
取引におけるニューラルネットワーク:Segment Attentionを備えたパラメータ効率重視Transformer(最終回)

はじめに
前回の記事では、PSformerフレームワークの理論的側面について説明しました。このフレームワークは、従来のTransformerアーキテクチャにパラメータ共有(PS)機構とSpatial-Temporal Segmented Attention (SegAtt)という2つの重要な革新を導入します。
復習すると、PSformerの著者は、Transformerアーキテクチャに基づくエンコーダを提案しました。このエンコーダは、二段階のSegment Attention構造を備えています。各レベルには、残差接続を持つ3つの全結合層からなるパラメータ共有ブロックが含まれています。このアーキテクチャにより、モデル内の情報交換を維持しながら、総パラメータ数を削減できます。
セグメントはパッチング手法を用いて生成されます。時系列変数はパッチに分割され、異なる変数間で同じ位置にあるパッチはセグメントとしてまとめられます。このセグメントは、単一変数パッチの空間的拡張を表し、多次元時系列を効率的に複数のセグメントに整理することを可能にします。
各セグメント内では、Attention機構が局所的な時空間関係を特定することに重点を置き、セグメント間の情報統合により全体的な予測精度が向上します。
さらに、PSformerフレームワークにおけるSAM最適化手法の使用により、性能を損なうことなく過学習のリスクを低減できます。
著者らが様々なデータセットで行った長期時系列予測の大規模な実験により、PSformerの高い性能が確認されています。主要な8つの予測タスクのうち6つで、このアーキテクチャは最先端モデルと比べて競争力のある、あるいは優れた結果を達成しました。
PSformerフレームワークのオリジナルの可視化を以下に示します。
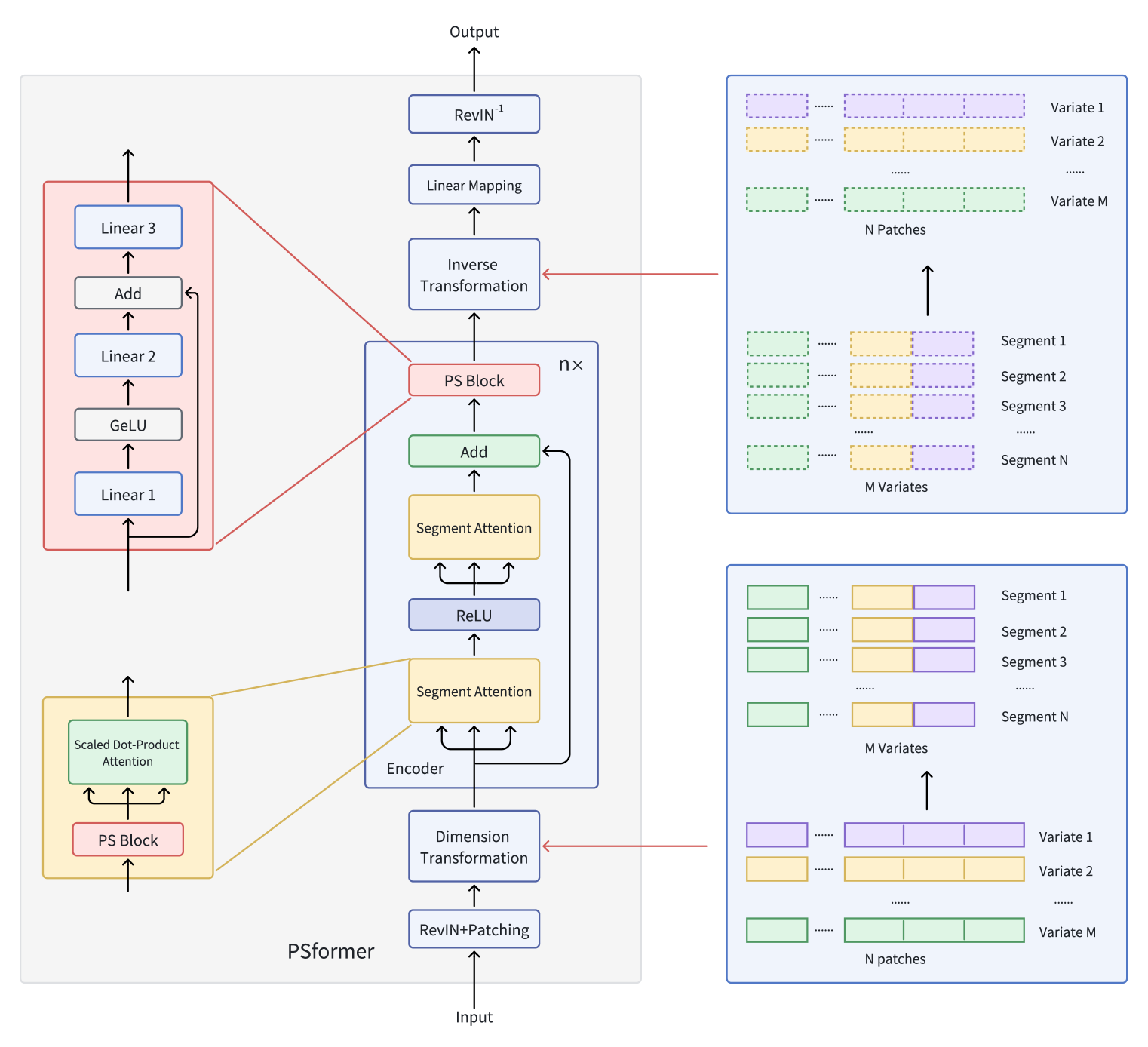
前回の記事では、提案されたアプローチの実装をMQL5を用いて開始しました。CNeuronPSBlockクラスのメソッドのアルゴリズムを検討し、パラメータ共有ブロックの機能がどのように実装されているかを確認しました。今回は作業を続け、エンコーダの機能構築に進みます。
PSformerエンコーダオブジェクトの作成
コード実装に入る前に、まずアルゴリズムについて簡単に説明します。フレームワークの著者によると、入力データは最初にRevInを通過します。ご存じの通り、RevInモジュールは2つのブロックで構成されています。モデルの入力では、生データを正規化し、出力では、以前に抽出された分布パラメータをモデルの結果に戻します。これにより、モデルの出力分布が元のデータ分布と整合するようになります。これは、時系列の将来値を予測する際に非常に重要な要素です。
本記事では前回同様、入力データの正規化のみを使用します。これは別個のバッチ正規化層として実装されます。その理由は、最終的な目的が時系列の将来値を予測することではなく、収益性の高いActor方策を学習させることだからです。モデルは一般的に正規化データでより良い性能を発揮するため、入力データを正規化します。同様の理由で、エンコーダの隠れ状態からActorに正規化データを渡すのが論理的です。そのため、エンコーダを環境内でActorと同時に学習させる場合、線形マッピングブロックやRevInの逆変換モジュールは不要になります。
もちろん、ステージ型トレーニングではマッピングブロックとRevIn逆変換モジュールが必要です。この場合、環境状態エンコーダをまず時系列の次の状態を予測するように学習させ、その後にActorとCriticモデルを別々に学習させます。しかし、この場合でも、元データのよりコンパクトで正規化された表現を含むエンコーダの隠れ状態をActorに渡す方が望ましいです。
ステージ型トレーニングには利点と欠点があります。主な利点は、エンコーダが生データで学習され、特定のタスクに縛られないため汎用性が高いことです。これにより、同じデータセットで異なる問題に対してエンコーダを再利用できます。
