
取引におけるニューラルネットワーク:ウェーブレット変換とマルチタスクアテンションを用いたモデル(最終回)

はじめに
前回の記事では、Multitask-Stockformerフレームワークの理論的側面の検討を開始し、提案されたアプローチをMQL5で実装し始めました。Multitask-Stockformerは、離散ウェーブレット変換(DWT)とマルチタスクSelf-Attention(自己アテンション)モデルを組み合わせた強力な手法です。ウェーブレット変換により時系列データの詳細な分析が可能になり、マルチタスク自己アテンションモデルは金融データ内の複雑な依存関係を捉えることができます。この2つの手法の相乗効果により、時系列分析と予測のための汎用的なツールを作り出すことができます。
このフレームワークは、主に3つのコアブロックで構成されています。まず、時系列分解モジュールでは、分析対象のデータを高周波成分と低周波成分に分解します。低周波成分は全体のトレンドを表し、長期的なパターンの分析をサポートします。一方で、高周波成分は短期的な変動や急激な活動、異常を捉えます。データを詳細に分解することで処理の精度が向上し、重要な特徴を抽出しやすくなります。これは金融時系列データを扱う上で非常に重要です。
次に、デュアル周波数時空間エンコーダがデータを処理します。このモジュールは複数のサブモジュールで構成されており、抽出された周波数成分とその相互依存性を分析するように設計されています。低周波信号は長期的なトレンドとその変化に注目した時間的アテンション機構を通して処理されます。一方、高周波データは、微細な変動やそのダイナミクスを捉える拡張因果畳み込み層を通して処理されます。さらに、処理された信号はGraph Attentionモジュールで統合され、複数の資産や時間間隔間の関係を反映した時空間依存性を捉えます。このプロセスにより多層のグラフ表現が生成され、それが多次元埋め込みに変換されます。これらの埋め込みは加算やGraph Attention機構を通じて統合され、後続の分析に用いる包括的なデータ表現が形成されます。
最後に、二重周波数融合デコーダが予測結果の生成に重要な役割を果たします。デコーダーはFusion Attention機構を用いて、低周波および高周波データを統合した潜在表現を作成します。この表現は複数のスケールにわたる時間パターンを反映しており、データ分析をより包括的におこなうことができます。この段階では、モデルは隠れ表現を生成し、その後、専門化された全結合層によって処理されます。これらの層によって、モデルは複数のタスクを同時に実行できるようになります。具体的には、資産リターンの予測、トレンド変化確率の推定、その他時系列の重要な特徴の識別などです。マルチタスク処理のアプローチにより、モデルは柔軟かつ多様な市場状況に適応できるようになっています。これは、特に金融市場の高いボラティリティが存在する状況では重要な特徴です。
以下に、著者が提供したMultitask-Stockformerフレームワークの可視化を示します。
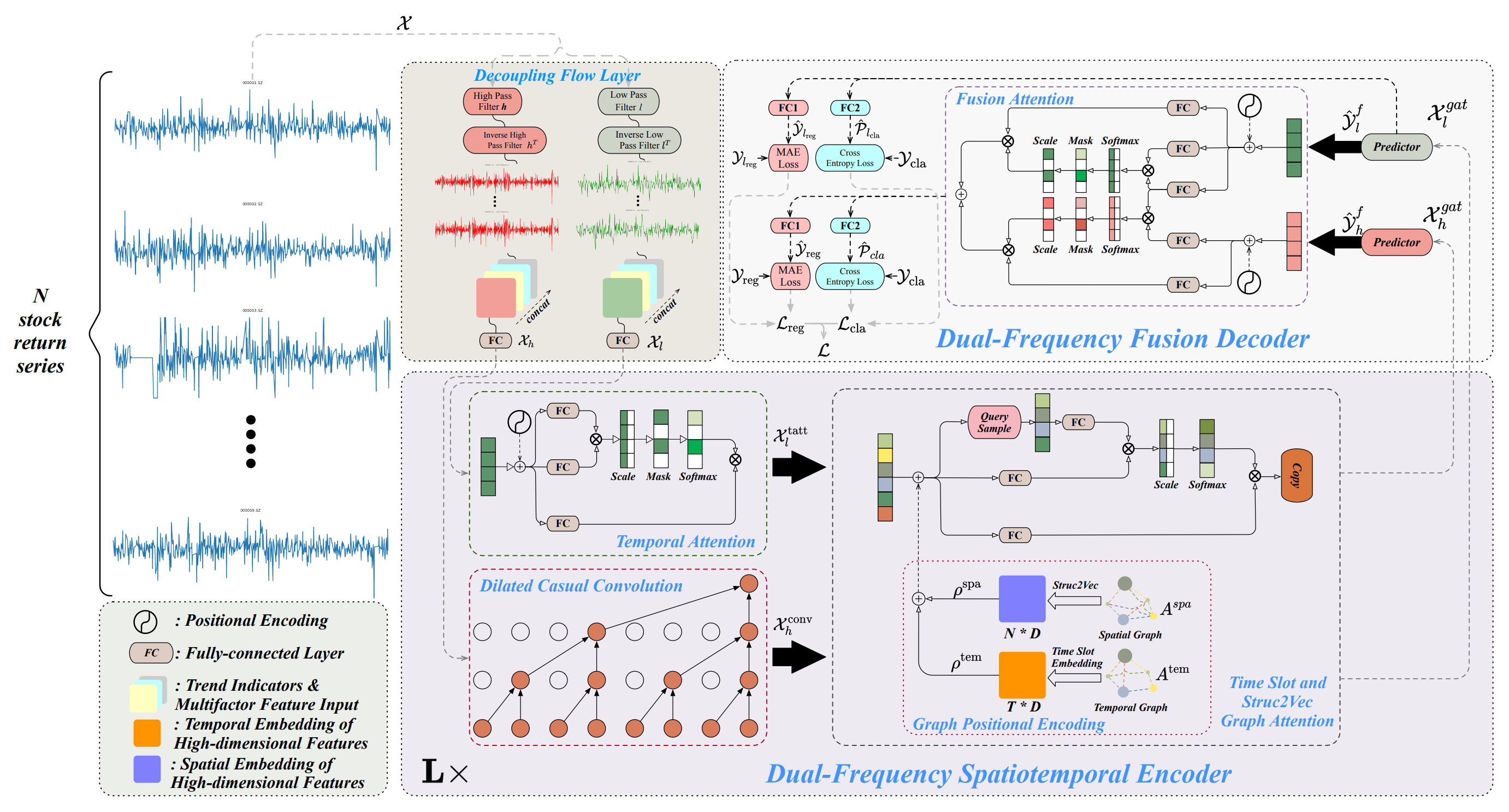
Multitask-Stockformerフレームワークの実装
引き続き、Multitask-Stockformerフレームワークの著者が提案した手法をMQL5で実装する作業を進めています。これは、時系列解析を最適化することを目的としたシステムの主要コンポーネントの実践的な実装を含みます。
フレームワークの基本要素の一つは、CNeuronDecouplingFlowクラスで実装されている時系列分解モジュールです。このコンポーネントは入力データを高周波成分と低周波成分に分離し、後続の解析の基盤を形成します。このモジュールの主な目的は、時系列の特性や潜在的な市場トレンドを考慮しながら、時系列の主要な構造的特徴を抽出することです。前回の記事では、CNeuronDecouplingFlowクラスの設計におけるアーキテクチャおよびアルゴリズム上の解決策を詳しく確認しました。
次のデータ処理段階では、二重周波数の時空間エンコーダを通じた解析がおこなわれます。前述の通り、フレームワークの著者は、各データストリームが独自の構造を持つ2つの独立したデータストリームを含む複雑なエンコーダアーキテクチャを提案しています。
低周波成分は自己アテンションアーキテクチャに基づく時間的アテンション機構を用いて解析されます。このアプローチにより、長期依存関係の特定やグローバル市場トレンドの予測が可能になります。自己アテンションを使用することで、複雑なデータ構造を深く理解し、重要な依存関係を見落とすリスクを最小化できます。現在の実装では、ライブラリ内の既存のAttentionモジュールの1つを使用し、自己アテンション機構を適用しています。
