
ニューラルネットワークが簡単に (第42回):先延ばしのモデル、理由と解決策

はじめに
強化学習の分野では、ニューラルネットワークモデルは、学習プロセスが遅くなったり行き詰まったりすると、しばしば先延ばしの問題に直面します。モデルの先延ばしは目標達成に深刻な結果をもたらす可能性があり、適切な対策を講じる必要があります。この記事では、モデルを先延ばしにする主な理由を調べ、それを解決する方法を提案します。
1.先延ばし問題
モデルを先延ばしにする主な理由のひとつは、訓練環境が不十分であることです。モデルは、訓練データへのアクセスが制限されていたり、リソースが不足していたりする可能性があります。この問題を解決するには、データセットを作成または更新し、訓練例の多様性を増やし、計算能力や事前訓練済みモデルなどの追加的な訓練リソースを適用する必要があります。
モデルを先延ばしにするもう1つの理由は、解決すべきタスクの複雑さや、多くの計算資源を必要とする訓練アルゴリズムの使用かもしれません。この場合の解決策は、問題やアルゴリズムを単純化し、計算プロセスを最適化し、より効率的なアルゴリズムや分散学習を用いることでしょう。
目標達成への動機が低ければ、モデルは先延ばしにするかもしれません。モデルに対して明確で適切な目標を設定し、その目標達成にインセンティブを与える報酬関数を設計し、報酬や罰則などの強化技術を使用することで、この問題を解決することができます。
モデルがフィードバックを受け取らなかったり、新しいデータに基づいて更新されなかったりすると、開発が先延ばしになる可能性があります。その解決策は、新しいデータとフィードバックに基づく定期的なモデル更新サイクルを確立し、学習の進捗状況を管理監視するメカニズムを開発することです。
モデルの進歩や学習成果を定期的に評価することが重要です。これは、進捗状況を確認し、起こりうる問題やボトルネックを特定するのに役立ちます。定期的な評価によって、訓練の遅れを避けるために、訓練プロセスを適時に調整することができます。
モデルになるようなさまざまな仕事や刺激的な環境を与えることは、先延ばしを避けるのに役立ちます。タスクにバリエーションを持たせることで、モデルの興味とやる気を維持することができます。また、競争やゲームの要素など、刺激的な環境を与えることで、モデルの積極的な参加と進歩を促すことができます。
モデルの先延ばしは、更新や改良が不十分なために起こる可能性があります。定期的に結果を分析し、フィードバックや新しいアイデアに基づいてモデルを反復的に改善することが重要です。モデルを徐々に発展させ、目に見える進歩を遂げることで、先延ばしに対処することができます。
モデルにとってポジティブで協力的な学習環境を提供することは、強化モデルの訓練の重要な側面です。研究によると、肯定的な例は、より効果的で集中的なモデル学習につながります。これは、モデルが最も最適な選択を探し求めているためで、誤った行動に対するペナルティは、誤った行動を選択する確率の減少につながります。同時に、肯定的な報酬は、その選択が正しかったことをモデルに明確に示し、そのような行動を繰り返す可能性を著しく高めます。
ある行動に対して肯定的な報酬を受けると、モデルはその行動にもっと注意を払うようになり、将来その行動を繰り返すようになります。この動機付けのメカニズムは、モデルが目標を達成するために最も成功する戦略を探し、特定するのに役立ちます。
最後に、先延ばしに効果的に対処するには、その理由を分析する必要があります。先延ばしにする具体的な原因を特定することで、それを解消するための的を射た対策を講じることができます。これには、訓練プロセスの監査、ボトルネックの特定、リソースの問題、最適でないモデル設定などが含まれます。
状況の変化を考慮し、それに適応することで、先延ばしを避けることができます。新しいデータや学習課題の変化に基づいてモデルを定期的に更新することで、適切かつ効果的なモデルを維持することができます。さらに、新しい要件や制約などの要因を考慮することで、モデルを適応させ、停滞を避けることができます。
小さな目標やマイルストーンを設定することで、大きな仕事をより管理しやすく、達成可能な部分に分割することができます。こうすることで、学習プロセスにおいて、モデルが進歩を確認し、動機を維持することができます。
強化学習モデルで先延ばしをうまく克服するには、さまざまなアプローチや戦略を用いる必要があります。この包括的なアプローチは、先延ばしを効果的に克服し、訓練で最高の結果を出すのに役立ちます。学習環境の改善、明確な目標の設定、進捗状況の定期的な評価、動機の活用など、さまざまなテクニックを組み合わせることで、このモデルは先延ばしを克服し、学習目標の達成に向けて前進することができるでしょう。
2.実践的な解決策
理論的な考察の後は、これらのアイデアの実践的な応用に目を向けてみましょう。
前回の記事では、負けトレードを最小限に抑えるためにさらなる訓練が必要だと述べました。しかし、訓練を続けているうちに、EAが訓練期間中一度も取引をおこなわないという事態に遭遇しました。
