
Машинное обучение и Data Science (Часть 31): Применение моделей CatBoost в трейдинге

«CatBoost — это библиотека градиентного бустинга, которая отличается эффективной и масштабируемой обработкой категориальных признаков, обеспечивая значительный прирост производительности для множества прикладных задач».
— Энтони Голдблум.
Что такое CatBoost?
CatBoost — это библиотека с открытым исходным кодом, реализующая алгоритмы градиентного бустинга на деревьях решений. Разработана специально для решения задач, связанных с обработкой категориальных признаков и данных в задачах машинного обучения.
Разработанная компанией Яндекс, библиотека была выложена в открытый доступ в 2017 году (подробнее).
Несмотря на то, что CatBoost появился относительно недавно по сравнению с другими методами машинного обучения, например, линейной регрессией или SVM, библиотека быстро завоевал популярность и вошла в число самых используемых моделей машинного обучения на Kaggle.
CatBoost привлек столько внимания благодаря своей способности автоматически обрабатывать категориальные признаки в наборе данных — а это довольно сложная задача для многих алгоритмов машинного обучения.
- Модели Catboost обычно дают лучшую производительность по сравнению с другими, требуя при этом минимальные усилиях, и даже с параметрами и настройками по умолчанию эти модели демонстрируют отличную точность.
- В отличие от нейронных сетей, для работы с которыми требуются глубокие знания предметной области, CatBoost проще для реализации.

Данный материал предполагает, что у вас есть базовые знания о машинном обучении, деревьях решений, XGBoost, LightGBM и ONNX.
Как работает CatBoost?
CatBoost основан на алгоритме градиентного усиления, это делает его сходим с методами Light Gradient Machine (LightGBM) и Extreme Gradient Boosting (XGBoost). Принцип его работы заключается в последовательном построении нескольких моделей на основе решающих деревьев, где каждая последующая модель пытается скорректировать ошибки предыдущей.
Окончательный прогноз представляет собой взвешенную сумму предсказаний всех моделей, участвующих в процессе.
Цель деревьев решений с градиентным бустингом заключается в минимизации функции потерь. Для этого и добавляется новая модель, которая компенсирует ошибки предыдущей.
Обработка категориальных признаков
Как упоминалось в начале статьи, CatBoost способен обрабатывать категориальные признаки без необходимости кодирования вручную, например, с помощью one-hot или label encoding, которые обычно нужны для других моделей машинного обучения. Это становится возможным благодаря встроенному механизму target-based encoding —кодирования категориальных признаков с использованием информации о целевой переменной.
Суть его в том, что для каждого уникального значения категориального признака рассчитывается условное распределение целевой переменной.
Еще одна важная особенность CatBoost — использование так называемого упорядоченного бустинга (ordered boosting) для вычисления статистики категориальных признаков. При этом кодирование каждого объекта данных опирается только на информацию, полученную из предыдущих объектов.
Такой подход помогает избежать потери данных и переобучения.
Использование симметричных структур решающих деревьев
В отличие от LightGBM и XGBoost, которые используют асимметричные деревья, CatBoost использует симметричные деревья решений для построения моделей. В симметричном дереве обе ветви на каждом разбиении формируются симметрично, с использованием одинакового правила разбиения. Такой подход имеет несколько преимуществ:
- Более быстрое обучение за счет симметричных разбиений;
- Эффективное использование памяти благодаря упрощенной структуре дерева;
- Симметричные деревья более устойчивы к небольшим изменениям в данных.
Сравнение CatBoost, XGBoost и LightGBM
Давайте разберемся, чем CatBoost отличается от других деревьев решений с градиентным бустингом. Ниже представлена сравнительная таблица, которая поможет лучше понять, какой вариант подходит для той или иной ситуации.
