
Neuronale Netze im Handel: Szenenspezifische Objekterkennung (HyperDet3D)

Einführung
In den letzten Jahren hat die Objekterkennung große Aufmerksamkeit erlangt. Basierend auf Merkmalslernen und volumetrischer Faltung, PointNet++ die lokale Geometrie in den Vordergrund und analysiert auf elegante Weise rohe Punktwolken. Dies hat dazu geführt, dass es in verschiedenen Objekterkennungsmodellen als Backbone-Netz eingesetzt wird.
Die Attribute ähnlicher Objekte können jedoch mehrdeutig sein, was die Leistung des Modells beeinträchtigt. Dies hat zur Folge, dass die Anwendbarkeit des Modells eingeschränkt wird oder seine Architektur komplexer gestaltet werden muss. Die Autoren des Papiers „ Learning a Scene-conditioned 3D Object Detector“ stellte fest, dass Informationen auf Szenenebene Vorwissen liefern, das hilft, Mehrdeutigkeiten bei der Interpretation von Objektattributen aufzulösen. Dies wiederum verhindert unlogische Erkennungsergebnisse aus Sicht des Szenenverständnisses.
Der Beitrag stellt den Algorithmus HyperDet3D zur 3D-Objekterkennung in Punktwolken vor, der eine Hypernetwork-basierte Architektur verwendet. HyperDet3D lernt szenenabhängige Informationen und bezieht das Wissen über die Szene in die Netzparameter ein. Dadurch kann sich der 3D-Objektdetektor dynamisch an wechselnde Eingangsdaten anpassen. Das szenenbedingte Wissen kann in zwei Ebenen unterteilt werden: szeneninvariante Informationen und szenenspezifische Informationen.
Um szeneninvariantes Wissen zu erfassen, schlagen die Autoren das Erlernen von Einbettungen vor, die vom Hypernetwork verwendet und iterativ aktualisiert werden, wenn das Modell auf verschiedenen Szenen trainiert wird. Diese szeneninvariante Information wird in der Regel von den Merkmalen der Trainingsdaten abstrahiert und kann vom Detektor während der Inferenz genutzt werden.
Da herkömmliche Detektoren bei der Erkennung von Objekten in verschiedenen Szenen einen festen Satz von Parametern beibehalten, schlagen die Autoren von HyperDet3D vor, szenenspezifische Informationen zu integrieren, um den Detektor zum Zeitpunkt der Inferenz an eine bestimmte Szene anzupassen. Dazu wird analysiert, wie stark die aktuelle Szene mit der allgemeinen Darstellung übereinstimmt oder von ihr abweicht, wobei die spezifische Eingabe als Abfrage verwendet wird.
In diesem Beitrag wird eine neuartige Modulstruktur mit der Bezeichnung Multi-head Scene-Conditioned Attention (MSA) vorgestellt. MSA ermöglicht die Zusammenführung von Vorwissen mit Objektmerkmalen, wodurch eine effektivere Objekterkennung ermöglicht wird.
1. Der Algorithmus HyperDet3D
Das Modell HyperDet3D umfasst drei Hauptkomponenten:
- Ein Backbone-Encoder
- Ein Objekt Decoderschicht
- Ein Detektionskopf
Die eingegebene Punktwolke wird zunächst vom Backbone verarbeitet, der die Punkte abtastet, um erste Objektkandidaten zu generieren und deren Merkmale mithilfe hierarchischer Architekturen grob zu extrahieren. Die Autoren schlagen vor, PointNet++ als Backbone-Netz zu verwenden.
Als Nächstes verfeinern die Objektdecoderschichten die Kandidatenmerkmale, indem sie szenenbedingtes Vorwissen in die Repräsentationen auf Objektebene integrieren. Der Erkennungskopf regressiert dann den Begrenzungsrahmen auf der Grundlage der Positionen und verfeinerten Merkmale dieser Kandidatenobjekte.
Um HyperDet3D in die Lage zu versetzen, Metainformationen auf Szenenebene zu berücksichtigen, führen die Autoren ein HyperNetwork ein, ein neuronales Netz, das zur Parametrisierung der trainierbaren Parameter des primären Netzes dient. Im Gegensatz zu standardmäßigen, tiefen, neuronalen Netzen, die während der Inferenz feste Parameter beibehalten, bieten Hypernetze Flexibilität, indem sie die Parameter auf der Grundlage der Eingabedaten anpassen.
HyperDet3D verwendet ein szenenkonditioniertes Hypernetz, um Vorwissen in die Parameter der Transformer-Decoder-Schichten einzubringen. Dadurch kann sich das Erkennungsnetz dynamisch an unterschiedliche Eingangsszenen anpassen. Der Kerngedanke ist die Anreicherung der Objektrepräsentation 𝒐, die aus der vom Backbone-Encoder generierten Kandidatenmenge gebildet wird, mit durch 𝑾 parametrisiertem Vorwissen, das durch szenenkonditionierte Hypernetze bereitgestellt wird.
Die durch die szenenkonditionierten Hypernetze erzeugten Parameter werden in szeneninvariante und szenenspezifische Komponenten unterteilt.
Um szeneninvariantes Wissen zu erhalten, schlagen die Autoren vor, einen Satz von n szenenunabhängigen Einbettungsvektoren 𝒁a zu trainieren, die dann vom Hypernetwork verwendet werden. Die Ausgabe dieses Hypernetzes ist eine Gewichtsmatrix 𝑾a, die das szeneninvariante Vorwissen parametrisiert.
Da die Objekteigenschaften iterativ durch eine Abfolge von Decoderschichten verfeinert werden, können sie schrittweise mit den Ergebnissen des szeneninvarianten Hypernetzes verschmolzen werden. Dieses Netzwerk abstrahiert das Vorwissen über verschiedene 3D-Szenen. Das Ergebnis ist, dass HyperDet3D nicht nur ein verallgemeinertes, szenekonditioniertes Wissen über alle Decoderebenen hinweg beibehält, sondern auch Rechenressourcen spart, indem es Wissen durch reichhaltige Feature-Hierarchien teilt.
Um szenenspezifisches Wissen zu erhalten, lernt das Modell einen Satz von Einbettungen 𝒁s analog zu 𝒁a. Aber in diesem Fall ist 𝒁s Informationen erfassen, die für einzelne Szenen einzigartig sind. Dies wird durch einen Kreuzaufmerksamkeitsblock erreicht, bei dem die Einbettung der aktuellen Szene mit den erlernten szenenspezifischen Einbettungen 𝒁s verglichen wird. Durch den Aufmerksamkeitsmechanismus bewertet das Modell, wie gut 𝒁s mit der aktuellen Szene im Einbettungsraum übereinstimmt (oder wie sehr es davon abweicht).
