
Redes neuronales: así de sencillo (Parte 50): Soft Actor-Critic (optimización de modelos)

Introducción
Continuamos nuestro estudio del algoritmo SAC. En el artículo anterior implementamos dicho algoritmo, pero lamentablemente no pudimos entrenar un modelo rentable. Hoy hablaremos de las opciones disponibles para resolver este problema. Ya planteamos una cuestión similar en el artículo "Procrastinación del modelo, causas y métodos de solución". En esta ocasión, les propongo ampliar nuestros conocimientos en dicho ámbito y analizar nuevos enfoques usando nuestro modelo SAC como ejemplo.
1. Optimización del modelo
Antes de pasar directamente a la optimización del modelo que hemos construido, permítanme recordarles que el SAC es un algoritmo de aprendizaje por refuerzo para modelos estocásticos en un espacio continuo de acciones. La principal característica de este método es la introducción de un componente de entropía en la función de recompensa.
El uso de la política estocástica del Actor dota al modelo de mayor flexibilidad y lo hace capaz de resolver problemas en entornos complejos en los que algunas acciones pueden ser inciertas o resulta imposible definir reglas claras. Esta política suele ser más sólida al trabajar con datos que contienen mucho ruido, porque considera el componente probabilístico en lugar de verse atado a reglas claras.
Añadir un componente de entropía fomenta la exploración del entorno, aumentando la recompensa de las acciones de baja probabilidad. El equilibrio entre exploración y explotación se rige por el coeficiente de temperatura.
De forma matemática, el método SAC puede representarse usando la siguiente fórmula.

1.1 Añadiendo estocasticidad a la política del Actor
En nuestra implementación hemos renunciado a utilizar la política estocástica del Actor debido a la complejidad de su implementación usando OpenCL. De forma similar al TD3, la sustituiremos desplazando aleatoriamente la acción seleccionada en algunas de sus proximidades. Este enfoque es más fácil de aplicar y permite al modelo explorar el entorno, aunque también tiene sus inconvenientes.
Lo primero que llama la atención es la falta de conexión entre la acción muestreada y la distribución aprendida por el modelo. En ciertos casos, cuando la distribución aprendida resulta más amplia que la zona de muestreo, el área de estudio se comprime. Por ello, es muy probable que la política del modelo no resulte óptima, sino que dependa de un punto de entrenamiento inicial elegido al azar. Al fin y al cabo, al inicializar un nuevo modelo, lo llenaremos con pesos aleatorios.
En otros casos, la acción muestreada puede ir más allá de la distribución aprendida, lo cual ampliará la zona de exploración, pero entrará en conflicto con el componente de entropía de la función de recompensa. Una acción fuera de la distribución aprendida tendrá una probabilidad cero desde el punto de vista del modelo, y obtendrá la máxima recompensa independientemente de su valor, debido al componente entrópico.
Durante el proceso de aprendizaje, el modelo tiende a encontrar una estrategia rentable y aumenta la probabilidad de las acciones con máxima recompensa. Al mismo tiempo, se reducirá la probabilidad de acciones menos rentables y no rentables. El muestreo simple que hemos utilizado antes no tiene en cuenta este factor, y resulta igualmente probable que nos ofrezca cualquier acción de la zona de muestreo. La baja probabilidad de acciones no rentables generará un alto componente de entropía, lo cual distorsionará el verdadero valor de las acciones, nivelando la experiencia previa y provocando la construcción de políticas del Actor incorrectas.
La única solución en este caso consistirá en construir un modelo estocástico del Actor y muestrear las acciones a partir de la distribución aprendida.
Ya hemos mencionado que no existe un generador de números pseudoaleatorios en el lado del contexto OpenCL, así que usaremos el generador en el lado del programa principal.
Al mismo tiempo, somos conscientes de la presencia de una distribución aprendida solo en el lado OpenCL; esta se halla en los objetos internos de nuestro modelo. En consecuencia, para organizar el proceso de muestreo, deberemos organizar la transferencia de datos entre el programa principal y el contexto OpenCL, cosa que no depende de dónde se organice el proceso.
Al organizar el proceso en el lado del programa principal, deberemos cargar la distribución. Esta consta de 2 búferes: uno de probabilidades y otro con los valores de función correspondientes.
Al organizar el proceso en el lado del contexto OpenCL, tendremos que trasmitir un búfer de valores aleatorios, que más tarde se usará para seleccionar una acción individual.
Otro punto a tener en cuenta aquí es quién consumirá los valores obtenidos. Durante la explotación, utilizaremos los valores muestreados para realizar acciones, es decir, en el lado del programa principal. En el proceso de aprendizaje, en cambio, los transmitiremos al Crítico en el lado OpenCL del contexto. Como bien sabemos, precisamente durante el proceso de entrenamiento del modelo se plantean las mayores exigencias para reducir el tiempo de realización de las operaciones. En este sentido, la solución de transmitir solo un búfer de valores aleatorios al contexto OpenCL y organizar allí el proceso de muestreo parece bastante lógica.
