
Ciência de dados e aprendizado de máquina (Parte 32): Como manter a relevância de modelos de IA com treinamento on-line

Conteúdo
- O que é aprendizado online?
- Vantagens do aprendizado online
- Infraestrutura de aprendizado online para MetaTrader 5
- Automatização do processo de treinamento e execução
- Aprendizado online para modelos de IA com aprendizado profundo
- Aprendizado incremental de máquina
- Considerações finais
O que é aprendizado online?
Aprendizado online, no contexto de aprendizado de máquina, é um método em que o modelo é treinado gradualmente com um fluxo contínuo de dados em tempo real. Trata-se de um processo dinâmico que permite adaptar o algoritmo de previsão graças ao reeducamento com novos dados. Esse aprendizado contínuo é especialmente importante em ambientes com muitos dados que mudam rapidamente, pois ajuda a manter o modelo relevante.
Ao lidar com dados de mercado, sempre é difícil determinar o momento ideal para atualizar os modelos e com qual frequência essas atualizações devem acontecer. Por exemplo, se o modelo de IA foi treinado com dados do Bitcoin, os dados mais recentes podem ser considerados valores atípicos para o algoritmo, considerando que recentemente a criptomoeda atingiu uma nova máxima histórica.
Diferente do mercado cambial, onde os símbolos historicamente oscilam dentro de certos intervalos, instrumentos como NASDAQ 100, S&P 500 e índices semelhantes, bem como ações, geralmente tendem a subir e a renovar os máximos históricos.
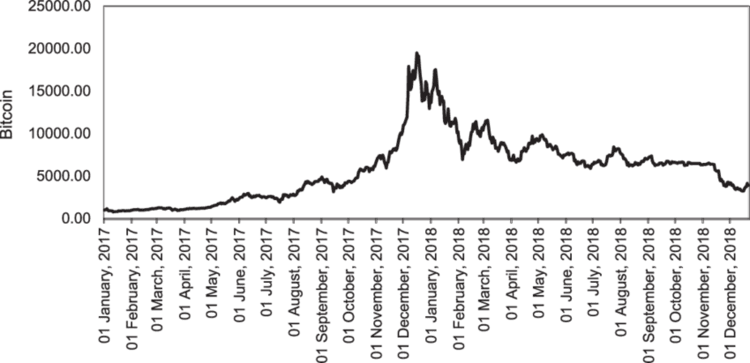
O aprendizado online não é usado apenas para combater a obsolescência dos dados nos quais o modelo foi treinado, mas também para mantê-lo atualizado com informações recentes que podem influenciar diretamente os eventos atuais do mercado.
Vantagens do aprendizado online
- Adaptabilidade
Como um ciclista que melhora suas habilidades enquanto pedala, os algoritmos de aprendizado online conseguem se ajustar a novos padrões nos dados, aumentando gradualmente a precisão das previsões. - Escalabilidade
Alguns métodos de aprendizado online permitem processar os dados uma amostra por vez. Isso torna a abordagem mais econômica em termos de recursos computacionais, o que é um ponto importante para a maioria dos usuários. Isso facilita a escalabilidade de modelos que lidam com grandes volumes de dados. - Previsões em tempo real
Diferente do aprendizado em lote, cujos resultados podem estar desatualizados no momento da aplicação, o aprendizado online mantém a relevância, algo especialmente importante em estratégias de trading. - Eficiência
O aprendizado passo a passo e a atualização dos modelos permitem reduzir o tempo de treinamento e seu custo, ao mesmo tempo em que garantem adaptação contínua.
Agora que analisamos as principais vantagens dessa abordagem, vamos ver qual infraestrutura é necessária para implementar de forma eficaz o aprendizado online no MetaTrader 5.
Infraestrutura de aprendizado online para MetaTrader 5
Como nosso objetivo final é tornar os modelos de IA úteis para o trading no MetaTrader 5, isso exige uma infraestrutura de aprendizado online diferente daquela normalmente utilizada em aplicações baseadas em Python.

