
ニューラルネットワークが簡単に(第51回):Behavior-Guided Actor-Critic (BAC)

はじめに
最後の2つの記事では、Soft Actor-Criticアルゴリズムについて説明しました。覚えているとおり、このアルゴリズムは、連続行動空間で確率モデルを訓練するために使用されます。この手法の主な特徴は、報酬関数にエントロピーコンポーネントを導入することで、環境探索とモデル操作のバランスを調整できるようになります。同時に、このアプローチでは、訓練済みモデルにいくつかの制限が課されます。エントロピーを使用するには、行動を実行する確率について何らかのアイデアが必要ですが、行動の連続空間を直接計算するのは非常に困難です。
分位分布アプローチを使用しましたが、ここで、分位数分布のハイパーパラメータの調整を追加します。分位数分布を使用するというアプローチ自体が、私たちを連続的な行動空間から少し遠ざけます。結局、行動を選択するたびに、学習した確率分布から分位点を選択し、その平均値を行動として使用していました。分位数が十分に大きく、取り得る値の範囲が十分に小さい場合、連続行動空間に近づきます。しかし、これによりモデルの複雑さが増し、訓練と運用のコストが増加します。さらに、これにより、訓練済みモデルのアーキテクチャに制限が課されます。
この記事では、2021年4月に導入された代替アプローチであるBehavior-Guided Actor-Critic (BAC)について説明します。
1.アルゴリズム構築機能
まず、環境全般について学ぶ必要性について話しましょう。このプロセスが必要であることには誰もが同意すると思います。しかし、正確には何のために、どの段階ででしょうか。
簡単な例から始めましょう。同じドアが3つある部屋にいて、通りに出る必要があるとします。どうするべきでしょうか。必要なドアが見つかるまで、ドアを1つずつ開けていきます。再び同じ部屋に入ったとき、すべてのドアを開けて外に出るのではなく、すぐに既知の出口に向かうようになります。別のタスクがある場合は、いくつかのオプションが考えられます。すでに知っている出口を除くすべてのドアを再び開き、正しい出口を探すことができます。あるいは、出口を探すときに以前にどのドアを開けたか、そしてその中に必要なドアがあったかどうかを最初に思い出すことができます。正しいドアを思い出したら、そこに向かって進みます。それ以外の場合は、これまでに試したことのないドアを確認します。
結論:正しい行動を選択するには、不慣れな状況における環境を研究する必要があります。必要なルートを見つけた後、さらに環境を探索しても邪魔になるだけです。
ただし、既知の状態でタスクが変化する場合は、環境をさらに調査する必要がある場合があります。これには、より最適なルートの検索が含まれる場合があります。上の例では、これは、さらにいくつかの部屋を通過する必要がある場合、または建物の間違った側にいることに気付いた場合に発生する可能性があります。
したがって、未踏の状態では環境探査を強化し、以前に探査された状態では環境探査を最小限に抑えることを可能にするアルゴリズムが必要です。
Soft Actor-Criticで使用されるエントロピー正則化は、この要件を満たすことができますが、それには多くの条件が必要です。行動の確率が低い場合、行動のエントロピーは高くなります。実際、確率の低い行動の後に私たちが入る状態は、おそらくあまり理解されていません。エントロピーの正則化により、その後の状態をよりよく研究するために、エントロピーの正則化を繰り返すことが求められます。しかし、この動きベクトルを研究した後はどうなるでしょうか。より最適なパスが見つかった場合、モデルの訓練の過程で、行動の確率が増加し、エントロピーが減少します。これは私たちの要件を満たしています。ただし、他の行動の確率は減少し、そのエントロピーは増加します。これにより、私たちは別の方向でさらなる研究を進めることになります。この道に集中し続けることができるのは、かなりのレベルのポジティブな報酬だけです。
一方、新しいルートが要件を満たさない場合は、モデルの訓練中にそのような行動が発生する可能性を減らします。同時に、そのエントロピーはさらに増大し、それが私たちを再び同じように駆り立てるのです。重大なマイナスの報酬(罰金)だけが、私たちを再び軽率な行動から遠ざけることができます。
そのため、研究とモデルの運用の間で望ましいバランスを確保するには、温度比の重み付けを正しく選択することが非常に重要です。
これは少し奇妙に思えるかもしれません。私たちは、探索と開発の間のバランスが確率定数によって制御されるε貪欲戦略から始めました。ここで、モデルを複雑にして、比率を選択することの重要性についてもう一度話します。これは純粋な既視感です。
別の解決策を求めてBehavior-Guided Actor-Critic (BAC)(「Behavior-Guided Actor-Critic:Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning」で紹介)アルゴリズムに注目します。この方法の著者らは、状態行動ペアモデルによる学習レベルを評価するために、報酬関数のエントロピー成分を特定の値に置き換えることを提案しています。
