取引におけるニューラルネットワーク:Attentionメカニズムを備えたエージェントのアンサンブル(MASAAT)

はじめに
金融商品のポートフォリオ管理は、投資意思決定の重要な要素であり、資本を複数の資産に動的に配分することで、リスクを最小化しながらリターンを最大化することを目的としています。金融市場は非常に変動が激しく、資産価格は多くの要因に依存するため、利益の最大化とリスクの最小化という相反する目標を同時に達成する最適なポートフォリオの構築は困難です。従来の金融モデルは、さまざまな投資原則に基づいて構築されており、単一市場では有効な場合がありますが、現代の複雑で動的な市場環境下では必ずしも機能しないことがあります。
近年、非定常的な価格系列を分析するための機械学習手法への関心が高まっています。その中でも、深層学習や強化学習戦略は、計算金融において顕著な成果を示しています。しかし、金融市場の価格データは通常ノイズの多い時系列であり、将来のトレンドを示すシグナルを抽出することは困難です。
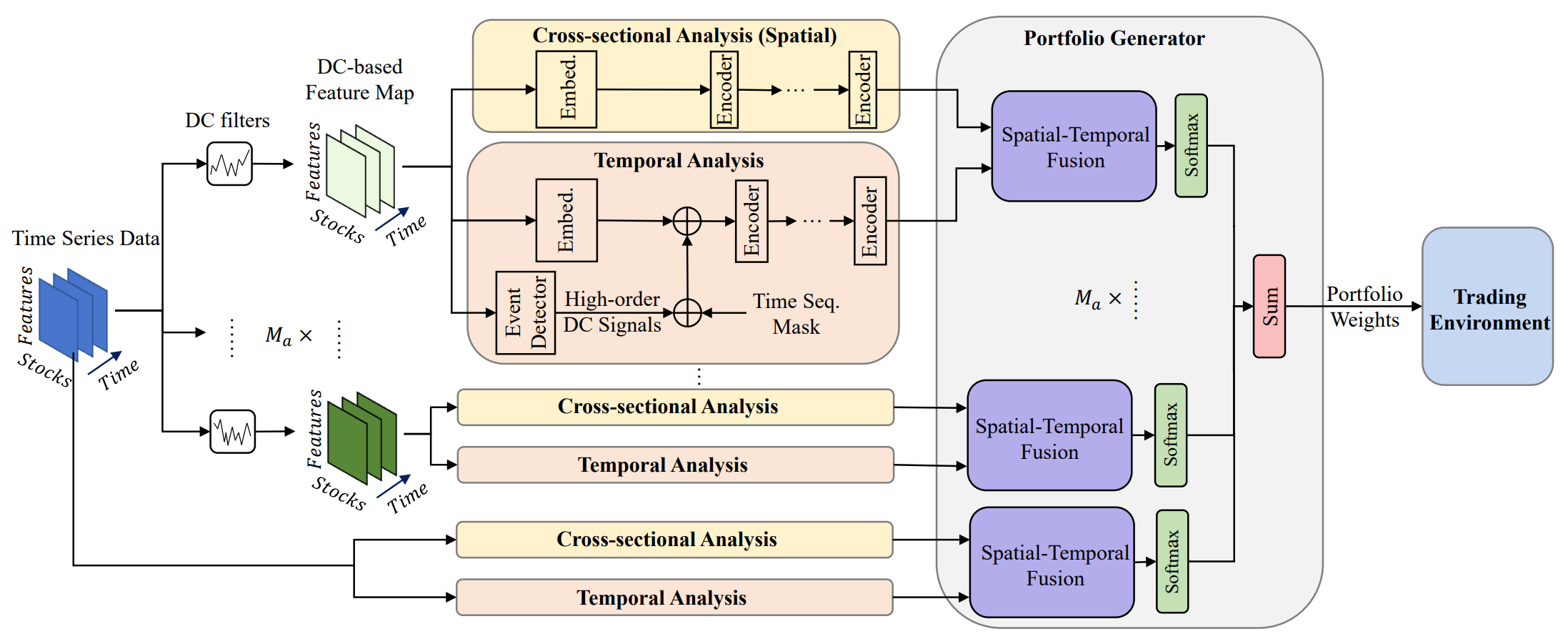
有望なアプローチの一例として、「Developing an attention-based ensemble learning framework for financial portfolio optimisation」という論文が挙げられます。本論文では、Attention機構と時系列解析を統合した革新的な適応型取引フレームワーク(Multi-Agent and Self-Adaptive portfolio optimisation framework integrated with Attention mechanisms and Time series — MASAAT)を紹介しています。本フレームワークでは、複数のエージェントが展開され、資産価格の方向性変化を異なる粒度で観察・分析します。これにより、非常に変動の激しい市場においても、リターンとリスクのバランスを考慮したポートフォリオのリバランスを可能にします。
エージェントはまず、重要な価格変動を捉えるために異なる閾値を用いた方向性変化フィルタを適用し、生の時系列データからトレンド特徴量を抽出します。これにより、複数の視点から市場のレジームシフトを追跡できるようになります。このアプローチは、シーケンス内のトークン生成の新しい方法を導入し、エージェント内のCross-Sectional Attention (CSA)モジュールとTemporal Attention (TA)モジュールが、資産間の相関関係と時間的依存関係の両方を効果的に捉えることを可能にします。具体的には、特徴量マップを再構築する際、CSAモジュールのシーケンストークンは個々の資産特徴量に基づき、資産間で最適な注意埋め込みを生成します。一方、TAモジュールのトークンは個々の時間点に基づき、現在と過去の観測値の関連性を捉えます。
さらに、資産間および時間的依存関係の情報は、時空間注意ブロック内で統合されます。CSAとTAの役割が明確に定義されることで、エージェントは資産トレンドに関するより豊富な洞察を獲得でき、それぞれの視点に基づいたポートフォリオ提案が可能となります。最終的に、異なるエージェントによって生成されたポートフォリオは、新たなアンサンブルポートフォリオとして統合され、現在の市場状況に応じて動的に適応します。単一のエージェントが市場トレンドを誤解し、バイアスのかかった推奨を出した場合でも、MASAATフレームワークはマルチエージェント統合を通じて最終ポートフォリオを適応的に修正し、負の影響を緩和します。
MASAATアルゴリズム
MASAATフレームワークは、複数の方向性変動フィルタを異なる閾値で適用し、マルチスケールの受容野にわたる顕著な価格変動を捉えることで、将来の価格変動に影響を与える可能性のある要因を分析します。これらの受容野は、資産価格のボラティリティの異なるレベルを表しており、エージェントが市場ダイナミクスを直感的に把握できるようにします。MASAATは、CSAモジュールで資産指向の方向性移動特徴量を、TAモジュールで時間点指向の特徴量をシーケンストークンとして再構築し、異なるスケールでの価格変動に関する空間的および時間的情報を同時に収集します。これにより、今後のトレンドの方向と強度の両方を特定することが可能となります。生の価格系列は、まず資産指向および時間指向の特徴量に直接変換され、CSAモジュールとTAモジュールにおいて、それぞれ資産間および時系列的な分析がおこなわれます。