Etapa 01: Cliente Python
No cliente Python (script), vamos construir modelos de IA com base nos dados de mercado obtidos a partir do MetaTrader 5.
Vamos utilizar a biblioteca MetaTrader 5 Python. Começamos com a inicialização da plataforma.
import pandas as pd import numpy as np import MetaTrader5 as mt5 from datetime import datetime if not mt5.initialize(): # Initialize the MetaTrader 5 platform print("initialize() failed") mt5.shutdown()
Após inicializar o MetaTrader 5, obtemos os dados de mercado usando o método copy_rates_from_pos.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) if len(rates) < bars: # if the received information is less than specified print("Failed to copy rates from MetaTrader 5, error = ",mt5.last_error()) # create a pandas DataFrame out of the obtained data df_rates = pd.DataFrame(rates) return df_rates
Exibimos os dados obtidos.
print("Trading info:\n",getData(1, 100)) # get 100 bars starting at the recent closed bar
Exibição dos dados
time open high low close tick_volume spread real_volume 0 1731351600 1.06520 1.06564 1.06451 1.06491 1688 0 0 1 1731355200 1.06491 1.06519 1.06460 1.06505 1607 0 0 2 1731358800 1.06505 1.06573 1.06495 1.06512 1157 0 0 3 1731362400 1.06512 1.06564 1.06512 1.06557 1112 0 0 4 1731366000 1.06557 1.06579 1.06553 1.06557 776 0 0 .. ... ... ... ... ... ... ... ... 95 1731693600 1.05354 1.05516 1.05333 1.05513 5125 0 0 96 1731697200 1.05513 1.05600 1.05472 1.05486 3966 0 0 97 1731700800 1.05487 1.05547 1.05386 1.05515 2919 0 0 98 1731704400 1.05515 1.05522 1.05359 1.05372 2651 0 0 99 1731708000 1.05372 1.05379 1.05164 1.05279 2977 0 0 [100 rows x 8 columns]
Usamos o método copy_rates_from_pos porque ele permite acessar a última barra fechada com o índice 1. Isso é muito mais conveniente do que usar datas fixas, já que sempre retornam os dados mais recentes.
Graças a isso, podemos ter certeza de que, a partir da barra com índice 1, estamos recebendo os dados justamente da última barra fechada e, a partir daí, tantas barras quanto forem necessárias.
Depois que os dados necessários forem obtidos, podemos seguir para os passos padrão do aprendizado de máquina.
Criamos arquivos separados para cada modelo. Essa abordagem facilita o trabalho no arquivo principal main.py, onde os processos e funções principais estão implementados, será fácil importar os modelos desejados.
Arquivo catboost_models.py
from catboost import CatBoostClassifier from sklearn.metrics import accuracy_score from onnx.helper import get_attribute_value from skl2onnx import convert_sklearn, update_registered_converter from sklearn.pipeline import Pipeline from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost.utils import convert_to_onnx_object # Example initial data (X_initial, y_initial are your initial feature matrix and target) class CatBoostClassifierModel(): def __init__(self, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None def train(self, iterations=100, depth=6, learning_rate=0.1, loss_function="CrossEntropy", use_best_model=True): # Initialize the CatBoost model params = { "iterations": iterations, "depth": depth, "learning_rate": learning_rate, "loss_function": loss_function, "use_best_model": use_best_model } self.model = Pipeline([ # wrap a catboost classifier in sklearn pipeline | good practice (not necessary tho :)) ("catboost", CatBoostClassifier(**params)) ]) # Testing the model self.model.fit(X=self.X_train, y=self.y_train, catboost__eval_set=(self.X_test, self.y_test)) y_pred = self.model.predict(self.X_test) print("Model's accuracy on out-of-sample data = ",accuracy_score(self.y_test, y_pred)) # a function for saving the trained CatBoost model to ONNX format def to_onnx(self, model_name): update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, self.skl2onnx_convert_catboost, parser=self.skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( self.model, "pipeline_catboost", [("input", FloatTensorType([None, self.X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(model_name, "wb") as f: f.write(model_onnx.SerializeToString())
No caso deste modelo CatBoost, discutimos ele com mais detalhes em um artigo separado. Eu utilizei este modelo CatBoost como exemplo, mas você pode usar qualquer outro modelo conforme sua preferência.