「モデルの先延ばし」と呼ばれるこの現象は、私たちの注意と解決策を必要とする深刻な問題です。

2.1.理由の分析
強化学習におけるモデルの先延ばしを克服するためには、まず現状を分析し、その原因を特定することから始めることが重要です。この分析は、モデルがなぜ取引をおこなわないのか、そしてそのパフォーマンスを向上させるために何を調整すればよいのかを理解するのに役立ちます。
訓練されたモデルのテストは、貪欲にエージェントと行動を選択するTest.mq5 EAを用いておこなわれます。重要なのは、同じパラメータとテスト期間でEAを起動するたびに、前回のパスが高い精度で再現されることです。これにより、EAを起動するたびにコントロールポイントを追加し、EAの動作を分析することができます。
コントロールポイントを追加し、各発射におけるEAの働きを分析することで、強化モデルの訓練結果に対するより高い信頼性と確信が得られます。モデルがどのように知識と予測を実データに適用するかをよりよく理解し、適切な結論を出し、パフォーマンスを向上させるための調整をおこなうことができます。
スケジューラーの働きを評価するために、各エージェントが選択された回数を格納するModelsCountベクトルを導入します。これをおこなうには、グローバル変数のブロックでModelsCountベクトルを宣言します。
vector<float> ModelsCount;
次に、OnInit関数で、使用するエージェント数に対応するサイズでこのベクトルを初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
OnTick関数では、スケジューラーの各フォワードパスの後、ModelsCountベクトルの対応するエージェントのカウンタを増やします。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
最後に、EAを非初期化する際に、計算結果を操作ログに表示します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
そこで、各エージェントの選択回数をカウントする機能を追加し、EAの初期化解除時にカウント結果を操作ログに表示します。これにより、スケジューラーの性能を評価し、EA実行中に各エージェントがどれくらいの頻度で選択されたかという情報を得ることができます。
最初のコントロールポイントを追加した後、パラメータやテスト期間を変更することなく、ストラテジーテスターでEAを起動しました。得られた結果は、私たちの不安を裏付けるものでした。テスト中、スケジューラーは1つのエージェントしか使っていないことがわかります。

この観察結果は、スケジューラーが特定のエージェントに偏り、他の利用可能なエージェントの探索を怠っている可能性を示しています。このようなバイアスは、強化学習モデルのパフォーマンスを妨げ、より効果的な戦略を発見する能力を制限する可能性があります。
この問題を解決するためには、スケジューラーがエージェントを1つしか選ばない理由を探る必要があります。
この挙動の理由を分析し続けるために、2つのコントロールポイントを追加します。ここでは、環境の状態の変化によるモデルの出力分布の変化のダイナミクスに注目します。そのために、prev_schedulerとprev_actorという2つの追加ベクトルを導入します。これらのベクトルには、スケジューラーとエージェントがそれぞれ前回行ったフォワードパスの結果が格納されます。
vector<float> prev_scheduler; vector<float> prev_actor;
これにより、現在の分布を以前のものと比較し、その変化を評価することができます。もし分布が時間の経過や環境の変化に応じて大きく変化することがわかったら、それはモデルが変化に対して敏感すぎるか、戦略が不安定であることを示しているのかもしれません。
このようなベクトルをモデルに加えることで、戦略や配分の変化のダイナミクスについて、より詳細な情報を得ることができ、その結果、特定のエージェントの選好の理由を理解し、この問題を解決するための対策を講じることができます。
前のケースと同様に、OnInitメソッドでベクトルを初期化し、データ制御の準備をします。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
実際のデータ制御はOnTickメソッドでおこなわれます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
この場合、環境の状態の変化がモデルの結果にどのような影響を与えるかを評価します。この実験の結果、テストサンプルの各ローソク足について、モデル出力でユニークな確率分布が見られると予想されます。言い換えれば、市場環境の変化によるモデルの戦略の変化を観察するのです。
