
ニューラルネットワークが簡単に(第50回):Soft Actor-Critic(モデルの最適化)

はじめに
Soft Actor-Criticアルゴリズムの研究を続けます。前回の記事では、アルゴリズムを実装しましたが、収益性の高いモデルを訓練することができませんでした。今日は可能な解決策を考えてみましょう。同じような疑問は、「先延ばしのモデル、理由と解決策」稿でもすでに提起されています。この分野の知識を広げ、私たちのSoft Actor-Criticモデルを例として新しいアプローチを検討することを提案します。
1.モデルの最適化
構築したモデルの最適化に直接移る前に、Soft Actor-Criticが連続行動空間における確率モデルの強化学習アルゴリズムであることを思い出してください。この方法の主な特徴は、報酬関数にエントロピー成分を導入したことです。
確率的Actor方策を使用することで、モデルはより柔軟になり、いくつかの行動が不確実であったり、明確なルールを定義できないような複雑な環境における問題を解決することができます。この方策は、確率的な要素を考慮し、明確なルールに縛られないため、多くのノイズを含むデータを扱う場合、よりロバストであることが多くなります。
エントロピーの要素を加えることで、環境の探索を促し、確率の低い行動の報酬を増やします。探査と開発のバランスは温度比に支配されます。
数学的な形では、Soft Actor-Critic法は以下の式で表すことができます。

1.1 Actor方策に確率性を加える
実装では、OpenCLを使った実装が複雑なため、確率的Actor方策の使用を断念しました。TD3と同様に、選択された行動の周囲をランダムにオフセットすることに置き換えました。このアプローチは実装が簡単で、モデルが環境を探索することができます。しかし、デメリットもあります。
まず注目されるのは、サンプリングされた行動とモデルによって学習された分布との間に関連性がないことです。場合によっては、学習した分布がサンプリングエリアより広い場合、調査エリアが圧縮されます。つまり、モデルの方針は最適ではない可能性が高く、ランダムに選択された学習の開始点に依存します。結局のところ、新しいモデルを初期化するときは、ランダムな重みで埋めます。
他のケースでは、サンプリングされた行動が学習された分布から外れることがあります。これは研究の幅を広げますが、報酬関数のエントロピー成分と相反します。モデルから見れば、学習された分布の外にある行動は確率ゼロです。エントロピーの構成要素のおかげで、その価値に関係なく最大の報酬を受け取ることができます。
訓練中、モデルは利益を生む戦略を見つけようと努力し、最大の報酬を得る行動の可能性を高めます。同時に、収益性の低い、不採算な行動をとる可能性も低くなります。先ほどの単純サンプリングでは、この要素は考慮されていません。これは、サンプリングエリアからのあらゆる行動を等確率で提供してくれます。利益を生まない行動の確率が低いため、エントロピー成分が高くなります。これは行動の真価を歪め、過去に蓄積された経験を無にし、誤ったActor方策を構築することにつながります。
Actorの確率モデルを構築し、学習した分布から行動をサンプリングします。
OpenCLコンテキスト側に擬似乱数ジェネレーターがないことはすでにお話ししましたが、メインプログラム側のジェネレーターを使うことにします。
同時に、学習した分布はOpenCL側でのみ利用可能であることも覚えていらっしゃるとおもいます。これはモデルの内部オブジェクトに含まれています。したがって、サンプリングプロセスを準備するために、メインプログラムとOpenCLコンテキストの間でデータ転送を実装する必要があります。これは、プロセスがどこに配置されているかには関係ありません。
メインプログラム側の処理を整理する際、分布を読み込む必要があります。これには、確率と対応する関数値という2つのバッファが関係します。
OpenCLのコンテキスト側でプロセスを準備する場合、ランダムな値のバッファを渡さなければなりません。これは後で別の行動を選択するために使われます。
ここでもう1つ考慮すべき点があります。取得した値の消費者です。操作中は、サンプリングされた値を使って行動します。しかし訓練中は、OpenCL側のコンテキストのCriticに転送します。ご存知のように、モデル訓練は、操作の実行時間を短縮するために最も厳しい要件を課しています。これを考慮すると、OpenCLコンテキストにランダム値のバッファを1つだけ転送し、そこでさらにサンプリング処理をおこなうという決定は、極めて論理的であるように思われます。
決断が下されたので、実行に移しましょう。まず、OpenCLプログラムのSAC_AlphaLogProbsカーネルを修正します。私たちの変更は、指定されたカーネルのアルゴリズムをある程度単純化することにさえなります。
カーネルの外部パラメータにランダムな値のバッファを1つ追加します。このバッファでサンプリング処理を準備するために、[0, 1]の範囲のランダムな値のセットを受け取ることを期待します。
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, __global float *random, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float prob = 0; float value = 0; float sum = 0; float rnd = random[i];
