記事についてのディスカッション
別のプロジェクトで、20~50行のループにおける高速誤差計算と古典的な誤差計算の比較を行いました。(5万行、数百万行でも同じ累積誤差があると仮定します)
まず50行のデータを目で見て比較しました。エラーはない。
しかし、エラーは累積総和とみなされる。各計算で1e-14 ...1e-17の誤差がある。これらの誤差を何回も加えると、合計誤差は1e-5を超える。
もっと深く比較してみた。50,000行を計算し、誤差を比較した。結果は以下の通り。
1e-4以上の累積誤差(つまり小数点第4位の差)が個々にある。
スピードは確かに良いが、文字列が5万ではなく5億になるとしたら?ループ内の正確な計算とは全く比較にならない結果になると思います。
fast_error= 9.583545e+02 true_error= 9.582576e+02
fast_error= 9.204969e+02 true_error= 9.204000e+02
fast_error= 8.814563e+02 true_error= 8.813594e+02
fast_error= 8.411763e+02 true_error= 8.410794e+02
fast_error= 7.995969e+02 true_error= 7.995000e+02
fast_error= 7.566543e+02 true_error= 7.565574e+02
fast_error= 7.246969e+02 true_error= 7.246000e+02
fast_error= 6.916562e+02 true_error= 6.915593e+02
fast_error= 6.574762e+02 true_error= 6.573793e+02
fast_error= 6.220969e+02 true_error= 6.220000e+02
fast_error= 5.854540e+02 true_error= 5.853571e+02
fast_error= 5.588969e+02 true_error= 5.588000e+02
fast_error= 5.313562e+02 true_error= 5.312593e+02
fast_error= 5.027762e+02 true_error= 5.026792e+02
fast_error= 4.730969e+02 true_error= 4.730000e+02
fast_error= 4.422538e+02 true_error= 4.421569e+02
fast_error= 4.205969e+02 true_error= 4.205000e+02
fast_error= 3.980561e+02 true_error= 3.979592e+02
fast_error= 3.745761e+02 true_error= 3.744792e+02
fast_error= 3.500969e+02 true_error= 3.500000e+02
fast_error= 3.245534e+02 true_error= 3.244565e+02
fast_error= 3.072969e+02 true_error= 3.072000e+02
fast_error= 2.892560e+02 true_error= 2.891591e+02
fast_error= 2.703760e+02 true_error= 2.702791e+02
fast_error= 2.505969e+02 true_error= 2.505000e+02
fast_error= 2.298530e+02 true_error= 2.297561e+02
fast_error= 2.164969e+02 true_error= 2.164000e+02
fast_error= 2.024559e+02 true_error= 2.023590e+02
fast_error= 1.876759e+02 true_error= 1.875789e+02
fast_error= 1.720969e+02 true_error= 1.720000e+02
fast_error= 1.556525e+02 true_error= 1.55556e+02
fast_error= 1.456969e+02 true_error= 1.456000e+02
fast_error= 1.351557e+02 true_error= 1.350588e+02
fast_error= 1.239757e+02 true_error= 1.238788e+02
fast_error= 1.120969e+02 true_error= 1.120000e+02
fast_error= 9.945174e+01 true_error= 9.935484e+01
fast_error= 9.239691e+01 true_error= 9.230000e+01
fast_error= 8.485553e+01 true_error= 8.475862e+01
fast_error= 7.677548e+01 true_error= 7.667857e+01
fast_error= 6.809691e+01 true_error= 6.800000e+01
fast_error= 5.875075e+01 true_error= 5.865385e+01
fast_error= 5.409691e+01 true_error= 5.400000e+01
fast_error= 4.905524e+01 true_error= 4.895833e+01
fast_error= 4.357517e+01 true_error= 4.347826e+01
fast_error= 3.759691e+01 true_error= 3.750000e+01
fast_error= 3.104929e+01 true_error= 3.095238e+01
fast_error= 2.829691e+01 true_error= 2.820000e+01
fast_error= 2.525480e+01 true_error= 2.515789e+01
fast_error= 2.187468e+01 true_error= 2.17777878e+01
fast_error= 1.809691e+01 true_error= 1.800000e+01
