
取引におけるニューラルネットワーク:予測符号化を備えたハイブリッド取引フレームワーク(StockFormer)

はじめに
近年、強化学習(RL)は、取引戦略やポートフォリオ管理など、金融の複雑な問題への応用が増えています。モデルは、資産価格の変動、取引量、テクニカル指標などの過去データを解析するように訓練されます。しかし、既存の多くの手法は、解析対象のデータが資産間のすべての相互依存関係を完全に捉えていると仮定しています。実際の市場環境はノイズが多く変動が激しいため、この仮定はほとんどの場合成立しません。
従来のアプローチは、短期・長期のリターン予測や資産間の相関関係を同時に考慮できないことが多いです。しかし、成功する投資戦略は通常、これらの要素を深く理解していることが重要です。これに対処するために、論文「StockFormer:Learning Hybrid Trading Machines with Predictive Coding」では、予測符号化とRLエージェントの柔軟性を組み合わせたハイブリッド取引システム「StockFormer」を提案しています。予測符号化は、自然言語処理やコンピュータビジョンの分野で広く使用されており、ノイズの多い入力データから有益な隠れ状態を抽出することが可能です。これは金融応用において特に有用です。
StockFormerは、以下の市場ダイナミクスの異なる側面を捉える3つの改良Transformerブランチを統合しています。
- 長期トレンド
- 短期トレンド
- 資産間の依存関係
各ブランチには、Diversified Multi-Head Attention (DMH-Attn)機構が組み込まれています。DMH-Attnは従来のTransformerを拡張したもので、単一のFeedForwardブロックを複数の並列ブロックに置き換えています。これにより、主要な情報を保持しつつ、サブスペース全体にわたる多様な時系列パターンを捉えることができます。
取引戦略を最適化するため、これら3つのブランチから生成された潜在状態をマルチヘッドAttentionで適応的に統合し、RLエージェントが利用する統一状態空間を構築します。
方策学習はActor-Critic手法を用いておこないます。重要な点は、Criticからの勾配フィードバックが予測符号化モジュールに逆伝播され、予測モデルと方策最適化が緊密に統合されるということです。
3つの公開データセットで実施した実験の結果、StockFormerは既存手法に比べて予測精度および投資リターンの両面で大幅に優れていることが示されました。
StockFormerアルゴリズム
StockFormerは、金融市場における予測および取引意思決定を強化学習(RL)を用いて実現します。従来の手法の大きな制約は、資産間の動的依存関係や将来のトレンドを効果的にモデル化できない点にあります。これは、特に市場状況が急速かつ予測困難に変化する場合に重要です。StockFormerは、この課題を予測符号化と取引戦略学習という2つの主要ステージで解決します。
最初のステージでは、StockFormerは自己教師あり学習を活用して、ノイズの多い市場データから隠れたパターンを抽出します。これにより、短期・長期のダイナミクスや資産間の依存関係を捉えることが可能になります。抽出された重要な隠れ状態は、次のステップで取引意思決定に活用されます。
金融市場では、複数資産にわたる多様な時間的パターンが存在し、生データから有効な表現を抽出することは困難です。この課題に対応するため、StockFormerは従来型TransformerのマルチヘッドAttentionを改良し、単一のFeedForwardネットワーク(FFN)を複数並列のFFNに置き換えています。パラメータ数を増やさずにこの設計を行うことで、マルチヘッドAttentionの特徴分解能力が強化され、サブスペース間での異種時系列パターンのモデル化精度が向上します。
この改良モジュールはDiversified Multi-Head Attention (DMH-Attn)と呼ばれます。Query、Key、Valueの次元がdmodelの場合、マルチヘッドAttentionの出力特徴量Zをチャネル方向にh個のグループに分割し(hはAttentionヘッド数)、Zの各グループに専用FFNを適用します。
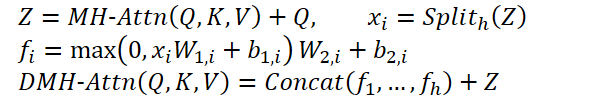
ここで、MH-AttnはマルチヘッドAttentionを示します。𝑓𝑖は各FFNヘッドの出力特徴量であり、その間にReLU活性化を含む2つの線形投影が含まれます。
各ブランチは、StockFormerにおける改良型Transformerにおいて、エンコーダとデコーダの2つのモジュールに分かれています。これらは予測符号化の学習時に両方使用されますが、取引戦略の最適化時にはエンコーダのみが使用されます。モデルは、L層のエンコーダとM層のデコーダで構成されており、最終エンコーダ出力XLencは各デコーダ層に入力されます。l層目のエンコーダ層およびm層目のデコーダ層での計算は、以下のように表されます。
- エンコーダ層
![]()
- デコーダ層
![]()
ここでXl,encとXm,decはそれぞれエンコーダおよびデコーダの出力です。最初のエンコーダとデコーダ層への入力は、生データに位置埋め込みを加えたものです。最終的なデコーダ出力は投影層に通され、予測符号化の結果を生成します。
クロス資産依存モジュールは、時間系列間の動的な相関関係を特定します。各タイムステップtにおいて、エンコーダとデコーダは同一の入力を処理します。株式市場データでは、MACD、RSI、SMAなどのテクニカル指標を使用しています。
学習時にはデータを2つに分割します。
- 共分散行列:時刻tより前の一定期間における全資産の日次終値から計算します。
- マスク統計量:時系列の半分をランダムに0でマスクし、残りを可視特徴として使用します。テスト時には、マスクなしの全データを使用します。
予測符号化タスクでは、残された特徴量と共分散行列を用いて、マスクされた統計量を再構築します。この過程により、Transformerのエンコーダは資産間の依存関係を学習することができます。
StockFormerの短期および長期予測モジュールは、資産ごとのリターンを異なる時間スケールで予測することを目的としています。
短期予測モジュールは、翌日のリターン(H = 1)を予測します。T日分の解析統計をエンコーダに入力し、デコーダには同じ時刻の統計情報を入力します。