行動を選択するために、分析対象の行動のすべての分位の確率を列挙し、その累積和を計算するループを準備します。ループの本体では、累積和を計算すると同時に、その現在値と結果のランダム値をチェックします。この値を超えるとすぐに、現在の分位値を選択された行動として使用し、ループ反復の実行を中断します。
for(int r = 0; r < count_quants; r++) { prob = probs[shift + r]; sum += prob; if(sum >= rnd || r == (count_quants - 1)) { value = quantiles[shift + r]; break; } }
これで、以前のように最も近い分量の組を探す必要はなくなりました。既知の確率で1つの分位数が選択されています。あとは結果の値をアクティブにして、エントロピー成分の値を計算するだけです。
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; else outputs[i] = value; break; default: outputs[i] = value; break; } log_probs[i] = -alphas[i] * log(prob); }
カーネルに変更を加えた後、メインプログラムのコードを補足します。まず、CNeuronSoftActorCriticクラスを変更することから始めます。ここでは、乱数値用のバッファを追加します。初期化は、cLogProbsバッファと同様にInitメソッドでおこなわれます。このことにこだわるつもりはありません。直接パスごとに新たに記入されるため、保存する必要はありません。そのため、ファイル処理方法は調整されません。
class CNeuronSoftActorCritic : public CNeuronFQF { protected: .......... .......... CBufferFloat cRandomize; .......... .......... };
フォワードパスメソッドCNeuronSoftActorCritic::feedForwardに目を向けてみましょう。ここでは、親クラスと内部のcAlphas層を直接通過した後、行動の数によってループを準備し、cRandomizeバッファにランダムな値を入力します。
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false; //--- int actions = cRandomize.Total(); for(int i = 0; i < actions; i++) { float probability = (float)MathRand() / 32767.0f; cRandomize.Update(i, probability); } if(!cRandomize.BufferWrite()) return false;
満たされたバッファのデータは、OpenCLのコンテキストメモリに渡されます。
次に、カーネルを実行キューに入れます。ここで、カーネルに追加されたパラメータを転送する必要があります。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_random, cRandomize.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
このように、Actorのフォワードパス中の行動選択の確率性を実装しました。しかし、その逆のパスにはニュアンスがあります。ポイントは、後方パスでは、各判定要素にその寄与度に応じて誤差勾配を分配することです。以前は、親クラスの直接パスを使用しており、エラー勾配も同様に分布していました。これで行動選択の最終段階での調整が終わりました。その結果、誤差勾配の分布にも反映されるはずです。
ランダムな値を生成することはモデルの範囲外であり、それらに勾配をつけることはしません。しかし、選択された行動についてのみ、誤差勾配の分布を準備する必要があります。結局のところ、他のどの値も、実行されたActorの行動には影響を与えませんでした。したがって、その誤差勾配は0です。
直接パスとは異なり、親クラスのメソッドを呼び出すと保存したグラデーションが上書きされるため、機能に新しいメソッドを追加することはできません。したがって、ニューラル層の要素に誤差勾配を分配する方法を完全に再定義しなければなりません。
いつものように、SAC_OutputGradientカーネルを作成することから始めます。カーネルパラメータの構造は、親クラスのFQF_OutputGradientカーネルを思い起こさせるでしょう。これをベースに、1つのバッファと2つの定数を加えました。
- output - フォワードパス結果のバッファ
- count_quants - 各行動の分位数
- activation - 適用される活性化関数
__kernel void SAC_OutputGradient(__global float* quantiles, __global float* delta_taus, __global float* output_gr, __global float* quantiles_gr, __global float* taus_gr, __global float* output, const int count_quants, const int activation ) { size_t action = get_global_id(0); int shift = action * count_quants;
行動の数に応じて、1次元のタスク空間でカーネルを起動します。