分析結果のログは、大量のデータになるため取りません。代わりに、デバッグモードを使って値の変化を見ることにします。比較する値の量を減らすため、ベクトルの偏差の合計だけを確認します。
残念ながら、テスト中にズレは見つかりませんでした。つまり、モデル出力の確率分布は、どの環境状態でもほとんど変わりません。
この観察結果は、モデルが環境の変化に適応しておらず、市場環境の違いを考慮していないことを示しています。このようなモデルの挙動にはいくつかの理由が考えられ、それを解決するためのさまざまなアプローチがあります。
- 訓練データセットの限界:訓練データセットに十分な種類の状況が含まれていない場合、モデルは新しい状況に適切に対応することを学習できない可能性があります。その解決策は、より幅広いシナリオと変化する市場環境を含むように、訓練データセットを拡大し多様化することかもしれません。
- モデルの訓練不足:モデルは、異なる環境条件に適応するために、十分な訓練を受けなかったり、十分な訓練エポックを経なかったりする可能性があります。この場合、訓練時間を増やしたり、ファインチューニングのような追加的な方法を使うことで、モデルの適応力を高めることができます。
- モデルの複雑さが不十分:環境状態の微妙な違いを捉えるには、モデルが複雑でない可能性があります。この場合、層を増やしたりニューロンの数を増やすなど、モデルのサイズや複雑さを増すことで、データの違いをよりよく捉え、処理することができます。
- モデルアーキテクチャの選択ミス:現在のモデルアーキテクチャが、変化する環境に適応するという問題を解決するには適していないのかもしれません。そのような場合、モデルのアーキテクチャを見直すことで、環境の変化に適応する能力を向上させることができます。
- 報酬関数が正しくない:モデルの報酬関数が十分な情報を持っていなかったり、必要な目標を満たしていなかったりする可能性があります。このような場合、報酬関数を再考し、より関連性の高い要素を報酬関数に組み込むことで、変化する環境の中でモデルがより賢い決断を下すことができます。
これらのアプローチはすべて、変化する環境によりよく適応し、パフォーマンスを向上させるために、さらなる実験、テスト、モデルのチューニングを必要とします。
各層のアーキテクチャーを分析し、システムの状態変化に関する情報がモデルのどこで失われているかを正確に突き止めます。デバッグモードでは、モデルの各層の出力の変化を確認します。
まずは完全連結されたCNeuronBaseOCL層から始めます。この層では、システムの状態変化に関する情報が保存されているかどうかを確認します。次に、CNeuronBatchNormOCL バッチデータ正規化層が状態変化データを歪めていないことを確認します。次に、CNeuronConvOCL畳み込み層を分析し、システムの状態変化情報をどのように扱うかを確認します。最後に、CNeuronMultiModelマルチモデル完全連結層を検証し、モデル間の状態変化をどのように説明するかを判断します。
この分析をおこなうことで、システム状態の変化に関する情報がモデルアーキテクチャのどの層で失われているかを特定し、変化する環境に適応するモデルの性能を向上させるために、どの層を最適化または修正することができるかを特定することができます。
モデル内の各層の出力を制御し追跡するために、CNeuronBaseOCLクラスでprev_outputベクトルを実装します。覚えているかもしれませんが、このクラスは他のすべてのニューラル層クラスの基本クラスであり、他のすべての層はこれを継承します。このクラスの本体にベクトルを追加することで、モデルのすべての層でその存在を保証します。
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
クラス初期化メソッドでは、この層のニューロン数に等しいベクトルサイズを設定します。
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
モデルを順方向に通過させるfeedForwardメソッドでは、すべての反復が完了した後、メソッドの最後に制御点を追加します。このメソッドでの操作はすべてOpenCLのコンテキストで実行されることにご注目ください。データを制御するためには、演算結果をメインメモリにロードする必要があるが、これにはかなりの時間がかかります。これまでは、この負荷を最小限に抑え、モデルの結果の負荷だけを残すようにしていました。この場合、各ニューラル層の結果を読み込む必要があります。しかし、データ制御が必要なければ、このコードブロックは後で削除したり、コメントアウトすることができます。
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
また、分析したすべてのクラスのニューラル層のフォワードパスメソッドにも同様のコントロールを追加します。これにより、各層の出力値を監視し、システムの状態の変化が「失われる」可能性のある場所を特定することができます。各層クラスのフォワードパスメソッドに適切なコードブロックを追加することで、モデル訓練の各反復で層の結果を保存し、分析することができます。
