
MQL5とデータ処理パッケージの統合(第5回):適応学習と柔軟性

はじめに
多くのアルゴリズムトレーダーが直面する問題は、従来の取引システムの硬直性と適応力の欠如にあります。前回の記事で述べた通り、ほとんどのルールベースのエキスパートアドバイザー(EA)は、静的な条件や閾値でハードコーディングされており、リアルタイムの市場変動やボラティリティの変化、未知のパターンに柔軟に対応できません。その結果、特定の市場環境では優れたパフォーマンスを示すものの、市場の挙動が変化すると性能が低下し、チャンスを逃したり、誤シグナルが頻発したり、長期的なドローダウンに直面することになります。
適応学習モードと柔軟性モードの導入は、この問題に対する有効な解決策です。Pythonを用いて過去のXAU/USD価格変動から継続的に学習できる強化学習モデルを構築することで、市場の変化に応じて戦略を自動的に調整できるシステムを実現します。Pythonのライブラリ(PyTorch、Gym、Pandasなど)を活用すれば、データ前処理、環境シミュレーション、モデル最適化を高度におこなうことが可能です。学習が完了したモデルはONNX形式でエクスポートでき、MQL5環境内での実運用への組み込みが可能になります。
履歴データの取得
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2025, 05, 15, tzinfo=timezone.utc) utc_to = datetime.(2025, 07,08, tzinfo=timezone.utc) # Get bars from XAU H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("XAUUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "XAU_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
履歴データを取得するために、まずmt5.initialize()関数を使ってMetaTrader 5ターミナルとの接続を初期化します。これにより、PythonとMetaTrader 5プラットフォーム間で通信が可能になります。次に、データ抽出の対象期間を指定するため、開始日と終了日を設定します。これらの日付はUTCのdatetimeオブジェクトとして扱い、タイムゾーン間の一貫性を保ちます。本例では、スクリプトはXAUUSDの過去1時間足データを、2025年5月15日から2025年7月8日までの期間で取得するようmt5.copy_rates_range()関数を使用して構成されています。
filename = "XAUUSD_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
ご存知の通り、私のOSはLinuxです。Windows OSをお使いの場合、以下のPythonスクリプトを使って履歴データを簡単に取得できます。
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2025, 05, 15, tzinfo=timezone.utc) utc_to = datetime(2025, 07, 08, tzinfo=timezome.utc) # Get bars from XAUUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("XAUUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10)
プログラムで履歴データを取得できない場合は、MetaTrader 5プラットフォームから手動でダウンロードすることも可能です。まずプラットフォームを起動し、上部メニューから[ツール]>[オプション]を開いて[チャート]設定に移動します。ここで、[チャートの最大バー数]を指定する必要があります。[Unlimited]を選択することを推奨します。特に日付範囲を扱う場合、指定した期間に何本のバーがあるか正確に予測できないためです。
次に、実際のデータをダウンロードするには、メニューバーから[表示]>[銘柄]を選択します。これにより[銘柄]ウィンドウが開き、[仕様]タブが表示されます。そこから、必要なデータの種類に応じて、[チャートバー]タブまたは[ティック]タブを選択します。取得したい過去データの開始日と終了日を入力して[情報呼出]ボタンをクリックします。データが取得できたら、後で利用できるように.csv形式でエクスポートして保存します。
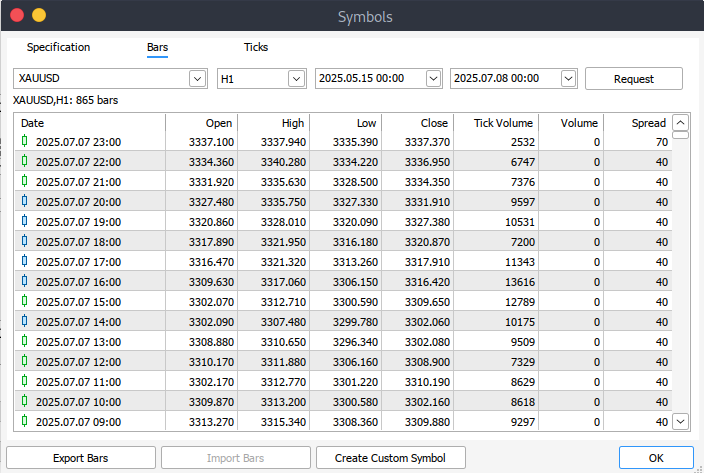
導入手順
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_j/Documents/Art Draft/Data Science/Adaptive Learning/XAUUSD_H1.csv' xau_data = pd.read_csv(file_path) # Display basic information about the dataset xau_data_info = xau_data.info() xau_data_head = xau_data.head() xau_data_info, xau_data_head
まずデータセットの構造を理解するために確認をおこないます。具体的には、info()関数を用いてデータ型、次元、欠損値の有無などをチェックします。さらに、head()関数で最初の数行を表示し、データの内容やレイアウトを把握します。このステップは探索的データ分析(EDA)の基本的な手順であり、データが正しくインポートされていることを確認すると同時に、その構造や特徴を把握するためのものです。