カーネル本体では、解析対象のActorの行動を即座に特定し、データバッファ内のオフセットを決定します。
次に、層の結果バッファから、各分位の平均値と完璧な行動を比較するループを用意します。ただし、平均分位値は元の値に格納され、結果バッファの選択行動には活性化関数後の値が格納されることに留意する必要があります。したがって、値を比較する前に、各分位の平均値に活性化関数を適用する必要があります。
for(int i = 0; i < count_quants; i++) { float quant = quantiles[shift + i]; switch(activation) { case 0: quant = tanh(quant); break; case 1: quant = 1 / (1 + exp(-quant)); break; case 2: if(quant < 0) quant = quant * 0.01f; break; } if(output[i] == quant) { float gradient = output_gr[action]; quantiles_gr[shift + i] = gradient * delta_taus[shift + i]; taus_gr[shift + i] = gradient * quant; } else { quantiles_gr[shift + i] = 0; taus_gr[shift + i] = 0; } } }
理論的には、逆関数を一度実行し、活性化関数の前に結果バッファの値を決定することができることに注意すべきです。しかし、計算の精度には誤差があるため、ほとんどの場合、元の値とは異なるものの、近い値を受け取ることになります。ある種の寛容さをもって比較せざるを得ないでしょう。これはかえって比較を複雑にし、精度を下げることになります。
分位数が一致した場合、誤差勾配を分位数の平均とその確率に分配します。残りの分位数とその確率については、勾配を0に設定します。
ループの反復が完了したら、カーネルをシャットダウンします。
前述のように、メインプログラムの側では、誤差勾配分布メソッドcalcInputGradientsを完全に再定義しなければなりません。このメソッドは、似たような親クラスのメソッドからコピーされたものです。この変更は、カーネルの上に記述されているキューイングブロックだけに影響しました。従って、今はその記述にこだわるつもりはありません。添付ファイル「..\NeuroNet_DNG\NeuroNet.mqh」にあります。
1.2 目標モデルの更新プロセスの調整
お気づきかもしれませんが、私はモデルで加重比率を更新するのにアダム法を好んで使っています。そこで、Criticのターゲットモデルのソフト更新にこの手法を導入するアイデアが生まれました。
覚えているかもしれませんが、Soft Actor-Criticアルゴリズムは、(0, 1}の範囲にある一定の比率を使って、ターゲットモデルをソフトに更新します。比率が1の場合、パラメータは単にコピーされます。0は適用されません。この場合、ターゲット モデルは更新されないためです。
アダム法を使用することで、モデルは個々の訓練済みパラメータの比率を独立して調整することができます。これにより、一方向にシフトしたパラメータを素早く更新することが可能になり、ターゲットモデルが初期値から第一近似値へより速くシフトすることになります。同時に、適応的な方法によって、多方向振動のコピー速度を下げることが可能になり、目標モデルの値のノイズを減らすことができます。
しかし、訓練の初期段階でモデルがアンバランスになるリスクには注意を払う必要があります。個々のパラメータをコピーするスピードに大きな差があると、予想外の予測不能な結果につながる可能性があります。
すべての長所と短所を評価した上で、このアプローチの有効性を実際に試してみることにしました。
OpenCLコンテキスト側でモデルの最適化処理をおこないます。すべての訓練済みモデルパラメータの現在値は、コンテキストメモリに保存されます。OpenCL側で訓練済みモデルとターゲットモデルの間で、これらのパラメータを転送する方が得策であることは、極めて論理的です。このアプローチには複数の利点があります。
- これにより、訓練済みモデルの現在のパラメータをコンテキストからメインメモリに読み込み、その後にターゲットモデルの新しいパラメータをコンテキストメモリにコピーするプロセスが不要になります。
- 並列データストリームで複数のパラメータを同時に転送することができます。
データを転送するためにSoftUpdateAdamカーネルを作成しましょう。カーネルパラメータには、4つのデータバッファへのポインタと、メソッドが提供する3つのパラメータを渡します。
__kernel void SoftUpdateAdam(__global float *target, __global const float *source, __global float *matrix_m, __global float *matrix_v, const float tau, const float b1, const float b2 ) { const int i = get_global_id(0); float m, v, weight;
現在のモデル層の更新されたパラメータの数に応じて、1次元タスク空間の各ニューラル層に対してカーネルを順次起動する予定です。このオプションでは、カーネル本体で定義されたスレッドIDが、解析対象のパラメータへのポインタとデータバッファのオフセットを同時に兼ねます。
