
取引におけるニューラルネットワーク:Attentionメカニズムを備えたエージェントのアンサンブル(最終回)

はじめに
ポートフォリオ管理は投資の意思決定において重要な役割を果たし、資産間での資本の動的な再配分を通じて、収益の向上とリスクの軽減を目指します。研究「Developing an attention-based ensemble learning framework for financial portfolio optimisation」では、アテンション機構と時系列分析を統合した革新的なマルチエージェント適応型フレームワーク「MASAAT」を紹介しています。このアプローチでは、複数の粒度レベルで価格の方向性変動をクロス分析する一連の取引エージェントを生成します。このような設計により、ポートフォリオの継続的なリバランスが可能となり、変動の激しい金融市場において収益性とリスクの効果的なトレードオフを実現することができます。
大きな価格変動を捉えるために、エージェントは異なる閾値を持つ方向性移動フィルタを採用します。これにより、分析対象の価格時系列から主要なトレンド特性量を抽出でき、市場のさまざまな強度の変化をより的確に解釈できるようになります。提案手法では、新しいシーケンストークン生成技術を導入し、Cross-Sectional Attention (CSA)およびTemporal Analysis (TA)モジュールが多様な相関関係を効果的に識別できるようにします。具体的には、特徴量マップを再構築する際、CSAモジュール内のシーケンストークンは、アテンションメカニズムによって最適化された各資産インジケーターに基づいて生成されます。一方、TAモジュール内のトークンは時間的特性から構築され、異なる時点間の意味のある関係を特定することが可能になります。
CSAモジュールとTAモジュールから得られた資産および時点の相関評価は、アテンションメカニズムを用いてMASAATエージェントによって統合され、観測期間全体における各資産の依存関係を検出することを目的としています。
MASAATフレームワークのオリジナルの可視化を以下に示します。
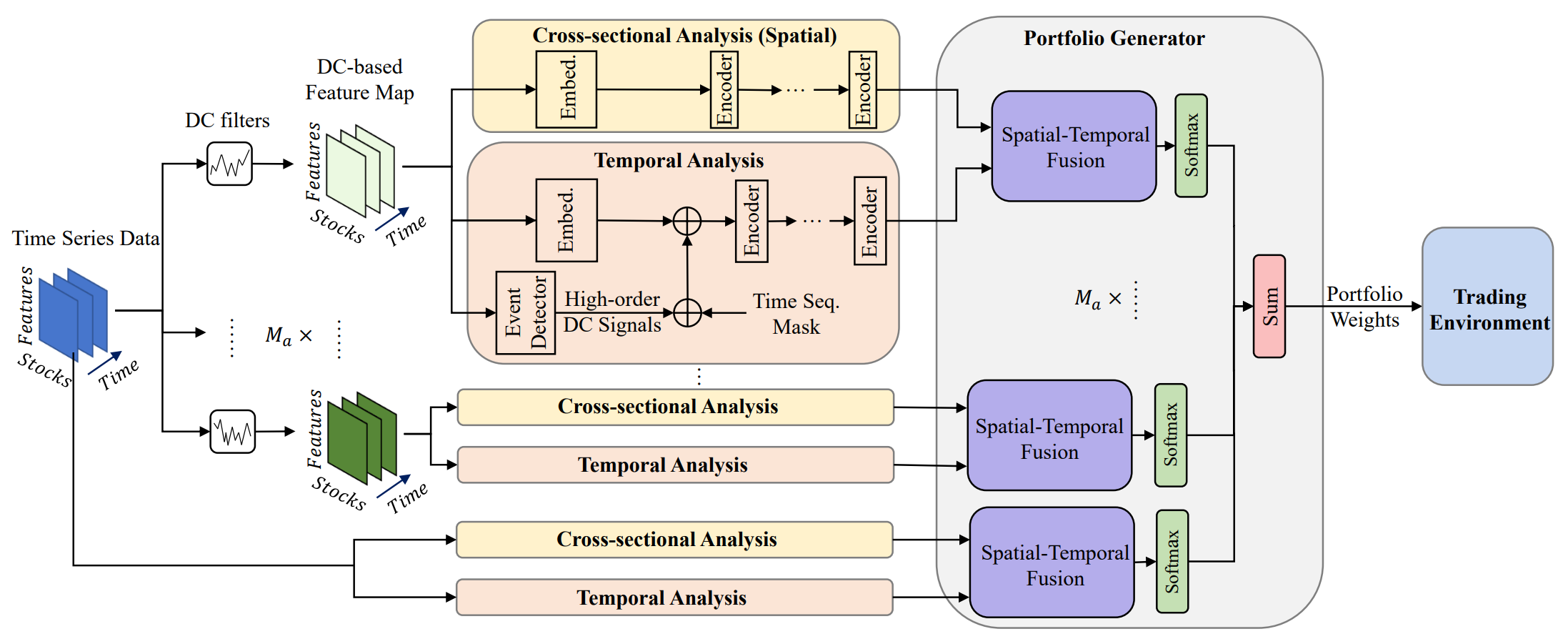
MASAATフレームワークは、明確に定義されたモジュールアーキテクチャを備えており、各モジュールを独立したクラスとして実装し、それらのオブジェクトを統一的な構造に統合することが可能です。前回の記事では、分析されたマルチモーダル時系列をマルチスケールの区分線形表現へと変換するマルチエージェントオブジェクトCNeuronPLRMultiAgentsOCLの実装アルゴリズムを紹介しました。また、CSACNeuronCrossSectionalAnalysisモジュールのアルゴリズムについても解説しました。今回は、この研究の流れを引き続き進めていきます。
時間分析(Time Analysis)モジュール
前回の記事では、CSAモジュールを実装するCNeuronCrossSectionalAnalysisオブジェクトについて検討しました。MASAATフレームワークにはこれに並ぶ時間分析モジュール(TA)も含まれており、分析対象のマルチモーダルシーケンス内の個々の時点間の依存関係を明らかにするよう設計されています。両モジュールの構造を詳しく見るとほぼ同等ですが、解析対象の次元(視点)が異なるため、シーケンスを異なる観点からクロス分析する役割を果たします。
この点から単純な解決策が示唆されます。すなわち、元のシーケンスを転置してから既存のCNeuronCrossSectionalAnalysisオブジェクトに入力すれば、時間方向の依存性を解析できるということです。この時点で、3次元テンソル内の2つの次元を転置する必要が生じます。ここで重要なのは、私たちが複数のマルチモーダル時系列を並列に分析しようとしている点です。より正確に言えば、各エージェントはソースのマルチモーダルシーケンスを区分線形表現に変換したものを、それぞれ独自のスケールで処理します。したがって、このオブジェクトへの入力は[Agent, Asset, Time]という形式の3次元テンソルであることが想定されます。時点間の依存関係を分析するためには、最後の2つの次元を転置する必要があります。現時点で私たちのライブラリはこの機能をサポートしていないため、自前で実装しなければなりません。
3次元テンソルの末尾2次元を転置する方法はいくつか考えられます。最も直接的な解決策は、OpenCLプログラム内に新しいカーネルを作成し、それを制御する新しいクラスをメインプログラム側で実装することです。このアプローチは計算性能の観点から最も効率的ですが、開発者にとっては最も労力を要するものでもあります。そこで私たちは、計算リソースをある程度犠牲にする代わりに、プログラミングの複雑さを軽減する方針を取りました。最初のステップでは、3次元テンソルの最後の2つの次元を1つに結合し、これを2次元行列転置層に入力します。これにより、データ構造は次のように変化します。
[Agent, [Asset, Time]] → [[Time, Asset], Agent]
続いてCNeuronTransposeRCDOCLオブジェクトを使用して、得られた3次元テンソルの最初の2つの次元を転置します。
[Time, Asset, Agent] → [Asset, Time, Agent]
最後に、もう一度2次元行列転置層を適用し、残りの2次元を結合してエージェント軸を最初の位置に戻します。結果として、次のような構造が得られます。
[[Asset, Time], Agent] → [Agent, [Time, Asset]]
この一連の操作は、新しいクラス「CNeuronTransposeVRCOCL」によって実装されます。
