
取引におけるニューラルネットワーク:シャープネス低減によるTransformerの効率向上(最終回)

はじめに
前回の記事では、SAMformer (Sharpness-Aware Multivariate Transformer)フレームワークの理論的側面について紹介しました。これは、多変量時系列データの長期予測タスクにおいて、従来型Transformersが抱える本質的な制約を克服するために設計された革新的なモデルです。従来型Transformersの主要な問題点としては、学習の複雑さ、小規模データセットにおける汎化性能の低さ、そして不適切な局所的極小値に陥りやすい傾向などが挙げられます。こうした制約が、限られた入力データと高い予測精度が求められる状況において、Transformerベースのモデルの実用性を妨げています。
SAMformerの核心的なアイデアは、浅いアーキテクチャを採用する点にあります。これにより計算の複雑さを軽減し、過学習を防ぐことが可能になります。その中心的要素のひとつがSharpness-Aware Minimization (SAM)最適化機構であり、パラメータのわずかな変動に対するモデルの堅牢性を高めることで、汎化能力と最終的な予測精度を向上させます。
これらの特徴により、SAMformerは合成データセットと実世界の時系列データセットの双方で優れた予測性能を発揮します。モデルは高い精度を達成しつつパラメータ数を大幅に削減しており、効率的でリソース制約のある環境での導入にも適しています。こうした利点は、金融、医療、サプライチェーン管理、エネルギーといった長期予測が重要な領域において、SAMformerの幅広い応用可能性を開くものです。
以下にフレームワークのオリジナルの可視化を示します。
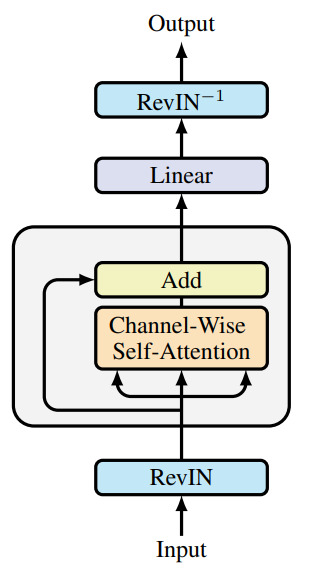
提案されたアプローチの実装はすでに開始しています。前回の記事では、OpenCL側の新しいカーネルを紹介しました。また、全結合層の改善についても議論しました。本日は、この作業をさらに進めていきます。
1. SAM最適化を用いた畳み込み層
私たちは前回の作業を引き続きおこないます。次のステップとして、畳み込み層をSAM最適化機能で拡張します。ご想像の通り、新しいクラスCNeuronConvSAMOCLは、既存の畳み込み層CNeuronConvOCLのサブクラスとして実装されています。新しいオブジェクトの構造を以下に示します。
class CNeuronConvSAMOCL : public CNeuronConvOCL { protected: float fRho; //--- CBufferFloat cWeightsSAM; CBufferFloat cWeightsSAMConv; //--- virtual bool calcEpsilonWeights(CNeuronBaseOCL *NeuronOCL); virtual bool feedForwardSAM(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConvSAMOCL(void) { activation = GELU; } ~CNeuronConvSAMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronConvSAMOCL; } virtual int Activation(void) const { return (fRho == 0 ? (int)None : (int)activation); } virtual int getWeightsSAMIndex(void) { return cWeightsSAM.GetIndex(); } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
提示された構造には、調整済みパラメータを格納するための2つのバッファが含まれていることに注意してください。1つは全結合層と同様に、出力接続用のバッファ(cWeightsSAM)です。もう1つは入力接続用のバッファ(cWeightsSAMConv)です。親クラスは、このようなパラメータバッファの複製を明示的に含んでいないことに注意してください。実際、出力接続の重み用バッファは親の全結合層で定義されています。
ここで、設計上のジレンマに直面しました。それは、SAM機能を持つ全結合層から継承するか、既存の畳み込み層から継承するか、という問題です。最初のケースでは、調整済み出力接続用の新しいバッファを定義する必要はありません(継承されるため)。しかし、この場合、畳み込み層のメソッドを完全に再実装する必要があります。
2つ目のシナリオでは、畳み込み層から継承することで、既存の機能をすべて保持できます。ただし、この方法では調整済み出力重み用のバッファが欠落しており、後続の全結合SAM最適化層の正常な動作に必要です。
私たちは、必要な機能を実装する手間が少ないため、2つ目の継承オプションを選択しました。