fast_error= 1.384691e+01 true_error= 1.375000e+01
fast_error= 1.249691e+01 true_error= 1.240000e+01
fast_error= 1.095405e+01 true_error= 1.085714e+01
fast_error= 9.173829e+00 true_error= 9.076923e+00
fast_error= 7.096906e+00 true_error= 7.000000e+00
fast_error= 4.642360e+00 true_error= 4.545455e+00
fast_error= 4.196906e+00 true_error= 4.100000e+00
fast_error= 3.652461e+00 true_error= 3.555556e+00
fast_error= 2.971906e+00 true_error= 2.875000e+00
fast_error= 2.096906e+00 true_error= 2.0000000000e+00
fast_error= 9.302390e-01 true_error= 8.3333333333e-01
fast_error= 8.96909057e-01 true_error= 8.000000e-01
fast_error= 8.469057e-01 true_error= 7.500000e-01
fast_error= 7.635724e-01 true_error= 6.66666667e-01
fast_error= 5.969057e-01 true_error= 5.000000e-01
fast_error= 4.546077e+00 true_error= 4.545455e+00
fast_error= 4.100623e+00 true_error= 4.100000e+00
fast_error= 3.556178e+00 true_error= 3.555556e+00
fast_error= 2.875623e+00 true_error= 2.875000e+00
fast_error= 2.000623e+00 true_error= 2.000000e+00
fast_error= 8.339561e-01 true_error= 8.33333e-01
fast_error= 8.006228e-01 true_error= 8.000000e-01
fast_error= 7.506228e-01 true_error= 7.500000e-01
fast_error= 6.672894e-01 true_error= 6.666667e-01
fast_error= 5.006228e-01 true_error= 5.000000e-01
何が問題なのでしょうか?
トレーニング中にターミナルがクラッシュしてエラーが出るんだ。
N 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
MP 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL プログラムの作成に失敗しました。Error code=4003
CD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OnInit - 153 -> Error of reading EURUSD_PERIOD_H1_ 20AttentionMLMH_d.nnw prev Net 5015
RD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
QN 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL プログラムの作成に失敗しました。Error code=4003
IO 0 22:58:20.933 Core 1 final balance 10000.00 USD
LE 2 22:58:20.933 Core 1 2021.02.19 23:54:59 invalidpointer access in 'NeuroNet.mqh' (2271,16)
MS 2 22:58:20.933 Core 1 OnDeinit critical error
NG 0 22:58:20.933 Core 1 EURUSD,H1: 863757 ticks, 360 bars generated.環境は 0:00:00.018 に同期しました。
QD 0 22:58:20.933 Core 1 EURUSD,H1: ログインからテスト停止までの合計時間 0:00:00.274 (ヒストリデータ同期用の 0:00:00.018 を含む)
LQ 0 22:58:20.933 Core 1 使用メモリ 321 Mb (ヒストリデータ 0. 47 Mb、64 Mb を含む)。47 Mb of history data, 64 Mb of tick data
JF 0 22:58:20.933 Core 1 log file "C:◆UsersBuruy\AppData\Roaming◇MetaQuotes◇Tester◇36A64B8C79A6163D85E6173B540966◇Agent-127.0.0.0.1-3000logs\20210410.log" written
PP 0 22:58:20.939 Core 1 connection closed
よろしくお願いします!
ドミトリーこんにちは!数ヶ月の間、私はOOSの実行と同じ間隔の最終的な作業の間に強い不一致を観察しますが、すでにExpert Advisorです。すべてのシグナルは統一されています(私は各バーごとにすべてのシグナルをファイルにアンロードして比較します)。トレーニングの保存と読み込みのプロセスが正しく機能していない疑いがあります。各ネットワークのNeuroNet.mphファイルには、トレーニングの保存方法が個別に設定されています。
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
その他
保存は
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
この違いについて説明してください。また、保存されたデータとエポック後のメモリからのトレーニングをマッチさせることは可能ですか?