一方で、汎用モデルは特定のタスクに対して最適とは限らず、特定のドメイン固有のニュアンスを捉えきれない場合があります。
また、2つの別々の学習ステージは、全モデルを同時に学習させるより計算コストが高くなる可能性があります。
これらの要因を考慮し、本記事ではエンコーダアーキテクチャを簡略化しつつ、モデルを同時に学習させる方法を選択しました。
データ正規化の後、PSformerフレームワークはパッチングおよびデータ変換モジュールを適用します。著者らはかなり複雑な変換プロセスを記述していますので、これを分解してみましょう。
モデルはマルチモーダル時系列を入力として受け取ります。ここでは正規化は省略し、変換プロセスに焦点を当てます。
まず、マルチモーダル時系列はM個の単変量系列に分割されます。各単変量系列はさらに長さPのN個の等しいパッチに分割されます。次に、同一時間インデックスを持つパッチがセグメントとして結合されます。これにより、サイズM×PのN個のパッチが得られます。
本記事のケースでは、生データは解析対象データセットの履歴バーの逐次的な記述です。つまり、生データバッファには1本のバーにつきM個の記述要素が含まれ、次のバーにも同様にM個の要素が続きます。したがって、セグメントを形成するには、P本の連続するバー記述を取るだけで十分です。明らかに、追加のデータ変換は不要です。
PSformerの著者は、この生データを(M×P)×Nに変換すると説明しています。実装上は、入力データテンソルを転置するだけで同じ結果が得られます。
したがって、本記事の場合、PSformerのパッチングおよび変換ブロックは実質的に単一の転置層に簡略化されます。
次に、順次的なPSformerエンコーダ層の構築方法について重要な疑問があります。選択肢は2つです。ベースアプローチを使用し、モデルアーキテクチャの説明内で直接必要な層数を指定する方法か、内部層を必要な数だけ生成するオブジェクトを作成する方法です。
最初の方法はアーキテクチャ説明を複雑にしますが、エンコーダオブジェクトの作成を簡単にし、順次層の設定に柔軟性を持たせられます。
2番目の方法はアーキテクチャ説明を簡略化しますが、内部層がすべて同じアーキテクチャになるため、エンコーダの実装は複雑になります。
明らかに、層数が少ないモデルでは最初の方法が望ましく、層が深いモデルには2番目の方法が適しています。
判断のために、エンコーダ層数が予測精度に与える影響について元論文を参照します。PSformerの著者らは、標準のETTh1およびETTm1時系列データセットで実験をおこないました。これらのデータセットには、Transformerのデータが含まれています。各データポイントには、日付、油温、6種類の外部負荷特性など8つの特徴があります。ETTh1は1時間間隔、ETTm1は1分間隔です。結果は以下の表に示されています。

提示されたデータから、混乱度の低い時間単位のデータセットでは、最も良い結果は単一のエンコーダ層で得られたことが明らかです。一方、ノイズの多い分単位のデータセットでは、エンコーダ層を3層使用することが最適であることが分かりました。したがって、エンコーダ層を多数持つモデルを構築する必要はないと考えられます。そのため、本稿では最初の実装アプローチを採用し、エンコーダオブジェクトの構造を簡略化しつつ、モデルアーキテクチャの説明内で各エンコーダ層のパラメータを明示的に指定する方法を選択しました。
新しいCNeuronPSformerオブジェクトの完全な構造体を以下に示します。
class CNeuronPSformer : public CNeuronBaseSAMOCL { protected: CNeuronTransposeOCL acTranspose[2]; CNeuronPSBlock acPSBlocks[3]; CNeuronRelativeSelfAttention acAttention[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSformer(void) {}; ~CNeuronPSformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPSformer; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
