
Datenwissenschaft und ML (Teil 32): KI-Modelle auf dem neuesten Stand halten, Online-Lernen

Inhalt
- Was ist Online-Lernen?
- Vorteile des Online-Lernens
- Die Infrastruktur des Online-Lernens für MetaTrader 5
- Automatisierung des Trainings- und Bereitstellungsprozesses
- Online-Lernen für Deep-Learning-KI-Modelle
- Inkrementelles maschinelles Lernen
- Schlussfolgerung
Was ist Online-Lernen?
Das maschinelle Online-Lernen ist eine Methode des maschinellen Lernens, bei der das Modell schrittweise aus einem Strom von Datenpunkten in Echtzeit lernt. Es handelt sich um einen dynamischen Prozess, der seinen Vorhersagealgorithmus im Laufe der Zeit anpasst, sodass sich das Modell mit dem Eintreffen neuer Daten ändern kann. Diese Methode ist in sich schnell entwickelnden, datenreichen Umgebungen, wie z. B. beim Handel mit Daten, von großer Bedeutung, da sie zeitnahe und genaue Vorhersagen liefern kann.
Bei der Arbeit mit den Handelsdaten ist es immer schwierig, den richtigen Zeitpunkt für die Aktualisierung Ihrer Modelle zu bestimmen. Wenn Sie beispielsweise KI-Modelle für Bitcoin im letzten Jahr trainiert haben, könnten sich die jüngsten Informationen als Ausreißer für ein maschinelles Lernmodell erweisen, wenn man bedenkt, dass diese Kryptowährung erst letzte Woche den neuen Höchstpreis erreicht hat.
Im Gegensatz zu Forex-Instrumenten, die in der Regel nach oben und unten innerhalb bestimmter Bereiche historisch, Instrumente wie NASDAQ 100, S & P 500 und andere ihrer Art und Aktien in der Regel neigt dazu, zu erhöhen und erreichen neue Spitzenwerte.
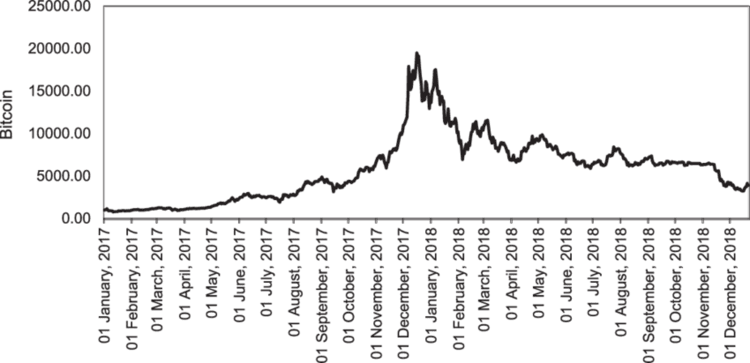
Das Online-Lernen erfolgt nicht nur aus Angst, dass die alten Trainingsinformationen veralten, sondern auch, um das Modell mit aktuellen Informationen auf dem neuesten Stand zu halten, die sich auf das aktuelle Marktgeschehen auswirken könnten.
Vorteile des Online-Lernens
- Anpassungsfähigkeit
Genau wie die Radfahrer, die während der Fahrt lernen, kann sich das maschinelle Online-Lernen an neue Muster in den Daten anpassen und so seine Leistung mit der Zeit verbessern. - Skalierbarkeit
Einige Online-Lernmethoden für einige Modelle verarbeiten die Daten einzeln. Dies macht diese Technik sicherer für knappe Rechenressourcen, über die die meisten von uns verfügen, und kann schließlich bei der Skalierung von Modellen helfen, die von großen Daten abhängen. - Vorhersagen in Echtzeit
Im Gegensatz zum Batch-Lernen, das zum Zeitpunkt der Implementierung bereits veraltet sein kann, liefert das Online-Lernen Erkenntnisse in Echtzeit, die für viele Handelsanwendungen entscheidend sein können. - Effizienz
Inkrementelles maschinelles Lernen ermöglicht kontinuierliches Lernen und Aktualisieren von Modellen, was zu einem schnelleren und kosteneffizienteren Trainingsprozess führen kann.
Nachdem wir nun einige Vorteile dieser Technik kennen, wollen wir uns die Infrastruktur ansehen, die für ein effektives Online-Lernen im MetaTrader 5 erforderlich ist.
Die Infrastruktur des Online-Lernens für MetaTrader 5
Da unser Ziel darin besteht, KI-Modelle für Handelszwecke im MetaTrader 5 nutzbar zu machen, ist eine andere Infrastruktur für das Online-Lernen erforderlich als die, die man normalerweise in Python-basierten Anwendungen sieht.