Assim, acima escrevemos a classe que usaremos para inicializar, treinar e salvar o modelo CatBoost. Vamos integrar esse modelo no arquivo "main.py".
Arquivo main.py
Como antes, começamos com a obtenção de dados do terminal desktop MetaTrader 5:
data = getData(start=1, bars=1000)
Se observar com atenção o modelo CatBoost utilizado, verá que se trata de um classificador. No entanto, não temos uma variável alvo (target) para esse classificador. Precisamos criá-la.
# Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows
Podemos remover do array bidimensional X todas as variáveis futuras, assim como as características que contêm uma grande quantidade de valores zero, e definir a variável target como um array unidimensional y.
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"]
Depois disso, dividimos os dados em conjuntos de treino e validação, inicializamos o modelo CatBoost usando dados de mercado e o treinamos.
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train()
Por fim, salvamos o modelo no formato ONNX dentro do diretório comum do MetaTrader 5.
Etapa 02: Pasta compartilhada
Com a biblioteca Python MetaTrader 5, é possível obter o caminho para o diretório comum.
terminal_info_dict = mt5.terminal_info()._asdict()
common_path = terminal_info_dict["commondata_path"] É nesse local que vamos armazenar todos os modelos de IA treinados, criados no nosso cliente Python.
Ao acessar esse diretório comum a partir do MQL5, normalmente utilizamos a subpasta Files, localizada dentro desse diretório compartilhado. Para que o acesso a esses modelos funcione corretamente no MQL5, eles devem ser salvos exatamente nessa subpasta.
# Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Por fim, vamos encapsular todas essas linhas de código em uma única função para facilitar a execução de todos os processos quando necessário.
def trainAndSaveCatBoost(): data = getData(start=1, bars=1000) # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() # Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train() # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Em seguida, chamamos essa função e observamos o que ela realiza.
trainAndSaveCatBoost()
exit() # stop the script Execução da função
0: learn: 0.6916088 test: 0.6934968 best: 0.6934968 (0) total: 163ms remaining: 16.1s 1: learn: 0.6901684 test: 0.6936087 best: 0.6934968 (0) total: 168ms remaining: 8.22s 2: learn: 0.6888965 test: 0.6931576 best: 0.6931576 (2) total: 175ms remaining: 5.65s 3: learn: 0.6856524 test: 0.6927187 best: 0.6927187 (3) total: 184ms remaining: 4.41s 4: learn: 0.6843646 test: 0.6927737 best: 0.6927187 (3) total: 196ms remaining: 3.72s ... ... ... 96: learn: 0.5992419 test: 0.6995323 best: 0.6927187 (3) total: 915ms remaining: 28.3ms 97: learn: 0.5985751 test: 0.7002011 best: 0.6927187 (3) total: 924ms remaining: 18.9ms 98: learn: 0.5978617 test: 0.7003299 best: 0.6927187 (3) total: 928ms remaining: 9.37ms 99: learn: 0.5968786 test: 0.7010596 best: 0.6927187 (3) total: 932ms remaining: 0us bestTest = 0.6927187021 bestIteration = 3 Shrink model to first 4 iterations. Точность модели на данных вне обучающей выборки составила 0,5
O arquivo .onnx está disponível na pasta Common\Files.
Etapa 03: MetaTrader 5
Agora, no MetaTrader 5, é necessário carregar o modelo salvo no formato ONNX.
