
Redes neurais de maneira fácil (Parte 50): Soft Actor-Critic (otimização do modelo)

Introdução
Continuamos a explorar o algoritmo Soft Actor-Critic. No artigo anterior, implementamos este algoritmo, mas, infelizmente, não conseguimos treinar um modelo lucrativo. Hoje, vamos discutir soluções para esse problema. Questões semelhantes já foram abordadas no artigo "Procrastinação do modelo, causas e métodos de resolução". Vou sugerir expandir nosso conhecimento nesta área e analisar novas abordagens usando nosso modelo Soft Actor-Critic como exemplo.
1. Otimização do modelo
Antes de prosseguir diretamente para a otimização do modelo que construímos, gostaria de lembrar que o Soft Actor-Critic é um algoritmo de aprendizado por reforço para modelos estocásticos em espaços de ação contínua. A principal característica deste método é a introdução de um componente de entropia na função de recompensa.
O uso de uma política estocástica do Ator permite que o modelo seja mais flexível e capaz de lidar com tarefas em ambientes complexos, onde algumas ações podem ser indefinidas ou impossíveis de serem governadas por regras claras. Essa política muitas vezes é mais robusta ao lidar com dados que contêm muito ruído, uma vez que leva em consideração o aspecto probabilístico em vez de estar vinculada a regras rígidas.
A adição do componente de entropia incentiva a exploração do ambiente, aumentando as recompensas para ações de baixa probabilidade. O equilíbrio entre exploração e reconhecimento é controlado pelo coeficiente de temperatura.
Em termos matemáticos, o método Soft Actor-Critic pode ser representado pela seguinte fórmula.

1.1 Adição de estocasticidade à política do ator
Na nossa implementação, optamos por não usar a política estocástica do Ator devido à complexidade de sua implementação com o OpenCL. Seguindo o exemplo do TD3, substituímos essa política por um deslocamento aleatório da ação escolhida em sua vizinhança. Essa abordagem é mais simples de implementar e permite que o modelo explore o ambiente. No entanto, também possui desvantagens.
A primeira coisa a notar é a falta de conexão entre a ação amostrada e a distribuição aprendida pelo modelo. Em alguns casos, quando a distribuição aprendida é mais ampla do que a área de amostragem, isso restringe a área de exploração. Isso significa que a política do modelo provavelmente não será ótima e dependerá do ponto de partida de treinamento escolhido aleatoriamente. Afinal, quando inicializamos um novo modelo, preenchemos seus pesos com valores aleatórios.
Em outros casos, a ação amostrada pode estar fora dos limites da distribuição aprendida. Isso amplia a área de exploração, mas entra em conflito com o componente de entropia da função de recompensa. A ação fora da distribuição aprendida, do ponto de vista do modelo, tem probabilidade zero. E receberá a recompensa máxima, independentemente de sua utilidade, graças ao componente de entropia.
Durante o processo de treinamento, o modelo busca encontrar uma estratégia lucrativa e aumenta a probabilidade de ações com recompensas máximas. Ao mesmo tempo, a probabilidade de ações menos lucrativas e deficitárias diminui. A amostragem simples que usamos anteriormente não leva esse fator em consideração. E com a mesma probabilidade, nos dará qualquer ação dentro da área de amostragem. A baixa probabilidade de ações deficitárias gera um alto componente de entropia. Isso distorce o valor real das ações, anula a experiência acumulada anteriormente e leva à construção de uma política do Ator incorreta.
A solução aqui é única: construir um modelo estocástico do Ator e amostrar ações a partir da distribuição aprendida.
Já falamos sobre a falta de um gerador de números pseudoaleatórios do lado do contexto OpenCL, então usaremos um gerador do lado do programa principal.
Ao mesmo tempo, lembramos que só temos a distribuição aprendida do lado do OpenCL. Ela está contida nos objetos internos do nosso modelo. Assim, para preparar o processo de amostragem, teremos que realizar a transferência de dados entre o programa principal e o contexto OpenCL. E isso não depende de onde o processo será organizado.
Ao organizar o processo do lado do programa principal, precisamos carregar a distribuição. E isso envolve 2 buffers: probabilidades e valores correspondentes da função.
Ao organizar o processo do lado do contexto OpenCL, teremos que transmitir o buffer de valores aleatórios. Que posteriormente será usado para selecionar a ação individual.
Aqui, deve-se considerar mais um ponto: o consumidor dos valores obtidos. Durante a operação, usaremos os valores amostrados para realizar ações, nomeadamente, do lado do programa principal. Mas durante o treinamento, transmitiremos esses valores ao Crítico do lado do contexto OpenCL. Como se sabe, as maiores demandas para redução do tempo de operação ocorrem durante o treinamento do modelo. E, nesse contexto, faz todo sentido transmitir apenas um buffer de valores aleatórios para o contexto OpenCL e organizar o processo de amostragem lá.
