
Машинное обучение и Data Science (Часть 32): Как поддерживать актуальность AI-моделей с онлайн-обучением

Содержание
- Что такое онлайн-обучение?
- Преимущества онлайн-обучения
- Инфраструктура онлайн-обучения для MetaTrader 5
- Автоматизация процесса обучения и запуска
- Онлайн-обучение для AI-моделей глубокого обучения
- Инкрементальное машинное обучение
- Заключение
Что такое онлайн-обучение?
Онлайн-обучение применительно к машинному обучению — это метод, при котором модель поэтапно обучается на непрерывном потоке данных в реальном времени. Это динамический процесс, который позволяет адаптировать алгоритм прогнозирования благодаря дообучению на новых данных. Такое непрерывное обучение особенно важно в средах с множеством данных, которые быстро меняются, поскольку оно позволяет поддерживать актуальность модели.
При работе с торговыми данными всегда сложно определить оптимальный момент для обновления моделей и частоту этих обновлений. Например, если AI-модель обучалась на данных по Bitcoin, то данные из недавнего прошлого могут оказаться выбросами для алгоритма, учитывая, что недавно криптовалюта установила новый исторический максимум.
В отличие от валютного рынка, где символы исторически колеблются в определенных диапазонах, такие инструменты, как NASDAQ 100, S&P 500 и аналогичные фондовые индексы, а также акции, как правило, имеют тенденцию к росту и обновлению максимальных значений.
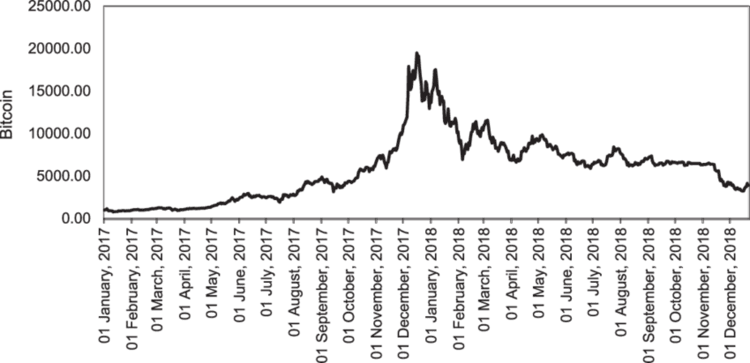
Онлайн-обучение используется не только для того, чтобы бороться с устареванием данных, на которых обучалась модель, но и для поддержания ее в актуальном состоянии с учетом свежей информации, которая может напрямую влиять на текущие рыночные события.
Преимущества онлайн-обучения
- Адаптивность
Как велосипедист, который улучшает свои навыки прямо во время движения, алгоритмы онлайн-обучения способны подстраиваться под новые закономерности в данных, постепенно повышая точность прогнозов. - Масштабируемость
Некоторые методы онлайн-обучения позволяют обрабатывать данные по одной выборке за раз. Это делает подход более экономичным в плане вычислительных ресурсов — важный момент для большинства пользователей. Это облегчает масштабирование моделей, работающих с большими массивами данных. - Прогнозы в реальном времени
В отличие от пакетного обучения, результаты которого к моменту применения могут устареть, онлайн-обучение поддерживает актуальность, что особенно важно в торговых стратегиях. - Эффективность
Пошаговое обучение и обновление моделей позволяют сократить время обучения и снизить его стоимость, обеспечивая при этом непрерывную адаптацию.
Итак, мы разобрали ключевые преимущества этого подхода. Теперь рассмотрим, какая инфраструктура необходима для эффективной реализации онлайн-обучения в MetaTrader 5.
Инфраструктура онлайн-обучения для MetaTrader 5
Поскольку наша конечная цель — сделать AI-модели полезными для трейдинга в MetaTrader 5, для этого требуется иная инфраструктура онлайн-обучения, чем та, которая обычно используется в приложениях на базе Python.

Шаг 01: Клиент Python
В Python-клиенте (скрипте) мы будем строить AI-модели на основе торговых данных, получаемых из MetaTrader 5.