これまでと同様に、追加の内部オブジェクトは静的に宣言し、コンストラクタとデストラクタを空のままにしています。それでも、クラスのコンストラクタ内では、デフォルトの活性化関数としてGELUを設定します。継承されたオブジェクトと新規に宣言されたオブジェクトの残りの初期化手順は、すべてInitメソッド内でおこないます。ここでは、同名で異なるパラメータセットを持つ2つのメソッドがオーバーライドされている点に注目してください。まず、最も包括的なパラメータリストを持つバージョンを確認します。
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, optimization_type, batch)) return false;
このメソッドのパラメータには、作成されるオブジェクトのアーキテクチャを一意に決定するための主な定数が渡されます。これらのパラメータのほとんどはすぐに、同名の親クラスのメソッドに渡されます。親クラス側では、継承されたオブジェクトに必要なすべての制御ポイントや初期化アルゴリズムがすでに実装されています。
親クラスのメソッドが正常に実行された後、ぼかし領域係数を内部変数に格納します。これは親メソッドに渡さない唯一のパラメータです。
fRho = fabs(rho); if(fRho == 0) return true;
次に、格納された値をすぐに確認します。ぼかし係数がゼロの場合、SAM最適化アルゴリズムは基本的なパラメータ最適化手法に退化します。その場合、必要なすべてのコンポーネントはすでに親クラスによって初期化されているため、正常終了として結果を返すことができます。
そうでない場合、まず調整済み入力接続用のバッファをゼロ値で初期化します。
cWeightsSAMConv.BufferFree(); if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
次に、必要に応じて、調整された送信パラメータのバッファを同様に初期化します。
cWeightsSAM.BufferFree(); if(!Weights) return true; if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
この最後のバッファは、出力接続用パラメータが存在する場合にのみ初期化されることに注意してください。これは、畳み込み層の後に全結合層が続く場合に発生します。
すべての内部コンポーネントを正常に初期化した後、メソッドは操作の論理結果を呼び出し元のプログラムに返します。
クラス内の2つ目の初期化メソッドは、親クラスのメソッドを完全にオーバーライドし、パラメータは同一です。しかし、ご想像の通り、このメソッドではSAM最適化に重要なぼかし係数のパラメータを省略しています。メソッド本体内では、デフォルトのぼかし係数として0.7を設定します。この係数は、SAMformerフレームワークを紹介した元の論文で言及されている値です。その後、先に説明したクラス初期化メソッドを呼び出します。
bool CNeuronConvSAMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { return CNeuronConvSAMOCL::Init(numOutputs, myIndex, open_cl, window_in, step, window_out, units_count, variables, 0.7f, optimization_type, batch); }
このアプローチにより、ほとんどの先に議論したアーキテクチャ構成において、通常の畳み込み層をSAM最適化版に簡単に置き換えることができます。方法は、オブジェクトの型を変更するだけです。
全結合層と同様に、順伝播および勾配分配の機能はすべて親クラスから継承されます。ただし、OpenCLプログラムのカーネルを呼び出すためのラッパーメソッドとして、calcEpsilonWeightsとfeedForwardSAMの2つを追加しています。最初のメソッドは、調整済みパラメータを計算するカーネルを呼び出します。2番目のメソッドは親クラスの順伝播メソッドを反映していますが、調整済みパラメータバッファを使用します。これらのメソッドの詳細なロジックについてはここでは触れません。カーネルキューイングのアルゴリズムは先に説明したものと同様です。完全な実装は添付のソースコードで確認できます。
このクラスのパラメータ最適化手法は、全結合SAM最適化層の手法と非常によく似ています。ただし、この場合は前の層の種類をチェックしません。全結合層とは異なり、畳み込み層は入力データに適用される独自の内部パラメータ行列を持っています。そのため、自身の調整済みパラメータバッファを使用します。前の層から必要なのは入力データバッファだけで、すべてのオブジェクトがこれを提供します。