高頻度の時系列コンポーネントは、CNeuronDilatedCasualConvクラスで実装された拡張因果畳み込みモジュールを通じて処理されます。改善されたアルゴリズムにより、局所的な異常や活動の急増を効果的に検出できます。このコンポーネントは、特に高ボラティリティ期間における短期市場動態の解析において重要な役割を果たします。このモジュールをフレームワーク全体に統合することで、適応性とパフォーマンスが向上します。CNeuronDilatedCasualConvの設計における元のフレームワークのアーキテクチャ上の選択や局所的な改良点は、前回の記事で説明しました。
高周波・低周波成分の前処理が完了した後、データはGraph Attentionスロットの個別ブランチに送られます。このモジュールは、2つの専門化されたグラフの作成に基づいています。最初のグラフは時系列依存性をモデル化し、その順序構造を強調します。これにより、トレンドや周期性、その他の時間的特徴を特定できます。2つ目のグラフは、金融資産価格の相関行列に基づいており、資産間の依存関係情報を深く統合します。これにより、ある資産が他の資産に与える影響をモデルが考慮できるようになり、金融モデリングや予測において特に重要です。両方のグラフは多層構造を形成し、データ解析および解釈の精度を向上させます。
グラフ情報を解析的に有用な表現に変換するために、Struct2Vecアルゴリズムを使用します。このアルゴリズムは、グラフのトポロジー特性をコンパクトなベクトル埋め込みに変換し、さらに学習可能な全結合層で最適化されます。この埋め込みにより、局所的およびグローバルなデータ特徴を効率的に統合でき、時系列解析の品質が向上します。処理されたデータは、さらにアテンション機構を用いた解析がおこなわれるGraph Attentionブランチに送られます。この段階では、短期および長期の依存関係を検出できます。
Multitask-Stockformerフレームワークの著者は、Graph Attentionスロットに対して非常に複雑なアーキテクチャを提案しています。その実装には、多大な計算リソースと綿密なデータ準備が必要です。本研究のモデル準備にあたり、実用性を高めつつ高性能を維持するためにいくつかの簡略化を導入しました。最初の簡略化として、解析対象環境の時間的情報を除外しました。この決定は、時間的情報は有用ではあるものの、この段階ではモデルの全体効率に致命的な影響を与えないという仮定に基づいています。元のフレームワークでは出力が構築された株式ポートフォリオでしたが、私たちの実装では、主な目的は環境の潜在表現を作成することです。この表現はActorモデルによる取引判断に使用され、口座状態やタイムスタンプ情報と組み合わせることで文脈認識を提供します。つまり、時間的情報をモデルに渡すポイントを単に移動させた形です。
しかし、時間依存性グラフに対する簡略化は、資産相関グラフには適用できません。これをおこなうと重要な情報が失われるためです。代わりに、元の構造を学習可能な位置埋め込み層に置き換える方法を提案します。このアプローチにより、計算コストを最小化しつつ、重要な資産間関係を保持しながら埋め込みを学習できます。この改良により、多様な市場状況に適応可能な柔軟なアーキテクチャが実現します。
さらに、Graph AttentionスロットNode-Adaptive Feature Smoothing(NAFS)モジュールに置き換えることで、もう一歩前進しました。NAFSモジュールの主な利点は、学習可能なパラメータを持たないことです。これにより、計算コストを削減するだけでなく、モデルの設定や学習も簡略化されます。
NAFSを使用することで、埋め込み構築プロセスはグラフのトポロジーやノード特性に適応するため、より柔軟かつ堅牢になります。これは、データ構造が異種である場合や動的に変化する場合に特に重要です。結果として、NAFSは局所的およびグローバルなグラフ関係を同時に考慮した高品質なデータ表現の作成を可能にします。
2つの情報ストリームの統合は、二重周波数デコーダでおこなわれ、データの異なる側面を統合して多次元解析の基盤を作成します。これにより、信号の動態をより包括的に表現できます。二重周波数デコーダはFusion Attention機構に基づいており、2つの並列アテンションモジュールを組み合わせています。最初のモジュールは自己アテンションに基づき、低周波成分を深く処理し、長期依存関係や安定したトレンド、全体のパターンを特定します。これにより、予測において重要な時系列の基本的特徴を捉えることができます。2つ目のモジュールはCross-Attentionを用いて高周波情報を統合し、短期的かつ細粒度な成分を解析に反映させます。この統合により、低周波データの分析において微細ながら意味のある変動を考慮できます。
両アテンションモジュールは同期的に動作し、一貫性のある補完的なデータ表現を生成します。その結果は加算によって統合され、その後、全結合層(MLP)で処理されます。この手法により、大域的および局所的な信号特徴を同時に考慮でき、幅広い関係性や影響を捉えることが可能です。
