
Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP

Contenido
- Introducción
- 1. Ideas generales sobre los modelos de GPT
- 2. Características distintivas de los modelos de GPT del Transformer anteriormente analizado
- 3. Implementación
- 3.1. Creando una nueva clase para nuestro modelo
- 3.2. Propagación hacia delante
- 3.3. Propagación inversa
- 3.4. Cambios puntuales en las clases básicas de la red neronal
- 4. Simulación
- Conclusión
- Enlaces
- Programas utilizados en el artículo
Introducción
En junio de 2018, OpenAI presentó al mundo el modelo de red neuronal GPT, que mostró de inmediato los mejores resultados en una serie de pruebas de lenguaje. En febrero de 2019, apareció GPT-2 y en mayo de 2020, se dio a conocer GPT-3. Estos modelos mostraron las capacidades de una red neuronal para generar texto relacionado. También se realizaron experimentos para generar música e imágenes. Podríamos decir que la principal desventaja de los modelos son los requisitos de los recursos informáticos. Para entrenar el primer GPT en una máquina con 8 GPU, se requirió un mes. Esta desventaja se ve parcialmente compensada por la posibilidad de usar modelos previamente entrenados para resolver nuevos problemas. No obstante, las dimensiones del modelo requieren recursos para su funcionamiento.
1. Ideas generales sobre los modelos de GPT
Conceptualmente, los modelos de GPT se construyen usando como base el Transformer ya analizado. La idea principal consiste en entrenar previamente el modelo sin supervisión con una gran cantidad de datos y luego ajustarlo según una cantidad relativamente pequeña de datos etiquetados.
Realizamos el entrenamiento en dos pasos debido al tamaño del modelo. Los modelos modernos de aprendizaje automático profundo como el GPT poseen una enorme cantidad de parámetros, cuyo número alcanza ya los cientos de millones. En consecuencia, entrenar dichas redes neuronales requiere una muestra de entrenamiento gigantesca. Cuando usamos el aprendizaje supervisado, la creación de un conjunto de entrenamiento etiquetado requerirá mucho esfuerzo. Al mismo tiempo, ahora existen muchos textos digitalizados diferentes y sin etiquetar en la web que sirven estupendamente para entrenar un modelo sin supervisión. No obstante, los resultados del aprendizaje no supervisado, desde un punto estadístico, resultan inferiores a los del aprendizaje supervisado. Por consiguiente, tras realizar un entrenamiento no supervisado, el modelo se ajusta en una muestra relativamente pequeña de datos etiquetados.
El aprendizaje no supervisado permite al GPT aprender el modelo de lenguaje, mientras que el ajuste específico con datos marcados configura el modelo para tareas específicas. Por ello, podemos replicar un modelo previamente entrenado y ajustar este para realizar diferentes tareas de lenguaje. Como limitación actúa el lenguaje de la muestra original para el aprendizaje no supervisado.
Como ha demostrado la práctica, este enfoque ofrece buenos resultados en una amplia gama de problemas relacionados con el lenguaje. Por ejemplo, el modelo GPT-3 puede generar textos relacionados sobre un tema concreto. Pero aquí debemos considerar que este modelo contiene 175 mil millones de parámetros y ha sido previamente entrenado en un conjunto de datos de 570 GB.
A pesar de que los modelos de GPT se desarrollaron para el procesamiento del lenguaje natural, también han mostrado resultados notables en las tareas de generación de música e imágenes.
En teoría, podemos usar modelos de GPT con cualquier secuencia de datos digitalizados. La cuestión aquí es si tendremos datos y recursos suficientes para implementar aprendizaje previo no supervisado.
2. Características distintivas de los modelos de GPT del Transformer anteriormente analizado
Vamos a analizar las características distintivas de los modelos de GPT del Transformer anteriormente estudiado. En primer lugar, en los modelos de GPT abandonaron el uso del codificador, dejando solo el decodificador. Al mismo tiempo, el rechazo del codificador redundó en el rechazo de la capa interna del Encoder-Decoder Self-Attention. La figura de abajo muestra un bloque del Transformer de GPT.
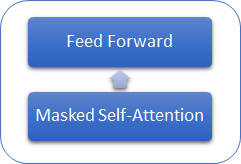
Como en el Transformer clásico, en los modelos de GPT, estos bloques se construyen uno encima del otro. Y cada bloque posee sus propias matrices de coeficientes de peso para el mecanismo de atención y las capas Feed Forward completamente conectadas. La cantidad de dichos bloques determina el tamaño del modelo. Resulta que la pila de bloques puede tener un tamaño considerable. En el GPT-1 y el más pequeño de los GPT-2 (GPT-2 Small) son 12, en el GPT-2 Extra Large, son 48, y en el GPT-3, son ya 96.
Al igual que los modelos de lenguaje tradicionales, el GPT nos permite encontrar relaciones solo con los elementos anteriores de la secuencia, sin permitirnos mirar hacia el futuro. Pero a diferencia del transformador, no utiliza enmascaramiento de elementos, sino que realiza cambios en el proceso computacional. En el GPT, se resetean los coeficientes de atención en la matriz Score para los elementos posteriores.
Al mismo tiempo, el GPT se puede clasificar como un modelo autorregresivo. Al generar un token de secuencia en cada iteración, el token resultante se añade a la secuencia de entrada y se suministra a la entrada del modelo para la siguiente iteración.
Como en el Transformer clásico, dentro del mecanismo de auto-atención se generan tres vectores para cada token: consulta (query), clave (key) y valor (valur). En el modelo autorregresivo, cuando en cada nueva iteración la secuencia de entrada cambia en solo 1 token, no resulta necesario recalcular los vectores para cada token. Por consiguiente, en el GPT, cada capa calcula los vectores solo para los nuevos elementos de la secuencia y los almacena para cada elemento de la misma. Cada bloque del Transformer almacena sus propios vectores para su posterior uso.
Este enfoque hace posible que el modelo genere textos palabra por palabra antes de obtener el token final.
Y, obviamente, los modelos de GPT usan un mecanismo de auto-atención de varias cabezas.
3. Implementación
Antes de proceder a la implementación, vamos a repitir brevemente el algoritmo:
- La secuencia del token de entrada se suministra a la entrada del bloque del Transformer.
- Calculamos los 3 vectores (query, key, value) para cada token multiplicando el vector del token por la matriz de entrenamiento correspondiente de los coeficientes de peso W.
- Multiplicando los vectores query y key, determinamos las dependencias entre los elementos de la secuencia. En esta etapa, el vector query de cada elemento de la secuencia se multiplica por los vectores key del elemento actual y todos los elementos anteriores de la secuencia.
- La matriz de los coeficientes de atención obtenida se normaliza usando la función Softmax en el contexto de cada consulta (query). En este caso, establecemos un coeficiente de atención cero para los elementos posteriores de la secuencia.
- Multiplicando los coeficientes de atención normalizados por los vectores value de los elementos correspondientes de la secuencia y luego sumando los vectores resultantes, obtenemos el valor de atención corregido para cada elemento de la secuencia (Z).
