
ニューラルネットワークが簡単に(第9部):作業の文書化

内容
はじめに
過去8稿では、新しいオブジェクトを追加し、既存のオブジェクトの機能を拡張してきました。これらすべての追加により、ライブラリが拡張されました。OpenCLプログラムファイルも追加されました。現在のコードは最初のコードの10倍になっており、コード内のオブジェクト間の関係を追跡することが難しくなっています。読者のみなさんは、コードが非常に混乱し、理解するのが難しいと感じられているかもしれません。それぞれの記事ではアクションロジックの詳細な説明を提供しようとしていますが、個別のアクションチェーンのデモでは、プログラムの一般的な理解は得られません。
これがコードの文書化をデモすることにした理由です。文書化によって、コードを別の観点から見ることができます。文書化の目的は、ライブラリ内のすべてのオブジェクトとメソッドを一般化し、オブジェクトとメソッドの継承の階層を構築することです。これにより、私たちが何をおこなってきたかがおおよそわかるはずです。
1. 文書化の基本原則
IT開発における技術文書の目的とは何でしょうか。まず第一に、文章化はプログラムのアーキテクチャと操作の一般的な考え方を提供します。適切な文章化により、開発チームは責任のある領域を正しく区別し、コードのすべての変更を追跡し、アルゴリズム全体とアーキテクチャの整合性に対するそれらの影響を評価できます。また、知識の共有も容易になります。プログラムアーキテクチャの整合性を理解することで、プロジェクト開発の方法を分析して解決することができます。
技術文書を適切に作成するには、対象読者のレベルを考慮に入れる必要があります。情報は明確にし、過度の説明は避けます。ドキュメントは、ユーザが必要とするすべての情報を含むと同時に、簡潔で読みやすいものにする必要があります。内容が極端に多いと読むのに余分な時間がかかり、読者を悩ませることになります。長いドキュメントを読んだ末に必要な情報を見つけられなければ、さらに厄介です。これは「文書化には情報検索のための便利なツールが必要である」というルールにつながります。ユーザーフレンドリーなインターフェースと相互参照を使用すれば、必要な情報が簡単に見つかります。
ドキュメントには、ソリューションの完全なアーキテクチャと実装された技術ソリューションの説明が含まれている必要があります。ソリューションを完全で詳細に説明すれば、開発とさらなるサポートが容易になります。また、ドキュメントは常に最新の状態に保つことが非常に重要です。情報が古くなると、管理上の決定が矛盾する可能性があり、その結果、開発全体のバランスが崩れる可能性があります。
また、ドキュメントには、コンポーネント間のインターフェイスが必ず記載されている必要があります。
2. ツールの選択
ドキュメントの作成を支援できる特殊なプログラムはいくつかあります。最も一般的なものはDoxygen、Sphinx、Latexだと思います(他にもいくつかのツールがあります)。それらはすべて、ドキュメント作成の人件費を削減することを目的としています。もちろん、それぞれのプログラムは特定の問題を解決するために開発者によって作成されました。たとえば、Doxygenは、C++プログラムおよび同様のプログラミング言語のドキュメントを作成するためのプログラムです。SphinxはPythonのドキュメント用に作成されました。しかし、これはそれらがプログラミング言語に高度に特化しているという意味ではありません。これらのプログラムは両方とも、さまざまなプログラミング言語でうまく機能します。プログラムのWebサイトには、それらの使用方法に関する詳細なリファレンスが記載されているため、最適なものを選択できます。
MQL5の文書化については、「MQL5コード用自動作成ドキュメンテーション」稿ですでに説明しました。この記事では、Doxygenの使用を提案しました。私もこのプログラムを自分の開発に使用しています。MQL5構文はC++に近いため、DoxygenはMQL5プログラムに非常に適しています。ドキュメントを作成するには、プログラムコードに適切なコメントを追加するだけで、残りは専用のソフトウェアが実行するという事実が気に入っています。さらに、Doxygenを使用すると、ハイパーリンクや数式を挿入できます。これは、記事のトピックを考えると重要です。この記事では、特定の例を使用して、機能の使用法の詳細についてさらに検討します。
3. コードでの文書化
上記のように、ドキュメントを生成するには、プログラムコードにコメントを追加する必要があります。Doxygenは、これらのコメントに基づいてドキュメントを作成します。当然、すべてのコードコメントをドキュメントに含める必要はありません。一部のコメントには開発者向けのメモが含まれており、未使用のコードhsコメント化されている場合もあります。Doxygenは、コメントをドキュメントに含めるように指定する方法を備えています。いくつかのオプションがあるので、自分に都合の良いものを選ぶことができます。
MQL5と同様に、ドキュメントのコメントは1行でも複数行でもかまいません。将来的にコードを直接使用するのを妨げないように、コメントを挿入するための標準オプションを使用し、単一行コメントには追加のスラッシュを使用し、複数行コメントにはアスタリスクを使用します。オプションで、ドキュメントのコメントブロックは感嘆符を使用して識別できます。