# Reload the data with tab-separated values xau_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing xau_data_info = xau_data.info() xau_data_head = xau_data.head() xau_data_info, xau_data_head
このコードブロックでは、指定されたファイルパスからXAU/USDの履歴データを再読み込みします。区切り文字にはデフォルトのカンマではなくタブ(\t)を使用しています。これは、TSV(タブ区切り値)ファイルを正しく解析するために重要です。データがxau_data DataFrameに読み込まれた後、info()を使って列のデータ型、非null件数、メモリ使用量などの基本情報を出力し、head()で最初の数行を表示してデータ内容を簡単に確認します。
import pandas as pd import numpy as np import ta from sklearn.preprocessing import StandardScaler # Split the single column into proper columns if len(xau_data.columns) == 1: # Extract column headers from the first row headers = xau_data.columns[0].split('\t') # Split data into separate columns xau_data = xau_data[xau_data.columns[0]].str.split('\t', expand=True) xau_data.columns = headers # Convert columns to proper data types numeric_cols = ['<OPEN>', '<HIGH>', '<LOW>', '<CLOSE>', '<TICKVOL>', '<VOL>', '<SPREAD>'] xau_data[numeric_cols] = xau_data[numeric_cols].apply(pd.to_numeric, errors='coerce') # Clean and create features xau_data = xau_data.dropna() xau_data['return'] = xau_data['<CLOSE>'].pct_change() # Add technical indicators xau_data['rsi'] = ta.momentum.RSIIndicator(xau_data['<CLOSE>'], window=14).rsi() xau_data['macd'] = ta.trend.MACD(xau_data['<CLOSE>']).macd_diff() xau_data['sma_20'] = ta.trend.SMAIndicator(xau_data['<CLOSE>'], window=20).sma_indicator() xau_data['sma_50'] = ta.trend.SMAIndicator(xau_data['<CLOSE>'], window=50).sma_indicator() xau_data = xau_data.dropna() # Normalize features scaler = StandardScaler() features = ['rsi', 'macd', 'sma_20', 'sma_50', 'return'] xau_data[features] = scaler.fit_transform(xau_data[features])
このコードブロックでは、まずXAU/USDの履歴データセットをクリーンアップおよびフォーマットします。データが誤って1列として読み込まれていた場合(タブ区切りファイルで起こり得ます)、スクリプトはその列をタブで分割し、正しいヘッダーと値を抽出します。その後、open、high、low、close、volume、spreadなどの主要列を明示的に数値型に変換し、変換時のエラーは「errors='coerce'」で処理します。続いて、欠損値を削除し、終値の前日比(パーセンテージ変化)から日次リターン列を追加します。
次のセクションでは、TA(テクニカル分析)ライブラリを用いてデータセットにテクニカル指標を追加します。RSI(相対力指数)、MACD(移動平均収束拡散法)、20期間および50期間の単純移動平均などを終値を基に計算します。これらの特徴量は、アルゴリズム取引においてトレンドやモメンタムをモデルが捉えるために一般的に使用されます。最後に、選択した特徴量列はscikit-learnのStandardScalerで標準化され、平均0、分散1に揃えられます。これは機械学習や強化学習モデルにデータを入力する前の重要な前処理ステップです。
import gym from gym import spaces class TradingEnv(gym.Env): def __init__(self, df, window_size=30, initial_balance=10000): super(TradingEnv, self).__init__() self.df = df.reset_index(drop=True) self.window_size = window_size self.initial_balance = initial_balance self.action_space = spaces.Discrete(3) # 0: hold, 1: buy, 2: sell # Use correct shape (window_size, number of features) self.observation_space = spaces.Box( low=-np.inf, high=np.inf, shape=(self.window_size, len(features)), dtype=np.float32 ) def reset(self): self.current_step = self.window_size self.balance = self.initial_balance