
Машинное обучение и Data Science (Часть 30): Тандем из сверточных (CNN) и рекуррентных (RNN) нейросетей для прогнозирования фондового рынка

Разделы
- Введение
- О двух типах нейросетей: рекуррентные (RNN) и сверточные (CNN)
- Синергия CNN и RNN
- Извлечение признаков с помощью CNN
- Временное моделирование с помощью RNN
- Обучение и составление прогнозов
- Комбинация CNN и LSTM
- Комбинация CNN и GRU
- Заключение
Введение
В предыдущих статьях мы говорили об эффективности сверточных нейронных сетей (CNN) и рекуррентных сетей (RNN). Мы поговорили о вариантах их использования применительно к рынку для получения качественных торговых сигналов.
В этой статье мы попытаемся объединить эти две мощные технологии. Оценим способность такого тандема предсказывать фондовый рынок. Но перед этим давайте вкратце вспомним, что такое CNN и RNN.
О двух типах нейросетей: рекуррентные (RNN) и сверточные (CNN)
Сверточные нейронные сети (CNN) были разработаны для распознавания паттернов и особенностей в данных. Хотя изначально они предназначались для задач распознавания изображений, они хорошо справляются с табличными данными, которые используются для прогнозирования временных рядов.
Как мы говорили в предыдущих статьях, они сначала применяют фильтры к входным данным, а затем извлекают высокоуровневые признаки, которые могут быть полезны для прогнозирования. В рыночных данных такими признаками являются тренды, сезонные эффекты и аномалии.

Архитектура CNN
Поскольку сверточные нейросети имеют иерархическую природу, они позволяют выявлять различные слои представления данных, каждый из которых дает представление о различных аспектах рынка.
Рекуррентные нейронные сети (RNN) — это искусственные нейросети, разработанные для распознавания закономерностей в последовательностях данных, таких как временные ряды, текст или видео.
В отличие от традиционных нейронных сетей, которые предполагают, что входные данные независимы друг от друга, RNN могут улавливать и анализировать закономерности внутри последовательностей.
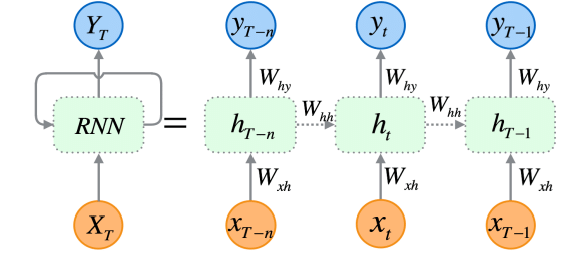
Поскольку рекуррентные нейронные сети специально разработаны для работы последовательными данными, их архитектура позволяет им сохранять информацию о предыдущих значениях и учитывают входные связи данные. Это делает их особенно подходящими для прогнозирования временных рядов — именно способность учитывать временные зависимости в данных имеет критическое значение для составления точных прогнозов на фондовом рынке.
Как я уже рассказывал в Части 25 этой серии статей, существует три наиболее часто используемых типа RNN: базовая (или "ванильная") рекуррентная нейронная сеть (RNN), сеть с долгосрочной и краткосрочной памятью (LSTM) и блок с управляемыми рекуррентными связями (GRU).
Если кратко: CNN отлично справляются с извлечением и обнаружением признаков в данных, а RNN умеют интерпретировать эти признаки с течением времени. Идея проста — объединить сильные стороны обеих моделей и попытаться создать более эффективную систему для прогнозирования фондового рынка.
Синергия CNN и RNN
Чтобы объединить эти два подхода, мы построим модель из трех этапов:
- Извлечение признаков с помощью CNN
- Моделирование временных зависимостей с помощью RNN
- Обучение модели и получение прогнозов
Давайте поэтапно разберем каждый шаг и соберем работающую модель, объединяющую в себе возможности RNN и LSTM.