Мы будем использовать библиотеку MetaTrader 5 Python. Начнем с инициализации платформы.
import pandas as pd import numpy as np import MetaTrader5 as mt5 from datetime import datetime if not mt5.initialize(): # Initialize the MetaTrader 5 platform print("initialize() failed") mt5.shutdown()
После инициализации MetaTrader 5 получим торговые данные с помощью метода copy_rates_from_pos.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) if len(rates) < bars: # if the received information is less than specified print("Failed to copy rates from MetaTrader 5, error = ",mt5.last_error()) # create a pandas DataFrame out of the obtained data df_rates = pd.DataFrame(rates) return df_rates
Выведем полученные данные.
print("Trading info:\n",getData(1, 100)) # get 100 bars starting at the recent closed bar
Пример вывода
time open high low close tick_volume spread real_volume 0 1731351600 1.06520 1.06564 1.06451 1.06491 1688 0 0 1 1731355200 1.06491 1.06519 1.06460 1.06505 1607 0 0 2 1731358800 1.06505 1.06573 1.06495 1.06512 1157 0 0 3 1731362400 1.06512 1.06564 1.06512 1.06557 1112 0 0 4 1731366000 1.06557 1.06579 1.06553 1.06557 776 0 0 .. ... ... ... ... ... ... ... ... 95 1731693600 1.05354 1.05516 1.05333 1.05513 5125 0 0 96 1731697200 1.05513 1.05600 1.05472 1.05486 3966 0 0 97 1731700800 1.05487 1.05547 1.05386 1.05515 2919 0 0 98 1731704400 1.05515 1.05522 1.05359 1.05372 2651 0 0 99 1731708000 1.05372 1.05379 1.05164 1.05279 2977 0 0 [100 rows x 8 columns]
Мы используем метод copy_rates_from_pos, так как он позволяет обращаться к последнему закрытому бару по индексу 1. Это гораздо удобнее, чем фиксированные даты, поскольку всегда возвращаются актуальные данные.
Благодаря этому мы можем быть уверены, что начиная с бара с индексом 1 мы получаем данные именно с последнего закрытого бара и далее — столько баров, сколько нужно.
После того, как нужные данные получены, мы можем переходить к стандартным шагам машинного обучения.
Создадим отдельные файлы для каждой модели. Такой подход упрощает работу — в основном файле main.py, где реализованы ключевые процессы и функции, можно будет легко подключать нужные модели.
Файл catboost_models.py
from catboost import CatBoostClassifier from sklearn.metrics import accuracy_score from onnx.helper import get_attribute_value from skl2onnx import convert_sklearn, update_registered_converter from sklearn.pipeline import Pipeline from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost.utils import convert_to_onnx_object # Example initial data (X_initial, y_initial are your initial feature matrix and target) class CatBoostClassifierModel(): def __init__(self, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None def train(self, iterations=100, depth=6, learning_rate=0.1, loss_function="CrossEntropy", use_best_model=True): # Initialize the CatBoost model params = { "iterations": iterations, "depth": depth, "learning_rate": learning_rate, "loss_function": loss_function, "use_best_model": use_best_model } self.model = Pipeline([ # wrap a catboost classifier in sklearn pipeline | good practice (not necessary tho :)) ("catboost", CatBoostClassifier(**params)) ]) # Testing the model self.model.fit(X=self.X_train, y=self.y_train, catboost__eval_set=(self.X_test, self.y_test)) y_pred = self.model.predict(self.X_test) print("Model's accuracy on out-of-sample data = ",accuracy_score(self.y_test, y_pred)) # a function for saving the trained CatBoost model to ONNX format def to_onnx(self, model_name): update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, self.skl2onnx_convert_catboost, parser=self.skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( self.model, "pipeline_catboost", [("input", FloatTensorType([None, self.X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(model_name, "wb") as f: f.write(model_onnx.SerializeToString())
Что касается этой модели CatBoost, мы подробнее обсуждали ее в отдельной статье. Эту модель CatBoost я использовал в качестве примера, вы же можете использовать любую другую модель на свое усмотрение.