長期モジュールは同様の手法で、より長期のリターンを予測します。これにより、モデルは拡張された市場ダイナミクスを捉えることが可能になります。
短期・長期モジュールの学習には、回帰誤差と株式ランク誤差を組み合わせた損失関数を使用します。回帰誤差は予測リターンと実リターンの差を最小化し、ランク誤差はリターンの高い資産が優先されるように調整します。
これにより、2つのブランチが異なる時間スケールで市場ダイナミクスを捉え、RLエージェントによるより正確で情報量の多い取引意思決定が可能になります。
次に、StockFormerは3種類の潜在表現srelat,t、slong,t、sshort,tを統合し、マルチヘッドAttentionのカスケードを用いて統一状態空間Stを構築します。このプロセスは、短期予測と長期予測の融合から始まります。ここでは、長期予測表現をQueryとして使用し、短期ノイズの影響を抑えます。融合出力を資産間依存関係の潜在表現に合わせ、KeyおよびValueとしてAttentionモジュールに入力します。
この状態空間をもとに、モデルはActor-Critic手法で最適な取引戦略を学習します。StockFormerの大きな利点は、予測符号化と方策最適化の統合です。Criticからの評価により潜在表現の品質が改善され、資産間の関係分析やノイズ耐性が強化されます。
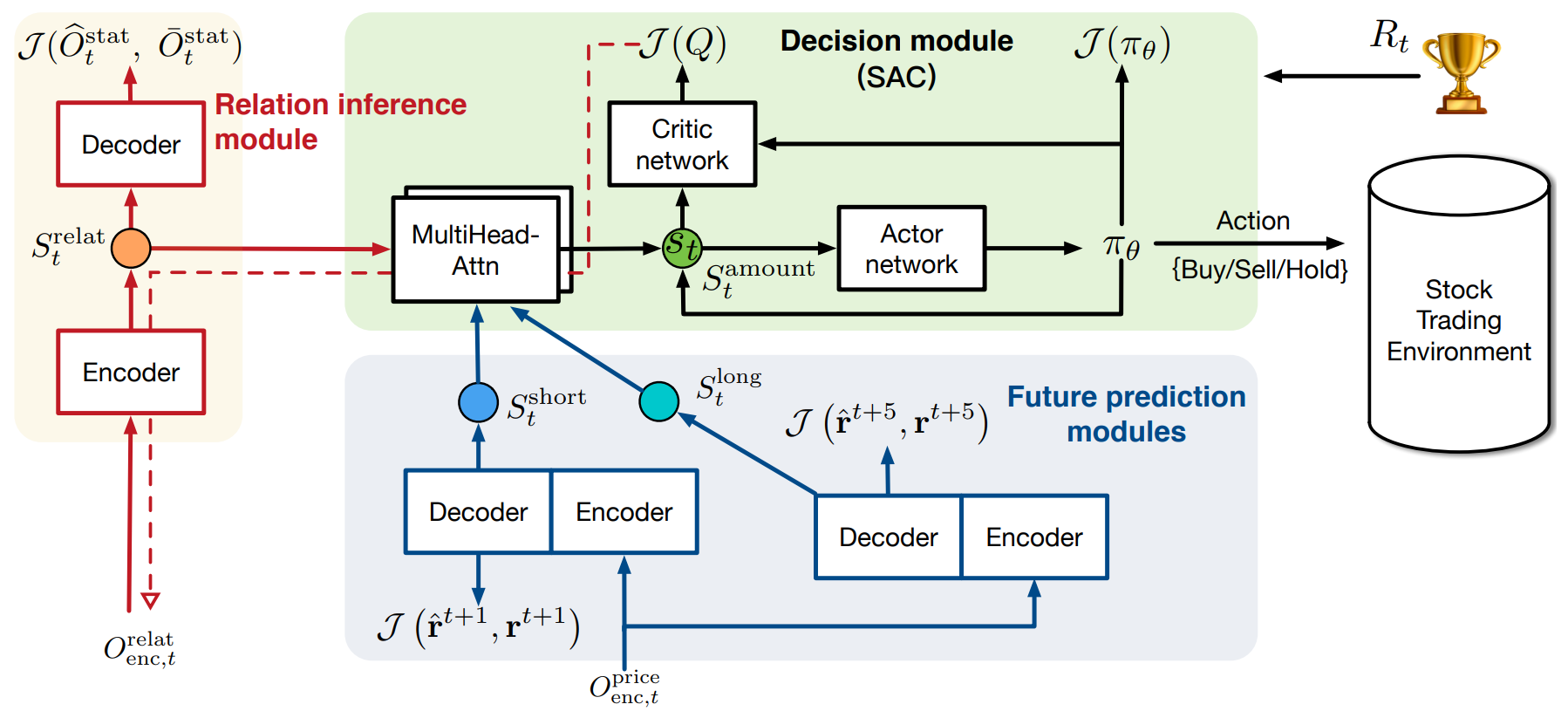
StockFormerフレームワークのオリジナルの可視化を以下に示します。
MQL5での実装
StockFormerの理論的基礎を説明したあと、提案されたメソッドをMQL5で実装していきます。理論てきnア説明でも前述した通り、アーキテクチャ上の重要な改良点は、マルチヘッドFeedForwardブロックを導入する点にあります。このブロックの実装が、まず最初のステップとなります。
StockFormerフレームワークの著者によって提案されたマルチヘッドFeedForwardブロックの実装では、各シーケンス要素に対するマルチヘッドSelf-Attentionブロックの出力をh個の等しいグループに分割し、それぞれのグループを独自のMLP(学習可能なパラメータを持つ)で処理します。
ここで注意すべき点は、ヘッドの形成方法が従来型マルチヘッドAttentionとは異なることです。従来のMulti-Head Self-Attentionでは、単一のシーケンス要素の埋め込みから複数のQuery、Key、Valueを生成していました。しかしStockFormerでは、シーケンス要素の表現ベクトルを直接複数の等しいグループに分割し、それぞれのグループを独自のMLPで処理します。この方法により、学習可能なパラメータ数を増やさずに複数のヘッドを作成できます。さらに、このアプローチでは出力テンソルの次元数が維持されるため、従来のMH Self-Attentionのように投影層を追加する必要はありません。ただし、この方式では、従来は可能であった既存の畳み込み層の再利用ができません。そのため、代替手段を検討する必要があります。
一つの方法として、3次元テンソルを転置して、1次元系列を独立に解析する畳み込み層に適応させることが考えられます。しかし、StockFormerではこのような層が多数存在するため、FeedForwardブロックの前後で毎回データを転置すると、学習および推論時間が大幅に増加してしまいます。そのため、マルチヘッド対応の畳み込み層を設計することが決定されました。ただし、この新しいコンポーネントをメインプログラムに実装する前に、OpenCLでいくつかの調整が必要となります。
OpenCLプログラムの拡張
まず、新しいFeedForwardMHConv層のfeed-forwardパス用カーネルを構築します。パラメータ構造やアルゴリズムの一部は、既存の畳み込み層のカーネルから流用しています。さらに、畳み込みヘッドの識別子と総ヘッド数を、タスク空間の追加次元として導入しました。
__kernel void FeedForwardMHConv(__global float *matrix_w, __global float *matrix_i, __global float *matrix_o, const int inputs, const int step, const int window_in, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t h = get_global_id(1); const size_t v = get_global_id(2); const size_t total = get_global_size(0); const size_t heads = get_global_size(1);
カーネル本体内では、タスク空間のすべての次元にわたるスレッドを特定します。その後、各畳み込みヘッドに対する入力次元と出力次元を決定し、解析対象となる要素に対応するグローバルデータバッファ内のオフセットを算出します。
const int window_in_h = (window_in + heads - 1) / heads; const int window_out_h = (window_out + heads - 1) / heads; const int shift_out = window_out * i + window_out_h * h; const int shift_in = step * i + window_in_h * h; const int shift_var_in = v * inputs; const int shift_var_out = v * window_out * total; const int shift_var_w = v * window_out * (window_in_h + 1); const int shift_w_h = h * window_out_h * (window_in_h + 1);
この準備作業が完了したら、次に入力データと学習可能なフィルタ間の畳み込み演算の構築に進みます。単一スレッド内では、入力データの1つのヘッドとそれに対応するフィルタの畳み込みを実行します。これを実現するために、入れ子構造のループを組織します。最も外側のループは、与えられた畳み込みヘッドに対応する出力層の各要素を順に反復処理します。