class CNeuronTransposeVRCOCL : public CNeuronTransposeOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronTransposeRCDOCL cTransposeRCD; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; public: CNeuronTransposeVRCOCL(void) {}; ~CNeuronTransposeVRCOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronTransposeVRCOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
このクラスは、親オブジェクトとして2次元行列転置層を継承し、データ再配置の最終段階を担います。この設計により、新しいクラス内部で宣言すべき静的オブジェクトは2つのみとなります。すべてのオブジェクトの初期化はInitメソッドによっておこなわれます。このメソッドは転置対象となるテンソルの3つの次元を入力パラメータとして受け取ります。
bool CNeuronTransposeVRCOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint variables, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, count * window, variables, optimization_type, batch)) return false;
このメソッドの最初のステップでは、親クラスの同名メソッドを呼び出します。ただし、この親オブジェクトは主に最終的なデータ再配置を担当するため、呼び出し時に渡すパラメータは適切に変換する必要があります。具体的には、最初の次元を元のテンソルの最後の2つの次元の積として計算し、その値を親クラスに渡します。残りの次元は単純にコピーします。
親クラスの初期化が成功した後、内部オブジェクトの初期化を続けます。最初に、主要な2次元行列転置層を初期化します。このとき、パラメータは先ほど親クラスに渡したものの逆を使用します。
if(!cTranspose.Init(0, 0, OpenCL, variables, count * window, optimization, iBatch)) return false;
次に、3次元テンソルの最初の2つの次元を転置するためのオブジェクトを初期化します。これにより、資産軸と時間軸が入れ替わります。
if(!cTransposeRCD.Init(0, 1, OpenCL, count, window, variables, optimization, iBatch)) return false; //--- return true; }
最後に、これらすべての操作の結果を論理値として返し、メソッドを終了します。
これが初期化プロセス全体です。このクラスの構造と初期化手順は比較的単純で、理解しやすいものになっています。他のメソッドも同様の構造を持っています。たとえばfeedForwardメソッドでは、内部オブジェクトの対応するメソッドを順に呼び出し、最後に親クラスのfeedForwardメソッドを実行して処理を完了します。
bool CNeuronTransposeVRCOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!cTransposeRCD.FeedForward(cTranspose.AsObject())) return false; //--- return CNeuronTransposeOCL::feedForward(cTransposeRCD.AsObject()); }
後方伝播に関するアルゴリズムは、この記事の添付ファイルに完全な形で示されています。CNeuronTransposeVRCOCLオブジェクトは学習可能なパラメータを持たないため、ここでは詳細な検討は省略します。
このようにして必要なデータ転置オブジェクトを用意できたため、次に時間分析モジュール(TA)の実装に進むことができます。このモジュールのアルゴリズムはCNeuronTemporalAnalysisクラスに実装されています。この新しいクラスの動作は意図的に非常に単純化されており、入力データを転置した後にCSAモジュールのメカニズムを適用する構成となっています。新しいオブジェクトの構造を以下に示します。
class CNeuronTemporalAnalysis : public CNeuronCrossSectionalAnalysis { protected: CNeuronTransposeVRCOCL cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronTemporalAnalysis(void) {}; ~CNeuronTemporalAnalysis(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) const override { return defNeuronTemporalAnalysis; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
CNeuronTemporalAnalysisクラスは、Cross-Sectional Attention (CSA)モジュールを実装するCNeuronCrossSectionalAnalysisを親クラスとして継承します。前述のとおり、このモジュールの機能はアルゴリズムの基盤を形成しています。私たちは、この既存の機能の上に、3次元テンソルの最後の2つの次元を転置するための内部オブジェクトを追加するだけです。新しく導入されたオブジェクトと継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。このメソッドは、親クラスの同名メソッドと同じ構造のパラメータを持ちます。