提案するFusion Attentionアーキテクチャは、既存のCross-AttentionモジュールとSelf-Attentionモジュールを使用して簡単に実装できます。さらに、基本アルゴリズムの大幅な変更を必要としません。
以上より、Multitask-Stockformerフレームワークの包括的アーキテクチャを構築するための主要モジュールはすべて揃ったと言えます。これにより、次の開発ステップである、これらすべてのモジュールを統合した高レベルオブジェクトの形成に進む基盤が整います。このステップの主な目的は、コンポーネントを統合するだけでなく、各モジュールの特性を考慮した同期動作を確保することです。以下に、新しいCNeuronMulttaskStockformerオブジェクトの構造を示します。
class CNeuronMultitaskStockformer : public CNeuronBaseOCL { protected: CNeuronDecouplingFlow cDecouplingFlow; CNeuronBaseOCL cLowFreqSignal; CNeuronBaseOCL cHighFreqSignal; CNeuronRMAT cTemporalAttention; CNeuronDilatedCasualConv cDilatedCasualConvolution; CNeuronLearnabledPE cLowFreqPE; CNeuronLearnabledPE cHighFreqPE; CNeuronNAFS cLowFreqGraphAttention; CNeuronNAFS cHighFreqGraphAttention; CNeuronDMHAttention cLowFreqFusionDecoder; CNeuronCrossDMHAttention cLowHighFreqFusionDecoder; CNeuronBaseOCL cLowHigh; CNeuronConvOCL cProjection; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultitaskStockformer(void) {}; ~CNeuronMultitaskStockformer(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultitaskStockformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
提示された構造には、多数の内部オブジェクトが含まれており、これらは上記で説明したMultitask-Stockformerフレームワークのモジュールに直接対応しています。これらのコンポーネントは、高い機能統合性と実装の柔軟性を確保するように整理されています。これから、それらの相互作用を支配するアルゴリズムや、統合オブジェクトのメソッド実行時のデータフローについて詳しく解析していきます。
すべての内部オブジェクトは静的として宣言されているため、コンストラクタとデストラクタを空のままにすることができます。新たに宣言・継承されたすべてのオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronMultitaskStockformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, neurons_out, optimization_type, batch)) return false;
このメソッドのパラメータの中には、従来の定数に加えて、新しいパラメータ「neurons_out」が含まれています。これは、解析対象の環境状態の潜在表現ベクトルのサイズを指定するもので、ユーザーはこのMultitask-Stockformerブロックの出力としてこのベクトルを得ることを期待します。このベクトルは、親クラスの対応するメソッドに渡され、モデル内の外部ニューラル層とのデータ交換用コアインターフェースの初期化が行われます。
親クラスのメソッドの実行に成功したら、内部オブジェクトの初期化に移ります。この処理は、フィードフォワードパスでのオブジェクト使用順に従って進められます。前述の通り、入力データはまずCNeuronDecouplingFlow信号分解モジュールによって、高周波成分と低周波成分に分離されます。
uint index = 0; uint wave_window = MathMin(24, units_count); if(!cDecouplingFlow.Init(0, index, OpenCL, wave_window, 2, units_count, filters, window, optimization, iBatch)) return false; cDecouplingFlow.SetActivationFunction(None);