Итак, выше мы написали класс, который мы будем использовать для инициализации, обучения и сохранения модели CatBoost. Развернем эту модель в файле "main.py".
Файл main.py
Как и раньше, начнем с получения данных из десктопного терминала MetaTrader 5:
data = getData(start=1, bars=1000)
Если внимательно посмотреть на используемую модель CatBoost, вы увидите, что это классификатор. Однако у нас нет целевой переменной (target) для этого классификатора. Нужно ее создать.
# Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows
Мы можем удалить из двумерного массива X все будущие переменные, а также признаки, содержащие большое количество нулевых значений, и назначить переменную target в качестве одномерного массива y.
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"]
После этого разбиваем данные на обучающую и валидационную выборки, инициализируем модель CatBoost с использованием рыночных данных и обучаем ее.
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train()
В завершение сохраняем модель в формате ONNX в общий каталог MetaTrader 5.
Шаг 02: Общая папка
С помощью Python-библиотеки MetaTrader 5 можно получить путь к общему каталогу.
terminal_info_dict = mt5.terminal_info()._asdict()
common_path = terminal_info_dict["commondata_path"] Здесь мы будем хранить все обученные AI-модели, созданные в нашем Python-клиенте.
При доступе к общему каталогу через MQL5 обычно используется подпапка Files, расположенная внутри этого общего каталога. Чтобы далее без проблем получать доступ к этим моделям из MQL5, необходимо сохранять их именно в эту подпапку.
# Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
В завершение обернем все эти строки кода в одну функцию, чтобы упростить выполнение всех процессов, когда это потребуется.
def trainAndSaveCatBoost(): data = getData(start=1, bars=1000) # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() # Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train() # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Далее вызовем эту функцию и посмотрим, что она делает.
trainAndSaveCatBoost()
exit() # stop the script Вывод функции
0: learn: 0.6916088 test: 0.6934968 best: 0.6934968 (0) total: 163ms remaining: 16.1s 1: learn: 0.6901684 test: 0.6936087 best: 0.6934968 (0) total: 168ms remaining: 8.22s 2: learn: 0.6888965 test: 0.6931576 best: 0.6931576 (2) total: 175ms remaining: 5.65s 3: learn: 0.6856524 test: 0.6927187 best: 0.6927187 (3) total: 184ms remaining: 4.41s 4: learn: 0.6843646 test: 0.6927737 best: 0.6927187 (3) total: 196ms remaining: 3.72s ... ... ... 96: learn: 0.5992419 test: 0.6995323 best: 0.6927187 (3) total: 915ms remaining: 28.3ms 97: learn: 0.5985751 test: 0.7002011 best: 0.6927187 (3) total: 924ms remaining: 18.9ms 98: learn: 0.5978617 test: 0.7003299 best: 0.6927187 (3) total: 928ms remaining: 9.37ms 99: learn: 0.5968786 test: 0.7010596 best: 0.6927187 (3) total: 932ms remaining: 0us bestTest = 0.6927187021 bestIteration = 3 Shrink model to first 4 iterations. Точность модели на данных вне обучающей выборки составила 0,5
Файл .onnx доступен в папке Common\Files.
Шаг 03: MetaTrader 5
Теперь в MetaTrader 5 нужно загрузить модель, сохраненную в формате ONNX.
Начнем с импорта библиотеки для выполнения этой задачи.
Файл "Online Learning Catboost.mq5"
#include <CatBoost.mqh> CCatBoost *catboost; input string model_name = "catboost.H1.onnx"; input string symbol = "EURUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; string common_path;
Первое, что надо сделать в функции OnInit — проверить, есть ли файл модели в общем каталоге. Если файл отсутствует, это может означать, что модель не была обучена.
Затем инициализируем ONNX-модель с передачей флага ONNX_COMMON_FOLDER, чтобы явно указать загрузку модели из общего каталога Common folder.
int OnInit() { //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize a catboost model catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- }
Чтобы использовать загруженную модель для прогнозирования, вернемся в скрипт Python и посмотрим, какие признаки использовались для обучения после того, как часть из них была удалена.