データはデバッグモードでモニターされます。
結果を分析した結果、生データ層、バッチ正規化層、畳み込みニューラル層と完全連結層の2つの連続ブロックからなるデータ前処理ブロックが正しく機能していないことがわかりました。その結果、2層目の畳み込み層の後では、分析されたシステムの状態の変化にモデルが反応しないことがわかりました。
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
これは、エージェントの場合と、同様のデータ前処理ユニットを使用したスケジューラーの場合の両方で観察されます。テスト結果はどちらも同じでした。
以前の実験では、このアーキテクチャーは良い結果をもたらしたにもかかわらず、今回は効果がないことが判明しました。そのため、ここでは、使用するモデルのアーキテクチャを変更する必要性に迫られています。
2.2.モデルアーキテクチャの変更
現在のモデルアーキテクチャは効果がないことが証明されています。ここで一歩引いて、以前に作成したアーキテクチャを新たな視点から見て、それを最適化するための可能な方法を評価しなければなりません。
現在のモデルでは、私たちは市場の状況と口座の状態をエージェントの入力に提出し、エージェントは状況を分析し、可能な行動を提案します。エージェントの作業結果を事前に収集した初期データに加え、それをスケジューラーの入力として渡し、スケジューラーは行動を実行するエージェントを1つ選択します。
ここで、ある投資部門を想像してみましょう。そこでは、従業員が市場の状況を分析し、その分析結果を部門長に報告します。結果を得た部門長は、元のデータと組み合わせ、さらに分析をおこない、自分の予想と一致するエージェントを1つ選びます。しかし、この方法は部門の効率を低下させる可能性があります。
この場合、部門長は自ら市場の状況を分析し、従業員の仕事の成果も研究しなければなりません。これはさらなる負担を強いるものであり、決断を下す際に必ずしも実用的な価値を持つとは限りません。各ステップで可能な限り多くの情報を提供しようとすると、問題をより小さな構成要素に分割するという階層モデルの主要なアイデアを見逃してしまう可能性があります。
このような場合、私たちのモデルから類推すると、このような部門の効率は、市場状況の分析だけでなく、従業員のパフォーマンスチェックにも対応しなければならないため、部門長の効率よりも低くなる可能性があります。これによって、意思決定の効率が低下する可能性があります。
提示されたシナリオから、市場状況の分析をエージェントとスケジューラーの間で共有すれば、投資部門の効率が向上することは明らかです。このモデルでは、エージェントは市場分析に特化し、スケジューラーは独自に市場状況を分析することなく、エージェントの予測に基づいて意思決定をおこないます。
エージェントは、テクニカル分析やファンダメンタルズ分析など、市場データの分析を担当します。市場の現状を調査評価し、トレンドを見極め、可能な対策を提案します。しかし、分析をおこなう際に口座残高は考慮しません。
一方、スケジューラーは、リスク管理とエージェント分析に基づく意思決定を担当します。エージェントとから提供された予測や推奨を利用し、口座の健全性やリスク管理に関連するその他の要因について追加的な分析をおこないます。この情報に基づいて、プランナーは投資戦略の中で具体的な行動を最終的に決定します。
このような役割分担により、エージェントは口座状況に気を取られることなく市場分析に集中することができ、専門性と予測の精度が高まります。スケジューラーは、エージェントの予測に基づき、リスクの評価と意思決定に集中することができ、ポートフォリオを効果的に管理し、リスクを最小限に抑えることができます。
このアプローチは、各メンバーがそれぞれの専門分野に集中することで、投資チームの意思決定プロセスを改善し、より正確な分析と予測を可能にします。これにより、私たちのモデルのパフォーマンスが向上し、より多くの情報に基づいた投資判断が可能になります。
提示された情報をもとに、モデルのアーキテクチャを見直すことにします。まず、エージェントのソースデータ層を変更し、市場状況の分析のみに集中させ、口座状態の分析を担当するニューロンを削除します。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
データの前処理ブロックでは、完全連結層を削除します。バッチ正規化層と2つの畳み込み層だけを残しておくことにします。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
決定ブロックに変更はありません。
Criticのアーキテクチャを変更することにしました。前回同様、Criticは市場の状況と口座の状態の両方を分析します。なぜなら、次の状態の値は、最後に取った行動だけでなく、ポジションや累積損益で表される以前の行動にも依存するからです。