Schritt 01: Python-Klient
In einem Python-Client (Skript) wollen wir KI-Modelle auf der Grundlage der vom MetaTrader 5 empfangenen Handelsdaten erstellen.
Wir beginnen die Initialisierung der Plattform mit MetaTrader 5 (Python-Bibliothek).
import pandas as pd import numpy as np import MetaTrader5 as mt5 from datetime import datetime if not mt5.initialize(): # Initialize the MetaTrader 5 platform print("initialize() failed") mt5.shutdown()
Nach der Initialisierung der MetaTrader 5-Plattform können wir mit der Methode copy_rates_from_pos Handelsinformationen von ihr erhalten.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) if len(rates) < bars: # if the received information is less than specified print("Failed to copy rates from MetaTrader 5, error = ",mt5.last_error()) # create a pnadas DataFrame out of the obtained data df_rates = pd.DataFrame(rates) return df_rates
Wir können die erhaltenen Informationen ausdrucken, um sie zu sehen.
print("Trading info:\n",getData(1, 100)) # get 100 bars starting at the recent closed bar
Ausdrucke
time open high low close tick_volume spread real_volume 0 1731351600 1.06520 1.06564 1.06451 1.06491 1688 0 0 1 1731355200 1.06491 1.06519 1.06460 1.06505 1607 0 0 2 1731358800 1.06505 1.06573 1.06495 1.06512 1157 0 0 3 1731362400 1.06512 1.06564 1.06512 1.06557 1112 0 0 4 1731366000 1.06557 1.06579 1.06553 1.06557 776 0 0 .. ... ... ... ... ... ... ... ... 95 1731693600 1.05354 1.05516 1.05333 1.05513 5125 0 0 96 1731697200 1.05513 1.05600 1.05472 1.05486 3966 0 0 97 1731700800 1.05487 1.05547 1.05386 1.05515 2919 0 0 98 1731704400 1.05515 1.05522 1.05359 1.05372 2651 0 0 99 1731708000 1.05372 1.05379 1.05164 1.05279 2977 0 0 [100 rows x 8 columns]
Wir verwenden die Methode copy_rates_from_pos, da sie es uns ermöglicht, auf den letzten geschlossenen Balken zuzugreifen, der am Index 1 platziert ist, was sehr nützlich ist im Vergleich zum Zugriff über feste Daten.
Wir können immer sicher sein, dass wir durch das Kopieren von dem Balken mit dem Index 1 immer die Informationen ab dem kürzlich geschlossenen Balken bis zu einer bestimmten Anzahl von Balken, die wir haben wollen, erhalten.
Nachdem wir diese Informationen erhalten haben, können wir die typischen maschinellen Lernverfahren für diese Daten durchführen.
Wir erstellen eine eigene Datei für unser Modell. Indem wir jedes Modell in eine eigene Datei packen, machen wir es einfach, diese Modelle in der Datei „main.py“ aufzurufen, in der alle wichtigen Prozesse und Funktionen bereitgestellt werden.
Die Datei catboost_models.py
from catboost import CatBoostClassifier from sklearn.metrics import accuracy_score from onnx.helper import get_attribute_value from skl2onnx import convert_sklearn, update_registered_converter from sklearn.pipeline import Pipeline from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost.utils import convert_to_onnx_object # Example initial data (X_initial, y_initial are your initial feature matrix and target) class CatBoostClassifierModel(): def __init__(self, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None def train(self, iterations=100, depth=6, learning_rate=0.1, loss_function="CrossEntropy", use_best_model=True): # Initialize the CatBoost model params = { "iterations": iterations, "depth": depth, "learning_rate": learning_rate, "loss_function": loss_function, "use_best_model": use_best_model } self.model = Pipeline([ # wrap a catboost classifier in sklearn pipeline | good practice (not necessary tho :)) ("catboost", CatBoostClassifier(**params)) ]) # Testing the model self.model.fit(X=self.X_train, y=self.y_train, catboost__eval_set=(self.X_test, self.y_test)) y_pred = self.model.predict(self.X_test) print("Model's accuracy on out-of-sample data = ",accuracy_score(self.y_test, y_pred)) # a function for saving the trained CatBoost model to ONNX format def to_onnx(self, model_name): update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, self.skl2onnx_convert_catboost, parser=self.skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( self.model, "pipeline_catboost", [("input", FloatTensorType([None, self.X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(model_name, "wb") as f: f.write(model_onnx.SerializeToString())
Weitere Informationen über das eingesetzte CatBoost-Modell finden Sie in diesem Artikel. Ich habe das CatBoost-Modell als Beispiel verwendet, Sie können aber auch jedes andere von Ihnen bevorzugte Modell verwenden.