01. Извлечение признаков с помощью CNN
На первом этапе мы передаем данные временного ряда в модель на основе CNN. Сверточная нейронная сеть обрабатывает данные, выявляя значимые паттерны и извлекая ключевые признаки, которые будут использоваться для дальнейшего прогнозирования.
В качестве примера возьмем данные по акциям компании Tesla. В наборе будут цены открытия (Open), максимума (High), минимума (Low) и закрытия (Close). Начнем с подготовки данных в формате 3D, который необходим для подачи на вход как CNN, так и RNN.
Также сформируем целевую переменную для задачи классификации.
Код Python
target_var = [] open_price = new_df["Open"] close_price = new_df["Close"] for i in range(len(open_price)): if close_price[i] > open_price[i]: # Closing price is greater than opening price target_var.append(1) # buy signal else: target_var.append(0) # sell signal
Нормализуем данные с помощью Standard Scaler, чтобы сделать их подходящими для машинного обучения.
X = new_df.iloc[:, :-1] y = target_var # Scalling the data scaler = StandardScaler() X = scaler.fit_transform(X) # Train-test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) print(f"x_train = {X_train.shape} - x_test = {X_test.shape}\n\ny_train = {len(y_train)} - y_test = {len(y_test)}")
Результаты
x_train = (799, 3) - x_test = (200, 3) y_train = 799 - y_test = 200
Затем мы можем подготовить данные в формате временного ряда.
# creating the sequence
X_train, y_train = create_sequences(X_train, y_train, time_step)
X_test, y_test = create_sequences(X_test, y_test, time_step) Поскольку это проблема классификации, мы применяем one-hot кодирование к целевой переменной.
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train)
y_test_encoded = to_categorical(y_test)
print(f"One hot encoded\n\ny_train {y_train_encoded.shape}\ny_test {y_test_encoded.shape}") Результаты
One hot encoded y_train (794, 2) y_test (195, 2)
Извлечение признаков выполняется непосредственно самой моделью CNN. Передадим ей сырые данные, которые мы только что подготовили.
model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2))
02. Моделирование временных зависимостей с помощью RNN
Извлеченные на предыдущем этапе признаки передадим на вход модели RNN. Она обрабатывает эти признаки, учитывая их временную последовательность и взаимосвязи между данными во времени.
В отличие от архитектуры модели CNN, с которой мы работали в Части 27 этой серии статей, где после слоя Flatten шли полносвязные слои, здесь мы поступим иначе: вместо обычных нейронных слоев мы используем рекуррентные — RNN, LSTM или GRU.
Важно также удалить слой Flatten из архитектуры CNN.
В классической CNN он используется для преобразования трёхмерного тензора (например, (batch, time, features)) в двумерный (например, (batch, features)), чтобы можно было передать данные в полносвязную сеть.
model.add(MaxPooling1D(pool_size=2)) model.add(SimpleRNN(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # Softmax for binary classification (1 buy, 0 sell signal)
03. Обучение модели и получение прогнозов
И наконец, мы переходим к этапу обучения построенной модели. После обучения мы проведем ее валидацию, оценим качество предсказаний и получим финальные результаты.