bool CNeuronTemporalAnalysis::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronCrossSectionalAnalysis::Init(numOutputs, myIndex, open_cl, 3 * units_count, window_key, heads, heads_kv, window / 3, layers, layers_to_one_kv, variables, optimization_type, batch)) return false;
このメソッド内では、まず親クラスの初期化メソッドを呼び出し、すべての受け取ったパラメータをそのまま渡します。
この段階で、実装に関していくつか注意すべき点があります。第一に、外部パラメータは元のデータの次元を定義しています。私たちは、3次元テンソルの最後の2つの次元を転置することを目的としているため、親クラスの初期化メソッドにパラメータを渡す際には、対応する次元を入れ替えなければなりません。
第二に、入力データの構造を考慮する必要があります。このオブジェクトはマルチエージェントトレンド検出ブロックの出力を受け取ります。したがって、モデルの入力は、マルチモーダル時系列の区分線形近似を表すテンソルです。私たちの実装では、単変量時系列の各有向セグメントが3つの要素によって表現されます。論理的には、これら3つの要素は分析において単一の単位として扱うべきです。そのため、分析ウィンドウのサイズを3倍にし、対応するシーケンス長を3分の1に短縮します。
親クラスの初期化が正常に完了した後、内部に保持された3次元テンソル転置オブジェクトの初期化メソッドを呼び出します。
if(!cTranspose.Init(0, 0, OpenCL,variables, units_count, window, optimization_type, batch)) return false; //--- return true; }
この処理の最後に、操作結果の論理値を呼び出し元プログラムに返し、メソッドの実行を終了します。
CNeuronTemporalAnalysisオブジェクトのフィードフォワードおよびバックプロパゲーションアルゴリズムは非常に単純です。従って、この記事ではそれについては触れないことにします。このクラスおよびすべてのメソッドの完全なソースコードは、この記事に添付されたファイルに含まれています。
ポートフォリオ生成モジュール
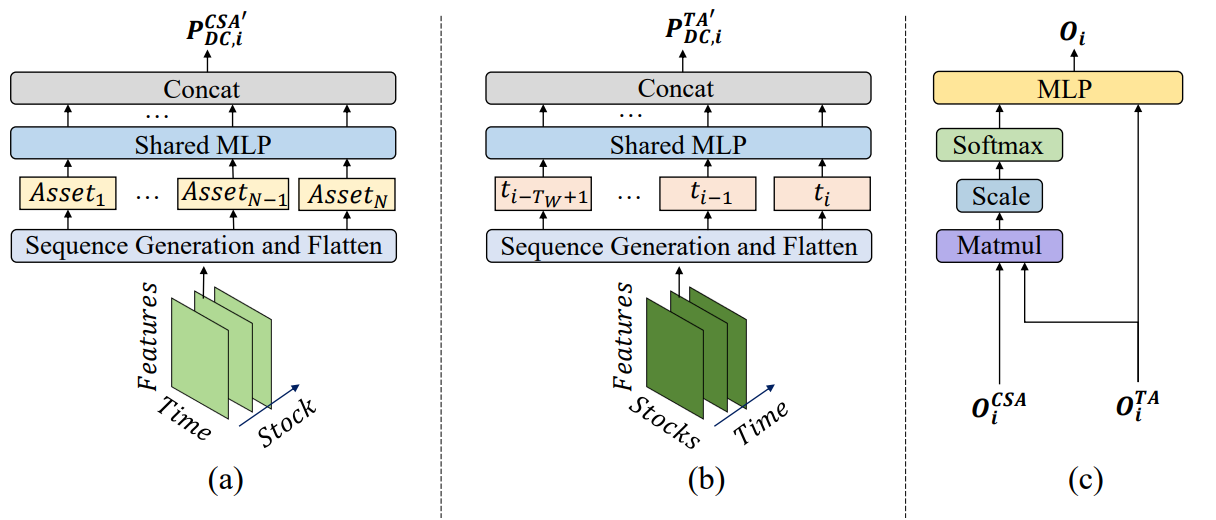
CSAブロックとTAブロックの出力では、それぞれ資産間および時点間の依存関係に関する情報で拡張されたデータが得られます。これらの情報はアテンションメカニズムを通じて結合され、各エージェントが独自の投資ポートフォリオを構築できるようになります。より正確に言えば、各エージェントはまず時間的依存関係を考慮した資産埋め込みを形成し、それを完全結合層に通してポートフォリオ配分を表す重みベクトルを生成します。このとき、すべてのベクトル要素の合計は1になります。
ポートフォリオ生成関数の数学的表現は以下のとおりです。
![]()
これらのポートフォリオ提案に基づいて、最終的なポートフォリオ表現が構築されます。
ここで、MASAATフレームワークの著者による元の説明から若干逸脱します。しかしこの逸脱は数学的というよりも論理的なものであり、実際には元の関数の構造を忠実に踏襲しつつ、出力結果の解釈を再構成しています。
私たちのタスクはMASAATの著者らのそれとはやや異なります。モデルの出力として、取引方向、ポジションサイズ、ストップロスおよびテイクプロフィットの水準を指定するエージェントのアクションベクトルを得ることを目的としています。ポジションサイズを決定するには、金融商品の動態に加えて口座の状態情報が必要ですが、この情報は入力データには含まれていません。そのため、私たちのMASAAT実装においては、出力が現在の市場状況に関する包括的な分析を内包する隠れ状態埋め込みとなることを期待しています。
MASAATの最終的な機能はCNeuronPortfolioGeneratorオブジェクト内で実現されます。その構造を以下に示します。
class CNeuronPortfolioGenerator : public CNeuronBaseOCL { protected: uint iAssets; uint iTimePoints; uint iAgents; uint iDimension; //--- CNeuronBaseOCL cAssetTime[2]; CNeuronTransposeVRCOCL cTransposeVRC; CNeuronSoftMaxOCL cSoftMax; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPortfolioGenerator(void) {}; ~CNeuronPortfolioGenerator(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronPortfolioGenerator; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
この新しいクラスの構造内では、いくつかの内部オブジェクトを宣言しています。これらの機能については、各メソッドの実装部分で説明します。すべての内部オブジェクトは静的に宣言されているため、クラスのコンストラクタおよびデストラクタは空のままとします。これらの宣言済みおよび継承された内部オブジェクトの初期化は、Initメソッド内でおこなわれます。ここでいくつかの点に注意が必要です。