特に、CSAモジュールとTAモジュールはSelf-Attentionエンコーダに基づいて構築されており、アテンションスコアはトークン列全体にわたって計算されます。これにより、畳み込みニューラルネットワーク(CNN)のようにカーネルサイズや局所的な位置構造に依存することなく、すべての資産間で公正な類似度の推定が可能となります。アテンションスコアによってトークン間の類似度を明示的に定量化するため、MASAATが生成する売買シグナルは本質的に高い解釈性を持ちます。空間・時間アテンションブロックを通じて、資産系列と過去の時間系列の間にマッピングが構築されます。このプロセスにより、観測ウィンドウ内の全時点に対する各資産のアテンションスコアを表す埋め込みが生成されます。これらの埋め込みは、ポートフォリオ配分の提案に利用されます。ポートフォリオ生成器は、各エージェントの提案を統合して再構成し、市場環境の変化に適応するアンサンブルポートフォリオを形成します。
ここで、Nを資産の数、 Mを観測可能な市場特徴量の数、 M aを取引エージェントの数とします。ある一定の履歴深度に対して、各エージェントはまず観測ウィンドウT wにおける価格特徴量𝐏∈R N ×M×T wを観測します。その後、方向性変動フィルタを用いて、トレンドベースの関数𝐏DC={𝐏DC,1, 𝐏DC,2,…,𝐏DC,𝐌a} ∈ RMa, 𝐏DC,i ∈ RN×M×Twを抽出します。前述のとおり、これらの𝐏 DC,iはCSAモジュール用に𝐏DC ,i, CSA ∈ R N ×MT wに、ТАモジュール用に𝐏 DC,i,TA ∈ R T w ×NMに変換されます。その後、Transformerエンコーダによって相互依存関係が分析されます。同様に、生の価格系列𝐏も𝐏CSA∈RN × MTwおよび𝐏TA∈RTw × NMに変換されます。
トークン依存性の分析後、CSAモジュールとTAモジュールは、資産指向の埋め込み𝐎 CSA ∈ R N ×Dおよび時間指向の埋め込み𝐎 TA ∈ R T w× Dを出力します。ここで、 Dは埋め込みベクトルの次元です。これらの埋め込みは統合され、更新されたポートフォリオを構築します。その後、他のエージェントの出力と統合され、最終的な依存ベクトルW𝐭を取得し、ポートフォリオをさらに洗練します。
取引操作が実行された後、報酬rtが収集され、経験リプレイバッファĎにW𝐭、𝐏、𝐏DCと共に格納されます。また、Actor方策πは、ポリシー勾配法を用いてĎからサンプリングすることで逐次更新されます。
一般に、高いリターンは高リスクを伴うことが多いため、分散投資は非常に重要であり、かつ難易度も高いです。エージェントは、ヘッジ効果を達成するために異質な資産に適切な重みを割り当てる必要があります。そのため、資産間の相関を継続的に学習することにより、変動の激しい市場環境下でもリスクをより効果的に管理できます。
トレンド特徴量は、Self-Attentionエンコーダを通じて相関分析の前にシーケンストークンに変換されます。最適化されたアテンションベクトルは資産間の相関を定量化し、類似したアテンションベクトルを持つ資産は関連特性を共有していると推定されます。
資産間の相関に加え、MASAATは観測ウィンドウ間の時間的関連性も調査し、複数レベルでの価格トレンド予測を目指します。この場合、各時点はシーケンストークンとして扱われ、Transformerエンコーダを通じて時点間の相関が学習されます。類似したアテンションベクトルを持つ2つの時点は、同様のトレンド動態を共有していると見なされます。
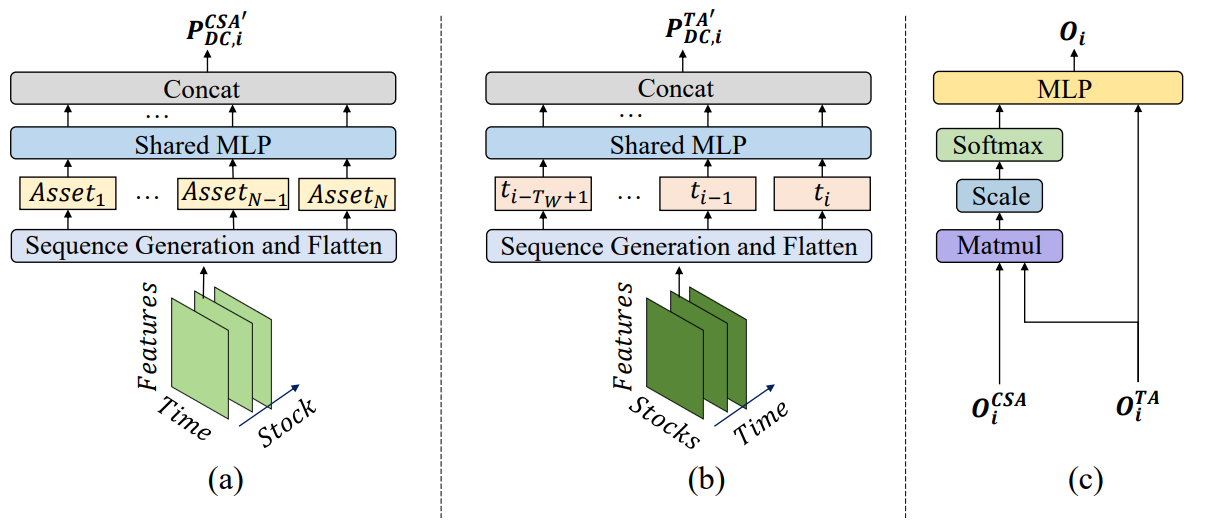
CSAモジュールとTAモジュールからの情報を統合することで、MASAATエージェントは資産レベルおよび時間レベルのアテンションスコアを組み合わせ、観測期間内の各時点に対する各資産の重要度を推定します。各エージェントが提案するポートフォリオは次の式で表されます。
![]()
ここで𝐕iとbiはMLPの学習可能なパラメータです。
異なる粒度で価格変動を観測する複数のエージェントの出力は統合され、現在の金融環境に応じたアンサンブルポートフォリオが形成されます。個別エージェントによって生成されるポートフォリオと比較すると、MASAATのマルチエージェント構造は、多様な視点から導出された複数の候補ポートフォリオを提供します。これにより、特に高ボラティリティ市場において、システムの適応性が大幅に向上します。
MASAATフレームワークのオリジナルの可視化を以下に示します。
MQL5での実装
MASAATフレームワークの理論的側面について説明した後、本記事の実践的な部分に移り、MQL5を用いて提案手法を解釈した実装例を紹介します。前述のとおり、MASAATは包括的なフレームワークです。異なるブロック間で機能を明確に分離するために、MASAATの各機能を担当する独立オブジェクトで構成されるモジュール構造として設計します。