Характеристики | CatBoost | LightGBM | XGBoost |
|---|---|---|---|
Обработка категориальных признаков | Автоматическое определение и упорядоченный бустинг для обработки категориальных переменных. | Требует предварительного кодирования (например, one-hot encoding, label encoding и др.) | Требует предварительного кодирования (например, one-hot encoding, label encoding и др.) |
Структура дерева решений | Симметричные деревья решений, которые сбалансированы и растут равномерно. Они дают более быстрые прогнозы и меньший риск переобучения. | Рост по листьям (асимметричная структура), фокусируется на листьях с наибольшими потерями. В результате получаются глубокие и несбалансированные деревья, которые могут обеспечить более высокую точность, но при этом повышают риск переобучения. | Поуровневый рост (асимметричная структура), которая выращивает дерево на основе наилучшего разбиения для каждого узла. Дает гибкие, но более медленные прогнозы, есть потенциальный риск переобучения. |
Точность модели | Хорошая точность при работе с наборами данных, содержащими множество категориальных признаков, благодаря упорядоченному усилению и снижению риска переобучения на меньших данных. | Дают хорошую точность, особенно для больших и многомерных наборов данных, применяются для улучшения производительности в областях с высокой погрешностью. | Обеспечивают хорошую точность для большинства наборов данных, но, как правило, уступают CatBoost на категориальных наборах данных и LightGBM на очень больших наборах данных из-за менее агрессивной стратегии выращивания деревьев. |
Скорость и точность обучения | Обычно обучаются медленнее, чем LightGBM, но более эффективны на небольших и средних наборах данных, особенно когда работаем с категориальными признаками. | Обычно это самый быстрый из этих трех методов, особенно при сравнении на больших наборах данных, благодаря росту дерева по листьям, что более эффективно для многомерных данных. | Самый медленный из этих трех. Эффективен для работы с большими наборами данных. |
Развертывание модели CatBoost
Прежде чем мы приступим к непосредственной работе с CatBoost, давайте создадим сценарий задачи. Мы будем генерировать прогноз торговых сигналов (покупка/продажа) на основе данных Open, High, Low, Close, а также нескольких категориальных признаков — текущая дата, день недели (с понедельника до воскресенья), день года (от 1 до 365) и месяц (с января до декабря).
Значения OHLC (открытие, максимум, минимум, закрытие) являются непрерывными признаками, а остальные — категориальными. Скрипт для сбора этих данных приложен к статье.
Начнем с импорта модели CatBoost.
Установка
Командная строка
pip install catboost
Импорт.
Код Python
import numpy as np import pandas as pd import catboost from catboost import CatBoostClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import seaborn as sns import matplotlib.pyplot as plt sns.set_style("darkgrid")
Чтобы разобраться в данных, визуализируем их.
df = pd.read_csv("/kaggle/input/ohlc-eurusd/EURUSD.OHLC.PERIOD_D1.csv")
df.head()Вывод
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 |
При сборе данных в скрипте на MQL5 я получил значения DayofWeek (с понедельника по воскресенья) и Month (с января по декабря) в виде целочисленных значений, а не строк. Это связано с тем, что данные сохранялись в матрице, и в нее нельзя добавить строки. Хотя эти признаки по своей природе являются категориальными. В их текущем виде они не распознаются как категориальные, поэтому преобразуем их обратно в категориальные данные и посмотрим, как CatBoost справится с ними.
Подготовим целевую переменную.
Код Python
new_df = df.copy() # Create a copy of the original DataFrame # we Shift the 'Close' and 'open' columns by one row to ge the future close and open price values, then we add these new columns to the dataset new_df["target_close"] = df["Close"].shift(-1) new_df["target_open"] = df["Open"].shift(-1) new_df = new_df.dropna() # Drop the rows with NaN values resulting from the shift operation open_values = new_df["target_open"] close_values = new_df["target_close"] target = [] for i in range(len(open_values)): if close_values[i] > open_values[i]: target.append(1) # buy signal else: target.append(0) # sell signal new_df["signal"] = target # we create the signal column and add the target variable we just prepared print(new_df.shape) new_df.head()
Вывод
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | target_close | target_open | signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 | 1.09399 | 1.09678 | 0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 | 1.09805 | 1.09701 | 1 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 | 1.09742 | 1.09639 | 1 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 | 1.09757 | 1.10302 | 0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 | 1.10297 | 1.10431 | 0 |
Итак, мы разобрались с сигналами, которые можно спрогнозировать. Теперь давайте разделим данные на обучающую и тестовую выборки.