A decisão está tomada, vamos começar a implementação. Primeiro, modificaremos o kernel SAC_AlphaLogProbs do programa OpenCL. Devo dizer que nossas alterações até simplificarão o algoritmo deste kernel em certa medida.
Nos parâmetros externos do kernel, adicionamos um buffer de valores aleatórios. Para preparar o processo de amostragem neste buffer, esperamos receber um conjunto de valores aleatórios no intervalo de [0, 1].
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, __global float *random, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float prob = 0; float value = 0; float sum = 0; float rnd = random[i];
Para a seleção da ação, fazemo um laço que percorre as probabilidades de todos os quantis da ação analisada, calculando sua soma acumulativa. No corpo do laço, ao mesmo tempo em que calculamos a soma acumulativa, verificamos seu valor atual em relação ao valor aleatório obtido. Assim que ultrapassar esse valor, usamos o quantil atual como a ação escolhida e interrompemos a execução das iterações do laço.
for(int r = 0; r < count_quants; r++) { prob = probs[shift + r]; sum += prob; if(sum >= rnd || r == (count_quants - 1)) { value = quantiles[shift + r]; break; } }
Agora não precisamos mais procurar o par de quantis mais próximos, como fazíamos anteriormente. Temos um quantil selecionado com probabilidade conhecida. Apenas ativamos o valor obtido e calculamos o valor do componente de entropia.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; else outputs[i] = value; break; default: outputs[i] = value; break; } log_probs[i] = -alphas[i] * log(prob); }
Após as alterações no kernel, complementamos o código do programa principal. Começaremos fazendo alterações na classe CNeuronSoftActorCritic. Aqui, adicionamos um buffer para valores aleatórios. Sua inicialização ocorre no método Init, da mesma forma que o buffer cLogProbs, e não precisamos nos deter nisso. Não há necessidade de salvá-lo, pois é preenchido novamente a cada propagação. Por isso, não faremos ajustes nos métodos de trabalho com arquivos.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: .......... .......... CBufferFloat cRandomize; .......... .......... };
Vamos nos referir ao método de feedForward de propagação CNeuronSoftActorCritic::feedForward. Aqui, após a propagação da classe pai e da camada interna cAlphas, fazemos um laço pelo número de ações e preenchemos o buffer cRandomize com valores aleatórios.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false; //--- int actions = cRandomize.Total(); for(int i = 0; i < actions; i++) { float probability = (float)MathRand() / 32767.0f; cRandomize.Update(i, probability); } if(!cRandomize.BufferWrite()) return false;
Os dados do buffer preenchido são transferidos para a memória do contexto OpenCL.
Em seguida, preparamos o processo de enfileiramento do kernel para execução. Aqui, precisamos realizar a transferência dos parâmetros adicionados ao kernel.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_random, cRandomize.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Dessa forma, geramos a aleatoriedade na escolha da ação durante a propagação do nosso Ator. No entanto, há um detalhe no processo de retropropagação. O ponto é que a retropropagação deve distribuir o gradiente de erro para cada elemento de tomada de decisão de acordo com sua contribuição. Anteriormente, usávamos a propagação da classe pai e distribuíamos o gradiente de erro da mesma forma. Agora, fizemos ajustes na etapa final da seleção da ação. Em consequência, isso também deve afetar a distribuição do gradiente de erro.
A geração de valores aleatórios está além do escopo do nosso modelo, e não aplicaremos gradientes a eles. No entanto, devemos fazer a distribuição do gradiente de erro apenas para a ação selecionada. Afinal, nenhum dos outros valores afetou a ação executada pelo Ator. Portanto, seus gradientes de erro são iguais a "0".
Ao contrário da propagação, não podemos complementar a funcionalidade com um novo método, pois chamar o método da classe pai sobrescreverá os gradientes que armazenamos. Assim, teremos que redefinir completamente o método de distribuição de gradientes através dos elementos de nossa camada neural.
Como sempre, começamos criando o kernel SAC_OutputGradient. A estrutura dos parâmetros deste kernel lembrará o kernel FQF_OutputGradient da classe pai. Usamos isso como base e adicionamos 1 buffer e 2 constantes:
- output — buffer de resultado de propagação
- count_quants — número de quantis para cada ação
- activation — função de ativação a ser usada
__kernel void SAC_OutputGradient(__global float* quantiles, __global float* delta_taus, __global float* output_gr, __global float* quantiles_gr, __global float* taus_gr, __global float* output, const int count_quants, const int activation ) { size_t action = get_global_id(0); int shift = action * count_quants;
Vamos executar o kernel em um espaço unidimensional de acordo com o número de ações.
No corpo do kernel, identificamos imediatamente a ação analisada do Ator e determinamos o deslocamento nos buffers de dados.