状態と行動のペアの選択は非常に明白です。これは、特定の時点でわかっていることです。自分が特定の状態にあることに気づき、私たちは行動を選択します。次の状態への移行と、この移行に対する報酬は、ある程度それに依存します。同じ行動の背後で、予期される新しい状態への遷移が存在する場合もあれば、(ある程度の確率で)異なる状態が存在する場合もあります。たとえば、ドアを開けるには、それに近づく必要があります。ここでは、一歩ごとにドアに近づくことがかなり期待されます。次に、ドアハンドルを回して開けます。ただし、ロックされていることがわかる可能性があります(これは私たちが制御できない要因です)。ドアの外では報酬か罰金が待っています。しかし、そこに着くまではわかりません。したがって、私たちは、そこから起こり得るすべての行動を考慮することによってのみ、独立した状態の完全な研究について話すことができます。
この方法の著者らは、「状態と行動」のペアを研究するための手段としてオートエンコーダを使用することを提案しています。オートエンコーダの使用には、すでにさまざまなアルゴリズムで何度か遭遇しました。しかし、これは常にデータ圧縮や特定の相互依存モデルの構築に関連していました。経験上、金融市場のモデルを構築することは、必ずしも明白ではない影響要因が多数あるため、かなり難しい作業であることがわかっています。この場合、オートエンコーダの別のプロパティが使用されます。
純粋な形式のオートエンコーダは、ソースデータを非常によくコピーします。しかし、オートエンコーダはニューラルネットワークです。冒頭で、ニューラルネットワークは研究されたデータに対してのみ適切に機能すると言いました。さもないと、結果が予測不能になる可能性があります。このため、訓練サンプルの代表性と訓練中および操作中のモデルのハイパーパラメータの不変性に常に焦点を当てます。
この方法の作成者は、ニューラルネットワークのこの特性を利用しました。特定の状態セットと対応する行動を訓練した後、オートエンコーダの出力でそれらの適切なコピーが得られます。しかし、モデル入力で未知の「State-Action」ペアを送信するとすぐに、データコピーの誤差が大幅に増加します。別の「状態と行動」のペアの知識の尺度として使用するのはこのデータコピーの誤差です。
このアプローチには、エントロピー正則化に比べて多くの利点があります。まず、このアプローチは確率モデルと確定モデルの両方に適用できます。オートエンコーダの使用は、Actorアーキテクチャの選択には影響しません。
第2に、状態と行動のペアのインセンティブ報酬は、受け取った報酬や将来その行動を実行する可能性に関係なく、訓練とともに減少します。オートエンコーダが訓練されると、0になる傾向があり、モデルが完全に動作するようになります。
ただし、新しい状態が現れると(ニューラルネットワークの一般化能力を考慮すると、以前に研究されたものと類似していません)、環境探索モードがすぐにアクティブになります。
1つの状態と行動のペアの刺激的な報酬は、同じ状態にある別の行動の訓練の程度、パフォーマンスの確率、またはその他の要因とはまったく関係ありません。
もちろん、私たちは行動の連続空間を扱っており、モデルは得られた経験を一般化することができます。1つの「状態と行動」のペアを研究する場合、以前に得た経験を同様の状態および同様の行動に適用できます。しかし同時に、データ転送エラーも継続的に変化し、状態と行動の近接性(類似性)に依存します。
数学的には、方策訓練は次のように表すことができます。
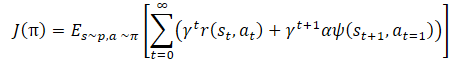
ここで、γは割引係数です。
αは温度比、
ψ(St+1,At=1)は、その後の状態の動作の関数(オートエンコーダによるコピーの誤差)です。
ここでも、モデルの探索と活用の間のバランスを調整するための温度比がわかります。これもまた、上述したハイパーパラメータ調整とモデル訓練の困難につながります。方法の作成者は、方策の訓練機能をわずかに変更することを提案しました。
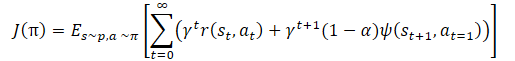
α温度比自体は次の式を使用して決定する必要があります。
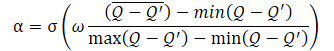
ここで、σはシグモイド関数です。
ωは10に等しく、
Qは、行動の質を評価するためのニューラルネットワークです。
ここで使用されるQニューラルネットワークはCriticに似ており、現在の方策を考慮して特定の状態における行動の品質を評価します。
提示された式からわかるように、温度比(1−α)の範囲は0から0.5です。行動の質の評価が向上すると増加します。当然、この時点では、オートエンコーダによるデータコピーの誤差は0になる傾向にあります。高い確率で、モデルは現在、ある種の極小値にあり、環境を研究することでこの状態から抜け出すことができます。
データコピーの精度が低いと、特定の状態での行動の評価の品質も低下します。これにより、シグモイド関数内の式の分母が増加します。したがって、シグモイド引数の全体の値は減少し、その結果は0.5になる傾向があります。
ここでは常に、大きい誤差から小さい誤差を減算することに注意してください。したがって、シグモイド引数は常に0より大きくなります。0で割ることはできないため、0に等しくなることはほとんどありません。
提示されたアルゴリズムは依然としてActor-Criticアルゴリズムの大きなファミリーのメンバーであり、このアルゴリズムファミリーの一般的なアプローチを使用します。Soft Actor-Criticと同様に、このアルゴリズムは、連続行動スペースでActor方策を学習するために使用されます。2つのCriticモデルを使用して、行動の品質と、報酬から行動までの誤差勾配の分布を評価します。また、ターゲットモデルのソフトアップデート、経験バッファ、およびActor-Criticモデルを訓練するためのその他の一般的なアプローチも使用します。