X = new_df.drop(columns = ["target_close", "target_open", "signal"]) # we drop future values y = new_df["signal"] # trading signals are the target variables we wanna predict X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
Определим список категориальных признаков в нашем наборе данных.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"]
Затем мы можем использовать этот список для преобразования категориальных признаков в формат string, которым обычно бывают представлены категориальные переменные.
X_train[categorical_features] = X_train[categorical_features].astype(str) X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Вывод
<class 'pandas.core.frame.DataFrame'> Index: 6999 entries, 9068 to 7270 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Open 6999 non-null float64 1 High 6999 non-null float64 2 Low 6999 non-null float64 3 Close 6999 non-null float64 4 Day 6999 non-null object 5 DayofWeek 6999 non-null object 6 DayofYear 6999 non-null object 7 Month 6999 non-null object dtypes: float64(4), object(4) memory usage: 492.1+ KB
Мы получили категориальные переменные с типом данных object — e нас это string. Если попытаться применить эти данные к другой модели машинного обучения (не CatBoost), мы получим ошибки, поскольку тип данных object не поддерживается в типичных обучающих выборках для машинного обучения.
Обучение модели CatBoost
Прежде чем вызывать метод обучения модели CatBoost fit, давайте разберемся с параметрами модели.
Параметр | Описание |
|---|---|
Iterations | Количество итераций построения решающих деревьев. Большее количество итераций обычно приводит к улучшению производительности, однако также увеличивает риск переобучения. |
learning_rate | Этот параметр контролирует вклад каждого дерева в итоговое предсказание. Меньшее значение learning_rate требует большего числа итераций для сходимости деревьев, но зачастую приводит к более качественным моделям. |
depth | Максимальная глубина деревьев. Более глубокие деревья способны улавливать более сложные закономерности в данных, но часто могут приводить к переобучению. |
cat_features | Список категориальных индексов. Хотя модель CatBoost способна самостоятельно определять категориальные признаки, хорошей практикой считается явное указание модели, какие признаки являются категориальными. Это помогает модели правильно интерпретировать категориальные данные с человеческой точки зрения, так как автоматические методы обнаружения категориальных переменных могут иногда ошибаться. |
l2_leaf_reg | Коэффициент L2-регуляризации. Позволяет бороться с переобучением, накладывая штраф на большие веса листьев. |
border_count | Количество разделений для каждого категориального признака. Чем выше это число, тем выше качество модели, но при этом увеличивается время вычислений. |
eval_metric | Метрика оценки, которая будет использоваться в процессе обучения. Позволяет эффективно отслеживать производительность модели. |
early_stopping_rounds | При наличии валидационных данных обучение остановится, если в течение указанного числа итераций не будет улучшения точности модели. Параметр помогает снизить риск переобучения и может существенно сократить время обучения. |
Определим словарь для этих параметров.
params = dict( iterations=100, learning_rate=0.01, depth=10, l2_leaf_reg=5, bagging_temperature=1, border_count=64, # Number of splits for categorical features eval_metric='Logloss', random_seed=42, # Seed for reproducibility verbose=1, # Verbosity level # early_stopping_rounds=10 # Early stopping for validation )
Наконец, мы можем создать модель CatBoost внутри пайплайна Sklearn, а затем вызвать метод fit для обучения. В параметрах методу передадим данные для валидации и список категориальных признаков.