Eine offizielle Visualisierung der Methode HyperDet3D finden Sie unten.
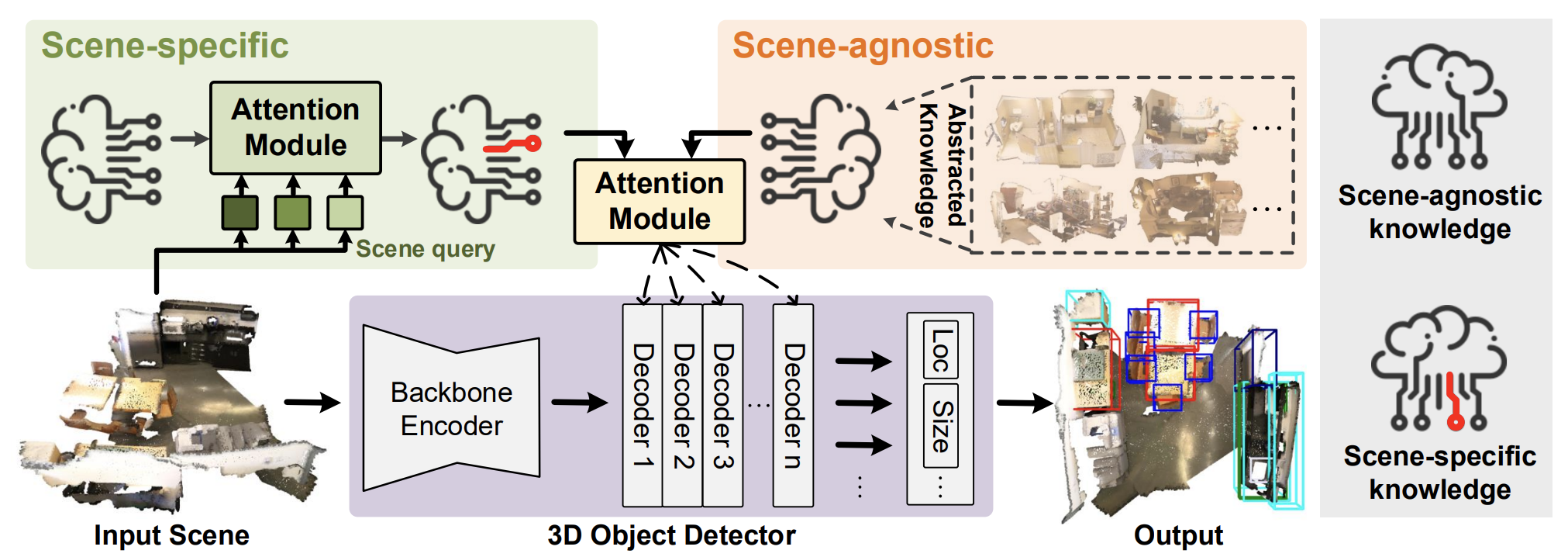
2. Implementation in MQL5
Nach der Betrachtung der theoretischen Aspekte der Methode HyperDet3D gehen wir zum praktischen Teil unseres Artikels über, in dem wir unsere Vision der vorgeschlagenen Ansätze umsetzen.
Um es gleich vorweg zu sagen: Wir haben noch viel Arbeit vor uns. Um dies effizient zu bewerkstelligen, werden wir die Implementierung in mehrere logische Module unterteilen. Also, krempeln wir die Ärmel hoch und legen los.
2.1 Szenespezifisches Wissensmodul
Wir beginnen mit dem Aufbau des Moduls, das für das Erlernen von szenespezifischem Wissen zuständig ist. Wie im theoretischen Teil erläutert, wird die Kreuzaufmerksamkeit genutzt, um die aktuelle Szene mit den szenenspezifischen Wissenseinbettungen abzugleichen. Dementsprechend werden wir eine neue Klasse, CNeuronSceneSpecific, als Unterklasse des Cross-Attention-Blocks CNeuronMLCrossAttentionMLKV definieren. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronSceneSpecific : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cSceneSpecificKnowledge; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSceneSpecific(void) {}; ~CNeuronSceneSpecific(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSceneSpecific; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
An dieser Stelle ist es wichtig, einen grundlegenden Unterschied zwischen unserer neuen Klasse und ihrer Mutterklasse hervorzuheben. Die übergeordnete Klasse benötigt zwei Datenquellen, um korrekt zu funktionieren: die Eingabedaten und einen Kontext. In unserer neuen Klasse wird der Kontext jedoch durch gelernte, szenenspezifische Daten aus der Trainingsmenge repräsentiert. Diese Daten werden durch zwei interne Schichten gelernt: cOne und cSceneSpecificKnowledge. Im Wesentlichen handelt es sich dabei um ein zweischichtiges MLP, das aus einer skalaren Eingabe (1) einen Tensor erzeugt, der szenenspezifisches Wissen darstellt. Wie zu erwarten, bleibt dieser Tensor während der Inferenz statisch. Während des Trainings „schreibt“ das Modell jedoch die notwendigen Informationen hinein.
Dieser Logik folgend, schließen wir Zeiger auf den externen Kontext aus den Methoden unserer neuen Klasse aus.
Alle Objekte werden statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse „leer“ lassen können. Die Objektinitialisierung wird in der Methode Init durchgeführt. In seinen Parametern finden wir die wichtigsten Konstanten der Objektarchitektur. Die Funktionalität der verwendeten Parameter ist ähnlich wie bei der entsprechenden Methode der übergeordneten Klasse.
bool CNeuronSceneSpecific::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, 16, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst die Initialisierungsmethode der übergeordneten Klasse auf und übergeben dabei alle erhaltenen Parameter. Diese übergeordnete Methode übernimmt die Parametervalidierung und die Einrichtung der geerbten Komponenten.
Als Nächstes initialisieren wir den bereits erwähnten szenenspezifischen MLP.
Beachten Sie, dass die erste Schicht nur eine einzige konstante Eingabe enthält. Die zweite Schicht erzeugt eine Reihe von Einbettungsvektoren, die szenenspezifisches Wissen repräsentieren. Jeder Einbettungsvektor hat eine Länge von 16 Elementen. Die Anzahl der Einbettungen wird durch Methodenparameter festgelegt und hängt von der Komplexität der zu modellierenden Umgebung ab.
if(!cOne.Init(16 * units_count_kv, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false; if(!cSceneSpecificKnowledge.Init(0, 1, OpenCL, 16 * units_count_kv, optimization, iBatch)) return false; //--- return true; }
Bevor wir die Methode abschließen, geben wir einen booleschen Wert zurück, der den Erfolg oder Misserfolg der Initialisierung an die aufrufende Funktion anzeigt.