Começamos importando a biblioteca responsável por essa tarefa.
Arquivo "Online Learning Catboost.mq5"
#include <CatBoost.mqh> CCatBoost *catboost; input string model_name = "catboost.H1.onnx"; input string symbol = "EURUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; string common_path;
A primeira coisa a ser feita dentro da função OnInit é verificar se o arquivo do modelo está presente no diretório comum. Caso o arquivo esteja ausente, isso pode indicar que o modelo ainda não foi treinado.
Em seguida, inicializamos o modelo ONNX passando o parâmetro ONNX_COMMON_FOLDER, para indicar explicitamente que o modelo deve ser carregado a partir da pasta comum (Common folder).
int OnInit() { //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize a catboost model catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- }
Para utilizar o modelo carregado na previsão, voltamos ao script Python e verificamos quais características foram utilizadas no treinamento após a remoção de algumas delas.
No MQL5, é necessário reunir as mesmas características, na mesma ordem.
Código Python do arquivo "main.py".
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] print(X.head())
Execução da função
time open high low close tick_volume 0 1726772400 1.11469 1.11584 1.11453 1.11556 3315 1 1726776000 1.11556 1.11615 1.11525 1.11606 2812 2 1726779600 1.11606 1.11680 1.11606 1.11656 2309 3 1726783200 1.11656 1.11668 1.11590 1.11622 2667 4 1726786800 1.11622 1.11644 1.11605 1.11615 1166
Depois, dentro da função OnTick, obtemos esses dados e chamamos a função predict_bin, que faz a previsão das classes.
No nosso caso, a função retorna duas classes, correspondentes aos valores da variável target preparada no cliente Python: 0 — mercado de alta (bullish), 1 — mercado de baixa (bearish).
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, 1, rates); //copy the recent closed bar information vector x = { (double)rates[0].time, rates[0].open, rates[0].high, rates[0].low, rates[0].close, (double)rates[0].tick_volume}; Comment(TimeCurrent(),"\nPredicted signal: ",catboost.predict_bin(x)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Execução da função
Automatização do processo de treinamento e execução
Conseguimos treinar e carregar o modelo no MetaTrader 5, porém, nosso objetivo é automatizar completamente esse processo.
Dentro do ambiente virtual Python, é necessário instalar a biblioteca schedule.
$ pip install schedule
Esse pequeno módulo permite agendar a execução de determinadas funções. Como já encapsulamos o código de coleta de dados, treinamento e salvamento do modelo em uma função, podemos configurar sua chamada automática a cada minuto.
schedule.every(1).minute.do(trainAndSaveCatBoost) #schedule catboost training # Keep the script running to execute the scheduled tasks while True: schedule.run_pending() time.sleep(60) # Wait for 1 minute before checking again
O agendamento funciona como mágica :)
No EA principal, também vamos configurar um agendamento, isto é, quando e com que frequência ele deve carregar o modelo a partir do diretório comum. Dessa forma, atualizamos o modelo para o nosso robô de trading.
Para isso, usamos a função OnTimer, que também executa essa tarefa perfeitamente.
int OnInit() { //--- Check if the model file exists .... //--- Initialize a catboost model .... //--- if (!EventSetTimer(60)) //Execute the OnTimer function after every 60 seconds { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- .... } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnTimer(void) { if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; //--- Load the new model after deleting the prior one from memory catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Execução da função
HO 0 13:14:00.648 Online Learning Catboost (EURUSD,D1) 2024.11.18 12:14 New model loaded FK 0 13:15:55.388 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:15 New model loaded JG 0 13:16:55.380 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:16 New model loaded MP 0 13:17:55.376 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:17 New model loaded JM 0 13:18:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:18 New model loaded PF 0 13:19:55.368 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:19 New model loaded CR 0 13:20:55.387 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:20 New model loaded NO 0 13:21:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:21 New model loaded LH 0 13:22:55.379 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:22 New model loaded
Vimos como automatizar o processo de treinamento e manter a relevância dos modelos em conjunto com o EA no MetaTrader 5. Embora essa abordagem seja facilmente aplicável à maioria dos métodos de aprendizado de máquina, ao trabalhar com modelos de aprendizado profundo (como redes neurais recorrentes, RNN) podem surgir dificuldades. Em particular, RNN não pode ser integrada de forma prática no pipeline Sklearn, que facilita bastante o uso de modelos clássicos de aprendizado de máquina.