ここでは、中間データを格納するローカル変数も宣言し、グローバルバッファから元のデータを書き込みます。
m = matrix_m[i]; v = matrix_v[i]; weight=target[i];
アダム法は、反勾配に向かってモデルパラメータを更新するために開発されました。この場合、誤差勾配は訓練済みモデルからのターゲットモデルのパラメータの偏差となります。反勾配に向かってパラメータの値を調整するので、偏差を、訓練済みモデルのパラメータと訓練済みモデルの対応するパラメータ間の差として定義します。
float g = source[i] - weight; m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
さらに、その2次値の誤差勾配の指数平均を即座に決定します。
次に、必要なパラメータのオフセットを決定し、対応する要素をグローバルデータバッファに格納します。
float delta = tau * m / (v != 0.0f ? sqrt(v) : 1.0f); if(delta * g > 0) target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT);
カーネル演算の最後に、誤差勾配の平均値とその2乗をグローバルデータバッファに保存します。この後のパラメータ更新の繰り返しで必要になります。
matrix_m[i] = m; matrix_v[i] = v; }
カーネルを作成したら、メインプログラムの側でそれを呼び出すプロセスを準備しなければなりません。ここには2つの選択肢があります。
- 新しいメソッドの作成
- 以前に作成したメソッドの更新
この記事では、CNeuronBaseOCL::WeightsUpdateAdamニューラル層の基本クラスのレベルに新しいメソッドを作成することを提案します。メソッドのパラメータには、先に作成したターゲットモデルのソフト更新メソッドと同様に、訓練済みモデルのニューラル層へのポインタとアップデート係数を渡します。デフォルトモデルを更新するために指定されたアダム法のハイパーパラメータを使用します。
bool CNeuronBaseOCL::WeightsUpdateAdam(CNeuronBaseOCL *source, float tau) { if(!OpenCL || !source) return false; if(Type() != source.Type()) return false; if(!Weights || Weights.Total() == 0) return true; if(!source.Weights || Weights.Total() != source.Weights.Total()) return false;
制御ブロックはメソッド本体に実装されます。ここでは、使用されているオブジェクトへのポインタの関連性をチェックします。また、現在のニューラル層のタイプと結果のポインタの対応関係もチェックします。
制御ブロックの受け渡しに成功したら、パラメータをカーネルに転送し、実行キューに入れます。
アダム法では、2つのデータバッファを追加で作成する必要があることに注意してください。しかし、モデルの学習可能パラメータを更新するために、各モデルに同様のバッファを作成することを覚えておきましょう。この場合、パラメータが更新されたターゲットモデルを扱うことになります。その最適化は、訓練済みモデルから定期的にデータを転送することでおこなわれます。つまり、限られた機能しか持たないモデルです。同時に、ターゲットモデル用に別のタイプのオブジェクトを作成するのではなく、必要なオブジェクトやバッファをすべて作成した上で、完全に機能するモデル用に以前作成したものを使用しました。これは、メモリリソースの非効率的な使用とみなすことができます。しかし、モデルを統一するために、意識的にこのステップを踏みました。これで、未使用のターゲットモデルバッファができました。それを使ってパラメータを更新していきます。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Weights.Total()}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, source.getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, getFirstMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, getSecondMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
各段階での作業の正確さを監視することを忘れてはなりません。すべての反復が成功したら、メソッドを完了します。