La decisión está tomada: procedamos ahora a la aplicación. En primer lugar, modificaremos el kernel del programa SAC_AlphaLogProbs OpenCL. Debemos decir que nuestros cambios incluso simplificarán en cierta medida el algoritmo de dicho kernel.
En los parámetros externos del kernel, añadiremos un búfer de valores aleatorios. Para organizar el proceso de muestreo en este búfer, esperaremos un conjunto de valores aleatorios en el rango [0, 1].
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, __global float *random, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float prob = 0; float value = 0; float sum = 0; float rnd = random[i];
Para seleccionar una acción, organizaremos un ciclo de iteración de las probabilidades de todos los cuantiles de la acción analizada y calcularemos su suma acumulada. En el cuerpo del ciclo, simultáneamente al cálculo de la suma acumulativa, comprobaremos su valor actual con el valor aleatorio obtenido, y en cuanto supere este valor, utilizaremos el cuantil actual como acción seleccionada para interrumpir las iteraciones del ciclo.
for(int r = 0; r < count_quants; r++) { prob = probs[shift + r]; sum += prob; if(sum >= rnd || r == (count_quants - 1)) { value = quantiles[shift + r]; break; } }
Ahora no necesitamos buscar un par de cuantiles más cercanos como hacíamos antes, tenemos un cuantil seleccionado con probabilidad conocida, así que solo deberemos activar el valor obtenido y calcular el valor del componente de entropía.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; else outputs[i] = value; break; default: outputs[i] = value; break; } log_probs[i] = -alphas[i] * log(prob); }
Tras realizar los cambios en el kernel, completaremos el código del programa principal. Comenzaremos realizando cambios en la clase CNeuronSoftActorCritic. Aquí añadiremos un búfer para valores aleatorios. Su inicialización tendrá lugar en el método Init, de forma similar al búfer cLogProbs, por lo que no nos detendremos aquí. No deberemos guardarlo, ya que se vuelve a rellenar con cada pasada directa. Por consiguiente, no ajustaremos los métodos de procesamiento de archivos.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: .......... .......... CBufferFloat cRandomize; .......... .......... };
Recurriremos al método de pasada directa CNeuronSoftActorCritic::feedForward. Aquí, después de la pasada directa de la clase padre y la capa interna cAlphas, organizaremos un ciclo por el número de acciones y rellenaremos el búfer cRandomize con valores aleatorios.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false; //--- int actions = cRandomize.Total(); for(int i = 0; i < actions; i++) { float probability = (float)MathRand() / 32767.0f; cRandomize.Update(i, probability); } if(!cRandomize.BufferWrite()) return false;
Luego transferiremos los datos del búfer rellenado a la memoria contextual OpenCL.
A continuación, tendremos un proceso organizado para poner el kernel en la cola de ejecución. Aquí deberemos implementar la transmisión en los parámetros añadidos al kernel.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_random, cRandomize.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
De este modo hemos organizado la estocasticidad de la selección de las acciones en la pasada directa de nuestro Actor. Pero hay un matiz con la pasada inversa. La cuestión es que la pasada inversa deberá distribuir el gradiente de error a cada elemento de decisión en función de su contribución. Antes, usábamos la pasada directa de la clase padre. Y de forma similar distribuíamos el gradiente de error. Ahora hemos realizado ajustes en la fase final de selección de la acción. En consecuencia, esto también debería reflejarse en la distribución del gradiente de error.
La generación de valores aleatorios está fuera del alcance de nuestro modelo, por lo que no les asignaremos un gradiente. No obstante, deberemos organizar la distribución del gradiente de error solo para la acción seleccionada, pues ninguno de los otros valores ha tenido efecto alguno sobre la acción perfecta del Actor. Por consiguiente, su gradiente de error será "0".
A diferencia de la pasada directa, no podemos añadir un nuevo método a la funcionalidad, porque la llamada al método de la clase padre sobrescribirá los gradientes que hemos guardado. Por lo tanto, deberemos redefinir al completo el método de distribución de los gradientes de error a través de los elementos de nuestra capa neuronal.
Como siempre, empezaremos creando el kernel SAC_OutputGradient. La estructura de los parámetros de este kernel le recordará al kernel FQF_OutputGradient de la clase padre. Lo tomaremos como básica y le añadiremos 1 búfer y 2 constantes:
- output - búfer de resultados de la pasada directa
- count_quants — número de cuantiles para cada acción
- activation - función de activación utilizada.
__kernel void SAC_OutputGradient(__global float* quantiles, __global float* delta_taus, __global float* output_gr, __global float* quantiles_gr, __global float* taus_gr, __global float* output, const int count_quants, const int activation ) { size_t action = get_global_id(0); int shift = action * count_quants;
Luego ejecutaremos el kernel en un espacio unidimensional de tareas de acuerdo con el número de acciones.
En el cuerpo del kernel, identificaremos directamente la acción del Actor que analizada y determinaremos el desplazamiento en los búferes de datos.