統合オブジェクトの初期化メソッドの外部パラメータでは、離散ウェーブレット変換のウィンドウサイズやステップは指定しないことに注意してください。これらのパラメータは、メソッド内で固定値として設定されます。本記事で説明する実験では、過去のH1時間足データに焦点を当てています。それに応じて、ウェーブレット変換のウィンドウサイズを1日に制限し、解析対象シーケンスの24ステップに対応させ、マルチモーダル時系列の長さを超えないようチェックを追加しています。ウィンドウのステップは2に設定されており、シーケンスの1要素を実質的にスキップする形になります。
分解モジュールの出力は、高周波成分と低周波成分の両方を含む統合テンソルです。二重周波数の時空間エンコーダで処理するために、2つの並列ストリームが用意され、それぞれの成分が個別に解析されます。この手法を実装するために、データを個別のオブジェクトに分割します。これにより、その後の処理において利便性と柔軟性が向上します。
//--- Dual-Frequency Spatiotemporal Encoder uint wave_units_out = cDecouplingFlow.GetUnits(); index++; if(!cLowFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cLowFreqSignal.SetActivationFunction(None); index++; if(!cHighFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cHighFreqSignal.SetActivationFunction(None); index++;
低周波成分は、Self-Attention機構に基づく時間的アテンションモジュールで処理されます。元のMultitask-Stockformerフレームワークでは、シーケンス処理を強化するために位置符号化が提案されています。しかし、本手法では相対位置符号化を用いたAttentionモジュールを使用しており、これによりシーケンス要素の相対位置が自動的に決定されます。そのため、追加の位置符号化は不要となり、アーキテクチャを簡素化するとともに効率も向上します。
if(!cTemporalAttention.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; cTemporalAttention.SetActivationFunction(None); index++;
単一のシーケンス要素を表すベクトルの次元は、ウェーブレット変換で使用されるフィルターの数に対応していることに注意してください。一方で、シーケンスの長さはすべての単変量時系列をカバーしています。このアプローチにより、シーケンスの各コンポーネントを個別に解析するのではなく、マルチモーダルシーケンス全体にわたるトレンドの相互依存関係を研究することが可能になります。
高周波依存関係は、拡張因果畳み込みモジュールで解析されます。ここでは、最小の畳み込みウィンドウとして2要素を用い、同じステップで処理します。解析は単位シーケンス内でおこなわれるため、局所的な依存関係を詳細に調べることができます。
if(!cDilatedCasualConvolution.Init(0, index, OpenCL, 2, 2, filters, wave_units_out, window, layers, optimization, iBatch)) return false; index++;
次に、両コンポーネントに位置符号化が追加されます。
if(!cLowFreqPE.Init(0, index, OpenCL, cTemporalAttention.Neurons(), optimization, iBatch)) return false; index++; if(!cHighFreqPE.Init(0, index, OpenCL, cDilatedCasualConvolution.Neurons(), optimization, iBatch)) return false; index++;
各コンポーネントには、個別の学習可能な位置符号化層が割り当てられています。このアプローチにより、高周波コンポーネントと低周波コンポーネントを独立して、より深く解析することが可能になります。
二重周波数エンコーダの処理が完了した後、高周波コンポーネントおよび低周波コンポーネントにそれぞれ適用されるNode-Adaptive Feature Smoothing (NAFS)モジュールを初期化します。両モジュールは、シーケンス長を除いてパラメータを共有しています。高周波シーケンスは、拡張因果畳み込みモジュールの性質上、より短くなることが想定されます。