В MQL5 необходимо собрать те же признаки в том же порядке.
Код Python из файла "main.py".
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] print(X.head())
Вывод функции
time open high low close tick_volume 0 1726772400 1.11469 1.11584 1.11453 1.11556 3315 1 1726776000 1.11556 1.11615 1.11525 1.11606 2812 2 1726779600 1.11606 1.11680 1.11606 1.11656 2309 3 1726783200 1.11656 1.11668 1.11590 1.11622 2667 4 1726786800 1.11622 1.11644 1.11605 1.11615 1166
Затем, внутри функции OnTick, мы получаем эти данные и вызываем функцию predict_bin, которая предсказывает классы.
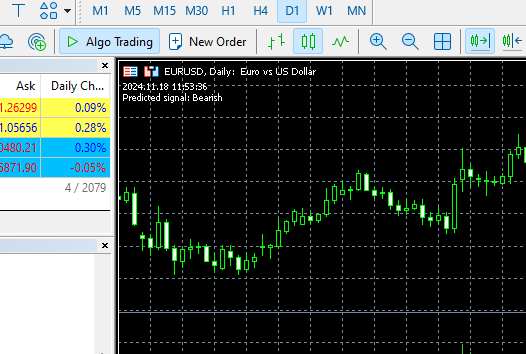
В нашем случае функция возвращает два класса, соответствующие значениям целевой переменной, подготовленной в Python-клиенте: 0 — бычий рынок (bullish), 1 — медвежий рынок (bearish).
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, 1, rates); //copy the recent closed bar information vector x = { (double)rates[0].time, rates[0].open, rates[0].high, rates[0].low, rates[0].close, (double)rates[0].tick_volume}; Comment(TimeCurrent(),"\nPredicted signal: ",catboost.predict_bin(x)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Вывод функции
Автоматизация процесса обучения и запуска
Мы смогли обучить и загрузить модель в MetaTrader 5, однако наша цель — полностью автоматизировать этот процесс.
Внутри виртуального окружения Python необходимо установить библиотеку schedule.
$ pip install schedule
Этот небольшой модуль позволяет планировать выполнение определенных функций. Поскольку мы уже обернули код для сбора данных, обучения и сохранения модели в одну функцию, можно настроить ее автоматический вызов каждую минуту.
schedule.every(1).minute.do(trainAndSaveCatBoost) #schedule catboost training # Keep the script running to execute the scheduled tasks while True: schedule.run_pending() time.sleep(60) # Wait for 1 minute before checking again
Расписание работает как магия :)
В основном советнике мы также установим расписание — когда и как часто он должен загружать модель из общего каталога. Таким образом мы обновляем модель для нашего торгового робота.
Для этого используем функцию OnTimer, которая также прекрасно справляется с задачей.
int OnInit() { //--- Check if the model file exists .... //--- Initialize a catboost model .... //--- if (!EventSetTimer(60)) //Execute the OnTimer function after every 60 seconds { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- .... } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnTimer(void) { if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; //--- Load the new model after deleting the prior one from memory catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Вывод функции
HO 0 13:14:00.648 Online Learning Catboost (EURUSD,D1) 2024.11.18 12:14 New model loaded FK 0 13:15:55.388 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:15 New model loaded JG 0 13:16:55.380 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:16 New model loaded MP 0 13:17:55.376 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:17 New model loaded JM 0 13:18:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:18 New model loaded PF 0 13:19:55.368 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:19 New model loaded CR 0 13:20:55.387 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:20 New model loaded NO 0 13:21:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:21 New model loaded LH 0 13:22:55.379 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:22 New model loaded
Мы увидели, как можно автоматизировать процесс обучения и поддерживать актуальность моделей в связке с советником в MetaTrader 5. Хотя этот подход легко реализуется для большинства методов машинного обучения, при работе с моделями глубокого обучения (например, рекуррентными нейронными сетями — RNN) могут возникнуть сложности. В частности, RNN не получится удобно встроить в конвейер Sklearn, который значительно упрощает работу с классическими моделями машинного обучения.