前述したように、PSformerフレームワークはSAM最適化手法を組み込んでいます。そのため、新しいクラスは、対応する全結合層から基本機能を継承しています。
さらに、CNeuronPSformer構造体には2つのデータ転置層が含まれており、前方および逆方向のデータ変換機能を担います。
新しいクラス構造体には、3つのパラメータ共有ブロック(PSブロック)と2つのRelative Attentionモジュールが含まれ、これらには以前にSAM最適化機能を統合しました。おそらく、これは元のPSformerアルゴリズムからの最大の変更点です。
PSformerの著者は、パラメータ共有ブロックを用いてQuery、Key、Valueエンティティを生成しました。PSブロック内では、パラメータ行列のサイズはN×Nであり、これは3つのエンティティすべてに同じテンソルが使用されることを意味します。
本実装では、エンコーダアーキテクチャをやや複雑化しています。PSブロックはあくまでデータの前処理用に使用し、依存関係の分析はより高度な相対注意ブロックでおこないます。
すべての内部オブジェクトは静的として宣言されているため、コンストラクタとデストラクタを空のままにすることができます。宣言済みおよび継承されたすべてのオブジェクトの初期化は、Initメソッド内でおこないます。このメソッドのパラメータには、作成される層のアーキテクチャを完全に定義する主要な定数が含まれています。
- window:1つのシーケンス要素を表すベクトルのサイズ
- units_count:履歴データの深さ(シーケンス長)
- segments:生成されるセグメントの数
- rho:ぼかし領域係数
bool CNeuronPSformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count % segments > 0) return false;
初期化メソッド内では、まず制御ブロックを設定し、シーケンス長がセグメント数で割り切れるかを確認します。次に、同名の親クラスメソッドを呼び出し、定数のさらなる検証と継承オブジェクトの初期化をおこないます。
if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, window * units_count, rho, optimization_type, batch)) return false;
次に、単一のセグメントのサイズを決定します。
uint count = Neurons() / segments;
次に、新たに宣言された内部オブジェクトの初期化に進みます。まず、入力データ転置層を初期化します。転置後の行数はセグメント数に設定し、各行のサイズは1セグメント内の要素総数に設定します。
if(!acTranspose[0].Init(0, 0, OpenCL, segments, count, optimization, iBatch)) return false; acTranspose[0].SetActivationFunction(None);
この層には活性化関数は指定されていません。
転置層に活性化関数を指定する必要はありませんが、この層の順方向伝播アルゴリズムでは、必要に応じて元データオブジェクトの活性化関数と同期する機能が備わっています。
次に、最初のパラメータ共有ブロックを初期化します。これは、明示的なオブジェクト初期化メソッドを用いておこないます。
if(!acPSBlocks[0].Init(0, 1, OpenCL, segments, segments, units_count / segments, 1, fRho, optimization, iBatch)) return false;
次に、Attentionモジュールと残りのパラメータ共有ブロックを初期化するためのループを作成します。