Jetzt haben wir diese Klasse, die uns beim Initialisieren, Trainieren und Speichern des Modells catboost hilft. Lassen Sie uns dieses Modell in der Datei „main.py“ einsetzen.
Die Datei main.py
Auch hier beginnen wir mit dem Empfang der Daten von der MetaTrader 5 Desktop App.
data = getData(start=1, bars=1000)
Wenn Sie sich das CatBoost-Modell genau ansehen, werden Sie feststellen, dass es sich um ein Klassifikatormodell handelt. Wir haben noch keine Zielvariable für diesen Klassifikator, lassen Sie uns eine erstellen.
# Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows
Wir können alle zukünftigen Variablen und andere Merkmale mit vielen Nullwerten aus dem X 2D-Array entfernen und die „Ziel“-Variable dem y 1D-Array zuweisen.
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"]
Dann teilen wir die Informationen in Trainings- und Validierungsstichproben auf, initialisieren das CatBoost-Modell mit den Daten vom Markt und trainieren es.
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train()
Schließlich speichern wir dieses Modell im ONNX-Format in einem gemeinsamen MetaTrader 5-Verzeichnis.
Schritt 02: Der gemeinsamer Ordner „Common“
Mit dem MetaTrader 5 Python können wir die Informationen über den gemeinsamen Pfad abrufen.
terminal_info_dict = mt5.terminal_info()._asdict()
common_path = terminal_info_dict["commondata_path"] Hier wollen wir alle trainierten KI-Modelle aus unserem Python-Client speichern.
Wenn man mit MQL5 auf den gemeinsamen Ordner zugreift, bezieht man sich in der Regel auf einen Unterordner „Files“, der sich unter dem gemeinsamen Ordner „Common“ befindet. Um den Zugriff auf diese Dateien aus Sicht von MQL5 zu erleichtern, müssen wir die Modelle in diesem Unterordner speichern.
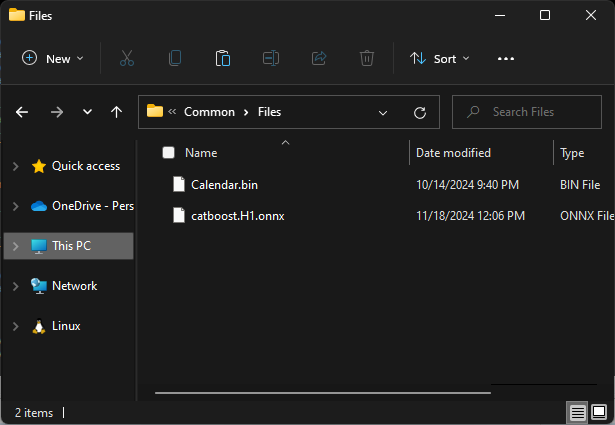
# Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Schließlich müssen wir all diese Codezeilen in eine einzige Funktion verpacken, um die Ausführung all dieser verschiedenen Prozesse zu erleichtern, wann immer wir wollen.
def trainAndSaveCatBoost(): data = getData(start=1, bars=1000) # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() # Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train() # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Rufen wir also diese Funktion auf und sehen wir, was sie tut.
trainAndSaveCatBoost()
exit() # stop the script Ergebnis:
0: learn: 0.6916088 test: 0.6934968 best: 0.6934968 (0) total: 163ms remaining: 16.1s 1: learn: 0.6901684 test: 0.6936087 best: 0.6934968 (0) total: 168ms remaining: 8.22s 2: learn: 0.6888965 test: 0.6931576 best: 0.6931576 (2) total: 175ms remaining: 5.65s 3: learn: 0.6856524 test: 0.6927187 best: 0.6927187 (3) total: 184ms remaining: 4.41s 4: learn: 0.6843646 test: 0.6927737 best: 0.6927187 (3) total: 196ms remaining: 3.72s ... ... ... 96: learn: 0.5992419 test: 0.6995323 best: 0.6927187 (3) total: 915ms remaining: 28.3ms 97: learn: 0.5985751 test: 0.7002011 best: 0.6927187 (3) total: 924ms remaining: 18.9ms 98: learn: 0.5978617 test: 0.7003299 best: 0.6927187 (3) total: 928ms remaining: 9.37ms 99: learn: 0.5968786 test: 0.7010596 best: 0.6927187 (3) total: 932ms remaining: 0us bestTest = 0.6927187021 bestIteration = 3 Shrink model to first 4 iterations. Model's accuracy on out-of-sample data = 0.5
Die .onnx-Datei ist im Ordner Common\Files zu finden.
Schritt 03: MetaTrader 5
Im MetaTrader 5 müssen wir nun dieses im ONNX-Format gespeicherte Modell laden.
Wir beginnen damit, die Bibliothek zu importieren, die uns bei dieser Aufgabe helfen soll.