Die Initialisierungsmethode unserer neuen Klasse ist relativ kurz und prägnant. Aus gutem Grund: Die Kernfunktionalität wurde bereits in der übergeordneten Klasse implementiert. Dieses Muster gilt nicht nur für die Initialisierungsmethode. Dies gilt auch für die Methode feedForward, deren Parameter einen Zeiger auf die Quell-Eingangsdaten enthalten.
bool CNeuronSceneSpecific::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !cSceneSpecificKnowledge.FeedForward(cOne.AsObject())) return false;
Im Hauptteil der Methode müssen wir zunächst eine Matrix von gelernten kontextabhängigen Darstellungen der Szene erstellen. Wir führen diesen Vorgang jedoch nur während des Modelltrainings durch, wenn sich der resultierende Tensor ändert, weil wir die Parameter unseres MLP anpassen. Während des Modellbetriebs sind diese gelernten Werte statisch und müssen nicht neu berechnet werden. Wir verwenden einfach die zuvor gespeicherten Informationen wieder.
Schließlich rufen wir die Methode feedForward der übergeordneten Klasse auf und übergeben unseren szenenspezifischen Wissenstensor als Kontexteingabe.
if(!CNeuronMLCrossAttentionMLKV::feedForward(NeuronOCL, cSceneSpecificKnowledge.getOutput())) return false; //--- return true; }
Die Methoden für die Rückwärtsdurchläufe sind ähnlich aufgebaut. Aus Gründen der Übersichtlichkeit und um den Artikel nicht zu lang werden zu lassen, schlage ich vor, sie unabhängig voneinander zu lesen. Die vollständige Implementierung der Klasse und aller ihrer Methoden finden Sie in den beigefügten Materialien.
2.2 Erstellen des MSA-Blocks
Nun gehen wir dazu über, den Block der mehrköpfigen, szenebedingten Aufmerksamkeit (MSA) zu konstruieren. Natürlich werden wir die Kernfunktionalität von einem der zuvor implementierten Aufmerksamkeitsblöcke erben. Die Struktur der neuen Klasse CNeuronMLMHSceneConditionAttention wird im Folgenden dargestellt.
class CNeuronMLMHSceneConditionAttention : public CNeuronMLMHAttentionMLKV { protected: CLayer cSceneAgnostic; CLayer cSceneSpecific; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMLMHSceneConditionAttention(void) {}; ~CNeuronMLMHSceneConditionAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMLMHSceneConditionAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Innerhalb dieser Struktur werden Sie die Deklaration von zwei neuen Objekten des Typs CLayer bemerken. Der eine speichert kontextabhängige Darstellungen der Szene, während der andere allgemeine objektbezogene Informationen enthält, die unabhängig von der Szene sind.
Es ist wichtig anzumerken, dass das Vorhandensein dieser beiden Objekte die Schaffung von tieferen, verschachtelten neuronalen Schichten zur Objekterkennung nicht einschränkt. In diesem Fall werden die Objekte von CLayer als dynamische Arrays verwendet. Die Anzahl der internen, neuronalen Schichten wird vom Nutzer während der Objektinitialisierung festgelegt.
Alle internen Objekte werden als statisch deklariert, sodass wir den Konstruktor und den Destruktor leer lassen können. Wie üblich wird die Initialisierung aller internen und geerbten Objekte in der Methode Init durchgeführt.
bool CNeuronMLMHSceneConditionAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
In den Methodenparametern erhalten wir die wichtigsten Konstanten, die die Architektur des erstellten Objekts bestimmen. Und im Hauptteil der Methode rufen wir sofort die entsprechende Vorgängermethode auf. In diesem Fall verwenden wir jedoch nicht die Methode der direkten übergeordneten Klasse, sondern die vollständig verbundenen Basisschicht CNeuronBaseOCL. Dies ist auf die erheblichen Unterschiede in der Struktur und Größe der vererbten Objekte zurückzuführen.
Nachdem die Operationen der abgeleiteten Initialisierungsmethode erfolgreich abgeschlossen sind, werden wir die Architekturkonstanten unserer neuen Klasse speichern.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
Dann berechnen wir die Abmessungen der internen Objekte.
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow * iHeads) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow * iHeadsKV) * iWindowKey; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Wir fügen 2 weitere lokale Variablen für die temporäre Speicherung von Zeigern auf Objekte der neuronalen Schicht hinzu.
CNeuronBaseOCL *base = NULL; CNeuronSceneSpecific *ss = NULL;
Damit sind die vorbereitenden Arbeiten abgeschlossen. Anschließend wird eine Schleife mit der Anzahl der Iterationen organisiert, die der Anzahl der vom Nutzer in den Methodenparametern angegebenen internen Schichten entspricht. Bei jeder Iteration dieser Schleife erstellen wir Objekte einer inneren Schicht. Dementsprechend erstellen wir nach der vollständigen Beendigung der angegebenen Anzahl von Schleifeniterationen einen vollständigen Satz von Objekten, die für das normale Funktionieren der erforderlichen Anzahl von internen neuronalen Schichten erforderlich sind.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Im Hauptteil der Schleife erstellen wir sofort eine weitere verschachtelte Schleife mit 2 Iterationen. Im Hauptteil der verschachtelten Schleife speichern wir Datenpuffer, um die Hauptflussdaten des Vorwärtsdurchlaufs und die entsprechenden Fehlergradienten des Rückwärtsdurchlaufs aufzuzeichnen. Diese 2-Iterationsschleife ermöglicht es uns, eine Spiegelarchitektur für die Vorwärts- und Rückwärtsdurchläufe zu schaffen.
Hier erstellen wir zunächst einen Puffer, um die generierten Entität von Query zu speichern. Dann erstellen wir einen Puffer für die Aufzeichnung der Gewichtsmatrix zur Erzeugung dieser Entität.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Beachten Sie, dass wir bisher die Gewichtsmatrix immer mit Zufallswerten gefüllt haben, die während des Modelltrainings angepasst wurden. Diesmal haben wir einen Puffer mit Nullwerten erstellt. Dies ist auf die Implementierung der Hypernetwork-Architektur zurückzuführen, die diese Matrix unter Berücksichtigung der analysierten Szene erstellt.