まずはトレンド検出メカニズムから始めます。時系列に対する区分線形(PLR: piecewise linear representation)層は、局所的なトレンドを識別するのに適しています。しかし、制約があります。以前実装されたオブジェクトは単一エージェントとしてしか動作できませんでした。MASAATでは複数エージェントを用いた柔軟なモデル構築が必要なため、よりスケーラブルな解決策が求められます。
1つの方法として、解析対象の時系列に対して複数のPLRオブジェクトへのポインタを格納する動的配列を用いる方法が考えられます。それぞれのオブジェクトは異なる閾値で動作します。しかし、この方法では逐次実行になり、最適ではありません。そこで、複数のトレンド検出エージェントを並列で動作させる新しいオブジェクトを開発します。そのためには、まずOpenCLプログラムに新しいカーネルを追加する必要があります。
OpenCLプログラムの拡張
既存のPLRカーネルを適応させる際、単一の閾値パラメータをエージェントごとの閾値ベクトルに置き換える必要がありました。この変更には、カーネルアルゴリズムの修正だけでなく、依存オブジェクトの再構築も伴います。開発を簡略化するため、既存実装のロジックを部分的に再利用しつつ、新しい順伝播および逆伝播カーネルを作成しました。
順伝播については、PLRMultiAgentsカーネルを開発しました。このカーネルは4つのデータバッファポインタを受け取ります。2つのバッファには生の時系列データとエージェントごとの閾値が格納され、残りの2つのバッファには分析結果とトレンド反転フラグが格納されます。
__kernel void PLRMultiAgents(__global const float *inputs, __global float *outputs, __global int *isttp, const int transpose, __global const float *min_step ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1); const size_t a = get_global_id(2); const size_t agents = get_global_size(2);
このカーネルは3次元タスク空間で実行されます。第1次元は解析対象シーケンスのサイズに対応します。第2次元はマルチモーダルシーケンス内の単変量系列の数に対応します。第3次元はエージェントの数に対応します。カーネル内では、各スレッドが全タスク次元における自身の位置を特定します。その後、データバッファ内のオフセットを決定します。
//--- constants const int shift_in = ((bool)transpose ? (i * variables + v) : (v * lenth + i)); const int step_in = ((bool)transpose ? variables : 1); const int shift_ag = a * lenth * variables;
重要な点として、すべてのエージェントは同じマルチモーダルシーケンスを解析します。そのため、エージェント識別子は、結果および閾値バッファのオフセットにのみ影響します。
初期化後、カーネルはトレンド反転点(極値)の探索を開始します。各フローは、現在の要素の位置にトレンド反転点が存在するかどうかを判定します。解析対象の時系列の極値は、セグメントの極値であることが事前に分かっているため、自動的にトレンド反転点としてのステータスが付与されます。
//--- look for ttp float value = IsNaNOrInf(inputs[shift_in], 0); bool bttp = false; if(i == 0 || i == lenth - 1) bttp = true;
その他の点については、アルゴリズムは閾値を超える偏差を持つ最も近い要素を逆方向に探索します。この過程で、確認した区間内の最小値と最大値を記録します。
else { float prev = value; int prev_pos = i; float max_v = value; float max_pos = i; float min_v = value; float min_pos = i; while(fmax(fabs(prev - max_v), fabs(prev - min_v)) < min_step[a] && prev_pos > 0) { prev_pos--; prev = IsNaNOrInf(inputs[shift_in - (i - prev_pos) * step_in], 0); if(prev >= max_v && (prev - min_v) < min_step[a]) { max_v = prev; max_pos = prev_pos; } if(prev <= min_v && (max_v - prev) < min_step[a]) { min_v = prev; min_pos = prev_pos; } }