Innerhalb von „Online Learning Catboost.mq5“
#include <CatBoost.mqh> CCatBoost *catboost; input string model_name = "catboost.H1.onnx"; input string symbol = "EURUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; string common_path;
Das erste, was wir in der Oninit-Funktion tun wollen, ist zu prüfen, ob die Datei im gemeinsamen Ordner existiert. Wenn sie nicht existiert, könnte das bedeuten, dass das Modell nicht trainiert wurde.
Danach initialisieren wir das ONNX-Modell, indem wir das Flag ONNX_COMMON_FOLDER übergeben, um das Modell explizit aus dem Verzeichnis „Common“ zu laden.
int OnInit() { //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize a catboost model catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- }
Um dieses geladene Modell für Vorhersagen zu verwenden, können wir zum Python-Skript zurückkehren und überprüfen, welche Merkmale für das Training verwendet wurden, nachdem einige weggelassen wurden.
Die gleichen Merkmale und in der gleichen Reihenfolge müssen in MQL5 erfasst werden.
Der Python-Code in der Datei „main.py“.
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] print(X.head())
Ergebnis:
time open high low close tick_volume 0 1726772400 1.11469 1.11584 1.11453 1.11556 3315 1 1726776000 1.11556 1.11615 1.11525 1.11606 2812 2 1726779600 1.11606 1.11680 1.11606 1.11656 2309 3 1726783200 1.11656 1.11668 1.11590 1.11622 2667 4 1726786800 1.11622 1.11644 1.11605 1.11615 1166
Nun wollen wir diese Informationen in der OnTick-Funktion abrufen und die Funktion predict_bin aufrufen, die die Klassen vorhersagt.
Diese Funktion wird zwei Klassen vorhersagen, die in der Zielvariable, die wir im Python-Client vorbereitet haben, gesehen wurden. 0 (bullish, steigend), 1 (bearish, fallend).
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, 1, rates); //copy the recent closed bar information vector x = { (double)rates[0].time, rates[0].open, rates[0].high, rates[0].low, rates[0].close, (double)rates[0].tick_volume}; Comment(TimeCurrent(),"\nPredicted signal: ",catboost.predict_bin(x)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Ergebnis:
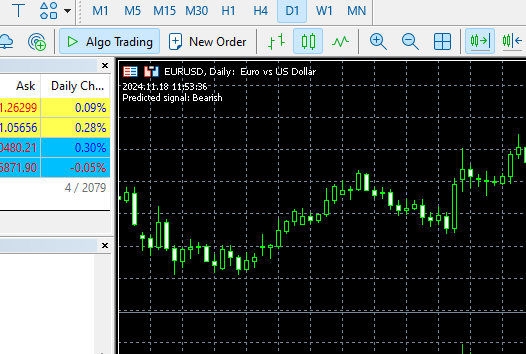
Automatisierung des Trainings- und Bereitstellungsprozesses
Wir konnten das Modell in MetaTrader 5 trainieren und einsetzen, aber das ist nicht das, was wir wollen, unser Hauptziel ist es, den gesamten Prozess zu automatisieren.
Innerhalb der virtuellen Python-Umgebung müssen wir die Bibliothek schedule installieren:
$ pip install schedule
Dieses kleine Modul kann bei der Planung helfen, wann eine bestimmte Funktion ausgeführt werden soll. Da wir den Code für das Sammeln von Daten, das Training und das Speichern des Modells bereits in eine Funktion verpackt haben, können wir diese Funktion so planen, dass sie nach jeder (einer) Minute aufgerufen wird.
schedule.every(1).minute.do(trainAndSaveCatBoost) #schedule catboost training # Keep the script running to execute the scheduled tasks while True: schedule.run_pending() time.sleep(60) # Wait for 1 minute before checking again
Diese Terminplanung funktioniert hervorragend :)
In unserem Hauptexpertenberater legen wir auch fest, wann und wie oft unser EA das Modell aus dem gemeinsamen Verzeichnis laden soll, wodurch wir das Modell für unseren Handelsroboter effektiv aktualisieren.