Код Python
model.summary()
# Compile the model
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train_encoded, epochs=1000, batch_size=16, validation_split=0.2, callbacks=[early_stopping])
plt.figure(figsize=(7.5, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.savefig("training loss curve-rnn-cnn-clf.png")
plt.show()
# Evaluating the Trained Model
y_pred = model.predict(X_test)
classes_in_y = np.unique(y)
y_pred_binary = classes_in_y[np.argmax(y_pred, axis=1)]
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix RNN + CNN.png") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary))
Результаты
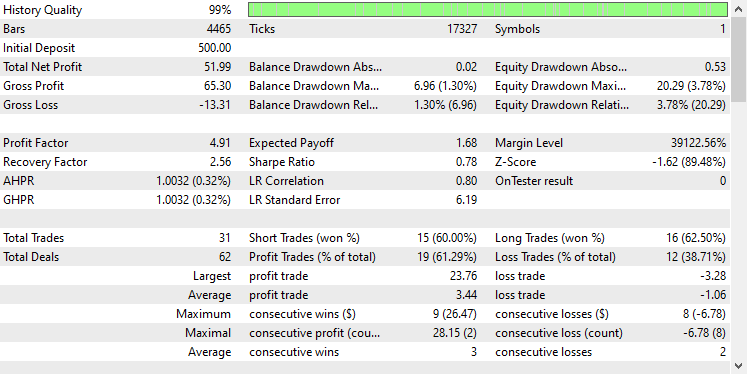
В результате оценки модели после 14 эпох точность модели на тестовых данных составила 54%.

7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step Classification Report precision recall f1-score support 0 0.70 0.40 0.51 117 1 0.45 0.74 0.56 78 accuracy 0.54 195 macro avg 0.58 0.57 0.54 195 weighted avg 0.60 0.54 0.53 195
Стоит отметить, что обучение финальной модели заняло довольно много времени, особенно после того, как добавились дополнительные слои. Это вполне ожидаемо, учитывая сложность объединенной архитектуры.
После завершения обучения сохраняем финальную модель в формате ONNX.
Код Python
onnx_file_name = "rnn+cnn.TSLA.D1.onnx" spec = (tf.TensorSpec((None, time_step, X_train.shape[2]), tf.float16, name="input"),) model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(onnx_file_name, "wb") as f: f.write(onnx_model.SerializeToString())
Также не забываем сохранить параметра масштабатора.
# Save the mean and scale parameters to binary files scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin") scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Сохраненную ONNX-модель я открыл в Netron, и она действительно оказалась очень объемной.

Аналогично тому, как мы ранее разворачивали сверточную нейрсеть (CNN), здесь мы можем воспользоваться той же библиотекой, чтобы без особых усилий загрузить и использовать эту громоздкую модель в MQL5.
#include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler; //from preprocessing.mqh
Но прежде чем приступить к работе, необходимо добавить ONNX-модель и параметры стандартизации (StandardScaler) в наш советник в качестве ресурсов.
#resource "\\Files\\rnn+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[]
Первое, что нам нужно сделать внутри функции OnInit, — это инициализировать масштабатор и саму модель CNN).
int OnInit() { //--- if (!cnn.Init(onnx_model)) //Initialize the Convolutional neural network return INIT_FAILED; scaler = new StandardizationScaler(standardization_mean, standardization_std); //Initialize the saved scaler by populating it with values ... ... return (INIT_SUCCEEDED); }
Для получения прогнозов необходимо сначала нормализовать входные данные с использованием заранее загруженного масштабатора, затем передать нормализованные данные в модель CNN и на выходе получить прогнозный сигнал и вероятности.
if (NewBar()) //Trade at the opening of a new candle { CopyRates(Symbol(), PERIOD_D1, 1, time_step, rates); for (ulong i=0; i<x_data.Rows(); i++) { x_data[i][0] = rates[i].open; x_data[i][1] = rates[i].high; x_data[i][2] = rates[i].low; } //--- x_data = scaler.transform(x_data); //Normalize the data int signal = cnn.predict_bin(x_data, classes_in_data_); //getting a trading signal from the RNN model vector probabilities = cnn.predict_proba(x_data); //probability for each class Comment("Probability = ",probabilities,"\nSignal = ",signal);
На скриншоте ниже показано, как комментарий выглядит на графике.