学習時の出力信号データTempDataと出力ニューロンResultData
を出力し、テスト時には別々に出力します。WinMergeプログラムで両方のファイルを比較しました。
{kind=link}
ドミトリーこんにちは!数ヶ月の間、私はOOSの実行と同じ間隔の最終的な作業の間に強い不一致を観察しますが、すでにExpert Advisorです。すべてのシグナルは統一されています(私は各バーごとにすべてのシグナルをファイルにアンロードして比較します)。トレーニングの保存と読み込みのプロセスが正しく機能していない疑いがあります。各ネットワークのNeuroNet.mphファイルには、トレーニングの保存方法が個別に設定されています。
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
その他
保存は
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
この違いについて説明してください。また、保存されたデータとエポック後のメモリからのトレーニングをマッチさせることは可能ですか?
学習時の出力信号データTempDataと出力ニューロンResultData
を出力し、テスト時には別々に出力します。WinMergeプログラムで両方のファイルを比較しました。
CNet::Save(...)メソッドを見てみましょう。ネットワークの学習 状態を特徴づける変数を記録した後、ニューラル・レイヤーの配列(CArrayObjから継承したCArrayLayer)のSaveメソッドが呼ばれます。
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return true; if(file_name==NULL) return false; //--- int handle=FileOpen(file_name,(common ? FILE_COMMON : 0)|FILE_BIN|FILE_WRITE); if(handle==INVALID_HANDLE) return false; //--- if(FileWriteDouble(handle,error)<=0 || FileWriteDouble(handle,undefine)<=0 || FileWriteDouble(handle,forecast)<=0 || FileWriteLong(handle,(long)time)<=0) { FileClose(handle); return false; } bool result=layers.Save(handle); FileFlush(handle); FileClose(handle); //--- return result; }
CArrayLayerクラスはSaveメソッドを持っていないので、親クラス CArrayObj::Save(const int file_handle)のメソッドが呼ばれる 。このメソッドのボディは全てのネストされたオブジェクトを列挙し、各オブジェクトのSaveメソッドを呼び出すループを含んでいる。
//+------------------------------------------------------------------+ //| 配列のファイルへの書き込み| //+------------------------------------------------------------------+ bool CArrayObj::Save(const int file_handle) { int i=0; //--- チェック if(!CArray::Save(file_handle)) return(false); //--- 配列の長さを書き込む if(FileWriteInteger(file_handle,m_data_total,INT_VALUE)!=INT_VALUE) return(false); //--- 配列を書き込む for(i=0;i<m_data_total;i++) if(m_data[i].Save(file_handle)!=true) break; //--- 結果 return(i==m_data_total); }