pipe = Pipeline([ ("catboost", CatBoostClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test), catboost__cat_features=categorical_features)
Результаты
90: learn: 0.6880592 test: 0.6936112 best: 0.6931239 (3) total: 523ms remaining: 51.7ms 91: learn: 0.6880397 test: 0.6936100 best: 0.6931239 (3) total: 529ms remaining: 46ms 92: learn: 0.6880350 test: 0.6936051 best: 0.6931239 (3) total: 532ms remaining: 40ms 93: learn: 0.6880280 test: 0.6936103 best: 0.6931239 (3) total: 535ms remaining: 34.1ms 94: learn: 0.6879448 test: 0.6936110 best: 0.6931239 (3) total: 541ms remaining: 28.5ms 95: learn: 0.6878328 test: 0.6936387 best: 0.6931239 (3) total: 547ms remaining: 22.8ms 96: learn: 0.6877888 test: 0.6936473 best: 0.6931239 (3) total: 553ms remaining: 17.1ms 97: learn: 0.6877408 test: 0.6936508 best: 0.6931239 (3) total: 559ms remaining: 11.4ms 98: learn: 0.6876611 test: 0.6936708 best: 0.6931239 (3) total: 565ms remaining: 5.71ms 99: learn: 0.6876230 test: 0.6936898 best: 0.6931239 (3) total: 571ms remaining: 0us bestTest = 0.6931239281 bestIteration = 3 Shrink model to first 4 iterations.
Оценка модели
Для оценки эффективности модели будем использовать метрики Sklearn.
# Make predicitons on training and testing sets y_train_pred = pipe.predict(X_train) y_test_pred = pipe.predict(X_test) # Training set evaluation print("Training Set Classification Report:") print(classification_report(y_train, y_train_pred)) # Testing set evaluation print("\nTesting Set Classification Report:") print(classification_report(y_test, y_test_pred))
Результаты
Training Set Classification Report: precision recall f1-score support 0 0.55 0.44 0.49 3483 1 0.54 0.64 0.58 3516 accuracy 0.54 6999 macro avg 0.54 0.54 0.54 6999 weighted avg 0.54 0.54 0.54 6999 Testing Set Classification Report: precision recall f1-score support 0 0.53 0.41 0.46 1547 1 0.49 0.61 0.54 1453 accuracy 0.51 3000 macro avg 0.51 0.51 0.50 3000 weighted avg 0.51 0.51 0.50 3000
В результате мы получили модель со средней производительностью. Я заметил, что после удаления списка категориальных признаков точность модели на обучающем наборе данных увеличилась до 60%, но на тестовом наборе осталась на прежнем уровне.
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Вывод
91: learn: 0.6844878 test: 0.6933503 best: 0.6930500 (30) total: 395ms remaining: 34.3ms 92: learn: 0.6844035 test: 0.6933539 best: 0.6930500 (30) total: 399ms remaining: 30ms 93: learn: 0.6843241 test: 0.6933791 best: 0.6930500 (30) total: 404ms remaining: 25.8ms 94: learn: 0.6842277 test: 0.6933732 best: 0.6930500 (30) total: 408ms remaining: 21.5ms 95: learn: 0.6841427 test: 0.6933758 best: 0.6930500 (30) total: 412ms remaining: 17.2ms 96: learn: 0.6840422 test: 0.6933796 best: 0.6930500 (30) total: 416ms remaining: 12.9ms 97: learn: 0.6839896 test: 0.6933825 best: 0.6930500 (30) total: 420ms remaining: 8.58ms 98: learn: 0.6839040 test: 0.6934062 best: 0.6930500 (30) total: 425ms remaining: 4.29ms 99: learn: 0.6838397 test: 0.6934259 best: 0.6930500 (30) total: 429ms remaining: 0us bestTest = 0.6930499562 bestIteration = 30 Shrink model to first 31 iterations.
Training Set Classification Report: precision recall f1-score support 0 0.61 0.53 0.57 3483 1 0.59 0.67 0.63 3516 accuracy 0.60 6999 macro avg 0.60 0.60 0.60 6999 weighted avg 0.60 0.60 0.60 6999
Чтобы более подробно разобраться в этой модели, построим график значимости признаков.