Wir können die Funktion OnTimer verwenden, die auch sehr gut funktioniert :)
int OnInit() { //--- Check if the model file exists .... //--- Initialize a catboost model .... //--- if (!EventSetTimer(60)) //Execute the OnTimer function after every 60 seconds { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- .... } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnTimer(void) { if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; //--- Load the new model after deleting the prior one from memory catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Ergebnis:
HO 0 13:14:00.648 Online Learning Catboost (EURUSD,D1) 2024.11.18 12:14 New model loaded FK 0 13:15:55.388 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:15 New model loaded JG 0 13:16:55.380 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:16 New model loaded MP 0 13:17:55.376 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:17 New model loaded JM 0 13:18:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:18 New model loaded PF 0 13:19:55.368 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:19 New model loaded CR 0 13:20:55.387 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:20 New model loaded NO 0 13:21:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:21 New model loaded LH 0 13:22:55.379 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:22 New model loaded
Jetzt haben wir gesehen, wie Sie den Trainingsprozess planen und die neuen Modelle mit dem ExpertAdvisor in MetaTrader 5 synchronisieren können. Der Prozess ist zwar für die meisten eine einfach zu implementierenden maschinellen Lerntechnik, aber es könnte eine Herausforderung sein, wenn man mit tiefen Lernmodellen wie rekurrenten neuronalen Netzen (RNNs) arbeitet, die nicht in der Pipeline von Sklearn enthalten sein können, was unser Leben einfacher macht, wenn wir mit verschiedenen maschinellen Lernmodellen arbeiten.
Sehen wir uns an, wie Sie diese Technik bei der Arbeit mit einer Gated Recurrent Unit (GRU) anwenden können, die eine spezielle Form eines rekurrenten neuronalen Netzes ist.
Online-Lernen für Deep Learning AI-Modelle
Im „Python Client“
Wir wenden das typische maschinelle Lernen innerhalb der Klasse GRUClassifier an. Weitere Informationen über GRU finden Sie in diesem Artikel.
Nach dem Training des Modells speichern wir es in ONNX, dieses Mal speichern wir auch die Informationen des StandardScalers in Binärdateien, dies wird uns später bei der ähnlichen Normalisierung der neuen Daten in MQL5 helfen, so wie es derzeit in Python steht.
Datei gru_models.py
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx class GRUClassifier(): def __init__(self, time_step, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None self.time_step = time_step self.classes_in_y = np.unique(self.y_train) def train(self, learning_rate=0.001, layers=2, neurons = 50, activation="relu", batch_size=32, epochs=100, loss="binary_crossentropy", verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.X_train.shape[2]))) self.model.add(GRU(units=neurons, activation=activation)) # input layer for layer in range(layers): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=neurons, activation=activation)) self.model.add(Dropout(0.5)) self.model.add(Dense(units=len(self.classes_in_y), activation='softmax', name='output_layer')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=learning_rate) self.model.compile(optimizer=adam_optimizer, loss=loss, metrics=['accuracy']) early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.X_train, self.y_train, epochs=epochs, batch_size=batch_size, validation_data=(self.X_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.X_test, self.y_test, verbose=verbose) print("Gru accuracy on validation sample = ",val_accuracy) def to_onnx(self, model_name, standard_scaler): # Convert the Keras model to ONNX spec = (tf.TensorSpec((None, self.time_step, self.X_train.shape[2]), tf.float16, name="input"),) self.model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(model_name, "wb") as f: f.write(onnx_model.SerializeToString()) # Save the mean and scale parameters to binary files standard_scaler.mean_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_mean.bin") standard_scaler.scale_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_scale.bin")
In der Datei „main.py“ erstellen wir eine Funktion, die für alles verantwortlich ist, was wir mit dem GRU-Modell machen wollen.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) # Preparing the target variable data["future_open"] = data["open"].shift(-1) data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: target.append(1) else: target.append(0) data["target"] = target data = data.dropna() # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=False) ########### Preparing data for timeseries forecasting ############### time_step = 10 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) x_train_seq, y_train_seq = create_sequences(X_train, y_train, time_step) x_test_seq, y_test_seq = create_sequences(X_test, y_test, time_step) ###### One HOt encoding ####### y_train_encoded = to_categorical(y_train_seq) y_test_encoded = to_categorical(y_test_seq) gru = gru_models.GRUClassifier(time_step=time_step, X_train= x_train_seq, y_train= y_train_encoded, X_test= x_test_seq, y_test= y_test_encoded ) gru.train( batch_size=64, learning_rate=0.001, activation = "relu", epochs=1000, loss="binary_crossentropy", layers = 2, neurons = 50, verbose=1 ) # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist gru.to_onnx(model_name=os.path.join(models_path, "gru.H1.onnx"), standard_scaler=scaler)
Schließlich können wir planen, wie oft diese Funktion trainAndSaveGRU in Aktion treten soll, ähnlich wie wir es für die CatBoost-Funktion geplant haben.