それでも、ぼかし係数の値は確認します。ゼロの場合、SAM最適化は実質的にスキップされ、この場合は単に親クラスのメソッドを使用します。
bool CNeuronConvSAMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(fRho <= 0) return CNeuronConvOCL::updateInputWeights(NeuronOCL);
SAM最適化が有効な場合、まず誤差勾配と順伝播結果を組み合わせて、現在のオブジェクトのターゲットテンソルを生成します。
if(!SumAndNormilize(Gradient, Output, Gradient, iWindowOut, false, 0, 0, 0, 1)) return false;
次に、ぼかし係数を用いてモデルパラメータを更新します。これは、適切なカーネルをキューに追加するラッパーメソッドを呼び出すことでおこなわれます。なお、畳み込み層と全結合層の両方が同じ名前のメソッドを使用しますが、それぞれの内部アーキテクチャに対応した異なるカーネルにキューイングされます。
if(!calcEpsilonWeights(NeuronOCL)) return false;
調整済みパラメータを使用する順伝播メソッドにも同じことが当てはまります。
if(!feedForwardSAM(NeuronOCL)) return false;
2回目の順伝播が正常に完了した後、ターゲット値からの偏差を計算します。
float error = 1; if(!calcOutputGradients(Gradient, error)) return false;
次に、親クラスのメソッドを呼び出して、モデルのパラメータを更新します。
//--- return CNeuronConvOCL::updateInputWeights(NeuronOCL); }
最後に、操作の論理結果が呼び出し元プログラムに返され、メソッドが完了します。
学習済みモデルのパラメータ保存についても少し触れておきます。学習済みモデルを保存する際には、全結合SAM層の文脈で説明したのと同じ方法を採用します。調整済みパラメータを含むバッファは保存せず、親クラスによって保存されるデータにぼかし係数のみを追加します。
bool CNeuronConvSAMOCL::Save(const int file_handle) { if(!CNeuronConvOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, fRho) < INT_VALUE) return false; //--- return true; }
事前学習済みモデルを読み込む際には、必要なバッファを準備する必要があります。調整済みの入力パラメータおよび出力パラメータ用のバッファを作成する基準は異なることに注意してください。
まず、親クラスによって保存されたデータを読み込みます。
bool CNeuronConvSAMOCL::Load(const int file_handle) { if(!CNeuronConvOCL::Load(file_handle)) return false;
次に、ファイルにさらにデータが含まれているかどうかを確認し、ぼかし係数を読み取ります。
if(FileIsEnding(file_handle)) return false; fRho = FileReadFloat(file_handle);
調整済みパラメータバッファを初期化するための重要な条件は、ぼかし係数が正の値であることです。そのため、読み込んだパラメータの値を確認します。この条件が満たされない場合、OpenCLコンテキストおよびメインメモリ内の未使用バッファをすべてクリアします。その後、メソッドは正常終了として完了します。
cWeightsSAMConv.BufferFree(); cWeightsSAM.BufferFree(); cWeightsSAMConv.Clear(); cWeightsSAM.Clear(); if(fRho <= 0) return true;
これは、プログラム実行において制御ポイントが必須でない例です。前述の通り、ぼかし係数がゼロの場合、SAMは基本的な最適化手法に簡略化されます。そのため、この場合はオブジェクトは親クラスの機能にフォールバックします。
条件が満たされた場合、調整済み入力パラメータのために、OpenCLコンテキスト内でメモリの初期化と割り当てをおこないます。
if(!cWeightsSAMConv.BufferInit(WeightsConv.Total(), 0) || !cWeightsSAMConv.BufferCreate(OpenCL)) return false;
調整済み出力パラメータ用のバッファを作成するには、追加の条件が必要です。それは、該当する接続が存在することです。したがって、初期化前にポインタの有効性を確認します。
if(!Weights) return true;