/// 文書化する単数行コメント /** 文書化する複数行コメント */ //!文書化する単数行コメント(別方法) /*!文書化する 複数行コメント (別方法) */
複数行コメントブロックの行数はドキュメントでは変わる場合があります。プログラムオブジェクトの簡単な説明と詳細な説明を区切る必要がある場合は、別々のコメントブロックを追加するか、「\」または「@」で示される特殊コマンドを使用できます。 改行は「\n」コマンドで強制できます。
オプション1: 別々のブロック /// 短い説明 /** 詳細な説明 */ オプション2: 特殊コマンドの使用 /** \brief 短い説明 \details 長い説明 */
一般に、文書化オブジェクトは、コメントブロックの隣のファイルにあると想定されていますが、実際には、コメントブロックの前にあるオブジェクトにコメントする必要がある場合があります。この場合、コメントされたオブジェクトがブロックの前にあることをDoxygenに通知する文字「<」を使用します。コメントで相互参照を作成するには、参照オブジェクトの前に「#」を付けます。以下は、ドキュメントで生成されたコードとブロックの例です。生成されたテンプレートでは、「CConnection」は適切なクラスのドキュメントページを指す参照です。
#define defConnect 0x7781 ///<Connection \details Identified class #CConnection
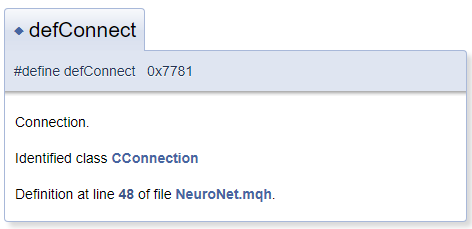
Doxygenの機能は豊富です。コマンドの完全なリストとその説明は、プログラムページのドキュメントセクションにあります。さらに、DoxygenはHTMLおよびXMLマークアップを理解します。これらすべての機能により、ドキュメント作成時にさまざまなタスクを解決できます。
4. コードソースファイルの準備
ツールの機能を確認したので、ドキュメントの作成を開始できます。まず、ファイルについて説明します。
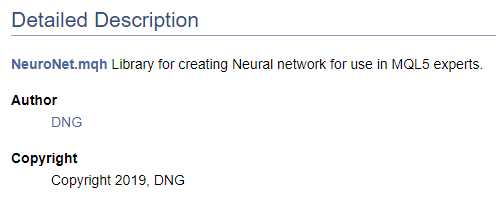
/// \file /// \brief NeuroNet.mqh /// Library for creating Neural network for use in MQL5 experts /// \author [DNG](https://www.mql5.com/en/users/dng) /// \copyright Copyright 2019, DNG
そして
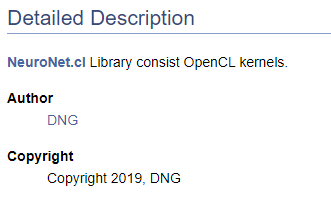
/// \file /// \brief NeuroNet.cl /// Library consist OpenCL kernels /// \author <A HREF="https://www.mql5.com/en/users/dng"> DNG </A> /// \copyright Copyright 2019, DNG
前者の場合、\authorポインタの後にDoxygenによって提供されるマークアップが続き、後者の場合、HTMLマークアップが使用されることに注意してください。個々での目的はハイパーリンクを作成するための異なるオプションを示すことです。結果はこれらの場合でも同じで、私のMQL5.comでのプロファイルへのリンクを作成します。
もちろん、コードドキュメントの作成を開始するときは、少なくとも目的の結果の高レベルの構造が必要です。最終的な構造を理解することで、ドキュメントオブジェクトを正しくグループ化できます。作成した列挙を別のグループにまとめましょう。グループを宣言するには、「\defgroup」コマンドを使用します。グループの境界は、文字「@{」および「@}」で示されます。
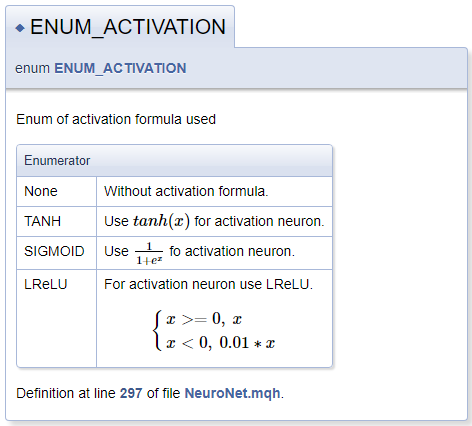
///\defgroup enums ENUM ///@{ //+------------------------------------------------------------------+ /// Enum of activation formula used //+------------------------------------------------------------------+ enum ENUM_ACTIVATION { None=-1, ///< Without activation formula TANH, ///< Use \f$tanh(x)\f$ for activation neuron SIGMOID, ///< Use \f$\frac{1}{1+e^x}\f$ fo activation neuron LReLU ///< For activation neuron use LReLU \f[\left\{ \begin{array} a x>=0, \ x \\x<0, \ 0.01*x \end{array} \right.\f] }; //+------------------------------------------------------------------+ /// Enum of optimization method used //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM ///< Adam }; ///@}