- A continuación, determinamos el vector ponderado Z según los resultados del procesamiento de todas las cabezas de atención. Para ello, los vectores value corregidos de todas las cabezas de atención se concatenan en un solo vector y se multiplican por la matriz de entrenamiento W0.
- El tensor resultante se añade a la secuencia de entrada y se normaliza.
- Al mecanismo Multi-Heads Self-Attention le siguen las 2 capas completamente conectadas del bloque Feed Forward. La primera capa (oculta) contiene 4 veces más neuronas que la secuencia de entrada con la función de activación ReLU. La dimensión de la segunda capa es igual a la dimensión de la secuencia de entrada y las neuronas no usan la función de activación.
- Sumamos al tensor suministrado a la entrada del bloque Feed Forward el resultado del procesamiento de las capas completamente conectadas, y normalizamos el tensor resultante.
Una secuencia para todas las cabezas (hilos) de auto-atención. Además, las acciones de los puntos 2-5 resultan idénticas para cada cabeza de atención.
Como resultado de los pasos 3 y 4, obtenemos una puntuación de matriz cuadrada igual al número de elementos en la secuencia, donde la suma de todos los elementos en el contexto de cada consulta es "1".
3.1. Creando una nueva clase para nuestro modelo.
Para implementar nuestro modelo, crearemos una nueva clase CNeuronMLMHAttentionOCL basada en la clase base CNeuronBaseOCL. Aquí, hemos dado a propósito un paso atrás y no hemos utilizado las clases de atención que creamos antes. Esto se realaciona con el cambio en los principios de creación de la auto-atención multi-cabeza. Recordemos que en el artículo [10] creamos la clase CNeuronMHAttentionOCL, en la que organizamos el recálculo secuencial de 4 hilos de atención. En este caso, el número de hilos está integrado en el código del método y un cambio en el número de hilos requerirá un esfuerzo significativo a la hora de realizar cambios en el código de la clase y sus métodos.
Y otra cosa importante. Como hemos mencionado anteriormente, el modelo de GPT usa una pila de bloques idénticos del Transformer con los mismos hiperparámetros (inmutables), la única diferencia reside en las matrices entrenadas. Por consiguiente, hemos decidido crear un bloque multicapa que permita crear modelos con los hiperparámetros transmitidos al crear una clase, incluido el número de repeticiones de los bloques del Transformer en la pila.
Como resultado, obtuvimos una clase que puede crear casi todo el modelo según varios parámetros especificados. Entonces, en el bloque protegido de la nueva clase, declaramos 5 variables para almacenar los parámetros del bloque:
| iLayers | Número de bloques del Transformer en el modelo |
| iHeads | Número de cabezas de atención |
| iWindow | Tamaño de la ventana de entrada (del token de secuencia de entrada) |
| iWindowKey | Dimensión de los vectores internos Query, Key, Value |
| iUnits | Número de elementos (tokens) en la secuencia de entrada. |
Además, en el bloque protegido, declaramos 6 matrices para almacenar una colección de búferes para nuestros tensores y matrices de peso de entrenamiento:
| QKV_Tensors | Matriz para guardar los tensores Query, Key, Value y sus gradientes |
| QKV_Weights | Matriz para guardar las matrices de peso Wq, Wk, Wv y las matrices de sus momentos |
| S_Tensors | Matriz para guardar la colección de matrices Score y sus gradientes |
| AO_Tensors | Matriz para guardar los tensores de salida del mecanismo de auto-atención y sus gradientes. |
| FF_Tensors | Matriz para guardar los tensores de entrada, ocultos y de salida del bloque Feed Forward y sus gradientes |
| FF_Weights | Matriz para guardar las matrices de peso del bloque Feed Forward y sus momentos. |
Proponemos al lector familiarizarse con los métodos de clase más adelante, a medida que los implementemos.
class CNeuronMLMHAttentionOCL : public CNeuronBaseOCL { protected: uint iLayers; ///< Number of inner layers uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CCollection *QKV_Tensors; ///< The collection of tensors of Queries, Keys and Values CCollection *QKV_Weights; ///< The collection of Matrix of weights to previous layer CCollection *S_Tensors; ///< The collection of Scores tensors CCollection *AO_Tensors; ///< The collection of Attention Out tensors CCollection *FF_Tensors; ///< The collection of tensors of Feed Forward output CCollection *FF_Weights; ///< The collection of Matrix of Feed Forward weights ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. virtual bool ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ); ///< \brief Convolution Feed Forward method of calling kernel ::FeedForwardConv(). virtual bool AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true); ///< \brief Multi-heads attention scores method of calling kernel ::MHAttentionScore(). virtual bool AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out); ///< \brief Multi-heads attention out method of calling kernel ::MHAttentionOut(). virtual bool SumAndNormilize(CBufferDouble *tensor1, CBufferDouble *tensor2, CBufferDouble *out); ///< \brief Method sum and normilize 2 tensors by calling 2 kernels ::SumMatrix() and ::Normalize(). ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. virtual bool ConvolutuionUpdateWeights(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *momentum1, CBufferDouble *momentum2, uint window, uint window_out); ///< Method for updating weights in convolution layer.\details Calling one of kernels ::UpdateWeightsConvMomentum() or ::UpdateWeightsConvAdam() in depends of optimization type (#ENUM_OPTIMIZATION). virtual bool ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ); ///< Method of passing gradients through a convolutional layer. virtual bool AttentionInsideGradients(CBufferDouble *qkv,CBufferDouble *qkv_g,CBufferDouble *scores,CBufferDouble *scores_g,CBufferDouble *gradient); ///< Method of passing gradients through attention layer. public: /** Constructor */CNeuronMLMHAttentionOCL(void); /** Destructor */~CNeuronMLMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMLMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
En el constructor de la clase, establecemos los valores iniciales de los hiperparámetros de la clase e inicializamos las matrices de nuestras colecciones.
CNeuronMLMHAttentionOCL::CNeuronMLMHAttentionOCL(void) : iLayers(0), iHeads(0), iWindow(0), iWindowKey(0), iUnits(0) { QKV_Tensors=new CCollection(); QKV_Weights=new CCollection(); S_Tensors=new CCollection(); AO_Tensors=new CCollection(); FF_Tensors=new CCollection(); FF_Weights=new CCollection(); }
En consecuencia, eliminamos las matrices de colección en el destructor de clases.