Вектор вероятностей зависит от классов, которые присутствовали в целевой переменной обучающего набора данных. Напомним, что при подготовке данных для обучения мы обозначили целевую переменную следующим образом: 0 — сигнал на продажу, 1 — сигнал на покупку. При этом идентификаторы классов (номера) должны быть в порядке возрастания.
input int time_step = 5; input int magic_number = 24092024; input int slippage = 100; MqlRates rates[]; matrix x_data(time_step, 3); //3 columns for open, high and low vector classes_in_data_ = {0, 1}; //unique target variables as they are in the target variable in your training data int OldNumBars = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---
Матрица x_data отвечает за временное хранение независимых переменных (признаков), полученных с рынка. Эта матрица масштабируется под 3 столбца, так как модель обучалась на трех признаках: Open, High, Low, а число строк соответствует значению временного окна (time step), использованному при подготовке обучающей выборки.
Временной шаг обязательно должен совпадать с тем, который использовался при обучении модели, чтобы сохранить корректную структуру последовательности.
На основе сигналов, генерируемых нашей моделью, разработаем простую стратегию.
double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { ClosePos(POSITION_TYPE_SELL); //close sell trades when the signal is buy if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions { if (!m_trade.Buy(min_lot, Symbol(), ticks.ask, 0 , 0)) //Open a buy trade printf("Failed to open a buy position err=%d",GetLastError()); } } else if (signal==0) //Bearish signal { ClosePos(POSITION_TYPE_BUY); //close all buy trades when the signal is sell if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions { if (!m_trade.Sell(min_lot, Symbol(), ticks.bid, 0 , 0)) //open a sell trade printf("Failed to open a sell position err=%d",GetLastError()); } } else //There was an error return;
Теперь, когда модель загружена и готова к работе, протестируем ее на периоде с 01.01.2020 по 01.09.2024. Ниже представлено изображение с полной конфигурацией тестера.
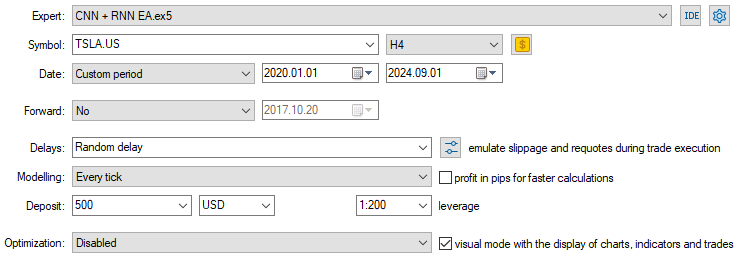
Обратите внимание: советник запущен на 4-часовом графике, хотя данные по акциям Tesla были собраны с дневного таймфрейма. Это сделано не случайно. Стратегия и модель были запрограммированы на активацию сразу после открытия новой свечи, однако дневная свеча обычно открывается в момент, когда рынок закрыт, что может привести к тому, что советник пропустит сделку и "заснет" до следующего дня.
Запуская советника на младшем таймфрейме (в данном случае H4), мы обеспечиваем непрерывный мониторинг рынка каждые 4 часа и возможность оперативно реагировать на сигналы модели.
При этом источник данных для принятия решений не меняется, так как мы применяем функцию CopyRates к дневному таймфрейму — торговые сигналы по-прежнему формируются на основе дневных данных.
Ниже представлен результат тестера.