活性関数を説明するときに、MathJaxを使用して数式を宣言する機能を示しました。このような数式の説明は、数式をテキスト行で表示する場合は「\f$」コマンドのペアの間に配置し、数式を別の行に表示する場合はコマンド「\f[」および「\f]」の間に配置する必要があります。「\frac」コマンドは分数を記述し、コマンドの後には、中括弧で囲まれた分数の分子と分母が続きます。
LReLUを説明する際には、統一された左中括弧が必要でした。これを作成するには、コマンド「\left\{」と「\right\.」を使用しました。数式では右中括弧が必要ないため、「\right」コマンドの後に「\.」が続きます。それ以外の場合、ピリオドは閉じ中括弧に置き換えられます。文字列の配列は、コマンド「\begin{array} a」および「\end{array}」を使用してブロック内で宣言されます。 「\ 」文字を使用するとスペースを強制的に挿入できます。
生成されたドキュメントブロックを以下に示します。
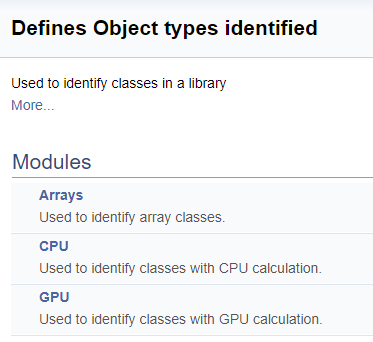
次の手順では、ライブラリ内のクラス識別子用に別のグループを作成します。グループ内では、配列のサブグループ、CPUでの演算を計算するニューロン、GPUでの演算を計算するニューロンを割り当てます。前に説明したように、適切なクラスへのリンクが追加されます。
///\defgroup ObjectTypes Defines Object types identified ///Used to identify classes in a library ///@{ //+------------------------------------------------------------------+ ///\defgroup arr Arrays ///Used to identify array classes ///\{ #define defArrayConnects 0x7782 ///<Array of connections \details Identified class #CArrayCon #define defLayer 0x7787 ///<Layer of neurons \details Identified class #CLayer #define defArrayLayer 0x7788 ///<Array of layers \details Identified class #CArrayLayer #define defNet 0x7790 ///<Neuron Net \details Identified class #CNet ///\} ///\defgroup cpu CPU ///Used to identify classes with CPU calculation ///\{ #define defConnect 0x7781 ///<Connection \details Identified class #CConnection #define defNeuronBase 0x7783 ///<Neuron base type \details Identified class #CNeuronBase #define defNeuron 0x7784 ///<Full connected neuron \details Identified class #CNeuron #define defNeuronConv 0x7785 ///<Convolution neuron \details Identified class #CNeuronConv #define defNeuronProof 0x7786 ///<Proof neuron \details Identified class #CNeuronProof #define defNeuronLSTM 0x7791 ///<LSTM Neuron \details Identified class #CNeuronLSTM ///\} ///\defgroup gpu GPU ///Used to identify classes with GPU calculation ///\{ #define defBufferDouble 0x7882 ///<Data Buffer OpenCL \details Identified class #CBufferDouble #define defNeuronBaseOCL 0x7883 ///<Neuron Base OpenCL \details Identified class #CNeuronBaseOCL #define defNeuronConvOCL 0x7885 ///<Convolution neuron OpenCL \details Identified class #CNeuronConvOCL #define defNeuronProofOCL 0x7886 ///<Proof neuron OpenCL \details Identified class #CNeuronProofOCL #define defNeuronAttentionOCL 0x7887 ///<Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL ///\} ///@}
生成されたドキュメントでのグループへの分割は次のようになります。