CNeuronMLMHAttentionOCL::~CNeuronMLMHAttentionOCL(void) { if(CheckPointer(QKV_Tensors)!=POINTER_INVALID) delete QKV_Tensors; if(CheckPointer(QKV_Weights)!=POINTER_INVALID) delete QKV_Weights; if(CheckPointer(S_Tensors)!=POINTER_INVALID) delete S_Tensors; if(CheckPointer(AO_Tensors)!=POINTER_INVALID) delete AO_Tensors; if(CheckPointer(FF_Tensors)!=POINTER_INVALID) delete FF_Tensors; if(CheckPointer(FF_Weights)!=POINTER_INVALID) delete FF_Weights; }
La propia inicialización de la clase y la construcción del modelo se llevan a cabo en el método Init. En los parámetros, el método recibe:
| numOutputs | Número de elementos en la capa siguiente para crear conexiones. |
| myIndex | Índice de la neurona en la capa |
| open_cl | Puntero al indicador OpenCL |
| window | Tamaño de la ventana de entrada (del token de secuencia de entrada) |
| window_key | Dimensión de los vectores internos Query, Key, Value |
| heads | Número de cabezas (hilos) de atención |
| units_count | Número de elementos en la secuencia de entrada. |
| layers | Número de bloques (capas) en la pila del modelo |
| optimization_type | Método de optimización de los parámetros durante el entrenamiento |
bool CNeuronMLMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint window_key,uint heads,uint units_count,uint layers,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,window*units_count,optimization_type)) return false; //--- iWindow=fmax(window,1); iWindowKey=fmax(window_key,1); iUnits=fmax(units_count,1); iHeads=fmax(heads,1); iLayers=fmax(layers,1);
Al comienzo del método, inicializamos la clase padre llamando al método correspondiente. Debemos tener en cuenta que no estamos haciendo verificaciones básicas sobre la validez del puntero del objeto OpenCL resultante y el tamaño de la secuencia de entrada, ya que estas comprobaciones ya se han implementado en el método de la clase principal.
Después de inicializar con éxito la clase principal, guardamos los hiperparámetros en las variables correspondientes.
A continuación, calculamos los tamaños de los tensores creados. Aquí debemos prestar atención al enfoque modificado mencionado anteriormente para organizar la atención multi-cabeza. No vamos a crear matrices aparte para los vectores query, key y value, pero sí que los combinaremos en una matriz. Además, no vamos a crear matrices aparte para cada cabeza de atención, sino que crearemos matrices generales de QKV (query + key + value), Scores y salidas del mecanismo de auto-atención. Dividiremos los elementos en secuencias a nivel de índices en el tensor. Este enfoque, claro está, ofrece mayores dificultades a la hora de comprender y encontrar el elemento requerido en el tensor, pero nos permite flexibilizar el modelo según el número de cabezas de atención y organizar el recálculo simultáneo de todas las cabezas de atención paralelizando los hilos al nivel de los kernels.
Entonces, el tamaño del tensor QKV_Tensor (num) se define como el producto de los 3 tamaños del vector interno (query + key + value) por el número de cabezas. La dimensión de la matriz de pesos concatenada QKV_Weight se define como el producto de los 3 tamaños del token de la secuencia de entrada incrementado por el elemento de compensación, por el tamaño del vector interno y el número de cabezas de atención. Del mismo modo, calculamos las dimensiones de los tensores restantes.
uint num=3*iWindowKey*iHeads*iUnits; //Size of QKV tensor uint qkv_weights=3*(iWindow+1)*iWindowKey*iHeads; //Size of weights' matrix of QKV tenzor uint scores=iUnits*iUnits*iHeads; //Size of Score tensor uint mh_out=iWindowKey*iHeads*iUnits; //Size of multi-heads self-attention uint out=iWindow*iUnits; //Size of our tensore uint w0=(iWindowKey+1)*iHeads*iWindow; //Size W0 tensor uint ff_1=4*(iWindow+1)*iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2=(4*iWindow+1)*iWindow; //Size of weights' matrix 2-nd feed forward layer
Después de determinar las dimensiones de todos los tensores, iniciamos un ciclo por el número de capas de atención en nuestro bloque para crear los tensores necesarios. No conviene olvidar que dentro del cuerpo del ciclo hay dos ciclos anidados organizados. El primero crea las matrices para los tensores de los valores y sus gradientes. En el segundo, se crean matrices para las matrices de pesos y sus momentos. No olvidemos que para la última capa no se crean nuevas matrices para el tensor de salida del bloque Feed Forward y su gradiente; en su lugar, se añaden a la colección los punteros a las matrices de los valores de salida y los gradientes de la clase padre. Un paso tan sencillo nos permitirá excluir la iteración innecesaria para la transferencia de valores entre las matrices y descartar un consumo de memoria igualmente innecesario.
for(uint i=0; i<iLayers; i++) { CBufferDouble *temp=NULL; for(int d=0; d<2; d++) { //--- Initilize QKV tensor temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(num,0)) return false; if(!QKV_Tensors.Add(temp)) return false; //--- Initialize scores temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(scores,0)) return false; if(!S_Tensors.Add(temp)) return false; //--- Initialize multi-heads attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(mh_out,0)) return false; if(!AO_Tensors.Add(temp)) return false; //--- Initialize attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(4*out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i==iLayers-1) { if(!FF_Tensors.Add(d==0 ? Output : Gradient)) return false; continue; } temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; } //--- Initilize QKV weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; for(uint w=0; w<qkv_weights; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!QKV_Weights.Add(temp)) return false; //--- Initilize Weights0 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w=0; w<w0; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- for(int d=0; d<(optimization==SGD ? 1 : 2); d++) { temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights,0)) return false; if(!QKV_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(w0,0)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_1,0)) return false; if(!FF_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_2,0)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Como resultado, para cada capa, obtendremos la matriz de tensores que vemos más abajo.
| QKV_Tensor |
|
| S_Tensors |
|
| AO_Tensors |
|
| FF_Tensors |
|
| QKV_Weights |
|
| FF_Weights |
|
Después de crear las colecciones de matrices, salimos del método con el resultado true. Podrá familiarizarse con el código completo de todas las clases y sus métodos en los anexos.
3.2. Propagación hacia delante.
La propagación hacia adelante se organiza tradicionalmente en el método feedForward, al cual transmitimos en los parámetros un puntero a la capa anterior de la red neuronal. Al comienzo del método, verificamos que el puntero resultante sea válido.
bool CNeuronMLMHAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false;
A continuación, organizamos un ciclo para recalcular todas las capas de nuestro bloque. A diferencia de los métodos homónimos de otras clases descritos anteriormente, este método es de nivel superior. Las operaciones organizadas en él se reducen a la preparación de datos y la llamada a métodos auxiliares, cuya lógica describiremos a continuación.
Al comienzo del ciclo, obtenemos de la colección los búferes de datos de entrada de los tensores QKV y QKV_Weights correspondientes a la capa actual. Y llamamos al método ConvolutionForward para calcular los vectores Query, Key y Value.
for(uint i=0; (i<iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferDouble *inputs=(i==0? NeuronOCL.getOutput() : FF_Tensors.At(6*i-4)); CBufferDouble *qkv=QKV_Tensors.At(i*2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),inputs,qkv,iWindow,3*iWindowKey*iHeads,None)) return false;
Otro punto que encontramos al aumentar las capas de atención. En algún momento, obtuvimos el error5113 ERR_OPENCL_TOO_MANY_OBJECTS, lo que nos hizo pensar en guardar todos los tensores de forma permanente en la memoria de la GPU. Por consiguiente, después de completar las operaciones, liberaremos los búferes que ya no se usarán en este paso. En los desarrollos, no debemos olvidar leer los últimos datos de los búferes liberados de la memoria de la GPU. En la clase presentada en el artículo, la lectura de los datos de estos búferes se efectúa en los métodos de inicialización de los kernels de los que hablaremos un poco más adelante.