float sum = 0; float4 inp, weight; int stop = (window_in_h <= (inputs - shift_in) ? window_in_h : (inputs - shift_in)); //--- for(int out = 0; (out < window_out_h && (window_out_h * h + out) < window_out); out++) { int shift = (window_in_h + 1) * out + shift_w_h;
外側のループ内では、まず学習可能なパラメータバッファのオフセットを計算します。その後、内側のループを開始し、入力データに適用される畳み込みウィンドウの各要素を順に処理していきます。
for(int k = 0; k <= stop; k += 4) { switch(stop - k) { case 0: inp = (float4)(1, 0, 0, 0); weight = (float4)(matrix_w[shift_var_w + shift + window_in_h], 0, 0, 0); break; case 1: inp = (float4)(matrix_i[shift_var_in + shift_in + k], 1, 0, 0); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + window_in_h], 0, 0); break; case 2: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], 1, 0); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + window_in_h], 0); break; case 3: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], matrix_i[shift_var_in + shift_in + k + 2], 1); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + k + 2], matrix_w[shift_var_w + shift + shift_w_h]); break; default: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], matrix_i[shift_var_in + shift_in + k + 2], matrix_i[shift_var_in + shift_in + k + 3]); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + k + 2], matrix_w[shift_var_w + shift + k + 3]); break; }
計算を最適化するために、組み込みのベクトル乗算関数を使用します。これにより、プロセッサ資源をより効率的に活用することが可能になります。具体的には、まず外部バッファから必要な値をローカルのベクトル変数に読み込み、その後ベクトル乗算を実行します。そして、内側のループの次の反復に進みます。
sum += IsNaNOrInf(dot(inp, weight), 0);
}
内側のループのすべての反復が完了したら、活性化関数を適用し、その結果を対応する出力バッファの要素に格納します。その後、外側のループの次の反復に進みます。
sum = IsNaNOrInf(sum, 0); //--- matrix_o[shift_var_out + out + shift_out] = Activation(sum, activation);; } }
すべてのループの反復が終了すると、出力バッファには必要なすべての値が格納され、カーネルの実行は完了します。
次に、バックプロパゲーション(逆伝播)アルゴリズムの構築に進みます。ここで注意すべき点は、フィードフォワードパスとは異なり、畳み込みヘッドの識別子をタスク空間の次元として導入することはできないということです。
勾配分配の過程では、各入力要素が出力に与える影響値を累積します。畳み込みウィンドウのストライドがサイズより小さい場合、単一の入力要素が複数の畳み込みヘッドにまたがる結果テンソル要素に影響を与えることがあります。
このため、逆伝播では、CalcHiddenGradientMHConvカーネルの追加の外部パラメータとしてAttentionヘッドの数を導入します。そして、特定の畳み込みヘッドの識別子は、誤差勾配を累積する過程で決定されます。
__kernel void CalcHiddenGradientMHConv(__global float *matrix_w, __global float *matrix_g, __global float *matrix_o, __global float *matrix_ig, const int outputs, const int step, const int window_in, const int window_out, const int activation, const int shift_out, const int heads ) { const size_t i = get_global_id(0); const size_t inputs = get_global_size(0); const size_t v = get_global_id(1);
カーネル本体内では、まず2次元タスク空間における現在のスレッドを特定します。これにより、対象となる入力データ要素および単変量系列の識別子が決まります。その後、定数値を決定します。ここには、データバッファ内のシフト量や、畳み込みウィンドウのサイズ、1つの畳み込みヘッドに対するフィルターの数などが含まれます。
const int shift_var_in = v * inputs; const int shift_var_out = v * outputs; const int shift_var_w = v * window_out * (window_in + 1); const int window_in_h = (window_in + heads - 1) / heads; const int window_out_h = (window_out + heads - 1) / heads;