必要な偏差を持つ次の要素を前方に検索します。
float next = value; int next_pos = i; while(fmax(fabs(next - max_v), fabs(next - min_v)) < min_step[a] && next_pos < (lenth - 1)) { next_pos++; next = IsNaNOrInf(inputs[shift_in + (next_pos - i) * step_in], 0); if(next > max_v && (next - min_v) < min_step[a]) { max_v = next; max_pos = next_pos; } if(next < min_v && (max_v - next) < min_step[a]) { min_v = next; min_pos = next_pos; } }
現在の要素が極値として適格かどうかを判断します。
if( (value >= prev && value > next) || (value > prev && value == next) || (value <= prev && value < next) || (value < prev && value == next) ) if(max_pos == i || min_pos == i) bttp = true; }
しかし、ここで忘れてはならないのは、最小限必要な偏差を持つ要素を探索する際に、極値のプラトーを形成する複数の要素から値の集合(コリドー)を取得する可能性があることです。そのため、要素がそのようなコリドー内で極値である場合にのみ、フラグが付与されます。同じ値を持つ要素が複数存在する場合は、最初の要素に極値フラグを割り当てます。
取得したフラグを保存し、出力バッファをクリアします。同時に、ワークグループ内のフローを同期させます。
isttp[shift_in + shift_ag] = (int)bttp; outputs[shift_in + shift_ag] = 0; barrier(CLK_LOCAL_MEM_FENCE);
後続のステップは、確認済みのトレンド反転に関連するスレッドのみが実行します。それ以外のスレッドは設定された条件を満たさないため、実質的に操作を完了します。
まず、現在の極値の位置を特定します。そのために、保存されたフラグに基づき、解析対象位置までのすべての先行極値をカウントし、元のデータバッファから前回の極値の位置をローカルバッファに保存します。
//--- calc position int pos = -1; int prev_in = 0; int prev_ttp = 0; if(bttp) { pos = 0; for(int p = 0; p < i; p++) { int current_in = ((bool)transpose ? (p * variables + v) : (v * lenth + p)); if((bool)isttp[current_in + shift_ag]) { pos++; prev_ttp = p; prev_in = current_in; } } }
次に、セグメントの線形近似のパラメータを計算します。
//--- cacl tendency if(pos > 0 && pos < (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = i - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = IsNaNOrInf(inputs[prev_in + p * step_in], 0); sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = IsNaNOrInf((dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1), 0); float intercept = IsNaNOrInf((sum_y - slope * sum_x) / dist, 0);
その後、取得した値を結果バッファに保存します。
int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)) + shift_ag; outputs[shift_out] = slope; outputs[shift_out + step_in] = intercept; outputs[shift_out + 2 * step_in] = ((float)dist) / lenth; }