CBufferDouble *temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree();
De manera semejante, llamando a los métodos correspondientes, calculamos los coeficientes de atención y los vectores ponderados de los valores del mecanismo Self-Attention.
//--- Score calculation temp=S_Tensors.At(i*2); if(IsStopped() || !AttentionScore(qkv,temp,true)) return false; //--- Multi-heads attention calculation CBufferDouble *out=AO_Tensors.At(i*2); if(IsStopped() || !AttentionOut(qkv,temp,out)) return false; qkv.BufferFree(); temp.BufferFree();
Después de calcular Multi-Heads Self-Attention, reducimos la salida de atención concatenada hasta el tamaño de la secuencia de entrada, añadimos dos vectores y normalizamos el resultado.
//--- Attention out calculation temp=FF_Tensors.At(i*6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out,temp,iWindowKey*iHeads,iWindow,None)) return false; out.BufferFree(); //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp,inputs,temp)) return false; if(i>0) inputs.BufferFree();
Al mecanismo de auto-atención en el algoritmo del Transformer le sigue el bloque Feed Forward, que consta de dos capas completamente conectadas y la suma posterior del resultado a la secuencia de entrada. Normalizamos el tensor total y lo suministramos a la siguiente capa. En nuestro caso, cerramos el ciclo.
//--- Feed Forward inputs=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),inputs,temp,iWindow,4*iWindow,LReLU)) return false; out=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); out.BufferFree(); out=FF_Tensors.At(i*6+2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),temp,out,4*iWindow,iWindow,activation)) return false; temp.BufferFree(); temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out,inputs,out)) return false; inputs.BufferFree(); } //--- return true; }
Podrá entontrar el código completo del método en el archivo adjunto: ahora vamos a ver los métodos auxiliares llamados desde el método feedForward. En primer lugar, llamamos al método ConvolutionForward, que se llama 4 veces en un ciclo del método de propagación hacia delante. El cuerpo de este método llama al kernel de propagación hacia delante de la capa convolucional, que en este caso actúa como una capa completamente conectada para cada token individual de la secuencia de entrada. Ya discutimos esta solución con más detalle en el artículo [8]. A diferencia de la solución que describimos antes, el nuevo método recibe en los parámetros los punteros a los búferes para transmitir los datos al kernel de OpenCL. Por consiguiente, al comienzo del método, verificamos la validez de los punteros recibidos.
bool CNeuronMLMHAttentionOCL::ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(outputs)==POINTER_INVALID) return false;
El siguiente paso consistirá en crear búferes en la memoria de la GPU y transmitirles la información necesaria.
if(!weights.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!outputs.BufferCreate(OpenCL)) return false;
Después viene el código descrito en el artículo [8] sin cambios. El kernel llamado se utiliza sin cambios.
uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=outputs.Total()/window_out; OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_i,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_o,outputs.GetIndex()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_inputs,inputs.Total()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_step,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_window_in,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffс_window_out,window_out); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_activation,(int)activ); if(!OpenCL.Execute(def_k_FeedForwardConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel FeedForwardConv: %d",GetLastError()); return false; } //--- return outputs.BufferRead(); }
Además, según el código del método feedForward, llamamos al método AttentionScore, en el que se llama el kernel para calcular y normalizar los coeficientes de atención, con el posterior registro de los valores obtenidos en la matriz Score. Hemos escrito de nuevo el kernel para este método, lo revisaremos después de analizar el método.
Al igual que el método anterior, el método AttentionScore obtiene en los parámetros los punteros a los búferes de los datos iniciales y a los registros de los valores obtenidos. En consecuencia, al inicio del método, comprobamos la validez de los punteros obtenidos.
bool CNeuronMLMHAttentionOCL::AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID) return false;
Siguiendo la lógica descrita con anterioridad, creamos los búferes de intercambio de datos con la GPU.
if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false;
Después de efectuar el trabajo preparatorio, procederemos a establecer los parámetros del kernel. Crearemos los hilos de este kernel en dos dimensiones: en el contexto de los elementos de la secuencia de entrada y en el contexto de las cabezas de atención. Así, podremos organizar el cálculo paralelo para todos los elementos de la secuencia y todas las cabezas de atención.
uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_score,scores.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_dimension,iWindowKey); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_mask,(int)mask);
Después, pasamos directamente a la llamada del kernel. Y leemos los resultados de los cálculos en el búfer Score.
if(!OpenCL.Execute(def_k_MHAttentionScore,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionScore: %d",GetLastError()); return false; } //--- return scores.BufferRead(); }
Vamos a analizar la lógica del kernel MHAttentionScore llamado. Como mostramos arriba, el kernel recibe en los parámetros un puntero a la matriz de datos de origen qkv y una matriz para registrar los resultados de la puntuación. Además, al kernel se le transmite en los parámetros la dimensión de los vectores internos (Query, Key) y la bandera para activar el algoritmo de enmascaramiento para los elementos subsecuentes.
Primero, obtenemos los números ordinales de la solicitud "q" procesada y la cabeza de atención "h", así como las dimensiones del número de solicitudes y las cabezas de atención.
__kernel void MHAttentionScore(__global double *qkv, ///<[in] Matrix of Querys, Keys, Values __global double *score, ///<[out] Matrix of Scores int dimension, ///< Dimension of Key int mask ///< 1 - calc only previous units, 0 - calc all ) { int q=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1);
Usando como base los datos obtenidos, determinamos el desplazamiento de las matrices para query y score.
int shift_q=dimension*(h+3*q*heads); int shift_s=units*(h+q*heads);
Después, calculamos el coeficiente para la corrección de Score.
double koef=sqrt((double)dimension); if(koef<1) koef=1;
Realizaremos el cálculo de los coeficientes de atención en un ciclo en el que pasaremos por las claves de toda la secuencia de elementos en la cabeza de atención correspondiente.