Em seguida, realizamos um laço no qual compararemos a média de cada quantil e a ação executada no buffer de resultados de nossa camada. No entanto, aqui é importante observar um detalhe: as médias dos quantis são armazenadas no valor original, enquanto a ação selecionada no buffer de resultados contém o valor após a função de ativação. Por isso, antes de comparar os valores, precisamos aplicar a função de ativação à média de cada quantil.
for(int i = 0; i < count_quants; i++) { float quant = quantiles[shift + i]; switch(activation) { case 0: quant = tanh(quant); break; case 1: quant = 1 / (1 + exp(-quant)); break; case 2: if(quant < 0) quant = quant * 0.01f; break; } if(output[i] == quant) { float gradient = output_gr[action]; quantiles_gr[shift + i] = gradient * delta_taus[shift + i]; taus_gr[shift + i] = gradient * quant; } else { quantiles_gr[shift + i] = 0; taus_gr[shift + i] = 0; } } }
É importante mencionar que teoricamente poderíamos executar a função inversa uma vez e determinar o valor do buffer de resultados antes da função de ativação. No entanto, devido às imprecisões nos cálculos, é altamente provável que obteríamos um valor próximo, mas diferente do valor original. E teríamos que realizar comparações com uma certa tolerância, o que complicaria o processo de comparação e diminuiria a precisão.
Quando um quantil coincide, distribuímos o gradiente de erro para a média desse quantil e sua probabilidade. Para os outros quantis e suas probabilidades, definimos o gradiente como "0".
Após a conclusão das iterações do laço, encerramos a execução do kernel.
No programa principal, como mencionado anteriormente, teremos que redefinir completamente o método de distribuição de gradientes calcInputGradients. Devo observar que este método foi completamente copiado do método correspondente da classe pai. As alterações se limitaram apenas ao bloco de enfileiramento do kernel descrito anteriormente. Por isso, não vou me deter na descrição deste método agora e sugiro que você o examine por si mesmo no arquivo anexado "..\NeuroNet_DNG\NeuroNet.mqh".
1.2 Ajuste do processo de atualização das modelagens alvo
Você deve ter notado que em meus modelos, eu prefiro usar o método Adam para atualizar os coeficientes de peso. Nesse sentido, surgiu a ideia de experimentar a incorporação desse método no processo de atualização suave das modelagens alvo dos críticos.
Lembrando que o algoritmo Soft Actor-Critic prevê uma atualização suave das modelagens alvo usando um coeficiente constante no intervalo (0, 1}. Quando o coeficiente é igual a "1", ocorre uma simples cópia dos parâmetros. O coeficiente igual a "0" não é aplicado, pois nesse caso, a modelagem alvo não é atualizada.
O uso do método Adam permitirá que o modelo ajuste independentemente os coeficientes para cada parâmetro treinável. Isso acelerará a atualização dos parâmetros que estão se deslocando na mesma direção, resultando em uma rápida convergência das modelagens alvo em relação aos valores iniciais. Ao mesmo tempo, o método adaptativo reduzirá a taxa de cópia para oscilações em diferentes direções, reduzindo o ruído nos valores das modelagens alvo.
No entanto, é importante observar o risco de desequilíbrio nas modelagens no início do treinamento. Grandes diferenças na taxa de cópia de parâmetros individuais podem levar a resultados inesperados e imprevisíveis para essas modelagens.
Avaliando os prós e contras, decidimos testar a eficácia desse abordagem na prática.
O processo de otimização das modelagens é realizado no contexto OpenCL, e os valores atuais de todos os parâmetros treináveis do modelo são armazenados na memória do contexto. É lógico que a transferência de dados entre o modelo em treinamento e as modelagens alvo seja mais vantajosa para nós no lado OpenCL. Nesse cenário, só existem vantagens:
- excluímos o processo de carregamento de dados reais de parâmetros do modelo treinado do contexto para a memória principal e a cópia subsequente de novos parâmetros de modelos-alvo para a memória do contexto;
- podemos transferir vários parâmetros simultaneamente em fluxos de dados paralelos.
Criaremos o kernel SoftUpdateAdam para realizar as operações de transferência de dados. Nos parâmetros do kernel, passaremos ponteiros para 4 buffers de dados e 3 parâmetros fornecidos pelo método.
__kernel void SoftUpdateAdam(__global float *target, __global const float *source, __global float *matrix_m, __global float *matrix_v, const float tau, const float b1, const float b2 ) { const int i = get_global_id(0); float m, v, weight;
Planejamos executar o kernel sequencialmente para cada camada neural em um espaço unidimensional, de acordo com o número de parâmetros atualizáveis da camada atual do modelo. Nesse cenário, o identificador da thread, que determinamos no corpo do kernel, serve simultaneamente como um indicador para o parâmetro analisado e um deslocamento nos buffers de dados.