また、その後の状態の価値は、選択した戦略に依存すべきではないという結論に達しました。ここでの目標は、具体的な戦略にかかわらず、潜在的な利益を最大化することです。これを考慮して、Criticのモデルにいくつかの変更を加えました。
具体的には、Criticのアーキテクチャを簡素化し、多モデルの完全連結層を削除しました。その代わりに、完全にパラメータ化された決定モデルを追加しました。これにより、戦略が状態値の評価に直接影響しない、より一般的で柔軟なアプローチを実現することができます。
このCriticモデルのアーキテクチャの変更により、市場分析と意思決定を分離することができ、プロセスが簡素化され、選択した戦略にかかわらず、利益の最大化に集中できるようになりました。
さらに、エージェントアーキテクチャの変更と同様に、データ前処理ブロックにも変更を加えました。データ前処理ブロックでは、完全連結層を取り除き、バッチ正規化層と2つの畳み込み層だけを残して、アーキテクチャを単純化しました。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
次に、スケジューラーのアーキテクチャを大幅に簡素化しました。市場状況の分析を放棄したことで、ソースデータ層のサイズを大幅に縮小することができました。その結果、データの前処理ユニットはほぼ完全に取り除かれ、バッチ正規化層のみが残りました。口座状態の絶対値を分析するために、バッチ正規化を使用することにしました。現在、エージェントモデルの出力から完全に正規化された値を使用しています。将来的には、相対的なスコア値に移行し、データ正規化層の使用をなくすかもしれません。
決定ブロックでは、出力にSoftMax層を持つ単純なパーセプトロンモデルを使用しました。このモデルは、様々なAgentの確率分布を求め、その確率に基づいて最も適切な行動を選択することができます。
このようにスケジューラーアーキテクチャを単純化することで、エージェント分析の結果のみを考慮した、より効率的な意思決定が可能になります。これによって計算の複雑さが軽減され、追加データへの依存も減ります。
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
モデルを訓練する過程で、3つのEAを使用します。それぞれが独自の機能を果たしています。混乱を避け、エラーの可能性を減らすため、モデルアーキテクチャを記述する機能を、モデルで使用するクラスと構造を記述したライブラリの一部であるTrajectory.mqhファイルに移すことにしました。これにより、すべてのEAで単一のモデルアーキテクチャを使用することができ、3つのEAすべての作業における変更の自動同期が保証されます。
ソースデータストリームの分離を含め、モデルの構造が変更され、そのために現在の状態の説明の構造を変更する必要がありました。分析および意思決定の際に考慮できるように、口座ステータスを記録するための別の配列を割り当てました。この変更により、モデルの訓練や運用において、アカウント情報をより効果的に管理利用できるようになりました。
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
モデルの構造を変更した結果、ファイルを扱うメソッドも変更しなければなりませんでした。更新された構造体と対応するメソッドの完全なコードは、添付ファイルにあります。
2.3.データ収集プロセスの変更
次の段階ではデータ収集プロセスに変更を加えました。これはResearch.mq5 EAでおこなわれます。
前述したように、モデルを訓練するために肯定的な例を使用することは、その効率を高めます。そこで、例のデータベースに保存するために、取引の最低収益率に制限を導入しました。この最小収益性のレベルは、外部パラメータProfitToSaveによって決定されます。
さらに、ポジションを長期保有するケースを減らすため、テイクプロフィットやストップロスのレベルを制限する外部パラメータを導入しました。これらのパラメータの値は預金通貨で設定され、ポジションを保有する期間を制限し、ポジションの量を間接的に制御することができます。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
データストレージ構造やモデルアーキテクチャの変化により、モデルを直接実行するためのデータ収集や準備作業を変更する必要が出てきました。前回同様、市場の状態データをstate配列に集め始めます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
次に、口座情報をaccount配列に保存します。
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
更新されたAgentsモデルアーキテクチャを使ったフォワードパスでは、state配列から市場の状態を取得するだけでよくなります。