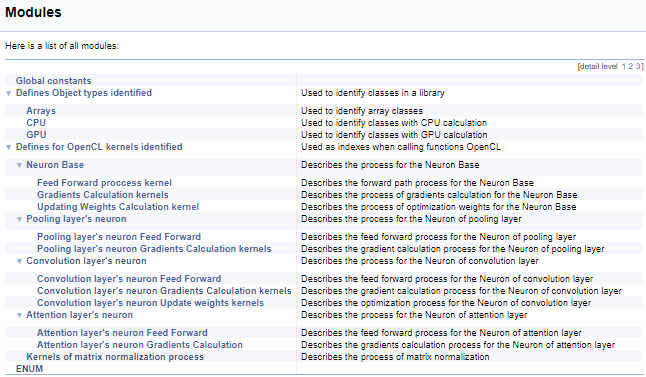
次に、OpenCLカーネルを操作するための定義の大規模なグループに取り組みます。このブロックでは、ニーモニック名がカーネルインデックスとそのパラメータに割り当てられ、メインプログラムからカーネルを呼び出すときに使用されます。上記のテクノロジーを使用して、このグループを、カーネルが呼び出されるニューロンのクラスによって分割し、次にカーネル内の操作の内容(フィードフォワード、勾配バックプロパゲーション、重み係数の更新)によって分割します。完全なコードはここでは提供しませんが、以下の添付ファイルで入手できます。サブグループを構築するためのロジックは、上記の例と同様です。以下のスクリーンショットは、完全なグループ構造を示しています。
カーネルでのOpenCLプログラムについてのコメントに移りましょう。一貫性のあるドキュメント構造を作成して全体像を把握するために、別のDoxygenコマンド「\ingroup」を使用して、以前に作成したグループに新しいドキュメントオブジェクトを追加します。カーネルを操作するために以前に作成したインデックスのグループにカーネルを追加しましょう。カーネルの記述で、呼び出し元のクラスと、プロセスの説明が記載されたこのサイトの記事へのリンクを追加します。次に、カーネルパラメータについて説明します。ポインタ「[in]」および「[out]」の使用法は、情報の流れの方向を示します。相互参照は、データの形式を示します。
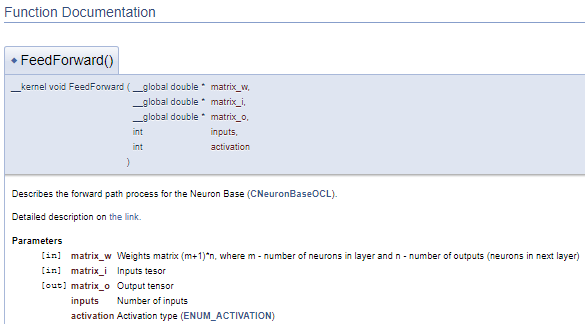
///\ingroup neuron_base_ff Feed forward process kernel /// Describes the forward path process for the Neuron Base (#CNeuronBaseOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/en/articles/8435#para41">the link.</A> //+------------------------------------------------------------------+ __kernel void FeedForward(__global double *matrix_w,///<[in] Weights matrix (m+1)*n, where m - number of neurons in layer and n - number of outputs (neurons in next layer) __global double *matrix_i,///<[in] Inputs tesor __global double *matrix_o,///<[out] Output tensor int inputs,///< Number of inputs int activation///< Activation type (#ENUM_ACTIVATION) )
上記のコードは、次のドキュメントブロックを生成します。
上記の例では、パラメータの説明は宣言の直後に示されています。しかし、このアプローチではコードがぎこちなくなる可能性があるので、このような場合は、「\param」コマンドを使用してパラメータを記述することをお勧めします。このコマンドを使用すると、ファイルの任意の部分にパラメータを記述できますが、パラメータ名を直接指定する必要があります。
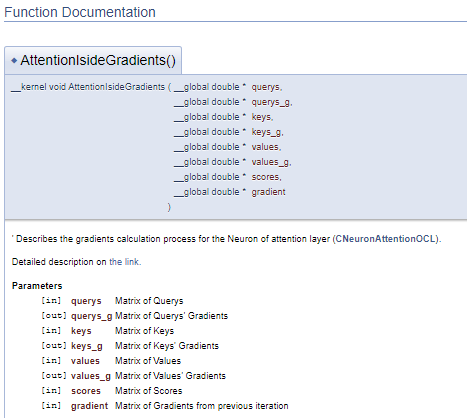
///\ingroup neuron_atten_gr Attention layer's neuron Gradients Calculation kernel /// Describes the gradients calculation process for the Neuron of attention layer (#CNeuronAttentionOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8765#para44">the link.</A> /// @param[in] querys Matrix of Querys /// @param[out] querys_g Matrix of Querys' Gradients /// @param[in] keys Matrix of Keys /// @param[out] keys_g Matrix of Keys' Gradients /// @param[in] values Matrix of Values /// @param[out] values_g Matrix of Values' Gradients /// @param[in] scores Matrix of Scores /// @param[in] gradient Matrix of Gradients from previous iteration //+------------------------------------------------------------------+ __kernel void AttentionIsideGradients(__global double *querys,__global double *querys_g, __global double *keys,__global double *keys_g, __global double *values,__global double *values_g, __global double *scores, __global double *gradient)