# Extract the trained CatBoostClassifier from the pipeline
catboost_model = pipe.named_steps['catboost']
# Get feature importances
feature_importances = catboost_model.get_feature_importance()
feature_im_df = pd.DataFrame({
"feature": X.columns,
"importance": feature_importances
})
feature_im_df = feature_im_df.sort_values(by="importance", ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(data = feature_im_df, x='importance', y='feature', palette="viridis")
plt.title("CatBoost feature importance")
plt.xlabel("Importance")
plt.ylabel("feature")
plt.show()Вывод
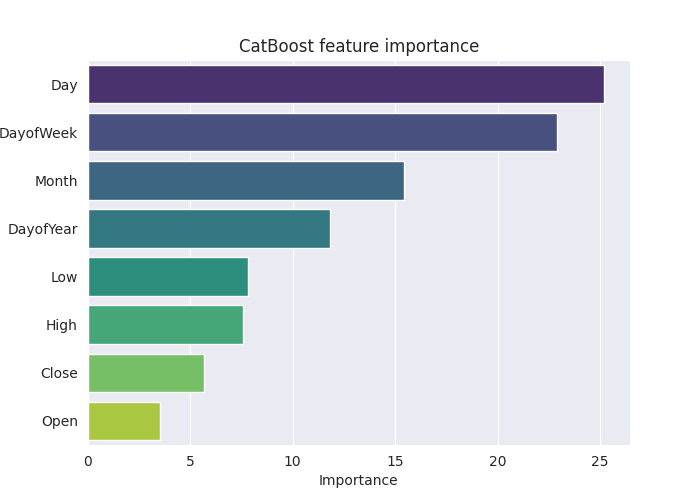
Приведенный выше график feature importance наглядно демонстрирует, как модель принимала решения. Похоже, что модель CatBoost посчитала категориальные признаки более значимыми для финального прогноза, чем непрерывные признаки.
Сохранение модели CatBoost в ONNX
Чтобы использовать модель в платформе MetaTrader 5, нужно сохранить ее в формате ONNX. Однако сохранение модели CatBoost может быть немного сложнее, чем в случае с Sklearn или Keras, которые предлагают более простые методы конвертации.
Но все вполне реализуемо, если следовать их инструкциям из официальной документации. Не пришлось особо вникать в детали кода.
from onnx.helper import get_attribute_value import onnxruntime as rt from skl2onnx import convert_sklearn, update_registered_converter from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost import CatBoostClassifier from catboost.utils import convert_to_onnx_object def skl2onnx_parser_castboost_classifier(scope, model, inputs, custom_parsers=None): options = scope.get_options(model, dict(zipmap=True)) no_zipmap = isinstance(options["zipmap"], bool) and not options["zipmap"] alias = _get_sklearn_operator_name(type(model)) this_operator = scope.declare_local_operator(alias, model) this_operator.inputs = inputs label_variable = scope.declare_local_variable("label", Int64TensorType()) prob_dtype = guess_tensor_type(inputs[0].type) probability_tensor_variable = scope.declare_local_variable( "probabilities", prob_dtype ) this_operator.outputs.append(label_variable) this_operator.outputs.append(probability_tensor_variable) probability_tensor = this_operator.outputs if no_zipmap: return probability_tensor return _apply_zipmap( options["zipmap"], scope, model, inputs[0].type, probability_tensor ) def skl2onnx_convert_catboost(scope, operator, container): """ CatBoost returns an ONNX graph with a single node. This function adds it to the main graph. """ onx = convert_to_onnx_object(operator.raw_operator) opsets = {d.domain: d.version for d in onx.opset_import} if "" in opsets and opsets[""] >= container.target_opset: raise RuntimeError("CatBoost uses an opset more recent than the target one.") if len(onx.graph.initializer) > 0 or len(onx.graph.sparse_initializer) > 0: raise NotImplementedError( "CatBoost returns a model initializers. This option is not implemented yet." ) if ( len(onx.graph.node) not in (1, 2) or not onx.graph.node[0].op_type.startswith("TreeEnsemble") or (len(onx.graph.node) == 2 and onx.graph.node[1].op_type != "ZipMap") ): types = ", ".join(map(lambda n: n.op_type, onx.graph.node)) raise NotImplementedError( f"CatBoost returns {len(onx.graph.node)} != 1 (types={types}). " f"This option is not implemented yet." ) node = onx.graph.node[0] atts = {} for att in node.attribute: atts[att.name] = get_attribute_value(att) container.add_node( node.op_type, [operator.inputs[0].full_name], [operator.outputs[0].full_name, operator.outputs[1].full_name], op_domain=node.domain, op_version=opsets.get(node.domain, None), **atts, ) update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, skl2onnx_convert_catboost, parser=skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, )
Ниже показан финальный код для конвертации модели и сохранения ее в файле .onnx.
model_onnx = convert_sklearn( pipe, "pipeline_catboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("CatBoost.EURUSD.OHLC.D1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
При визуализации в Netron структура модели выглядит так же, как у XGBoost и LightGBM.

