出力し、次のセッションに進みます。
PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, cum_reward, loss); } Comment(""); //--- ExpertRemove(); }
操作実行結果の確認も忘れてはいけません。すべての反復処理が正常に終了したら、この関数を終了し、ターミナル終了イベントを生成します。完全なEAコードは添付ファイルにあります。
また、本モデルの方策関数を近似するために、前回の記事のQ関数訓練と同様のアーキテクチャを持つニューラルネットワークを使用したことにも留意してください。さらに、前回の記事で訓練したモデルを使用し、その中の決定ブロックをニューラルネットワークの最終層としてSoftMaxを追加して置き換え、データを正規化しています。
モデルの訓練プロセスは、他のモデルの訓練と全く同様です。本連載内の各記事には、たくさんの事例があります。そこで、おこなった作業をまとめるために、いつもの記事形式から外れてみることにしたのです。その代わり、訓練したモデルがストラテジーテスターでどのように動作するかを見てみましょう。
4.ストラテジーテスターでの訓練済みモデルのテスト
前回は、DQNモデルの訓練をおこないました。今回は、方策勾配モデルの作成と訓練をおこないました。テスト用のEAを作成し、それを使ってストラテジーテスターでモデルのパフォーマンスを確認することを提案します。では、2つのEAを作成してみましょう。Q-learning-test.mq5とREINFORCE-test.mq5です。名称は、各EAでテストされるモデルを反映しています。
EAの構造も同じなので、そのうちの1つを紹介しますが、両方のEAの完全なコードは添付ファイルにあります。
新しいEA「REINFORCE-test.mq5 」は、前述のREINFORCE.mq5 EAを元にして構築されて いますが、EAではモデルの訓練をおこなわないため、Train機能は削除されました。基本的な機能は、新しいティックイベントごとに処理するOnTick関数に移動されました。
訓練されたモデルは、ローソク足の終値から環境状態を評価します。したがって、OnTick関数の本体で、新しいローソク足の開始を確認します。この関数の残りの操作は、新しいローソク足が表示されたときのみ実行されます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if(lastBar >= iTime(Symb.Name(), TimeFrame, 0)) return;
新しいローソク足が表示されたら、最新の履歴データを読み込み、システム状態記述バッファに記入します。
int bars = CopyRates(Symb.Name(), TimeFrame, 0, HistoryBars+1, Rates); if(!ArraySetAsSeries(Rates, true)) return; RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = (int)HistoryBars - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) break; }
次に、データが正しく入力されているかどうかを確認し、モデルのフィードフォワードパスを実装します。
if(State1.Total() < (int)(HistoryBars * 12)) return; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; StudyNet.getResults(TempData); if(!TempData) return;
フィードフォワードの結果、可能な行動の確率分布が得られ、そこからランダムな行動をサンプリングします。
lastBar = Rates[0].time; int action = GetAction(TempData); delete TempData;
次に、選択した行動をとりますが、新しい取引を開く前に、すでにポジションがあるかどうかを確認します。そのために、BuyとSellの2つのフラグを定義します。変数を宣言するときは、その変数を falseに設定します。.
その後、すべての値に対してループを実装します。分析した銘柄のポジションが見つかったら、対応するフラグの値を変更します。
bool Buy = false; bool Sell = false; for(int i = 0; i < PositionsTotal(); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((ENUM_POSITION_TYPE)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: Buy = true; break; case POSITION_TYPE_SELL: Sell = true; break; } }
続くのは取引ブロックです。ここでは、「switch」文を使って、とられた行動に応じてブロックアルゴリズムを分岐させています。新しいポジションを開いている場合は、ポジションのフラグを確認します。該当する方向の未決済ポジションがある場合は、そのまま放置し、新しいローソク足が開くのを待ちます。
判断の際に、反対側のポジションが開いている場合は、まずそのポジションを決済し、その後で新たにポジションを建てます。
switch(action) { case 0: if(!Buy) { if((Sell && !Trade.PositionClose(Symb.Name())) || !Trade.Buy(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 1: if(!Sell) { if((Buy && !Trade.PositionClose(Symb.Name())) || !Trade.Sell(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 2: if(Buy || Sell) if(!Trade.PositionClose(Symb.Name())) { lastBar = 0; return; } break; } //--- }
エージェントがすべてのポジションを決済する必要がある場合、現在の銘柄のポジションを決済するための関数を呼び出します。この関数は、少なくとも1つのポジションが存在する場合にのみ呼び出されます。