Aqui, declaramos variáveis locais para armazenar dados intermediários e os preenchemos com os dados brutos dos buffers globais.
m = matrix_m[i]; v = matrix_v[i]; weight=target[i];
O método Adam foi desenvolvido para atualizar os parâmetros do modelo na direção oposta ao gradiente. Neste caso, o gradiente de erro será a diferença entre os parâmetros da modelagem alvo e da modelagem treinável. E, como estamos ajustando os valores dos parâmetros na direção oposta ao gradiente, definimos a diferença como a diferença entre o parâmetro da modelagem treinável e o parâmetro correspondente da modelagem alvo.
float g = source[i] - weight; m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
Em seguida, calculamos as médias exponenciais do gradiente de erro e seu valor quadrático.
Depois, determinamos o deslocamento necessário para o parâmetro e salvamos seu elemento correspondente no buffer de dados global.
float delta = tau * m / (v != 0.0f ? sqrt(v) : 1.0f); if(delta * g > 0) target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT);
No final das operações do kernel, salvamos nos buffers globais os valores médios do gradiente de erro e seu valor quadrático. Eles serão necessários nas iterações subsequentes de atualização dos parâmetros.
matrix_m[i] = m; matrix_v[i] = v; }
Após criar o kernel, precisamos preparar o processo de chamá-lo no programa principal. Temos duas opções:
- criação de um novo método
- adição de um método criado anteriormente
Neste artigo, sugiro considerar a opção de criar um novo método, que criaremos no nível da classe base da camada neural CNeuronBaseOCL::WeightsUpdateAdam. Nos parâmetros do método, passaremos um ponteiro para a camada neural do modelo treinável e o coeficiente de atualização, semelhante ao método anterior de atualização suave da modelagem alvo. Usaremos os hiperparâmetros do método Adam definidos por padrão para atualização de modelos.
bool CNeuronBaseOCL::WeightsUpdateAdam(CNeuronBaseOCL *source, float tau) { if(!OpenCL || !source) return false; if(Type() != source.Type()) return false; if(!Weights || Weights.Total() == 0) return true; if(!source.Weights || Weights.Total() != source.Weights.Total()) return false;
No corpo do método, organizamos um bloco de controles. Aqui, verificamos a validade dos ponteiros para os objetos usados e também verificamos a correspondência entre o tipo da camada neural atual e o ponteiro recebido.
Após passar com sucesso pelo bloco de controles, transmitimos os parâmetros ao kernel e o enfileiramos para execução.
Aqui, vale ressaltar que o método Adam requer a criação de dois buffers de dados adicionais. No entanto, lembremos que criamos buffers semelhantes em cada modelo para atualizar os parâmetros treináveis do modelo. Neste caso, estamos lidando com a modelagem alvo, que, por definição, passa pelo processo de atualização de parâmetros. Sua otimização é realizada transferindo periodicamente dados da modelagem treinável. Em outras palavras, temos um modelo com funcionalidade limitada. Ao mesmo tempo, não criamos tipos de objetos separados para modelagens alvo e usamos os criados anteriormente para modelagens completamente funcionais, com a criação de todos os objetos e buffers necessários. Isso pode parecer ineficiente no uso de recursos de memória. Mas tomamos essa decisão com a intenção de unificar as modelagens. E agora temos buffers de modelagens alvo criados e não utilizados. Vamos usá-los no processo de atualização dos parâmetros.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Weights.Total()}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, source.getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, getFirstMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, getSecondMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Não se esqueça de controlar a correção das operações em cada etapa. E, após a conclusão bem-sucedida de todas as iterações, encerramos o método.
Após a criação do método, é necessário planejar e preparar o processo de chamá-lo. Eu queria encontrar uma abordagem que tornasse a chamada máxima simples com o mínimo de alterações na estrutura geral dos modelos. E parece que encontrei uma solução prometedora. Não criei um ramo separado para chamar o método do lado de fora do programa por meio de uma classe de gerenciamento do modelo e de um array dinâmico de camadas neurais. Em vez disso, acessei o método de atualização suave já criado CNeuronBaseOCL::WeightsUpdate e configurei a verificação do método de atualização de parâmetros do modelo treinável, que o usuário define para cada camada neural ao descrever a arquitetura do modelo. Se o usuário escolher o método Adam para atualizar os parâmetros do modelo, simplesmente redirecionamos o fluxo de operações para executar nosso novo método. Para outros métodos de atualização de parâmetros, usamos a atualização suave clássica.
bool CNeuronBaseOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(optimization == ADAM) return WeightsUpdateAdam(source, tau); //--- ........ ........ }
Esse método, entre outras coisas, garante a presença dos buffers de dados necessários.