繰り返しますが、ポインタが有効でないことは重大なエラーではありません。これは単にモデルのアーキテクチャを反映しているに過ぎません。そのため、現在有効なポインタが存在しない場合は、メソッドを正常終了として終了します。
送信接続バッファが見つかった場合、調整済みパラメータに対して同様のサイズのバッファを初期化して作成します。
if(!cWeightsSAM.BufferInit(Weights.Total(), 0) || !cWeightsSAM.BufferCreate(OpenCL)) return false; //--- return true; }
次に、操作の論理結果を呼び出し元に返して、メソッドの実行を完了します。
これで、CNeuronConvSAMOCLでSAM最適化を実装する畳み込み層メソッドの調査が完了します。このクラスおよびそのすべてのメソッドの完全なコードは、添付ファイルにて確認できます。
2. TransformerへのSAM導入
この段階で、SAMベースのパラメータ最適化を組み込んだ全結合層および畳み込み層のオブジェクトを作成しました。次は、これらの手法をTransformerアーキテクチャに統合する段階です。これは、SAMformerフレームワークの著者が提案した通りの手法です。モデル性能への影響を客観的に評価するため、まったく新しいクラスを作成するのではなく、既存クラスの構造に直接SAMベースの手法を統合しました。基盤となるアーキテクチャとしては、Relative Attentionを持つTransformer(R-MAT)を選択しました。
ご存知のとおり、CNeuronRMATクラスは、CNeuronRelativeSelfAttentionオブジェクトとCResidualConvオブジェクトが交互に並ぶ線形シーケンスを実装しています。前者はフィードバック付きのRelative Attentionを実装し、後者はフィードバックベースの畳み込みブロックを含みます。SAM最適化を統合するには、これらのオブジェクト内のすべての畳み込み層を、SAM対応版に置き換えるだけで十分です。更新後のクラス構造は以下の通りです。
class CNeuronRelativeSelfAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iHeads; uint iUnits; int iScore; //--- CNeuronConvSAMOCL cQuery; CNeuronConvSAMOCL cKey; CNeuronConvSAMOCL cValue; CNeuronTransposeOCL cTranspose; CNeuronBaseOCL cDistance; CLayer cBKey; CLayer cBValue; CLayer cGlobalContentBias; CLayer cGlobalPositionalBias; CLayer cMHAttentionPooling; CLayer cScale; CBufferFloat cTemp; //--- virtual bool AttentionOut(void); virtual bool AttentionGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronRelativeSelfAttention(void) : iScore(-1) {}; ~CNeuronRelativeSelfAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeSelfAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual uint GetWindow(void) const { return iWindow; } virtual uint GetUnits(void) const { return iUnits; } };
class CResidualConv : public CNeuronBaseOCL { protected: int iWindowOut; //--- CNeuronConvSAMOCL cConvs[3]; CNeuronBatchNormOCL cNorm[3]; CNeuronBaseOCL cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CResidualConv(void) {}; ~CResidualConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defResidualConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); };