A continuación, organizaremos un ciclo en el que compararemos la media de cada cuantil y la acción perfecta del búfer de resultados de nuestra capa. Sin embargo, aquí deberemos prestar atención a un detalle: los valores medios de los cuantiles se almacenarán en el valor original, mientras que la acción seleccionada en el búfer de resultados contendrá el valor después de la función de activación. Por lo tanto, tendremos que aplicar la función de activación a la media de cada cuantil antes de comparar los valores.
for(int i = 0; i < count_quants; i++) { float quant = quantiles[shift + i]; switch(activation) { case 0: quant = tanh(quant); break; case 1: quant = 1 / (1 + exp(-quant)); break; case 2: if(quant < 0) quant = quant * 0.01f; break; } if(output[i] == quant) { float gradient = output_gr[action]; quantiles_gr[shift + i] = gradient * delta_taus[shift + i]; taus_gr[shift + i] = gradient * quant; } else { quantiles_gr[shift + i] = 0; taus_gr[shift + i] = 0; } } }
Debemos decir que, en teoría, podríamos realizar la función inversa una vez y determinar el valor del búfer de resultados antes de la función de activación. Sin embargo, debido a cierto margen de error dentro de la precisión de los cálculos, resulta muy probable que obtengamos un valor cercano pero diferente del valor original. Y nos veremos obligados a realizar comparaciones con una cierta tolerancia. Esto, a su vez, complicará el proceso de comparación y reducirá la precisión.
Cuando un cuantil coincide, asignaremos el gradiente de error a la media del cuantil y a su probabilidad. Para el resto de cuantiles y sus probabilidades, estableceremos un gradiente igual a "0".
Una vez completadas las iteraciones del ciclo, finalizaremos el funcionamiento del kernel.
En el lado del programa principal, como hemos mencionado antes, deberemos redefinir completamente el método de distribución de gradientes de error calcInputGradients. Permítanme decir de inmediato que este método sería completamente copiado del método análogo de la clase padre. Los únicos cambios se producirían en el bloque que coloca en la cola el kernel descrito anteriormente. Por eso no nos detendremos ahora en su descripción: le sugiero que se familiarice con él en el archivo adjunto "..\NeuroNet_DNG\NeuroNet.mqh".
1.2 Ajustando el proceso de actualización de los modelos objetivo
Se habrá dado cuenta de que en nuestros modelos preferimos utilizar el método Adam para actualizar los coeficientes de peso. Y en este sentido, se me ocurrió experimentar con la aplicación de este método durante la actualización suave de los modelos objetivo de los críticos.
Recordemos que el algoritmo SAC posibilita la actualización suave de los modelos objetivo utilizando un coeficiente constante en el rango (0, 1}. Si el coeficiente es igual a "1", los parámetros se copiarán sin más. Un coeficiente igual a "0" no se aplicará, porque en este caso el modelo objetivo no se actualizará.
El uso del método Adam permitirá al modelo ajustar de forma independiente los coeficientes de cada parámetro entrenado de forma individual. Esto ofrecerá una actualización más rápida de los parámetros desplazados en la misma dirección y, por tanto, un desplazamiento más rápido del modelo objetivo desde los valores iniciales hasta la primera aproximación. Al mismo tiempo, el método adaptativo puede reducir la velocidad de copiado de las fluctuaciones multidireccionales, lo cual disminuirá el ruido de los valores del modelo objetivo.
Sin embargo, debemos prestar atención al riesgo de desequilibrar los modelos en la fase inicial de entrenamiento, cuando las diferencias significativas en la velocidad de copiado de los parámetros individuales pueden provocar resultados inesperados e impredecibles en tales modelos.
Tras evaluar todos los pros y los contras, hemos decidido probar la eficacia de este planteamiento en la práctica.
Así, ejecutaremos el proceso de optimización del modelo en el lado del contexto OpenCL, mientras que los valores reales de todos los parámetros entrenados del modelo se almacenarán en la memoria contextual. Por ello, resulta bastante lógico que nos sea más cómodo transferir estos parámetros entre los modelos entrenados y de destino en el lado OpenCL. Este planteamiento solo tiene ventajas:
- excluimos el proceso de carga de los datos reales de los parámetros del modelo entrenado desde el contexto a la memoria principal y el posterior copiado de los nuevos parámetros de los modelos objetivo en la memoria del contexto;
- podemos realizar múltiples traslados de parámetros simultáneamente en flujos de datos paralelos.
Vamos a crear ahora el kernel SoftUpdateAdam para realizar operaciones de traslado de datos. En los parámetros del kernel, trasmitiremos los punteros a los 4 búferes de datos y los 3 parámetros ofrecidos por el método.
__kernel void SoftUpdateAdam(__global float *target, __global const float *source, __global float *matrix_m, __global float *matrix_v, const float tau, const float b1, const float b2 ) { const int i = get_global_id(0); float m, v, weight;
La ejecución del kernel la realizaremos de forma secuencial para cada capa neuronal en el espacio unidimensional de tareas según el número de parámetros actualizados de la capa del modelo actual. En tal variante, el identificador de flujo que definimos en el cuerpo del kernel sirve simultáneamente como puntero al parámetro analizado y como desplazamiento en los búferes de datos.