メソッドを作ったら、その呼び出し方を考えて準備する必要があります。私は、モデルの全体的な構造を最小限の変更で、できるだけシンプルに呼び出せるアプローチを探したいと思いました。妥協点を見つけたようです。モデルのディスパッチャクラスとニューラル層の動的配列を通して外部プログラムからメソッドを呼び出すための独立したブランチは作りませんでした。その代わりに、以前に作成したCNeuronBaseOCL::WeightsUpdate soft updateメソッドに入り、モデルアーキテクチャを記述する際に各ニューラル層ごとにユーザーが指定する、訓練済みモデルのパラメータを更新するメソッドのチェックを設定しました。ユーザがモデルパラメータを更新するためにアダム法を指定した場合、単に新しいメソッドを実行するようにワークフローをリダイレクトします。その他のパラメータ更新方法については、古典的なソフト更新を使用します。
bool CNeuronBaseOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(optimization == ADAM) return WeightsUpdateAdam(source, tau); //--- ........ ........ }
とりわけ、このアプローチは必要なデータバッファの確保を保証します。
1.3 ソースデータ構造に変更を加える
ソースのデータ構造にも気を配りました。ご存知のように、各履歴データバーの説明は12個の要素で構成されています。
- 始値と終値の差
- 初値と最高値の差
- 始値と最低価格の違い
- ローソク足の時間
- 曜日
- 月
- 5つの指標パラメータ
State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign);
このデータセットで私が注目したのはタイムスタンプでした。時間的要素を評価することは、季節性や異なるセッションにおける通貨の異なる挙動を理解する上で大きな価値があります。しかし、それぞれのローソク足にとって、それらの存在はどれほど重要なのでしょうか。個人的な意見としては、市場の現状をスナップショットとして全体的に把握するには、タイムスタンプは1セットで十分だと思います。以前は、1つのバッファのソースデータを使用する場合、各ローソク足の記述の構造を維持するために、このデータを繰り返すことを余儀なくされていました。これで、モデルに2つの初期データソースがある場合、口座状態記述バッファにタイムスタンプを入れることができます。ここでは、市場状況のスナップショットの履歴データのみを残します。こうすることで、情報容量を失うことなく、分析データの総量を減らすことができます。その結果、モデルの性能を上げながら、実行される操作の数を減らすことができます。
さらに、タイムスタンプの表現も変更しました。口座の状態を説明するのに、相対的なパラメータを使っていることを思い出してください。これにより、それらを比較可能な、部分的に正規化された形にすることができます。タイムスタンプの正規化されたビューが望まれます。同時に、プロセスの季節性に関する情報を保存することも重要です。このような場合、正弦関数と余弦関数を使うことが多いです。これらの関数のグラフは連続的かつ周期的です。関数サイクルの長さは既知であり、2πに等しくなります。
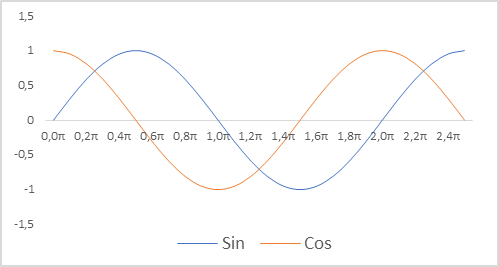
タイムスタンプを正規化し、周期性を考慮に入れるには、次のことが必要です。
- 現在時刻を期間サイズで割る
- 結果の値に定数 「2π」を掛ける
- 関数値(sinまたはcos)を計算する
- 結果の値をバッファに追加する
実装では、年、月、週、日の期間を使用しました。
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
また、ローソク足の説明と口座状態のサイズ定数を変更することを忘れないでください。それらの値は、蓄積された経験の軌跡を記述するためのバッファとして、モデルのアーキテクチャや配列のサイズに反映されます。
#define BarDescr 9 //Elements for 1 bar description #define AccountDescr 12 //Account description
ソースデータの準備、特にタイムスタンプの正規化は、モデル自体の構築やそのアーキテクチャとは無関係であることは注目に値します。これは外部プログラムの側でおこなわれますが、ソースデータの準備の質は、モデルの訓練プロセスと結果に大きく影響します。
2.モデル訓練
モデルの動作にプラスの変更を加えたので、訓練に移りましょう。第1段階では、「..\SoftActorCritic\Research.mq5」EAを使用して環境と対話し、データを学習セットに収集します。
指定されたEAでは、環境状態バッファから口座状態バッファにタイムスタンプを転送するために、上述の変更をおこないます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- ......... ......... //--- float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } State.AssignArray(sState.state); //--- ........ ........ //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return;
加えて、ヘッジ操作を断念することにしました。取引は、ボリュームの差だけ大きい方に開かれます。そのために、取引量の予測をチェックし、その量を減らします。