2.MQL5を使用した実装
提案されたアプローチの理論的側面を検討した後、MQL5を使用して実装してみましょう。まず最初にモデルのアーキテクチャから始めます。メソッドを比較できるようにするために、モデルのアーキテクチャを前の記事からあまり変更しませんでした。ただし、Actorアーキテクチャを少し単純化し、Soft Actor-Critic法から確率的Actorアルゴリズムを実装するために作成した複雑な最後のニューラル層を削除しました。ただし、確率的Actor方策の使用はそのまま残しました。しかし今回は、変分オートエンコーダの潜在状態層を使用することでそれが実現されます。覚えていらっしゃるとおり、このニューラル層の入力には、結果バッファのサイズのちょうど2倍のデータテンソルが供給されます。指定されたソースデータテンソルには、結果の各要素の分布の平均と分散が含まれています。このようにして、計算の複雑さを軽減しますが、確率的Actorモデルを連続行動空間に残します。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *autoencoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!autoencoder) { autoencoder = new CArrayObj(); if(!autoencoder) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2*NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticモデルは変更せずに転送されているため、これについては詳しく説明しません。
オートエンコーダモデルについて少し話しましょう。前述したように、オートエンコーダは、前述の「状態と行動」のペアのメモリ要素として使用されます。これは、これらのペアの訪問数のカウンターと呼ぶことができます。しかし、Criticが評価するのは「状態と行動」のペアであることを忘れないでください。より正確には、Criticは特定の状態における個々の行動を評価します。これは言葉や概念の遊びのように見えるかもしれませんが、初期データの1セットです。
以前は、モデルの訓練にかかるリソースと時間を節約するために、Criticアーキテクチャからソースデータの前処理ブロックを除外していました。代わりに、Actorモデルの非表示状態からのすでに処理されたデータを使用します。Criticの入力で、隠れた状態とActorの結果バッファを連結し、それによって状態と行動を1つのテンソルに結合します。
これからはさらに進んでいきます。Criticの1つの隠れた状態をオートエンコーダの入力としてフィードします。Criticと同様に、元のデータの2つのテンソルの連結層を使用できます。ただし、オートエンコーダ結果の1つのバッファとソースデータの2つのバッファを比較するという問題を解決する必要があります。Criticの潜在表現からのソースデータの1つのバッファを使用すると、より単純なオートエンコーダモデルを使用して、ソースデータをその作業の結果と「1:1」で比較できるようになります。したがって、オートエンコーダアーキテクチャでは完全に接続された層のみを使用します。
//--- Autoencoder autoencoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 20; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(2)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(1)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(0)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- return true; }
オートエンコーダの4番目の層以降、新しいニューラル層の記述が完全には作成されていないことに注意してください。代わりに、以前に作成した説明を逆の順序で単純にコピーしました。これにより、デコーダ内にエンコーダのミラーコピーを作成できるようになりました。エンコーダアーキテクチャの変更(新しい層の追加を除く)は、対応するデコーダ層に即座に反映されます。ニューラル層アーキテクチャの記述を同期するかなり便利な方法は、さまざまな場合に使用できます。
モデルアーキテクチャの記述を作成した後、モデルを訓練するための例のデータベースを収集するプロセスの準備に進みます。以前と同様、このプロセスは「..\BAC\Research.mq5」EAで編成されます。BACメソッドは、主要なデータ収集アルゴリズムに変更を加えません。したがって、このEAの変更は最小限でした。