フィードバック畳み込みモジュールについては、クラス構造内でオブジェクト型を変更するだけで十分であり、クラスメソッド自体を変更する必要はありません。これは、SAM初期化に対応した畳み込み層のオーバーロードされた初期化メソッドを用いているため可能です。CNeuronConvSAMOCLクラスには、ぼかし係数をパラメータとして持つ初期化メソッドと、持たない初期化メソッドの2種類があります。ぼかし係数なしのメソッドは、以前畳み込み層を初期化するために使用されていた親クラスのメソッドをオーバーライドしています。その結果、CResidualConvオブジェクトを初期化する際、プログラムはオーバーライドされた初期化メソッドを呼び出し、デフォルトのぼかし係数を自動で割り当て、SAM最適化付きの畳み込み層を完全に初期化します。
一方、Relative Attentionモジュールの状況はやや複雑です。CNeuronRelativeSelfAttentionモジュールは、追加のネストされた学習可能なバイアスモデルを含むより複雑なアーキテクチャを持っており、その構造はオブジェクト初期化メソッド内で定義されています。そのため、これら内部モデルにSAM最適化を適用するには、Relative Attentionモジュール自身の初期化メソッドを修正する必要があります。
メソッドのパラメータは変更されず、アルゴリズムの初期ステップも保持されます。Query、Key、Valueエンティティを生成するオブジェクト型は、すでにクラス構造内で更新されています。
bool CNeuronRelativeSelfAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- iWindow = window; iWindowKey = window_key; iUnits = units_count; iHeads = heads; //--- int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cQuery.SetActivationFunction(GELU); idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; cKey.SetActivationFunction(GELU); idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false; idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnits, optimization, iBatch)) return false;
さらに、BKeyおよびBValueバイアス生成モデルでは、他のパラメータを維持しながら畳み込みオブジェクトタイプを置き換えます。
idx++; CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
グローバルコンテキストと位置バイアスを生成するモデルでは、SAM最適化を備えた全結合層を使用します。
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseSAMOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
プーリング操作MLPでは、SAM最適化アプローチを使用して畳み込み層を再度使用します。
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cMHAttentionPooling.Add(conv) ) return false; idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(softmax) ) return false; softmax.SetHeads(iUnits);
最初の層については、依然として基礎の全結合層を使用します。これは、Multi-head Attentionブロックの出力を格納するためだけに用いられます。
同様の状況はスケーリングブロックでも見られます。最初の層は引き続き基礎の全結合層であり、Multi-head Attentionブロックの出力にAttention重みを掛けた結果を格納します。その後に、SAM最適化付きの畳み込み層が続きます。
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iUnits, optimization, iBatch) || !cScale.Add(neuron) ) return false; idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 2 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 2 * iWindow, 2 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None); //--- if(!SetGradient(conv.getGradient(), true)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