bool CNeuronPortfolioGenerator::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint assets, uint time_points, uint dimension, uint agents, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(assets <= 0 || time_points <= 0 || dimension <= 0 || agents <= 0) return false;
このメソッドは、以下のような明確化が必要な複数のパラメータを受け取ります。
- assets:CSAモジュールで分析される資産の数
- time_points:TAモジュールで分析される時点の数
- dimension:各シーケンス要素の埋め込みベクトルのサイズ(CSAおよびTAモジュールに共通)
- agents:エージェントの数
- projection:モジュール出力における分析状態の射影次元
まず、すべてのパラメータが0より大きいことを確認します。次に、分析状態の射影サイズを渡して親クラスの初期化メソッドを呼び出します。これはモジュール出力で期待されるテンソルに対応します。
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, projection, optimization_type, batch)) return false;
親クラスの初期化が正常に完了したら、外部パラメータの値を内部変数に格納します。
iAssets = assets; iTimePoints = time_points; iDimension = dimension; iAgents = agents;
次に、内部オブジェクトの初期化に進みます。前述の式を思い出すと、TAモジュールの出力は転置形と元の形の2通りで使用されることがわかります。
TAモジュールは[Agent, Time, Embedding]の3次元テンソルを出力するため、この場合は最後の2つの次元に対して3次元テンソル転置オブジェクトを使用する必要があります。
if(!cTransposeVRC.Init(0, 0, OpenCL, iAgents, iTimePoints, iDimension, optimization, iBatch)) return false;
次に、CSAモジュールの結果と転置したTA出力を乗算します。行列乗算メソッドは親クラスから継承されています。結果を保持するために、内部の完全結合層を初期化します。
if(!cAssetTime[0].Init(0, 1, OpenCL, iAssets * iTimePoints * iAgents, optimization, iBatch)) return false; cAssetTime[0].SetActivationFunction(None);
結果の値はSoftmax関数を使用して正規化されます。
if(!cSoftMax.Init(0, 2, OpenCL, cAssetTime[0].Neurons(), optimization, iBatch)) return false; cSoftMax.SetHeads(iAssets * iAgents);
正規化は資産ごと、エージェントごとにおこなわれる点を強調する必要があります。したがって、正規化ヘッドの数は資産数とエージェント数の積に等しくなります。
正規化された係数は、各資産の各時点に対するアテンション重みとして機能します。この係数行列をTA出力に掛け合わせることで、分析対象資産の埋め込みを得ます。これらの埋め込みを格納するために、もう1つの完全結合層を初期化します。
if(!cAssetTime[1].Init(Neurons(), 3, OpenCL, iAssets * iDimension * iAgents, optimization, iBatch)) return false; cAssetTime[1].SetActivationFunction(None); //--- return true; }
すべてのエージェントによって生成された埋め込みを、分析環境の統一表現に射影するために、完全結合層を使用します。ここで重要なのは、この完全結合層がクラスの親オブジェクトであるという点です。このため、追加の内部層を作成せず、親クラスの機能を直接利用します。最後の内部層では、外部プログラムから与えられる射影サイズに対応する出力接続数のみを指定します。
すべての内部オブジェクトが正常に初期化されたら、これらの操作の論理結果を呼び出し元プログラムに返し、メソッドを終了します。
次の段階では、feedForwardメソッド内でフィードフォワードアルゴリズムを開発します。ここで重要なのは、入力データのソースが2つあることです。さらに、時間分析(TA)モジュールの結果は2回使用されるため、この情報ストリームを主要なものとして扱います。
bool CNeuronPortfolioGenerator::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false; //--- if(!cTransposeVRC.FeedForward(NeuronOCL)) return false;
feedForwardメソッドでは、まず2番目のデータソースへのポインタが有効であるかを検証します。初期準備が完了したら、実際の計算に進みます。まず、2番目のデータソースのテンソルを、1番目のデータソースの転置テンソルで乗算します。
if(!MatMul(SecondInput, cTransposeVRC.getOutput(), cAssetTime[0].getOutput(), iAssets, iDimension, iTimePoints, iAgents)) return false;
結果はSoftMax関数を使用して正規化されます。
if(!cSoftMax.FeedForward(cAssetTime[0].AsObject())) return false;