ここでは、解析対象となる入力データ要素によって影響を受ける出力ウィンドウの範囲も定義します。
float sum = 0; float out = matrix_o[shift_var_in + i]; const int w_start = i % step; const int start = max((int)((i - window_in + step) / step), 0); int stop = (w_start + step - 1) / step; stop = min((int)((i + step - 1) / step + 1), stop) + start; if(stop > (outputs / window_out)) stop = outputs / window_out;
準備作業が完了したら、次に結果テンソルのすべての依存要素から誤差勾配を収集する工程に進みます。これを実現するために、入れ子構造のループを構築します。外側のループでは、前段階で定義したウィンドウ内の依存する要素を順に反復処理します。
for(int k = start; k < stop; k++) { int head = (k % window_out) / window_out_h;
外側のループ本体内では、まず結果テンソルの単一要素に対応する畳み込みヘッドを定義します。その後、フィルタを順に処理するための入れ子構造のループを構築します。
for(int h = 0; h < window_out_h; h ++) { int shift_g = k * window_out + head * window_out_h + h; int shift_w = (stop - k - 1) * step + (i % step) / window_in_h + head * (window_in_h + 1) + h * (window_in_h + 1); if(shift_g >= outputs || shift_w >= (window_in_h + 1) * window_out) break; float grad = matrix_g[shift_out + shift_g + shift_var_out]; sum += grad * matrix_w[shift_w + shift_var_w]; } }
入れ子構造のループ本体内では、単一の畳み込みヘッドに対するすべてのフィルターの誤差勾配を累積します。その後、ループシステムの次の反復に進みます。
すべての依存要素から勾配を収集した後、累積された値に活性化関数の微分を適用して調整し、その結果を対応するデータバッファの要素に格納します。
matrix_ig[shift_var_in + i] = Deactivation(sum, out, activation); }
この時点で、勾配分配カーネルの操作は完了です。パラメータ更新カーネルについては、各自で確認することを推奨します。完全なOpenCLプログラムコードは、本記事の添付ファイルで提供されています。ここからは、作業の次のステージであるメインプログラムでのマルチヘッド畳み込みニューラル層の実装に進みます。
マルチヘッド畳み込み層
メインプログラム側で畳み込み機能を実装するために、新しいオブジェクト「CNeuronMHConvOCL」を導入します。ご想像の通り、既存の畳み込み層を親クラスとして使用しています。新しいオブジェクトの構造を以下に示します。
class CNeuronMHConvOCL : public CNeuronConvOCL { protected: uint iHeads; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHConvOCL(void) : iHeads(1) {}; ~CNeuronMHConvOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMHConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; };
この構造では、畳み込みヘッドの数を格納するための内部変数が1つだけ導入されています。その他の処理に必要なオブジェクトや変数は、すべて親クラスから継承されています。さらに、フォワードパスおよびバックワードパスのメソッドはオーバーライドされており、先に説明したカーネルを呼び出すためのラッパーとして機能します。カーネルのスケジューリングアルゴリズムは変更されておらず、追加の説明は不要です。本記事では、ほぼ一から実装された初期化メソッドInitに焦点を当てます。
メソッドのパラメータ構造内では、新たに1つの要素が追加され、呼び出しプログラムから畳み込みヘッドの数を渡すことが可能になっています。
bool CNeuronMHConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronProofOCL::Init(numOutputs, myIndex, open_cl, window, step, units_count * window_out * variables, ADAM, batch)) return false;
メソッド内部では、まず親サブサンプリング層の対応する初期化メソッドを呼び出します。この場合、親層が先祖オブジェクトとして機能します。その後、外部から渡されたパラメータの値をローカル変数に代入します。
iWindowOut = window_out; iVariables = variables; iHeads = MathMax(MathMin(heads, window), 1);
次に、学習可能なパラメータのテンソルをランダム値で初期化する必要があります。しかしその前に、まずテンソルの次元数を定義します。テンソルのサイズは、解析対象のマルチモーダル系列に含まれる単変量系列の数、フィルタの総数、および単一ヘッドの畳み込みウィンドウのサイズに依存します。
const int window_h = int((iWindow + heads - 1) / heads); const int count = int((window_h + 1) * iWindowOut * iVariables);