Давайте посмотрим, как можно применить этот подход при работе с управляемым рекуррентным блоком (GRU), который представляет собой особую форму рекуррентной нейронной сети.
Онлайн-обучение для AI-моделей глубокого обучения
В Python-клиенте
Выполним стандартные шаги машинного обучения внутри класса GRUClassifier. Подробнее о GRU мы уже говорили ранее в этой статье.
После обучения модели мы сохраняем ее в формате ONNX. На этот раз мы дополнительно сохраняем параметры объекта StandardScaler в бинарные файлы — это позволит впоследствии нормализовать новые данные в MQL5 точно так же, как в Python.
Файл gru_models.py
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx class GRUClassifier(): def __init__(self, time_step, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None self.time_step = time_step self.classes_in_y = np.unique(self.y_train) def train(self, learning_rate=0.001, layers=2, neurons = 50, activation="relu", batch_size=32, epochs=100, loss="binary_crossentropy", verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.X_train.shape[2]))) self.model.add(GRU(units=neurons, activation=activation)) # input layer for layer in range(layers): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=neurons, activation=activation)) self.model.add(Dropout(0.5)) self.model.add(Dense(units=len(self.classes_in_y), activation='softmax', name='output_layer')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=learning_rate) self.model.compile(optimizer=adam_optimizer, loss=loss, metrics=['accuracy']) early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.X_train, self.y_train, epochs=epochs, batch_size=batch_size, validation_data=(self.X_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.X_test, self.y_test, verbose=verbose) print("Gru accuracy on validation sample = ",val_accuracy) def to_onnx(self, model_name, standard_scaler): # Convert the Keras model to ONNX spec = (tf.TensorSpec((None, self.time_step, self.X_train.shape[2]), tf.float16, name="input"),) self.model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(model_name, "wb") as f: f.write(onnx_model.SerializeToString()) # Save the mean and scale parameters to binary files standard_scaler.mean_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_mean.bin") standard_scaler.scale_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_scale.bin")
В файле main.py мы создаем функцию, отвечающую за работу с моделью GRU.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) # Preparing the target variable data["future_open"] = data["open"].shift(-1) data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: target.append(1) else: target.append(0) data["target"] = target data = data.dropna() # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=False) ########### Preparing data for timeseries forecasting ############### time_step = 10 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) x_train_seq, y_train_seq = create_sequences(X_train, y_train, time_step) x_test_seq, y_test_seq = create_sequences(X_test, y_test, time_step) ###### One HOt encoding ####### y_train_encoded = to_categorical(y_train_seq) y_test_encoded = to_categorical(y_test_seq) gru = gru_models.GRUClassifier(time_step=time_step, X_train= x_train_seq, y_train= y_train_encoded, X_test= x_test_seq, y_test= y_test_encoded ) gru.train( batch_size=64, learning_rate=0.001, activation = "relu", epochs=1000, loss="binary_crossentropy", layers = 2, neurons = 50, verbose=1 ) # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist gru.to_onnx(model_name=os.path.join(models_path, "gru.H1.onnx"), standard_scaler=scaler)
Наконец, установим, как часто нужно вызывать функцию trainAndSaveGRU. Точно так же мы устанавливали расписание в CatBoost.