Vamos ver como aplicar essa abordagem ao trabalhar com um bloco recorrente controlado (GRU), que é uma forma especial de rede neural recorrente.
Aprendizado online para modelos de IA com aprendizado profundo
No cliente Python
Executamos os passos padrão de aprendizado de máquina dentro da classe GRUClassifier. Já falamos mais detalhadamente sobre GRU anteriormente neste artigo.
Após o treinamento do modelo, salvamos ele no formato ONNX. Desta vez, também salvamos os parâmetros do objeto StandardScaler em arquivos binários. Isso permitirá normalizar novos dados no MQL5 da mesma forma que no Python.
Arquivo gru_models.py
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx class GRUClassifier(): def __init__(self, time_step, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None self.time_step = time_step self.classes_in_y = np.unique(self.y_train) def train(self, learning_rate=0.001, layers=2, neurons = 50, activation="relu", batch_size=32, epochs=100, loss="binary_crossentropy", verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.X_train.shape[2]))) self.model.add(GRU(units=neurons, activation=activation)) # input layer for layer in range(layers): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=neurons, activation=activation)) self.model.add(Dropout(0.5)) self.model.add(Dense(units=len(self.classes_in_y), activation='softmax', name='output_layer')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=learning_rate) self.model.compile(optimizer=adam_optimizer, loss=loss, metrics=['accuracy']) early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.X_train, self.y_train, epochs=epochs, batch_size=batch_size, validation_data=(self.X_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.X_test, self.y_test, verbose=verbose) print("Gru accuracy on validation sample = ",val_accuracy) def to_onnx(self, model_name, standard_scaler): # Convert the Keras model to ONNX spec = (tf.TensorSpec((None, self.time_step, self.X_train.shape[2]), tf.float16, name="input"),) self.model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(model_name, "wb") as f: f.write(onnx_model.SerializeToString()) # Save the mean and scale parameters to binary files standard_scaler.mean_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_mean.bin") standard_scaler.scale_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_scale.bin")
No arquivo main.py, criamos uma função responsável por trabalhar com o modelo GRU.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) # Preparing the target variable data["future_open"] = data["open"].shift(-1) data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: target.append(1) else: target.append(0) data["target"] = target data = data.dropna() # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=False) ########### Preparing data for timeseries forecasting ############### time_step = 10 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) x_train_seq, y_train_seq = create_sequences(X_train, y_train, time_step) x_test_seq, y_test_seq = create_sequences(X_test, y_test, time_step) ###### One HOt encoding ####### y_train_encoded = to_categorical(y_train_seq) y_test_encoded = to_categorical(y_test_seq) gru = gru_models.GRUClassifier(time_step=time_step, X_train= x_train_seq, y_train= y_train_encoded, X_test= x_test_seq, y_test= y_test_encoded ) gru.train( batch_size=64, learning_rate=0.001, activation = "relu", epochs=1000, loss="binary_crossentropy", layers = 2, neurons = 50, verbose=1 ) # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist gru.to_onnx(model_name=os.path.join(models_path, "gru.H1.onnx"), standard_scaler=scaler)
Por fim, definimos com que frequência a função trainAndSaveGRU deve ser chamada. Exatamente como fizemos com o CatBoost.