このアプローチでは、同様のドキュメントブロックが生成されますが、コメントブロックをプログラムコードから分離できるので、コードが読みやすくなります。
主な作業は、ライブラリクラスとそのメソッドの文書化に関するものです。使用されるすべてのクラスとそのメソッドを説明する必要があります。これを行うには、上記のすべてのコマンドをさまざまなバリエーションで使用し、いくつかの新しいコマンドを追加します。まず、カーネルで以前に行ったように(\ingroupコマンド)、クラスを適切なグループに追加しましょう。「\class」コマンドは、以下の説明がクラスに適用されることをDoxygenに通知します。説明を適切なオブジェクトにリンクするためにコマンドパラメータでクラス名を指定します。
「\brief」および「\details」コマンドを使用して、簡単で拡張されたクラスの説明を提供します。詳細な説明で、対応する記事へのハイパーリンクを追加します。ここでは、記事の特定のセクションにアンカーリンクを追加するので、ユーザーは必要な情報をすばやく見つけることができます。
説明は変数宣言行に直接追加します。必要に応じて、説明オブジェクトへのリンクを追加します。コメントで宣言されたオブジェクトのクラスへのポインターを設定する必要はありませんが、Doxygenはそれらを自動的に追加します。
同様に、クラスのメソッドを説明します。ただし、変数とは異なり、パラメータの説明はコメントに追加する必要があります。これを行うには、前述の「\param」コマンドを「[in]」、「[out]」、「[in,out]」ポインタと一緒に使用します。「\return」コマンドを使用してメソッドの実行結果を記述します。
特定の機能によって、個々のメソッドをグループにアタッチすることもできます。たとえば、機能ごとに組み合わせることができます。
以下のコードは、上記のすべての手順を示しています。
///\ingroup neuron_base ///\class CNeuronBaseOCL ///\brief The base class of neuron for GPU calculation. ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8435#para45">the link.</A> //+------------------------------------------------------------------+ class CNeuronBaseOCL : public CObject { protected: COpenCLMy *OpenCL; ///< Object for working with OpenCL CBufferDouble *Output; ///< Buffer of Output tenzor CBufferDouble *PrevOutput; ///< Buffer of previous iteration Output tenzor CBufferDouble *Weights; ///< Buffer of weights matrix CBufferDouble *DeltaWeights; ///< Buffer of last delta weights matrix (#SGD) CBufferDouble *Gradient; ///< Buffer of gradient tenzor CBufferDouble *FirstMomentum; ///< Buffer of first momentum matrix (#ADAM) CBufferDouble *SecondMomentum; ///< Buffer of second momentum matrix (#ADAM) //--- const double alpha; ///< Multiplier to momentum in #SGD optimization int t; ///< Count of iterations //--- int m_myIndex; ///< Index of neuron in layer ENUM_ACTIVATION activation; ///< Activation type (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Optimization method (#ENUM_OPTIMIZATION) //--- ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. public: /** Constructor */CNeuronBaseOCL(void); /** Destructor */~CNeuronBaseOCL(void); virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual void SetActivationFunction(ENUM_ACTIVATION