schedule.every(1).minute.do(trainAndSaveGRU) #scheduled GRU training
Вывод функции
Epoch 1/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 7s 87ms/step - accuracy: 0.4930 - loss: 0.6985 - val_accuracy: 0.5000 - val_loss: 0.6958 Epoch 2/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4847 - loss: 0.6957 - val_accuracy: 0.4931 - val_loss: 0.6936 Epoch 3/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5500 - loss: 0.6915 - val_accuracy: 0.4897 - val_loss: 0.6934 Epoch 4/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4910 - loss: 0.6923 - val_accuracy: 0.4690 - val_loss: 0.6938 Epoch 5/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.5538 - loss: 0.6910 - val_accuracy: 0.4897 - val_loss: 0.6935 Epoch 6/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.5037 - loss: 0.6953 - val_accuracy: 0.4931 - val_loss: 0.6937 Epoch 7/1000 ... ... ... 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step - accuracy: 0.4964 - loss: 0.6952 - val_accuracy: 0.4793 - val_loss: 0.6940 Epoch 20/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.5285 - loss: 0.6914 - val_accuracy: 0.4793 - val_loss: 0.6949 Epoch 21/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5224 - loss: 0.6935 - val_accuracy: 0.4966 - val_loss: 0.6942 Epoch 22/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step - accuracy: 0.5009 - loss: 0.6936 - val_accuracy: 0.5103 - val_loss: 0.6933 10/10 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.4925 - loss: 0.6938 Gru accuracy on validation sample = 0.5103448033332825
В MetaTrader 5
Сначала загрузим библиотеки, которые позволят загрузить модель GRU и стандартный масштабатор.
#include <preprocessing.mqh> #include <GRU.mqh> CGRU *gru; StandardizationScaler *scaler; //--- Arrays for temporary storage of the scaler values double scaler_mean[], scaler_std[]; input string model_name = "gru.H1.onnx"; string mean_file; string std_file;
Далее, в функции OnInit, получаем имена бинарных файлов масштабатора — тот же принцип мы использовали при создании этих файлов.
string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin";
Наконец, загрузим модель GRU в формате ONNX из общей папки. При этом также читаем бинарные файлы масштабатора, присваивая их значения в массивах scaler_mean и scaler_std.
int OnInit() { string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) //we followed this same file patterns while saving the binary files in python client { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin"; //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize the GRU model from the common folder gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Read the scaler files if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return INIT_FAILED; } scaler = new StandardizationScaler(scaler_mean, scaler_std); //Load the scaler class by populating it with values //--- Set the timer if (!EventSetTimer(60)) { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; }
В функции OnTimer зададим расписание для чтения файлов масштабатора и модели из общей папки.
void OnTimer(void) { //--- Delete the existing pointers in memory as the new ones are about to be created if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; //--- if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return; } scaler = new StandardizationScaler(scaler_mean, scaler_std); gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Вывод функции
II 0 14:49:35.920 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:49 New model loaded QP 0 14:50:35.886 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... MF 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) ONNX model Initialized IJ 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:50 New model loaded EN 0 14:51:35.894 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... JD 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) ONNX model Initialized EL 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:51 New model loaded NM 0 14:52:35.885 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... KK 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QQ 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:52 New model loaded DK 0 14:53:35.899 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... HI 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) ONNX model Initialized MS 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:53 New model loaded DI 0 14:54:35.885 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... IL 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QE 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:54 New model loaded
Чтобы получить прогнозы от модели GRU, необходимо учитывать значение временного шага timestep — оно позволяет рекуррентным нейросетям (RNN) понимать временные зависимости в данных.
В функции trainAndSaveGRU устанавливает значение timestep = 10.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) .... .... time_step = 10
Получим последние 10 баров (timesteps) из истории, начиная с последнего закрытого бара в MQL5. (как это и должно быть)
input int time_step = 10;
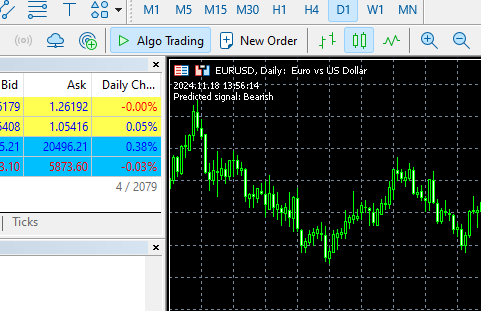
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, time_step, rates); //copy the recent closed bar information vector classes = {0,1}; //Beware of how classes are organized in the target variable. use numpy.unique(y) to determine this array matrix X = matrix::Zeros(time_step, 6); // 6 columns for (int i=0; i<time_step; i++) { vector row = { (double)rates[i].time, rates[i].open, rates[i].high, rates[i].low, rates[i].close, (double)rates[i].tick_volume}; X.Row(row, i); } X = scaler.transform(X); //it's important to normalize the data Comment(TimeCurrent(),"\nPredicted signal: ",gru.predict_bin(X, classes)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Вывод функции
Инкрементальное машинное обучение
Некоторые модели более устойчивы и эффективны, чем другие, когда речь идет о методах обучения. Если поискать в интернете информацию про машинное обучение онлайн / online machine learning, чаще всего можно встретить определение, согласно которому небольшие пачки данных (mini-batches) дообучают исходную модель в рамках более крупной задачи обучения.