if(!cLowFreqGraphAttention.Init(0, index, OpenCL, filters, 3, wave_units_out * window, optimization, iBatch)) return false; index++; if(!cHighFreqGraphAttention.Init(0, index, OpenCL, filters, 3, cDilatedCasualConvolution.Neurons()/filters, optimization, iBatch)) return false; index++;
次に、データフローフュージョンデコーダのオブジェクトを初期化します。ここでは、2つのアテンションブロックを初期化します。低周波コンポーネントにはSelf-Attentionを、高周波コンポーネントの統合にはCross-Attentionを用います。
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; index++; if(!cLowHighFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, filters, cDilatedCasualConvolution.Neurons()/filters, heads, layers, optimization, iBatch)) return false; index++;
アテンションブロックの出力は合算されます。そして、結果を格納するための基本ニューラル層オブジェクトが作成されます。
if(!cLowHigh.Init(0, index, OpenCL, cLowFreqFusionDecoder.Neurons(), optimization, iBatch)) return false; CBufferFloat *grad = cLowFreqFusionDecoder.getGradient(); if(!grad || !cLowHigh.SetGradient(grad, true) || !cLowHighFreqFusionDecoder.SetGradient(grad, true)) return false; index++;
不要なデータコピーを減らすために、最後の3つのオブジェクトの勾配バッファへのポインタを同期させます。このアプローチにより、メモリ使用量を削減し、学習効率を向上させることができます。
最後に、環境状態の潜在表現を生成するためのMLPオブジェクトを初期化します。ここでは、次元削減のための畳み込み層と、目標表現サイズを生成する全結合層を使用します。
全結合層は親クラスから継承されているため、必要な出力接続を持つ畳み込み層のみを初期化すれば済みます。全結合層の機能を実装するためには、親クラスから継承した機能を活用します。
if(!cProjection.Init(Neurons(), index, OpenCL, filters, filters, 3, wave_units_out, window, optimization, iBatch)) return false; //--- return true; }
すべての内部オブジェクトを初期化した後、Initメソッドは終了し、呼び出し元のプログラムに論理的な成功ステータスを返します。
次に、統合オブジェクトのフィードフォワードアルゴリズムを構築します。
bool CNeuronMultitaskStockformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Decoupling Flow if(!cDecouplingFlow.FeedForward(NeuronOCL)) return false;
このメソッドは、入力データオブジェクトへのポインタを受け取り、それが分解モジュールに渡されます。
結果のテンソルは、独立した分析のために2つのストリームに分割されます。
if(!DeConcat(cLowFreqSignal.getOutput(), cHighFreqSignal.getOutput(), cDecouplingFlow.getOutput(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false;
低周波コンポーネントは、時間的アテンションモジュールを通過します。その後、位置符号化を受け、グラフ表現モジュールに入力されます。
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cTemporalAttention.FeedForward(cLowFreqSignal.AsObject())) return false; if(!cLowFreqPE.FeedForward(cTemporalAttention.AsObject())) return false; if(!cLowFreqGraphAttention.FeedForward(cLowFreqPE.AsObject())) return false;