その後、正規化された結果を主要な情報ストリーム(1番目のデータソース)の元のデータに掛けます。
if(!MatMul(cSoftMax.getOutput(), NeuronOCL.getOutput(), cAssetTime[1].getOutput(), iAssets, iTimePoints, iDimension, iAgents)) return false;
最後に、親クラスの機能を使用して、得られたデータを指定されたサブスペースに投影します。
return CNeuronBaseOCL::feedForward(cAssetTime[1].AsObject()); }
これらの操作の論理結果を呼び出し元プログラムに返して、メソッドを終了します。
フィードフォワードプロセスの実装が完了した後、バックプロパゲーションアルゴリズムに進みます。ここでは、まず誤差勾配分布メソッドcalcInputGradientsを確認します。
bool CNeuronPortfolioGenerator::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient || !SecondInput) return false;
メソッドのパラメータには、入力データオブジェクトへのポインタと、両方の情報ストリームに対応する誤差勾配が含まれます。メソッド内では、ポインタの有効性を直ちに確認します。ポインタが無効な場合、それ以降の操作は意味を持ちません。
ご存知のように、誤差勾配の伝播は、フィードフォワード情報フローの構造に正確に従いますが、その流れは逆になります。このメソッドの操作は、まず親クラスの同名メソッドを呼び出して、内部オブジェクトに勾配を伝播することから始まります。
if(!CNeuronBaseOCL::calcInputGradients(cAssetTime[1].AsObject())) return false;
次に、行列乗算の誤差勾配分布メソッドを呼び出し、データを入力レベルと内部Softmax層に渡します。
if(!MatMulGrad(cSoftMax.getOutput(), cSoftMax.getGradient(), NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cAssetTime[1].getGradient(), iAssets, iTimePoints, iDimension, iAgents)) return false;
ここで注意すべきは、主要情報ストリームの入力レベルへの誤差勾配は、2つの異なるフローから到達する必要があることです。この段階で得られた値は、データ転置オブジェクトの補助バッファに一時的に格納されます。
次に、Softmax層を通して誤差勾配を非正規化係数レベルまで伝播します。
if(!cAssetTime[0].calcHiddenGradients(cSoftMax.AsObject())) return false;
その後、得られた勾配を2番目のデータソースと転置層に分配します。
if(!MatMulGrad(SecondInput, SecondGradient, cTransposeVRC.getOutput(), cTransposeVRC.getGradient(), cAssetTime[0].getGradient(), iAssets, iDimension, iTimePoints, iAgents)) return false;
この時点で、2番目のデータソースの活性化関数を確認し、必要に応じて対応する導関数を用いて誤差勾配を調整します。
if(SecondActivation != None) if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false;
この段階で、勾配はCSAモジュール(2番目のデータソースとして機能)に渡されます。残りは、Temporal Attentionモジュール(主要情報ストリーム)への勾配伝達を完了することです。このモジュールは、アテンション係数と結果の2つの情報フローを介して勾配を受け取ります。現在、これら2つのストリームからのデータはデータ転置オブジェクトの異なるバッファに格納されています。主要勾配バッファには、アテンション係数フローから転置された値があります。3次元テンソル転置オブジェクトのコア機能を使用して、これらの値を入力レベルに伝播します。
if(!NeuronOCL.calcHiddenGradients(cTransposeVRC.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cTransposeVRC.getPrevOutput(), NeuronOCL.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
次に、両方の情報ストリームからのデータを合計します。最後に、主要ストリームの活性化関数の導関数に従って、結果として得られる勾配を調整します。
if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), cTransposeVRC.getPrevOutput(), cTransposeVRC.getPrevOutput(), NeuronOCL.Activation())) return false; //--- return true; }
メソッドは、操作の論理結果を呼び出し元プログラムに返して終了します。
モデルのパラメータを更新するメソッドについては、個別に確認することをお勧めします。CNeuronPortfolioGeneratorクラスとそのすべてのメソッドの完全なソースコードは添付ファイルで提供されています。
MASAATフレームワークの組み立て