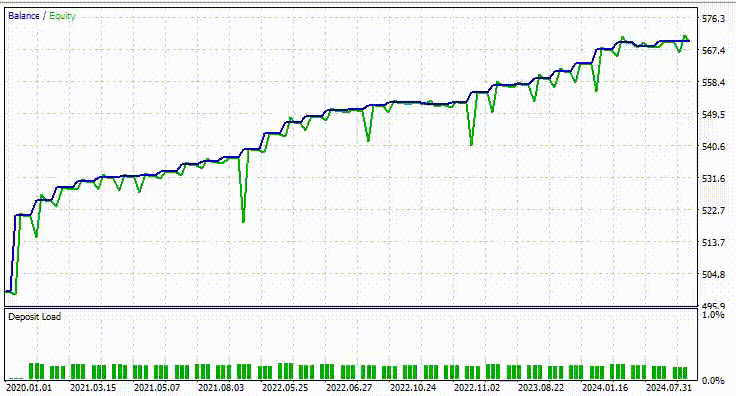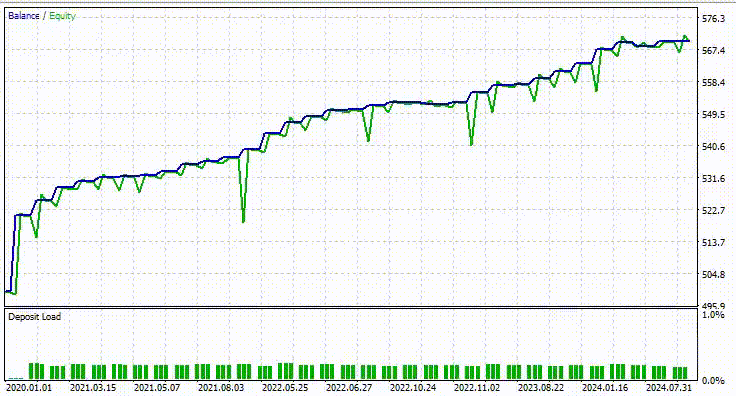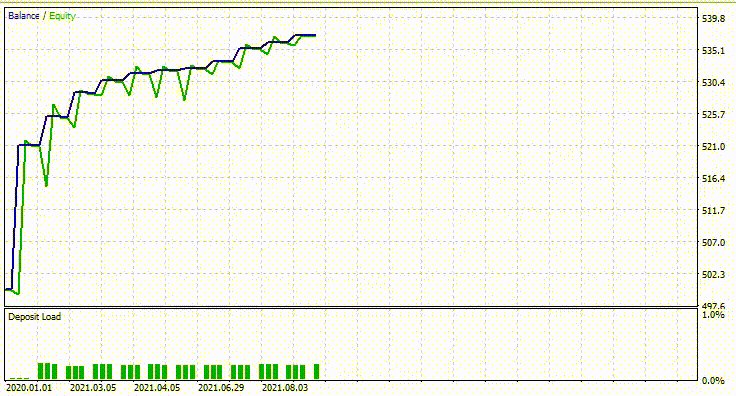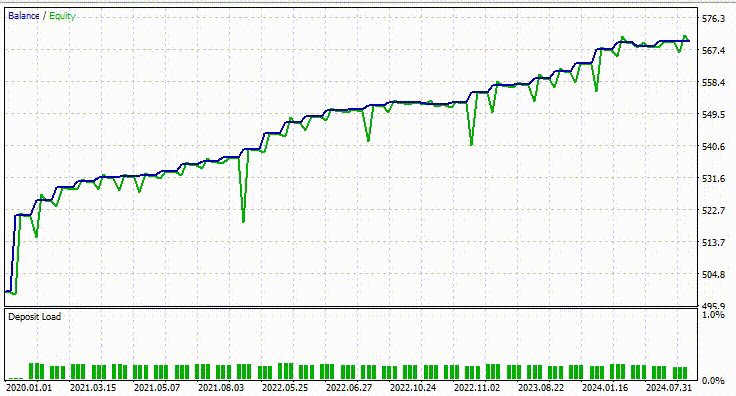
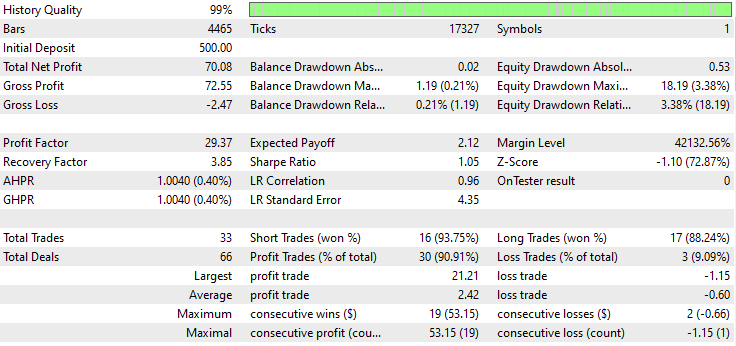
Впечатляюще! Советник показал 90% прибыльных сделок. Причем использовалась простая модель на основе RNN.