........ ........ //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
加えて、報酬にも注目しました。報酬の本体を形成する際には、口座残高の相対的な変化を使用しました。その値は希薄で、1を大きく下回ります。同時に、初期訓練段階での報酬のエントロピー成分の値は8~12の範囲で変動しました。エントロピー成分のサイズが比較にならないほど大きいことは明らかです。この値のズレを補うために、報酬の目標部分を形成するときの変化と同じように、残高の金額で割りました。それに加えて、LogProbMultiplierの減少率も導入しました。
........ ........ //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; if(Actor.GetLogProbs(temp)) reward += LogProbMultiplier * temp.Sum() / (float)PrevBalance; if(!Base.Add(sState, reward)) ExpertRemove(); }
これらの変更をおこなった後、訓練データを収集する第一段階を開始しました。そのために、EURUSD H1の履歴データを使用しました。データ収集は、2023年の最初の5か月間、フルパラメータ列挙モードでストラテジーテスターで実施されました。初期資本は1万米ドルです。この段階で、200パス分のサンプルデータベースを収集し、指定された時間間隔における「状態」→「行動」→「新しい状態」→「報酬」のデータセットを0.5百万以上得ました。
覚えておいでかもしれませんが、この段階では事前に訓練済みモデルはありません。各パスで、EAは新しいモデルを生成し、ランダムなパラメータで埋めます。履歴を通過する間、モデルの訓練はおこなわれません。従って、完全にランダムで独立したパスが200本得られます。いずれも利益は出ていません。

実際にモデルを学習する過程は、「..\SoftActorCritic\Study.mq5」EAにまとめられています。また、ここでいくつかのスポット的な編集もおこないました。
まず、口座状態記述ベクトルを生成するプロセスについて、前述の環境調査EAのアプローチと同様にタイムスタンプの追加という点で変更を加えました。
さらに、エントロピー成分の観点から目標報酬の形成を調整しました。アプローチは3つのEAすべてで同じであるべきです。
void Train(void) { ......... ......... //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { ......... ......... Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- ......... ......... //--- TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1] + LogProbMultiplier * log_prob.Sum() / (float)PrevBalance);
そして、ActorとCriticの訓練を分けました。前回と同様に、偶数回と奇数回の訓練反復でCritic1とCritic2を交互に使用しますが、Actorを訓練する際、使用しているCriticの訓練機能を無効にしています。Actorにはエラー勾配しか渡しません。この場合、Criticのパラメータは更新されません。従って、実環境の報酬に対して客観的なCriticを訓練することを目指します。
........ ........ //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(Result); Actor.GetLogProbs(log_prob); Result.Update(0, reward); Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Critic1.TrainMode(true); break; } Critic1.TrainMode(true);
さらに、Criticを訓練する際には、客観的なCriticが必要であるため、目標報酬からエントロピーの成分を除外します。一方、エントロピーの成分の機能は、Actorが環境を探索するように刺激することです。
Result.Update(0, reward - LogProbMultiplier * log_prob.Sum() / (float)PrevBalance); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Update Target Nets TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Criticのパラメータを更新した後、1つのCriticのターゲットモデルのみを更新します。それ以外のEAコードは変更されていません。添付ファイルでご覧ください。
変更後、100,000反復(デフォルトパラメータ)のサイクルでモデル訓練プロセスを開始します。この段階で、「Actor」と「2つのCritic」のモデルが形成されます。初期訓練もおこなわれます。
モデル訓練の最初のラウンドで大きな結果を期待してはいけません。これにはいくつかの理由があります。完了した反復回数は、例のベースの1/5しかカバーしていません。完全とは呼べません。その中に、モデルが学べる有益な箇所は1つもありません。