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
スケジューラーのフォワードパスのための初期データを提供するためには、口座状態のデータとエージェントモデルのフォワードパスの結果を組み合わせる必要があります。
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
2つのモデルを直接通過した結果、サンプリングして行動を選択します。このプロセスに変更はありません。ただし、累積損益の分析を加えます。累積損益値が指定されたしきい値に達した場合、すべてのポジションを決済する行動を指定します。
注意すべき点は、私たちのモデルはポジションをすべて決済するという行動のみを想定していることです。したがって、累積損益を分析する際には、方向性に関係なく、すべてのポジションの価値を合計します。
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
また、報酬関数にも変更を加えました。この決定は、株式変動の影響を排除するためにおこなわれました。しかし、金融市場における取引の過程では、最終的な価値を持つのは残高の変化だけであることがわかっています。これは報酬関数を調整する際に考慮されました。
すべてのEAメソッドと関数の完全なコードは添付ファイルにあります。
2.4.学習プロセスの変化
また、すべてのモデルとエージェントを並行して訓練することに重点を置き、モデルの訓練プロセスにも変更を加えました。特に、リバースパスの際の報酬の渡し方を変えました。以前は、選択されたエージェントにのみ報酬を指定していましたが、すべてのエージェントに報酬の分配全体を渡すようにします。これにより、スケジューラーは各エージェントの可能な影響をより十分に評価することができ、先に観察したように、すべての状態に対して単一のエージェントを選択する可能性を減らすことができます。
確率論から、複雑な事象が発生する確率は、その構成要素の確率の積に等しいことが分かっています。ここでの場合、エージェントの選択の確率分布と、各エージェントの行動の選択の確率分布があります。データベースの例では、具体的な行動とそれに対応するシステムからの報酬もあります。プランナーのバックワードパス用のデータを準備するために、エージェントの選択確率のベクトルの要素に、与えられた行動に対する各エージェントの選択確率のベクトルの要素を掛けます。
完全な報酬をスケジューラーに渡すために、SoftMax関数を使って結果の確率を正規化し、その結果のベクトルに外部報酬を掛けます。同時に、状態の値に基づいて外部報酬を事前調整することで、最適軌道からの乖離を推定することができます。
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
Criticを訓練するには、対応する行動に対して未修正の外部報酬を渡すだけでよくなります。
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
エージェントモデルを扱う際には、どのような戦略を使っても利益と損失の両方が出る可能性があることを考慮します。場合によっては、エントリーで失敗した後、時間通りにポジションを終了し、損失を限定する決意を持つことが重要です。したがって、マイナスの報酬を伴う行動を完全に排除することはできません。場合によっては、他の行動がさらに大きなマイナスの効果をもたらすこともあるからです。プラスの報酬についても同様です。
エージェントモデルのバックワードパス用のデータを準備する場合、各エージェントが行動を選択する確率とシステムからの外部報酬を考慮して、前回のフォワードパスの結果を調整するだけです。各エージェントの確率分布の整合性を保つために、SoftMax関数を使って調整された分布を正規化します。
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
添付ファイルでは、すべてのEAの完全なコードと、その作業で使用される関数を見ることができます。
モデルの訓練プロセスを開始するために、Go-Explore アルゴリズムの記事で説明したのと同様のストラテジーテスター最適化モードでResearch.mq5 EAを起動します。 ここでの主な違いは、データベースに保存される例を決定する最低合格利益レベルの指定です。これにより、データベースに保存されるサンプルが決まります。これは、肯定的な例に焦点を当てるため、モデル訓練の効率を向上させるのに役立ちます。
ただし、1つ重要なことを指摘しておきます。環境をより多様に探索し、行動戦略の網羅性を高めるために、サンプル収集プロセスにテイクプロフィットやストップロスのパラメータの最適化を含めることができます。これにより、私たちのモデルはより多くの異なる戦略を研究し、ポジションからの最適な出口を見つけることができます。

