
ニューラルネットワークが簡単に(第13回): Batch Normalization

内容
はじめに
前回の記事では、ニューラルネットワークの収束を高めることを目的とした手法の考察を開始し、機能の共適応を減らすために使用されるドロップアウト手法を詳しく説明しました。このトピックを続けて、正規化の手法を理解しましょう。
1. 正規化の理論的前提条件
ニューラルネットワークアプリケーションの実践では、データの正規化に対するさまざまなアプローチが使用されています。ただし、これらはすべて、訓練サンプルデータとニューラルネットワークの隠れ層の出力を特定の範囲内に保ち、分散や中央値などのサンプルの特定の統計的特性を維持することを目的としています。ネットワークニューロンは線形変換を使用して訓練の過程でサンプルを逆勾配にシフトするため、これは重要です。
2つの隠れ層を持つ完全に接続されたパーセプトロンを考えてみましょう。フィードフォワードパス中に、各層は次の層の訓練サンプルとして機能する特定のデータセットを生成します。出力層の結果は、参照データと比較されます。次に、フィードバックパス中に、エラー勾配が出力層から隠れ層を介して初期データに向かって伝播されます。各ニューロンでエラー勾配を受け取ったら、重み係数を更新し、最後のフィードフォワードパスの訓練サンプルのニューラルネットワークを調整します。ここで競合が発生します。2番目の隠れ層(下図のH2)は、最初の隠れ層(図のH1)の出力のデータサンプルに調整されますが、データ配列は最初の隠れ層のパラメータを変更することによってすでに 変更されています。つまり、2番目の隠れ層を、存在しなくなったデータサンプルに合わせて調整しているのです。同様の状況は、すでに変更された2番目の隠れ層出力に合わせて調整される出力層でも発生します。1番目と2番目の隠れ層の間の歪みを考慮すると、エラーのスケールはさらに大きくなります。ニューラルネットワークが深いほど、この効果は強くなります。この現象は、内部共変量シフトと呼ばれます。
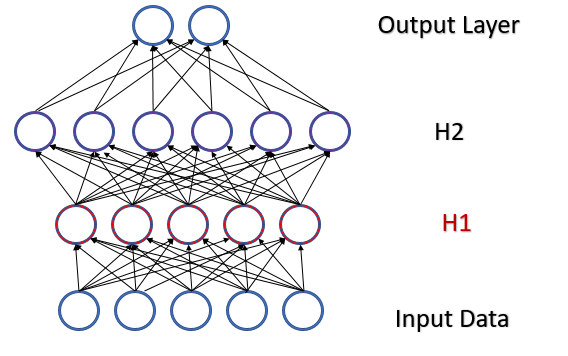
従来のニューラルネットワークは、学習率を下げることでこの問題を部分的に解決します。重みがわずかに変化しても、ニューラル層の出力でのサンプル分布は大幅には変化しません。しかし、このアプローチでは、ニューラルネットワーク層の数の増加に伴って発生するスケーリングの問題が解決されず、学習速度も低下します。学習率の低さのもう1つの問題は、プロセスが極小値でスタックする可能性があることです。これについては、第6部ですでに説明しました。
2015年2月、Sergey LoffeとChristian Szegedyは、内部共分散シフトの問題の解決策としてBatch Normalizationを提案しました[第13部]。この手法のアイデアは、サンプル(バッチ)の中央値をゼロにシフトして特定の時間間隔で個々のニューロンを正規化し、サンプルの分散を1にすることです。
正規化アルゴリズムは次のとおりです。最初に、データバッチの平均値が計算されます。
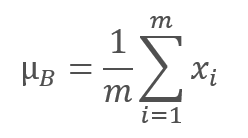
ここで、mはバッチサイズです。
次に、元のバッチの分散が計算されます。
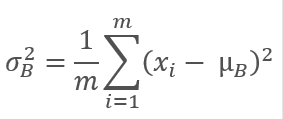
バッチデータは、バッチの平均がゼロになり、分散が1になるように正規化されます。
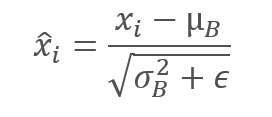
ゼロによる除算を避けるために、分母のバッチ分散に小さな正の数である定数ϵが追加されることに注意してください。
ただし、このような正規化は元のデータの影響を歪める可能性があることが判明しました。したがって、手法の作成者は、スケーリングとシフトというもう1つのステップを追加しました。2つの変数γとβが導入され、勾配降下法によってニューラルネットワークと一緒に訓練されます。
![]()
この手法を適用すると、訓練の各ステップで同じ分布のデータバッチを取得できるようになります。これにより、ニューラルネットワークの訓練がより安定し、学習率が向上します。一般に、この手法は、ニューラルネットワークの訓練に費やす時間を削減しながら質を向上させるのに役立ちます。
ただし、これにより、追加率を保存するコストが増加します。また、平均値と分散を計算するために、バッチサイズ全体の各ニューロンの履歴データを保存する必要があります。ここでは、指数平均の適用を確認できます。次の図は、100個の要素の移動平均と移動分散を、同じ100個の要素の指数移動平均と指数移動分散と比較したグラフを示しています。グラフは、-1.0から1.0の範囲の1000個のランダム要素に対して作成されています。
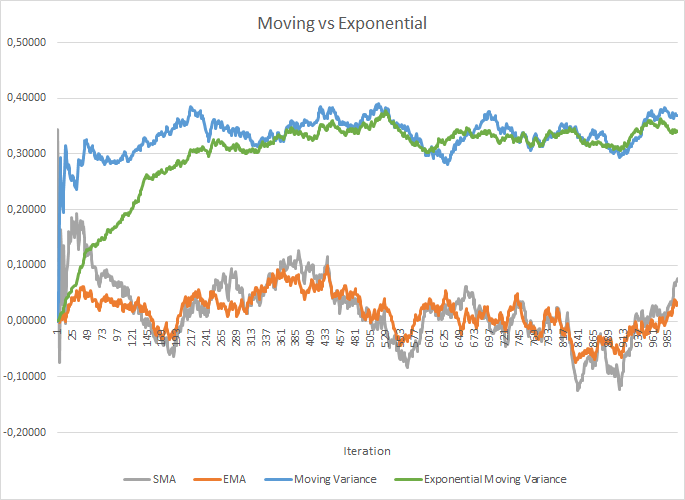
このグラフでは、移動平均と指数移動平均は120〜130回の反復後に互いに近づき、偏差は最小になります(無視できるように)。さらに、指数移動平均グラフはより滑らかになります。EMAは、関数の以前の値とシーケンスの現在の要素を知ることによって計算できます。指数移動平均の式を見てみましょう。
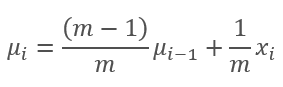 ,
,
ここで
- mはバッチサイズです。
- iは反復です。
移動分散グラフと指数移動分散グラフを近づけるには、もう少し反復(310〜320)が必要でしたが、全体像は似ています。分散の場合、指数アルゴリズムを使用すると、メモリが節約されるだけでなく、計算の数も大幅に削減されます。これは、移動分散の場合、バッチ全体の平均からの偏差が計算されるためです。
手法の作成者が実施した実験では、Batch Normalizationメソッドの使用が正則化としても機能することが示されています。これにより、以前に検討されたドロップアウトを含む、他の正則化方法の必要性が減少します。さらに、後の研究では、ドロップアウトとBatch Normalizationを組み合わせて使用すると、ニューラルネットワークの学習結果に悪影響があることが示されています。
提案された正規化アルゴリズムは、最新のニューラルネットワークアーキテクチャのさまざまなバリエーションで見つけることができます。著者らは、非線形性(活性化式)の直前にBatch Normalizationを使用することを提案しています。2016年7月に発表された層正規化手法は、このアルゴリズムのバリエーションの1つと見なすことができます。この手法については、attentionメカニズムを研究する際にすでに検討しました(第9部)。
2. 実装
2.1モデルでの新しいクラスの作成
理論的な側面を検討したので、ライブラリに実装します。アルゴリズムを実装するために、新しいクラスCNeuronBatchNormOCLを作成しましょう。
class CNeuronBatchNormOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL *PrevLayer; ///< Pointer to the object of the previous layer uint iBatchSize; ///< Batch size CBufferDouble *BatchOptions; ///< Container of method parameters ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::BatchFeedForward().@param NeuronOCL Pointer to previous layer. ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateBatchOptionsMomentum() or ::UpdateBatchOptionsAdam() in depends on optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previous layer. public: /** Constructor */CNeuronBatchNormOCL(void); /** Destructor */~CNeuronBatchNormOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, uint batchSize, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. //--- virtual int getOutputIndex(void) { return (iBatchSize>1 ? Output.GetIndex() : PrevLayer.getOutputIndex()); } ///< Get index of output buffer @return Index virtual int getGradientIndex(void) { return (iBatchSize>1 ? Gradient.GetIndex() : PrevLayer.getGradientIndex()); } ///< Get index of gradient buffer @return Index //--- virtual int getOutputVal(double &values[]) { return (iBatchSize>1 ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return (iBatchSize>1 ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return (iBatchSize>1 ? Gradient.GetData(values) : PrevLayer.getGradient(values)); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual CBufferDouble *getOutput(void) { return (iBatchSize>1 ? Output : PrevLayer.getOutput()); } ///< Get pointer of output buffer @return Pointer to object virtual CBufferDouble *getGradient(void) { return (iBatchSize>1 ? Gradient : PrevLayer.getGradient()); } ///< Get pointer of gradient buffer @return Pointer to object //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradientBatch(). @param NeuronOCL Pointer to next layer. //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronBatchNormOCL; }///< Identificator of class.@return Type of class };
新しいクラスは、CNeuronBaseOCL基本クラスから継承されます。CNeuronDropoutOCLクラスと同様に、PrevLayer変数を追加します。前の記事で示したデータバッファの置換方法は、「2」未満のバッチサイズを指定するときに適用され、iBatchSize変数に保存されます。
Batch Normalizationアルゴリズムでは、正規化された層のニューロンごとに個別のいくつかのパラメータを保存する必要があります。個々のパラメータごとに多くの個別のバッファを生成しないようにするために、次の構造を持つパラメータの単一のBatchOptionsバッファを作成します。

提示された構造から、パラメータバッファのサイズは、適用されたパラメータ最適化手法に依存するため、クラス初期化メソッドで作成されることがわかります。
クラスメソッドのセットはすでに標準なものです。それらを見てみましょう。クラスコンストラクタで、オブジェクトへのポインタをリセットし、バッチサイズを1に設定します。これにより、層が初期化されるまで、ネットワーク操作から実質的に除外されます。
CNeuronBatchNormOCL::CNeuronBatchNormOCL(void) : iBatchSize(1) { PrevLayer=NULL; BatchOptions=NULL; }
クラスデストラクタで、パラメータバッファのオブジェクトを削除し、前の層へのポインタをゼロに設定します。前の層のオブジェクトを削除するのではなく、ポインタをゼロにするだけであることに注意してください。オブジェクトは、作成された場所から削除されます。
CNeuronBatchNormOCL::~CNeuronBatchNormOCL(void) { if(CheckPointer(PrevLayer)!=POINTER_INVALID) PrevLayer=NULL; if(CheckPointer(BatchOptions)!=POINTER_INVALID) delete BatchOptions; }
ここで、クラス初期化メソッドCNeuronBatchNormOCL::Initについて考えてみましょう。パラメータで、次の層のニューロンの数、ニューロンを識別するためのインデックス、OpenCLオブジェクトへのポインタ、正規化層のニューロンの数、バッチサイズ、およびパラメータ最適化方法をクラスに渡します。
メソッドの開始時に、親クラスの関連するメソッドを呼び出します。このメソッドでは、基本変数とデータバッファが初期化されます。次に、バッチサイズを保存し、層の活性関数をNoneに設定します。
活性化関数にご注意ください。この機能の使用は、ニューラルネットワークのアーキテクチャによって異なります。手法の作成者が推奨するように、ニューラルネットワークアーキテクチャで活性化関数の前に正規化を含める必要がある場合は、前の層で活性化関数を無効にし、正規化層で必要な関数を指定する必要があります。技術的には、活性化関数は、クラスインスタンスを初期化した後、親クラスのSetActivationFunctionメソッドを呼び出すことによって指定されます。ネットワークアーキテクチャに従って活性化関数の後に正規化を使用する必要がある場合は、活性化メソッドを前の層で指定する必要があり、正規化層には活性化関数がありません。
bool CNeuronBatchNormOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint numNeurons,uint batchSize,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,numNeurons,optimization_type)) return false; activation=None; iBatchSize=batchSize; //--- if(CheckPointer(BatchOptions)!=POINTER_INVALID) delete BatchOptions; int count=(int)numNeurons*(optimization_type==SGD ? 7 : 9); BatchOptions=new CBufferDouble(); if(CheckPointer(BatchOptions)==POINTER_INVALID || !BatchOptions.BufferInit(count,0)) return false; //--- return true; }
メソッドの最後に、パラメータのバッファを作成します。上記のように、バッファサイズは層内のニューロンの数とパラメータの最適化方法に依存します。SGDを使用する場合、ニューロンごとに7つの要素を予約します。 Adam法で最適化する場合、ニューロンごとに9つのバッファ要素が必要です。すべてのバッファが正常に作成されたら、trueを指定してメソッドを終了します。
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
2.2. フィードフォワード
次のステップとして、フィードフォワードパスについて考えてみましょう。ダイレクトパスBatchFeedForwardを検討することから始めましょう。カーネルアルゴリズムは、個別のニューロンごとに起動されます。
カーネルは、初期データ、パラメータのバッファ、および結果を書き込むためのバッファの3つのバッファへのポインタをパラメータで受け取ります。さらに、パラメータにバッチサイズ、最適化方法、ニューロン活性化アルゴリズムを渡します。
カーネルの開始時に、正規化ウィンドウの指定されたサイズを確認します。1つのニューロンに対して正規化を実行する場合は、それ以上の操作を実行せずにメソッドを終了します。