Al comienzo del ciclo, comprobamos la condición para usar el mecanismo de atención. Si dicha funcionalidad está activada, comprobaremos el número ordinal de la clave. Si la clave actual se corresponde con el siguiente elemento de la secuencia, registraremos el coeficiente cero en la matriz score y pasaremos al siguiente elemento.
double sum=0; for(int k=0;k<units;k++) { if(mask>0 && k>q) { score[shift_s+k]=0; continue; }
Si calculamos el coeficiente de atención para la clave analizada, organizaremos un ciclo anidado para calcular el producto de los dos vectores. Debemos señalar que en el cuerpo del ciclo se organizan dos ramas de cálculo: con uso de cálculos vectoriales y sin él. La primera rama se utiliza en los casos en que tenemos 4 o más elementos desde la posición actual en el vector de clave hasta su último elemento; la segunda rama se utiliza para los 4 últimos elementos impares del vector de clave.
double result=0; int shift_k=dimension*(h+heads*(3*k+1)); for(int i=0;i<dimension;i++) { if((dimension-i)>4) { result+=dot((double4)(qkv[shift_q+i],qkv[shift_q+i+1],qkv[shift_q+i+2],qkv[shift_q+i+3]), (double4)(qkv[shift_k+i],qkv[shift_k+i+1],qkv[shift_k+i+2],qkv[shift_k+i+3])); i+=3; } else result+=(qkv[shift_q+i]*qkv[shift_k+i]); }
No olvidemos que, según el algoritmo del Transformer, los coeficientes de atención son normalizados por la función softmax. Para implementar este punto, dividiremos el resultado del producto de los vectores por nuestro factor de corrección y determinaremos el exponente para el valor resultante. Vamos a escribir el resultado del cálculo en el elemento correspondiente del tensor score y a sumarlo a la suma de los exponentes.
result=exp(clamp(result/koef,-30.0,30.0)); if(isnan(result)) result=0; score[shift_s+k]=result; sum+=result; }
De esta forma, calcularemos los exponentes para todos los elementos. Para completar la normalización de los coeficientes de atención por parte de Softmax, organizaremos otro ciclo en el que dividiremos todos los elementos del tensor Score por la suma de exponentes previamente calculada.
for(int k=0;(k<units && sum>1);k++) score[shift_s+k]/=sum; }
Al final del ciclo, saldremos del kernel.
Vamos a continuar con el método feedForward y a analizar el siguiente método auxiliar, AttentionOut. En los parámetros, este método obtiene los punteros a 3 tensores: QKV, Scores y Out. Internamente, el método se construye de forma parecida a los analizados anteriormente, e inicia el kernel MHAttentionOut en dos dimensiones: los elementos de secuencia y las cabezas de atención.
bool CNeuronMLMHAttentionOCL::AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID || CheckPointer(out)==POINTER_INVALID) return false; uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false; if(!out.BufferCreate(OpenCL)) return false; //--- OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_score,scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_out,out.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionOut,def_k_mhao_dimension,iWindowKey); if(!OpenCL.Execute(def_k_MHAttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionOut: %d",GetLastError()); return false; } //--- return out.BufferRead(); }
El kernel MHAttentionOut, al igual que el anterior, lo hemos escrito nuevamente considerando la atención multi-cabeza y el uso de un solo búfer para los tensores de consulta, claves y valores. En los parámetros, el kernel recibe los punteros a los tensores Scores, QKV, Out y la dimensión del vector de valores. El primer y segundo búfer contienen los datos originales, mientras que el último sirve para registrar el resultado.
Asimismo, al inicio del kernel, definimos los números ordinales de la solicitud "q" procesada, la cabeza de atención "h" y la dimensión del número de solicitudes y cabezas de atención.
__kernel void MHAttentionOut(__global double *scores, ///<[in] Matrix of Scores __global double *qkv, ///<[in] Matrix of Values __global double *out, ///<[out] Output tesor int dimension ///< Dimension of Value ) { int u=get_global_id(0); int units=get_global_size(0); int h=get_global_id(1); int heads=get_global_size(1);
El siguiente consiste en determinar la posición del coeficiente de atención deseado y el primer elemento del vector de valores de salida analizado. Además, calcularemos la longitud del vector de un elemento en el tensor QKV; este valor se usará para determinar el desplazamiento por el tensor QKV.
int shift_s=units*(h+heads*u); int shift_out=dimension*(h+heads*u); int layer=3*dimension*heads;
Para realizar la mayor parte de los cálculos, organizaremos ciclos anidados: externos en la dimensión del vector de valores, e internos en el número de elementos en la secuencia original. Al inicio del ciclo externo, declararemos e inicializaremos con un valor cero la variable para calcular el valor resultante. El ciclo interno comenzará por la definición del desplazamiento para el vector de valores. No debemos olvidar que el salto del ciclo interior es 4, ya que hemos previsto utilizar cálculos vectoriales más tarde.
for(int d=0;d<dimension;d++) { double result=0; for(int v=0;v<units;v+=4) { int shift_v=dimension*(h+heads*(3*v+2))+d;
Igual que sucede en el kernel MHAttentionScore, dividiremos los cálculos en 2 hilos: usando cálculos vectoriales y sin ellos. La segunda secuencia se usará solo para los últimos elementos, cuando la longitud de la secuencia no sea múltipla de 4.
if((units-v)>4) { result+=dot((double4)(scores[shift_s+v],scores[shift_s+v+1],scores[shift_s+v+1],scores[shift_s+v+3]), (double4)(qkv[shift_v],qkv[shift_v+layer],qkv[shift_v+2*layer],qkv[shift_v+3*layer])); } else for(int l=0;l<(int)fmin((double)(units-v),4.0);l++) result+=scores[shift_s+v+l]*qkv[shift_v+l*layer]; } out[shift_out+d]=result; } }
Después de salir del ciclo anidado, escribiremos el valor resultante en el elemento correspondiente del tensor de salida.
Además, en el método feedForward, usaremos el método ConvolutionForward anterior. El lector podrá familiarizarse con el código de todos los métodos y funciones en los anexos.
3.3. Propagación inversa.
La propagación inversa, como todas las clases analizadas anteriormente, se divide en 2 hilos: la distribución del gradiente de error y la corrección directa de los coeficientes de ponderación. La primera parte se implementa en el método calcInputGradients y la segunda en el método updateInputWeights.
La construcción del método calcInputGradients es similar a la construcción del método feedForward. En los parámetros, el método obtiene el puntero a la capa de neuronas anterior, a la que deberemos transmitir el gradiente de error; al inicio del método, comprobaremos la validez del puntero recibido.
bool CNeuronMLMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Luego, fijamos el tensor del gradiente resultante de la siguiente capa de neuronas y organizamos un ciclo para iterar sobre todas las capas internas y así recalcular secuencialmente el gradiente de error. Como tenemos un proceso de propagación inversa, el ciclo iterará sobre las capas internas en orden inverso.
for(int i=(int)iLayers-1; (i>=0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),out_grad,FF_Tensors.At(i*6+1),FF_Tensors.At(i*6+4),4*iWindow,iWindow,None)) return false; CBufferDouble *temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(i*6+4),FF_Tensors.At(i*6),temp,iWindow,4*iWindow,LReLU)) return false;
Al inicio del ciclo, calculamos el paso del gradiente de error a través de las capas de neuronas completamente conectadas en el bloque Feed Forward del Transformer. Para efectuar esta iteración, utilizaremos el método ConvolutionInputGradients. Después de ejecutar el método, liberaremos los búferes utilizados.