Wir wiederholen ähnliche Vorgänge, um Datenpuffer für die Entitäten Schlüssel (Key) und Werte (Value) zu erzeugen. Aber hier fügen wir auch die Möglichkeit hinzu, einen Tensor für mehrere interne Schichten zu verwenden. Daher prüfen wir vor der Erstellung von Datenpuffern die Durchführbarkeit solcher Vorgänge.
if(i % iLayersToOneKV == 0) { //--- Initilize KV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; //--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
Als Nächstes fügen wir einen Puffer hinzu, um die Abhängigkeitskoeffizienten zu speichern.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Und einen weiteren Puffer, um die Ergebnisse der mehrköpfigen Aufmerksamkeit zu speichern.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Wie zuvor skalieren die Ergebnisse der mehrköpfigen Aufmerksamkeit mit der Größe der ursprünglichen Daten. Das Ergebnis dieser Operation schreiben wir in den entsprechenden Datenpuffer.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Fügen wir auch die Puffer der Blockoperation FeedForward hinzu.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Wie in der entsprechenden Methode der Eltern werden auch für die letzte interne Schicht des FeedForward-Blocks keine neuen Ausgabepuffer erstellt. Stattdessen verweisen wir direkt auf die Puffer, die von der Basisschicht geerbt wurden, die vollständig verbunden ist. Diese Puffer werden für den schichtübergreifenden Datenaustausch verwendet. Und wir schreiben sie direkt während der Ausführung an, sodass ein unnötiger Datentransfer zwischen internen und externen Schnittstellen vermieden wird.
Nach der Initialisierung der Datenpuffer für die Datenströme von Vorwärts- und Rückwärtsdurchlauf werden die Gewichtsmatrizen initialisiert. In unserem Fall stützt sich die Generierung der an den aktuellen Szenenzustand angepassten Entitäten Abfrage, Schlüssel und Wert jedoch auf zwei Hypernetze: eines für szenenunabhängiges (vorheriges) Wissen über Objekte und eines für szenenabhängiges (kontextuelles) Wissen. Diese Hypernetze müssen ebenfalls initialisiert werden.
An diesem Punkt sind verschiedene Umsetzungsstrategien möglich. Wie Sie wissen, müssen Schlüssel und Wert im Gegensatz zur Abfrage nicht auf jeder internen Ebene erzeugt werden. Daher ordnen wir sie einem separaten Tensor zu. Theoretisch könnte man für jede entsprechende Gewichtsmatrix ein eigenes Hypernetz erstellen. Dieser Ansatz ist jedoch in Bezug auf die Leistung suboptimal. Denn dadurch würde sich die Zahl der sequenziellen Operationen erhöhen. Stattdessen haben wir uns dafür entschieden, die erforderlichen Tensoren mit Hilfe von vereinheitlichten Hypermodellen parallel zu generieren und die Ausgaben dann auf die entsprechenden Datenpuffer zu verteilen.
Schlüssel und Wert sind jedoch nicht auf jeder internen Ebene erforderlich. Deshalb berücksichtigen wir das und verwenden in solchen Fällen einfach ein Modell, das einen kleineren Ergebnissensor liefert.
Klingt logisch? Großartig - gehen wir zur Umsetzung über. Zunächst wird der Operationsstrom in zwei Zweige aufgeteilt, je nachdem, ob Schlüssel-Wert-Tensoren erzeugt werden müssen oder nicht. Der Ausführungsalgorithmus ist für beide Streams identisch. Der einzige Unterschied liegt in der Größe der resultierenden Tensoren.
if(i % iLayersToOneKV == 0) { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init((q_weights + kv_weights), cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false;
Zunächst arbeiten wir mit dem kontextabhängigen Repräsentationsmodell. Hier erstellen und initialisieren wir eine dynamische Instanz des szenenspezifischen Wissensmoduls, das wir zuvor implementiert haben. Ein Zeiger auf dieses neu erstellte Objekt wird in dem Array cSceneSpecific gespeichert, das Teil des kontextabhängigen Modells ist.
Allerdings ist hier eine wichtige Nuance zu beachten. Das szenenspezifische Wissensmodul wurde auf einem Kreuzaufmerksamkeitsblock aufgebaut, der als Input den analysierten Zustand der Szene erhält. Und es liefert einen Tensor mit den entsprechenden Dimensionen, angereichert mit kontextabhängigem Wissen. Das Problem ist, dass die Größe des Eingabetensors möglicherweise nicht mit den erforderlichen Dimensionen der Zielgewichtsmatrix übereinstimmt. Um dieses Problem zu lösen, führen wir eine vollständig verbundene Skalierungsschicht ein, die die Dimensionen entsprechend anpasst.
base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false;
Diese Skalierungsschicht verwendet den hyperbolischen Tangens (tanh) als Aktivierungsfunktion, die Werte im Bereich [-1, 1] ausgibt. Das kontextabhängige Wissen über die Szene fungiert also im Wesentlichen als Markierungsmechanismus, der die Wahrscheinlichkeit oder das Vorhandensein bestimmter Objekte innerhalb der analysierten Szene anzeigt.
Für das Modell des szenenunabhängigen Vorwissens verwenden wir ein zweischichtiges MLP, das ähnlich aufgebaut ist wie das zuvor beschriebene Modell für die kontextabhängigen Einbettungen.
//--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init((q_weights + kv_weights), cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Wenn keine Notwendigkeit besteht, einen Schlüssel-Wert-Tensor zu erzeugen, erstellen wir ähnliche Objekte, die jedoch kleiner sind.
else { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init(q_weights, cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, q_weights, optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false; //--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(q_weights, cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, q_weights, optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Für die skalierende Datenschicht der mehrköpfigen Aufmerksamkeitsergebnisse und den FeedForward-Block verwenden wir reguläre Matrizen von Trainingsparametern, die mit Zufallsparametern initialisiert werden.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Wir fügen auch Momentpuffer hinzu, die wir im Prozess der Optimierung der erstellten Matrizen von Trainingsparametern verwenden. Die Anzahl der Momentpuffer wird durch die angegebene Parameteroptimierungsmethode bestimmt.
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
Nachdem alle angegebenen Objekte erfolgreich initialisiert wurden, gehen wir zur nächsten Iteration der Schleife über, in der wir ähnliche Objekte für die nachfolgende innere Schicht erstellen werden.