高周波コンポーネントは、拡張因果畳み込みモジュールから始まる自分のストリームに沿って処理されます。
//--- High Frequency Encoder if(!cDilatedCasualConvolution.FeedForward(cHighFreqSignal.AsObject())) return false; if(!cHighFreqPE.FeedForward(cDilatedCasualConvolution.AsObject())) return false; if(!cHighFreqGraphAttention.FeedForward(cHighFreqPE.AsObject())) return false;
両ストリームの出力は、二重周波数フュージョンデコーダに渡されます。ここでは、まず2つのアテンションモジュールでデータが処理されます。その出力は合算され、正規化されます。
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject())) return false; if(!cLowHighFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject(), cHighFreqGraphAttention.getOutput())) return false; if(!SumAndNormilize(cLowFreqFusionDecoder.getOutput(), cLowHighFreqFusionDecoder.getOutput(), cLowHigh.getOutput(), cLowFreqFusionDecoder.GetWindow(), true, 0, 0, 0, 1)) return false;
次に、データは畳み込み投影層によって圧縮されます。
if(!cProjection.FeedForward(cLowHigh.AsObject())) return false; //--- return CNeuronBaseOCL::feedForward(cProjection.AsObject()); }
その結果は親クラスのメソッドに送られ、解析対象の環境状態の最終的な表現が生成されます。
次のステップは、モデルの学習において重要な役割を果たすバックプロパゲーション処理を実装することです。バックプロパゲーションはcalcInputGradients内で整理され、フィードフォワードパスの逆順でおこなわれます。
bool CNeuronMultitaskStockformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
このメソッドのパラメータには、ソースデータオブジェクトへのポインタが含まれています。このオブジェクトのバッファには、入力データが最終的なモデル出力に与える影響に応じて分配された誤差勾配を渡す必要があります。そしてメソッド本体では、受け取ったポインタの妥当性を確認します。これをおこなわないと、データ転送が不可能になります。
勾配はまず、親クラスの機能を用いて畳み込み投影層に適用されます。その後、二重周波数デコーダの合算層に伝播されます。
if(!CNeuronBaseOCL::calcInputGradients(cProjection.AsObject())) return false; if(!cLowHigh.calcHiddenGradients(cProjection.AsObject())) return false;
統合オブジェクトの初期化時に、デコーダアテンションモジュールおよび出力合算層で使用される誤差勾配バッファへのポインタの置換を実装しました。これにより、合算層に伝播された誤差勾配全体が対応するアテンションモジュールに完全に渡されることが保証されます。そのため、デコーダのアテンションモジュールを通じた勾配伝播に直接移行することができます。
ただし、低周波コンポーネントのデータは両アテンションブロックで同時に使用されることに注意が必要です。そのため、2つの情報ストリームから誤差勾配を取得する必要があります。まず、Self-Attentionモジュールを通じて誤差勾配の分配操作をおこないます。
//--- Dual-Frequency Fusion Decoder if(!cLowFreqGraphAttention.calcHiddenGradients(cLowFreqFusionDecoder.AsObject())) return false;
次に、Self-Attentionモジュールの誤差勾配バッファへのポインタを、同等のサイズを持つ空きバッファに一時的に置き換え、Cross-Attentionの誤差勾配伝播操作を実行します。