Como en nuestro algoritmo se organiza la transferencia de datos de un extremo a otro, necesitaremos un proceso similar para el gradiente de error. Por consiguiente, sumaremos el gradiente de error resultante del bloque Feed Forward al gradiente de error obtenido de la capa de neuronas anterior. Para excluir el riesgo de una "explosión de gradiente", normalizaremos la suma de los dos vectores. Las operaciones descritas se realizarán en el método SumAndNormilize. Después de ejecutar el método, liberaremos los búferes utilizados.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; if(i!=(int)iLayers-1) out_grad.BufferFree(); out_grad=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+4); temp.BufferFree(); temp=FF_Tensors.At(i*6); temp.BufferFree();
Tras descender por nuestro algoritmo, dividiremos el gradiente de error por las cabezas de atención. Para hacerlo, llamaremos al método ConvolutionInputGradients para la matriz W0.
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out_grad,AO_Tensors.At(i*2),AO_Tensors.At(i*2+1),iWindowKey*iHeads,iWindow,None)) return false; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=AO_Tensors.At(i*2); temp.BufferFree();
El paso posterior del gradiente dentro de las cabezas de atención se organizará en el método AttentionInsideGradients.
if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i*2),QKV_Tensors.At(i*2+1),S_Tensors.At(i*2),S_Tensors.At(i*2+1),AO_Tensors.At(i*2+1))) return false; temp=QKV_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2+1); temp.BufferFree(); temp=AO_Tensors.At(i*2+1); temp.BufferFree();
Al final del ciclo, calcularemos el gradiente de error transmitido a la capa anterior. Para hacerlo, pasaremos el gradiente de error obtenido en la iteración anterior a través del tensor QKV_Weights concatenado, y luego añadiremos el vector resultante al gradiente de error del bloque Feed Forward del mecanismo de auto-atención y normalizaremos el resultado para evitar el riesgo de una explosión de gradientes.
CBufferDouble *inp=NULL; if(i==0) { inp=prevLayer.getOutput(); temp=prevLayer.getGradient(); } else { temp=FF_Tensors.At(i*6-1); inp=FF_Tensors.At(i*6-4); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(i*2+1),inp,temp,iWindow,3*iWindowKey*iHeads,None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; out_grad.BufferFree(); if(i>0) out_grad=temp; temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(i*2+1); temp.BufferFree(); } //--- return true; }
No debemos olvidar liberar los búferes de datos utilizados. En este caso, deberemos tener en cuenta que los búferes de datos de la capa anterior se quedan en la memoria de la GPU.
Veamos los métodos llamados. Como podemos ver, el método llamado con más frecuencia es ConvolutionInputGradients, que se basa en un método semejante de la capa convolucional y está optimizado para la tarea actual. En los parámetros, el método recibe los punteros a los tensores de los coeficientes de peso, el gradiente de la capa siguiente, los datos de salida de la capa anterior y el tensor para almacenar el resultado de la iteración. Además, en los parámetros transmitimos al método los tamaños de las ventanas de los datos de entrada y salida y la función de activación usada.
bool CNeuronMLMHAttentionOCL::ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(gradient)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(inp_gradient)==POINTER_INVALID) return false;
Al inicio del método, comprobamos la validez de los punteros recibidos y creamos búferes de datos en la memoria de la GPU.
if(!weights.BufferCreate(OpenCL)) return false; if(!gradient.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!inp_gradient.BufferCreate(OpenCL)) return false;
Después de crear los búferes de datos, organizaremos el proceso de llamada del kernel correspondiente del programa OpenCL. Aquí, el kernel de la red convolucional se utiliza sin cambios.
//--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=inputs.Total(); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_g,gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_o,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_ig,inp_gradient.GetIndex()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_outputs,gradient.Total()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_step,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_in,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_out,window_out); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_activation,activ); //Comment(com+"\n "+(string)__LINE__+"-"__FUNCTION__); if(!OpenCL.Execute(def_k_CalcHiddenGradientConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel CalcHiddenGradientConv: %d",GetLastError()); return false; } //--- return inp_gradient.BufferRead(); }
El método AttentionInsideGradients, también llamado desde el método ConvolutionInputGradients, se construye según un algoritmo similar, y podemos encontrar su código en los anexos. Ahora, vamos a mirar el kernel del programa OpenCL llamado desde el método especificado, ya que todos los cálculos se realizan precisamente en el kernel.
El kernel MHAttentionInsideGradients se inicia utilizando hilos en dos dimensiones: los elementos de secuencia y las cabezas de atención. En los parámetros, el kernel obtiene los punteros al tensor concatenado QKV y al tensor de sus gradientes, así como al tensor de la matriz Scores y sus gradientes, al tensor del gradiente de error de la iteración anterior y a la dimensión del vector de claves.
__kernel void MHAttentionInsideGradients(__global double *qkv,__global double *qkv_g, __global double *scores,__global double *scores_g, __global double *gradient, int dimension) { int u=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1); double koef=sqrt((double)dimension); if(koef<1) koef=1;
Al inicio del método, obtenemos los números ordinales del elemento procesado de la secuencia y la cabeza de atención, además de su dimensión. De inmediato, calculamos el factor de corrección de la matriz Scores.
A continuación, organizamos un ciclo para calcular el gradiente de error para la matriz Scores. El establecimiento de una barrera tras el ciclo nos permitirá sincronizar el proceso de cálculo en todos los hilos. El paso al siguiente bloque de operaciones se realizará solo después de recalcular completamente los gradientes de la matriz Scores.
//--- Calculating score's gradients uint shift_s=units*(h+u*heads); for(int v=0;v<units;v++) { double s=scores[shift_s+v]; if(s>0) { double sg=0; int shift_v=dimension*(h+heads*(3*v+2)); int shift_g=dimension*(h+heads*v); for(int d=0;d<dimension;d++) sg+=qkv[shift_v+d]*gradient[shift_g+d]; scores_g[shift_s+v]=sg*(s<1 ? s*(1-s) : 1)/koef; } else scores_g[shift_s+v]=0; } barrier(CLK_GLOBAL_MEM_FENCE);
Ahora, organizaremos otro ciclo para recalcular los gradientes de error en los vectores de solicitud, claves y valores.
//--- Calculating gradients for Query, Key and Value uint shift_qg=dimension*(h+3*u*heads); uint shift_kg=dimension*(h+(3*u+1)*heads); uint shift_vg=dimension*(h+(3*u+2)*heads); for(int d=0;d<dimension;d++) { double vg=0; double qg=0; double kg=0; for(int l=0;l<units;l++) { uint shift_q=dimension*(h+3*l*heads)+d; uint shift_k=dimension*(h+(3*l+1)*heads)+d; uint shift_g=dimension*(h+heads*l)+d; double sg=scores_g[shift_s+l]; kg+=sg*qkv[shift_q]; qg+=sg*qkv[shift_k]; vg+=gradient[shift_g]*scores[shift_s+l]; } qkv_g[shift_qg+d]=qg; qkv_g[shift_kg+d]=kg; qkv_g[shift_vg+d]=vg; } }
El lector podrá familiarizarse con el código de todos los métodos y funciones en los anexos.