Am Ende der Initialisierungsmethode initialisieren wir den Hilfspuffer für die Speicherung temporärer Daten und geben das logische Ergebnis der Operationen an das aufrufende Programm zurück.
if(!Temp.BufferInit(MathMax((num_q + num_kv)*iWindow, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Die komplexe Struktur und die große Anzahl von Objekten erschweren das Verständnis des zu erstellenden Algorithmus. Außerdem müssen wir den Informationsfluss und den Datentransfer zwischen den Objekten während der Implementierung der Methoden für Vorwärts- und Rückwärtsdurchläufe sorgfältig überwachen. Und wir beginnen mit der Konstruktion der Methode feedForward.
bool CNeuronMLMHSceneConditionAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *ss = NULL, *sa = NULL; CBufferFloat *q_weights = NULL, *kv_weights = NULL, *q = NULL, *kv = NULL;
In den Methodenparametern erhalten wir einen Zeiger auf das Quelldatenobjekt. Wir führen jedoch keine Überprüfung der Relevanz des erhaltenen Indexes durch. Da in diesem Stadium kein direkter Zugriff auf das Quelldatenobjekt geplant ist, ist es nicht möglich, die Daten direkt zu bearbeiten. Wir werden jedoch ein wenig Vorarbeit leisten, indem wir lokale Variablen für die vorübergehende Speicherung von Zeigern auf verschiedene Objekte erstellen. Und dann erstellen wir eine Schleife, um die internen Schichten unseres Blocks zu durchlaufen.
for(uint i = 0; i < iLayers; i++) { //--- Scene-Specific ss = cSceneSpecific[i * 2]; if(!ss.FeedForward(NeuronOCL)) return false; ss = cSceneSpecific[i * 2 + 1]; if(!ss.FeedForward(cSceneSpecific[i * 2])) return false;
Innerhalb der Schleife beginnen wir mit der Generierung der Gewichtskoeffizienten, die für die Konstruktion der Abfrage-, Schlüssel- und Wertentitäten erforderlich sind, unter Verwendung der zuvor definierten Hypernetze.
Zunächst wird auf der Grundlage der vom aufrufenden Programm erhaltenen Zustandsbeschreibung der Szene die Matrix der kontextabhängigen Parameter erstellt. Wie bereits beschrieben, reichern wir diesen Tensor mit kontextspezifischem Wissen an und skalieren ihn neu, um ihn an die Dimensionen der erforderlichen Parametermatrix anzupassen.
Gleichzeitig erstellen wir die Matrix der szenenunabhängigen Parameter.
//--- Scene-Agnostic sa = cSceneAgnostic[i * 2 + 1]; if(bTrain && !sa.FeedForward(cSceneAgnostic[i * 2])) return false;
Beachten Sie, dass die szenenunabhängige Parametermatrix nur während des Modelltrainings erstellt wird. Während des Betriebs bleibt die Matrix statisch. Sie muss also nicht bei jedem Vorwärtsdurchlauf neu erstellt werden.
Als Nächstes führen wir eine elementweise Multiplikation der beiden Matrizen durch. Das Ergebnis ist die endgültige Gewichtsmatrix, die wir dann auf die zuvor initialisierten Datenpuffer verteilen. Es ist wichtig zu beachten, dass es sich hierbei um eine einzige generierte Gewichtsmatrix handelt, die in zwei Teile aufgeteilt ist. Ein Teil wird zur Erstellung von Abfrageentitäten verwendet. Der zweite Teil wird für Schlüssel- und Wertentitäten verwendet. Schlüssel und Wert werden jedoch nicht unbedingt auf jeder Ebene gebildet. Daher müssen wir den Operationsablauf verzweigen, je nachdem, ob die Generierung des Schlüssel-Wert-Tensors erforderlich ist.
Bevor wir dies tun, müssen wir einige Vorbereitungen treffen. Konkret übertragen wir einen Zeiger auf das Eingangsdatenobjekt der aktuellen internen Schicht in eine lokale Variable.
CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
Hier speichern wir den Zeiger auf den Eingang der internen Schicht. Das bedeutet, dass der vom externen Programm empfangene Zeiger nur in die erste interne Schicht übergeben wird. Für alle nachfolgenden Schichten verwenden wir die Ergebnisse der vorherigen internen Schicht.
Außerdem speichern wir in lokalen Variablen die Zeiger auf die Datenpuffer der Gewichtsparameter und des Abfrage-Tensors, die beide unabhängig davon verwendet werden, welchen der beiden Verarbeitungspfade wir verfolgen.
q_weights = QKV_Weights[i * 2]; q = QKV_Tensors[i * 2];
Wenn es notwendig ist, einen Key-Value-Tensor zu bilden, führen wir zunächst eine elementweise Multiplikation der beiden oben gebildeten Gewichtsmatrizen durch. Und wir schreiben das Ergebnis der Operation in den Zwischenspeicher.
if(i % iLayersToOneKV == 0) { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), GetPointer(Temp))) return false;
Wir speichern Zeiger auf die Gewichtspuffer und die Wertpuffer der Schlüssel-Wert-Entitäten in lokalen Variablen.
kv_weights = KV_Weights[(i / iLayersToOneKV) * 2]; kv = KV_Tensors[(i / iLayersToOneKV) * 2];
Dann verteilen wir den gemeinsamen Tensor der Gewichtsparameter auf zwei Datenpuffer.
if(IsStopped() || !DeConcat(q_weights, kv_weights, GetPointer(Temp), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(IsStopped() || !MatMul(inputs, kv_weights, kv, iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; }
Danach bilden wir einen Tensor von Schlüssel-Wert-Entitäten durch Matrixmultiplikation des anfänglichen Datentensors der aktuellen internen Schicht mit der erhaltenen Matrix von Gewichtskoeffizienten.
Wenn keine Notwendigkeit besteht, einen Tensor der Schlüssel-Wert-Entitäten zu bilden, führen wir nur die Operation der elementweisen Multiplikation zweier Parametermatrizen durch und schreiben die Ergebnisse in den entsprechenden Datenpuffer. Denn in diesem Fall bilden unsere Hypernetze nur eine Gewichtsmatrix der Abfrage-Entität.
else { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), q_weights)) return false; }
Die Bildung des Tensors der Schlüssel-Wert-Entitäten wird in jedem Fall durchgeführt. Daher implementieren wir diesen Vorgang in den allgemeinen Ablauf.
if(IsStopped() || !MatMul(inputs, q_weights, q, iUnits, iWindow, iHeads * iWindowKey, 1)) return false;
In diesem Stadium ist die Implementierung der Hypernetze in den Aufmerksamkeitsalgorithmus abgeschlossen. Dann folgt der Mechanismus, der uns bereits bekannt ist: Selbstaufmerksamkeit. Zunächst ermitteln wir die Ergebnisse der mehrköpfigen Aufmerksamkeit.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors[i * 2]; CBufferFloat *out = AO_Tensors[i * 2]; if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Dann reduzieren wir die Dimensionen des resultierenden Ausgangstensors.
//--- Attention out calculation temp = FF_Tensors[i * 6]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9)], out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Danach addieren wir die Ergebnisse des Selbstaufmerksamkeitsblocks mit den Originaldaten und normalisieren den resultierenden Tensor.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
Anschließend durchlaufen die Daten den FeedForward-Block.