ここで注意すべき点は、すべての畳み込みヘッドにまたがるフィルタの総数を参照しつつ、単一ヘッドの畳み込みウィンドウのみを使用していることです。単一の畳み込みヘッドに対する学習可能パラメータの数は、ヘッドあたりのフィルター数 × 入力ウィンドウサイズ + バイアス項1つ(Fi * (Wi + 1))であることは容易に導けます。単一の単変量系列に対するパラメータ総数を求めるには、この値にヘッド数Hを掛けます(Fi * (Wi + 1) * H)。また、ヘッドあたりのフィルタ数にヘッド数を掛けることで、ユーザーが指定した総フィルター数と一致することも明らかです。
次のステップでは、学習可能パラメータを格納するバッファオブジェクトのポインタの有効性を確認し、必要に応じて新しいオブジェクトを作成します。
if(!WeightsConv) { WeightsConv = new CBufferFloat(); if(!WeightsConv) return false; }
バッファ内に必要な数の要素を予約し、バッファにランダムな値を設定するためのループを構成します。
if(!WeightsConv.Reserve(count)) return false; float k = (float)(1 / sqrt(window_h + 1)); for(int i = 0; i < count; i++) { if(!WeightsConv.Add((GenerateWeight() * 2 * k - k) * WeightsMultiplier)) return false; } if(!WeightsConv.BufferCreate(OpenCL)) return false;
バッファにランダム値を正常に格納した後、それをOpenCLコンテキストのメモリに転送します。次に、モメンタム用バッファを作成し、ゼロで初期化します。
if(!FirstMomentumConv) { FirstMomentumConv = new CBufferFloat(); if(!FirstMomentumConv) return false; } if(!FirstMomentumConv.BufferInit(count, 0.0)) return false; if(!FirstMomentumConv.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumConv) { SecondMomentumConv = new CBufferFloat(); if(!SecondMomentumConv) return false; } if(!SecondMomentumConv.BufferInit(count, 0.0)) return false; if(!SecondMomentumConv.BufferCreate(OpenCL)) return false; if(!!DeltaWeightsConv) delete DeltaWeightsConv; //--- return true; }
これで、マルチヘッド畳み込み層オブジェクト「CNeuronMHConvOCL」のメソッドに関する解説は終了です。このクラスおよびすべてのメソッドの完全な実装は、添付ファイルで提供されています。
マルチヘッドFeedForwardブロック
これで、StockFormerフレームワーク構築における最初の構成要素が完成しました。 次に、このブロックを使用して、新しいオブジェクト「CNeuronMHFeedForward」内のマルチヘッドFeedForwardブロックを実装します。オブジェクトの構造は以下の通りです。
class CNeuronMHFeedForward : public CNeuronBaseOCL { protected: CNeuronMHConvOCL acConvolutions[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHFeedForward(void) {}; ~CNeuronMHFeedForward(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMHFeedForward; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; };
新しいオブジェクトの構造では、2つの内部マルチヘッド畳み込み層からなる配列を宣言し、従来通りの仮想メソッド群をオーバーライドします。これらの内部オブジェクトは静的に宣言されており、これによりコンストラクタとデストラクタは空のままにすることができます。宣言済みおよび継承されたすべてのオブジェクトの初期化は、Initメソッド内でおこないます。
bool CNeuronMHFeedForward::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
初期化メソッドでは、作成されるオブジェクトのアーキテクチャを定義する定数を受け取ります。これらのパラメータの一部は、継承された基底インターフェースを設定するために、親クラスの対応する初期化メソッドに即座に渡されます。
その後、最初の畳み込み層を初期化し、活性化関数としてGELUを指定します。
if(!acConvolutions[0].Init(0, 0, OpenCL, window, window, window_out, units_count, variables, heads, optimization, iBatch)) return false; acConvolutions[0].SetActivationFunction(GELU);
その後、2つ目の畳み込み層を初期化します。今回は、活性化関数を使用せずに初期化します。
if(!acConvolutions[1].Init(0, 1, OpenCL, window_out, window_out, window, units_count, variables, heads, optimization, iBatch)) return false; acConvolutions[1].SetActivationFunction(None);