CBufferFloat *grad = cLowFreqGraphAttention.getGradient(); if(!cLowFreqGraphAttention.SetGradient(cLowFreqGraphAttention.getPrevOutput(), false) || !cLowFreqGraphAttention.calcHiddenGradients(cLowHighFreqFusionDecoder.AsObject(), cHighFreqGraphAttention.getOutput(), cHighFreqGraphAttention.getGradient(), (ENUM_ACTIVATION)cHighFreqGraphAttention.Activation()) || !SumAndNormilize(grad, cLowFreqGraphAttention.getGradient(), grad, 1, false, 0, 0, 0, 1) || !cLowFreqGraphAttention.SetGradient(grad, false)) return false;
次に、2つの情報ストリームのデータを合算し、データバッファへのポインタを元の状態に戻します。
これで、二重周波数時空間エンコーダの出力レベルで、高周波コンポーネントと低周波コンポーネントへの誤差勾配の分配が完了しました。次に、2つの独立したストリームのオブジェクト間で順次勾配を分配していきます。低周波コンポーネントの場合、次のようになります。
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cLowFreqPE.calcHiddenGradients(cLowFreqGraphAttention.AsObject())) return false; if(!cTemporalAttention.calcHiddenGradients(cLowFreqPE.AsObject())) return false; if(!cLowFreqSignal.calcHiddenGradients(cTemporalAttention.AsObject())) return false;
次は高周波コンポーネントの場合です。
//--- High Frequency Encoder if(!cHighFreqPE.calcHiddenGradients(cHighFreqGraphAttention.AsObject())) return false; if(!cDilatedCasualConvolution.calcHiddenGradients(cHighFreqPE.AsObject())) return false; if(!cHighFreqSignal.calcHiddenGradients(cDilatedCasualConvolution.AsObject())) return false;
両ストリームからの勾配は、1つのテンソルに連結されます。
//--- Decoupling Flow if(!Concat(cLowFreqSignal.getGradient(), cHighFreqSignal.getGradient(), cDecouplingFlow.getGradient(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false; if(!prevLayer.calcHiddenGradients(cDecouplingFlow.AsObject())) return false; //--- return true; }
そして、それらは分解モジュールを通じて入力データに伝播されます。メソッドは処理の論理結果を呼び出し元に返して終了します。
updateInputWeightsにおけるパラメータの最適化も同じ順序でおこなわれますが、学習可能なパラメータを持つオブジェクトにのみ適用されます。このメソッドは独自に学習できるように残されており、統合オブジェクトおよびそのすべてのメソッドの完全なコードは添付資料で参照できます。
これで、Multitask-Stockformerフレームワークの実装アルゴリズムの説明は終了です。次のステップは、実現した手法を学習可能モデルのアーキテクチャに統合することです。
モデルアーキテクチャ
上記で実装したMultitask-Stockformerフレームワークの手法は、現在、環境状態エンコーダモデルに適用されます。包括的なMultitask-Stockformer実装オブジェクトを使用することで、モデルのアーキテクチャは非常にコンパクトに保たれており、層はわずか3層で構成されています。通常どおり、まず入力データとバッチ正規化層から開始します。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