個々のMASAATフレームワークブロックの機能は既に実装済みであり、次はそれらを統合された構造に組み立てます。この統合はCNeuronMASAATクラスに実装されています。親オブジェクトとして、先に作成したCNeuronPortfolioGeneratorを選択しました。これはMASAAT実装の最終ブロックを表します。この選択により、必要な機能はすべて継承されるため、このモジュールを新しいクラスの内部オブジェクトとして宣言する必要はありません。新しいクラスの構造は以下のとおりです。
class CNeuronMASAAT : public CNeuronPortfolioGenerator { protected: CNeuronTransposeOCL cTranspose; CNeuronPLRMultiAgentsOCL cPLR; CNeuronBaseOCL cConcat; CNeuronCrossSectionalAnalysis cCrossSectionalAnalysis; CNeuronTemporalAnalysis cTemporalAnalysis; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMASAAT(void) {}; ~CNeuronMASAAT(void) {}; //--- //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMASAAT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
このクラス構造では、以前に作成されたすべてのオブジェクトの宣言が表示されます。ご覧の通り、すべてのメソッドのアルゴリズムは、内部オブジェクトの対応するメソッドを順番に呼び出すことで構築されます。メソッドの実装を進めると、実行順序がより明確になります。
すべての内部オブジェクトは静的に宣言されているため、コンストラクタとデストラクタは空のままにできます。宣言および継承されたすべてのオブジェクトの初期化は、Initメソッドで実行されます。
bool CNeuronMASAAT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_cout, uint layers, vector<float> &min_distance, uint projection, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPortfolioGenerator::Init(numOutputs, myIndex, open_cl, window, units_cout / 3, window_key, (uint)min_distance.Size() + 1, projection, optimization_type, batch)) return false;
このメソッドのパラメータには、入力データの構造を記述し、初期化されるオブジェクトのアーキテクチャを定義するキー定数が含まれます。
メソッド本体では、確立された慣例に従い、継承されたオブジェクトと基本インターフェースを初期化するためのロジックが含まれる親クラスの初期化メソッドを直ちに呼び出します。ただし、この場合、親クラスはより広範なアルゴリズム内で完全に機能するブロックとして使用されることに注目に値します。このモジュールは、MASAAT実装の最終出力として使用されます。したがって、親オブジェクトの正しい初期化パラメータを決定するには、少し先を見据える必要があります。
親オブジェクトの入力には、CSAモジュールとTAモジュールの結果を供給する予定です。これらのモジュールでは、分析される資産の数は入力ウィンドウのサイズに等しく、時間ポイントの数は入力シーケンスの長さに対応します。しかし、元のマルチモーダル時系列に区分線形表現への変換を適用しているため、時間ポイントの数は3分の1に減少します。したがって、親クラスの初期化メソッドにパラメータを渡す際は、元のシーケンスの長さを3で割る必要があります。
パラメータをさらに確認すると、エージェントの数に行き当たります。前述のように、マルチエージェント変換オブジェクトの構築では、エージェントの数は閾値偏差のベクトルの長さによって決まります。しかし、MASAATの著者による個々のフレームワークコンポーネントの分析を考慮すると、時系列の区分線形表現を元の時系列と組み合わせることで、モデルの効率が向上することがわかります。したがって、エージェントの数を1つ増やし、追加のエージェントを変更されていない元の時系列で作業するように割り当てます。
その他のパラメータはすべて変更せずに渡されます。
親クラスの初期化が正常に完了したら、新しく宣言されたオブジェクトの初期化に進みます。まず、データ転置オブジェクトを初期化します。
if(!cTranspose.Init(0, 0, OpenCL, units_cout, window, optimization, iBatch)) return false;
次に、分析対象シーケンスの区分線形表現を生成するマルチエージェント変換オブジェクトを初期化します。
if(!cPLR.Init(0, 1, OpenCL, window, units_cout, false, min_distance, optimization, iBatch)) return false;
変換結果は元のデータと連結されます。そのため、対応するサイズの全結合層を初期化します。
if(!cConcat.Init(0, 2, OpenCL, cTranspose.Neurons() + cPLR.Neurons(), optimization, iBatch)) return false;
最後に、CSAモジュールとTAモジュールを初期化します。両者は同じソースデータで動作するため、同一のパラメータを受け取ります。