//--- Feed Forward inputs = temp; temp = FF_Tensors[i * 6 + 1]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors[i * 6 + 2]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], temp, out, 4 * iWindow, iWindow, activation)) return false;
Dann summieren und normalisieren wir die Daten.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- result return true; }
Wir wiederholen die Vorgänge für alle internen Schichten. Nachdem wir alle Schleifeniterationen abgeschlossen haben, wird das logische Ergebnis der Ausführung der Methodenoperationen an das aufrufende Programm zurückgegeben.
Ich hoffe, Sie verstehen jetzt, wie der Algorithmus unserer Klasse funktioniert. Aber es gibt noch eine weitere Nuance, die mit der Verteilung des Fehlergradienten während des Rückwärtsdurchlaufs zusammenhängt - sein Algorithmus ist in der Methode calcInputGradients implementiert.
bool CNeuronMLMHSceneConditionAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
In den Methodenparametern erhalten wir wie üblich einen Zeiger auf das Objekt der vorherigen Schicht, auf das wir den Fehlergradienten entsprechend dem Einfluss der ursprünglichen Daten auf das Endergebnis übertragen müssen. Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft. Danach erstellen wir mehrere lokale Variablen für die vorübergehende Speicherung von Zeigern auf Objekte.
CBufferFloat *out_grad = Gradient; CBufferFloat *kv_g = KV_Tensors[KV_Tensors.Total() - 1]; CNeuronBaseOCL *ss = NULL, *sa = NULL;
Dann organisieren wir eine umgekehrte Schleife durch die internen Schichten.
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors[(i / iLayersToOneKV) * 2 + 1];
Wie Sie wissen, spiegelt der Algorithmus des Rückwärtsdurchlaufs des Gradienten den Vorwärtsdurchlauf wider, wobei alle Operationen in umgekehrter Reihenfolge ausgeführt werden. Aus diesem Grund haben wir eine umgekehrte Iterationsschleife über die internen Schichten unseres Blocks aufgebaut.
Ich möchte Sie daran erinnern, dass die zweite Hälfte der Operationen des Vorwärtsdurchlaufs direkt die entsprechende Logik in der übergeordneten Klasse repliziert. Daher beginnen wir die erste Hälfte unserer Methode des Rückwärtsdurchlaufs der Gradienten mit der Wiederverwendung der entsprechenden Methode aus der Elternklasse.
Wir beginnen mit dem Rückwärtsdurchlauf des Fehlergradienten durch den FeedForward-Block.
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], out_grad, FF_Tensors[i * 6 + 1], FF_Tensors[i * 6 + 4], 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors[i * 6 + 3]; if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], FF_Tensors[i * 6 + 4], FF_Tensors[i * 6], temp, iWindow, 4 * iWindow, LReLU)) return false;
Danach summieren wir den Fehlergradienten aus den beiden Informationsströmen.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Und dann propagieren wir den Fehlergradienten durch den Block der mehrköpfigen Selbstaufmerksamkeit.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp; //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9)], out_grad, AO_Tensors[i * 2], AO_Tensors[i * 2 + 1], iWindowKey * iHeads, iWindow, None)) return false; //--- Passing gradient to query, key and value sa = cSceneAgnostic[i * 2 + 1]; ss = cSceneSpecific[i * 2 + 1]; if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[(i / iLayersToOneKV) * 2], kv_g, S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; } else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2], GetPointer(Temp), S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
Hier sollte besonders darauf geachtet werden, wie der Fehlergradient auf den Tensor von Schlüssel-Wert übertragen wird. Der Clou besteht darin, Fehlergradienten aus allen internen Schichten zu sammeln, die von einem bestimmten Tensor beeinflusst werden. Eine genauere Erläuterung dieses Algorithmus finden Sie in dem Artikel über die übergeordnete Klasse.
Anschließend wird der Fehlergradient entlang des Hauptinformationsflusses bis auf die Ebene der Eingabedaten zurückverfolgt.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); } if(IsStopped() || !MatMulGrad(inp, temp, QKV_Weights[i * 2], QKV_Weights[i * 2 + 1], QKV_Tensors[i * 2 + 1], iUnits, iWindow, iHeads * iWindowKey, 1)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
Wir übertragen den Fehlergradienten auch auf die Hypernetze entsprechend ihrem Einfluss auf das Gesamtergebnis des Modells.
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !MatMulGrad(inp, GetPointer(Temp), KV_Weights[i / iLayersToOneKV * 2], KV_Weights[i / iLayersToOneKV * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2 + 1], iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(!Concat(QKV_Weights[i * 2 + 1], KV_Weights[i / iLayersToOneKV * 2 + 1], ss.getGradient(), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), ss.getGradient(), ss.Activation(), sa.Activation())) return false; } else { if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), QKV_Weights[i * 2 + 1], ss.Activation(), sa.Activation())) return false; } if(i > 0) out_grad = temp; }
Danach gehen wir zur nächsten Iteration unserer Schleife durch die internen Ebenen über.
Es ist wichtig zu beachten, dass wir in der Hauptoperationsschleife den Fehlergradienten nur nach unten zu den Hypernetzen propagiert haben, aber nicht durch sie hindurch. Dies bringt eine Reihe von Nuancen mit sich. Erstens besteht unser szenenunabhängiges Hypernetwork aus nur zwei Schichten. Die erste ist statisch und gibt immer einen konstanten Wert von 1 aus. Der zweite enthält trainierbare Parameter und liefert das aktuelle Ergebnis. Im Hauptoperationsstrom geben wir den Fehlergradienten nur an die zweite Schicht weiter. Die Übertragung des Gradienten auf die statische erste Schicht wäre sinnlos. Natürlich ist dies ein Sonderfall. Hätte das Hypermodell mehr Schichten, müssten wir für alle Schichten, die trainierbare Parameter enthalten, die Logik des Rückwärtsdurchlauf der Gradienten-Backpropagation implementieren.
Die zweite Nuance bezieht sich auf das szenenabhängige Hypernetzwerk. Bei dieser Implementierung werden alle Parameter auf der Grundlage der vom aufrufenden Programm erhaltenen Szenenbeschreibung generiert. Infolgedessen muss der gesamte Fehlergradient auf diese Ebene übertragen werden. Um die Integrität des Hauptdatenflusses zu wahren, haben wir uns entschieden, die Gradientenfortpflanzung für dieses Modell in einer separaten Schleife zu behandeln. Auch hier handelt es sich um eine spezifische Implementierungsentscheidung. Wenn wir die Szenenbeschreibung aus einer anderen Quelle ableiten würden (z. B. aus der Ausgabe einer vorangehenden internen Schicht), müssten wir den Gradienten entsprechend übertragen.