取得された各セグメントは、3つのパラメータによって特徴付けられます。
- slope:トレンドラインの角度
- intercept:データ空間における行のオフセット
- dist:セグメントの正規化された長さ
この場合、シーケンスの長さを整数値として保存するのは最適ではありません。モデルを効率的に運用するには、正規化されたデータ形式を使用するほうが望ましいためです。そこで、整数のセグメントサイズを、解析対象の単変量シーケンスの長さに対する割合に変換します。そのために、セグメント内の要素数を単変量時系列全体の要素数で割ります。また、整数演算による誤差(「罠」)を避けるため、まずセグメントの要素数をint型からfloat型に変換します。
さらに、最後のセグメントについては特別な処理をおこないます。この時点では、任意の時刻で形成されるセグメント数を事前に把握できません。極端なケース(たとえば、小さな閾値や高いボラティリティ)の場合、ほぼすべての要素で反転が発生する可能性があります。発生確率は低いものの、この場合データ量が大幅に増加します。同時に、データの欠損も防がなければなりません。
そこで、MQL5における時系列データの構造と、その表現方法についての知識を活かします。MQL5では、最新のデータが時系列の先頭(インデックスの小さい部分)に位置し、古いデータは後方(インデックスの大きい部分)に配置されます。これらについてもう少し詳しく説明します。解析対象シーケンスの末尾にあるデータは、過去の時点で発生したものであり、以降の事象への影響は相対的に小さいと考えられます。ただし、このような依存関係を完全に除外するわけではありません。
この特性を踏まえ、結果を書き込むためのデータバッファを、入力時系列テンソルとほぼ同じサイズに設定します。これにより、シーケンスの長さの3分の1のサイズでセグメントを格納できます(1つのセグメントを記録するのに3つの要素を使用)。この容量で十分なはずですが、セグメント数が多い場合には、最後のセグメントのデータを1つに統合してデータ損失を回避します。
else { if(pos == (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = lenth - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = IsNaNOrInf(inputs[prev_in + p * step_in], 0); sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = IsNaNOrInf((dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1),0); float intercept = IsNaNOrInf((sum_y - slope * sum_x) / dist, 0); int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)) + shift_ag; outputs[shift_out] = slope; outputs[shift_out + step_in] = intercept; outputs[shift_out + 2 * step_in] = IsNaNOrInf((float)dist / lenth, 0); } } }
ほとんどの場合、セグメントの数は少なくなるため、結果バッファの最後の要素はゼロ値で埋められることになります。
ご覧の通り、順伝播パスのアルゴリズムでは学習可能なパラメータは使用していません。そのため、逆伝播パスは誤差勾配の分配に簡略化されます。この機能は、PLRMultiAgentsGradientカーネルに実装されています。
すべてのエージェントは同じ時系列を解析します。そのため、すべてのエージェントからの勾配は元データレベルで集約する必要があります。エージェント数は控えめであると想定されるため、カーネルを過度に複雑化しない方針を取りました。代わりに、単一エージェント用の勾配分配アルゴリズムを再利用し、すべてのエージェントから勾配を集めるループと、エージェント数を指定するパラメータを追加しています。それぞれの実装を独自に調査してみることをお勧めします。これらのカーネルを含む完全な OpenCLプログラムは添付資料に提供されています。
トレンド検出メカニズムオブジェクト