for(int i = 0; i < 2; i++) { if(!acAttention[i].Init(0, i + 2, OpenCL, segments, segments, units_count / segments, 2, optimization, iBatch)) return false; if(!acPSBlocks[i + 1].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false; }
残りのパラメータ共有ブロックも、最初のPSブロックと同様に初期化され、共有パラメータバッファへのポインタやモーメントも適宜コピーされます。
次に、残差接続記録用層を初期化します。ここでは標準的な全結合層を使用しますが、中間計算結果を格納するデータバッファのみが必要だからです。
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
データのコピー操作を減らすために、この層の勾配バッファを最終Attentionモジュールの勾配バッファに置き換えます。活性化関数が同期されていることを確認します。
最後に、逆転置層を初期化します。
if(!acTranspose[1].Init(0, 5, OpenCL, count, segments, optimization, iBatch)) return false; acTranspose[1].SetActivationFunction((ENUM_ACTIVATION)acPSBlocks[2].Activation());
さらに、オブジェクトのインターフェイス用データバッファを、最終転置層の対応するバッファに置き換えます。
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
この後、初期化メソッドは完了し、呼び出し元に論理結果が返されます。
次の段階は、feedForwardメソッドで実装される順方向伝播アルゴリズムを構築することです。主な機能は以前に実装された内部オブジェクトに存在するため、このメソッドは比較的明確です。
このメソッドは、元データオブジェクトへのポインタを受け取り、すぐに内部の転置層に渡して初期変換をおこないます。
bool CNeuronPSformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Dimension Transformation if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
次に、2つのSegment Attentionブロックを反復処理します。
//--- Segment Attention CObject* prev = acTranspose[0].AsObject(); for(int i = 0; i < 2; i++) { if(!acPSBlocks[i].FeedForward(prev)) return false; if(!acAttention[i].FeedForward(acPSBlocks[i].AsObject())) return false; prev = acAttention[i].AsObject(); }
各ループ反復内で、パラメータ共有ブロックとRelative Attentionモジュールのメソッドを順番に呼び出します。
ループのすべての反復が正常に完了したら、残差接続を生データに追加し、結果を内部層バッファcResidualに保存します。
//--- Residual Add if(!SumAndNormilize(acTranspose[0].getOutput(), acAttention[1].getOutput(), cResidual.getOutput(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false;
ただし、残差接続については、変換後の生データを取得することに注意してください。つまり、転置層の後です。これにより、残りの接続のデータ構造が保持されます。
結果のデータは、最後のパラメータ共有ブロックに渡されます。