value) { activation=value; } ///< Set the type of activation function (#ENUM_ACTIVATION) //--- virtual int getOutputIndex(void) { return Output.GetIndex(); } ///< Get index of output buffer @return Index virtual int getPrevOutIndex(void) { return PrevOutput.GetIndex(); } ///< Get index of previous iteration output buffer @return Index virtual int getGradientIndex(void) { return Gradient.GetIndex(); } ///< Get index of gradient buffer @return Index virtual int getWeightsIndex(void) { return Weights.GetIndex(); } ///< Get index of weights matrix buffer @return Index virtual int getDeltaWeightsIndex(void) { return DeltaWeights.GetIndex(); } ///< Get index of delta weights matrix buffer (SGD)@return Index virtual int getFirstMomentumIndex(void) { return FirstMomentum.GetIndex(); } ///< Get index of first momentum matrix buffer (Adam)@return Index virtual int getSecondMomentumIndex(void) { return SecondMomentum.GetIndex();} ///< Get index of Second momentum matrix buffer (Adam)@return Index //--- virtual int getOutputVal(double &values[]) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getPrevVal(double &values[]) { return PrevOutput.GetData(values); } ///< Get values of previous iteration output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return Gradient.GetData(values); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual int getWeights(double &values[]) { return Weights.GetData(values); } ///< Get values of weights matrix buffer @param[out] values Array of data @return number of items virtual int Neurons(void) { return Output.Total(); } ///< Get number of neurons in layer @return Number of neurons virtual int Activation(void) { return (int)activation; } ///< Get type of activation function @return Type (#ENUM_ACTIVATION) virtual int getConnections(void) { return (CheckPointer(Weights)!=POINTER_INVALID ? Weights.Total()/(Gradient.Total()) : 0); } ///< Get number of connections 1 neuron to next layer @return Number of connections //--- virtual bool FeedForward(CObject *SourceObject); ///< Dispatch method for defining the subroutine for feed forward process. @param SourceObject Pointer to the previous layer. virtual bool calcHiddenGradients(CObject *TargetObject); ///< Dispatch method for defining the subroutine for transferring the gradient to the previous layer. @param TargetObject Pointer to the next layer. virtual bool UpdateInputWeights(CObject *SourceObject); ///< Dispatch method for defining the subroutine for updating weights.