self.position = 0 # 1 = long, -1 = short, 0 = neutral self.entry_price = 0 self.trades = [] return self._next_observation() def _next_observation(self): # Use iloc to prevent overshooting shape obs = self.df.iloc[self.current_step - self.window_size : self.current_step] obs = obs[features].values return obs def step(self, action): current_price = self.df.loc[self.current_step, '<CLOSE>'] reward = 0 if action == 1 and self.position == 0: # Buy self.position = 1 self.entry_price = current_price elif action == 2 and self.position == 0: # Sell self.position = -1 self.entry_price = current_price elif action == 0 and self.position != 0: # Close position if self.position == 1: reward = current_price - self.entry_price elif self.position == -1: reward = self.entry_price - current_price self.position = 0 self.current_step += 1 done = self.current_step >= len(self.df) - 1 obs = self._next_observation() return obs, reward, done, {}
上記のコードでは、カスタムのOpenAI Gym環境「TradingEnv」を定義しています。これは、過去の金融データ(本例ではXAU/USD)を用いて強化学習エージェントに取引判断を学習させるための環境です。この環境では、保持(hold=0)、買い(buy=1)、売り(sell=2)の3つの離散行動が可能です。初期化時には過去の観測データの固定ウィンドウ(window_size)を用い、データの特徴量(RSI,、MACDなど)をもとに取引動作をシミュレートします。観測空間は過去の特徴量のウィンドウで構成され、環境は残高、ポジション状態、エントリ価格などの主要要素を追跡します。
reset()関数は、新しいエピソードに向けてステップカウンタ、残高、ポジション、未決済取引をリセットして環境を初期化します。step()関数はエージェントの各行動に対応するロジックを実装します。ニュートラルポジション時に買いまたは売りを選択すると取引を開始し、既にポジションを持った状態で保持(hold)を選ぶとポジションをクローズし、損益が報酬として計算されます。エピソードはデータセットの最後に到達する(done=True)までステップごとに進行し、返される観測値は過去特徴量のスライスで、エージェントが次の判断をおこなうために使用されます。
import torch.nn as nn import torch.nn.functional as F class DuelingDQN(nn.Module): def __init__(self, state_shape, action_dim): super(DuelingDQN, self).__init__() # Calculate flattened dimension flattened_dim = np.prod(state_shape) # Network layers self.fc1 = nn.Linear(flattened_dim, 128) # Value stream self.value_stream = nn.Sequential( nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 1) ) # Advantage stream self.advantage_stream = nn.Sequential( nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, action_dim) ) def forward(self, state): # Flatten state while keeping batch dimension x = state.view(state.size(0), -1) x = F.relu(self.fc1(x)) value = self.value_stream(x) advantages = self.advantage_stream(x) return value + (advantages - advantages.mean(dim=1, keepdim=True))
ここでは、PyTorchを用いてDueling Deep Q-Network (Dueling DQN)を定義します。これは標準的なDQNアーキテクチャの変種で、状態価値関数とアドバンテージ関数の推定を分離しています。DuelingDQNクラスはnn.Moduleを継承し、入力状態の形状(state_shape)と可能な行動の数(action_dim)をパラメータとして受け取ります。まず入力状態を1次元化して共有の全結合層(fc1)に通し、そこから出力を2つのストリームに分けます。1つは状態価値を推定し、もう1つは各行動のアドバンテージを推定します。
forward()メソッドでは、2つのストリームを次の式で再結合します。
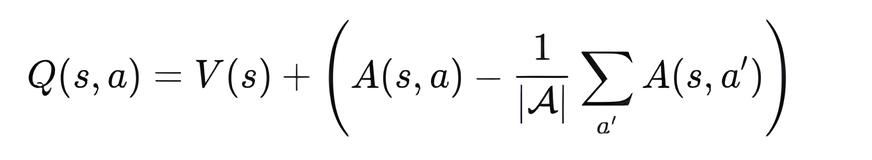