Actualizamos los pesos en el método updateInputWeights, basado en los principios de los métodos feedForward y calcInputGradients analizados anteriormente. Dentro del método, solo llamaremos secuencialmente a un método auxiliar para actualizar los coeficientes de peso de la red convolucional, ConvolutuionUpdateWeights.
bool CNeuronMLMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false; CBufferDouble *inputs=NeuronOCL.getOutput(); for(uint l=0; l<iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(l*2+1),inputs,(optimization==SGD ? QKV_Weights.At(l*2+1) : QKV_Weights.At(l*3+1)),(optimization==SGD ? NULL : QKV_Weights.At(l*3+2)),iWindow,3*iWindowKey*iHeads)) return false; if(l>0) inputs.BufferFree(); CBufferDouble *temp=QKV_Weights.At(l*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(l*2+1); temp.BufferFree(); if(optimization==SGD) { temp=QKV_Weights.At(l*2+1); } else { temp=QKV_Weights.At(l*3+1); temp.BufferFree(); temp=QKV_Weights.At(l*3+2); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)),FF_Tensors.At(l*6+3),AO_Tensors.At(l*2),(optimization==SGD ? FF_Weights.At(l*6+3) : FF_Weights.At(l*9+3)),(optimization==SGD ? NULL : FF_Weights.At(l*9+6)),iWindowKey*iHeads,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(l*6+3); temp.BufferFree(); temp=AO_Tensors.At(l*2); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+3); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+3); temp.BufferFree(); temp=FF_Weights.At(l*9+6); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(l*6+4),FF_Tensors.At(l*6),(optimization==SGD ? FF_Weights.At(l*6+4) : FF_Weights.At(l*9+4)),(optimization==SGD ? NULL : FF_Weights.At(l*9+7)),iWindow,4*iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(l*6+4); temp.BufferFree(); temp=FF_Tensors.At(l*6); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+4); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+4); temp.BufferFree(); temp=FF_Weights.At(l*9+7); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2),FF_Tensors.At(l*6+5),FF_Tensors.At(l*6+1),(optimization==SGD ? FF_Weights.At(l*6+5) : FF_Weights.At(l*9+5)),(optimization==SGD ? NULL : FF_Weights.At(l*9+8)),4*iWindow,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(l*6+5); if(temp!=Gradient) temp.BufferFree(); temp=FF_Tensors.At(l*6+1); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+5); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+5); temp.BufferFree(); temp=FF_Weights.At(l*9+8); temp.BufferFree(); } inputs=FF_Tensors.At(l*6+2); } //--- return true; }
Podrá familiarizarse con el código completo de todas las clases y sus métodos en los anexos.
3.4. Cambios puntuales en las clases básicas de la red neronal
Y como siempre, después de crear una nueva clase, introduciremos en las clases básicas de nuestra red neuronal los cambios necesarios para que esta funcione correctamente.
Vamos a añadir el identificador de la nueva clase.
#define defNeuronMLMHAttentionOCL 0x7889 ///<Multilayer multi-headed attention neuron OpenCL \details Identified class #CNeuronMLMHAttentionOCL
Además, en el bloque "define", añadiremos las constantes necesarias para trabajar con los nuevos kernels del programa OpenCL.
#define def_k_MHAttentionScore 20 ///< Index of the kernel of the multi-heads attention neuron to calculate score matrix (#MHAttentionScore) #define def_k_mhas_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhas_score 1 ///< Matrix of Scores #define def_k_mhas_dimension 2 ///< Dimension of Key #define def_k_mhas_mask 3 ///< 1 - calc only previous units, 0 - calc all //--- #define def_k_MHAttentionOut 21 ///< Index of the kernel of the multi-heads attention neuron to calculate multi-heads out matrix (#MHAttentionOut) #define def_k_mhao_score 0 ///< Matrix of Scores #define def_k_mhao_qkv 1 ///< Matrix of Queries, Keys, Values #define def_k_mhao_out 2 ///< Matrix of Outputs #define def_k_mhao_dimension 3 ///< Dimension of Key //--- #define def_k_MHAttentionGradients 22 ///< Index of the kernel for gradients calculation process (#AttentionInsideGradients) #define def_k_mhag_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhag_qkv_g 1 ///< Matrix of Gradients to Queries, Keys, Values #define def_k_mhag_score 2 ///< Matrix of Scores #define def_k_mhag_score_g 3 ///< Matrix of Scores Gradients #define def_k_mhag_gradient 4 ///< Matrix of Gradients from previous iteration #define def_k_mhag_dimension 5 ///< Dimension of Key
Asimismo, añadiremos la declaración de los nuevos kernels en el constructor de clases de la red neuronal.
//--- create kernels opencl.SetKernelsCount(23); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut");
Y también la creación de un nuevo tipo de neuronas en el constructor de la red neuronal.
case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break;
Además, añadiremos el procesamiento de la nueva clase de neuronas a los métodos de despacho de la clase básica de neuronas CNeuronBaseOCL.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; } //--- return false; }
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
Podrá familiarizarse con el código completo de todas las clases y sus métodos en los anexos.
4. Simulación
Para poner a prueba la nueva arquitectura, hemos creado 2 asesores: Fractal_OCL_AttentionMLMH y Fractal_OCL_AttentionMLMH_v2. Hemos creado los asesores expertos usando como base el asesor experto del artículo anterior, y reemplazando solo el bloque de atención. El asesor Fractal_OCL_AttentionMLMH usa un bloque de 5 capas con 8 cabezas de auto-atención. El segundo asesor experto usa un bloque de 12 capas con 12 cabezas de auto-atención.
La prueba de la nueva clase de la red neuronal se ha realizado con el mismo conjunto de datos de las pruebas anteriores: instrumento EURUSD, marco temporal H1, con los datos históricos de las últimas 20 velas suministrados a la entrada de la red neuronal.
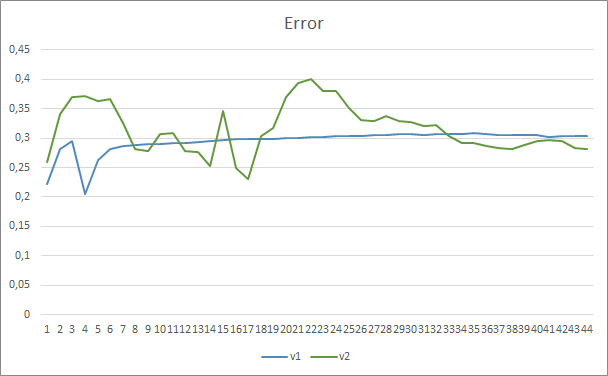
Los resultados de la prueba han confirmado nuestra suposición de que más parámetros requieren un periodo de entrenamiento mayor. En las primeras épocas del entrenamiento, el asesor experto con menos parámetros muestra resultados más estables. Pero al aumentar el periodo de entrenamiento, el asesor experto con un gran número de parámetros mejora los indicadores. En general, el error del asesor Fractal_OCL_AttentionMLMH_v2 después de 33 épocas de entrenamiento ha disminuido por debajo del nivel de error del asesor Fractal_OCL_AttentionMLMH y luego ha permanecido solamente más abajo.