Проблема в том, что многие модели либо вовсе не поддерживают такой режим работы, либо показывают неудовлетворительные результаты при обучении на малых выборках.
Современные методы машинного обучения, среди которых и CatBoost, изначально проектировались с учетом такого дообучения. Благодаря чему они подходят для онлайн-обучения и при этом позволяют существенно экономить память при работе с большими данными, разделяя их на небольшие блоки и поочередно дообучая исходную модель.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) df_rates = pd.DataFrame(rates) return df_rates def trainIncrementally(): # CatBoost model clf = CatBoostClassifier( task_type="CPU", iterations=2000, learning_rate=0.2, max_depth=1, verbose=0, ) # Get big data big_data = getData(1, 10000) # Split into chunks of 1000 samples chunk_size = 1000 chunks = [big_data[i:i + chunk_size].copy() for i in range(0, len(big_data), chunk_size)] # Use .copy() here for i, chunk in enumerate(chunks): # Preparing the target variable chunk["future_open"] = chunk["open"].shift(-1) chunk["future_close"] = chunk["close"].shift(-1) target = [] for row in range(chunk.shape[0]): if chunk["future_close"].iloc[row] > chunk["future_open"].iloc[row]: target.append(1) else: target.append(0) chunk["target"] = target chunk = chunk.dropna() # Check if we were able to receive some data if (len(chunk)<=0): print("Failed to obtain chunk from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = chunk.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = chunk["target"] X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.8, random_state=42) if i == 0: # Initial training, training the model for the first time clf.fit(X_train, y_train, eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") else: # Incremental training by using the initial trained model clf.fit(X_train, y_train, init_model="model.cbm", eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") # Save the model clf.save_model("model.cbm") print(f"Chunk {i + 1}/{len(chunks)} processed and model saved.")
Вывод функции
---> Acc score: 0.555 Chunk 1/10 processed and model saved. ---> Acc score: 0.505 Chunk 2/10 processed and model saved. ---> Acc score: 0.55 Chunk 3/10 processed and model saved. ---> Acc score: 0.565 Chunk 4/10 processed and model saved. ---> Acc score: 0.495 Chunk 5/10 processed and model saved. ---> Acc score: 0.55 Chunk 6/10 processed and model saved. ---> Acc score: 0.555 Chunk 7/10 processed and model saved. ---> Acc score: 0.52 Chunk 8/10 processed and model saved. ---> Acc score: 0.455 Chunk 9/10 processed and model saved. ---> Acc score: 0.535 Chunk 10/10 processed and model saved.
При этом вы можете использовать ту же архитектуру онлайн-обучения, выполняя построение модели инкрементально, а финальную версию сохранять в формате ONNX в общий каталог (Common Folder), чтобы в дальнейшем использовать ее в MetaTrader 5.
Заключительные мысли
Онлайн-обучение — это отличный способ поддерживать модели в актуальном состоянии с минимальным участием человека. Реализация такой инфраструктуры позволяет синхронизировать алгоритмы с последними рыночными тенденциями и помогать им быстро адаптироваться к новой информации. Однако важно помнить, что онлайн-обучение может сделать модели излишне чувствительными к порядку получения данных, поэтому нередко все же нужен контроль со стороны человека, чтобы убедиться, что модель и обучающая информация остаются логичными с точки зрения здравого смысла.Главная задача — найти баланс между автоматизацией процесса обучения и регулярной оценкой моделей, чтобы все работало так, как задумано.