Aquí declararemos las variables locales para almacenar los datos intermedios y escribiremos en ellas los datos iniciales de los búferes globales.
m = matrix_m[i]; v = matrix_v[i]; weight=target[i];
El método Adam se diseñó para actualizar los parámetros del modelo hacia el antigradiente. En nuestro caso, el gradiente de error supondrá la desviación de los parámetros del modelo objetivo respecto al modelo entrenado. Y como estamos ajustando el valor de los parámetros hacia el antigradiente, definiremos la desviación como la diferencia del parámetro del modelo entrenado respecto al parámetro correspondiente del modelo entrenado.
float g = source[i] - weight; m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
Y determinaremos inmediatamente las medias exponenciales de su gradiente de error cuadrático.
A continuación, determinaremos el desplazamiento del parámetro requerido y almacenaremos su elemento correspondiente del búfer de datos global.
float delta = tau * m / (v != 0.0f ? sqrt(v) : 1.0f); if(delta * g > 0) target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT);
Como finalización de las operaciones del kernel, almacenaremos en los búferes de datos globales los valores medios del gradiente de error y su cuadrado. Los necesitaremos en iteraciones posteriores de la actualización de parámetros.
matrix_m[i] = m; matrix_v[i] = v; }
Tras crear el kernel, deberemos organizar el proceso de llamada de este en el lado del programa principal. Aquí tendremos dos opciones:
- crear un método nuevo
- completar un método creado previamente.
En este artículo, le propongo considerar la creación de un nuevo método que implementaremos a nivel de la clase básica de la capa neuronal CNeuronBaseOCL::WeightsUpdateAdam. En los parámetros del método, transmitiremos un puntero a la capa neuronal del modelo entrenado y un factor de actualización, de forma análoga al método de actualización suave creado anteriormente para el modelo objetivo. Utilizaremos los hiperparámetros del conjunto de métodos Adam para actualizar los modelos por defecto.
bool CNeuronBaseOCL::WeightsUpdateAdam(CNeuronBaseOCL *source, float tau) { if(!OpenCL || !source) return false; if(Type() != source.Type()) return false; if(!Weights || Weights.Total() == 0) return true; if(!source.Weights || Weights.Total() != source.Weights.Total()) return false;
En el cuerpo del método, organizaremos un bloque de controles. Aquí comprobaremos si los punteros a los objetos utilizados están actualizados. También comprobaremos que el tipo de la capa neuronal actual y del puntero recibido se correspondan.
Después de pasar con éxito el bloque de control, transmitiremos los parámetros al kernel y lo pondremos en la cola de ejecución.
Nótese aquí que el método Adam requerirá la creación de dos búferes de datos adicionales; no obstante, recuerde que hemos creado búferes similares en cada modelo para actualizar los parámetros entrenados del modelo. En este caso, se tratará de un modelo objetivo, que por definición tendrá un proceso de actualización de parámetros. Lo optimizaremos transfiriendo periódicamente los datos del modelo entrenado. En otras palabras, tendremos un modelo con una funcionalidad limitada. Al mismo tiempo, no crearemos tipos de objetos distintos para los modelos objetivo, sino que utilizaremos los creados previamente para los modelos totalmente funcionales con todos los objetos y búferes necesarios ya creados. En esto se percibe un uso ineficiente de los recursos de memoria, pero hemos dado este paso conscientemente para unificar los modelos. Ahora tenemos los búferes de los modelos de destino creados, pero no utilizados. Los usaremos durante la actualización de los parámetros.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Weights.Total()}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, source.getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, getFirstMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, getSecondMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
No debemos olvidarnos de controlar la corrección de las operaciones en cada etapa: tras completar con éxito todas las iteraciones, finalizaremos el método.
Después de crear un método, tendremos que pensar y organizar el proceso de llamada del mismo. Quería encontrar un enfoque que simplificara al máximo su llamada con el menor número posible de cambios en la estructura general de los modelos, y creo que he hallado una solución de compromiso. No he creado una rama aparte de llamada del método en el lado del programa externo usando la clase de gestión del modelo y un array dinámico de capas neuronales. En su lugar, pasé al método de actualización suave CNeuronBaseOCL::WeightsUpdate creado anteriormente y establecí una comprobación para el método de actualización de los parámetros del modelo entrenado, que es definido por el usuario para cada capa neuronal al describir la arquitectura del modelo. Y si el usuario ha establecido el método Adam para actualizar los parámetros del modelo, simplemente redirigiremos el flujo de operaciones para ejecutar nuestro nuevo método. Para otros métodos de actualización de parámetros, usaremos la actualización suave clásica.
bool CNeuronBaseOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(optimization == ADAM) return WeightsUpdateAdam(source, tau); //--- ........ ........ }
Este enfoque, entre otras cosas, garantiza que dispongamos de los búferes de datos necesarios.
1.3 Modificando la estructura de los datos de origen
También reparé en la estructura de los datos de origen. Como ya sabemos, la descripción de cada barra de los datos históricos consta de 12 elementos:
- la diferencia entre los precios de apertura y cierre
- la diferencia entre el precio de apertura y el precio máximo
- la diferencia entre el precio de apertura y el precio mínimo
- la hora de la vela
- el día de la semana
- el mes
- 5 valores de los indicadores.