Kehren wir nun zum Algorithmus unserer Methode der Gradienten-Backpropagation zurück. Nach Abschluss der umgekehrten Iteration über die internen Schichten speichern wir im Gradientenpuffer der vorherigen Schicht die Ergebnisse, die zeigen, wie die Eingabedaten die Ausgabe des Modells durch den Hauptdatenfluss beeinflusst haben. Zu diesem Puffer müssen wir nun den Beitrag der Hypernetze hinzufügen. Dazu speichern wir zunächst einen Zeiger auf den Gradientenpuffer der vorherigen Schicht in einer lokalen Variablen. Dann weisen wir dem aktuellen Ebenenobjekt vorübergehend einen Zeiger auf unseren Hilfsdatenpuffer zu.
CBufferFloat *inp_grad = prevLayer.getGradient(); if(!prevLayer.SetGradient(GetPointer(Temp), false)) return false;
Jetzt können wir den Fehlergradienten auf die vorherige Schicht übertragen, ohne befürchten zu müssen, dass zuvor gespeicherte Daten verloren gehen. Wir erstellen eine Schleife, die über die Objekte unseres kontextabhängigen Hypernetzes iteriert; in ihrem Hauptteil propagieren wir den Fehlergradienten auf die Ebene der Quelldatenschicht. Bei jeder Iteration addieren wir das aktuelle Ergebnis zu dem zuvor akkumulierten Gradienten.
for(int i = int(iLayers - 2); (i >= 0 && !IsStopped()); i -= 2) { ss = cSceneSpecific[i]; if(IsStopped() || !ss.calcHiddenGradients(cSceneSpecific[i + 1])) return false; if(IsStopped() || !prevLayer.calcHiddenGradients(ss, NULL)) return false; if(IsStopped() || !SumAndNormilize(prevLayer.getGradient(), inp_grad, inp_grad, iWindow, false, 0, 0, 0, 1)) return false; }
Nach der erfolgreichen Ausführung der Schleifenoperationen geben wir dem Objekt der vorherigen Schicht einen Zeiger auf seinen Puffer mit dem bereits akkumulierten Fehlergradienten aus allen Informationsflüssen zurück.
if(!prevLayer.SetGradient(inp_grad, false)) return false; //--- return true; }
Der Fehlergradient wird vollständig verteilt und wir geben dem aufrufenden Programm das logische Ergebnis der Ausführung der Operationen unserer Methode zur Verteilung des Fehlergradienten zurück. Ich empfehle Ihnen, sich mit der Methode der unabhängigen Aktualisierung der Modellparameter vertraut zu machen. Den vollständigen Code dieser Klasse und alle ihre Methoden finden Sie im Anhang.
2.3 Konstruktion des vollständigen Algorithmus von HyperDet3D
Zuvor haben wir die einzelnen Komponenten von HyperDet3D entwickelt. Jetzt ist es an der Zeit, alles zu einer einzigen, zusammenhängenden Struktur zusammenzufügen. Auch wenn dies relativ einfach erscheinen mag, gibt es doch einige wichtige Nuancen, die hervorzuheben sind.
Für dieses Experiment habe ich mich entschieden, die Integration auf die Architektur von Pointformer zu stützen, die im vorherigen Artikel beschrieben wurde. Die wichtigste Änderung besteht darin, dass der globale Aufmerksamkeitsblock durch unser neu konstruiertes MSA-Modul ersetzt wird. Dieser Vorgang ist recht einfach. Zumal wir alle Methodenparameter unverändert gelassen haben, einschließlich der Initialisierungsmethode der Klasse. Die Sache hat jedoch einen Haken: Alle Objekte innerhalb der ursprünglichen Klasse CNeuronPointFormer wurden als statisch deklariert. Folglich können wir nicht von der Klasse erben und die Typen ihrer internen Objekte direkt ändern. Daher erstellen wir ein Duplikat der Klasse, in dem wir die Typen der erforderlichen internen Objekte anpassen, um die neue Funktionsweise zu integrieren. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronHyperDet : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHSceneConditionAttention caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHyperDet(void) {}; ~CNeuronHyperDet(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronHyperDet; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Wir werden nicht näher auf die Methoden dieser Klasse eingehen, da sie alle durch direktes Kopieren der entsprechenden Methoden aus der Klasse CNeuronPointFormer Klasse.
Die Modellarchitektur sowie alle Interaktions- und Trainingsskripte wurden ebenfalls aus dem vorherigen Artikel übernommen. Deshalb werden wir sie jetzt nicht diskutieren. Der vollständige Quellcode für alle Programme, die bei der Erstellung dieses Artikels verwendet wurden, ist im Anhang verfügbar.
3. Tests
Wir haben umfangreiche Arbeiten durchgeführt, um unsere eigene Interpretation der von den Autoren der Methode HyperDet3D vorgeschlagenen Ansätze umzusetzen. Nun ist es an der Zeit, zum letzten Teil unseres Artikels überzugehen. Hier trainieren und testen wir die Modelle, die die beschriebenen Techniken beinhalten.
Wie immer verwenden wir zum Trainieren der Modelle reale historische Daten des Instruments EURUSD mit dem Zeitrahmen H1 für das gesamte Jahr 2023. Alle Indikatorparameter wurden auf ihre Standardwerte gesetzt. Der Trainingsprozess selbst folgt genau dem Algorithmus, der im vorherigen Artikel beschrieben wurde. Wir konzentrieren uns daher nur auf die Ergebnisse des Tests der trainierten Akteurspolitik, die im Folgenden vorgestellt werden.