モデル訓練の第1段階が終了した後、以前に収集した例データベースを削除しました。私の論理はとてもシンプルです。このデータベースにはランダムな独立パスが含まれています。報酬には未知のエントロピー成分が含まれています。私は、訓練されていないモデルでは、すべての行動の可能性が等しいと仮定しています。しかし、いずれにせよ、モデルの確率分布とは比較にならないでしょう。そこで、以前に収集した事例データベースを削除し、新しいデータベースを作成します。
同時に、訓練サンプルを収集するプロセスを繰り返し、パラメータを完全に検索して環境調査EAの最適化を再実行します。このときだけ、反復処理されるエージェントの値をシフトさせます。この単純なトリックは、前回の最適化キャッシュからデータを読み込まないために必要です。
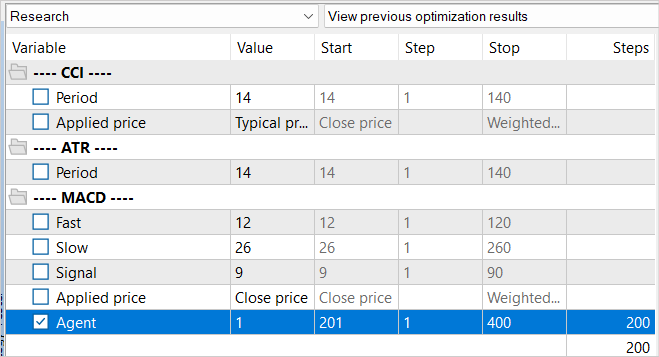
新しいサンプルベースとの主な違いは、環境探索の過程で、事前に訓練済みモデルが使われたことです。エージェントの行動の多様性は、Actorの方針の確率性によるものです。そして、すべての完了した行動は、モデルの学習された確率分布の中にあります。この段階で、最後にエージェントのパスをすべて回収します。
新たな事例データベースを収集した後、モデル学習用EA「..\SoftActorCritic\Study.mq5」を再実行します。今回は訓練の反復回数を500,000回に増やします。
2サイクル目の訓練が完了したら、訓練したモデルをテストするために「..\SoftActorCritic\Test.mq5」EAに移ります。環境調査EAと同様の変更を加えています。添付ファイルをご覧ください。
テスト用EAに切り替えたからといって、訓練が終わるわけではありません。訓練期間の履歴データでEAを数回実行します。私の場合は、2023年の最初の5カ月間です。10回パスをおこない、得られた利益幅のおおよそ上位1/4または1/5を決定しました。環境調査EAのコードに戻り、例のデータベースに保存されるパスの最小収益性に関する制限を導入してみましょう。
input double MinProfit = 10;
double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(profit >= MinProfit && profit != 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, profit, Frame); //--- return(ret); }
そのため、最適なパスだけを選び、それを使ってActorを訓練し、最適な戦略を使えるように努めています。
モデルを訓練しながら徐々にハードルを上げていくつもりなので、外部パラメータにはあえて収益性の最低指標を含めました。
変更を加えた後、以前に決定した最低収益性レベルを設定し、訓練データに対してストラテジーテスター最適化モードでさらに100パス実施します。
望ましい結果が得られるか、モデル能力の上限に達するまで(次の訓練サイクルでは収益性は変わらない)、モデルの訓練プロセスを繰り返します。これは、テストEAをシングルパスするときにも見られます。この場合、Actorの方針が確率的であるにもかかわらず、何度かの完璧なパスはほとんど同じ結果になります。これは、モデルが関連する状態における個々の行動の確率を最大化した証拠です。決定論的戦略の効果を得ることができます。この結果は、必ずしも不利になるとは限りません。タスクによっては、安定した決定論的な戦略の方が望ましい場合もあります。
3.検証
例データベースの更新、モデルの訓練、訓練サンプルでのテスト、収益性の最低ラインの引き上げ、例データベースの定期的な補充を15回ほど繰り返した結果、訓練範囲の過去データで一貫して利益を生み出すモデルを手に入れることができました。
次の段階は、新しいデータに対して、訓練セットの外で訓練済みモデルの能力をテストすることです。2023年6月の過去データで訓練済みモデルのパフォーマンスをテストしました。ご覧の通り、これは訓練期間の翌月です。
テスト期間中、このモデルは4回だけ買い取引をおこないました。そのうち1つだけが利益を上げています。これはおそらく、私たちが期待した結果ではないでしょう。ただ、バランスのグラフをご覧ください。3回の負け取引で、10,000米ドルの開始残高で合計300米ドルの損失。同時に、1回の取引で2000米ドル以上の利益が出ています。その結果、今月は17.5%の利益となりました。プロフィットファクターは6.77、リカバリーファクターは1.32、バランスドローダウンは1.65%です。


取引回数が少なく、一方向的であることが混乱を招いています。しかし、取引件数とその種類、または、最終的な収支の変化で、より重要なのはどちらでしょうか。
結論
本稿では、Soft Actor-Criticアルゴリズムの構築を再開しました。この補強は、Actorの収益戦略を訓練するのに役立ちました。出来上がったモデルがどの程度最適なのかを述べるのは困難です。すべてが相対的です。
この記事で提案されたアプローチは、モデルの収益性を高めることを可能にしましたが、それだけがすべてではありません。例えば、前回の記事のフォーラムスレッドでは、ユーザーのJimReaperさんがそのモデルアーキテクチャを提案しています。これも完全に有効な選択肢です。個人的には、まだテストしていませんが、提案された、あるいは他のアーキテクチャを使って利益を上げる可能性は十分に認めます。モデルによる分析のために新たなデータを追加することは、モデルの効率向上に役立つ可能性が高くなります。探求と新しい研究は、常に奨励されています。強化学習(機械学習の他の分野と同様)においてモデルを開発し最適化する際、異なるアーキテクチャ、ハイパーパラメータ、新しいデータを探索し実験することは、モデルの最適化と改善につながる重要な要素です。