schedule.every(1).minute.do(trainAndSaveGRU) #scheduled GRU training
Ergebnis:
Epoch 1/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 7s 87ms/step - accuracy: 0.4930 - loss: 0.6985 - val_accuracy: 0.5000 - val_loss: 0.6958 Epoch 2/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4847 - loss: 0.6957 - val_accuracy: 0.4931 - val_loss: 0.6936 Epoch 3/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5500 - loss: 0.6915 - val_accuracy: 0.4897 - val_loss: 0.6934 Epoch 4/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4910 - loss: 0.6923 - val_accuracy: 0.4690 - val_loss: 0.6938 Epoch 5/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.5538 - loss: 0.6910 - val_accuracy: 0.4897 - val_loss: 0.6935 Epoch 6/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.5037 - loss: 0.6953 - val_accuracy: 0.4931 - val_loss: 0.6937 Epoch 7/1000 ... ... ... 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step - accuracy: 0.4964 - loss: 0.6952 - val_accuracy: 0.4793 - val_loss: 0.6940 Epoch 20/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.5285 - loss: 0.6914 - val_accuracy: 0.4793 - val_loss: 0.6949 Epoch 21/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5224 - loss: 0.6935 - val_accuracy: 0.4966 - val_loss: 0.6942 Epoch 22/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step - accuracy: 0.5009 - loss: 0.6936 - val_accuracy: 0.5103 - val_loss: 0.6933 10/10 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.4925 - loss: 0.6938 Gru accuracy on validation sample = 0.5103448033332825
Im MetaTrader 5
Wir beginnen mit dem Laden der Bibliotheken, die uns beim Laden des GRU-Modells und des Standard-Skalierers helfen.
#include <preprocessing.mqh> #include <GRU.mqh> CGRU *gru; StandardizationScaler *scaler; //--- Arrays for temporary storage of the scaler values double scaler_mean[], scaler_std[]; input string model_name = "gru.H1.onnx"; string mean_file; string std_file;
Das erste, was wir in der OnInit-Funktion tun wollen, ist die Namen der Scaler-Binärdateien abzurufen, wir haben das gleiche Prinzip bei der Erstellung dieser Dateien angewendet.
string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin";
Schließlich laden wir das GRU-Modell im ONNX-Format aus dem allgemeinen Ordner und lesen auch die Skalierungsdateien im Binärformat, indem wir ihre Werte in die Arrays scaler_mean und scaler_std eintragen.
int OnInit() { string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) //we followed this same file patterns while saving the binary files in python client { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin"; //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize the GRU model from the common folder gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Read the scaler files if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return INIT_FAILED; } scaler = new StandardizationScaler(scaler_mean, scaler_std); //Load the scaler class by populating it with values //--- Set the timer if (!EventSetTimer(60)) { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; }
Wir planen den Prozess des Lesens der Skalierungs- und Modelldateien aus dem gemeinsamen Ordner in der Funktion OnTimer.
void OnTimer(void) { //--- Delete the existing pointers in memory as the new ones are about to be created if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; //--- if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return; } scaler = new StandardizationScaler(scaler_mean, scaler_std); gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Ergebnis:
II 0 14:49:35.920 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:49 New model loaded QP 0 14:50:35.886 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... MF 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) ONNX model Initialized IJ 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:50 New model loaded EN 0 14:51:35.894 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... JD 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) ONNX model Initialized EL 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:51 New model loaded NM 0 14:52:35.885 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... KK 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QQ 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:52 New model loaded DK 0 14:53:35.899 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... HI 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) ONNX model Initialized MS 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:53 New model loaded DI 0 14:54:35.885 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... IL 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QE 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:54 New model loaded
Um die Vorhersagen des GRU-Modells zu erhalten, müssen wir den Zeitschrittwert berücksichtigen, der rekurrenten neuronalen Netzen (RNNs) hilft, zeitliche Abhängigkeiten in den Daten zu verstehen.
Wir haben in der Funktion „trainAndSaveGRU“ einen Zeitschritt von zehn(10) verwendet.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) .... .... time_step = 10
Sammeln wir die letzten 10 Balken (Zeitschritte) aus der Historie, beginnend mit dem zuletzt geschlossenen Balken in MQL5 (so soll es sein).
input int time_step = 10;
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, time_step, rates); //copy the recent closed bar information vector classes = {0,1}; //Beware of how classes are organized in the target variable. use numpy.unique(y) to determine this array matrix X = matrix::Zeros(time_step, 6); // 6 columns for (int i=0; i<time_step; i++) { vector row = { (double)rates[i].time, rates[i].open, rates[i].high, rates[i].low, rates[i].close, (double)rates[i].tick_volume}; X.Row(row, i); } X = scaler.transform(X); //it's important to normalize the data Comment(TimeCurrent(),"\nPredicted signal: ",gru.predict_bin(X, classes)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Ergebnis:
Inkrementelles maschinelles Lernen
Einige Modelle sind in Bezug auf die Trainingsmethoden leistungsfähiger und robuster als andere. Wenn Sie im Internet nach „Online Machine Learning“ suchen, sagen die meisten Leute, dass es sich um einen Prozess handelt, bei dem kleine Datenmengen für das Modell für das größere Trainingsziel erneut trainiert werden.