State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign);
En este conjunto de datos, me llamaron la atención las marcas de tiempo. Estoy de acuerdo en que evaluar el componente temporal resulta de gran utilidad para comprender la estacionalidad, el diverso comportamiento de las divisas en las distintas sesiones. Pero, ¿hasta qué punto es importante tenerlas para cada vela? En mi opinión, un conjunto de marcas de tiempo resulta suficiente para conseguir una "instantánea general" del estado actual del mercado. Antes, al utilizar un único búfer de datos de origen, teníamos que repetir los datos para conservar la estructura de la descripción de cada vela. Ahora que nuestros modelos tienen 2 fuentes de datos de entrada cada uno, podemos poner las marcas de tiempo en el búfer de descripción del estado de la cuenta, donde dejaremos solo los datos históricos de la instantánea del mercado. De este modo reduciremos la cantidad total de datos analizados sin pérdida de poder informativo. Como consecuencia, reduciremos el número de operaciones a realizar y, al mismo tiempo, aumentaremos el rendimiento de nuestro modelo.
Además, cambiaremos la representación de las marcas de tiempo para nuestro modelo. Recordemos que estamos usando indicadores relativos para describir el estado de la cuenta. De este modo, podremos compararlos y, en parte, normalizarlos. Así que nos gustaría tener una visión normalizada de las marcas de tiempo. Resulta importante conservar la información sobre la estacionalidad de los procesos. En estos casos, se suele recurrir a las funciones de seno y coseno. Las gráficas de estas funciones son continuas y cíclicas. La longitud del ciclo de la función es conocida e igual a 2π.
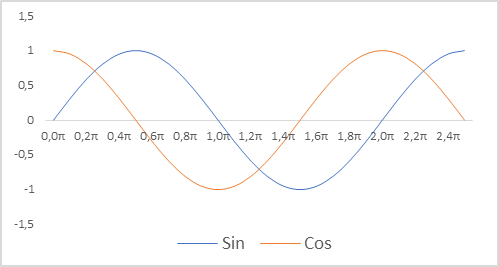
Para normalizar la marca de tiempo y teniendo en cuenta la ciclicidad necesitaremos:
- Dividir el tiempo actual por el tamaño del periodo
- Multiplicar el valor obtenido por la constante "2π"
- Calcular el valor de una función (sin o cos)
- Añadir el valor obtenido al búfer
En nuestra aplicación hemos utilizado periodos de un año, un mes, una semana y un día.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
No se olvide de cambiar las constantes para el tamaño de la descripción de la vela única y el estado de la cuenta. Sus valores afectarán a la arquitectura de nuestro modelo y al tamaño de los arrays del búfer de descripción de las trayectorias de la experiencia.
#define BarDescr 9 //Elements for 1 bar description #define AccountDescr 12 //Account description
Cabe señalar que la preparación de los datos de entrada y la normalización de las marcas de tiempo, en particular, no resultan relevantes para la construcción del modelo en sí y su arquitectura. Se ejecuta en el marco de un programa externo, pero la calidad de la preparación inicial de los datos tiene un gran impacto en el proceso de entrenamiento del modelo y en el resultado de este entrenamiento.
2. Entrenamiento de modelos
Tras introducir cambios constructivos en la organización del modelo, pasaremos a entrenar el mismo. En la primera etapa, utilizaremos el asesor experto "..\SoftActorCritic\Research.mq5" para interactuar con el entorno y recoger datos para la muestra de entrenamiento.
En el asesor anterior, realizamos los cambios descritos anteriormente para desplazar las marcas de tiempo del búfer de descripción del estado del entorno al búfer de descripción del estado de la cuenta.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- ......... ......... //--- float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } State.AssignArray(sState.state); //--- ........ ........ //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return;
Además, tomamos la decisión de abandonar las operaciones de cobertura. Una operación se abrirá solo según la diferencia de volúmenes en el sentido de la mayor de las dos. Para ello, comprobaremos los volúmenes previstos de las transacciones y los reduciremos en el volumen menor.
........ ........ //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Además, prestaba atención a las recompensas generadas. Y aquí debo decir que para formar el grueso de la recompensa hemos utilizado la variación relativa del balance de la cuenta. Su valor es escaso y muy inferior a 1. Al mismo tiempo, la magnitud del componente de entropía de la recompensa en la fase inicial del entrenamiento oscilaba entre 8 y 12. Obviamente, el tamaño del componente entrópico es incomparablemente grande. Para compensar esta diferencia de valor, la hemos dividido por el importe del balance, al igual que hacemos con su cambio para formar la parte objetivo de la recompensa. Además, hemos introducido el factor de reducción LogProbMultiplier.