例のデータベースを作成した後、Study2.mq5 EAを使用してモデルの訓練を開始します。これをおこなうには、選択したシンボルのチャートにEAを取り付け、反復回数を指定する必要があります。これにより、モデルパラメータが更新される回数が決まります。
チャート上でStudy2.mq5 EAを起動することで、モデルは収集されたサンプルを使って訓練し、パラメータを調整することができます。学習プロセスにおいて、モデルはより正確な意思決定をおこない、その効率を高めるために、市場環境に適応し、改善されます。
ストラテジーテスターでTest.mq5 EAのシングルパスを実行し、モデルの訓練結果を確認します。最初のモデル訓練反復の後、その結果が予想から大きく外れることは十分に予想されます。採算が合わないかもしれません。


あるいは利益を生むかもしれません。しかし、バランス曲線は私たちの予想とはかけ離れたものになるでしょう。

しかし同時に、私たちのスケジューラーが、ほとんどすべてのエージェントをある程度は使っていることもわかります。


モデルの誤った行動を検出するために、訪問した状態、完了した行動、受け取った外部報酬に関する情報を収集するブロックをテストTest.mq5 EAに追加します。このデータ収集ブロックは、エキスパートアドバイザー(EA)で例を収集するために使用されるものと似ています。
テストEAでは、エージェントと行動の貪欲な選択を使用していることに留意してください。つまり、モデルの戦略によって、すべてのステップが決定されるということです。したがって、収益性に関係なく、すべてのパスを例のデータベースに追加します。このデータを例のデータベースに含めることで、モデルの取引戦略を調整し、最適化することができます。
訪問した状態、取った行動、受け取った報酬に関する情報を収集することで、モデルのパフォーマンスを分析し、どの行動が望ましい結果につながり、どの行動が望ましくない結果につながるかを判断することができます。この情報によって、その後の訓練の繰り返しで、モデルの効率と意思決定の精度を向上させることができます。
ストラテジーテスター最適化モードで例の収集EAを実行する追加の反復は、肯定的な例のベースを拡大し、私たちのモデルを訓練するためのより多くのデータを提供するために重要です。
しかし、例を収集する過程とモデルを訓練する過程を交互におこなう必要があることに注意することが重要です。例の収集では、モデルによって生成された確率分布から行動をサンプリングします。つまり、例の収集には方向性があり、新しい例は貪欲な行動選択の短い距離内にあります。これによって、ある方向性の環境をより完全に探索し、例のデータベースを有用なデータで充実させることができます。
例の収集とモデルの訓練を交互におこなうことで、モデルは新しいデータをうまく利用し、受け取った情報に基づいて戦略を改善することができます。同時に、新しい反復を重ねるごとに、モデルはより経験を積み、求められる貿易の方向性に適応していきます。
3.検証
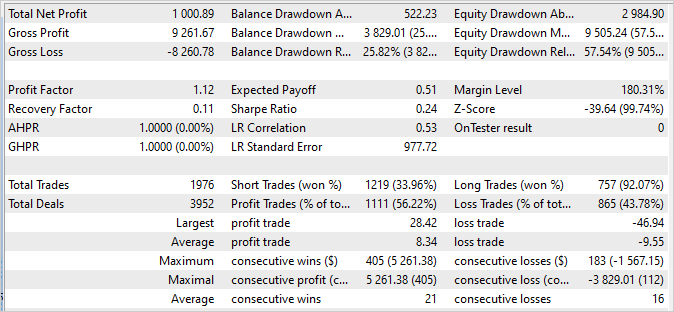
何度か例を収集し、訓練、テストを繰り返した結果、訓練セットで114.53の利益を生み出すモデルに到達しました。モデルを訓練した2023年の最初の4か月間で、286件の取引が完了しました。このうち、不採算だったのはわずか16件でした。訓練セットでのリカバリーファクターは1.3であり、これはモデルが損失から素早く回復する能力を示しています。
ポジションの保有時間は1時間から198時間の間で均等に分布し、平均保有時間は72時間59分でした。これは、このモデルが現在の市場の状況に応じて、短期と長期の両方の時間間隔で意思決定ができることを示しています。
全体として、これらの結果は、モデルが高い収益性、低い損失率、迅速な回復能力、およびタイミングのポジションの柔軟性を示すことを示唆しています。これは、モデルの有効性と実際の取引条件での適用の可能性を肯定的に確認するものです。



訓練セットに含まれていない次の2週間のバランスグラフが安定性を示しており、訓練セットのグラフと大きな違いがないことに注目することは非常に重要です。成績は少し落ちますが、それでもまずまずです。
- プロフィットファクターは15.64であり、リスクに対するモデルの収益性の高さを示します。
- リカバリーファクターは1.07で、負けトレードからの回復能力を示します。
- 完了した89件の取引のうち、80件が黒字で終了しており、成功した取引の割合が高いことを示します。
これらの結果は、その後の取引データにおけるモデルの安定性と頑健性を裏付けています。この値は訓練セットとは若干異なるかもしれないが、それでも印象的なものであり、このモデルが実世界で取引を成功させる可能性があることを裏付けています。


ストラテジーテスターのレポートは添付ファイルにあります。
結論
この記事では、モデルの先延ばしの問題を検討し、それを克服するための効果的なアプローチを提案しました。スケジューリングされた補助制御アルゴリズムを用いて、金融市場における自動売買のためのモデルを訓練するアプローチを開発しました。