Das Problem dabei ist, dass viele Modelle bei einer kleinen Datenstichprobe nicht unterstützt werden oder nicht gut funktionieren.
Moderne maschinelle Lerntechniken wie CatBoost sind auf inkrementelles Lernen ausgerichtet. Diese Trainingsmethode kann für das Online-Lernen verwendet werden und hilft, bei der Arbeit mit großen Datenmengen viel Speicherplatz zu sparen, da die Daten in kleine Teile aufgeteilt werden können, die dann wieder auf das ursprüngliche Modell rück-trainiert werden können.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) df_rates = pd.DataFrame(rates) return df_rates def trainIncrementally(): # CatBoost model clf = CatBoostClassifier( task_type="CPU", iterations=2000, learning_rate=0.2, max_depth=1, verbose=0, ) # Get big data big_data = getData(1, 10000) # Split into chunks of 1000 samples chunk_size = 1000 chunks = [big_data[i:i + chunk_size].copy() for i in range(0, len(big_data), chunk_size)] # Use .copy() here for i, chunk in enumerate(chunks): # Preparing the target variable chunk["future_open"] = chunk["open"].shift(-1) chunk["future_close"] = chunk["close"].shift(-1) target = [] for row in range(chunk.shape[0]): if chunk["future_close"].iloc[row] > chunk["future_open"].iloc[row]: target.append(1) else: target.append(0) chunk["target"] = target chunk = chunk.dropna() # Check if we were able to receive some data if (len(chunk)<=0): print("Failed to obtain chunk from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = chunk.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = chunk["target"] X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.8, random_state=42) if i == 0: # Initial training, training the model for the first time clf.fit(X_train, y_train, eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") else: # Incremental training by using the intial trained model clf.fit(X_train, y_train, init_model="model.cbm", eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") # Save the model clf.save_model("model.cbm") print(f"Chunk {i + 1}/{len(chunks)} processed and model saved.")
Ergebnis:
---> Acc score: 0.555 Chunk 1/10 processed and model saved. ---> Acc score: 0.505 Chunk 2/10 processed and model saved. ---> Acc score: 0.55 Chunk 3/10 processed and model saved. ---> Acc score: 0.565 Chunk 4/10 processed and model saved. ---> Acc score: 0.495 Chunk 5/10 processed and model saved. ---> Acc score: 0.55 Chunk 6/10 processed and model saved. ---> Acc score: 0.555 Chunk 7/10 processed and model saved. ---> Acc score: 0.52 Chunk 8/10 processed and model saved. ---> Acc score: 0.455 Chunk 9/10 processed and model saved. ---> Acc score: 0.535 Chunk 10/10 processed and model saved.
Sie können dieselbe Online-Learning-Architektur befolgen, während Sie das Modell schrittweise aufbauen und das endgültige Modell im ONNX-Format im Verzeichnis „Common“ für die Verwendung in MetaTrader 5 speichern.
Abschließende Überlegungen
Online-Lernen ist ein hervorragender Ansatz, um Modelle mit minimalen manuellen Eingriffen kontinuierlich zu aktualisieren. Durch die Implementierung dieser Infrastruktur können Sie sicher sein, dass Ihre Modelle mit den neuesten Markttrends übereinstimmen und sich schnell an neue Informationen anpassen lassen. Es ist jedoch zu beachten, dass das Online-Lernen die Modelle manchmal sehr empfindlich auf die Reihenfolge der Datenverarbeitung reagieren lässt. Oft ist eine menschliche Aufsicht erforderlich, um zu überprüfen, ob das Modell und die Trainingsinformationen aus menschlicher Sicht logisch sinnvoll sind.Sie müssen das richtige Gleichgewicht zwischen der Automatisierung des Lernprozesses und der regelmäßigen Bewertung Ihrer Modelle finden, um sicherzustellen, dass alles wie erwartet verläuft.