ここで注意すべき点は、2つ目の畳み込み層の初期化メソッドを呼び出す際に、フィルタ数と入力ウィンドウサイズに対応するパラメータを入れ替えることです。
FeedForwardブロックの出力では、正規化付きの残差接続が適用されます。そのため、ブロックのインターフェースの出力バッファはオーバーライドしません。しかし、誤差勾配バッファはオーバーライドし、インターフェースから2つ目の畳み込み層の対応バッファへの勾配の直接転送を可能にしています。
if(!SetGradient(acConvolutions[1].getGradient(), true)) return false; SetActivationFunction(None); //--- return true; }
ブロック自体の活性化関数も無効化し、初期化メソッドは実行結果の論理値を呼び出しプログラムに返すことで完了します。
初期化が完了したら、次にfeedForwardメソッド内でのフォワードパスアルゴリズムの実装に進みます。この場合、実装は非常に簡単です。内部の畳み込み層のフォワードパスメソッドを順番に呼び出すだけで済みます。
bool CNeuronMHFeedForward::feedForward(CNeuronBaseOCL *NeuronOCL) { CObject *prev = NeuronOCL; for(uint i = 0; i < acConvolutions.Size(); i++) { if(!acConvolutions[i].FeedForward(prev)) return false; prev = GetPointer(acConvolutions[i]); }
その後、出力は元の入力と合計され、解析対象のマルチモーダル系列の各要素内で正規化がおこなわれます。
if(!SumAndNormilize(NeuronOCL.getOutput(), acConvolutions[acConvolutions.Size() - 1].getOutput(), Output, acConvolutions[0].GetWindow(), true, 0, 0, 0, 1)) return false; //--- return true; }
メソッドは処理の論理結果を呼び出し元に返して終了します。
誤差勾配分配メソッドのcalcInputGradientsアルゴリズムは、2つのデータストリームに沿って勾配を伝播させる必要があるため、やや複雑に見えます。
bool CNeuronMHFeedForward::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このメソッドのパラメータには、入力データオブジェクトへのポインタが含まれます。 このオブジェクトのバッファには、最終的なモデル出力に対する入力データの影響に応じて分配された誤差勾配を格納します。そして、メソッド本体では、受け取ったポインタの関連性をすぐに確認します。
コントロールブロックを問題なく通過した後、内部の畳み込み層を逆順に反復処理するループを構築し、各層の該当メソッドを順番に呼び出します。
for(int i = (int)acConvolutions.Size() - 2; i >= 0; i--) { if(!acConvolutions[i].calcHiddenGradients(acConvolutions[i + 1].AsObject())) return false; }
内部オブジェクトのパイプライン全体に誤差勾配が分配された後、それは入力データレベルに伝播されます。この操作により、主要なワークフローは完了します。
if(!NeuronOCL.calcHiddenGradients(acConvolutions[0].AsObject())) return false;
次に、誤差勾配を第二の情報ストリームに沿って伝播させる必要があります。このアルゴリズムは、入力データの活性化関数の有無によって2つの操作ブランチに分かれます。今回、活性化関数を使用していないため、入力データレベルで累積された誤差勾配と、ブロック出力の対応する値を単純に加算するだけで処理します。
if(NeuronOCL.Activation() == None) { if(!SumAndNormilize(NeuronOCL.getGradient(), Gradient, NeuronOCL.getGradient(), acConvolutions[0].GetWindow(), false, 0, 0, 0, 1)) return false; } else { if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getPrevOutput(), Gradient, NeuronOCL.Activation()) || !SumAndNormilize(NeuronOCL.getGradient(), NeuronOCL.getPrevOutput(), NeuronOCL.getGradient(), acConvolutions[0].GetWindow(), false, 0, 0, 0, 1)) return false; } //--- return true; }
そうでなければ、まずブロック出力レベルの誤差勾配を入力データの活性化関数の微分で調整する必要があります。その後に、2つの情報ストリームからのデータを加算します。
後は、処理結果を呼び出し元プログラムに返してメソッドを終了するだけです。
ブロックの学習可能パラメータを調整してモデル全体の誤差を低減するメソッド「updateInputWeights」は、独自に確認することとします。そのアルゴリズムは非常に簡単で、内部オブジェクトの対応メソッドを順番に呼び出すだけです。マルチヘッドFeedForwardブロックオブジェクト「CNeuronMHFeedForward」およびそのすべてのメソッドの完全な実装は、本記事の添付ファイルで提供されています。
Diversified Multi-Head Attentionのデコーダ