schedule.every(1).minute.do(trainAndSaveGRU) #scheduled GRU training
Execução da função
Epoch 1/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 7s 87ms/step - accuracy: 0.4930 - loss: 0.6985 - val_accuracy: 0.5000 - val_loss: 0.6958 Epoch 2/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4847 - loss: 0.6957 - val_accuracy: 0.4931 - val_loss: 0.6936 Epoch 3/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5500 - loss: 0.6915 - val_accuracy: 0.4897 - val_loss: 0.6934 Epoch 4/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4910 - loss: 0.6923 - val_accuracy: 0.4690 - val_loss: 0.6938 Epoch 5/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.5538 - loss: 0.6910 - val_accuracy: 0.4897 - val_loss: 0.6935 Epoch 6/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.5037 - loss: 0.6953 - val_accuracy: 0.4931 - val_loss: 0.6937 Epoch 7/1000 ... ... ... 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step - accuracy: 0.4964 - loss: 0.6952 - val_accuracy: 0.4793 - val_loss: 0.6940 Epoch 20/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.5285 - loss: 0.6914 - val_accuracy: 0.4793 - val_loss: 0.6949 Epoch 21/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5224 - loss: 0.6935 - val_accuracy: 0.4966 - val_loss: 0.6942 Epoch 22/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step - accuracy: 0.5009 - loss: 0.6936 - val_accuracy: 0.5103 - val_loss: 0.6933 10/10 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.4925 - loss: 0.6938 Gru accuracy on validation sample = 0.5103448033332825
No MetaTrader 5
Primeiro, carregamos as bibliotecas necessárias para carregar o modelo GRU e o escalador padrão.
#include <preprocessing.mqh> #include <GRU.mqh> CGRU *gru; StandardizationScaler *scaler; //--- Arrays for temporary storage of the scaler values double scaler_mean[], scaler_std[]; input string model_name = "gru.H1.onnx"; string mean_file; string std_file;
Depois, na função OnInit, obtemos os nomes dos arquivos binários do escalador, o mesmo princípio que usamos ao criar esses arquivos.
string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin";
Por fim, carregamos o modelo GRU no formato ONNX a partir da pasta comum. Ao mesmo tempo, também lemos os arquivos binários do escalador, atribuindo seus valores aos arrays scaler_mean e scaler_std.
int OnInit() { string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) //we followed this same file patterns while saving the binary files in python client { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin"; //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize the GRU model from the common folder gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Read the scaler files if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return INIT_FAILED; } scaler = new StandardizationScaler(scaler_mean, scaler_std); //Load the scaler class by populating it with values //--- Set the timer if (!EventSetTimer(60)) { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; }
Na função OnTimer, definimos o agendamento para leitura dos arquivos do escalador e do modelo a partir da pasta comum.
void OnTimer(void) { //--- Delete the existing pointers in memory as the new ones are about to be created if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; //--- if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return; } scaler = new StandardizationScaler(scaler_mean, scaler_std); gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Execução da função
II 0 14:49:35.920 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:49 New model loaded QP 0 14:50:35.886 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... MF 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) ONNX model Initialized IJ 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:50 New model loaded EN 0 14:51:35.894 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... JD 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) ONNX model Initialized EL 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:51 New model loaded NM 0 14:52:35.885 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... KK 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QQ 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:52 New model loaded DK 0 14:53:35.899 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... HI 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) ONNX model Initialized MS 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:53 New model loaded DI 0 14:54:35.885 Online Learning GRU (GBPUSD,H1) Initializing ONNX model... IL 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QE 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:54 New model loaded
Para obter previsões do modelo GRU, é necessário considerar o valor do passo temporal timestep, já que ele permite que redes neurais recorrentes (RNN) compreendam as dependências temporais nos dados.