モデルアーキテクチャを記述する機能を変更し、Autoencoderの記述を追加しました。したがって、Research.mq5EAのOnInitメソッドでこの関数を呼び出すときは、モデルアーキテクチャの記述の動的配列への3つのポインタを渡す必要があります。ただし、このEAではActorのみを使用し、他のモデルの記述は必要ないため、追加のオブジェクトの配列を作成せず、Criticのアーキテクチャの記述の配列を2回指定します。このような呼び出しでは、Criticのアーキテクチャの記述が最初に関数内に作成され、次にそれが削除され、オートエンコーダアーキテクチャが配列に書き込まれます。この場合、クリティカルもオートエンコーダモデルも使用されないため、これは重要ではありません。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
さらに、報酬関数からエントロピー成分を除外します。エキスパートアドバイザー(EA)の残りのコードに変更はありません。EAの完全なコードとそのすべての機能は添付ファイルにあります。
「..\BAC\Study.mq5」モデル訓練EAコードにはさらに多くの作業が必要でした。ここではすべてのモデルを使用して初期化します。したがって、モデルアーキテクチャの記述を作成するメソッドを呼び出す前に、オートエンコーダ用の追加の動的配列を作成します。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Autoencoder.Load(FileName + "AEnc.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *autoencoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
モデルのアーキテクチャを取得した後、すべてのモデルを初期化し、動作を制御します。
if(!Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Autoencoder.Create(autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
Criticのターゲットモデルを忘れないでください。
if(!TargetCritic1.Create(critic) || !TargetCritic2.Create(critic)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; } delete actor; delete critic; delete autoencoder; //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1.0f); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1.0f); }
その後、必ずすべてのモデルを1つのOpenCLコンテキストに転送してください。オートエンコーダも例外ではありません。
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Autoencoder.SetOpenCL(OpenCL);
次にモデル対応チェックブロックです。
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
ここでは、AutoencoderアーキテクチャとCriticアーキテクチャの間の一貫性のチェックを追加します。
Critic1.GetLayerOutput(1, Result); latent_state = Result.Total(); Autoencoder.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Autoencoder doesn't match latent state Critic (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
メソッドの最後に、前と同様に補助バッファを初期化し、モデル訓練イベントを呼び出します。
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
温度比の動的計算機能の動作の質を評価するための追加モデルを作成していないことに気付くかもしれません。このモデルの機能がCriticの動作に似ていることは強調しました。全体的な訓練プロセスを簡素化するために、温度比の動的な計算を実装する際にCriticのモデルを使用します。
モデルを作成した後、訓練済みモデルをEAのOnDeinit初期化解除メソッドで保存することを忘れないでください。ここでは、すべてのモデルの保存と、ファイル名の接尾辞とダウンロード中に指定された対応するモデルに注意を払います。
void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Autoencoder.Save(FileName + "AEnc.nnw", Autoencoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
この時点で準備作業は完了し、EAのTrainメソッドでの直接モデル訓練アルゴリズムの実装に進むことができます。
このメソッドの始まりは非常に標準的です。前と同様に、EAの外部パラメータで指定された反復数で訓練サイクルを調整します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
ループの本体では、サンプルデータベースから軌道と特定の軌道ステップをランダムに決定します。次に、後続の状態に関する情報をデータバッファに読み込みます。