OpenCL側の実装が完了したので、次にメインライブラリに移り、CNeuronPLRMultiAgentsOCLオブジェクト内でマルチエージェントトレンド検出アルゴリズムを実装します。このオブジェクトは、基本的に以前開発した時系列の区分線形表現(PLR)を拡張したものです。これが、これを親クラスとして選択した理由です。新しいオブジェクトの構造を以下に示します。
class CNeuronPLRMultiAgentsOCL : public CNeuronPLROCL { protected: int iAgents; CBufferFloat cMinDistance; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CNeuronPLRMultiAgentsOCL(void) : iAgents(1) {}; ~CNeuronPLRMultiAgentsOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, vector<float> &min_distance, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPLRMultiAgentsOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
この新しいクラスでは、アクティブなエージェントの数を定義する定数(iAgents)と、解析対象時系列の特徴量変化における閾値を格納するバッファ(cMinDistance)を宣言します。
内部オブジェクトはすべて静的に宣言されているため、コンストラクタとデストラクタは空のままにできます。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronPLRMultiAgentsOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, vector<float> &min_distance, ENUM_OPTIMIZATION optimization_type, uint batch) { iAgents = (int)min_distance.Size(); if(iAgents <= 0) return false;
このメソッドは、閾値ベクトルのみを入力として受け取る点に注意してください。エージェント数を明示的に渡す必要はありません。エージェント数は閾値ベクトルのサイズから自動的に導出されます。これにより、外部パラメータの数が減り、閾値パラメータとバッファ長の整合性が保証されます。
メソッド内では、まず内部変数にエージェント数を保存し、検証をおこないます(正常に動作させるためには少なくとも1つのエージェントが必要です)。その後、基底オブジェクトの初期化メソッドを呼び出し、コアインターフェースを設定します。
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_in * units_count * iAgents, optimization_type, batch)) return false;
重要な点として、親クラスではなく基底オブジェクトのInitメソッドを呼び出していることがあります。これは、結果バッファのサイズがエージェント数に比例してスケーリングされるためであり、そのためには継承コンポーネントのより深い再初期化が必要です。
まず、受け取ったパラメータの値を継承変数に保存します。
iVariables = (int)window_in; iCount = (int)units_count; bTranspose = transpose;
次に、極値フラグのバッファを初期化します。
icIsTTP = OpenCL.AddBuffer(sizeof(int) * Neurons(), CL_MEM_READ_WRITE); if(icIsTTP < 0) return false;
これらのフラグは、順伝播パスのたびに再計算されます。サイズは結果バッファと一致しており、恒久的に値を保存する必要はありません。そのため、バッファはOpenCLコンテキストメモリ内でのみ作成され、オブジェクトはポインタのみを保持します。
次に、閾値バッファを初期化します。
if(!cMinDistance.AssignArray(min_distance) || !cMinDistance.BufferCreate(OpenCL)) return false; //--- return true; }
最後に、初期化処理の論理結果を呼び出し元プログラムに返して、メソッドを完了します。
順伝播および逆伝播のメソッドもオーバーライドされています。しかし、これらの唯一の機能は、前述のOpenCLカーネルを呼び出すことです。ロジックは非常にシンプルなため、詳細は各自で確認する形にしています。