マルチヘッドFeedForwardブロックの構築が完了した後は、Diversified Multi-Head Attentionのエンコーダおよびデコーダオブジェクトの構築に進みます。これらのモジュールのアルゴリズムを実装するために、新しいオブジェクト「CNeuronDMHAttention」および「CNeuronCrossDMHAttention」をそれぞれ導入します。これらのオブジェクトの構造は概ね類似しています。ただし後者は、内部にクロスアテンションブロックを含み、2つの入力データソースを扱う点で異なります。本記事では、より複雑なオブジェクトであるデコーダに焦点を当てることを提案します。デコーダのアルゴリズムが理解できれば、エンコーダの理解はそれほど難しくありません。
両オブジェクトの親クラスには、逐次モデルの基本アルゴリズムを提供するCNeuronRMATを使用します。
class CNeuronCrossDMHAttention : public CNeuronRMAT { protected: //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronCrossDMHAttention(void) {}; ~CNeuronCrossDMHAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint window_cross, uint units_cross, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronCrossDMHAttention; } };
デコーダオブジェクトの構造では、仮想メソッドのオーバーライドのみが確認できます。 内部オブジェクトの構造は、初期化メソッド「Init」内で定義されており、メソッドのパラメータにはオブジェクトのアーキテクチャを決定する主要な定数が含まれています。
bool CNeuronCrossDMHAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint window_cross, uint units_cross, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体内では、まず親クラスである全結合層の初期化メソッドを呼び出し、継承されたインターフェースを設定します。
次に、モジュールの内部オブジェクトへのポインタを格納する動的配列をクリアし、一時データを保持するためのいくつかのローカル変数を作成します。
cLayers.Clear(); cLayers.SetOpenCL(OpenCL); CNeuronRelativeSelfAttention *attention = NULL; CNeuronRelativeCrossAttention *cross = NULL; CNeuronMHFeedForward *conv = NULL; bool use_self = units_count > 0; int layer = 0;
この準備段階が完了したら、指定された内部層の数に等しい反復回数を持つループを構築します。このループは、Diversified Multi-Head Attentionデコーダの内部層ごとの処理を順におこなうために使用されます。
for(uint i = 0; i < layers; i++) { if(use_self) { attention = new CNeuronRelativeSelfAttention(); if(!attention || !attention.Init(0, layer, OpenCL, window, window_key, units_count, heads, optimization, iBatch) || !cLayers.Add(attention) ) { delete attention; return false; } layer++; }
ループ内では、まず相対的Self-Attentionブロックを作成し、主要な入力データストリーム内の依存関係を解析します。ここで重要な点は、主要入力ストリームのシーケンス長が1より大きい場合にのみSelf_Attentionブロックを生成するということです。シーケンス長が1の場合、依存関係を解析するデータが存在しないためです。
その後、相対的クロスアテンションモジュールを追加します。
cross = new CNeuronRelativeCrossAttention(); if(!cross || !cross.Init(0, layer, OpenCL, window, window_key, units_count, heads, window_cross, units_cross, optimization, iBatch) || !cLayers.Add(cross) ) { delete cross; return false; } layer++;
デコーダの各内部層はマルチヘッドFeedForwardブロックで完了し、その後、ループの次の反復に進みます。
conv = new CNeuronMHFeedForward(); if(!conv || !conv.Init(0, layer, OpenCL, window, 2 * window, units_count, 1, heads, optimization, iBatch) || !cLayers.Add(conv) ) { delete conv; return false; } layer++; }
すべての内部オブジェクトの初期化が完了した後、インターフェースポインタをこれらのオブジェクトへの参照に置き換えます。その後、論理値としての実行結果を呼び出し元プログラムに返し、メソッドを終了します。
SetOutput(conv.getOutput(), true); SetGradient(conv.getGradient(), true); //--- return true; }
feedForwardメソッドのアルゴリズムは、内部オブジェクトの対応するメソッドを順番に呼び出すという単純な構成になっています。この部分の学習については、読者自身で確認することをお勧めします。その代わりに、ここでは誤差勾配分配アルゴリズム「calcInputGradients」に焦点を当てて解説を進めます。
bool CNeuronCrossDMHAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondInput || !SecondGradient) return false;