検証が成功すると、入力データテンソル内の正規化された値の位置を示すストリーム識別子が取得されます。識別子に基づいて、正規化パラメータのテンソルの最初のパラメータのシフトを決定できます。このステップで、最適化方法はパラメータバッファの構造を提案します。
次に、このステップで指数平均と分散を計算します。このデータに基づいて、要素の正規化された値を計算します。
Batch Normalizationのアルゴリズムの次のステップは、シフトとスケーリングです。以前、初期化中にパラメータバッファをゼロで埋めたため、最初のステップでこの操作を「純粋な形式で」実行すると、「0」が返されます。これを回避するには、γパラメータの現在の値を確認し、「0」に等しい場合は、その値を「1」に変更します。シフトをゼロのままにします。この形式でシフトとスケーリングを実行します。
__kernel void BatchFeedForward(__global double *inputs, __global double *options, __global double *output, int batch int optimization, int activation) { if(batch<=1) return; int n=get_global_id(0); int shift=n*(optimization==0 ? 7 : 9); //--- for(int i=0;i<(optimization==0 ? 7 : 9);i++) if(isnan(options[shift+i])) options[shift+i]=0; //--- double mean=(options[shift]*((double)batch-1)+inputs[n])/((double)batch); double delt=inputs[n]-mean; double variance=options[shift+1]*((double)batch-1.0)+pow(delt,2); if(options[shift+1]>0) variance/=(double)batch; double nx=delt/sqrt(variance+1e-6); //--- if(options[shift+3]==0) options[shift+3]=1; //--- double res=options[shift+3]*nx+options[shift+4]; switch(activation) { case 0: res=tanh(clamp(res,-20.0,20.0)); break; case 1: res=1/(1+exp(-clamp(res,-20.0,20.0))); break; case 2: if(res<0) res*=0.01; break; default: break; } //--- options[shift]=mean; options[shift+1]=variance; options[shift+2]=nx; output[n]=res; }
正規化された値を取得したら、この層で活性化関数を実行して必要なアクションを実行する必要があるかどうかを確認しましょう。
ここで、新しい値をデータバッファに保存し、カーネルを終了します。
BatchFeedForwardカーネル構築アルゴリズムはかなり単純なので、メインプログラムからカーネルを呼び出すためのメソッドの作成に進むことができます。この機能はCNeuronBatchNormOCL::feedForwardメソッドによって実装されます。 メソッドアルゴリズムは、他のクラスの関連するメソッドに似ています。このメソッドは、前のニューラルネットワーク層へのポインタをパラメータで受け取ります。
メソッドの開始時に、受信したポインタとOpenCLオブジェクトへのポインタの有効性を確認します(これはOpenCLプログラムを操作するための標準ライブラリクラスのレプリカであることを覚えているかもしれません)。
次のステップで、ニューラルネットワークの前の層へのポインタを保存し、バッチサイズを確認します。正規化ウィンドウのサイズが「1」を超えない場合は、前の層の活性化関数のタイプをコピーして、trueの結果でメソッドを終了します。このようにして、バッファを置き換えるためのデータを提供し、アルゴリズムの不要な反復を除外します。
bool CNeuronBatchNormOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- PrevLayer=NeuronOCL; if(iBatchSize<=1) { activation=(ENUM_ACTIVATION)NeuronOCL.Activation(); return true; } //--- if(CheckPointer(BatchOptions)==POINTER_INVALID) { int count=Neurons()*(optimization==SGD ? 7 : 9); BatchOptions=new CBufferDouble(); if(!BatchOptions.BufferInit(count,0)) return false; } if(!BatchOptions.BufferCreate(OpenCL)) return false; //--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_BatchFeedForward,def_k_bff_inputs,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_BatchFeedForward,def_k_bff_options,BatchOptions.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_BatchFeedForward,def_k_bff_output,Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_BatchFeedForward,def_k_bff_batch,iBatchSize)) return false; if(!OpenCL.SetArgument(def_k_BatchFeedForward,def_k_bff_optimization,(int)optimization)) return false; if(!OpenCL.SetArgument(def_k_BatchFeedForward,def_k_bff_activation,(int)activation)) return false; ResetLastError(); //--- if(!OpenCL.Execute(def_k_BatchFeedForward,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Batch Feed Forward: %d",GetLastError()); return false; } if(!Output.BufferRead() || !BatchOptions.BufferRead()) return false; BatchOptions.BufferFree(); //--- return true; }
すべてのチェックの後で、ダイレクトパスカーネルの起動に到達した場合は、起動するための初期データを準備する必要があります。まず、正規化アルゴリズムのパラメータバッファへのポインタの有効性を確認します。必要に応じて、新しいバッファを作成して初期化します。次に、ビデオカードメモリにバッファを作成し、バッファの内容をロードします。
起動されたスレッドの数を層内のニューロンの数と同じに設定し、データバッファへのポインタを、必要なパラメータとともにカーネルに渡します。
準備作業の後、実行のためにカーネルを送信し、ビデオカードメモリから更新されたバッファデータを読み戻します。2つのバッファからのデータがビデオカードから受信されることに注意してください。アルゴリズム出力からの情報と、更新された平均、分散、および正規化された値を保存したパラメータバッファです。このデータは、以降の反復で使用されます。
アルゴリズムの完了後、ニューラルネットワークの次の層のバッファ用にメモリを解放するために、ビデオカードメモリからパラメータバッファを削除します。次にメソッドをtrueで終了します。
ライブラリのすべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
2.3. フィードバックワード
フィードバックパスも、エラーバックプロパゲーションと重みの更新の2つの段階で構成されます。通常の重みの代わりに、スケーリングおよびシフト関数のパラメータγとβを訓練します。
最急降下法機能から始めましょう。カーネルCalcHiddenGradientBatchを作成して、その機能を実装します。カーネルは、次の勾配層から受け取った正規化パラメータのテンソル、前の層の出力データ(最後のフィードフォワードパス中に取得)、および前の層の勾配のテンソルへのポインタをパラメータで受け取り、アルゴリズムの結果が書き込まれます。カーネルは、パラメータでバッチサイズ、活性化関数のタイプ、およびパラメータを最適化する方法も受け取ります。
ダイレクトパスと同様に、カーネルの開始時にバッチサイズを確認します。 1以下の場合は、他の反復を実行せずにカーネルを終了します。
次のステップは、スレッドのシリアル番号を取得し、パラメータテンソルのシフトを決定することです。これらのアクションは、フィードフォワードパスで前述したアクションと似ています。
__kernel void CalcHiddenGradientBatch(__global double *options, ///<[in] Options matrix m*(7 or 9), where m - Number of neurons in previous layer __global double *matrix_g, ///<[in] Tensor of gradients at current layer __global double *matrix_i, ///<[in] Tensor of previous layer output __global double *matrix_ig, ///<[out] Tensor of gradients at previous layer uint activation, ///< Activation type (#ENUM_ACTIVATION) int batch, ///< Batch size int optimization ///< Optimization type ) { if(batch<=1) return; //--- int n=get_global_id(0); int shift=n*(optimization==0 ? 7 : 9); //--- double inp=matrix_i[n]; double gnx=matrix_g[n]*options[shift+3]; double temp=1/sqrt(options[shift+1]+1e-6); double gmu=(-temp)*gnx; double gvar=(options[shift]*inp)/(2*pow(options[shift+1]+1.0e-6,3/2))*gnx; double gx=temp*gnx+gmu/batch+gvar*2*inp/batch*pow((double)(batch-1)/batch,2.0); //--- if(isnan(gx)) gx=0; switch(activation) { case 0: gx=clamp(gx+inp,-1.0,1.0)-inp; gx=gx*(1-pow(inp==1 || inp==-1 ? 0.99999999 : inp,2)); break; case 1: gx=clamp(gx+inp,0.0,1.0)-inp; gx=gx*(inp==0 || inp==1 ? 0.00000001 : (inp*(1-inp))); break; case 2: if(inp<0) gx*=0.01; break; default: break; } matrix_ig[n]=clamp(gx,-MAX_GRADIENT,MAX_GRADIENT); }
次に、アルゴリズムのすべての関数の勾配を順番に計算します。
そして最後に、前の層の活性化関数を介して勾配を伝播します。結果の値を前の層の勾配テンソルに保存します。
CalcHiddenGradientBatсhカーネルに続いて、メインプログラムからカーネルの実行を開始するCNeuronBatchNormOCL::calcInputGradientsメソッドについて考えてみましょう。他のクラスの関連するメソッドと同様に、このメソッドは、前のニューラルネットワーク層のオブジェクトへのポインタをパラメータで受け取ります。
メソッドの開始時に、受信したポインタとOpenCLオブジェクトへのポインタの有効性を確認します。その後、バッチサイズを確認してください。1以下の場合は、メソッドを終了します。メソッドから返される結果は、フィードフォワードパス中に保存された前のレイヤーへのポインタの有効性によって異なります。
アルゴリズムに沿ってさらに進む場合は、パラメータバッファの有効性を確認してください。エラーが発生した場合は、メソッドを終了して結果がfalseになります。
伝播された勾配は最後のフィードフォワードパスに属することに注意してください。そのため、最後の2つの制御ポイントで、フィードフォワードに参加しているオブジェクトをチェックしました。
bool CNeuronBatchNormOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(iBatchSize<=1) return (CheckPointer(PrevLayer)!=POINTER_INVALID); //--- if(CheckPointer(BatchOptions)==POINTER_INVALID || !BatchOptions.BufferCreate(OpenCL)) return false; //--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientBatch,def_k_bchg_matrix_i,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientBatch,def_k_bchg_options,BatchOptions.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientBatch,def_k_bchg_matrix_g,Gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientBatch,def_k_bchg_matrix_ig,NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgument(def_k_CalcHiddenGradientBatch,def_k_bchg_activation,NeuronOCL.Activation())) return false; if(!OpenCL.SetArgument(def_k_CalcHiddenGradientBatch,def_k_bchg_batch,iBatchSize)) return false; if(!OpenCL.SetArgument(def_k_CalcHiddenGradientBatch,def_k_bchg_optimization,(int)optimization)) return false; ResetLastError(); //--- if(!OpenCL.Execute(def_k_CalcHiddenGradientBatch,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Batch CalcHiddenGradient: %d",GetLastError()); return false; } if(!NeuronOCL.getGradient().BufferRead()) return false; BatchOptions.BufferFree(); //--- return true; }
フィードフォワードパスと同様に、起動されるカーネルスレッドの数は、レイヤー内のニューロンの数と同じになります。正規化パラメータバッファの内容をビデオカードメモリに送信し、必要なテンソルとパラメータポインタをカーネルに渡します。
上記のすべての操作を実行した後、カーネル実行を実行し、ビデオカードメモリから対応するバッファへの結果の勾配を計算します。
メソッドの最後に、ビデオカードメモリから正規化パラメータのテンソルを削除し、結果がtrueになるようにメソッドを終了します。
勾配を伝播した後、シフトとスケールのパラメータを更新します。これらの反復を実装するには、前述の最適化メソッドの数、UpdateBatchOptionsMomentumおよびUpdateBatchOptionsAdamに従って、2つのカーネルを作成します。
UpdateBatchOptionsMomentumメソッドから始めます。このメソッドは、正規化パラメータまたは勾配の2つのテンソルへのポインタをパラメータで受け取ります。また、最適化メソッド定数をメソッドパラメータ(学習率と運動量)に渡します。
カーネルの開始時に、スレッド番号を取得し、正規化パラメータのテンソルのシフトを決定します。
ソースデータを使用して、γとβのデルタを計算しましょう。この操作では、2要素の二重ベクトルを使用したベクトル計算を使用しました。この手法では、計算を並列化できます。
パラメータγ、βを調整し、結果を正規化パラメータテンソルの適切な要素に保存します。
__kernel void UpdateBatchOptionsMomentum(__global double *options, ///<[in,out] Options matrix m*7, where m - Number of neurons in previous layer __global double *matrix_g, ///<[in] Tensor of gradients at current layer double learning_rates, ///< Learning rates double momentum ///< Momentum multiplier ) { const int n=get_global_id(0); const int shift=n*7; double grad=matrix_g[n]; //--- double2 delta=learning_rates*grad*(double2)(options[shift+2],1) + momentum*(double2)(options[shift+5],options[shift+6]); if(!isnan(delta.s0) && !isnan(delta.s1)) { options[shift+5]=delta.s0; options[shift+3]=clamp(options[shift+3]+delta.s0,-MAX_WEIGHT,MAX_WEIGHT); options[shift+6]=delta.s1; options[shift+4]=clamp(options[shift+4]+delta.s1,-MAX_WEIGHT,MAX_WEIGHT); } };
UpdateBatchOptionsAdamカーネルは同様のスキームに従って構築されていますが、最適化方法のアルゴリズムに違いがあります。カーネルは、同じパラメータと勾配テンソルへのポインタをパラメータで受け取ります。また、最適化メソッドのパラメータを受け取ります。
カーネルの開始時に、スレッド番号を定義し、パラメータテンソルのシフトを決定します。
得られたデータに基づいて、1次モーメントと2次モーメントを計算します。ここで使用されるベクトル計算では、2つのパラメータのモーメントを同時に計算できます。
得られたモーメントに基づいて、デルタと新しいパラメータ値を計算します。計算結果は、正規化パラメータのテンソルの対応する要素に保存されます。
__kernel void UpdateBatchOptionsAdam(__global double *options, ///<[in,out] Options matrix m*9, where m - Number of neurons in previous layer __global double *matrix_g, ///<[in] Tensor of gradients at current layer const double l, ///< Learning rates const double b1, ///< First momentum multiplier const double b2 ///< Second momentum multiplier ) { const int n=get_global_id(0); const int shift=n*9; double grad=matrix_g[n]; //--- double2 mt=b1*(double2)(options[shift+5],options[shift+6])+(1-b1)*(double2)(grad*options[shift+2],grad); double2 vt=b2*(double2)(options[shift+5],options[shift+6])+(1-b2)*pow((double2)(grad*options[shift+2],grad),2); double2 delta=l*mt/sqrt(vt+1.0e-8); if(isnan(delta.s0) || isnan(delta.s1)) return; double2 weight=clamp((double2)(options[shift+3],options[shift+4])+delta,-MAX_WEIGHT,MAX_WEIGHT); //--- if(!isnan(weight.s0) && !isnan(weight.s1)) { options[shift+3]=weight.s0; options[shift+4]=weight.s1; options[shift+5]=mt.s0; options[shift+6]=mt.s1; options[shift+7]=vt.s0; options[shift+8]=vt.s1; } };
メインプログラムからカーネルを起動するには、CNeuronBatchNormOCL::updateInputWeightsメソッドを作成しましょう。このメソッドは、前のニューラルネットワーク層へのポインタをパラメータで受け取ります。実際には、このポインタはメソッドアルゴリズムでは使用されませんが、親クラスからのメソッドの継承のために残されます。
メソッドの開始時に、受信したポインタとOpenCLオブジェクトへのポインタの有効性を確認します。以前に検討したCNeuronBatchNormOCL::calcInputGradientsメソッドと同様に、バッチサイズとパラメータバッファの有効性を確認します。パラメータバッファの内容をビデオカードメモリにロードします。スレッドの数を層内のニューロンの数と同じに設定します。
さらに、アルゴリズムは、指定された最適化方法に応じて、2つのオプションに従うことができます。必要なカーネルの初期パラメータを渡し、その実行を再開します。
パラメータの最適化方法に関係なく、正規化パラメータバッファの更新された内容を計算し、ビデオカードメモリからバッファを削除します。
bool CNeuronBatchNormOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(iBatchSize<=1) return (CheckPointer(PrevLayer)!=POINTER_INVALID); //--- if(CheckPointer(BatchOptions)==POINTER_INVALID || !BatchOptions.BufferCreate(OpenCL)) return false; uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=Neurons(); //--- if(optimization==SGD) { if(!OpenCL.SetArgumentBuffer(def_k_UpdateBatchOptionsMomentum,def_k_buom_options,BatchOptions.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateBatchOptionsMomentum,def_k_buom_matrix_g,Gradient.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_UpdateBatchOptionsMomentum,def_k_buom_learning_rates,eta)) return false; if(!OpenCL.SetArgument(def_k_UpdateBatchOptionsMomentum,def_k_buom_momentum,alpha)) return false; ResetLastError(); //--- if(!OpenCL.Execute(def_k_UpdateBatchOptionsMomentum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel UpdateBatchOptionsMomentum %d",GetLastError()); return false; } } else { if(!OpenCL.SetArgumentBuffer(def_k_UpdateBatchOptionsAdam,def_k_buoa_options,BatchOptions.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateBatchOptionsAdam,def_k_buoa_matrix_g,Gradient.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_UpdateBatchOptionsAdam,def_k_buoa_l,lr)) return false; if(!OpenCL.SetArgument(def_k_UpdateBatchOptionsAdam,def_k_buoa_b1,b1)) return false; if(!OpenCL.SetArgument(def_k_UpdateBatchOptionsAdam,def_k_buoa_b2,b2)) return false; ResetLastError(); //--- if(!OpenCL.Execute(def_k_UpdateBatchOptionsAdam,1,global_work_offset,global_work_size)) { printf("Error of execution kernel UpdateBatchOptionsAdam %d",GetLastError()); return false; } } //--- if(!BatchOptions.BufferRead()) return false; BatchOptions.BufferFree(); //--- return true; }
操作が正常に完了したら、メソッドを終了して結果がtrueになります。
バッファ交換の方法は前回の記事で詳しく説明していたので、問題ないはずだと思います。これは、ファイルの操作(訓練されたニューラルネットワークの保存と読み込み)にも関係します。
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
2.4. ニューラルネットワーク基本クラスの変更
繰り返しますが、新しいクラスを作成したら、それをニューラルネットワークの一般的な構造に統合しましょう。まず、新しいクラスの識別子を作成しましょう。
#define defNeuronBatchNormOCL 0x7891 ///<Batchnorm neuron OpenCL \details Identified class #CNeuronBatchNormOCL
次に、新しいカーネルを操作するための定数マクロ置換を定義します。
#define def_k_BatchFeedForward 24 ///< Index of the kernel for Batch Normalization Feed Forward process (#CNeuronBathcNormOCL) #define def_k_bff_inputs 0 ///< Inputs data tensor #define def_k_bff_options 1 ///< Tensor of variables #define def_k_bff_output 2 ///< Tensor of output data #define def_k_bff_batch 3 ///< Batch size #define def_k_bff_optimization 4 ///< Optimization type #define def_k_bff_activation 5 ///< Activation type //--- #define def_k_CalcHiddenGradientBatch 25 ///< Index of the Kernel of the Batch neuron to transfer gradient to previous layer (#CNeuronBatchNormOCL) #define def_k_bchg_options 0 ///<[in] Options matrix m*(7 or 9), where m - Number of neurons in previous layer #define def_k_bchg_matrix_g 1 ///<[in] Tensor of gradients at current layer #define def_k_bchg_matrix_i 2 ///<[in] Tensor of previous layer output #define def_k_bchg_matrix_ig 3 ///<[out] Tensor of gradients at previous layer #define def_k_bchg_activation 4 ///< Activation type (#ENUM_ACTIVATION) #define def_k_bchg_batch 5 ///< Batch size #define def_k_bchg_optimization 6 ///< Optimization type //--- #define def_k_UpdateBatchOptionsMomentum 26 ///< Index of the kernel for Describe the process of SGD optimization options for the Batch normalization Neuron (#CNeuronBatchNormOCL). #define def_k_buom_options 0 ///<[in] Options matrix m*(7 or 9), where m - Number of neurons in previous layer #define def_k_buom_matrix_g 1 ///<[in] Tensor of gradients at current layer #define def_k_buom_learning_rates 2 ///< Learning rates #define def_k_buom_momentum 3 ///< Momentum multiplier //--- #define def_k_UpdateBatchOptionsAdam 27 ///< Index of the kernel for Describe the process of Adam optimization options for the Batch normalization Neuron (#CNeuronBatchNormOCL). #define def_k_buoa_options 0 ///<[in] Options matrix m*(7 or 9), where m - Number of neurons in previous layer #define def_k_buoa_matrix_g 1 ///<[in] Tensor of gradients at current layer #define def_k_buoa_l 2 ///< Learning rates #define def_k_buoa_b1 3 ///< First momentum multiplier #define def_k_buoa_b2 4 ///< Second momentum multiplier
ニューラルネットワークコンストラクターCNet::CNet,で、新しいクラスオブジェクトを作成し、新しいカーネルを初期化するブロックを追加しましょう(変更はコードで強調表示されています)。
CNet::CNet(CArrayObj *Description)
{
if(CheckPointer(Description)==POINTER_INVALID)
return;
//---
................
................
................
//---
for(int i=0; i<total; i++)
{
prev=desc;
desc=Description.At(i);
if((i+1)<total)
{
next=Description.At(i+1);
if(CheckPointer(next)==POINTER_INVALID)
return;
}
else
next=NULL;
int outputs=(next==NULL || (next.type!=defNeuron && next.type!=defNeuronBaseOCL) ? 0 : next.count);
temp=new CLayer(outputs);
int neurons=(desc.count+(desc.type==defNeuron || desc.type==defNeuronBaseOCL ? 1 : 0));
if(CheckPointer(opencl)!=POINTER_INVALID)
{
................
................
................
CNeuronBatchNormOCL *batch=NULL;
switch(desc.type)
{
................
................
................
................
//---
case defNeuronBatchNormOCL:
batch=new CNeuronBatchNormOCL();
if(CheckPointer(batch)==POINTER_INVALID)
{
delete temp;
return;
}
if(!batch.Init(outputs,0,opencl,desc.count,desc.window,desc.optimization))
{
delete batch;
delete temp;
return;
}
batch.SetActivationFunction(desc.activation);
if(!temp.Add(batch))
{
delete batch;
delete temp;
return;
}
batch=NULL;
break;
//---
default:
return;
break;
}
}
................
................
................
................
//---
if(CheckPointer(opencl)==POINTER_INVALID)
return;
//--- create kernels
opencl.SetKernelsCount(28);
................
................
................
................
opencl.KernelCreate(def_k_BatchFeedForward,"BatchFeedForward");
opencl.KernelCreate(def_k_CalcHiddenGradientBath,"CalcHiddenGradientBath");
opencl.KernelCreate(def_k_UpdateBatchOptionsMomentum,"UpdateBatchOptionsMomentum");
opencl.KernelCreate(def_k_UpdateBatchOptionsAdam,"UpdateBatchOptionsAdam");
//---
return;
}
同様に、事前に訓練されたニューラルネットワークをロードするときに新しいカーネルを開始します。
bool CNet::Load(string file_name,double &error,double &undefine,double &forecast,datetime &time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return false; //--- ................ ................ ................ //--- if(CheckPointer(opencl)==POINTER_INVALID) { opencl=new COpenCLMy(); if(CheckPointer(opencl)!=POINTER_INVALID && !opencl.Initialize(cl_program,true)) delete opencl; else { //--- create kernels opencl.SetKernelsCount(28); ................ ................ ................ opencl.KernelCreate(def_k_BatchFeedForward,"BatchFeedForward"); opencl.KernelCreate(def_k_CalcHiddenGradientBath,"CalcHiddenGradientBath"); opencl.KernelCreate(def_k_UpdateBatchOptionsMomentum,"UpdateBatchOptionsMomentum"); opencl.KernelCreate(def_k_UpdateBatchOptionsAdam,"UpdateBatchOptionsAdam"); } } ................ ................ ................ ................ ................ }
事前に訓練されたニューラルネットワークをロードするメソッドに新しいタイプのニューロンを追加します。
bool CLayer::Load(const int file_handle) { iFileHandle=file_handle; if(!CArrayObj::Load(file_handle)) return false; if(CheckPointer(m_data[0])==POINTER_INVALID) return false; //--- CNeuronBaseOCL *ocl=NULL; CNeuronBase *cpu=NULL; switch(m_data[0].Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: case defNeuronBatchNormOCL: ocl=m_data[0]; iOutputs=ocl.getConnections(); break; default: cpu=m_data[0]; iOutputs=cpu.getConnections().Total(); break; } //--- return true; }
同様に、新しいタイプのニューロンをCNeuronBaseOCL基本クラスのディスパッチャーメソッドに追加しましょう。
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: case defNeuronBatchNormOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; } bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- ................ ................ ................ CNeuronBatchNormOCL *batch=NULL; switch(TargetObject.Type()) { ................ ................ ................ case defNeuronBatchNormOCL: batch=TargetObject; temp=GetPointer(this); return batch.calcInputGradients(temp); break; } //--- return false; } bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: case defNeuronBatchNormOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
3. テスト
以前に作成したエキスパートアドバイザーで新しいクラスのテストを継続します。これにより、個々の要素のパフォーマンスを評価するための比較可能なデータが生成されます。ドロップアウトをBatch Normalizationに置き換えて、第12部のエキスパートアドバイザーに基づいて正規化方法をテストしてみましょう。新しいエキスパートアドバイザーのニューラルネットワーク構造を以下に示します。ここでは、学習率が0.000001から0.001に増加しました。
//--- 0 CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=None; if(!Topology.Add(desc)) return INIT_FAILED; //--- 1 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBatchNormOCL; desc.window=100; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 2 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=24; desc.optimization=ADAM; desc.activation=None; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*24; desc.type=defNeuronBatchNormOCL; desc.window=100; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMLMHAttentionOCL; desc.window=24; desc.window_out=4; desc.step=8; //heads desc.layers=5; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=None; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 6 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuronBatchNormOCL; desc.window=100; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM;
エキスパートアドバイザーは、EURUSD、上半期の時間枠でテストされました。以前のテストと同様に、最新のローソク足20個のデータがニューラルネットワークに入力されました。
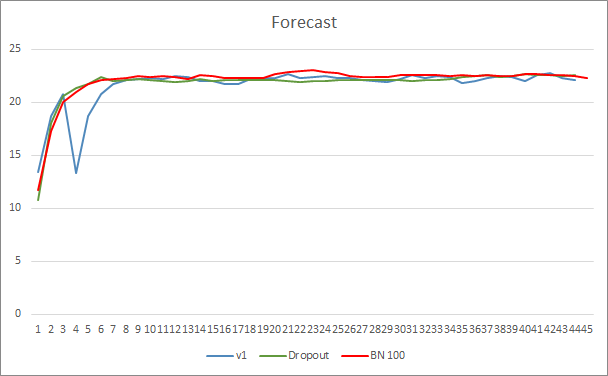
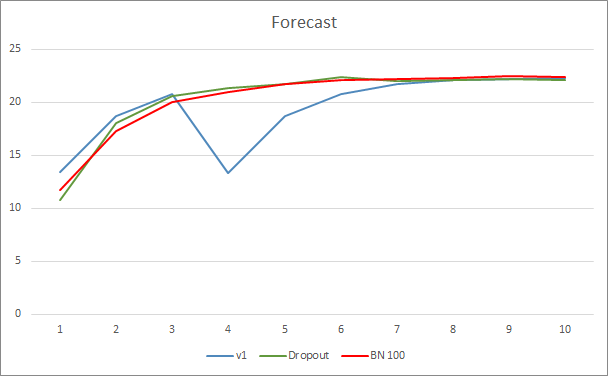
ニューラルネットワーク予測エラーグラフは、Batch Normalizationを使用したEAのグラフが滑らかでないことを示しています。これは、学習率の急激な増加が原因である可能性があります。ただし、予測誤差は、ほぼテスト全体を通じて、以前のテストよりも低くなっています。
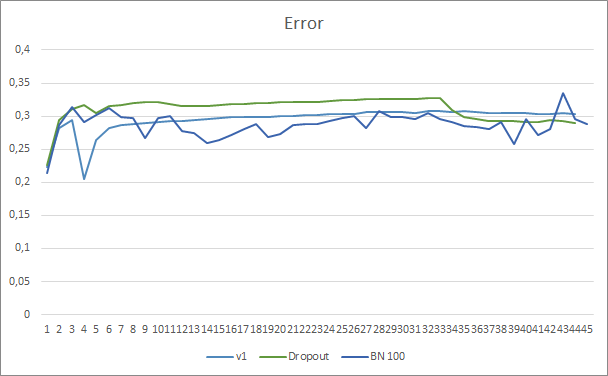
3つのエキスパートアドバイザーすべての予測ヒットグラフは非常に似ているため、いずれかが間違いなく優れていると結論付けることはできません。
終わりに
本稿では、ニューラルネットワークの収束を高めることを目的としたメソッドの検討を続け、ライブラリにBatch Normalizationクラスを追加しました。テストでは、この手法を使用するとニューラルネットワークエラーを減らし、学習率を上げることができることが示されています。
参照文献
- ニューラルネットワークが簡単に
- ニューラルネットワークが簡単に(第2回): ネットワークの訓練とテスト
- ニューラルネットワークが簡単に(第3回): コンボリューションネットワーク
- ニューラルネットワークが簡単に(第4回): リカレントネットワーク
- ニューラルネットワークが簡単に(第5回): OPENCLでのマルチスレッド計算
- ニューラルネットワークが簡単に(第6回): ニューラルネットワークの学習率を実験する
- ニューラルネットワークが簡単に(第7回): 適応的最適化法
- ニューラルネットワークが簡単に(第8回): アテンションメカニズム
- ニューラルネットワークが簡単に(第9部): 作業の文書化
- ニューラルネットワークが簡単に(第10回): Multi-Head Attention
- ニューラルネットワークが簡単に(第11部): GPTについて
- ニューラルネットワークが簡単に(第12回): ドロップアウト
- Batch Normalization: 内部共変量シフトを減らしてディープネットワークの訓練を加速する
- Layer Normalization
記事で使用されたプログラム
| # | ファイル名 | 種類 | 説明 |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH_b.mq5 | エキスパートアドバイザー | GTPアーキテクチャを使用した分類ニューラルネットワーク(出力層に3つのニューロン)と5のAttention層とBatchNormを備えたエキスパートアドバイザー |
| 2 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 3 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 4 | NN.chm | HTMLヘルプ | コンパイル済みのライブラリヘルプCHMファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/9207
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 ニューラルネットワークが簡単に(第12回): ドロップアウト
ニューラルネットワークが簡単に(第12回): ドロップアウト
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
記事パート 10 の例以降で EA を使用する場合
何か当てはまりますか?
ありがとうございました。
こんにちは、完全なログを送ることができますか?
こんにちは。
ロジェリオ
こんにちは。
ロジェリオ
こんにちは、ロジェリオ。
1.あなたはモデルを作成していません。
2.GPUがダブルをサポートしていません。https://www.mql5.com/ru/articles/11804。
こんにちは、ドミトリー
あなたはこう書きました:あなたはモデルを作成しません。
しかし、どうやってモデルを作成するのですか?私はすべてのプログラムフォントをコンパイルし、EAを実行します。
このファイルはモデルではないのですか?
ありがとうございます。
ドミトリー先生、こんにちは。
現在、どの.mqhもコンパイルできません。
例えば、vae.mqhをコンパイルしようとすると、次のようなエラーが出ます。
'MathRandomNormal' - 宣言されていない識別子 VAE.mqh 92 8
もう一度最初からやり直してみます。
もう一つ質問ですが、NeuroNet.mqhの新バージョンを入れた場合、このバージョンは他の古いEAと完全に互換性があるのでしょうか?
ありがとうございます。
ロジェリオ
追記: すべてのファイルとディレクトリを削除し、PART 1とPART 2から新しいコピーで始めても、これ以上どのコードもコンパイルできません。
例えば、fractal.mq5のコードをコンパイルしようとすると、こんなエラーが出ます:
cannot convert type'CArrayObj*' to reference of type 'const CArrayObj *' NeuroNet.mqh 437 29
すみません、あなたの記事とコードを理解したかったのですが。
追記2: 'feedForward'、'calcHiddenGradients'、'sumDOW'の'const'を削除したら、Fractal.mqh と Fractal2.mqh をコンパイルできるようになった。