1.3 Fazendo alterações na estrutura dos dados iniciais
Além disso, observei a estrutura dos dados iniciais. Como você sabe, a descrição de cada barra de dados históricos consiste em 12 elementos:
- diferença entre os preços de abertura e de fechamento
- diferença entre o preço de abertura e o preço máximo
- diferença entre o preço de abertura e o preço mínimo
- hora da vela
- dia da semana
- mês
- 5 métricas de indicadores
State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign);
Nesse conjunto de dados, minha atenção foi direcionada às marcas de tempo. Concordo que a avaliação do componente de tempo é de grande valor para entender a sazonalidade e o comportamento das moedas em diferentes sessões. Mas o quão importante é a presença deles para cada vela individual? Pessoalmente, acredito que um conjunto de marcas de tempo é suficiente para o conjunto geral que captura o estado atual do mercado. Anteriormente, ao usar um único buffer de dados iniciais, éramos obrigados a repetir esses dados para manter a estrutura de descrição de cada vela. No entanto, agora, com nossos modelos tendo dois fluxos de dados iniciais, podemos transferir as marcas de tempo para um buffer de descrição do estado da conta. E aqui, deixamos apenas os dados históricos do instantâneo da situação de mercado. Dessa forma, reduzimos o volume total de dados analisados sem perder informações. Portanto, diminuímos o número de operações realizadas e, ao mesmo tempo, aumentamos o desempenho de nosso modelo.
Adicionalmente, fizemos alterações na representação das marcas de tempo para o nosso modelo. Lembro que usamos indicadores relativos para descrever o estado da conta. Isso permite torná-los comparáveis e, em certa medida, normalizados. E gostaríamos que as marcas de tempo também fossem normalizadas. É importante, no entanto, manter informações sobre a sazonalidade dos processos. Nessas situações, muitas vezes recorremos ao uso de funções seno e cosseno. Os gráficos dessas funções são contínuos e cíclicos. O comprimento do laço dessas funções é conhecido e igual a 2π.
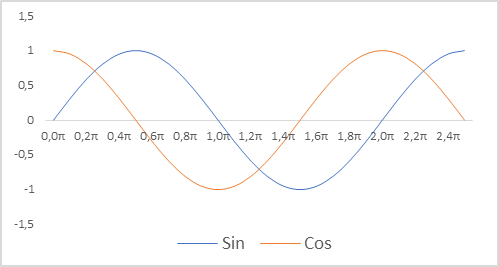
Para normalizar a marca de tempo, levando em consideração a natureza cíclica, precisamos:
- Divisão da hora atual pelo tamanho do período
- Multiplicação do valor obtido pela constante "2π"
- Cálculo do valor de uma função (sin ou cos)
- Adição do valor obtido ao buffer
Na minha implementação, usei períodos de ano, mês, semana e dia.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
E não se esqueça de alterar as constantes de tamanho da descrição de uma única vela e do estado da conta. Seus valores afetarão a arquitetura do nosso modelo e o tamanho dos arrays do buffer de descrição das trajetórias de experiência acumulada.
#define BarDescr 9 //Elements for 1 bar description #define AccountDescr 12 //Account description
Vale ressaltar que a preparação dos dados brutos e a normalização das marcas de tempo, em particular, não estão relacionadas à construção do próprio modelo e à sua arquitetura. Isso é feito do lado de fora do programa. No entanto, a qualidade da preparação dos dados brutos tem um grande impacto no processo de treinamento do modelo e no resultado desse treinamento.
2. Treinamento do modelo
Após fazer mudanças úteis no funcionamento do modelo, passamos ao processo de treinamento. Na primeira etapa, usamos o Expert Advisor (EA) "..\SoftActorCritic\Research.mq5" para interagir com o ambiente e coletar dados para o conjunto de treinamento.
No EA mencionado, implementamos as alterações descritas anteriormente para transferir as marcas de tempo do buffer de descrição do estado do ambiente para o buffer de descrição do estado da conta.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- ......... ......... //--- float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } State.AssignArray(sState.state); //--- ........ ........ //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return;
Além disso, decidimos abandonar as operações de hedge. A negociação é realizada apenas na diferença de volumes na direção do maior deles. Para fazer isso, verificamos os volumes previstos das operações realizadas e os reduzimos para o menor volume.
........ ........ //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Além disso, observei a formação da recompensa. Nesse sentido, é importante mencionar que ao formar a parte principal da recompensa, usamos a mudança relativa no saldo da conta. Seu valor é esparso e muito menor que 1. Ao mesmo tempo, a magnitude do componente de entropia da recompensa no estágio inicial do treinamento oscilava entre 8 e 12. É evidente que o tamanho do componente de entropia é incomparavelmente maior. Para compensar essa discrepância de valores, dividi-o pela soma do saldo, assim como é feito com sua mudança ao formar a parte alvo da recompensa. E introduzi adicionalmente um coeficiente de redução LogProbMultiplier.
........ ........ //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; if(Actor.GetLogProbs(temp)) reward += LogProbMultiplier * temp.Sum() / (float)PrevBalance; if(!Base.Add(sState, reward)) ExpertRemove(); }
Após realizar as alterações mencionadas, iniciei a primeira etapa da coleta de dados de treinamento. Para isso, utilizei os dados históricos do instrumento EURUSD no período de tempo H1. A coleta de dados foi realizada no testador de estratégias ao longo dos primeiros 5 meses de 2023, no modo de otimização completa de parâmetros. O capital inicial foi de 10.000 USD. Nesta fase, compilei uma base de exemplos a partir de 200 passagens, o que resultou em mais de 0,5 milhão de conjuntos de dados "Estado"→"Ação"→"Novo Estado"→"Recompensa" no intervalo de tempo especificado.