以上で、Relative Attention機構を持つTransformerへのSAM最適化手法の統合は完了です。更新されたオブジェクトの完全なコードは添付ファイルに記載されています。
3.モデルアーキテクチャ
新しいオブジェクトを作成し、一部の既存オブジェクトを更新しました。次のステップは、モデル全体のアーキテクチャを調整することです。最近の記事とは異なり、本日のアーキテクチャ変更はより大規模なものとなります。まず、CreateEncoderDescriptionsメソッドで実装されている環境エンコーダのアーキテクチャから始めます。これまでと同様に、このメソッドはモデル層のシーケンスを記録する動的配列へのポインタを受け取ります。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であれば動的配列の新しいインスタンスを作成します。
最初の2層は変更しません。これらはソースデータ層とバッチ正規化層です。両層のサイズは同一であり、元のデータテンソルを記録するのに十分である必要があります。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、SAMformerフレームワークの著者らはチャネル単位でのAttentionを用いることを提案しています。そのため、元のデータをAttentionチャネルのシーケンスとして表現できるように、データ転置層を使用します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window= BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、SAM最適化アプローチをすでに追加したRelative Attentionブロックを使用します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRMAT; descr.window=HistoryBars; descr.count=BarDescr; descr.window_out = EmbeddingSize/2; // Key Dimension descr.layers = 1; // Layers descr.step = 2; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
ここで2つの重要な点に注意する必要があります。第一に、チャネルAttentionを使用しているため、解析ウィンドウは解析対象の履歴の深さに等しく、要素数は独立したチャネル数と一致します。第二に、SAMformerフレームワークの著者らが提案しているように、Attention層は1つだけ使用します。ただし、元の実装とは異なり、私たちは2つのAttention Headを採用しました。また、FeedForwardブロックも保持しています。フレームワークの著者らはAttention Headを1つだけ使用し、FeedForwardコンポーネントを削除していました。
次に、出力テンソルの次元を目的のサイズに縮小する必要があります。これは2段階でおこないます。まず、各チャネルの次元を削減するために、SAM最適化を備えた畳み込み層を適用します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; descr.window_out = LatentCount/BarDescr; descr.probability = 0.7f; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、SAM最適化を備えた全接続層を使用して、指定されたサイズの現在の環境状態の一般的な埋め込みを取得します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
どちらの場合も、descr.probabilityを使用してぼかし領域係数を指定します。
メソッドは、操作の論理結果を呼び出し元に返すことで終了します。モデルアーキテクチャ自体は、パラメータとして渡された動的配列ポインタを介して返されます。
環境エンコーダのアーキテクチャを定義した後、次にActor層とCritic層を記述します。両モデルの記述はCreateDescriptionsメソッド内で生成されます。このメソッドは2つの独立したモデル記述を構築するため、そのパラメータには2つの動的配列ポインタが含まれます。
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド内では、渡されたポインタの有効性を確認し、必要に応じて新しい動的配列を作成します。