Теперь давайте посмотрим, насколько эффективны LSTM и GRU в тех же рыночных условиях.
Комбинация CNN и LSTM
В отличие от простой RNN, которая слабо справляется с анализом длинных последовательностей, LSTM умеет запоминать долгосрочные зависимости и распознавать сложные закономерности в данных.
На практике LSTM чаще дает более точные и стабильные результаты, чем классическая RNN. Давайте построим модель CNN с LSTM, протестируем ее на данных акций Tesla и посмотрим, как она себя проявит.
Код Python
from tensorflow.keras.layers import LSTM # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
Поскольку все RNN можно реализовать одинаково, мне нужно было внести всего одно изменение в блок кода, используемый для создания простой RNN.
После обучения и валидации модели ее точность составила 53% на тестовых данных.
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 36ms/step Classification Report precision recall f1-score support 0 0.67 0.44 0.53 117 1 0.45 0.68 0.54 78 accuracy 0.53 195 macro avg 0.56 0.56 0.53 195 weighted avg 0.58 0.53 0.53 195
В MQL5 мы можем использовать ту же библиотеку, что и для советника с простой RNN.
#resource "\\Files\\lstm+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Остальная часть кода осталась такой же, как и в советнике с CNN + RNN.
Я использовал те же настройки тестера, что и раньше, и вот что получилось.
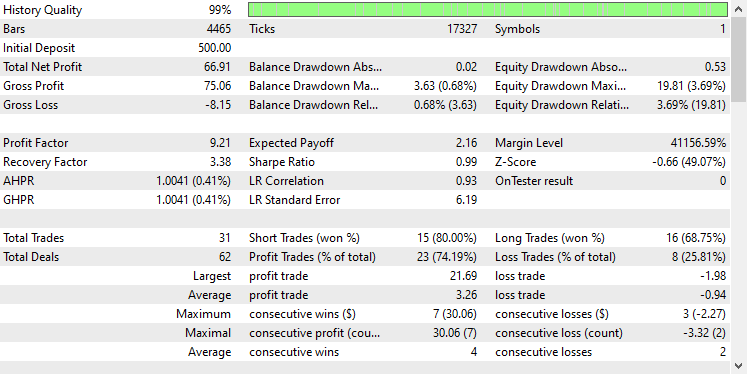
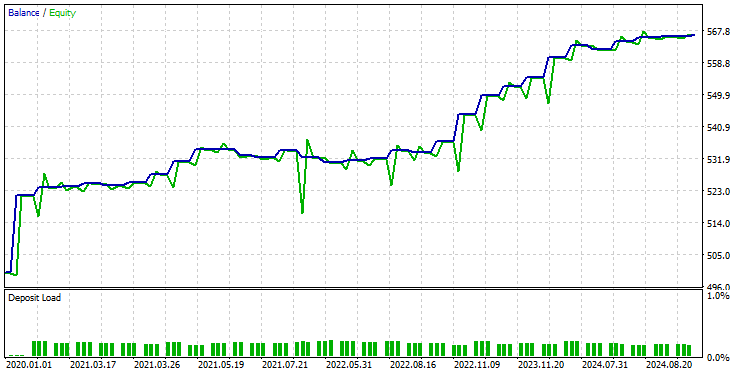
На этот раз общая точность сделок составила около 74%. Это меньше, чем в предыдущей модели, но все равно впечатляющий результат!