if(!cCrossSectionalAnalysis.Init(0, 3, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; if(!cTemporalAnalysis.Init(0, 4, OpenCL, units_cout, window_key, heads, heads / 2, window, layers, 1, iAgents, optimization, iBatch)) return false; //--- return true; }
すべての内部オブジェクトを正常に初期化した後は、操作の論理結果を呼び出し元プログラムに返して、メソッドを終了します。
次に、feedForwardメソッド内の順方向パスアルゴリズムに進みます。ここではすべてが非常に簡潔です。メソッドのパラメータは入力データオブジェクトへのポインタを提供し、それをすぐに同じ名前の転置オブジェクトのメソッドに渡します。
bool CNeuronMASAAT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
結果のデータは、区分線形時系列表現のいくつかのバージョンに変換され、出力は転置形式ではありますが、元のデータと連結されます。
if(!cPLR.FeedForward(cTranspose.AsObject())) return false; if(!Concat(cTranspose.getOutput(), cPLR.getOutput(), cConcat.getOutput(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
準備されたデータは、その後CSAモジュールとTAモジュールに渡され、その出力は親クラスの対応するメソッドに提供されます。
if(!cCrossSectionalAnalysis.FeedForward(cConcat.AsObject())) return false; if(!cTemporalAnalysis.FeedForward(cConcat.AsObject())) return false; //--- return CNeuronPortfolioGenerator::feedForward(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput()); }
最後に、親クラスのfeedForwardメソッドを呼び出し、論理結果を返してメソッドを終了します。
この順方向パスの一見単純な処理の裏には、情報フローの複雑な分岐があります。転置された元のデータと連結されたテンソルの両方が2回使用されていることに注意してください。これにより、calcInputGradientsメソッド内での誤差勾配分布の構成が複雑になります。
calcInputGradientsメソッドでは、誤差勾配を受け取る必要のある入力データオブジェクトへのポインタをパラメータとして受け取ります。メソッド本体では、まず受け取ったポインタの妥当性を確認します。
bool CNeuronMASAAT::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
その後、同名の親クラスメソッドを呼び出して、モデル出力への影響に応じてCSAモジュールとTAモジュール間でエラー勾配を分散します。
if(!CNeuronPortfolioGenerator::calcInputGradients(cTemporalAnalysis.AsObject(), cCrossSectionalAnalysis.getOutput(), cCrossSectionalAnalysis.getGradient(), (ENUM_ACTIVATION)cCrossSectionalAnalysis.Activation())) return false;
両方のモジュールは連結されたテンソルに対して動作します。したがって、勾配は2つの異なる情報フローからこのテンソルに伝播される必要があります。まず1つのモジュールから勾配を渡します。
if(!cConcat.calcHiddenGradients(cCrossSectionalAnalysis.AsObject())) return false;
次に、バッファ置換技術を適用して2番目のストリームから勾配を取得し、両方のソースからの情報を合計します。
CBufferFloat *grad = cConcat.getGradient(); if(!cConcat.SetGradient(cConcat.getPrevOutput(), false) || !cConcat.calcHiddenGradients(cTemporalAnalysis.AsObject()) || !SumAndNormilize(grad, cConcat.getGradient(), grad, 1, 0, 0, 0, 0, 1) || !cConcat.SetGradient(grad, false)) return false;
連結されたテンソルの勾配は、連結されたオブジェクト間に分配されます。この時点で、データ転置オブジェクトは別のストリームを介して勾配を受け取ることが想定されているため、補助データバッファを使用します。
if(!DeConcat(cTranspose.getPrevOutput(), cPLR.getGradient(), cConcat.getGradient(), cTranspose.Neurons(), cPLR.Neurons(), 1)) return false;
オブジェクト間の勾配分布を続ける前に、活性化関数の導関数による補正が必要かどうか確認します。
if(cPLR.Activation() != None) if(!DeActivation(cPLR.getOutput(), cPLR.getGradient(), cPLR.getGradient(), cPLR.Activation())) return false;
次に、マルチエージェント区分線形変換オブジェクトを通じて勾配を伝播し、両方のストリームからの値を合計します。