Это логично, так как CatBoost тоже основан на деревьях решений с градиентным бустингом. В своей основе они имеют схожие структуры.
Когда я попытался конвертировать модель CatBoost, встроенную в пайплайн, в формат ONNX с категориальными признаками, я получил ошибку:
CatBoostError: catboost/libs/model/model_export/model_exporter.cpp:96: ONNX-ML format export does yet not support categorical features
Категориальные признаки должны быть представлены в формате float64 (double), как и в изначально собранных данных в MetaTrader 5. Это решило проблему. Можно использовать модель в MQL5 и не переживать, что double или float перепутаются с целыми числами.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"] # Remove these two lines of code operations # X_train[categorical_features] = X_train[categorical_features].astype(str) # X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Несмотря на это изменение, точность модели CatBoost осталась на том же уровне, так как она способна работать с наборами данных различной природы.
Создание торгового робота с CatBoost
Начнем с внедрения модели ONNX в нашего советника в виде ресурса.
Код MQL5
#resource "\\Files\\CatBoost.EURUSD.OHLC.D1.onnx" as uchar catboost_onnx[]
We import the library for loading the CatBoost model.
#include <MALE5\Gradient Boosted Decision Trees(GBDTs)\CatBoost\CatBoost.mqh>
CCatBoost cat_boost;
Нужно собрать данные таким же образом, как мы собирали обучающие данные. Делается это внутри функции OnTick.
void OnTick() { ... ... ... if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar ... ... ... }
После этого мы можем получить сигнал и вектор вероятности. Определять будем два сигнала: медвежий класса 0 и бычий класса 1.
vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal);
Осталось реализовать в советнике торговую стратегию на основе прогнозов, полученных с помощью модели.
Будем использовать простейшую стратегию: когда модель предсказывает бычий сигнал, открываем сделку на покупку и, если при этом есть открытая сделка на продажу, закрываем ее. При медвежьем сигнале совершаем противоположные сделки — продаем, закрываем покупку.
void OnTick() { //--- if (!NewBar()) return; //--- Trade at the opening of each bar if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(min_lot, Symbol(), ticks.ask, 0, 0); //Open a buy trade ClosePosition(POSITION_TYPE_SELL); //close the opposite trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(min_lot, Symbol(), ticks.bid, 0, 0); //open a sell trade ClosePosition(POSITION_TYPE_BUY); //close the opposite trade } }
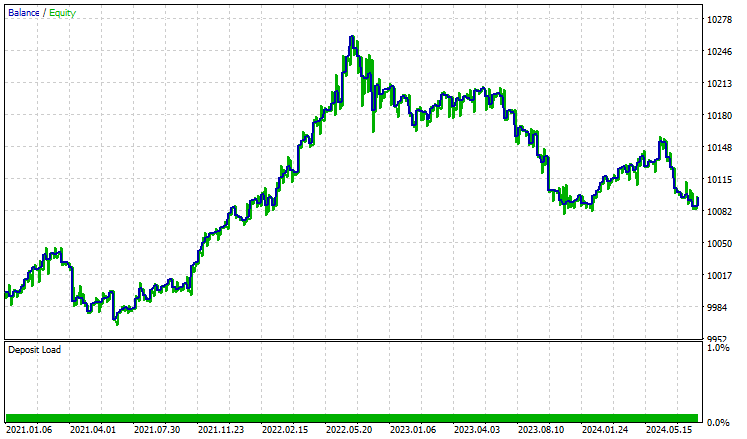
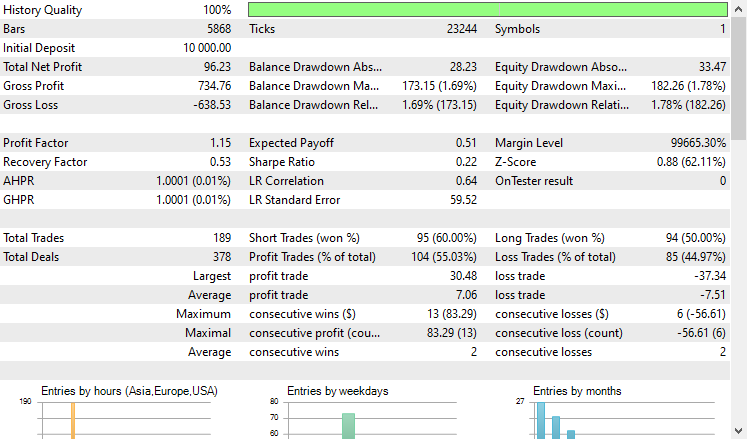
Тестировали стратегию в тестере на периоде с 01.01.2021 по 08.10.2024 на 4-часовом таймфрейме. Тестирование проводилось только по ценам открытия. Ниже представлен результат.
 '
'