つまり、ここでは入れ子人形の原理が使われています。最上位のオブジェクトに対してSaveメソッドを呼び出し、その内部ですべての入れ子オブジェクトが検索され、各オブジェクトに対して同じ名前のメソッドが呼び出されます。
ファイルからのデータのロードも同様の方法で行われる。
トレーニング時と運用時の評価の違いについて。ニューラルネットワークが動作モードでどのように構成されているかは知りませんが、トレーニングモードではニューラルネットワークのパラメータは常に変化しています。従って、同じ入力データでも異なる結果が得られます。
ドミトリー。
P.S. データの保存と読み込みの正しさは、ファイルからニューラルネットワークを読み込み、すぐに新しいファイルに保存する小さなテストプログラムを作成することで確認できます。そして2つのファイルを比較してください。不一致に気づいたら、私に知らせてください。
CNet::Save(...)メソッドを見てみましょう。ネットワークの学習 状態を特徴づける変数を記録した後、ニューラル・レイヤーのレイヤーの配列(CArrayObjから継承したCArrayLayer)のSaveメソッドが呼ばれます。
CArrayLayerクラスはSaveメソッドを持っていないので、親クラス CArrayObj::Save(const int file_handle)のメソッドが呼ばれる 。このメソッドのボディは全てのネストされたオブジェクトを列挙し、各オブジェクトのSaveメソッドを呼び出すループを含んでいる。
つまり、ここでは入れ子人形の原理が使われています。最上位のオブジェクトに対してSaveメソッドを呼び出し、その内部ですべての入れ子オブジェクトが検索され、各オブジェクトに対して同じ名前のメソッドが呼び出されます。
ファイルからデータをロードする場合も同じように構成されます。
トレーニング時と運用時の評価の違いについて。ニューラルネットワークが動作モードでどのように構成されているかは知りませんが、トレーニングモードではニューラルネットワークのパラメータは常に変化しています。従って、同じ入力データでも異なる結果が得られます。
ドミトリー。
P.S. データの保存と読み込みの正しさは、ファイルからニューラルネットワークを読み込み、すぐに新しいファイルに保存する小さなテストプログラムを作成することで確認できます。そして2つのファイルを比較してください。不一致に気づいたら、私に知らせてください。
以下の方法でチェックしてみる。最初のバーで、TempData (Signals) と OUTPUT Neurons をファイルに保存します。まず、ファイルを読み込まずにトレーニングを行い、次に同じ最初のバーからトレーニングを読み込みます。書き戻します。
訓練の過程で本当に各バーにneuronkaを学ぶので、p/s/テスターの過程で、同じプロセスを実装していますが、マイナスN bars.The影響は大きくはないはずです。しかし、私はそれがすべきであることに同意します。
親愛なるドミトリー!
あなたのライブラリの助けを借りて長い作業の過程で、私は5年間のEURUSDで11%のドローダウンとほぼ100%の利益という良い結果を持つトレーディングアドバイザーを作成することができました。
アルパリ
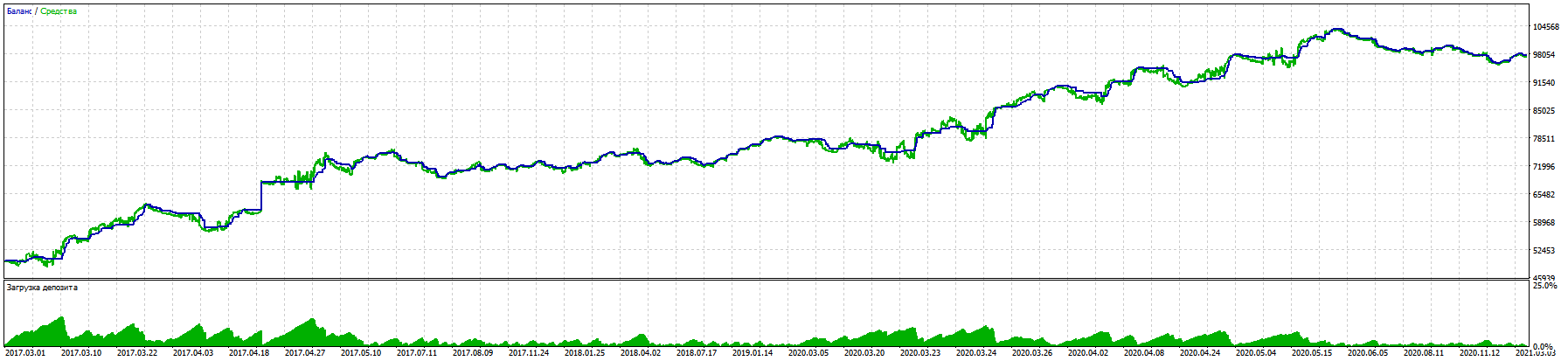
リアル口座でのテストも同じロジックです。
注目すべきは、BKS先物でもRURUSDは同じ入力でさらに良い結果を出していることです。(他のペアではまだテストしていません)。
重要な勝利は、ブラインド取引(過去期間のみでトレーニング)と、マーチンゲールやその他のトリックを使わない強制ストップロスのテストでした。
もちろん、WSEとスタンフォード大学の5週間のコースや、ニューラルネットワークに関する多くの記事、特に何を教えるべきか、何を教えるべきか、どのように教えるべきかを理解する上で、多くのことを学び、補う必要がありました。
本当にありがとう!