Tabelle der Anhänge
Infrastruktur (Ordner) | Dateien | Beschreibung und Verwendung |
|---|---|---|
Python Client | - catboost_models.py - gru_models.py - main.py - incremental_learning.py | - Ein CatBoost-Modell ist in dieser Datei zu finden. - Ein GRU-Modell ist in dieser Datei zu finden. - Die Hauptpython-Datei für die Zusammenstellung des Ganzen. - Das inkrementelle Lernen für das CatBoost-Modell wird in dieser Datei implementiert. |
Verzeichnis Common | - catboost.H1.onnx - gru.H1.onnx - gru.H1.standard_scaler_mean.bin - gru.H1.standard_scaler_scale.bin | Alle AI-Modelle im ONNX-Format und die Skalierungsdateien im Binärformat sind in diesem Ordner zu finden. |
| MetaTrader 5 (MQL5) | - Experts\Online Learning Catboost.mq5 - Experts\Online Learning GRU.mq5 - Include\CatBoost.mqh - Include\GRU.mqh - Include\preprocessing.mqh | - Setzt ein CatBoost-Modell in MQL5 ein. - Setzt ein GRU-Modell in MQL5 ein. - Eine Bibliotheksdatei zur Initialisierung und Bereitstellung eines CatBoost-Modells im ONNX-Format. - Eine Bibliotheksdatei zur Initialisierung und Bereitstellung eines GRU-Modells im ONNX-Format. - Eine Bibliotheksdatei, die den StandardScaler zur Normalisierung der Daten für die Verwendung des ML-Modells enthält |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16390
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Connexus Observer (Teil 8): Hinzufügen eines Request Observer
Connexus Observer (Teil 8): Hinzufügen eines Request Observer
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo Omega J Msigwa
ich habe gefragt, welche Version von Python Sie für diesen Artikel verwenden. Ich habe sie installiert und es gibt einen Bibliothekskonflikt.
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.3
onnx 1.17.0 ist abhängig von protobuf>=3.20.2
onnxconverter-common 1.14.0 hängt von protobuf==3.20.2 ab
Dann habe ich die Version wie vorgeschlagen geändert und erhielt einen weiteren Installationsfehler.
Um dies zu beheben, könnte man versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. Entfernen Sie die Paketversionen, damit pip versuchen kann, den Abhängigkeitskonflikt zu lösen.
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.2
onnx 1.17.0 hängt ab von protobuf>=3.20.2
onnxconverter-common 1.14.0 hängt ab von protobuf==3.20.2
tensorboard 2.18.0 hängt von protobuf ab!=4.24.0 und >=3.19.6
tensorflow-intel 2.18.0 hängt ab von protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev und >=3.20.3
Um dies zu beheben, könnten Sie versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. Entfernen Sie Paketversionen, damit pip versuchen kann, den Abhängigkeitskonflikt zu lösen.
Bitte geben Sie weitere Anweisungen
Hallo Omega J Msigwa
Ich habe gefragt, welche Version von Python Sie für diesen Artikel verwenden. Ich habe sie installiert und es gibt einen Bibliothekskonflikt.
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.3
onnx 1.17.0 hängt von protobuf>=3.20.2 ab
onnxconverter-common 1.14.0 hängt von protobuf==3.20.2 ab
Dann habe ich die Version wie vorgeschlagen geändert und erhielt einen weiteren Installationsfehler.
Um dies zu beheben, könnten Sie es versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. Paketversionen zu entfernen, damit pip versuchen kann
den Abhängigkeitskonflikt zu lösen
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.2
onnx 1.17.0 hängt von protobuf>=3.20.2 ab
onnxconverter-common 1.14.0 hängt von protobuf==3.20.2 ab
tensorboard 2.18.0 hängt von protobuf!=4.24.0 und >=3.19.6 ab
tensorflow-intel 2.18.0 hängt ab von protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev und >=3.20.3
Um das Problem zu beheben, könnten Sie Folgendes versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. entfernen Sie Paketversionen, damit pip versuchen kann, den Abhängigkeitskonflikt zu lösen
Bitte geben Sie weitere Anweisungen
Hallo Omega J Msigwa
Ich habe gefragt, welche Version von Python Sie für diesen Artikel verwenden. Ich habe sie installiert und es gibt einen Bibliothekskonflikt.
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.3
onnx 1.17.0 ist abhängig von protobuf>=3.20.2
onnxconverter-common 1.14.0 hängt von protobuf==3.20.2 ab
Dann habe ich die Version wie vorgeschlagen geändert und erhielt einen weiteren Installationsfehler.
Um dies zu beheben, könnten Sie es versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. entfernen Sie Paketversionen, damit pip versuchen kann, den Abhängigkeitskonflikt zu lösen
Der Konflikt wird verursacht durch:
Der Benutzer forderte protobuf==3.20.2
onnx 1.17.0 hängt von protobuf>=3.20.2 ab
onnxconverter-common 1.14.0 hängt von protobuf==3.20.2 ab
tensorboard 2.18.0 hängt von protobuf!=4.24.0 und >=3.19.6 ab
tensorflow-intel 2.18.0 hängt ab von protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev und >=3.20.3
Um das Problem zu beheben, könnten Sie Folgendes versuchen:
1. den Bereich der Paketversionen, den Sie angegeben haben, zu lockern
2. Entfernen Sie Paketversionen, damit pip versuchen kann, den Abhängigkeitskonflikt zu lösen
Bitte geben Sie weitere Anweisungen
numpy==1.23.5