@param SourceObject Pointer to previos layer. ///\ingroup neuron_base_gr ///@{ virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. virtual bool calcOutputGradients(CArrayDouble *Target); ///< Method of output gradients calculation by calling kernel ::CalcOutputGradient().@param Target target value ///@} //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronBaseOCL; }///< Identifier of class.@return Type of class };
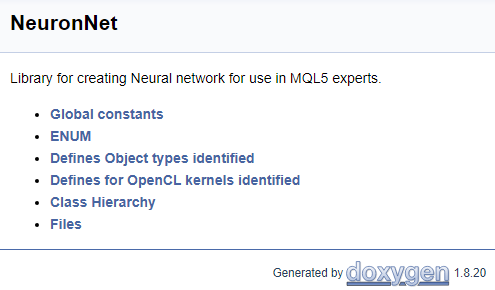
表紙を作成て、コードでの作業を終了しましょう。表紙ブロックを特定するには「\mainpage」コマンドが使用されます。コマンドの後には、表紙のタイトルが続く必要があります。以下で、プロジェクトの説明を追加し、参照のリストを作成しましょう。リスト項目は、文字「-」で指定されます。以前に作成したグループへのリンクを作成するには、「\ref」コマンドを使用します。Doxygenがドキュメントを生成すると、クラス階層のページ(hierarchy.html)と使用されるファイルのページ(files.html)が生成されます。指定されたページへのリンクをリストに追加します。表紙の最終的なコードを以下に示します。
///\mainpage NeuronNet /// Library for creating Neural network for use in MQL5 experts. /// - \ref const /// - \ref enums /// - \ref ObjectTypes /// - \ref group1 /// - [<b>Class Hierarchy</b>](hierarchy.html) /// - [<b>Files</b>](files.html)
上記のコードに基づいて次のページが生成されます。
すべてのコメントの完全なコードは添付ファイルで提供されています。
5. ドキュメントの生成
コードでの作業が完了したら、次の段階に進みます。Doxygenのインストールとセットアップについては、記事[9]で詳しく説明されています。いくつかのプログラムパラメータの設定について考えてみましょう。まず、Doxygenにどのファイルを処理するかを通知します。[エキスパート]タブの[入力]トピックで、必要なファイルマスクをFILE_PATTERNSパラメータに追加します。この場合、「*.mqh」と「*.cl」を追加しました。
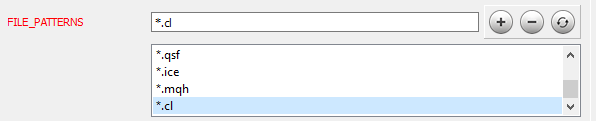
次に、追加されたファイルを解析する方法をDoxygenに通知する必要があります。次の図に示すように、同じ[エキスパート]タブの[プロジェクト]トピックに移動し、EXTENSION_MAPPINGパラメータを編集します。

Doxygenが数式を生成できるようにするには、MathJaxの使用を有効にします。これを行うには、次の図に示すように、[エキスパート]タブのHTMLトピックでUSE_MATHJAXパラメータをアクティブにします。

プログラムを構成した後、[ウィザード]タブに移動し、プロジェクトの名前、ソースファイルへのパス、および生成されたドキュメントを表示するためのパスを指定します(これらの手順はすべて記事[9]に示されています] )。[実行]タブに移動し、ドキュメント生成プログラムを実行します。
プログラムが完了すると、すぐに使用できるドキュメントが届きます。いくつかのスクリーンショットを以下に示します。完全なドキュメントは添付ファイルに記載されています。
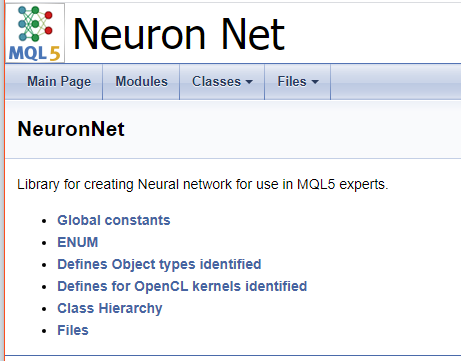
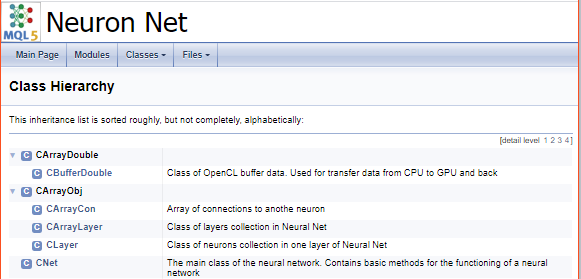
終わりに
開発されたプログラムの文書化は、プログラマーの主なタスクではありませんが、複雑なプロジェクトを開発する場合は、このような文書化は不可欠です。文書化は開発の全体像を提供し、タスクの実装を追跡して開発チームの作業を調整するのに役立ちます。知識を共有するときは、ドキュメントが必須です。
この記事では、MQL5言語で開発を文書化するためのメカニズムについて説明し、メカニズムのすべての手順の詳細な説明を提供しました。実行した作業の結果は添付ファイルに記載されているため、どなたでも評価できます。
私の経験がお役に立てば幸いです。
参照文献
- ニューラルネットワークが簡単に
- ニューラルネットワークが簡単に(第2回): ネットワークのトレーニングとテスト
- ニューラルネットワークが簡単に(第3回): コンボリューションネットワーク
- ニューラルネットワークが簡単に(第4回): リカレントネットワーク