Советник показал достойные результаты — 55% прибыльных сделок, что принесло общий чистый доход в размере $96 USD. Неплохой результат для простой выборки данных, простой модели и минимального объема сделок.
Заключительные мысли
CatBoost и другие модели градиентного бустинга на решающих деревьях хорошо подходят для работы в условиях ограниченных вычислительных ресурсов. Также это отличный вариант, если вам нужна модель, которая "просто работает". Или если вы не хотите заниматься не очень интересными аспектами вроде подбора признаков и настройки моделей, с которыми часто приходится сталкиваться при работе с другими методами машинного обучения.
При этом, несмотря на простоту и низкий порог входа, эти модели остаются одними из наиболее эффективных инструментов, применимых для множества реальных задач.
С наилучшими пожеланиями.
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозитории на GitHub.
Таблица вложений
Наименование файла | Тип файла | Описание и использование |
|---|---|---|
Experts\CatBoost EA.mq5 | Expert | Торговый робот для загрузки модели CatBoost в ONNX и тестирования полученной торговой стратегии в MetaTrader 5. |
Include\CatBoost.mqh | Include-файл |
|
Files\ CatBoost.EURUSD.OHLC.D1.onnx | Модель ONNX | Обученная модель CatBoost в формате ONNX. |
| Scripts\CollectData.mq5 | MQL5-скрипт | Скрипт для сбора обучающих данных. |
Jupyter Notebook\CatBoost-4-trading.ipynb | Python/Jupyter notebook | Блокнот содержит все коды Python, обсуждаемые в этой статье. |
Источники и ссылки
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16017
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
а еще есть проблема экспорта модели классификатора в ONNX
Note
The label is inferred incorrectly for binary classification. This is a known bug in the onnxruntime implementation. Ignore the value of this parameter in case of binary classification.
У меня есть небольшой вопрос или опасение, которым я надеюсь поделиться.
Я полагаю, что основная проблема может быть связана с тем, что описано здесь:
https://catboost.ai/docs/en/concepts/apply-onnx-ml
Специфика:
В настоящее время поддерживаются только модели, обученные на наборах данных без категориальных признаков.
В Jupyter Notebook catboost-4-trading.ipynb, который я скачал, код настройки конвейера написан так:
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Похоже, что параметр"catboost__cat_features=categorical_features" опущен, поэтому модель, возможно, была обучена без указания категориальных признаков.
Это может объяснить, почему модель может быть сохранена как ONNX без каких-либо проблем.
Если дело обстоит именно так, то, возможно, можно напрямую использовать родной метод CatBoost"save_model" , например, так:
model = pipe.named_steps['catboost']
model_filename = "CatBoost.EURUSD.OHLC.D1.onnx"
model.save_model(model_filename, format='onnx')
Надеюсь, это наблюдение окажется полезным.