どうか立ち止まることなく、ライブラリーの開発を続けてください。
皆さんに考えていただきたいこと
1.トレーニングの保存について。すでに書いた通りではうまくいきません。毎回、取引を中断することなく「いきなり」学ばなければなりません。これは問題ではなく、トレーニングは速いのですが、2つ目の問題があります。
2.スタート時に、プライマリー・ニューロンを作成するようにランダマイズ・ロジックを設定している。このため、最大で3つのバージョンのトレーニングが行われる。(キーポイントは、プライマリー・ニューロンが最初はポジティブかネガティブかということだと思います)。
そうですね、これも正しい測定基準に到達しなければ、いわばゼロから強制的に再トレーニングを行うことで対処できます。
しかし、各ニューロンに条件付きで0.01の重みをつけるところから始めることができるのは確かです。(残念ながらオーバートレーニングはより顕著になる)。
あるいは、やはり教育の最良のコピーを維持するように学習すれば、ポイント1になる。
親愛なるディミトリへ
あなたのライブラリの助けを借りて、長い作業の過程で、私は5年間のEURUSDで11%のドローダウンとほぼ100%の利益という良い結果を持つトレーディングアドバイザーを作成することができました。
アルパリ
リアル口座でのテストも同じロジックです。
注目すべきは、BKS先物でもRURUSDが同じ入力でさらに良い結果を出していることです。(他のペアではまだテストしていません)。
重要な勝利は、ブラインド取引(過去の期間のみでトレーニング)と、マーチンゲールやその他のトリックを使わない強制ストップロスのテストでした。
もちろん、WSEとスタンフォード大学の5週間のコースや、ニューラルネットワークに関する多くの記事から、特に何を教え、何を教え、どのように教えるかを理解する上で、多くのことを勉強し、補足しなければならなかった。
本当にありがとう!
どうか立ち止まることなく、ライブラリーの発展を続けてください。
皆さんに考えていただきたいこと
1.トレーニングの保存について。すでに書いたように、それはうまくいかない。毎回、取引を中断することなく「いきなり」学ばなければならない。これは問題ではありません、トレーニングは高速ですが、第二の問題があります。
2.スタート時に、プライマリー・ニューロンを作成するようにランダマイズ・ロジックを設定している。このため、最大で3つのバージョンのトレーニングが行われる。(キーポイントは、プライマリー・ニューロンが最初はポジティブかネガティブかということだと思います)。
必要なメトリクスに達していない場合は、最初から強制的に再トレーニングを行います。
しかし、各ニューロンに条件付きで0.01の重みをつけるところから始めることもできるはずだ。(残念ながら、オーバートレーニングはより顕著になる)。
あるいは、教育の最良のコピーを維持するように学習することもできます。
Dimitriさん、ご丁寧にありがとうございます。すべての重みを一定の値で開始するのは悪いやり方です。そのような場合、学習中、すべてのニューロンは同期して1つのものとして働きます。そしてニューラルネットワーク全体が、各層で1つのニューロンになってしまう。
....