これにより、モデルは状態そのものの価値(V(s))と各行動を取る相対的利得(A(s, a))を区別して学習できるようになり、取引のような価値ベースの強化学習タスクにおける安定性と性能が向上します。
# Training loop parameters env = TradingEnv(xau_data) # Use positional arguments instead of keyword arguments model = DuelingDQN(150, 3) # input_dim=150 (flattened state), action_dim=3 target_model = DuelingDQN(150, 3) # Same dimensions target_model.load_state_dict(model.state_dict())
出力
<All keys matched successfully>
ここでは、Dueling Deep Q-Network (Dueling DQN)エージェントの学習環境とモデルを初期化します。TradingEnv環境は、準備済みのxau_dataを使用して作成され、強化学習用の市場特徴量を提供します。DuelingDQNモデルのインスタンスを2つ作成します。model(オンラインネットワーク)とtarget_model(ターゲットネットワーク)です。どちらも入力次元を150に1次元化し、行動空間は3(買い、売り、保持)です。target_modelはmodelの重みをコピーして初期化されます。これは、DQN学習において、時間的差分更新中に遅延更新されるターゲットネットワークを使用することで学習の安定性を高める標準的な手法です。
class ReplayBuffer: def __init__(self, capacity=10000): self.buffer = deque(maxlen=capacity) def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done)) def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) state, action, reward, next_state, done = map(np.array, zip(*batch)) return ( torch.tensor(state, dtype=torch.float32), # Shape: [batch, state_dim] torch.tensor(action, dtype=torch.int64), # Should be integer (for indexing) torch.tensor(reward, dtype=torch.float32), torch.tensor(next_state, dtype=torch.float32), torch.tensor(done, dtype=torch.float32) ) def __len__(self): return len(self.buffer)
ReplayBufferクラスは、強化学習において学習用の経験を保存し、サンプリングするメモリバッファを実装しています。固定容量(デフォルト:10,000)のdequeを使用して、(state, action, reward, next_state, done)のタプルを効率的に管理します。push()メソッドは新しい経験をバッファに追加し、容量を超えた場合は自動的に最も古い経験を破棄します。
sample()メソッドはランダムに経験のバッチを選択し、PyTorchのテンソルに変換してモデル学習に適した形式にします。各要素のデータ型も適切に設定されます(例:actionはint64、stateやrewardはfloat32)。このバッファにより、連続するステップだけでなく、多様な過去の経験から学習できるため、学習の安定性と非相関性が確保されます。
env = TradingEnv(xau_data) obs_shape = env.observation_space.shape n_actions = env.action_space.n # Calculate flattened dimension flattened_dim = np.prod(obs_shape) # 30*5 = 150 model = DuelingDQN(flattened_dim, n_actions) target_model = DuelingDQN(flattened_dim, n_actions) target_model.load_state_dict(model.state_dict()) optimizer = optim.Adam(model.parameters(), lr=0.0005) buffer = ReplayBuffer() gamma = 0.99 epsilon = 1.0 batch_size = 64 target_update_interval = 10 all_rewards = [] all_actions = [] # We'll collect actions for the entire dataset # Training loop for episode in range(200): state = env.reset() total_reward = 0 done = False episode_actions = [] # Store actions for this episode while not done: if random.random() < epsilon: action = env.action_space.sample() else: with torch.no_grad(): # Flatten state and pass to model state_tensor = torch.tensor(state, dtype=torch.float32).flatten().unsqueeze(0) q_values = model(state_tensor) action = q_values.argmax().item() next_state, reward, done, _ = env.step(action) buffer.push(state, action, reward, next_state, done) state = next_state total_reward += reward episode_actions.append(action) # Record action if len(buffer) >= batch_size: s, a, r, s2, d = buffer.sample(batch_size) q_val = model(s).gather(1, a.unsqueeze(1)).squeeze() next_q_val = target_model(s2).max(1)[0] target = r + (1 - d) * gamma * next_q_val loss = nn.MSELoss()(q_val, target) optimizer.zero_grad() loss.backward() optimizer.step() epsilon = max(0.01, epsilon * 0.995) if episode % target_update_interval == 0: target_model.load_state_dict(model.state_dict()) print(f"Episode {episode}, Reward: {total_reward}") # After episode completes all_rewards.append(total_reward) all_actions.extend(episode_actions) # Add episode actions to master list
出力

この学習ループは、Dueling Deep Q-Network (Dueling DQN)を用いた取引向け強化学習環境を設定しています。まず、環境は過去のXAUUSDデータで初期化され、観測空間と行動空間から主要パラメータが決定されます。Dueling DQNモデルとターゲットモデルが作成され、どちらも入力を1次元化した形状(150次元:30ステップ×5特徴量)を持ちます。さらに、オプティマイザー(Adam)やリプレイバッファ、割引率 (gamma)、探索率 (epsilon)、バッチサイズ、ターゲットネットワークの更新頻度などのハイパーパラメータが設定されます。
各エピソードでは、環境をリセットし、エージェントはステップごとにepsilon-greedy方策で行動を選択します。乱数がepsilon未満の場合はランダム行動を選択し、それ以外ではモデルが最も高いQ値を予測する行動を選びます。行動を実行すると、環境から報酬が返され、それがリプレイバッファに保存されます。バッファに十分なデータが溜まったら、経験のバッチをサンプリングしてモデルを学習させます。Q値とターゲットを計算し、平均二乗誤差(MSE)損失を逆伝播させてモデルパラメータを更新します。
学習の安定化のために、ターゲットモデルは定期的に現在のモデルの重みで更新されます。epsilonは徐々に減衰させ、探索を減らして学習済み知識を活用できるようにします。学習中は、各エピソードごとの総報酬や行動が記録され、パフォーマンス評価に使用されます。このループを通じて、エージェントは探索と活用のバランスを取りながら、最適な取引戦略を学習します(エピソード数200回)。
import matplotlib.pyplot as plt # Plotting performance metrics like cumulative reward plt.plot([r for r in range(len(buffer.buffer))], label="Reward Trend") plt.title("Training Rewards") plt.show()
出力
ここではmatplotlibを使用して、リプレイバッファ内のデータに基づき報酬の推移をプロットし、学習パフォーマンスを可視化します。これにより、エージェントの累積報酬が学習中にどのように変化しているかを追跡できます。
import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(all_rewards) plt.xlabel("Episode") plt.ylabel("Total Reward") plt.title("Training Performance") plt.grid(True) plt.show()
出力
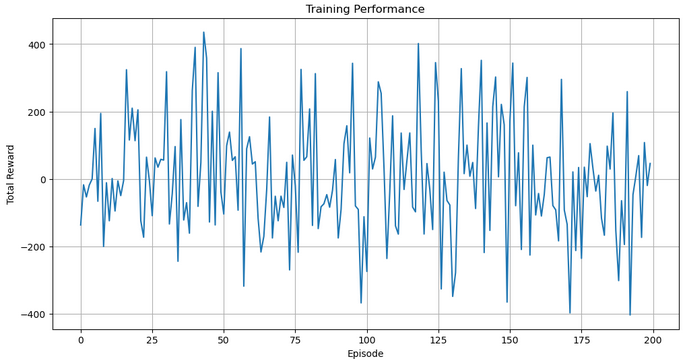
次に、各エピソードで得られた総報酬を格納したall_rewardsをプロットすることで、エージェントのパフォーマンスを可視化します。このプロットにより、学習の進捗状況や取引エージェントの安定性を時間の経過とともに把握でき、グリッドと明確なラベルにより読みやすさも向上します。
# Run a clean evaluation with the trained model (no exploration) eval_env = TradingEnv(xau_data) state = eval_env.reset() eval_actions = [] # Store actions for this single episode with torch.no_grad(): while True: # Flatten state and predict state_tensor = torch.tensor(state, dtype=torch.float32).flatten().unsqueeze(0) q_values = model(state_tensor) action = q_values.argmax().item() next_state, _, done, _ = eval_env.step(action) eval_actions.append(action) state = next_state if done: break # Now plot using eval_actions close_prices = xau_data['<CLOSE>'].values window_size = eval_env.observation_space.shape[0] # Create action array with same length as price data action_array = np.full(len(close_prices), np.nan) action_array[window_size:window_size + len(eval_actions)] = eval_actions # Create plot plt.figure(figsize=(14, 8)) plt.plot(close_prices, label='XAUUSD Price', alpha=0.7) # Plot buy signals (action=1) buy_mask = (action_array == 1) buy_indices = np.where(buy_mask)[0] plt.scatter(buy_indices, close_prices[buy_mask], color='green', label='Buy', marker='^', s=100) # Plot sell signals (action=2) sell_mask = (action_array == 2) sell_indices = np.where(sell_mask)[0] plt.scatter(sell_indices, close_prices[sell_mask], color='red', label='Sell', marker='v', s=100) plt.legend() plt.title("Trading Actions on XAUUSD (Trained Policy)") plt.xlabel("Time Step") plt.ylabel("Price") plt.grid(True) plt.show()
出力
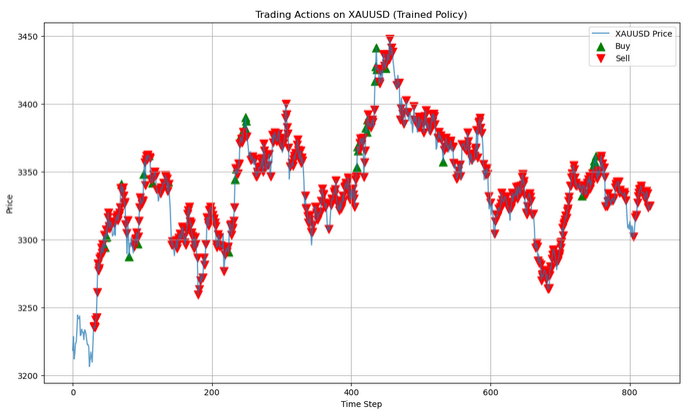
この評価フェーズでは、学習済みモデルを使用して、探索のないクリーンな環境(eval_env)で予測をおこないます。エージェントは市場の状態を観察し、学習済みのQ値に基づいて最適な行動を選択します(最大のQ値を貪欲に選択)。その後、取った行動を記録します。このループはエピソードの終了まで続き、エージェントがランダム性なしで学習済みの方針を実演できるようにします。
dummy_input = torch.randn(1, *obs_shape) torch.onnx.export(model, dummy_input, "dueling_dqn_xauusd.onnx", input_names=["input"], output_names=["output"], dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}}
最後に、学習済みのDueling DQNモデルをダミー入力を使ってONNX形式にエクスポートします。これにより、PyTorch以外の環境でも取引モデルを展開できるようになり、リアルタイムシステムやMQL5環境での利用が可能になります。
MQL5ですべてをまとめる
//+------------------------------------------------------------------+ //| ONNX_DQN_Trading_Script.mq5 | //| Copyright 2023, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- input parameters input string ModelPath = "dueling_dqn_xauusd.onnx"; // File in MQL5\Files\ input int WindowSize = 30; // Observation window size input int FeatureCount = 5; // Number of features //--- ONNX model handle long onnxHandle; //--- Normalization parameters (REPLACE WITH YOUR ACTUAL VALUES) const double RSI_MEAN = 55.0, RSI_STD = 15.0; const double MACD_MEAN = 0.05, MACD_STD = 0.5; const double SMA20_MEAN = 1800.0, SMA20_STD = 100.0; const double SMA50_MEAN = 1800.0, SMA50_STD = 100.0; const double RETURN_MEAN = 0.0002, RETURN_STD = 0.01; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load ONNX model onnxHandle = OnnxCreate(ModelPath, ONNX_DEFAULT); if(onnxHandle == INVALID_HANDLE) { Print("Error loading model: ", GetLastError()); return; } //--- Prepare input data buffer double inputData[]; ArrayResize(inputData, WindowSize * FeatureCount); //--- Collect and prepare data if(!PrepareInputData(inputData)) { Print("Data preparation failed"); OnnxRelease(onnxHandle); return; } //--- Set