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
次に、Actorモデルと2つのターゲットCriticモデルのフォワードパスを実行し、更新されたActor戦略を考慮して将来の状態の値を決定します。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1]);
一見したところ、すべてはSoft Actor-Criticアルゴリズムを使用した場合と同じです。また、2つのCriticから受け取った最低限の状態の評価も使用します。ただし、エントロピーコンポーネントが除外されていることに注意してください。BACメソッドの使用を考慮すると、これは非常に論理的です。ただし、動作コンポーネントは追加していません。これは、元のアルゴリズムから意図的に逸脱したものです。実際には、さまざまな方策を持つActorのパスの結果として取得された例のデータベースを使用しています。ここで動作コンポーネントを導入すると、Criticの評価は歪められますが、行為者を直接刺激することはありません。その後、Criticの評価に基づいてActorが訓練されるときに、Actorの間接的な刺激を受け取ります。ただし、もう1つの側面があります。Criticを訓練するときに「State-Action」ペアが使用される回数と、Actorを訓練するときに同じまたは類似の「State-Action」ペアが使用される回数の間にはどのような対応があるでしょうか。どちらか一方の方向に偏りが生じる可能性があります。そこで、Actorを訓練するときにオートエンコーダを使用して状態と行動を推定することにしました。私の意見では、これにより、行動方策の更新を考慮して、状態への訪問頻度とActorが使用する行動をより正確に評価できるようになります。
次の段階はCriticを訓練することです。選択した状態のデータをサンプルデータベースからデータバッファに読み込みます。
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); Account.BufferWrite();
次に、Actorのダイレクトパスを実行します。この場合、環境状態に関する初期データの事前処理に使用していることを思い出してください。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、Criticのフォワードパスとバックワードパスを実行してパラメータを調整する必要があります。Soft Actor-Critic法を使用してモデルを訓練するときは、モデルの代替を使用しました。この場合、同じ例を使用して両方のCriticを同時に訓練します。サンプルデータベースから行動に対してCriticのダイレクトパスメソッドを呼び出します。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ただし、リバースパスを実行する前に、報酬関数の動作コンポーネントの温度比を計算するためのデータを準備します。まず、最初のCriticの推定結果と上記で計算された将来状態推定値を比較し、最小、最大、平均誤差値を更新します。
最初の反復では、現在の誤差を3つの変数すべてに転送するだけであることに注意してください。次に、比較結果に基づいて最大値と最小値を更新します。次に、指数平均を計算します。
Critic1.getResults(Result); float error = reward - Result[0]; if(iter == 0) { MaxCriticError = error; MinCriticError = error; AvgCriticError = error; } else { MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error; }
2番目のCriticについては、変数の初期値がすでにあります。モデルの訓練の反復に関係なく、それらの値を更新します。
Critic2.getResults(Result); error = reward - Result[0]; MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error;
Criticのパラメータの更新の最後に、ターゲットモデルからの将来の状態の最小推定値を参照値として示す、両方のモデルのバックワードパスを実行するだけです。
Result.Update(0, reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
これでCriticのパラメータの更新が完了し、Actorの訓練に進みます。Actorを訓練するためのBACメソッドの作成者は、選択した行動の最小限の評価でCriticを使用することを推奨しています。2つのCriticを介してダイレクトパスを実行し、その結果を比較することを避けるために、少し異なる方法で実行します。状態と行動の評価を予測する際の平均誤差が最小のCriticを採用します。この値は、Criticモデルのリターンパスごとに再推定されます。その抽出に必要なコストは最小限であり、モデルを介してダイレクトパスを実行する場合に比べて無視できます。
1つ目と2つ目のCriticモデルに対する行動の繰り返しによる複雑な分岐構造の作成を避けるために、目的のモデルへのポインタをローカル変数に保存するだけです。次に、このローカル変数を操作します。