各ステップで結果を制御することを忘れないでください。
完全なEAコードは添付ファイルにあります。
最初にテストしたモデルはDQNですが、これは思いがけない驚きを見せてくれます。このモデルは、利益を生み出しました。しかし、実行された取引操作は1つだけで、テスト中はずっとオープンでした。実行された取引の銘柄チャートは以下のとおりです。

銘柄チャートで取引を評価すると、このモデルは全体的なトレンドを明確に認識し、その方向に取引を開始したことが分かります。この取引は利益が出ますが、問題はモデルがこのような取引の決済に間に合うかどうかです。実際、過去2年分の履歴データを使ってモデルを訓練しました。この2年間、分析対象商品はずっと弱気トレンドで推移しています。だからこそ、このモデルが時間内に取引を決済できるかどうかが気になります。
貪欲戦略を用いた場合、方策勾配モデルも同様の結果を得ることができます。強化学習法の勉強を始めた頃、報酬の方針を正しく選択することの重要性を繰り返し強調したことを思い出してください。そこで、報酬方策を実験することにしたのです。特に、負けポジションの長期保有を排除するため、不採算ポジションに対するペナルティーを増やすことにしました。そのため、新しい報酬方策を使って、方策勾配モデルを追加で訓練させました。モデルのハイパーパラメータをいくつか実験した結果、60%の利益率を達成することができました。テストのグラフは以下のとおりです。
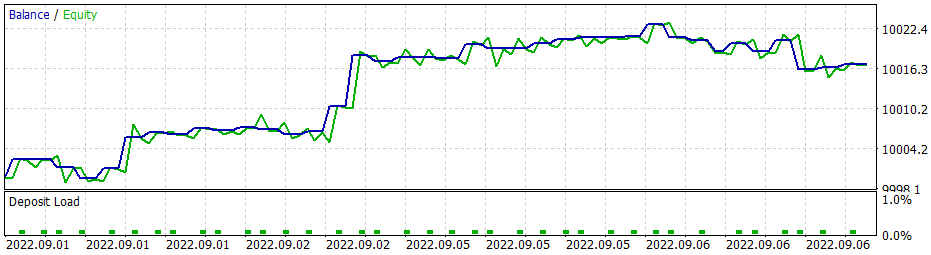
平均的なポジション保持時間は1時間40分です。
結論
今回は、強化学習法の別のアルゴリズムについて検討しました。方策勾配法を用いてモデルを作成し、訓練しました。
本連載の他の記事とは異なり、今回はストラテジーテスターでモデルの訓練とテストをおこないました。テスト結果に基づき、このモデルは有益な取引操作のためのシグナルを生成することができると結論付けることができます。同時に、望ましい結果を得るためには、適切な報酬方策と損失関数を選択することが重要であることを、改めて強調したいと思います。
参考文献リスト
- ニューラルネットワークが簡単に(第25部):転移学習の実践
- ニューラルネットワークが簡単に(第26部):強化学習
- ニューラルネットワークが簡単に(第27部):Deep Q-Learning (DQN)
記事で使用されているプログラム
| # | 名前 | タイプ | 詳細 |
|---|---|---|---|
| 1 | REINFORCE.mq5 | EA | モデルを訓練するEA |
| 2 | REINFORCE-test.mq5 | EA | ストラテジーテスターでモデルをテストするためのEA |
| 1 | Q-learning-test.mq5 | EA | ストラテジーテスターでDQNモデルをテストするためのEA |
| 2 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークモデルを作成するためのライブラリ |
| 3 | NeuroNet.cl | コードベース | ニューラルネットワークモデルを作成するためのOpenCLプログラムコードライブラリ |
…
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/11392
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 デマーカーによる取引システムの設計方法を学ぶ
デマーカーによる取引システムの設計方法を学ぶ
 一からの取引エキスパートアドバイザーの開発(第30部):指標としてのCHART TRADE?
一からの取引エキスパートアドバイザーの開発(第30部):指標としてのCHART TRADE?
 一からの取引エキスパートアドバイザーの開発(第29部):おしゃべりプラットフォーム
一からの取引エキスパートアドバイザーの開発(第29部):おしゃべりプラットフォーム
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
VAE .mqh ファイルに直接#include <MathStatNormal . mqh> 行を追加して みましたが、うまくいきませんでした。コンパイラーはまだ 'MathRandomNormal' - undeclared identifier VAE.mqh 92 8と書いて います。この関数を消してもう一度入力を始めると、この関数が書かれたツールチップが表示されます。これは、私の理解では、VAE.mqh ファイルから見ることができることを示しています。
一般的に、私はvindaの異なる偶数バージョンで別のコンピュータ上で試してみましたが、結果は同じです - 関数が表示されず、コンパイルされません。
ドミトリー、エディタで何か設定を有効にしていますか?
一般的に、私はWindowsの異なるバージョンで別のコンピュータ上でそれを試してみましたが、結果は同じです - それは関数を見ず、コンパイルされません。
ドミトリー、エディターで何か設定を有効にしていますか?
namespace Math" 行をコメントアウトしてみてください。
Dmitry 私は2022年8月5日付けのターミナルバージョン3391(最後の安定版)を持っています。今、私は2022年9月5日からのベータ版3420にアップグレードしようとしました。values.Assignの エラーはなくなりました。しかし、MathRandomNormalの エラーは 消えません。この関数を含むライブラリは、あなたが書いたようにパスにあります。しかし、VAE.mqh ファイルではこのライブラリへの参照はありませんが、 NeuroNet.mqhファイルでは以下のようにこのライブラリを指定しています:
名前空間 Math
{
#インクルード <MathStatatNormal.mqh
}
しかし、これではうまくいかない。:(
追記:VAE.mqh ファイルに直接ライブラリへのパスを指定した 場合。それは可能ですか?NeuroNet.mqh ファイルにライブラリを設定する方法がよくわからないのですが、競合しないのでしょうか?
3445(9月23日付け) - 同じことです。
アドバイスが必要です :)再インストール後、ターミナルに参加し、トレーニングを行いたいのですが、次のようなエラーが出ます。
こんにちは。
アドバイスが必要です :)再インストール後、ターミナルに参加し、トレーニングを行いたいのですが、次のようなエラーが出ます。