Таблица вложений
Инфраструктура (папки) | Файлы | Описание и использование |
|---|---|---|
Клиент Python | - catboost_models.py - gru_models.py - main.py - incremental_learning.py | - Файл содержит модель CatBoost - Файл содержит модель GRU - Основной файл python, собирает все воедино - В этом файле реализовано инкрементальное обучение для модели CatBoost |
Общая папка (Common Folder) | - catboost.H1.onnx - gru.H1.onnx - gru.H1.standard_scaler_mean.bin - gru.H1.standard_scaler_scale.bin | Содержит все AI-модели в формате ONNX и файлы масштабатора в бинарных форматах |
| MetaTrader 5 (MQL5) | - Experts\Online Learning Catboost.mq5 - Experts\Online Learning GRU.mq5 - Include\CatBoost.mqh - Include\GRU.mqh - Include\preprocessing.mqh | - Развертывает модель CatBoost в MQL5 - Развертывает модель GRU в MQL5 - Файл библиотеки для инициализации и развертывания модели CatBoost в формате ONNX - Файл библиотеки для инициализации и развертывания модели GRU в формате ONNX - Файл библиотеки, содержащий StandardScaler для нормализации данных для использования модели машинного обучения |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16390
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте, Omega J Msigwa
Я спросил, какую версию python вы используете для этой статьи Я установил его, и есть конфликт библиотек.
Конфликт вызван следующим:
Пользователь запросил protobuf==3.20.3
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
Затем я отредактировал версию, как было предложено, и получил еще одну ошибку установки.
Чтобы исправить это, вы можете попробовать:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться решить конфликт зависимостей.
Конфликт вызван:
Пользователь запросил protobuf==3.20.2
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
tensorboard 2.18.0 зависит от protobuf!=4.24.0 и >=3.19.6
tensorflow-intel 2.18.0 зависит от protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev и >=3.20.3
Чтобы исправить это, вы можете попробовать:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться решить конфликт зависимостей
Пожалуйста, дайте больше инструкций
Привет, Омега Джей Мсигва
Я спросил, какую версию python вы используете для этой статьи, я установил ее, и возник конфликт библиотек.
Конфликт вызван:
Пользователь запросил protobuf==3.20.3
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
Затем я отредактировал версию, как было предложено, и получил еще одну ошибку установки.
Чтобы исправить это, вы можете попробовать следующее:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться
разрешить конфликт зависимостей
Причиной конфликта являются:
Пользователь запросил protobuf==3.20.2
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
tensorboard 2.18.0 зависит от protobuf!=4.24.0 и >=3.19.6
tensorflow-intel 2.18.0 зависит от protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev и >=3.20.3
Чтобы исправить это, вы можете попытаться сделать следующее:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться решить конфликт зависимостей
Пожалуйста, дайте больше инструкций
Привет, Омега Джей Мсигва
Я спросил, какую версию python вы используете для этой статьи, я установил ее, и есть конфликт библиотек.
Конфликт вызван:
Пользователь запросил protobuf==3.20.3
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
Затем я отредактировал версию, как было предложено, и получил еще одну ошибку установки.
Чтобы исправить это, вы можете попробовать следующее:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться решить конфликт зависимостей
Конфликт вызван:
Пользователь запросил protobuf==3.20.2
onnx 1.17.0 зависит от protobuf>=3.20.2
onnxconverter-common 1.14.0 зависит от protobuf==3.20.2
tensorboard 2.18.0 зависит от protobuf!=4.24.0 и >=3.19.6
tensorflow-intel 2.18.0 зависит от protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev и >=3.20.3
Чтобы исправить это, вы можете попытаться сделать следующее:
1. расширить диапазон версий пакетов, которые вы указали
2. удалить версии пакетов, чтобы позволить pip попытаться решить конфликт зависимостей
Пожалуйста, дайте больше инструкций
numpy==1.23.5