これで、マルチエージェントトレンド検出オブジェクトCNeuronPLRMultiAgentsOCLの実装は完了です。メソッドの完全なソース コードは添付ファイルに提供されています。
Cross-Sectional Attention (CSA)モジュール
解析対象時系列のマルチスケール区分線形表現を取得した後、各エージェントは割り当てられたスケールを処理して詳細解析をおこないます。MASAATフレームワーク内では、時系列は資産間と時間点間の2つの投影軸で解析されます。
MASAATフレームワーク内での時系列解析は、クロスアセットアテンションモジュールによっておこなわれます。これをCNeuronCrossSectionalAnalysisオブジェクトとして実装します。しかし、実装に入る前に、CSAモジュールの構築アルゴリズムについて説明します。
理論セクションで説明した通り、CSAモジュールはSelf-Attentionエンコーダを使用して資産間依存関係を捉えます。ライブラリにはすでにいくつかのエンコーダ実装があります。しかし、MASAATでは複数のエージェントが並列で動作し、各エージェントは自分に割り当てられたデータのサブセット内でのみ依存関係を解析します。この点を考慮すると、適切な解決策が見えてきます。
たとえば、CNeuronMVMHAttentionMLKVブロックは、独立チャネル解析用に設計され、もともとはInjectTSTフレームワーク用に開発されました。悪くない選択肢です。このブロックは単一資産のマルチスケール依存関係解析用ですが、今回の課題は単一スケール内で異なる資産間の依存関係を見つけることです。適応するために、まず3次元入力テンソルの最初の2軸を転置します。ライブラリにはこの転置用の層「CNeuronTransposeRCDOCL」がすでに存在します。
エンコーダは決定しました。しかし、エンコーダにデータを入力する前に、資産軌跡の埋め込みを生成する必要があります。MASAATの著者は、資産間でパラメータを共有するMLPを使用することを提案しています。慣例に従い、MLPの代わりに畳み込み層を用います。具体的には、GELU活性化を持つ単一の畳み込み層を追加します。Query、Key、Valueを生成する2つ目のMLPの役割は、エンコーダ内部で処理されます。
これがCSAモジュールの構造です。モジュール内では、順にデータ転置層、畳み込み埋め込み層、独立チャネル解析ブロック(Self-Attentionエンコーダ)を使用します。効率のため、畳み込み層を転置前に配置します。操作結果自体は変わりませんが、処理効率が向上します。
解析対象資産の価格変動を含む時系列の表現をCSAモジュールに入力します。その結果、解析対象の履歴が深くなるにつれて、ソースデータのボリュームも増加します。PLRはゼロ埋め要素が多いため、小さい埋め込みを使用できます。これにより、畳み込み埋め込みレイヤー後に転置するテンソルのサイズが小さくなり、計算負荷が低減し、性能が向上します。
実装の主要ポイントを把握したので、新しいオブジェクトCNeuronCrossSectionalAnalysisの構築に移ります。その構造を以下に示します。
class CNeuronCrossSectionalAnalysis : public CNeuronMVMHAttentionMLKV { protected: CNeuronConvOCL cEmbeding; CNeuronTransposeRCDOCL cTransposeRCD; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronCrossSectionalAnalysis(void) {}; ~CNeuronCrossSectionalAnalysis(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) const override { return defNeuronCrossSectionalAnalysis; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
ここで、独立チャネル解析ブロックを親クラスとして使用している点に注意してください。この解決策により、内部コンポーネントとして埋め込むのではなく、そのメソッドを直接再利用できます。その他のオブジェクトは静的に宣言しているため、クラスのコンストラクタとデストラクタは空のままにできます。初期化はInitメソッドでおこない、パラメータは親クラスのものと同じ形式を採用しています。