A função trainAndSaveGRU define o valor timestep = 10.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) .... .... time_step = 10
Obtemos os últimos 10 bares (timesteps) do histórico, a partir da última barra fechada no MQL5. (como deve ser)
input int time_step = 10;
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, time_step, rates); //copy the recent closed bar information vector classes = {0,1}; //Beware of how classes are organized in the target variable. use numpy.unique(y) to determine this array matrix X = matrix::Zeros(time_step, 6); // 6 columns for (int i=0; i<time_step; i++) { vector row = { (double)rates[i].time, rates[i].open, rates[i].high, rates[i].low, rates[i].close, (double)rates[i].tick_volume}; X.Row(row, i); } X = scaler.transform(X); //it's important to normalize the data Comment(TimeCurrent(),"\nPredicted signal: ",gru.predict_bin(X, classes)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Execução da função
Aprendizado incremental de máquina
Alguns modelos são mais robustos e eficazes do que outros quando se trata de métodos de aprendizado. Se você buscar na internet sobre aprendizado de máquina online / online machine learning, com frequência encontrará a definição segundo a qual pequenos lotes de dados (mini-batches) são usados para reeducar o modelo original dentro de uma tarefa maior de treinamento.
O problema é que muitos modelos ou não suportam esse modo de funcionamento, ou apresentam resultados insatisfatórios ao serem treinados com pequenos conjuntos de dados.
Os métodos modernos de aprendizado de máquina, entre eles o CatBoost, foram projetados desde o início com esse reeducamento em mente. Isso os torna adequados para aprendizado online e, ao mesmo tempo, permite economia significativa de memória ao lidar com grandes volumes de dados, dividindo-os em blocos menores e reeducando o modelo original de forma sequencial.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) df_rates = pd.DataFrame(rates) return df_rates def trainIncrementally(): # CatBoost model clf = CatBoostClassifier( task_type="CPU", iterations=2000, learning_rate=0.2, max_depth=1, verbose=0, ) # Get big data big_data = getData(1, 10000) # Split into chunks of 1000 samples chunk_size = 1000 chunks = [big_data[i:i + chunk_size].copy() for i in range(0, len(big_data), chunk_size)] # Use .copy() here for i, chunk in enumerate(chunks): # Preparing the target variable chunk["future_open"] = chunk["open"].shift(-1) chunk["future_close"] = chunk["close"].shift(-1) target = [] for row in range(chunk.shape[0]): if chunk["future_close"].iloc[row] > chunk["future_open"].iloc[row]: target.append(1) else: target.append(0) chunk["target"] = target chunk = chunk.dropna() # Check if we were able to receive some data if (len(chunk)<=0): print("Failed to obtain chunk from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = chunk.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = chunk["target"] X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.8, random_state=42) if i == 0: # Initial training, training the model for the first time clf.fit(X_train, y_train, eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") else: # Incremental training by using the initial trained model clf.fit(X_train, y_train, init_model="model.cbm", eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") # Save the model clf.save_model("model.cbm") print(f"Chunk {i + 1}/{len(chunks)} processed and model saved.")
Execução da função
---> Acc score: 0.555 Chunk 1/10 processed and model saved. ---> Acc score: 0.505 Chunk 2/10 processed and model saved. ---> Acc score: 0.55 Chunk 3/10 processed and model saved. ---> Acc score: 0.565 Chunk 4/10 processed and model saved. ---> Acc score: 0.495 Chunk 5/10 processed and model saved. ---> Acc score: 0.55 Chunk 6/10 processed and model saved. ---> Acc score: 0.555 Chunk 7/10 processed and model saved. ---> Acc score: 0.52 Chunk 8/10 processed and model saved. ---> Acc score: 0.455 Chunk 9/10 processed and model saved. ---> Acc score: 0.535 Chunk 10/10 processed and model saved.
Além disso, você pode usar essa mesma arquitetura de aprendizado online para construir o modelo de forma incremental e salvar a versão final no formato ONNX dentro do diretório comum (Common Folder), para que possa ser utilizada posteriormente no MetaTrader 5.