Lembro que nesta fase não temos um modelo pré-treinado. A cada passagem, o EA gera um novo modelo e o preenche com parâmetros aleatórios. Durante a passagem pelo histórico, não há processo de treinamento dos modelos. Daí que obtemos 200 passagens completamente aleatórias e independentes, e nenhuma delas mostrou lucro.

O processo de treinamento do modelo em si é realizado no EA "..\SoftActorCritic\Study.mq5". Aqui também fizemos algumas edições pontuais.
Primeiro, fizemos alterações no processo de formação do vetor de descrição do estado da conta, adicionando marcas de tempo, seguindo a abordagem mencionada anteriormente no EA de reconhecimento do ambiente.
Além disso, ajustamos a formação da recompensa alvo em relação à componente de entropia. A abordagem deve ser uniforme em todos os três EAs.
void Train(void) { ......... ......... //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { ......... ......... Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- ......... ......... //--- TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1] + LogProbMultiplier * log_prob.Sum() / (float)PrevBalance);
Em seguida, dividimos os processos de treinamento do Ator e do Crítico. Como antes, alternamos entre Crítico1 e Crítico2 nas iterações pares e ímpares de treinamento. Mas agora, ao treinar o Ator, desativamos a funcionalidade de treinamento do Crítico utilizado. Ele apenas transmite o gradiente de erro para o Ator. Não há atualização dos parâmetros do Crítico nesse processo. Dessa forma, buscamos treinar um Crítico objetivo com base em recompensas reais do ambiente.
........ ........ //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(Result); Actor.GetLogProbs(log_prob); Result.Update(0, reward); Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Critic1.TrainMode(true); break; } Critic1.TrainMode(true);
Além disso, ao treinar o Crítico, excluímos a componente de entropia da recompensa alvo. Queremos um Crítico objetivo, e a função da componente de entropia é estimular o Ator a explorar o ambiente.
Result.Update(0, reward - LogProbMultiplier * log_prob.Sum() / (float)PrevBalance); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Update Target Nets TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Após a atualização dos parâmetros do Crítico, atualizamos o modelo alvo de apenas um dos Críticos. Caso contrário, o código do EA permanece inalterado e você pode revisá-lo no anexo.
Após realizar as alterações, iniciamos o processo de treinamento do modelo com um laço de 100.000 iterações (parâmetros padrão). Nesta etapa, treinamos os modelos do Ator e de 2 Críticos e realizamos seu treinamento inicial.
Não devemos esperar grandes sucessos no primeiro laço de treinamento do modelo, e há várias razões para isso. O número de iterações realizado cobre apenas 1/5 da nossa base de exemplos. Além disso, essa base não pode ser considerada completa, já que não incluiu nenhuma passagem lucrativa que o modelo poderia aprender.
Após a conclusão da primeira etapa do processo de treinamento do modelo, excluí a base de exemplos anteriormente coletada. Minha lógica aqui é bastante simples. Essa base de exemplos contém passagens independentes aleatórias. As recompensas incluem uma componente de entropia desconhecida. Suponho que, em um modelo não treinado, todas as ações são igualmente prováveis. No entanto, de qualquer forma, elas serão incomparáveis com a distribuição de probabilidade do nosso modelo. Por isso, excluímos a base de exemplos anteriormente coletada e formamos uma nova.
Nesse processo, repetimos a coleta de dados de treinamento e executamos novamente a otimização do EA de reconhecimento do ambiente com uma otimização completa de parâmetros. No entanto, desta vez, ajustamos os valores dos Agentes a serem otimizados. Esse é um truque simples necessário para evitar o uso de dados em cache da otimização anterior.
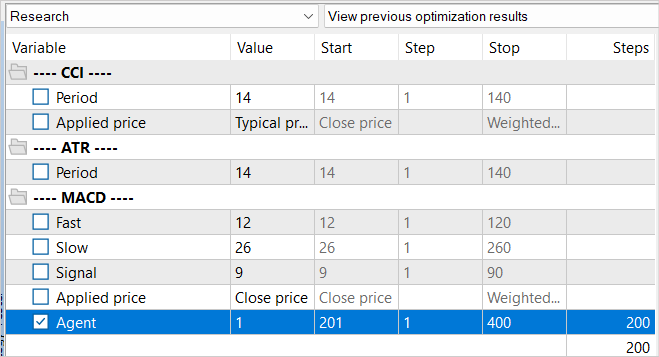
A principal diferença na nova base de exemplos é que, durante a reconhecimento do ambiente, usamos nosso modelo pré-treinado. A variedade de ações do Agente é devida à estocasticidade da política do Ator. Todas as ações realizadas estão dentro do aprendizado da distribuição de probabilidade do nosso modelo. Nesta etapa, coletamos todas as passagens do nosso Agente.