相互に作用し合う複数のモデルからなる階層的なアーキテクチャを提示しました。それぞれのモデルは、意思決定の特定の側面を担っています。このモジュール構造により、タスクをより小さいが相互に関連するサブタスクに分割することで、先延ばしを効果的に克服することができます。
また、実際のデータで効果的にモデルを訓練し、変化する市場の状況に適応することを可能にする、例の収集、モデルの訓練、テストの方法についても取り上げました。様々な戦略を取り入れ、蓄積された利益と損失を分析することで、情報に基づいた決断を下し、リスクを最小限に抑えることができます。
実験の結果、提案されたアプローチは確かに先延ばしを克服し、安定的で収益性の高い取引を実現できることが示されました。モデルは、訓練データとフォローアップデータにおいて高い収益性と安定性を実証しており、実環境における有効性を裏付けています。
全体として、ここでのアプローチによって、モデルは効果的に学習して市場の状況に適応し、情報に基づいた意思決定をおこなうことができるようになります。このアプローチをさらに発展させ最適化することで、金融市場における自動売買の収益性と安定性がさらに高まる可能性があります。
参考文献リスト
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 例収集EA |
| 2 | Study2.mql5 | EA | モデル訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | FQF.mqh | クラスライブラリ | 完全にパラメータ化されたモデルの作業を整理するためのクラスライブラリ |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
…
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12638
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは、ディミトリ。新作をありがとう。私もグラフを直線にしようとしていました。その理由がわかりました。どのような Study2 の結果が許容範囲と考えられるか教えてください。テストはまだ意味のあるアクションを示しておらず、すべてのバーで買いとフィルをオープンしています。
ところで、NeuroNet_DNGフォルダは前回のEAからドラッグする必要がありました。もし変更したのであれば、私は壁に頭を打ちつけています。
最新版のファイルは添付ファイルにあります。
ドミトリー、こんにちは。このExpert Advisorをどの程度トレーニングしたら、マイナスでも少なくとも意味のある取引ができるようになったのか教えてください。私の場合、全く取引しようとしないか、多くの取引を開始し、4ヶ月の全期間を通過することができません。同時に、残高は静止し、株式は浮いている。エージェントは1人か2人で、残りはゼロです。最初のサンプルはいろいろ試してみた。
-例えば50ドルから30-40の例を始め、Stady2(デフォルトで100000)の各パスの後に、1-2例をサイクルで追加した。
-35ドルから......たとえば、最初に130-150例、そしてStady2(デフォルトで100000)の各パスの後に、ループで1-2例を追加。
- 50$ からは、最初に 15 例を用い、500000 と 2000000 の Stady2 のトレーニングには何も追加しません。
すべてのバリエーションで結果は同じです - 動作しません、学習しません。さらに、例えば2-300万回繰り返した後、また何も表示されないかもしれません。
取引を開始したり終了したりするには、いくら(数字で)学習させる必要がありますか?
こんにちは、ドミトリー!あなたは素晴らしい先生であり、指導者でした!
350668273_1631799953971007_1316803797828649367_n.png (1115×666) (fbcdn.net)トレーニングに成功した後、私は99%の勝率を達成することができました。しかし、売りのみです。no buy trades
これがスクリーンショットです:
350733414_605596475011106_6366687350579423076_n.png (1909×682) (fbcdn.net)
ドミトリー、
この記事を読んで、最終的に提示されたモデルは、ショートトレードの識別には優れているが、ロングトレードの識別には全く成功していない。ショートトレードを補完するためにロングトレードモデルが 必要です。 ロングモデルは、いくつかの仮定を逆転させることで開発できると思いますか、それとも39番の記事で紹介されているToe Go Exploreのような全く新しいモデルが必要だと思いますか?
あなたの現在の努力に敬意を表し、今後の努力を応援します。