Комбинация сверточной нейронной сети (CNN) и Gated Recurrent Unit (GRU)
Как и LSTM, модели GRU тоже способны распознавать зависимости в длинных последовательностях данных. При этом они обладают более минималистичной архитектурой, чем LSTM.
Мы можем реализовать модель GRU так же, как и другие RNN, изменив только тип модели в коде при построении архитектуры CNN.
from tensorflow.keras.layers import GRU # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(GRU(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
После обучения и проверки модели она показала ту же точность, что и модель LSTM, а именно 53% точности на тестовых данных.
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 41ms/step Classification Report precision recall f1-score support 0 0.69 0.39 0.50 117 1 0.45 0.73 0.55 78 accuracy 0.53 195 macro avg 0.57 0.56 0.53 195 weighted avg 0.59 0.53 0.52 195
Загружаем модель GRU в формате ONNX и ее параметры масштабирования в двоичных файлах.
#resource "\\Files\\gru+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
Снова остальная часть кода остаётся такой же, как и в советнике с простой RNN.
После тестирования модели с использованием тех же настроек тестера, вот что мы получили.
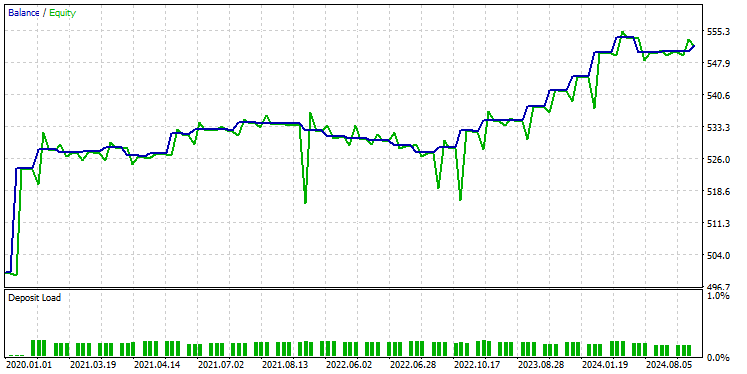
Модель GRU показала точность около 61%. Это не так хорошо, как в двух предыдущих моделях, но все равно достойный результат.
Заключительные мысли
Интеграция сверточных нейронных сетей (CNN) с рекуррентными нейронными сетями (RNN) может стать эффективным инструментом для прогнозирования фондового рынка, открывая возможности для выявления скрытых паттернов и временных зависимостей в данных. Однако эта комбинация относительно редка и сопряжена с определенными трудностями. Одним из главных рисков является переобучение, особенно при применении таких сложных моделей к относительно простым задачам. Переобучение может привести к тому, что модель будет хорошо работать на обучающих данных, но не сможет обобщать на новые данные.
Кроме того, сложность сочетания CNN и RNN ведет к значительным вычислительным затратам, особенно если вы решите масштабировать модель, добавив больше плотных слоев или увеличив количество нейронов. Важно тщательно сбалансировать сложность модели с доступными вычислительными ресурсами и задачей, которую необходимо решить.
Всем добра.
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозитории на GitHub.
Таблица вложений
Наименование файла | Тип файла | Описание и использование |
|---|---|---|
Experts\CNN + GRU EA.mq5 Experts\CNN + LSTM EA.mq5 Experts\CNN + RNN EA.mq5 | Советники | Торговый робот для загрузки моделей ONNX и тестирования торговой стратегии в MetaTrader 5. |
ConvNet.mqh preprocessing.mqh | Include files |
|
Files\ *.onnx | ONNX-модели | Модели машинного обучения, обсуждаемые в этой статье, в формате ONNX |
| Files\*.bin | Бинарные файлы | Бинарные файлы для загрузки параметров масштабатора для каждой модели |
Jupyter Notebook\cnns-rnns.ipynb | python/Jupyter notebook | Этот блокнот содержит весь код Python, обсуждаемый в этой статье. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15585
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования