
取引におけるニューラルネットワーク:層状メモリを持つエージェント

はじめに
金融データの量は日々増加しており、トレーダーは単に迅速にデータを処理するだけでなく、深く分析して正確かつタイムリーな意思決定をおこなうことが求められます。しかしながら、人間の記憶や注意力には限界があり、大量の情報を扱う際に重要なイベントを見逃したり、誤った結論に至ったりする可能性があります。このため、異種データを効率的かつ高精度で統合できる自律型取引エージェントの必要性が高まっています。こうした課題に対する解決策のひとつは、論文「FinMem:A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design」で提案されています。
提案されたFinMemフレームワークは、大規模言語モデル(LLM)ベースの革新的なエージェントであり、ユニークな多層メモリシステムを導入しています。このアプローチにより、異なる種類や時間的重要度を持つデータの効率的な処理が可能となります。FinMemのメモリモジュールは、短期的データ処理用のワーキングメモリと、情報の重要度・関連性に応じて分類される階層化された長期メモリに分かれています。たとえば、日々のニュースや短期的な市場変動は表層レベルで分析され、長期的な影響を持つレポートや研究はより深いメモリ層に蓄積されます。この構造により、エージェントは情報を優先順位付けし、最も関連性の高いデータに集中することができます
FinMemのプロファイリングモジュールにより、エージェントは専門的な文脈や市場状況に適応可能です。個人の好みやリスクプロファイルを考慮することで、最大効率の戦略に合わせた調整がおこなえます。また、意思決定モジュールは、現在の市場データと蓄積されたメモリを統合して、十分に根拠のある戦略を生成します。これにより、短期的なトレンドと長期的なパターンの両方を考慮することが可能です。このような認知科学に基づく設計により、FinMemは重要な市場イベントを記憶して活用することができ、意思決定の精度と適応性を向上させます。
元の研究で提示された複数の実験結果では、FinMemは他の自律型取引モデルを効率の面で上回ることが示されています。限られたデータで学習した場合でも、情報処理や投資判断において卓越した性能を発揮します。FinMemは認知負荷を調整する独自の能力を持つため、多数のイベントを同時に分析しつつも、分析の質を損なうことなく意思決定をおこなうことが可能です。たとえば、複数の独立した市場シグナルを同時に分析し、重要度順に整理した上で、時間制約下でも根拠のある意思決定をおこなえます。
さらに、FinMemの大きな利点として、新しいデータへのリアルタイム学習・適応能力が挙げられます。これにより、現在のタスクを管理するだけでなく、変化する市場状況に応じて取引戦略を継続的に改善できます。この認知的柔軟性と高度な技術的洗練を併せ持つ点により、FinMemは自律型取引における大きな進歩を示しています。FinMemは、複雑で動的な金融市場において成功を収めるために、認知原理と先端技術を融合した最先端のソリューションです。
FinMemアーキテクチャ
FinMemフレームワークは、次の3つの主要モジュールで構成されています。
- プロファイリング
- メモリ
- 意思決定
プロファイリングモジュールは、FinMemが複雑な金融市場のダイナミクスを効率的にナビゲートするための動的なエージェント特性を構築できるようにします。FinMemの動的特性は、主に2つの重要な構成要素で構成されています。1つは、取引専門家に匹敵する基本的なプロフェッショナル知識ベース、もう1つは、3種類の異なるリスク傾向を持つエージェントです。
1番目の構成要素には、2種類の情報が含まれます。ひとつは、FinMemが取引対象とする企業に関連する主要な取引セクターの概要、もうひとつは、対象ティッカーの学習期間全体にわたる過去の財務実績の簡易的な概要です。新しい企業の株式を取引する前に、FinMemはサーバー側データベースからこれらのセクター情報および過去財務データにアクセスし、最新化します。この専門知識の設定により、メモリの対象範囲が特定の取引タスクに関連するイベントに限定されます。
2番目の構成要素として、FinMemには3種類のリスク傾向プロファイルが設計されています。
- リスク追求型
- リスク回避型
- 自己適応型リスク特性
リスク追求型では、FinMemは攻撃的かつ高リターン戦略を採用し、リスク回避型では、保守的で低リスクなアプローチに軸足を置きます。FinMemの特徴は、現在の市場状況に応じてこれらのリスク設定を動的に切り替えられる点です。具体的には、累積リターンが短期間でゼロを下回った場合にリスク傾向を変更します。この柔軟な設計は、安全装置として機能し、市場が不安定な状況下での長期的な損失を緩和します。
初期学習段階では、FinMemは選択されたリスク傾向に基づき設定され、各プロファイルにはLLMプロンプト形式の詳細なテキスト指示が付与されます。これらの指示により、FinMemは受信メッセージの処理方法や、割り当てられたリスクプロファイルに応じた行動を定義します。システムは全リスクプロファイルとその詳細説明をバックログとして保持しており、必要に応じてプロファイルを切り替えることで異なる株式に容易に適応可能です。
このFinMemプロファイリングモジュール内の動的特性設定は、主観的かつ専門的な知識と、柔軟なリスク行動選択を提供します。これにより、取引関連情報やメモリ関連イベントを効率的にフィルタリングし、抽出するためのコンテキストが供給され、推論精度と市場状況変化への適応性が向上します。
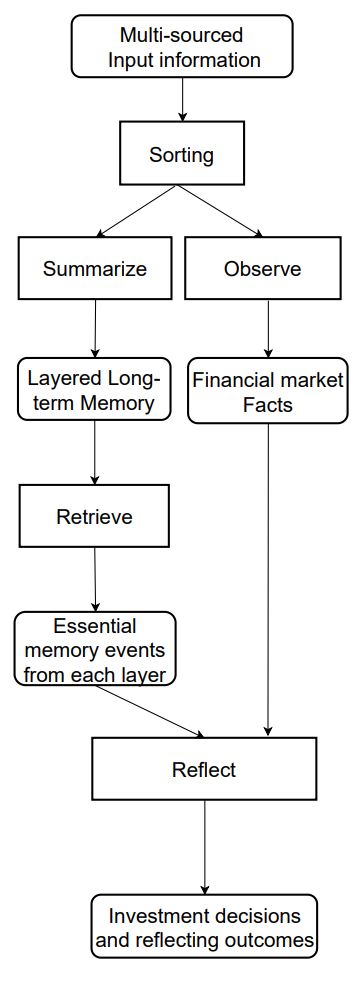
FinMemのメモリモジュールは、トレーダーの認知システムを模倣し、階層的な金融情報を効率的に処理し、重要なメッセージを優先的に扱うことで高品質な投資判断をサポートします。メモリ容量は動的に調整可能であり、長期間の情報取得にも対応できます。FinMemのメモリモジュールは、ワーキングメモリと長期メモリの両方を含み、層状処理が可能であり、特定の投資クエリに応じて起動されます。
ワーキングメモリは、人間の一時的記憶および思考操作機能に対応します。FInMemの設計者は、この概念を取り入れ、意思決定の中心的ワークスペースとして実装しています。人間のワーキングメモリはおおよそ7±2件の情報を保持できますが、FinMemのワーキングメモリは用途に応じて拡張可能です。FinMemのワーキングメモリは、金融データを取引行動に変換するため、要約、観察、反映の3つの主要操作をおこないます。
FinMemは外部市場データを用いて、特定株式取引クエリに対応した重要な投資洞察やセンチメントを抽出します。生データを情報密度の高い短文に圧縮することで、処理効率を向上させます。その後、関連データと投資センチメントを抽出して要約し、情報の時間的重要度に応じて適切な長期メモリ層に振り分けます。
同じクエリを開始する際、FinMemは観察操作を実施して市場事実を収集します。FinMemがアクセスできる情報は、学習とテスト段階で異なります。学習時には、指定期間の株価データ全般にアクセス可能です。ティッカーと日付を指定した取引クエリを受け取ると、FinMemは日次の調整後終値差分に注目し、翌日価格と当日価格を比較します。この価格差分は市場ベンチマークとして使用され、価格が下落すれば「売り」、上昇または変化なしであれば「買い」と判断されます。
テスト段階では、FinMemは未来の価格データにアクセスできず、過去の価格推移と分析期間中の累積リターンを評価します。この段階は、予測市場データがない状態で、株価トレンドとニュース、レポート、指標など多様な情報源との論理的関連を確立できるFinMemの能力を検証する重要なテストです。過去データの分析と解釈を通じて、自律的に取引戦略を進化させる能力を評価します。
応答には、即時応答と拡張応答の2種類があります。即時応答は特定ティッカーの毎日の取引クエリを受け取った際に発動します。LLMと事前定義プロンプトを用いて、各長期メモリ層の上位K個のメモリイベントと市場指標を組み合わせます。市場指標は観察操作の結果に基づき、学習段階とテスト段階で異なります。テスト時には、取引方向(「買い」「売り」「ホールド」)、意思決定の根拠、および最も影響力の高いメモリイベントとその識別子を出力します。学習時は将来の株価動向が既知であるため、取引方向の指示は不要です。上位K個のメモリイベントには、重要な投資関連メッセージから抽出された洞察やセンチメントが含まれ、FinMemが高度な能力で要約します。
拡張応答は、定義された追跡期間において即時応答の結果を再評価します。株価トレンド、取引パフォーマンス、複数の即時反映に基づく行動理由が含まれます。即時応答が直接的な取引とフィードバック記録を可能にする一方、拡張応答は市場トレンドの一般化と最近の累積投資パフォーマンスの再評価をおこないます。拡張応答は最終的に深層長期メモリ層に保存され、その重要性が強調されます。
FinMemの長期メモリは、分析済みの金融データを階層的に整理します。異なる金融データタイプに固有の時間感度を考慮して、階層構造で分類されます。要約されたイベントは、タイムリーさと減衰率(忘却速度)に応じて層分けされます。ワーキングメモリの一般化操作を通じて出力が生成され、深い層に振り分けられたイベントは減衰速度が遅く、保持期間が長くなります。各メモリイベントは1つの層にのみ属します。
投資クエリを受け取ると、FinMemは各層から上位Kの主要メモリイベントを取得し、ワーキングメモリの反映コンポーネントに送ります。イベントは、新規性、関連性、重要性の3つの指標でランク付けされ、1.0を超えるスコアは[0,1]に正規化して集計されます。
技術層に渡される取引クエリでは、エージェントはLLMクエリを用いて新規性を評価します。この新規性は、クエリとイベントのタイムスタンプ間の時間差に逆相関し、忘却曲線を反映しています。安定性は異なる層での減衰速度を部分的に制御し、安定性が高いほどメモリの保持期間が長くなります。取引文脈では、企業の年次報告書は日次の財務ニュースよりも重要と見なされます。そのため、より高い安定性値が付与され、深い処理層に保存されます。これは、金融意思決定における情報の長期的な関連性と影響を反映しています。
関連性は、メモリイベントのテキスト内容から生成された埋め込みベクトル間のコサイン類似度で定量化されます。LLMクエリには、元の取引リクエストデータとエージェントの特性設定が含まれます。
FinMemの意思決定モジュールは、プロファイリングおよびメモリモジュールからの出力を効果的に統合し、根拠ある投資判断を支援します。日次取引では、FinMemは特定の株式に対して「買い」「売り」「ホールド」の三択から行動を選択し、テキストベースで検証します。FinMem意思決定モジュールが必要とする入力データおよび出力は、学習段階とテスト段階で異なります。
学習段階では、FinMemは学習期間全体をカバーする複数の情報源から広範なデータにアクセスします。ティッカー、日付、トレーダー特性の説明を含む取引クエリを受け取ると、FinMemはワーキングメモリにおいて観察操作と要約操作を同時に開始します。FinMemは市場ラベルを監視し、日次の調整後終値差分に基づいて「買い」「売り」の行動を識別します。これらの価格変動シグナルを用いて、FinMemは上位K個のメモリを特定して優先順位付けし、各長期メモリ層の抽出スコアに基づいてランク付けします。このプロセスにより、FinMemは市場ラベルと取得メモリ間の相関関係を解釈・正当化する包括的な分析を生成します。繰り返しの取引操作により、影響力の高い反応やメモリイベントはより深い層に移動し、保持されることで、テスト段階での将来の投資判断をサポートします。
テスト段階では、FinMemは将来の株価データにアクセスできないため、分析期間の累積リターンに基づいて将来の市場動向を予測します。予測データがない場合には、即時反映から派生した拡張応答を補助ラベルとして使用します。特定の取引クエリに直面した際、FinMemは過去の累積リターン、拡張反映、取得された上位K個のメモリなど、複数の情報源を統合して意思決定をおこないます。この包括的なアプローチにより、FinMemは根拠のある取引判断を下すことが可能です。
なお、FinMemはテスト時においても、即時反応フェーズでのみ実行可能な行動を生成します。取引方向は実際の価格動向に基づくため、トレーニング段階では投資行動は実行されません。この段階は、複数の情報源から得られる金融データと市場動態を比較することで取引経験を蓄積し、FinMemのメモリモジュールを豊富な知識ベースで強化することに焦点を当てています。これにより、将来の自律的な意思決定能力が向上します。
FDinMemフレームワークのオリジナルの可視化を以下に示します。
MQL5での実装
FinMemフレームワークの理論的側面を検討した後、次に提案されたアプローチをMQL5を用いて実装します。ここでまず明確にしておくべき点は、今回の実装は従来の研究や原著者によるオリジナルのソリューションとは大きく異なる可能性が高いということです。これは主に、原フレームワークがコア部分として事前学習済みのLLMに依存しているためです。本記事では、原著者が提案した情報処理アプローチを基礎としつつも、異なる観点から実装を試みます。
メモリモジュール
まず、メモリモジュールの構築から始めます。元のFinMemフレームワークでは、LLMを使用することで、エージェントのメモリは様々な情報源から得られたイベントを要約したテキストと、それに対応する埋め込み情報で構成されます。しかし、今回の実装ではLLMは使用せず、取引ターミナルから直接取得可能な数値情報のみを扱います。
次に、層ごとに異なる減衰率を持つ多層メモリの構築を検討します。ここで直面する課題は、分析対象のイベントをどのように優先順位付けするかです。価格変動データや各種テクニカル指標で表される環境の現状のみを分析する場合、連続する2つの状態の優先度を判定することは容易ではありません。
さまざまなオプションを評価した結果、メモリ層を整理する手段として再帰ブロックを使用することにしました。異なる忘却率を模倣するため、各メモリ層には構造的に異なる再帰ブロックアーキテクチャを採用し、各層が固有の減衰特性を持つように設計します。環境状態を人工的に優先順位付けするのではなく、すべてのメモリ層が生データを均等に処理し、モデルが自ら優先順位を学習できるように設計します。
さらに、異なるメモリ層間でのデータ対応を実現するために、クロスアテンションブロックを導入します。
上記のアルゴリズムは、CNeuronMemoryオブジェクトとしてカプセル化され、その構造は以下の通りです。
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
私たちのライブラリでは、メモリ層を整理するためにLSTMブロックとMambaブロックの2種類の回帰型ブロックを実装しています。これらのブロックの出力を統合するために、相対クロスアテンションモジュールを使用します。さらに、アテンションブロック内の内部オブジェクト数を削減するため、クロスアテンションオブジェクトを親クラスとして利用します。
内部メモリ層オブジェクトは静的に宣言されており、そのためクラスのコンストラクタおよびデストラクタは空のままにしています。宣言および継承されたすべてのオブジェクトの初期化は、通常通りInitメソッド内でおこないます。
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
このメソッドのパラメータには、親クラスのメソッドでおなじみの定数が含まれています。しかし、本ケースでは、新しいオブジェクトが単一のデータストリーム上で動作するため、第2のデータソースパラメータは除外しています。親クラスのメソッドを呼び出す際には、第1のデータストリームの値を第2のデータソースパラメータにも複製して渡します。
親クラスのメソッド操作が正常に実行された後、対応するデータソースパラメータを用いて、メモリ層の再帰オブジェクトを初期化します。
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
最後に、このメソッドは操作の成功可否を示すブール値を呼び出し元のプログラムに返します。
次のステップは、feedForwardアルゴリズムの構築です。ここは比較的シンプルです。メソッドは、ソースデータオブジェクトへのポインタを受け取り、そのデータを内部メモリ層の対応するメソッドに渡します。
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
その後、親クラスであるクロスアテンションクラスを用いて再帰オブジェクトの結果を比較し、その操作の成否を示すブール値を呼び出し元のプログラムに返します。
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
誤差勾配を伝播するcalcInputGradientsアルゴリズムは、やや複雑に見えます。ここでは、2つの情報ストリームからの誤差勾配を、メソッドパラメータとしてポインタが提供されるソースデータオブジェクトに伝播する必要があります。
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッド内では、まずソースデータオブジェクトポインタの妥当性をチェックします。そうしないと、勾配を伝播することが不可能になるためです。
検証が成功すると、親オブジェクトを使用して誤差勾配を内部メモリ層全体に分散します。
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
次に、1つのメモリ層からソースデータレベルに勾配を伝播します。
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
次に、ソースデータ勾配バッファへのポインタを空きバッファに置き換え、2番目の情報ストリームを伝播します。
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
最後に、両ストリームからの勾配を合計し、バッファポインタを元の状態に戻します。すべての操作が完了すると、メソッドは呼び出しプログラムに実行ステータスを通知し、終了します。
モデルパラメータを更新するためのupdateInputWeightsメソッドアルゴリズムには、複雑な要素は含まれていません。独自に検討してみることをお勧めします。メモリモジュールとそのすべてのメソッドの完全なコードは、添付ファイルに含まれています。では次の段階に進みます。
FinMemフレームワークの構築
次の段階では、包括的なFinMemフレームワークアルゴリズムを実装します。これはCNeuronFinMemオブジェクト内で構築されます。新しいクラスの構造は以下の通りです。新しいクラスの構造体は以下のとおりです。
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
ご覧のとおり、新しいオブジェクトには、前述の2つのメモリモジュールといくつかのクロスアテンションブロックが含まれています。クラスメソッドの実装を進めていくと、それらの目的がより理解しやすくなります。
すべての内部オブジェクトは静的に宣言されているため、クラスのコンストラクタおよびデストラクタは空のままで問題ありません。通常どおり、宣言および継承されたすべてのオブジェクトの初期化は、Initメソッド内で処理されます。
ここで重要なのは、本ケースではAgentオブジェクトを生成しているという点です。このオブジェクトは入力データを解析し、特定の行動ベクトルを返します。この行動は、オブジェクトの初期化パラメータに反映されています。そのため、環境状態テンソルを記述する標準定数に加えて、初期化メソッドには口座状態ディスクリプタ(account_descr)および行動空間(nactions)のパラメータも含まれます。
さらに、FinMemフレームワークの著者らが提案した拡張反応モジュールの動作を再現するため、エージェントの過去の行動情報を新たな環境状態への遷移に関連づけて再帰的に再利用することを計画しています。この目的のために、クロスアテンションモジュールを親クラスとして採用しています。
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
オブジェクトの初期化メソッド本体では、これまでに確立した手順に従います。まず最初に親クラスのメソッドを呼び出します。前述のとおり、これはクロスアテンションオブジェクトです。主情報ストリームには、エージェントの過去の行動ベクトルを入力します。このベクトルは、買いおよび売りの操作を表すと推定される2つの等しい部分に分割されます。一方、副情報ストリームには、現在の環境状態を記述する処理済みデータを入力します。
親クラスの処理が正常に完了した後、新たに宣言されたオブジェクトの初期化を進めます。最初に初期化するのは、環境状態ディスクリプタ用のデータ転置オブジェクトです。
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
モデルの入力は、個々のバーをベクトルとして表現した環境状態の記述で構成されています。これらのテンソルを転置することで、個別の単変量系列間での解析が可能になります。
この特性に基づき、入力データを異なる視点から分析するために、2つのメモリモジュールを使用します。
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
これらのメモリモジュールによって生成された結果は、クロスアテンションブロックに集約されます。
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
次のクロスアテンションブロックは、口座状態ベクトルから取得した累積損益情報を用いて環境状態の記述を拡張します。このベクトルには、分析対象となる状態のタイムスタンプも含まれています。
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
最後に、もう1つのクロスアテンションブロックを初期化します。これは、エージェントの直近の行動を現在の口座状態に反映された対応する結果と整合させる役割を持ちます。
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
これらの手順を完了した後、すべての再帰オブジェクトの内部状態をクリアし、操作の成功可否を示すブール値を呼び出し元のプログラムに返します。
いつの間にか本記事も終わりに近づいていますが、私たちの作業はまだ完了していません。ここで一息入れ、次回の記事では本実装を論理的に完結させ、実際の過去データを用いて開発したソリューションの有効性を評価します。
結論
本記事では、自律型取引システムの進化における新たな段階を示すFinMemフレームワークを考察しました。このフレームワークは、認知原理と大規模言語モデルに基づく高度なアルゴリズムを融合したものです。多層メモリ構造とリアルタイム適応性により、変動の激しい市場環境下でも正確かつ論理的な投資判断をおこなうことが可能になります。
実践セクションでは、提案されたアプローチの独自解釈をMQL5を用いて開発し、あえて言語モデルを使用しない形で実装を開始しました。次回の記事では、この作業を完成させ、実装したソリューションのパフォーマンスを評価します。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16804
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは。残念ながら、Research.mq5ファイルをコンパイルすることができません。- パラメータの数が正しくありません。私は先に進むことができません(
Researchファイルはどのカタログから読み込まれていますか?確かに多くのパラメータがあります。この作品では1つのモデルしか使用していません。
リサーチファイルはどのカタログからダウンロードされたのですか?実に多くのパラメータがありますね。この論文では1つのモデルしか使用していません。
この論文にどのカタログを使えばいいのか、教えていただけますか?
この記事のために使用するカタログを私に指示してください?
この記事に関連するファイルはすべてFinMemフォルダにあります。
いろいろ試してみたが、あなたのような結果は得られなかった。
申し訳ありませんが、どのファイルをどのような順番で実行すればよいか、適切な指示をお願いします。
ありがとうございました。