input shape (no need to set shape for dynamic axes) //--- Run inference double outputData[3]; if(!RunInference(inputData, outputData)) { Print("Inference failed"); OnnxRelease(onnxHandle); return; } //--- Interpret results InterpretResults(outputData); OnnxRelease(onnxHandle); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(double &inputData[]) { //--- Get closing prices double closes[]; int closeCount = WindowSize + 1; if(CopyClose(_Symbol, _Period, 0, closeCount, closes) != closeCount) { Print("Not enough historical data. Requested: ", closeCount, ", Received: ", ArraySize(closes)); return false; } //--- Calculate returns (percentage changes) double returns[]; ArrayResize(returns, WindowSize); for(int i = 0; i < WindowSize; i++) returns[i] = (closes[i] - closes[i+1]) / closes[i+1]; //--- Calculate technical indicators double rsi[], macd[], sma20[], sma50[]; if(!CalculateIndicators(rsi, macd, sma20, sma50)) return false; //--- Verify indicator array sizes if(ArraySize(rsi) < WindowSize || ArraySize(macd) < WindowSize || ArraySize(sma20) < WindowSize || ArraySize(sma50) < WindowSize) { Print("Indicator data mismatch"); return false; } //--- Normalize features and fill input data int dataIndex = 0; for(int i = WindowSize - 1; i >= 0; i--) { inputData[dataIndex++] = (rsi[i] - RSI_MEAN) / RSI_STD; inputData[dataIndex++] = (macd[i] - MACD_MEAN) / MACD_STD; inputData[dataIndex++] = (sma20[i] - SMA20_MEAN) / SMA20_STD; inputData[dataIndex++] = (sma50[i] - SMA50_MEAN) / SMA50_STD; inputData[dataIndex++] = (returns[i] - RETURN_MEAN) / RETURN_STD; } return true; } //+------------------------------------------------------------------+ //| Calculate technical indicators | //+------------------------------------------------------------------+ bool CalculateIndicators(double &rsi[], double &macd[], double &sma20[], double &sma50[]) { //--- RSI (14 period) int rsiHandle = iRSI(_Symbol, _Period, 14, PRICE_CLOSE); if(rsiHandle == INVALID_HANDLE) return false; if(CopyBuffer(rsiHandle, 0, 0, WindowSize, rsi) != WindowSize) return false; IndicatorRelease(rsiHandle); //--- MACD (12,26,9) int macdHandle = iMACD(_Symbol, _Period, 12, 26, 9, PRICE_CLOSE); if(macdHandle == INVALID_HANDLE) return false; double macdSignal[]; if(CopyBuffer(macdHandle, 0, 0, WindowSize, macd) != WindowSize) return false; if(CopyBuffer(macdHandle, 1, 0, WindowSize, macdSignal) != WindowSize) return false; // Calculate MACD difference (histogram) for(int i = 0; i < WindowSize; i++) macd[i] = macd[i] - macdSignal[i]; IndicatorRelease(macdHandle); //--- SMA20 int sma20Handle = iMA(_Symbol, _Period, 20, 0, MODE_SMA, PRICE_CLOSE); if(sma20Handle == INVALID_HANDLE) return