これらの層は、環境から受け取った生の入力データの前処理を行います。その後、新たに追加された層が、Multitask-Stockformerフレームワークの手法を実装しています。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultitaskStockformer; //--- Windows { int temp[] = {BarDescr, 10, LatentCount}; //Window, Filters, Output if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers = 3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
本実験では、10個のウェーブレットフィルタを使用しました。各アテンションモジュールには4つのヘッドがあり、3つの内部層を持っています。
環境状態エンコーダの出力は2つのモデルで使用されます。1つは取引判断をおこなうActor、もう1つはActorが生成した行動を評価するCriticです。これらのモデルのアーキテクチャは、環境とのインタラクションや学習プログラムとともに、以前の研究から採用しました。本記事で使用した完全なモデルアーキテクチャおよびプログラムコードは添付資料に記載されています。これで、最終段階である、実際の過去データにおける実装手法の有効性のテストに進みます。
テスト
これまでの2つの記事で、MQL5を用いてMultitask-Stockformerフレームワークの提案手法の実装作業を広範におこないました。いよいよ最も興味深い段階、実際の過去データにおける実装手法の有効性のテストをおこないます。
ここで明確にしておくべきことは、今回評価するのは実装した手法であり、元のMultitask-Stockformerフレームワークではないということです。実装中にいくつかの修正が加えられたためです。
テスト中、モデルの学習はEURUSDの2023年全期間の過去データ(H1時間足)でおこなわれました。解析に用いたすべてのインジケーターは、デフォルトパラメータ設定で使用しました。
初期学習フェーズでは、以前の研究で収集したデータセットを使用しました。このデータセットは、進化するActor方策に適応するため定期的に更新されました。複数回の学習およびデータセット更新サイクルの後、得られたポリシーは、学習セットおよびテストセットの両方で収益性を示しました。
学習済み方策のテストは、2024年1月の過去データでおこなわれ、その他のパラメータは変更しませんでした。結果は以下の通りです。
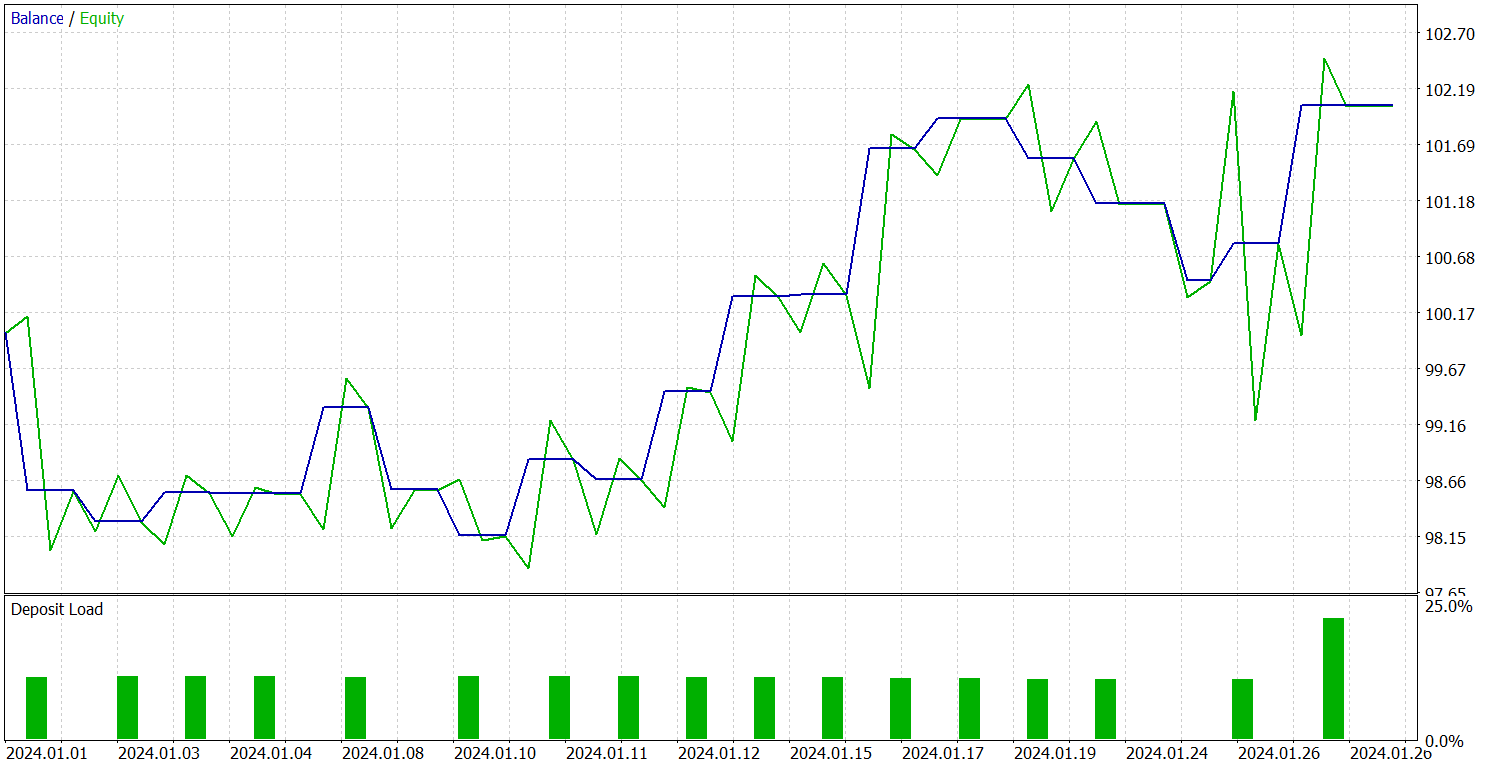
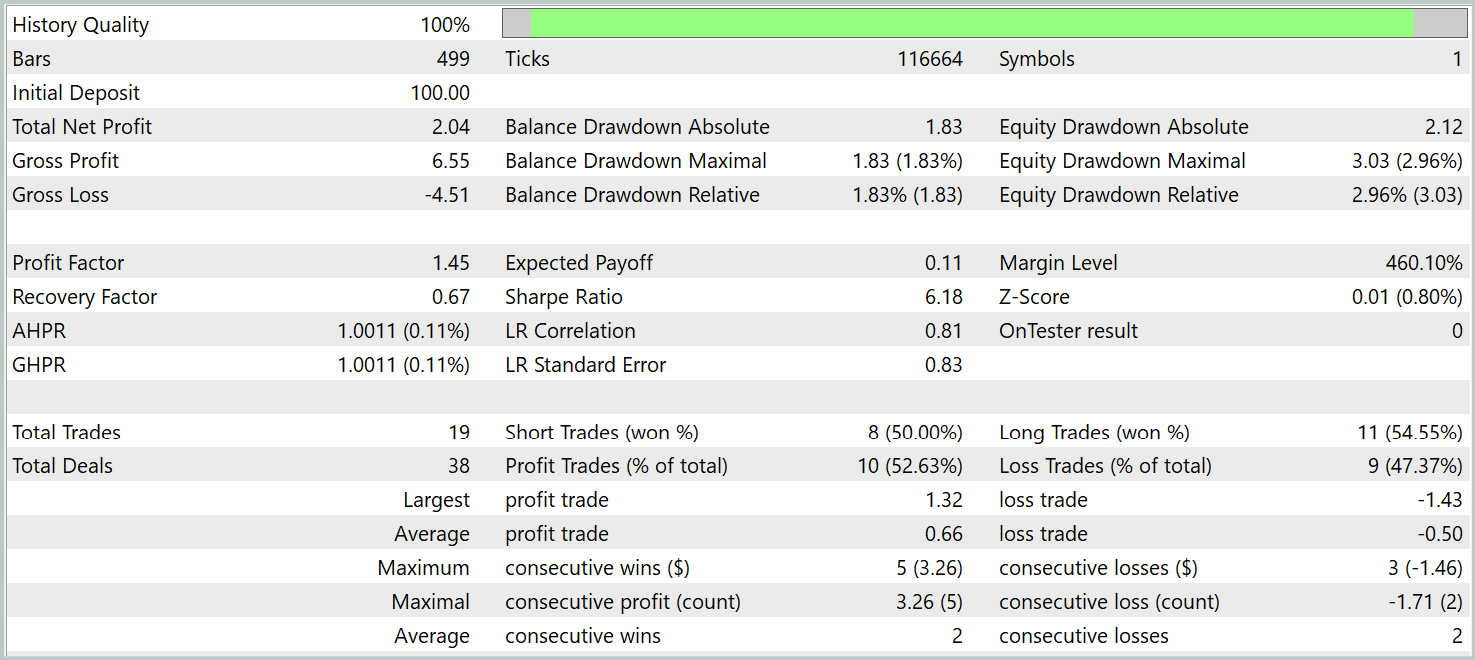
テスト期間中、モデルは合計19回の取引を実行し、そのうち10回が利益で終了しました。これは50%をわずかに上回る結果です。しかし、勝ち取引1回あたりの平均利益が負け取引よりも大きかったため、モデルはテスト期間を通じて総合的に利益を上げ、プロフィットファクターは1.45となりました。
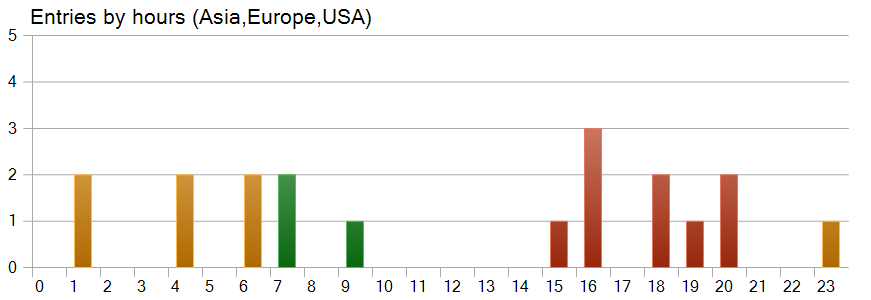
興味深い観察結果として、取引タイミングのチャートがあります。取引のほぼ半分は米国取引時間中に開始されており、最もボラティリティが高い時間帯にはほとんど取引をおこなっていませんでした。
結論
本記事では、Multitask-Stockformerフレームワークについて検討しました。これは、離散ウェーブレット変換とマルチタスク自己アテンション(Self-Attention)モジュールを組み合わせた革新的な株式選択モデルです。この包括的な手法により、市場データの時間的・周波数的特徴を特定し、解析対象の要因間の複雑な相互作用を正確にモデル化することが可能になります。
実践部分では、MQL5においてフレームワーク手法の独自実装をおこないました。実装した手法をモデルアーキテクチャに統合し、実際の過去データで学習させました。その後、学習済みモデルをMetaTrader 5ストラテジーテスターでテストしました。実験結果は、実装した手法の有用性を示しています。しかし、実際の取引に適用する前に、モデルはより代表的なデータセットで学習させ、包括的なテストを行う必要があります。
参照文献
- Stockformer:A Price-Volume Factor Stock Selection Model Based on Wavelet Transform and Multi-Task Self-Attention Networks
- この連載の他の記事記事
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムのコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16757
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索