Após coletar a nova base de exemplos, executamos novamente o EA de treinamento do modelo "..\SoftActorCritic\Study.mq5". Desta vez, aumentamos o número de iterações de treinamento para 500.000.
Após a conclusão do segundo laço do processo de treinamento, acessamos o EA de teste do modelo treinado "..\SoftActorCritic\Test.mq5". Fizemos alterações semelhantes às do EA de reconhecimento do ambiente. Você pode analisá-las no anexo.
A transição para o EA de teste não significa o fim do processo de treinamento. Rodamos o EA várias vezes usando os dados históricos do período de treinamento. No meu caso, isso corresponde aos primeiros 5 meses de 2023. Realizei 10 execuções e, com base nos resultados obtidos, determinamos aproximadamente o top 1/4 ou 1/5 da faixa de retornos obtidos. Voltamos ao código do EA de reconhecimento do ambiente e introduzimos um limite mínimo de rentabilidade para as passagens que são armazenadas na base de exemplos.
input double MinProfit = 10;
double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(profit >= MinProfit && profit != 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, profit, Frame); //--- return(ret); }
Dessa forma, buscamos selecionar apenas as melhores passagens e treinar nosso Ator com estratégias ótimas.
Intencionalmente, colocamos o indicador de lucro mínimo como um parâmetro externo, pois, durante o treinamento do modelo, iremos gradualmente aumentá-lo.
Após fazer as alterações, definimos um nível de lucro mínimo previamente estabelecido e realizamos mais 100 passagens no modo de otimização do testador de estratégias com base nos dados de treinamento.
Repetimos as iterações do processo de treinamento do modelo até obtermos os resultados desejados ou alcançarmos o limite superior das capacidades do modelo, quando um laço adicional de treinamento não resultará em mudanças na lucratividade. Isso pode ser observado durante a execução de passagens individuais no EA de teste. Quando, apesar da estocasticidade da política do Ator, várias passagens têm resultados praticamente idênticos. Isso é evidência de que o modelo maximizou a probabilidade de ações individuais nos estados correspondentes. E isso resulta em uma estratégia determinística. Esse resultado nem sempre é uma desvantagem. Afinal, uma estratégia estável e determinística pode ser preferível em algumas situações, especialmente se ações determinísticas levarem a bons resultados.
3. Testes
Após cerca de 15 iterações de atualização da base de exemplos, treinamento do modelo, testes na amostra de treinamento, aumento do limite mínimo de lucratividade e adição subsequente de exemplos à base, consegui obter um modelo que consistentemente gera lucros no período de treinamento com dados históricos.
A próxima etapa é testar as capacidades do modelo treinado fora da amostra de treinamento, em novos dados. Testei o desempenho do modelo treinado nos dados históricos de junho de 2023. Como pode ser observado, esse é o mês seguinte ao período de treinamento.
Devo dizer que durante o período de teste, o modelo realizou apenas 4 negociações de longo prazo, e apenas uma delas foi lucrativa. Talvez esse não seja o resultado que esperávamos. No entanto, observe o gráfico de saldo. Três negociações deficitárias resultaram em uma perda de apenas 300 USD, com um saldo inicial de 10.000 USD. Enquanto isso, uma negociação lucrativa gerou um lucro de mais de 2.000 USD. Como resultado, ao longo do mês, obtivemos um lucro de 17,5%. O fator de lucro foi de 6,77, o fator de recuperação foi de 1,32 e a redução de saldo foi de 1,65%.


Sim, preocupa o número limitado de negociações e sua direção unidirecional. Mas o que é mais importante? A quantidade e a diversidade de negociações ou o resultado final no saldo?
Considerações finais
Neste artigo, continuamos a trabalhar na construção do algoritmo Soft Actor-Critic. As adições feitas ajudaram a treinar uma estratégia lucrativa para o Ator. Não posso dizer o quão ótimo é o modelo resultante. Tudo é conhecido pela comparação.
As abordagens propostas no artigo aumentaram a rentabilidade do nosso modelo, mas não são as únicas nem as definitivas. Por exemplo, no fórum relacionado a um artigo anterior, um usuário com o pseudônimo JimReaper propôs sua própria arquitetura de modelo. Isso é totalmente viável. Pessoalmente, eu ainda não o testei, mas vejo a possibilidade de obter lucro com o uso dessa ou de outra arquitetura. Com uma alta probabilidade, a adição de novos dados para análise pelo modelo ajudará a melhorar sua eficácia. Sempre encorajo a busca e a pesquisa. No desenvolvimento e otimização de modelos na área de aprendizado por reforço (assim como em outras áreas de aprendizado de máquina), a pesquisa e a experimentação com diferentes arquiteturas, hiperparâmetros e novos dados são elementos-chave que podem levar à otimização e melhoria do modelo.