- ニューラルネットワークが簡単に(第5回): OPENCLでのマルチスレッド計算
- ニューラルネットワークが簡単に(第6回): ニューラルネットワークの学習率を実験する
- ニューラルネットワークが簡単に(第7回): 適応的最適化法
- ニューラルネットワークが簡単に(第8回): アテンションメカニズム
- MQL5 コード用自動作成ドキュメンテーション
- Doxygen
記事で使用されたプログラム
| # | 名称 | 種類 | 説明 |
|---|---|---|---|
| 1 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 2 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 3 | html.zip | ZIPアーカイブ | Doxygenで生成された文書アーカイブ |
| 4 | NN.chm | HTML Help | 変換済みHTMLヘルプファイル |
| 5 | Doxyfile | Doxygenパラメータファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/8819
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 自己適応アルゴリズムの開発(第I部):基本的なパターンの検索
自己適応アルゴリズムの開発(第I部):基本的なパターンの検索
 ニューラルネットワークが簡単に(第8回): アテンションメカニズム
ニューラルネットワークが簡単に(第8回): アテンションメカニズム
 市場とそのグローバルパターンの物理学
市場とそのグローバルパターンの物理学
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
そうではない。ちょうど隠れ層のように、outpuValを勾配に追加してターゲットを求め、その値をチェックします。ポイントは、シグモイドは結果の範囲が限られているということです。ロジスティック関数は0から1まで、tanhは-1から1までです。偏差に対してニューロンにペナルティを与え、重み付け係数を無制限に増やすと、重みがオーバーフローしてしまいます。結局のところ、ニューロンの値が1に等しくなったとき、後続の層がエラーを送信して、値を1.5に増やすべきだと言ったとする。そのため、ターゲットの値を活性化関数の許容値の範囲内に制限する。そして、その範囲外の調整は後続層の重みに委ねる。
うまくいったと思う。しかし、これが正しいアプローチなのかどうか、まだ疑問に思っている:
ネットワークが、本当は1なのに0を与えてミスをした場合。最後のレイヤーから、前のレイヤーで重み付けされた勾配が(私が理解する限り、おそらく)正になり、1以上になる可能性があります。
前の層に+0.6、つまり正しい値を出したニューロンがあったとしよう。そしてこの正規化によって、重みの変化をカットする。
結果はnorm(1,6)=1となる。1-0,6=0,4であり、私が提案したように正規化すれば1となる。この場合、正しいニューロンの増幅を抑制することになる。
どう思いますか?
重みの無限増加については、「悪い誤差関数」の場合、局所極小が多くて大域的な極小が表現されていない場合、関数が凸でない場合、そのような場合に起こると聞いたことがありますが、私は超専門家ではありません。
私は両方の変種をテストする実験を求めている。どのようにテストを定式化するか考えてみると、 )
ファイルからネットワークを保存して読み込むと、トランスフォーマーレイヤーでエラーが発生します。
メソッドの
bool CLayer::CreateElement(int index)
という行の
int type=FileReadInteger(iFileHandle);
は0を読み、スイッチはデフォルトのfalseになる。
(どうやら書き込みの非同期があるようだ)。
もしすでに修正されていたら、スピードアップのヒントをくださるか、ファイルを送ってください。
まあ、同じことが2回修正することではありませんし、ライブラリに多くの変更を加えることはありません。
テスターでの作業のために変更を加えたし、新しい記事があなたの編集の新しいバージョンに転送する必要があることが出てきたときに忘れてしまう)。
ファイルからネットワークを保存して読み込むと、トランスフォーマーレイヤーでエラーが発生する。
メソッドの
bool CLayer::CreateElement(int index)
を文字列
int type=FileReadInteger(iFileHandle);
は0を読み込み、スイッチはデフォルトのfalseになる。
(どうやら書き込みの非同期があるようだ)。
もしすでに修正されているようでしたら、スピードアップのヒントをくださるか、ファイルを送ってください。
まあ、その1と同じ2回修正することはありませんし、ちょうどライブラリに多くの変更を加えたくない。
テスターでの作業のために変更を加え、その後、新しい記事が出たときにあなたが新しいバージョンに編集を転送する必要があることを忘れてしまった)。
Good day,
現在、新しい記事はモデレーターによってチェックされています。このエラーはそこで修正されます。
こんにちは、
現在モデレーターがチェック中の新しい記事があります。この誤りはそちらで修正されています。
素晴らしい!待ちましょう。