bool CNeuronCrossSectionalAnalysis::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMVMHAttentionMLKV::Init(numOutputs, myIndex, open_cl, window_key, window_key, heads, heads_kv, variables, layers, layers_to_one_kv, units_count, optimization_type, batch)) return false;
メソッド本体では、通常通り親クラスの該当メソッドを呼び出します。1つ注意点があります。CSAモジュールの機能を実装するにあたり、継承されたすべてのメソッドをフルに活用する予定です。順伝播パスでは、親クラスメソッドへの入力に生データの転置済み埋め込みを渡します。そのため、親クラスの初期化メソッドを呼ぶ際には、ソースデータウィンドウを埋め込み次元に合わせてリサイズし、解析対象シーケンス長と独立変数の数を入れ替えます。
親クラスオブジェクトの初期化が正常に完了した後、順に畳み込み埋め込み層とデータ転置層を初期化します。
if(!cEmbeding.Init(0, 0, OpenCL, window, window, window_key, units_count, variables, optimization, iBatch)) return false; cEmbeding.SetActivationFunction(GELU); if(!cTransposeRCD.Init(0,1,OpenCL,variables,units_count,window_key,optimization,iBatch)) return false;
その後、活性化関数を強制的に無効化し、メソッドを終了します。この時点で、操作の論理結果は呼び出し元プログラムに返されています。
SetActivationFunction(None); //--- return true; }
次に、feedForwardメソッドでCSAモジュールの順伝播アルゴリズムを構築します。ここは非常にシンプルです。メソッドパラメータとして入力データオブジェクトのポインタを受け取り、それを畳み込み層の同名メソッドに即座に渡します。
bool CNeuronCrossSectionalAnalysis::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cEmbeding.FeedForward(NeuronOCL)) return false; if(!cTransposeRCD.FeedForward(cEmbeding.AsObject())) return false; //--- return CNeuronMVMHAttentionMLKV::feedForward(cTransposeRCD.AsObject()); }
畳み込み層の出力を転置し、親クラスの同名メソッドに渡します。メソッドは処理の論理結果を呼び出し元に返して終了します。
逆伝播アルゴリズムも同様にシンプルです。よって、この部分についてはご自身で詳細を確認されることをお勧めします。これでCNeuronCrossSectionalAnalysisオブジェクトの作業は完了です。これらすべてのメソッドの完全なコードは添付ファイルにあります。
これで本日の作業は終了です。ただし、プロジェクト自体はまだ完成していません。ここで短い休憩を取り、次回の記事ではプロジェクトを論理的に完結させます。
結論
本記事では、ポートフォリオ最適化のためのマルチエージェント自己適応型アテンション時系列フレームワーク(MASAAT)を紹介しました。本フレームワークでは、複数の視点から価格データを解析する取引エージェントのアンサンブルを使用することで、生成される取引アクションのバイアスを低減します。各エージェントは、資産間および時点間の相関を捉えるためにアテンション機構を用いたクロスセクショナル分析と時間分析をおこない、その後、抽出された情報を統合する時空間融合モジュールにより統合します。
実践編では、MQL5においてMASAATの独自解釈の実装を開始しました。具体的には、マルチエージェントトレンド検出メカニズムとCross-Sectional Attentionモジュールの実装をおこないました。次回の記事では、この作業を継続し、実際の過去データを用いて実装ソリューションの性能評価をおこないます。
参照文献
- Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
- この連載の他の記事記事
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16599
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索