//--- PS Block if(!acPSBlocks[2].FeedForward(cResidual.AsObject())) return false;
次に、逆のデータ変換を実行します。
//--- Inverse Transformation if(!acTranspose[1].FeedForward(acPSBlocks[2].AsObject())) return false; //--- return true; }
オブジェクトのインターフェイスと最終転置層間でバッファポインタを共有しているため、逆変換の結果は直接インターフェイスバッファに書き込まれ、追加のデータコピーが不要になります。そのため、逆変換後は順方向伝播メソッドは単にブール値を呼び出し元に返すだけです。
順方向伝播が完了すると、次に逆方向伝播処理に移ります。これはcalcInputGradientsメソッドとupdateInputWeightsメソッドで実装されます。前者は誤差勾配を分配し、後者はモデルパラメータを更新します。
calcInputGradientsメソッドは元データオブジェクトへのポインタを受け取り、このオブジェクトに入力データが最終結果に与える影響を反映した誤差勾配を渡す必要があります。
bool CNeuronPSformer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
まず、受信したポインタの有効性をチェックします。無効な場合は、それ以上の処理は無意味です。このチェックを通過すると、順方向伝播の逆順で、オブジェクト内部の各層を通して誤差勾配を順次逆伝播させます。
if(!acPSBlocks[2].calcHiddenGradients(acTranspose[1].AsObject())) return false; //--- if(!cResidual.calcHiddenGradients(acPSBlocks[2].AsObject())) return false; //--- if(!acPSBlocks[1].calcHiddenGradients(acAttention[1].AsObject())) return false; if(!acAttention[0].calcHiddenGradients(acPSBlocks[1].AsObject())) return false; if(!acPSBlocks[0].calcHiddenGradients(acAttention[0].AsObject())) return false; //--- if(!acTranspose[0].calcHiddenGradients(acPSBlocks[0].AsObject())) return false;
入力データ変換層に到達した後、残差接続の勾配を加える必要があります。これは元データオブジェクトの活性化関数によって2通りの方法でおこなわれます。活性化関数が存在しない場合は、単純に2つのデータバッファの値を加算します。
if(acTranspose[0].Activation() == None) { if(!SumAndNormilize(acTranspose[0].getGradient(), cResidual.getGradient(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
活性化関数が存在する場合は、データを加算する前に、まず誤差勾配を活性化関数の導関数で調整します。
else { if(!DeActivation(acTranspose[0].getOutput(), cResidual.getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].Activation()) || !SumAndNormilize(acTranspose[0].getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
メソッドの最後に、誤差勾配を入力レベルまで伝播させるための逆変換を実行し、その後ブール値の結果を呼び出し元プログラムに返します。