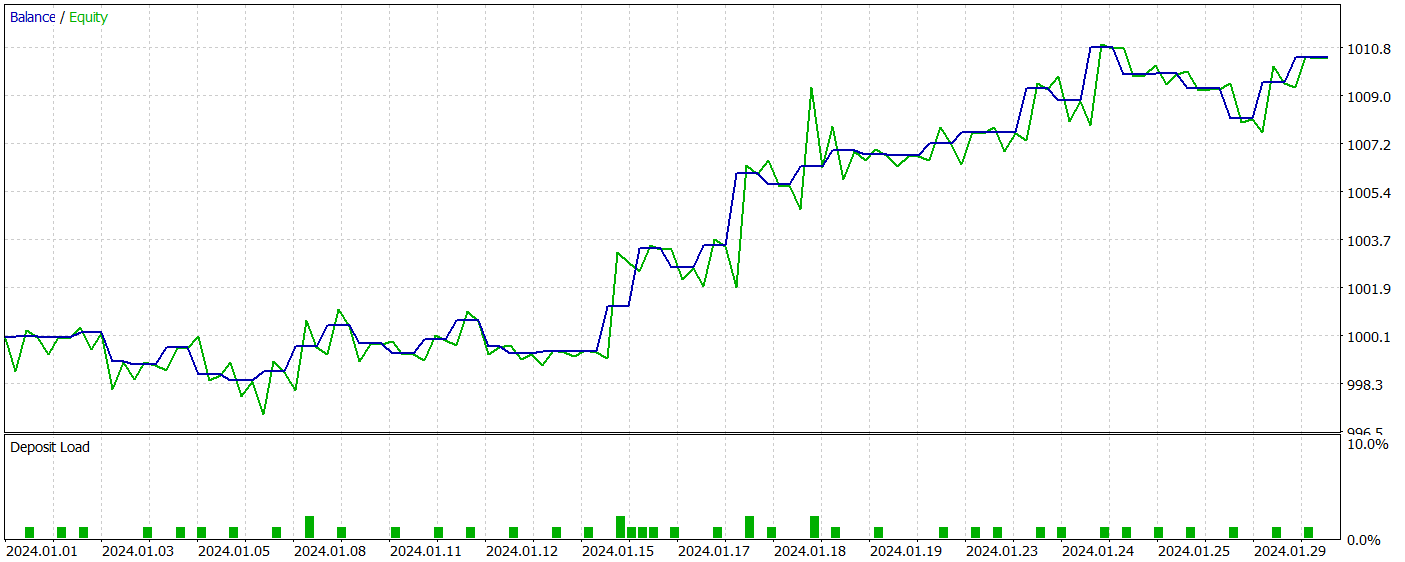
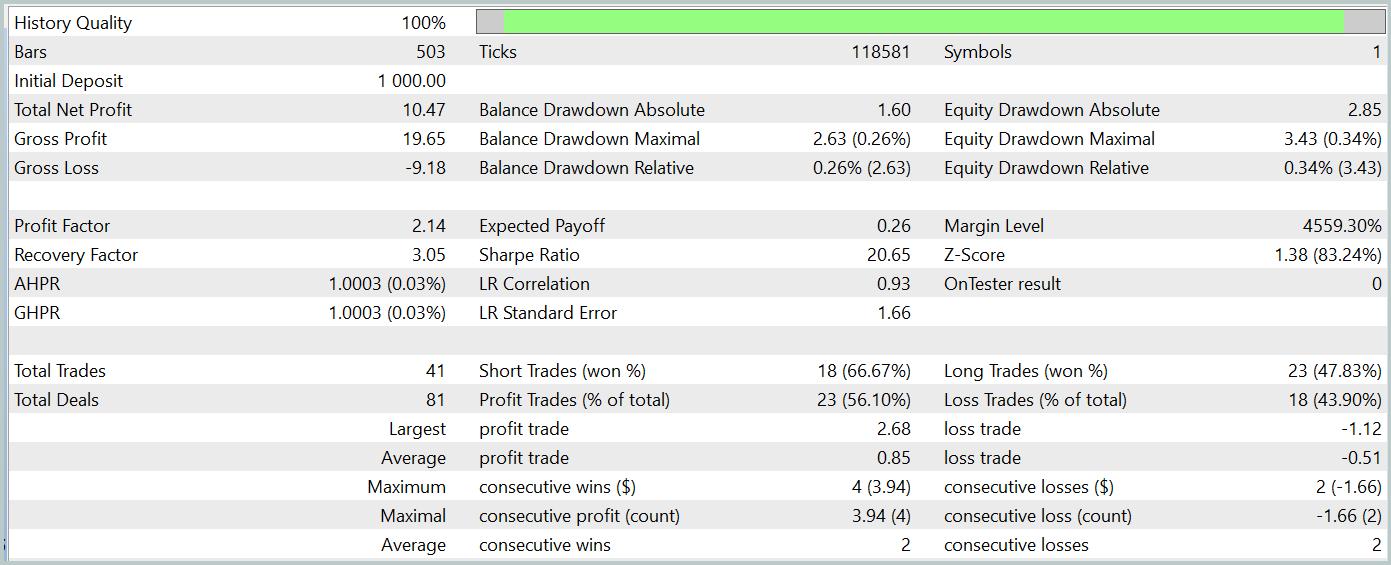
Das trainierte Modell wurde mit historischen Daten vom Januar 2024 getestet, die nicht Teil des Trainingsdatensatzes waren. In diesem Zeitraum führte das Modell 41 Handelsgeschäfte aus, von denen 56 % mit Gewinn abgeschlossen wurden. Der größte Gewinn war 2,4-mal so hoch wie der größte Verlust, und der durchschnittliche Gewinn überstieg den durchschnittlichen Verlust um 67 %. Diese Ergebnisse führten zu einem Gewinnfaktor von 2,14 und einer Sharpe Ratio von 20,65.
Insgesamt erzielte das Modell während des Testzeitraums einen Gewinn von 1 %, während der maximale Drawdown auf das Eigenkapital 0,34 % nicht überstieg. Die Inanspruchnahme des Saldos war sogar noch geringer. Die Aktienkurve zeigt einen stetigen Anstieg des Saldos, und das Kontorisiko blieb innerhalb von 1-2 %.
Der allgemeine Eindruck der Ergebnisse ist positiv. Das Modell ist vielversprechend. Aufgrund des kurzen Testzeitraums und der begrenzten Anzahl von Trades können wir jedoch keine Aussagen über die langfristige Stabilität des Modells machen. Bevor es im Live-Handel eingesetzt werden kann, sind weiteres Training mit einem größeren historischen Datensatz und umfassendere Tests erforderlich.
Schlussfolgerung
In diesem Artikel haben wir die Methode HyperDet3D untersucht, die szenenkonditionierte Hypernetze in eine Transformer-Architektur integriert, um Vorwissen einzubetten. Dadurch kann sich das Modell bei Objekterkennungsaufgaben effektiv an unterschiedliche Szenen anpassen, indem es die Detektorparameter auf der Grundlage von Szeneninformationen dynamisch abstimmt. Dadurch wird das System universeller und leistungsfähiger.
Im praktischen Teil haben wir unsere Interpretation der vorgeschlagenen Konzepte mit Hilfe von MQL5 umgesetzt und sie in unsere eigene Modellarchitektur integriert. Die Testergebnisse zeigen das Potenzial des Modells. Es sind jedoch noch weitere Arbeiten erforderlich, bevor es in der realen Welt der Finanzmärkte angewendet werden kann.
Referenzen
In diesem Artikel verwendete Programme
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15859
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.