リンク
- Soft Actor-Critic:Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- ニューラルネットワークが簡単に(第49回):Soft Actor-Critic
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練 EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12998
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
理論的には可能だが、すべてはリソース次第だ。例えば、我々は1000点のTPサイズについて話している。連続的なアクションスペースの概念では、これは1000のバリエーションです。10点刻みでも100種類です。SLを同じ数、あるいはその半分(50バリエーション)とします。取引量の少なくとも5つのバリエーションを加えると、100 * 50 * 5 = 25000のバリエーションになります。2(買い/売り)で乗算 - 1ろうそくのための50 000のバリアント。軌道の長さを掛けると、あなたは完全にすべての可能なスペースをカバーするために軌道の数を得る。
ステップバイステップ学習では、現在のアクターのアクションのすぐ近くの軌道をサンプリングします。こうして学習範囲を絞り込む。そして、すべての可能な変種を研究するのではなく、現在の戦略を改善するための変種を探しながら、小さな領域だけを研究する。現在の戦略を少し「チューニング」した後、これらの改善によって導かれた領域で新たなデータを収集し、さらなる動きのベクトルを決定する。
これは、未知の迷路で出口を見つけることを連想させるかもしれない。あるいは、観光客が道を歩きながら通行人に道を尋ねるような道だ。
なるほど。ありがとうございます。
今気づいたのですが、Research.mqhの コレクションを行うと、結果は何となくグループで形成され、グループ内の最終的なバランスは非常に近いですね。そして、Research.mqhでは何らかの進歩があるように思えます(ポジティブな結果のグループがより頻繁に現れるようになったとか)。しかし、Test.mqhではまったく進歩がないようだ。ランダム性があり、一般的にマイナスで終了することが多い。上昇してから下降することもあれば、そのまま下降して失速することもある。また、最後にエントリーする量を増やしているようだ。マイナスではなく、ゼロ近辺でトレードすることもある。また、彼は取引回数を変えていることにも気づきました。5ヶ月間は150回、ある人は500回(およそ)取引しています。これはすべて正常なことなのでしょうか?
なるほど。ありがとう。
Research.mqhの コレクションをやっていて気づいたのですが、最終的なバランスが非常に近いグループで結果が形成されています。そして、Research.mqhでは何らかの進歩があるように思えます(ポジティブな結果のグループがより頻繁に現れるようになったとか)。しかし、Test.mqhではまったく進歩がないようだ。ランダム性があり、一般的にマイナスで終了することが多い。上昇してから下降することもあれば、そのまま下降して失速することもある。また、最後にエントリーする量を増やしているようだ。マイナスではなく、ゼロ近辺でトレードすることもある。また、彼は取引回数を変えていることにも気づきました。5ヶ月間は150回、ある人は500回(およそ)取引しています。これはすべて正常なことなのでしょうか?
ランダム性はアクターの確率性の結果です。あなたが学ぶにつれて、それは少なくなります。完全にはなくならないかもしれませんが、結果は近いものになるでしょう。
ディールのないパスによって、例のデータベースが「詰まる」ことはない。Research.mq5にはチェック機能があり、そのようなパスは保存されない。しかし、Test.mq5から そのようなパスが保存されるのは良いことだ。報酬を生成する際に、ディールがないことに対するペナルティがある。そして、モデルがそのような状況から抜け出すのを助けるはずである。
ドミトリー 私は90以上のサイクル(データベースのトレーニング-テスト-コレクション)を行い、私はまだモデルがランダムを与える持っている。Test.mqh 7の10回の実行のうち、2-3回が0になり、1-2回が約4-5サイクルでプラスになりました。記事の中で、15サイクルでプラスの結果が出たとありましたが、これはどういうことですか?システムには多くのランダム性があることは理解していますが、なぜこのような違いがあるのか理解できません。私のモデルが30サイクル後にプラスの結果を出したのならわかりますが、例えば50サイクルだとすると、すでに90サイクルで、あまり進歩が見られないのでは......。
本当に自分でトレーニングしたコードをそのまま掲載しているのですか?もしかしたら、テストのために何かを修正したのをうっかり忘れて、間違ったバージョンを投稿してしまったとか......?
また、例えばトレーニング係数を1ランク上げれば、学習が早くなるのでは?
何か理解できないのですが......。