........ ........ //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; if(Actor.GetLogProbs(temp)) reward += LogProbMultiplier * temp.Sum() / (float)PrevBalance; if(!Base.Add(sState, reward)) ExpertRemove(); }
Tras realizar los cambios anteriores, hemos ejecutado la primera fase de recopilación de los datos de entrenamiento. Para ello, hemos usado los datos históricos del marco temporal H1 de EURUSD. Hemos recopilado los datos en el simulador de estrategias durante el periodo de tiempo correspondiente a los 5 primeros meses de 2023 en el modo de iteración completa de parámetros. Capital inicial 10000USD. En esta fase, hemos recopilado una base de datos de muestra de 200 pasadas, lo cual nos ofrece más de 0,5 millones de conjuntos de datos "Estado"→"Acción"→"Nuevo Estado"→"Recompensa" en el intervalo de tiempo especificado.
Recordemos que en esta fase no dispondremos de un modelo preentrenado. Y con cada pasada, el asesor experto generará un nuevo modelo y lo rellenará con parámetros aleatorios. Durante la pasada por la historia, no hemos realizado el proceso de entrenamiento del modelo. Por lo tanto, obtendremos 200 pasadas completamente aleatorias e independientes. Y ninguna de ellas ha arrojado beneficios.

El proceso de entrenamiento del modelo se organiza en el asesor experto "...\SoftActorCritic\Study.mq5". También hemos realizado algunas modificaciones puntuales.
En primer lugar, hemos modificado el proceso de generación del vector de descripción del estado de la cuenta en cuanto a la adición de marcas de tiempo, de forma similar al enfoque descrito anteriormente en el asesor de exploración del entorno.
Además, hemos ajustado la formación de la recompensa objetivo según el componente de entropía. El enfoque deberá ser el mismo en los 3 asesores.
void Train(void) { ......... ......... //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { ......... ......... Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- ......... ......... //--- TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1] + LogProbMultiplier * log_prob.Sum() / (float)PrevBalance);
A continuación, hemos separado los procesos de aprendizaje del Actor y del Crítico. Al igual que antes, alternaremos entre Crítico1 y Crítico2 en la iteración par e impar del entrenamiento. Pero ahora, al entrenar al Actor, desactivaremos la funcionalidad de entrenamiento del Crítico utilizado. Este solo transmitirá el gradiente de error al Actor. De esta forma, no actualizará los parámetros del Crítico. Así, pretendemos entrenar un Crítico objetivo con recompensas reales del entorno.
........ ........ //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(Result); Actor.GetLogProbs(log_prob); Result.Update(0, reward); Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Critic1.TrainMode(true); break; } Critic1.TrainMode(true);
Además, al entrenar al crítico, excluiremos el componente de entropía de la recompensa objetivo. Al fin y al cabo, necesitamos un Crítico objetivo, y la función del componente entrópico consiste en estimular al Actor para que explore el entorno.
Result.Update(0, reward - LogProbMultiplier * log_prob.Sum() / (float)PrevBalance); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Update Target Nets TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Después de actualizar los parámetros del Crítico, actualizaremos el modelo objetivo de un solo Crítico. Por lo demás, el código del asesor permanecerá inalterado y podrá leerlo en el archivo adjunto.
Tras realizar los cambios, ejecutaremos el proceso de entrenamiento del modelo con un ciclo de 100000 iteraciones (parámetros por defecto). En esta fase estaremos forzando los modelos del Actor y los 2 Críticos. Y también les proporcionaremos el entrenamiento inicial.
No cabe esperar beneficios significativos del primer ciclo de entrenamiento del modelo, y existen varias razones para ello. El número de iteraciones realizadas solo abarca 1/5 de nuestra base de datos de ejemplos. Además, no podemos considerarla completa. No tiene ni una sola pasada con beneficios para que el modelo pueda aprenderla.
Tras completar la primera fase del proceso de entrenamiento del modelo, hemos borrado la base de datos de ejemplos recopilada anteriormente. Mi lógica aquí es bastante simple: esta base de datos de ejemplos recoge pasadas aleatorias independientes. Las recompensas incluyen un componente entrópico desconocido. Supongo que en el modelo no entrenado, todas las acciones resultan igual de probables, pero, en cualquier caso, no serán comparables a la distribución de probabilidad de nuestro modelo. Por lo tanto, eliminaremos la base de datos de ejemplos recopilada anteriormente y formaremos una nueva.
En este caso, repetiremos el proceso de recopilación de la muestra de entrenamiento y volveremos a ejecutar la optimización del asesor con la iteración completa de parámetros, solo que esta vez desplazaremos el valor de los Agentes a iterar. Este sencillo truco será necesario para excluir la carga de datos desde la caché de la optimización anterior.
La principal diferencia de la nueva base de datos de ejemplos es que nuestro modelo preentrenado se ha utilizado en el proceso de exploración del entorno. La diversidad de las acciones del Agente se deberá a la estocasticidad de las políticas del Actor, y todas las acciones realizadas se encontrarán dentro de la distribución de probabilidad aprendida de nuestro modelo. Este paso supondrá la última vez que recopilemos todas las pasadas de nuestro Agente.
Tras recopilar una nueva base de datos de ejemplos, volveremos a ejecutar el modelo de entrenamiento del asesor experto "..\SoftActorCritic\Study.mq5". Esta vez aumentaremos el número de iteraciones de entrenamiento a 500000.