Considerações finais
O aprendizado online é uma excelente forma de manter os modelos atualizados com o mínimo de intervenção humana. Implementar essa infraestrutura permite sincronizar os algoritmos com as tendências mais recentes do mercado e ajudá-los a se adaptar rapidamente a novas informações. No entanto, é importante lembrar que o aprendizado online pode tornar os modelos excessivamente sensíveis à ordem de chegada dos dados, sendo muitas vezes necessária alguma supervisão humana para garantir que o modelo e os dados de treinamento continuem coerentes do ponto de vista lógico.O objetivo principal é encontrar o equilíbrio entre a automação do processo de treinamento e a avaliação periódica dos modelos, para que tudo funcione conforme o planejado.
Tabela de arquivos
Infraestrutura (pastas) | Arquivos | Descrição e uso |
|---|---|---|
Cliente Python | - catboost_models.py - gru_models.py - main.py - incremental_learning.py | - Arquivo contendo o modelo CatBoost - Arquivo contendo o modelo GRU - Arquivo principal Python que une todos os componentes - Arquivo com a implementação do aprendizado incremental para o modelo CatBoost |
Pasta comum (Common Folder) | - catboost.H1.onnx - gru.H1.onnx - gru.H1.standard_scaler_mean.bin - gru.H1.standard_scaler_scale.bin | Contém todos os modelos de IA no formato ONNX e arquivos do escalador nos formatos binários |
| MetaTrader 5 (MQL5) | - Experts\Online Learning Catboost.mq5 - Experts\Online Learning GRU.mq5 - Include\CatBoost.mqh - Include\GRU.mqh - Include\preprocessing.mqh | - Implementa o modelo CatBoost no MQL5 - Implementa o modelo GRU no MQL5 - Arquivo de biblioteca para inicializar e executar o modelo CatBoost em formato ONNX - Arquivo de biblioteca para inicializar e executar o modelo GRU em formato ONNX - Arquivo de biblioteca contendo o StandardScaler para normalização dos dados a serem usados no modelo de aprendizado de máquina |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16390
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, Omega J Msigwa
Perguntei qual versão do python você está usando para este artigo. Eu o instalei e há um conflito de biblioteca.
O conflito é causado por:
O usuário solicitou protobuf==3.20.3
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
Em seguida, editei a versão conforme sugerido e obtive outro erro de instalação.
Para corrigir isso, você pode tentar:
1. diminuir o intervalo de versões de pacotes que você especificou
2. remover versões de pacotes para permitir que o pip tente resolver o conflito de dependências
O conflito é causado por:
O usuário solicitou protobuf==3.20.2
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
tensorboard 2.18.0 depende de protobuf!=4.24.0 e >=3.19.6
tensorflow-intel 2.18.0 depende de protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev e >=3.20.3
Para corrigir isso, você pode tentar:
1. diminuir o intervalo de versões de pacotes que você especificou
2. remover versões de pacotes para permitir que o pip tente resolver o conflito de dependências
Por favor, forneça mais instruções
Oi Omega J Msigwa
Eu perguntei qual versão do python você está usando para este artigo. Eu o instalei e há um conflito de biblioteca.
O conflito é causado por:
O usuário solicitou protobuf==3.20.3
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
Em seguida, editei a versão conforme sugerido e obtive outro erro de instalação.
Para corrigir isso, você pode tentar:
1. diminuir o intervalo de versões de pacotes que você especificou
2. remover versões de pacotes para permitir que o pip tente
resolver o conflito de dependência
O conflito é causado por:
O usuário solicitou protobuf==3.20.2
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
tensorboard 2.18.0 depende de protobuf!=4.24.0 e >=3.19.6
tensorflow-intel 2.18.0 depende de protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev e >=3.20.3
Para corrigir isso, você pode tentar:
1. diminuir o intervalo de versões de pacotes que você especificou
2. remover versões de pacotes para permitir que o pip tente resolver o conflito de dependências
Forneça mais instruções
numpy==1.23.5