まずはActorのアーキテクチャから始めます。このモデルの最初の層は、SAM最適化を備えた全結合層として実装されています。そのサイズは、取引口座の状態記述ベクトルに一致します。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.probability=0.7f; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
ここでは、入力データを記録するためにSAM最適化付きの全結合層を使用している点に注目する必要があります。環境Encoderでは、同じ位置に基礎の全結合層が使用されていました。この違いは、その後に続くSAM最適化付き全結合層の存在によるものです。正しく動作するためには、直前の層が調整済みパラメータのバッファを提供する必要があるからです。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
環境エンコーダと同様に、ぼかし領域係数はdescr.probabilityを用いて設定します。すべてのモデルに対して、統一された係数0.7を適用します。
2つ連続したSAM最適化付き全結合層により、現在の取引口座状態の埋め込みが生成されます。これらは対応する環境状態の埋め込みと連結されます。この連結は、専用のデータ結合層によって実行されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
結果は、3つのSAM最適化付き全結合層で構成される意思決定ブロックに渡されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
最終層の出力では、Actorの目標行動ベクトルの2倍のサイズのテンソルを生成します。この設計により、行動に確率的要素を組み込むことが可能になります。これまでと同様に、オートエンコーダの潜在状態層を用いてこれを実現します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
オートエンコーダの潜在層は、入力テンソルを2つの部分に分割することを思い出してください。最初の部分には出力シーケンスの各要素の分布の平均値が含まれ、2つ目の部分には対応する分布の分散が含まれます。意思決定モジュール内でこれらの平均値と分散を学習することで、オートエンコーダの潜在層を通じて生成される乱数の範囲を制約でき、Actor方策に確率的要素を導入することが可能になります。
さらに補足すると、オートエンコーダの潜在層は出力シーケンスの各要素に対して独立した値を生成します。しかし、私たちの場合は、取引を実行するために一貫性のあるパラメータセット(ポジションサイズ、テイクプロフィットレベル、ストップロスレベル)が必要です。これらの取引パラメータ間の整合性を確保するために、SAM最適化付き畳み込み層を使用し、ロング取引とショート取引のパラメータをそれぞれ別々に解析します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!actor.Add(descr)) { delete descr; return false; }
この層の出力領域を制限するために、シグモイド活性化関数を使用します。
そして、Actorモデルの仕上げとして、周波数強調型フィードフォワード予測層(CNeuronFreDFOCL)を配置します。これにより、モデルの出力結果を周波数領域でターゲット値と整合させることが可能になります。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticモデルは、類似したアーキテクチャを持っています。ただし、Actorに渡される口座の状態を記述する代わりに、CriticモデルにはActorが生成した取引操作のパラメータを入力します。また、取引操作の埋め込みを得るために、SAM最適化付き全結合層を2層使用します。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
取引操作の埋め込みは、データ連結層内の環境状態の埋め込みと組み合わされます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = EmbeddingSize; descr.step = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
その後、3つ連続のSAM最適化付き全結合層で構成される意思決定ブロックを使用します。ただし、Actorとは異なり、この場合は結果の確率的性質は使用しません。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability=0.7f; if(!critic.Add(descr)) { delete descr; return false; }
Criticモデルの上には、周波数ゲイン付きの順伝播予測層を追加します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