Tras completar el segundo ciclo del proceso de entrenamiento, pasaremos al asesor para probar el modelo entrenado "..\SoftActorCritic\Test.mq5". En él realizaremos correcciones similares a las del asesor de exploración del entorno. Podrá leerlas por sí mismo en el archivo adjunto.
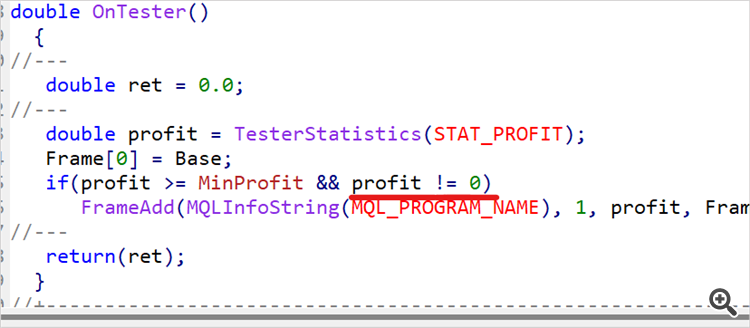
El hecho de pasar al asesor de prueba no implica que el proceso de entrenamiento haya terminado. Así, ejecutaremos el asesor varias veces con los datos históricos del periodo de entrenamiento. En nuestro caso, serán los 5 primeros meses de 2023. Hemos realizado 10 pasadas y a partir de los resultados hemos determinado aproximadamente el 1/4 o 1/5 superior del rango de ingresos obtenidos. Vamos a regresar al código del asesor de exploración del entorno e imponer una restricción al rendimiento mínimo de pasadas almacenadas en la base de datos de ejemplos.
input double MinProfit = 10;
double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(profit >= MinProfit && profit != 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, profit, Frame); //--- return(ret); }
De esta forma, pretendemos seleccionar solo las mejores pasadas y entrenar a nuestro Actor con ellas para conseguir una estrategia óptima.
Hemos establecido deliberadamente la cifra de rendimiento mínimo en los parámetros exteriores, ya que iremos subiendo el listón gradualmente durante el entrenamiento del modelo.
Tras realizar los cambios, fijaremos el nivel de rendimiento mínimo previamente determinado y realizaremos otras 100 pasadas en el modo de optimización del simulador de estrategias con los datos de entrenamiento.
Repetiremos iteraciones del proceso de entrenamiento del modelo hasta obtener los resultados deseados o alcanzar el límite superior de las capacidades del modelo, cuando un ciclo adicional de entrenamiento no producirá ningún cambio en el rendimiento. Esto también puede observarse al realizar pasadas individuales del asesor de prueba, cuando, a pesar de la estocasticidad de la política del Actor, varias pasadas perfectas tendrán resultados casi idénticos. Esto demuestra que el modelo ha maximizado la probabilidad de las acciones individuales en los respectivos estados, por lo que obtendremos el efecto de una estrategia determinista. Este resultado no siempre supone una desventaja. De hecho, una estrategia estable y determinista puede resultar preferible en algunas tareas, especialmente si las acciones deterministas conducen a buenos resultados.
3. Simulación
Tras unas 15 iteraciones de actualización de la base de datos de ejemplos, del entrenamiento del modelo, de las pruebas con la muestra de entrenamiento, de la subida del listón mínimo de rentabilidad y de la siguiente adición de la base de datos de ejemplos, hemos logrado obtener un modelo que genera beneficios de forma estable sobre el rango de entrenamiento de datos históricos.
El siguiente paso consistirá en probar las capacidades del modelo entrenado fuera de la muestra de entrenamiento, es decir, con nuevos datos. Hemos probado el rendimiento del modelo entrenado con datos históricos de junio de 2023. Como podemos ver, se trata del mes siguiente al periodo de entrenamiento.
Debemos decir que durante el periodo de prueba el modelo solo ha realizado 4 operaciones largas, y solo una de ellas ha sido rentable. Probablemente no sea el resultado que esperábamos, pero mire el gráfico de balance. 3 operaciones perdedoras han dado solo 300USD de pérdida con un balance inicial de 10000USD. Al mismo tiempo, una operación rentable ha dado un beneficio de más de 2000USD. Como conclusión, hemos terminado con un rendimiento del 17,5% en el mes. Hemos tenido un factor de beneficio de 6,77, un factor de recuperación de 1,32 y una reducción del balance de 1,65%.


Sí, el reducido número de transacciones y su carácter unidireccional resultan desconcertantes. Pero, ¿qué es más importante el número de transacciones y su variedad o la variación total del balance?
Conclusión
En este artículo, hemos continuado nuestro trabajo sobre la construcción del algoritmo SAC. Las incorporaciones realizadas han contribuido a formar una lucrativa estrategia del Actor. No podemos juzgar si el modelo resultante es óptimo, al fin y al cabo, se trata de comparar.