if(!NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; //--- return true; }
逆伝播パスを完了するためには、予測誤差を減らすようにモデルパラメータを更新する必要があります。前述の通り、パラメータ更新にはSAM最適化手法を使用します。SAMでは、摂動を加えたモデルパラメータで2回目の順方向伝播をおこなう必要があり、これによってバッファの値が変化します。これは現在の層の処理には影響しませんが、後続層のパラメータ更新を歪める可能性があります。そのため、内部層の更新は順方向伝播の逆順でおこないます。これにより、先行層のバッファ値が変更される前に、各層ののパラメータを適切に調整できます。
bool CNeuronPSformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!acPSBlocks[2].UpdateInputWeights(cResidual.AsObject())) return false; //--- CObject* prev = acAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { if(!acAttention[i].UpdateInputWeights(acPSBlocks[i].AsObject())) return false; if(!acPSBlocks[i].UpdateInputWeights(prev)) return false; prev = acTranspose[0].AsObject(); } //--- return true; }
ファイル操作メソッドについても少し触れておきます。パラメータ共有ブロックを3つ使用しているため、同じパラメータを3回保存する必要はありません。1回保存すれば十分です。そのため、以下のようなSaveメソッドを用意しています。
このメソッドはファイルハンドルを受け取り、まず親クラスのSaveメソッドに渡します。
bool CNeuronPSformer::Save(const int file_handle) { if(!CNeuronBaseSAMOCL::Save(file_handle)) return false;
次に、パラメータ共有ブロックを1回保存します。
if(!acPSBlocks[0].Save(file_handle)) return false;
次に、ループしてAttentionモジュールと転置層を保存します。
for(int i = 0; i < 2; i++) if(!acTranspose[i].Save(file_handle) || !acAttention[i].Save(file_handle)) return false; //--- return true; }
ループが完了したら、ブール値の結果を呼び出し元に返してメソッドを終了します。
なお、保存時には残差接続層も省略しています。これは学習可能なパラメータを持たないため、この過程で情報が失われることはありません。
しかし、以前に保存したオブジェクトを復元する際には、すべてのオブジェクトの構造と機能を復元する必要があります。保存時にスキップしたオブジェクトも含まれます。そのため、オブジェクトの機能を復元するLoadメソッドを詳しく見ていくことをお勧めします。
このメソッドのパラメータとして、以前に保存されたデータを含むファイルハンドルを受け取り、受け取ったハンドルをすぐに親クラスのLoadメソッドに渡して、継承オブジェクトを復元します。
bool CNeuronPSformer::Load(const int file_handle) { if(!CNeuronBaseSAMOCL::Load(file_handle)) return false;
次に、保存されたオブジェクトを保存された順序どおりに復元します。