false; if(CopyBuffer(sma20Handle, 0, 0, WindowSize, sma20) != WindowSize) return false; IndicatorRelease(sma20Handle); //--- SMA50 int sma50Handle = iMA(_Symbol, _Period, 50, 0, MODE_SMA, PRICE_CLOSE); if(sma50Handle == INVALID_HANDLE) return false; if(CopyBuffer(sma50Handle, 0, 0, WindowSize, sma50) != WindowSize) return false; IndicatorRelease(sma50Handle); return true; } //+------------------------------------------------------------------+ //| Run model inference | //+------------------------------------------------------------------+ bool RunInference(const double &inputData[], double &outputData[]) { //--- Run model directly without setting shape (for dynamic axes) if(!OnnxRun(onnxHandle, ONNX_DEBUG_LOGS, inputData, outputData)) { Print("Model inference failed: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Interpret model results | //+------------------------------------------------------------------+ void InterpretResults(const double &outputData[]) { //--- Find best action int bestAction = ArrayMaximum(outputData); string actionText = ""; switch(bestAction) { case 0: actionText = "HOLD"; break; case 1: actionText = "BUY"; break; case 2: actionText = "SELL"; break; } //--- Print results Print("Model Output: [HOLD: ", outputData[0], ", BUY: ", outputData[1], ", SELL: ", outputData[2], "]"); Print("Recommended Action: ", actionText); }
このMQL5スクリプト「ONNX_DQN_Trading_Script.mq5」は、ONNX形式でエクスポートされた学習済みDueling DQNモデルを使用して、MetaTrader 5内で取引シグナルを生成するために設計されています。スクリプトはまずFilesディレクトリからONNXモデルを読み込み、固定された観測ウィンドウに基づいて入力データを準備します。直近の価格データを収集し、RSI、MACDヒストグラム、SMA20、SMA50などの複数のテクニカル指標を計算した後、あらかじめ定義された平均値と標準偏差に基づいて正規化します。処理済みの特徴量は、モデルが期待する1次元配列の形式に整形されます。
入力ベクトルが準備できたら、スクリプトはOnnxRunを使って推論を実行し、HOLD、BUY、SELLの各行動に対応するQ値の予測結果を返します。最も高い値を持つ行動がモデルの推奨取引として解釈され、ターミナルに表示されます。推論処理はエラーチェックでラップされており、操作完了後にはハンドルを解放してシステムリソースを確保します。
結論
まとめると、私たちは過去のXAU/USDデータを用いて学習させたDueling DQNアーキテクチャを活用し、適応型で柔軟な取引モデルを構築しました。本モデルは、RSI、MACDヒストグラム、SMA20、SMA50、リターン率などのテクニカル特徴量をローリングウィンドウで処理し、統計パラメータに基づいて正規化しています。学習の安定性を確認するため、累積報酬を用いて学習進捗を可視化しました。学習後、モデルはONNX形式にエクスポートされ、MetaTrader 5に統合可能となっています。専用のMQL5スクリプトでは、モデルを読み込んで入力データを動的に準備して、推論を実行し、出力値が最も高い行動(HOLD、BUY、SELL)をモデルの推奨取引として解釈します。
結論として、このエンドツーエンドのパイプラインは、トレーダーに対して強力で自動化された意思決定支援システムを提供します。深層強化学習とリアルタイム市場データを融合させたことで、入力特徴量を調整し再学習することで新しい通貨ペアや指標構成にも容易に適応可能です。さらに、ONNX推論をMQL5内に直接組み込むことで、外部ソフトウェアに依存せずにプラットフォーム上でインテリジェントなモデルを運用でき、戦略の実行効率と市場対応力の両方を向上させます。
| ファイル名 | 説明 |
|---|---|
| Ada_flex.mq5 | Pythonで学習させた強化学習モデルとMetaTrader 5の橋渡しとして機能するMQL5スクリプト |
| Ada_L.ipynb | モデルの学習および保存をおこなうJupyter Notebookファイル |
| XAUUSD_H1.csv | XAUUSDの過去の価格データを含むファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18761
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索