Referências
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Redes neurais de maneira fácil (Parte 49): Soft Actor-Critic (SAC)
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA de treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para criar uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12998
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Desenvolvendo um agente de Aprendizado por Reforço em MQL5.com Integração RestAPI(Parte 2): Funções MQL5 para Interação HTTP com API REST do Jogo da Velha
Desenvolvendo um agente de Aprendizado por Reforço em MQL5.com Integração RestAPI(Parte 2): Funções MQL5 para Interação HTTP com API REST do Jogo da Velha
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Teoricamente, isso é possível, mas tudo depende dos recursos. Por exemplo, estamos falando de um tamanho de TP de 1.000 pontos. No conceito de um espaço de ação contínuo, isso representa 1.000 variantes. Mesmo se considerarmos incrementos de 10, são 100 variantes. Deixe o mesmo número de SLs ou até a metade deles (50 variantes). Adicione pelo menos 5 variantes do volume de negociação e teremos 100 * 50 * 5 = 25.000 variantes. Multiplique por 2 (compra / venda) - 50.000 variantes para um candle. Multiplique pelo comprimento da trajetória e você terá o número de trajetórias para cobrir totalmente todo o espaço possível.
No aprendizado passo a passo, coletamos amostras de trajetórias na vizinhança imediata das ações do ator atual. Assim, restringimos a área de estudo. E não estudamos todas as variantes possíveis, mas apenas uma pequena área com busca de variantes para aprimorar a estratégia atual. Após um pequeno "ajuste" da estratégia atual, coletamos novos dados na área para onde esses aprimoramentos nos levaram e determinamos o vetor de movimento adicional.
Isso pode ser uma reminiscência de como encontrar uma saída em um labirinto desconhecido. Ou o caminho de um turista que caminha pela rua e pede orientações aos transeuntes.
Estou vendo. Obrigado.
Notei agora que, quando você faz a coleta Research.mqh, os resultados são formados de alguma forma em grupos com um equilíbrio final muito próximo no grupo. E parece que há algum progresso no Research.mqh (grupos de resultados positivos começaram a aparecer com mais frequência ou algo assim). Mas com o Test.mqh parece não haver progresso algum. Ele apresenta alguma aleatoriedade e, em geral, termina com mais frequência uma aprovação com um sinal de menos. Às vezes ele sobe e depois desce, e às vezes desce direto e depois para. Ele também parece aumentar o volume de entrada no final. Às vezes, ele não negocia no negativo, mas em torno de zero. Também notei que ele muda o número de negociações - por 5 meses, ele abre 150 negociações, e alguém abre 500 (aproximadamente). Isso tudo é normal, o que estou observando?
Estou vendo. Obrigado.
Percebi que, quando faço a coleta do Research.mqh, os resultados são, de alguma forma, formados em grupos com um equilíbrio final muito próximo no grupo. E parece que há algum progresso no Research.mqh (grupos de resultados positivos começaram a aparecer com mais frequência ou algo assim). Mas com o Test.mqh parece não haver progresso algum. Ele apresenta alguma aleatoriedade e, em geral, termina com mais frequência uma aprovação com um sinal de menos. Às vezes ele sobe e depois desce, e às vezes desce direto e depois para. Ele também parece aumentar o volume de entrada no final. Às vezes, ele não negocia no negativo, mas em torno de zero. Também notei que ele muda o número de negociações - por 5 meses, ele abre 150 negociações, e alguém abre 500 (aproximadamente). Isso tudo é normal, o que estou observando?
A aleatoriedade é resultado da estocasticidade do Actor. À medida que você aprender, ela diminuirá. Talvez não desapareça completamente, mas os resultados serão próximos.
O banco de dados de exemplos não será "entupido" por passagens sem acordos. O Research.mq5 tem uma verificação e não salva essas passagens. Mas é bom que esse tipo de passe seja salvo no Test.mq5. Há uma penalidade para a ausência de negócios ao gerar a recompensa. E isso deve ajudar o modelo a sair de tal situação.
Dmitriy, eu fiz mais de 90 ciclos (treinamento-teste-coleta de banco de dados) e ainda tenho o modelo dá aleatório. Posso dizer que, de 10 execuções do Test.mqh, 7 drenam de 2 a 3 para 0 e de 1 a 2 vezes, por cerca de 4 a 5 ciclos, há uma execução positiva. Você indicou no artigo que obteve um resultado positivo em 15 ciclos. Entendo que há muita aleatoriedade no sistema, mas não entendo por que essa diferença? Bem, entendo que se meu modelo desse um resultado positivo após 30 ciclos, digamos 50, bem, já são 90 e você não consegue ver muito progresso.....
Tem certeza de que publicou o mesmo código que você mesmo treinou? Talvez você tenha corrigido algo para os testes e acidentalmente tenha se esquecido e publicado a versão errada.....?
E se, por exemplo, o coeficiente de treinamento for aumentado em um grau, ele não aprenderá mais rápido?
Não estou entendendo algo......