モデルアーキテクチャ記述の生成が完了した後、メソッドは操作の論理結果を呼び出し元に返して終了します。アーキテクチャの記述自体は、メソッドパラメータとして受け取った動的配列ポインタを通じて返されます。
これでモデル構築の作業は完了です。完全なアーキテクチャは添付資料に示されています。また、環境との相互作用やモデル学習プログラムの完全なソースコードも添付されており、これらは以前の作業から変更なしで引き継がれています。
4.テスト
SAMformerフレームワークの著者らが提案した手法を実装するために、大規模な作業をおこないました。ここで、実際の過去データを用いて実装の有効性を評価します。前回と同様、モデルの学習は2023年のEURUSDデータ全期間を対象に実施しました。実験中はH1時間枠を使用し、すべてのインジケーターのパラメータはデフォルト値のままとしています。
前述の通り、環境との相互作用およびモデル学習を担当するプログラムは変更されていません。これにより、以前作成した学習データセットをモデルの初期学習に再利用できます。さらに、SAM最適化を組み込む基盤としてR-MATフレームワークを選択したため、モデル学習中に学習セットを更新しないことにしました。もちろん、この選択はモデル性能に負の影響を与える可能性がありますが、学習データセットの変更による影響を排除することで、ベースラインモデルとのより直接的な比較が可能になります。
3つのモデルすべての学習は同時におこなわれました。学習済みActor方策のテスト結果は以下に示します。テストは2024年1月の実際の過去データを対象におこない、その他の学習パラメータは変更していません。
結果を確認する前に、モデル学習に関していくつか述べておきます。第一に、SAM最適化は本質的に損失関数のランドスケープを平滑化します。これにより、より高い学習率を検討できるようになります。以前の研究では主に学習率3.0e-04を使用していましたが、今回は1.0e-03に引き上げました。
第二に、Attention層を1つだけ使用したことで、学習可能なパラメータの総数が削減され、SAM最適化に必要な追加のフィードフォワード処理による計算負荷を相殺するのに役立ちました。
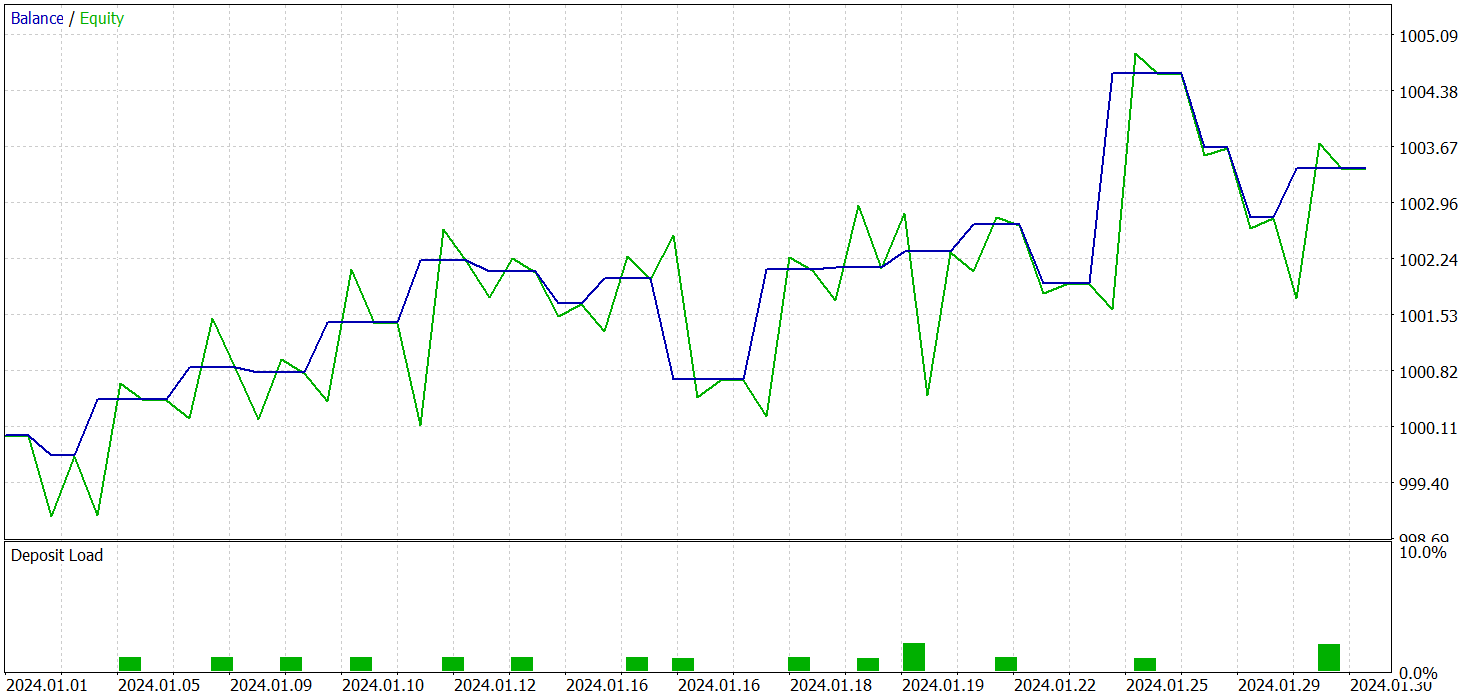
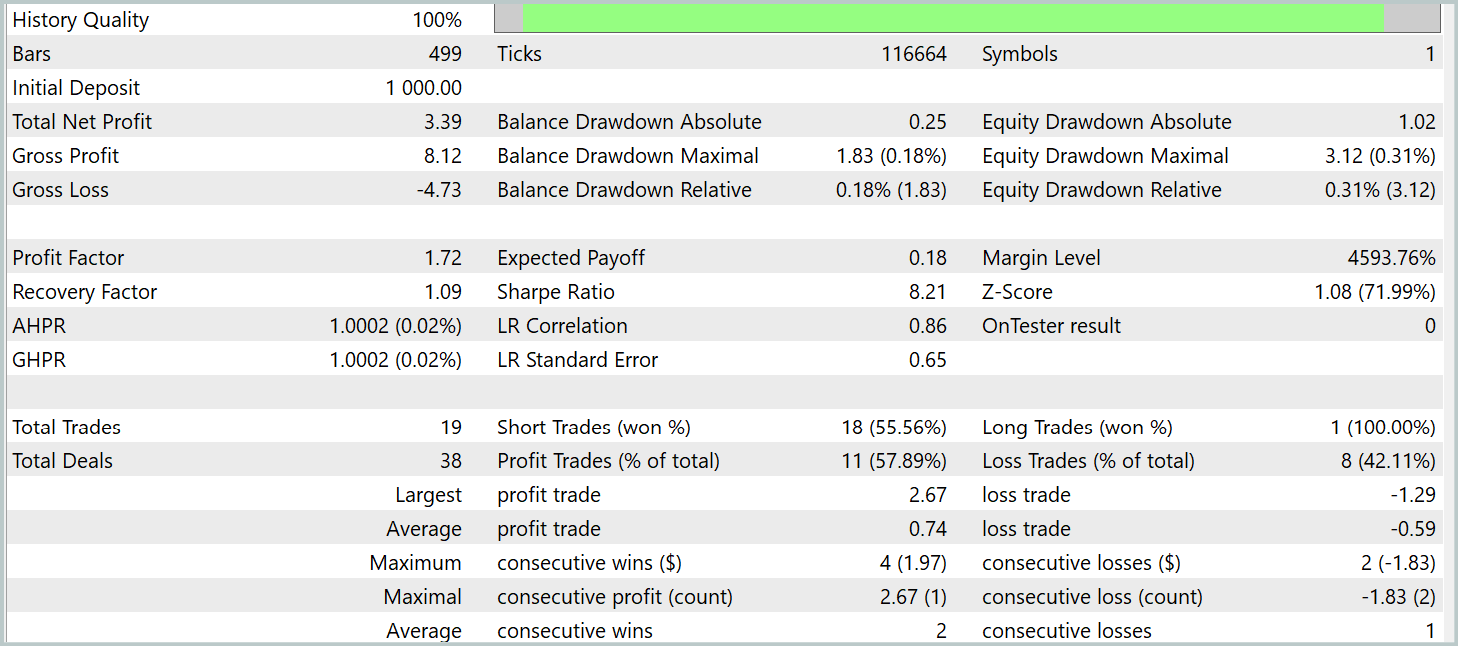
学習の結果、学習データセット外でも利益を生み出せる方策を得ることができました。テスト期間中、モデルは19回の取引を実行し、そのうち11回が利益を出すことに成功しました(成功率57.89%)。比較として、以前実装したR-MATモデルは同期間で15回の取引をおこない、9回が利益(成功率60.0%)でした。注目すべき点として、新モデルの総リターンはベースラインのほぼ2倍となっています。
結論
SAMformerフレームワークは、多変量時系列の長期予測におけるTransformerアーキテクチャの主要な制約に対する効果的な解決策を提供します。従来のTransformerでは、学習の複雑さが高く、特に学習データセットが小さい場合に汎化性能が低下するなど、重要な課題が存在します。
SAMformerの核心的な強みは、浅いアーキテクチャとSharpness-Aware Minimization (SAM)の統合にあります。これらの手法により、モデルは局所的な悪い最小値を回避し、学習の安定性と精度を向上させ、優れた汎化性能を発揮できます。
実践部分では、これらの手法をMQL5で独自に実装し、実際の過去データを用いてモデルを学習させました。テスト結果は、提案手法の有効性を裏付けており、ベースラインモデルの性能を向上させつつ、追加の学習コストを発生させないことを示しています。場合によっては、学習コストを削減することさえ可能です。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いた例収集用のEA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダ学習用EA |
| 5 | Test.mq5 | EA | モデルテスト用EA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16403
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ロシアの銀行のドル建て年収。12で割って比較する。
元では6、元債券では10以上。
人民元で6、人民元建て債券で10以上。
しかし、EURUSDでテストした結果と米ドルでの結果は記事に記載されている。同時に、預金の負荷は1-2%である。 そして、誰もそれが聖杯であると書いていない。
しかし、記事にはEURUSDでのテスト結果と米ドルでの結果が示されている。同時に、入金に対する負荷は1-2%である。 そして、誰もそれが聖杯であるとは書いていない。
OK]をクリックします。
月に0.35%の利益?銀行に預けた方が得では?