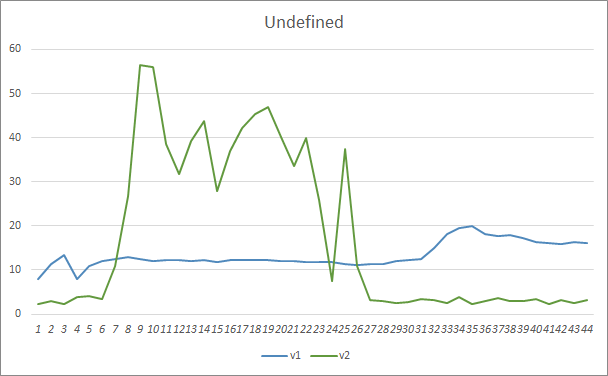
El parámetro de omisión de patrones ha mostrado resultados similares. Al inicio del entrenamiento, los parámetros desequilibrados del asesor Fractal_OCL_AttentionMLMH_v2 omitían más del 50% de los patrones, pero a medida que ha avanzado el entrenamiento, este indicador se ha reducido, estabilizándose tras 27 épocas en un 3-5%, mientras que el asesor con menor número de parámetros ha mostrado resultados más fluidos, pero con un 10-16% de patrones omitidos.
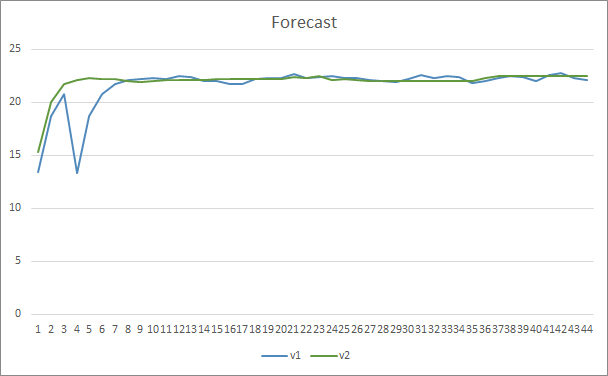
En cuanto a la precisión en la predicción de patrones, ambos asesores expertos han mostrado resultados uniformes al nivel del 22-23%.
Conclusión
En este artículo, hemos creado una nueva clase de neuronas de atención, similar a las arquitecturas de GPT presentadas por OpenAI. Obviamente, en casa no podemos repetir y entrenar por completo estas arquitecturas, ya que su formación y funcionamiento requieren mucho tiempo y recursos informáticos. No obstante, el objeto que hemos creado también se puede usar en redes neuronales para crear robots comerciales.
Enlaces
- Redes neuronales: así de sencillo
- Redes neuronales: así de sencillo (Parte 2): Entrenamiento y prueba de la red
- Redes neuronales: así de sencillo (Parte 3): Redes convolucionales
- Redes neuronales: así de sencillo (Parte 4): Redes recurrentes
- Redes neuronales: así de sencillo (Parte 5): Cálculos multihilo en OpenCL
- Redes neuronales: así de sencillo (Parte 6): Experimentos con la tasa de aprendizaje de la red neuronal
- Redes neuronales: así de sencillo (Parte 7): Métodos de optimización adaptativos
- Redes neuronales: así de sencillo (Parte 8): Mecanismos de atención
- Redes neuronales: así de sencillo (Parte 9): Documentamos el trabajo realizado
- Redes neuronales: así de sencillo (Parte 10): Multi-Head Attention (atención multi-cabeza)
- Improving Language Understanding with Unsupervised Learning
- Better Language Models and Their Implications
- How GPT3 Works - Visualizations and Animations
…
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | Asesor | Asesor con la red neuronal de clasificación (3 neuronas en la capa de salida) con uso de la arquitectura GPT, 5 capas de atención |
| 2 | Fractal_OCL_AttentionMLMH_v2.mq5 | Asesor | Asesor con la red neuronal de clasificación (3 neuronas en la capa de salida) con uso de la arquitectura GPT, 12 capas de atención |
| 3 | NeuroNet.mqh | Biblioteca de clase | Biblioteca de clases para crear la red neuronal |
| 4 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
| 5 | NN.chm | Guía de ayuda de HTML | Archivo CHM compilado. |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/9025
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Técnicas útiles y exóticas para el comercio automático
Técnicas útiles y exóticas para el comercio automático
 Aprendizaje de máquinas en sistemas comerciales con cuadrícula y martingale. ¿Apostaría por ello?
Aprendizaje de máquinas en sistemas comerciales con cuadrícula y martingale. ¿Apostaría por ello?
 Algoritmo de autoadaptación (Parte IV): Funcionalidad adicional y pruebas
Algoritmo de autoadaptación (Parte IV): Funcionalidad adicional y pruebas
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola,
Compruebe NN.chm. Tal vez te ayude.
Hola,
Sí, gracias.
El código no es tan malo ahora y puedo ver claramente cómo cambiar la arquitectura de red si es necesario.
Tengo todo en archivos de clase separados, además de un tazón de espaguetis mucho más pequeño que sigue siendo necesario porque mt5 tiene tanto la definición como las implementaciones en los mismos archivos.
Traté de hacer un poco de entrenamiento en GBPUSD utilizando el código como es, pero los resultados no parecen ser buenos el error sube de la natural del 50% al 70% y se mantiene allí sin mejora en épocas posteriores.
¿Alguna sugerencia de dónde empezar a ajustar?
BTW esta línea:
Necesita ser corregido a:
Al principio no estaba entendiendo mucho el artículo, porque no estaba entendiendo bien la idea principal.
Al preguntarle al propio ChatGPT sobre este texto me acalaró bastante las cosas y entendí la mayor parte de lo que estaba leyendo:
"El algoritmo Transformer es un modelo utilizado para procesar lenguaje natural, es decir, texto. Este modelo divide el texto en una secuencia de palabras (o "tokens"), y luego realiza una serie de operaciones en cada una de estas palabras para entender mejor su significado.
Una de las operaciones que hace el modelo es la auto-atención, que consiste en calcular la importancia que cada palabra tiene en relación a las demás palabras de la secuencia. Para hacer esto, el modelo utiliza tres vectores: el vector de consulta, el vector clave y el vector valor, que se calculan para cada palabra.
Luego, el modelo calcula la atención, que es la importancia que cada palabra tiene en relación a las demás palabras de la secuencia. Utiliza una función matemática llamada softmax para normalizar los coeficientes de atención.
Finalmente, el modelo combina todas las operaciones de auto-atención para producir un resultado final, que se utiliza para predecir el significado del texto.
En resumen, el algoritmo Transformer utiliza operaciones matemáticas complejas para entender el significado del texto."
Hola de nuevo :) He encontrado el problema. En la carpeta include la configuración de Opencl fallaba, porque probé mi sistema, y la GPU no soportaba el código solo la cpu, un pequeño cambio y funcionando perfectamente, pero lento :S