Los enfoques propuestos en el documento han mejorado la rentabilidad de nuestro modelo, pero no son los únicos ni tampoco exhaustivos. Por ejemplo, en el hilo del foro del artículo anterior, el usuario con el seudónimo JimReaper propuso su modelo de arquitectura. También es una opción totalmente posible. Personalmente, aún no la he probado, pero estoy abierto a la posibilidad de obtener beneficios utilizando la arquitectura propuesta, o bien otra. Es muy probable que la adición de nuevos datos que el modelo pueda analizar contribuya a mejorar su eficacia. Siempre animo a todo el mundo a buscar y realizar nuevas investigaciones. A la hora de desarrollar y optimizar modelos en el aprendizaje por refuerzo (como en otras áreas del aprendizaje automático), la exploración y experimentación con diferentes arquitecturas, hiperparámetros y nuevos datos resultan elementos clave que pueden llevar a la optimización y mejora del modelo.
Enlaces
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Redes neuronales: así de sencillo (Parte 49): Soft Actor-Critic
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12998
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Teóricamente es posible, pero todo depende de los recursos. Por ejemplo, estamos hablando del tamaño TP de 1000 puntos. En el concepto de un espacio de acción continuo, esto son 1000 variantes. Incluso si tomamos en incrementos de 10, eso es 100 variantes. Que el mismo número de SL o incluso la mitad de ellos (50 variantes). Añadir al menos 5 variantes del volumen de comercio y obtenemos 100 * 50 * 5 = 25000 variantes. Multiplique por 2 (compra / venta) - 50 000 variantes para una vela. Multiplique por la longitud de la trayectoria y se obtiene el número de trayectorias para cubrir completamente todo el espacio posible.
En el aprendizaje paso a paso, tomamos muestras de trayectorias en las inmediaciones de las acciones del Actor actual. Así reducimos el área de estudio. Y no estudiamos todas las variantes posibles, sino sólo un área pequeña con búsqueda de variantes para mejorar la estrategia actual. Tras un pequeño "ajuste" de la estrategia actual, recogemos nuevos datos en la zona a la que nos han conducido estas mejoras y determinamos el vector de movimiento posterior.
Esto puede recordar a la búsqueda de una salida en un laberinto desconocido. O el camino de un turista que camina por la calle y pregunta a los transeúntes por una dirección.
Ya veo. Gracias.
Me he dado cuenta ahora de que cuando haces la recopilación Research.mqh, los resultados se forman de alguna manera en grupos con un balance final muy ajustado en el grupo. Y parece como si hubiera algún progreso en Research.mqh (los grupos positivos de resultados empezaron a aparecer más a menudo o algo así). Pero con Test.mqh no parece haber ningún progreso. Da algo de aleatoriedad y en general termina más a menudo una pasada con un menos. A veces sube y luego baja, y a veces baja directamente y luego se para. También parece aumentar el volumen de entrada al final. A veces no comercia en el menos, pero justo alrededor de cero. También me di cuenta de que cambia el número de operaciones - durante 5 meses se abre 150 operaciones, y alguien se abre 500 (aproximadamente). ¿Es todo esto normal, lo que estoy observando?
Ya veo. Gracias, señor.
He notado que cuando hago la colección Research.mqh, los resultados se forman de alguna manera en grupos con un balance final muy cercano en el grupo. Y parece como si hubiera algún progreso en Research.mqh (los grupos positivos de resultados empezaron a aparecer más a menudo o algo así). Pero con Test.mqh no parece haber ningún progreso. Da algo de aleatoriedad y en general termina más a menudo una pasada con un menos. A veces sube y luego baja, y a veces baja directamente y luego se para. También parece aumentar el volumen de entrada al final. A veces no comercia en el menos, pero justo alrededor de cero. También me di cuenta de que cambia el número de operaciones - durante 5 meses se abre 150 operaciones, y alguien se abre 500 (aproximadamente). ¿Es todo esto normal, lo que estoy observando?
La aleatoriedad es el resultado de la estocasticidad del Actor. A medida que aprendas, será menor. Puede que no desaparezca por completo, pero los resultados se aproximarán.
La base de datos de ejemplos no se "atascará" con pases sin tratos. Research.mq5 tiene una comprobación y no guarda tales pases. Pero es bueno que tal pase se guardará de Test.mq5. Hay una penalización por la ausencia de tratos al generar la recompensa. Y debería ayudar al modelo a salir de tal situación.
Dmitriy he hecho más de 90 ciclos (entrenamiento-prueba-colección de base de datos) y todavía tengo el modelo da al azar. Puedo decir que de 10 ejecuciones de Test.mqh 7 drena 2-3 a 0 y 1-2 veces durante unos 4-5 ciclos hay una ejecución en el plus. Usted ha indicado en el artículo que obtuvo un resultado positivo para 15 ciclos. Entiendo que hay mucha aleatoriedad en el sistema, pero no entiendo por qué tal diferencia? Bueno, entiendo que si mi modelo dio un resultado positivo después de 30 ciclos, digamos 50, bueno, ya es 90 y no se puede ver mucho progreso.....
¿Estás seguro de que has publicado el mismo código que tú mismo entrenaste? ¿Quizás corregiste algo para las pruebas y accidentalmente te olvidaste y publicaste la versión equivocada.....?
Y si, por ejemplo, se aumenta un grado el coeficiente de entrenamiento, ¿no aprenderá más rápido?
No entiendo algo......