if(!LoadInsideLayer(file_handle, acPSBlocks[0].AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acTranspose[i].AsObject()) || !LoadInsideLayer(file_handle, acAttention[i].AsObject())) return false;
次に、保存中に失われたオブジェクトの機能を復元する必要があります。まず、パラメータ共有ブロックを復元します。1つはファイルから読み込み、残りは読み込んだブロックを基に初期化し、共有されたパラメータバッファおよびそのモーメントへのポインタをコピーすることで再構築します。
for(int i = 1; i < 3; i++) if(!acPSBlocks[i].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false;
また、残差接続記録層も初期化します。そのサイズは、最終的なRelative Attentionモジュールの出力テンソルと同じです。
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
不要なコピー操作を排除し、活性化関数を同期するために、勾配バッファポインタを置き換えます。
最後に、オブジェクトのインターフェイスバッファを最後の転置層のバッファに置き換えます。
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
メソッドは、操作の論理結果を呼び出し元に返すことで終了します。
この時点で、CNeuronPSformerエンコーダオブジェクトに関する作業は完了です。このクラスとそのすべてのメソッドの完全なコードは、添付ファイルで確認できます。
モデルアーキテクチャ
PSformerフレームワークの著者によって提案された手法を実装するオブジェクトを構築した後、学習可能なモデルのアーキテクチャの説明に進みます。まず注目するのは、提案手法を実装する環境状態エンコーダです。
環境状態エンコーダのアーキテクチャは、CreateEncoderDescriptionsメソッド内で定義されます。メソッドのパラメータには、モデルアーキテクチャの記述を記録するための動的配列オブジェクトへのポインタを渡します。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であれば動的配列の新しいインスタンスを作成します。
以前と同様に、生データ層は標準の全結合層です。そのサイズは、指定された分析深度で完全な履歴データテンソルをキャプチャするのに十分な大きさである必要があります。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
続いて、生データの初期前処理のためのバッチ正規化層が続きます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化されたデータは、その後PSformerエンコーダに渡されます。本記事では、同一のアーキテクチャを持つ3つのPSformerエンコーダ層を順に使用します。必要なエンコーダ層数を定義するために、希望するエンコーダの深さに等しい回数のループを用います。ループ本体では、各反復において1つのCNeuronPSformerオブジェクトの記述を作成します。
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } }
PSformerエンコーダの後には、1つの畳み込み層と1つの全結合層からなるマッピングブロックを適用します。すべてのニューラル層はSAM最適化に適合するように調整されています。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
環境状態エンコーダのアーキテクチャ記述が完了したら、呼び出し元に論理型の結果を返し、メソッドを終了します。
エンコーダのアーキテクチャを記述するこのメソッドの完全なコードは、添付ファイルに記載されています。また、過去の記事で紹介したActorおよびCriticモデルのアーキテクチャも変更せずに含まれています。