if(!cTranspose.calcHiddenGradients(cPLR.AsObject()) || !SumAndNormilize(cTranspose.getGradient(), cTranspose.getPrevOutput(), cTranspose.getGradient(), iDimension, false, 0, 0, 0, 1)) return false;
必要に応じて活性化関数の導関数に基づいて勾配を調整し、入力レベルに戻します。
if(cTranspose.Activation() != None) if(!DeActivation(cTranspose.getOutput(), cTranspose.getGradient(), cTranspose.getGradient(), cTranspose.Activation())) return false; if(!prevLayer.calcHiddenGradients(cTranspose.AsObject())) return false; //--- return true; }
最後に、メソッドは操作の論理結果を呼び出し元プログラムに返して終了します。
これで、MASAATアプローチのアルゴリズム実装に関する検討は終了です。提示されたすべてのクラスとメソッドの完全なソースコードは添付ファイルにあります。そこにはこの記事の作成に使用されたすべてのプログラムやモデルアーキテクチャも含まれています。ここでは、モデルアーキテクチャについて簡単に触れます。私たちのMASAATフレームワークの実装はActorモデルに統合されています。ここでは完全なアーキテクチャについては検討しません。ほぼ完全に以前の作業から継承されています。代わりに、新しい層の宣言を見てみましょう。
動的なウィンドウサイズの配列では、分析対象のデータウィンドウのサイズと、出力層によって生成される隠れ状態テンソルの長さを指定します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMASAAT; //--- Windows { int temp[] = {BarDescr, LatentCount}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; }
3つのエージェントの閾値は、等比数列として生成されました。
//--- Min Distance { vector<float> ones = vector<float>::Ones(3); vector<float> cs = ones.CumSum() - 1; descr.radius = pow(ones * 2, cs) * 0.01f; }
その他すべてのパラメータは標準値を保持します。
descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
前述のとおり、モデルの完全なアーキテクチャは添付ファイルで確認できます。
テスト
私たちのMQL5におけるMASAATフレームワーク手法の実装作業は、論理的に完了しました。次の最も重要な段階は、実装した手法を実際の過去データに対して評価することです。
ここで強調すべきは、評価対象は実装された手法であり、元のMASAATフレームワークそのものではないという点です。これは、実装過程でいくつかの修正が加えられたためです。
モデルはEURUSDの2023年の履歴データ(H1時間足)を用いて学習されました。解析対象のすべてのインジケーターは、デフォルトパラメータ設定で使用されています。
初期学習段階では、以前の研究で収集したデータセットを使用し、Actorの現行戦略に適応するため、学習中にデータセットは定期的に更新されました。
複数サイクルの学習およびデータセット更新を経て、学習およびテストデータの両方で利益を示す方策を取得しました。
学習済み方策の最終テストは、2024年1月の履歴データに対して実施され、その他のパラメータはすべて固定されました。以下にそのテスト結果を示します。
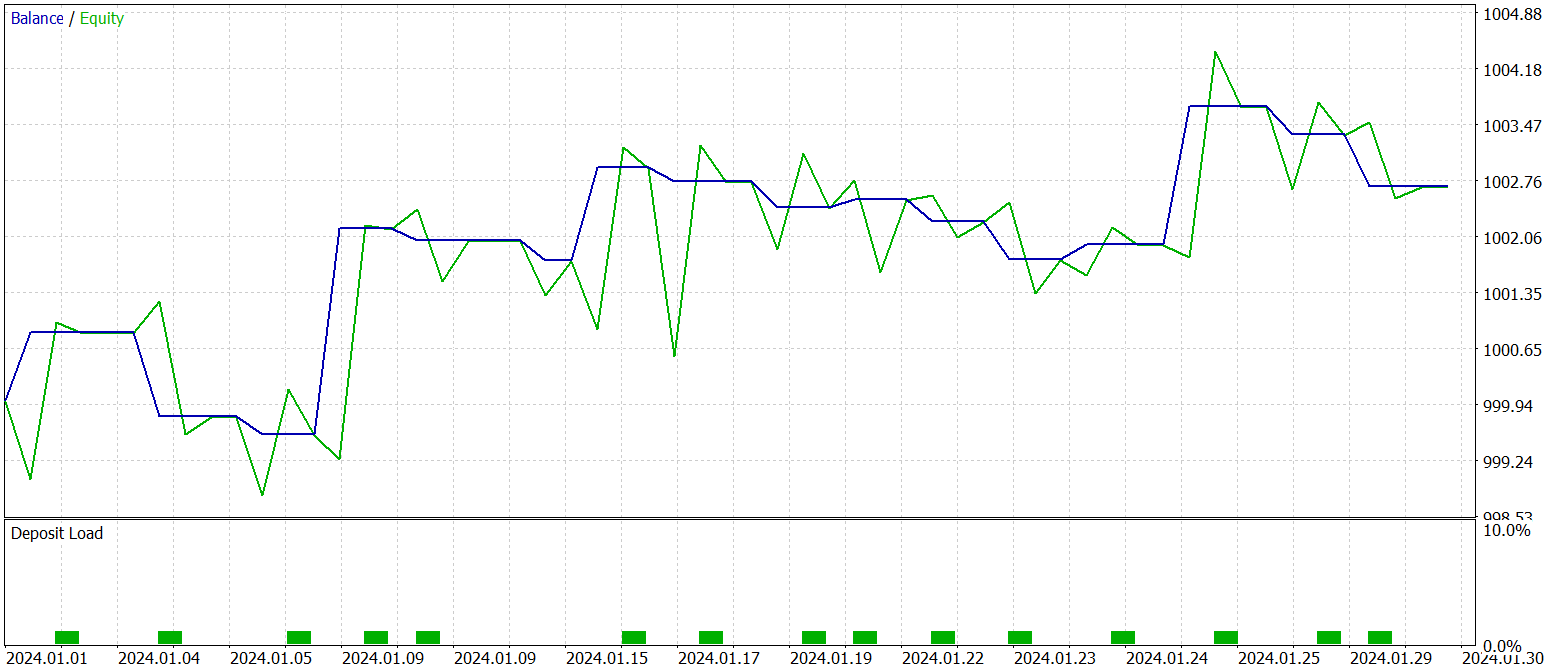
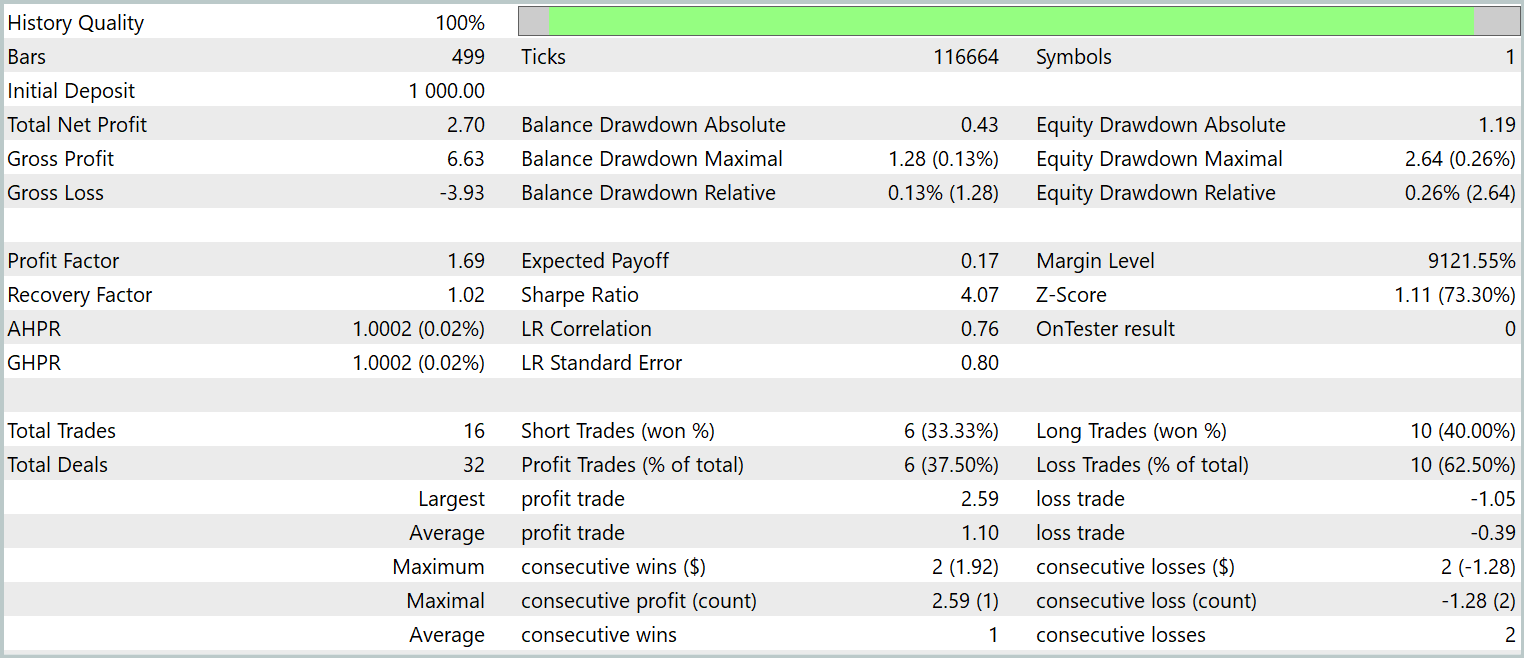
データからわかるように、テスト期間中にモデルは合計16回の取引を実行しました。そのうち利益で終了した取引は約3分の1強でした。しかし、最大利益取引は最大損失の2.5倍に達しています。さらに、1取引あたりの平均利益は平均損失の3倍に相当します。その結果、口座残高には明確な上昇傾向が見られます。
結論
本研究では、投資ポートフォリオの最適化を目的としたマルチエージェント適応型MASAATフレームワークを検討しました。MASAATはアテンション機構と時系列解析を組み合わせています。このフレームワークでは、複数の取引エージェントを用いて価格データを多面的に解析し、取引判断におけるバイアスを低減します。各エージェントはアテンション機構に基づく銘柄間分析(Cross-Sectional Analysis)を適用し、観測期間内の資産間および時間ポイント間の相関を特定します。この情報は、時空間融合モジュールを介して統合され、データの効果的な結合と取引戦略の強化を可能にします。
実践部分では、提案手法の独自の解釈をMQL5で実装しました。これらのアプローチをモデルに統合し、実際の過去データを用いて学習をおこないました。学習済みモデルのテスト結果は、提案手法の潜在的な有効性を示しています。
参照文献
- Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
- 本連載の他の記事
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16631
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索