このメソッドのパラメータには、入力データオブジェクトへのポインタおよびそれに対応する誤差勾配オブジェクトへのポインタが含まれています。これらの誤差勾配オブジェクトには、演算結果が書き込まれることになります。したがって、メソッド本体ではまず、受け取ったポインタの有効性を検証します。
ここで重要なのは、順伝播処理の際に、2つ目の入力データソースがすべてのデコーダ層のクロスアテンションモジュールで同様に使用されるという点です。そのため、すべての情報フローから誤差勾配を集約する必要があります。このような場合、通常はデータを一時的に保持するための内部バッファが必要になります。新しいオブジェクトにはそのような専用バッファが定義されていないため、親クラスから継承された未使用のバッファの1つを流用します。
まず、継承されたバッファのサイズを確認し、必要に応じてサイズを調整します。
if(PrevOutput.Total() != SecondGradient.Total()) { PrevOutput.BufferFree(); if(!PrevOutput.BufferInit(SecondGradient.Total(), 0) || !PrevOutput.BufferCreate(OpenCL)) return false; }
次に、第2入力データソース用の誤差勾配バッファをゼロで初期化します。この手順により、現在の計算パスで生成される勾配が、以前のパスの値と累積されないようにすることができます。
if(!SecondGradient.Fill(0)) return false;
次に、一時的なデータ保存用のローカル変数を作成します。
CObject *next = cLayers[-1]; CNeuronBaseOCL *current = NULL;
この時点で準備段階は完了し、内部オブジェクトに対して逆反復ループを開始します。
for(int i = cLayers.Total() - 2; i >= 0; i--) { current = cLayers[i]; if(!current || !current.calcHiddenGradients(next, SecondInput, PrevOutput, SecondActivation)) return false; if(next.Type() == defNeuronCrossDMHAttention) if(!SumAndNormilize(SecondGradient, PrevOutput, SecondGradient, 1, false, 0, 0, 0, 1)) return false; next = current; }
このループ内では、内部オブジェクトの対応するメソッドを順番に呼び出しながら、誤差勾配の分配を担当するオブジェクトの種類を継続的に確認します。もしクロスアテンションブロックが検出された場合には、第2入力データソースの誤差勾配を、これまでに累積された値に加算します。
すべてのループ反復を正常に完了した後、誤差勾配を主ストリームの入力データへと逆伝播させます。
if(!NeuronOCL.calcHiddenGradients(next, SecondInput, PrevOutput, SecondActivation)) return false; if(next.Type() == defNeuronCrossDMHAttention) if(!SumAndNormilize(SecondGradient, PrevOutput, SecondGradient, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
この段階で、再び勾配分配を実行しているオブジェクトの種類を確認し、必要に応じて第2情報ストリームからの誤差勾配を累積値に加算します。最後に、論理値としての実行結果を呼び出し元プログラムに返し、メソッドを終了します。
これで、Diversified Multi-Head Attentionのデコーダ構築アルゴリズムの解説は完了です。本オブジェクトおよびそのすべてのメソッドの完全な実装は、添付ファイルで提供されています。また、本記事で紹介したその他すべてのオブジェクトの完全なコードも添付ファイルに収録されています。
ここまでで、StockFormerフレームワークの中核となるアーキテクチャ要素、すなわち、Transformerアーキテクチャに基づくDiversified Multi-Head Attentionモジュール(エンコーダおよびデコーダの両方)を実装しました。ただし、StockFormerの著者らはこれに加えて、学習可能モデル間の高度な相互作用メカニズムを備えた2段階の学習プロセスを提案しています。この内容については、次回の記事で詳しく取り上げる予定です。
結論
本記事では、金融市場における取引戦略の学習に対する革新的なアプローチを提案するフレームワークStockFormerを紹介しました。StockFormerは、予測符号化の手法と深層強化学習を組み合わせたハイブリッドモデルです。その主な利点は、複数資産間の動的依存関係を考慮しながら、短期および長期の両方の時間スケールで資産の挙動を予測できる柔軟な方策を学習できる点にあります。
3つのブランチからなる予測符号化機構は、短期トレンド、長期ダイナミクス、資産間依存関係 に対応する潜在表現を抽出します。また、カスケード型マルチヘッドアテンション機構によって、これら多様な表現を効率的に統合し、統一された状態空間を構築します。
実装セクションでは、StockFormerの著者が提案した従来のTransformerの改良版をMQL5上で実装し、Diversified Multi-Head Attentionのエンコーダおよびデコーダモジュールに統合しました。次回の記事では、この研究をさらに進め、学習可能モデルのアーキテクチャおよびその学習プロセスについて詳しく説明していきます。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study1.mq5 | EA | 予測学習EA |
| 4 | Study2.mq5 | EA | 方策学習EA |
| 5 | Test.mq5 | EA | モデルテスト用EA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16686
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索