さらに、環境との相互作用プログラムとモデルの学習プログラムも修正なしで引き継いでおり、それらも添付ファイルに含まれています。ここからはいよいよ最終段階に進み、実際の履歴データを用いて、実装した手法の有効性を評価します。
テスト
PSformerフレームワークの著者が提案したアプローチをMQL5を使用して実装するために、かなりの作業をおこなってきました。そしていよいよ最もエキサイティングな段階である、実際の履歴データを用いた有効性の評価に入ります。
ここで強調しておきたいのは、これは私たちが実装した手法の評価であり、オリジナルの著者らが提案した手法そのものの評価ではないという点です。なぜなら、今回の実装はオリジナルのPSformerフレームワークからいくつかの点で逸脱しているからです。
モデルはEURUSDの2023年全期間にわたるH1時間枠の履歴データで学習させました。いつものように、すべてのインジケーターパラメーターはデフォルト値に設定されました。
先に述べたように、環境状態エンコーダ、Actorモデル、Criticモデルは同時に学習されました。初期学習には、過去のモデルを用いた作業中に収集したデータセットを利用し、学習の進行に合わせて定期的に更新をおこないました。
モデルの学習とデータセット更新を数回繰り返した結果、学習データセットとテストデータセットの両方で利益を生み出せる方策を獲得することができました。
学習済みActorの方策は、その他のパラメータを変更せずに、2024年1月のEURUSD履歴データでテストしました。以下にそのテスト結果を示します。
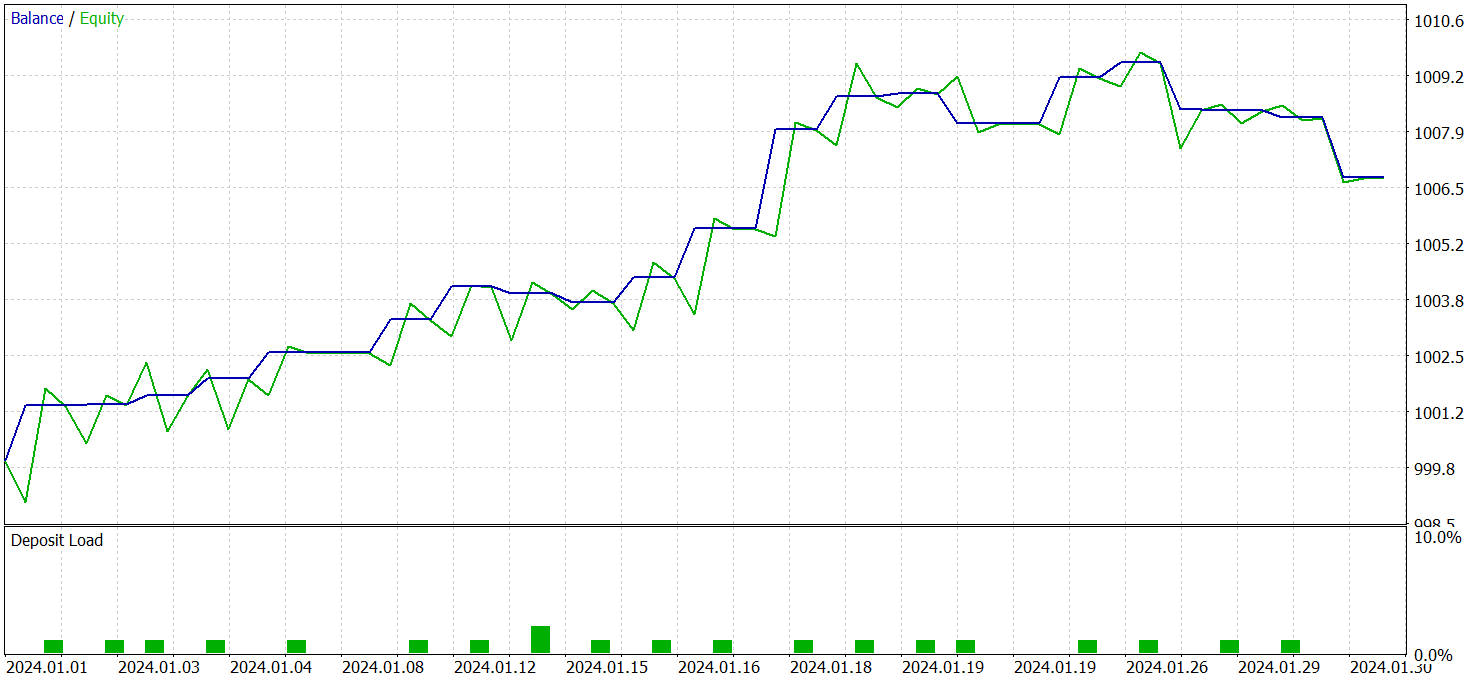
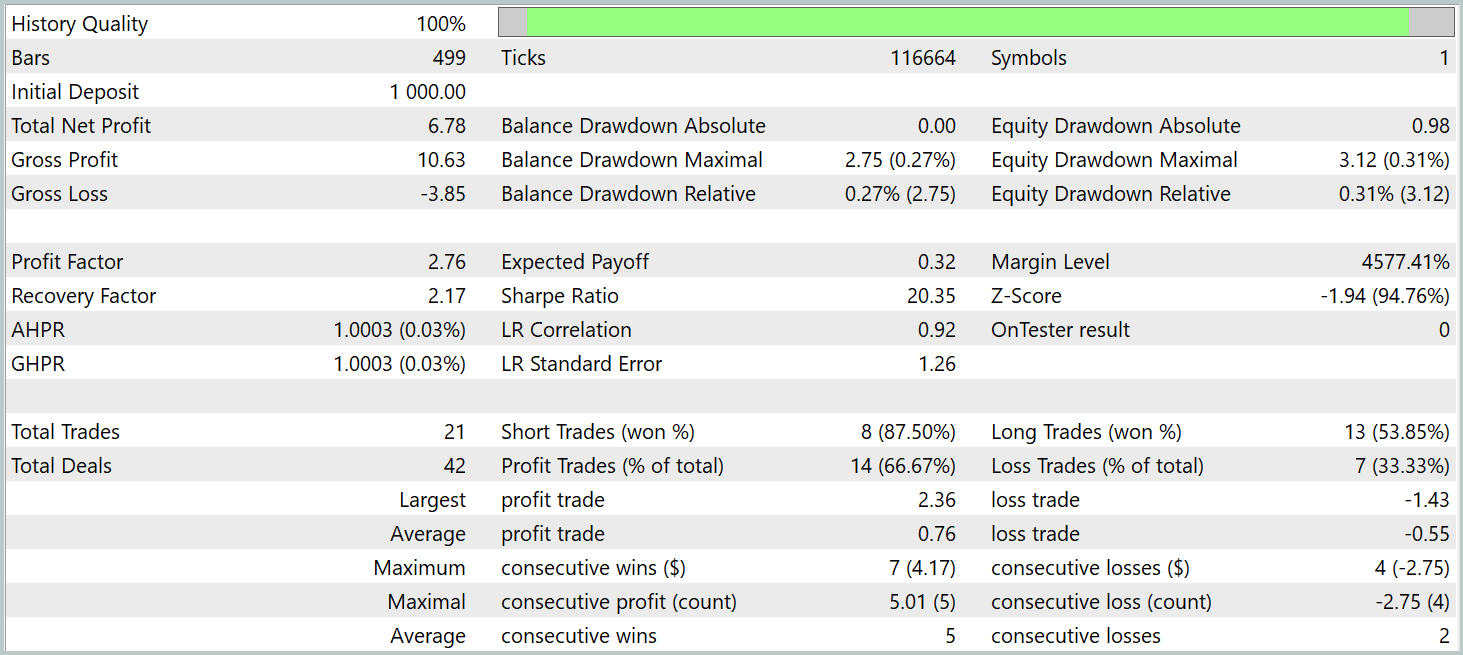
テスト期間中、モデルは21回の取引を実行し、これは1営業日あたりおよそ1回の取引に相当します。そのうち14回が利益をもたらし、割合にして66%以上でした。また、平均的な利益取引は平均的な損失取引を38%上回る結果となりました。
バランスグラフでは、月の最初の20日間にわたって明確な上昇トレンドが確認されます。
総合的に見て、この結果は有望な可能性を示しています。さらなる改良と、より大規模なデータセットでの追加学習により、このモデルは実運用トレードにも利用できると考えられます。
結論
高精度な時系列予測と効率的な計算資源の利用で注目されるPSformerフレームワークを検討しました。PSformerの主要なアーキテクチャ要素には、パラメータ共有(PS)ブロックおよびSpatial-Temporal Segmented Attention (SegAtt)機構があります。これらの要素により、局所的および大域的な時系列依存関係を効果的にモデリングし、予測精度を犠牲にすることなくパラメータ数を削減することが可能になります。。
本研究では、これらの提案手法をMQL5上で独自に解釈・実装しました。この方法を用いてモデルを学習し、学習データ外の履歴データでテストを行ったところ、学習済みモデルの明確な有用性が確認されました。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いた例収集用のEA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダ学習用EA |
| 5 | Test.mq5 | EA | モデルテスト用EA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16483
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
Research.mq5 ファイルをコンパイルすると、次のエラーが発生します。
ResearchRealORL.mq5をコンパイルすると、このエラーが発生します。
Study.mq5ファイルをコンパイルすると、このエラーが出ます。
ほとんど同じミスを繰り返しています。
Test.mq5ファイルをコンパイルすると、このエラーが発生します。
math.math/mqhファイルからエラーが出ています。何か解決策があれば、ぜひ教えてください。