皆さんに考えていただきたいこと
1.まだトレーニングを続けることについて。すでに書いたように、それはうまくいかない。 毎回、取引を中断することなく「いきなり」学ばなければならない。これは問題ではなく、トレーニングは速いのだが、2つ目の問題がある。
2.スタート時に、プライマリー・ニューロンを作成するようにランダマイズ・ロジックを設定している。このため、最大で3つのバージョンのトレーニングが行われる。(キーポイントは、プライマリー・ニューロンが最初はポジティブかネガティブかということだと思います)。
必要なメトリクスに達していない場合は、最初から強制的に再トレーニングを行います。
しかし、各ニューロンに条件付きで0.01の重みをつけるところから始めることもできるはずだ。(残念ながら、オーバートレーニングはより顕著になる)。
あるいは、教育の最良のコピーを維持するように学習することもできます。
ディミトリ、著者のアドバイス通りにテストしてみました。
1.いくつかのエポックをトレーニングし、各エポックの後にネットワークファイルを保存します。
2.グラフから削除します。パラメータtestSaveLoadを有効にして再実行 - Expert Advisorは以前に学習したネットワークを読み込んだ後、再度書き込みを行い、再度読み込みと書き込みのサイクルを繰り返してアンロードします。
3.3つのファイルを比較し、a)テストを通してプログラミングを学ぶ b)自分自身のエラーを探す。

ありがとう、アレクセイ。
問題は別のところにあることがわかった。
セーブ/ロードのプロセスは機能している。
解決策は、Randomizeを使ってニューロンネットワーク要素を作成する行にありました。
bool CArrayCon::CreateElement(int index) { if(index<0 || index>=m_data_max) return false; //--- xor128; double weigh=(double)rnd_w/UINT_MAX-0.5; m_data[index]=new CConnection(weigh); if(!CheckPointer(m_data[index])!=POINTER_INVALID) return false; //--- return (true); }
ネットワークが販売や購入に傾かないように、プラスとマイナスのニューロンを同数作ることが重要です。
double weigh=(double)MathMod(index,0)?sin(index):sin(-index);
念のため、初期重みを作成する関数も同じようにしました。
double CNeuronBaseOCL::GenerateWeight(void) { xor128; double result=(double)rnd_w/UINT_MAX-0.5; //--- return result; } //+----
バックテストでは、学習ファイルをロードした後、学習済みネットワークを テストしても同じ結果が得られました。
入力は毎秒単位である。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「ニューラルネットワークが簡単に(第13回): Batch Normalization」はパブリッシュされました:
前回の記事では、ニューラルネットワーク訓練の品質を向上させることを目的とした手法の説明を開始しました。本稿では、このトピックを継続し、別のアプローチであるデータのBatch Normalizationについて説明します。
ニューラルネットワークアプリケーションの実践では、データの正規化に対するさまざまなアプローチが使用されています。ただし、これらはすべて、訓練サンプルデータとニューラルネットワークの隠れ層の出力を特定の範囲内に保ち、分散や中央値などのサンプルの特定の統計的特性を維持することを目的としています。ネットワークニューロンは線形変換を使用して訓練の過程でサンプルを逆勾配にシフトするため、これは重要です。
2つの隠れ層を持つ完全に接続されたパーセプトロンを考えてみましょう。フィードフォワードパス中に、各層は次の層の訓練サンプルとして機能する特定のデータセットを生成します。出力層の結果は、参照データと比較されます。次に、フィードバックパス中に、エラー勾配が出力層から隠れ層を介して初期データに向かって伝播されます。各ニューロンでエラー勾配を受け取ったら、重み係数を更新し、最後のフィードフォワードパスの訓練サンプルのニューラルネットワークを調整します。ここで競合が発生します。2番目の隠れ層(下図のH2)は、最初の隠れ層(図のH1)の出力のデータサンプルに調整されますが、データ配列は最初の隠れ層のパラメータを変更することによってすでに 変更されています。つまり、2番目の隠れ層を、存在しなくなったデータサンプルに合わせて調整しているのです。同様の状況は、すでに変更された2番目の隠れ層出力に合わせて調整される出力層でも発生します。1番目と2番目の隠れ層の間の歪みを考慮すると、エラーのスケールはさらに大きくなります。ニューラルネットワークが深いほど、この効果は強くなります。この現象は、内部共変量シフトと呼ばれます。
従来のニューラルネットワークは、学習率を下げることでこの問題を部分的に解決します。重みがわずかに変化しても、ニューラル層の出力でのサンプル分布は大幅には変化しません。しかし、このアプローチでは、ニューラルネットワーク層の数の増加に伴って発生するスケーリングの問題が解決されず、学習速度も低下します。学習率の低さのもう1つの問題は、プロセスが極小値でスタックする可能性があることです。これについては、第6部ですでに説明しました。
作者: Dmitriy Gizlyk