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
TD3とは異なり、Actor-Critic法は反復ごとにActor方策を更新します。Criticを訓練するために選択したのと同じ初期データのセットを使用します。Criticの訓練中に、現在の初期データセットを使用してActorのダイレクトパスをすでに実行していることを思い出してください。したがって、方策の更新を考慮して、現在の状態でのActorの行動を評価するには、選択したCriticのダイレクトパスを実行するだけで十分です。
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Autoencoder.feedForward(critic, 1, NULL, -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Criticのフォワードパスの後、Autoencoderのフォワードパスを実行します。ここにニュアンスがあります。実際には、以前に2つのモデルを1つの全体にリンクする際に、後続のモデルのソースデータ層を、これらのソースデータを提供するモデルの潜在層へのポインタで置き換える処理を追加しました。これは、1つのActorを2つのCriticのドナーとして使用する場合にうまく機能します。最初の反復中に、Criticは不要なソースデータ層を削除し、Actorの潜在状態層へのポインタを保存します。自動エンコーダの場合は、逆の状況になります。1つの自動エンコーダのドナーとして2つのCriticモデルを使用します。最初の反復で、オートエンコーダは元のデータの不要な層を削除し、使用されたCriticの潜在層へのポインタを保存します。ただし、Criticを変更すると、あるCriticの層が削除され、別のCriticの層へのポインタが保存されます。このプロセスは非常に望ましくないものです。さらに、それは訓練全体に悪影響を及ぼします。したがって、ソースデータ層を最初に削除した後、ニューラル層配列を更新するときにオブジェクト削除フラグを無効にする必要があります。
bool CNet::feedForward(CNet *inputNet, int inputLayer = -1, CNet *secondNet = NULL, int secondLayer = -1) { ........ ........ //--- if(layer.At(0) != neuron) if(!layer.Update(0, neuron)) { if(del_second) delete second; return false; } else layer.FreeMode(false); //--- ........ ........ //--- return true; }
これは訓練プロセスとBACアルゴリズムからわずかに逸脱していますが、プロセス設計の実装にとっては重要です。
モデルの訓練メソッドのアルゴリズムに戻りましょう。オートエンコーダのダイレクトパスの後、データコピーの誤差を評価する必要があります。これをおこなうために、オートエンコーダの結果とCriticの潜在状態からの初期データを読み込みます。コードの効率を高めるために、両方のデータバッファが読み込まれるベクトル変数を使用します。
Autoencoder.getResults(AutoencoderResult);
critic.GetLayerOutput(1, Result);
Result.GetData(CriticResult);
ここでは、Criticによる行動の評価の結果をすぐにアップロードします。
critic.getResults(Result);
Actor方策を訓練するときにターゲット値を決定するには、両方の情報ストリームが必要です。したがって、計算全体を1つのブロックに結合します。
前回、温度比を計算するためのデータを用意しました。ここで、最初にシグモイド引数を計算します。次に、関数の値を決定し、それを1から減算します。
float alpha = (MaxCriticError == MinCriticError ? 0 : 10.0f * (AvgCriticError - MinCriticError) / (MaxCriticError - MinCriticError)); alpha = 1.0f / (1.0f + MathExp(-alpha)); alpha = 1 - alpha; reward = Result[0]; reward = (reward > 0 ? reward + PoliticAdjust : PoliticAdjust); reward += AutoencoderResult.Loss(CriticResult, LOSS_MSE) * alpha;
次に、TD3のアプローチと同様に、Actorパラメータを運用の収益性を高める方向にシフトします。したがって、行動の現在の評価に小さな定数を追加し、収益性の向上に向けた勾配の変化を刺激します。
ターゲット値の形成を完了するには、オートエンコーダの損失関数を考慮して動作コンポーネントを追加します。ベクトル演算のおかげで、損失関数のサイズは、データバッファのサイズに関係なく、文字通り単一の文字列で定義されます。
ここで、ターゲット値を生成した後、行動とその後のActorのパラメータの調整の前に、CriticとActorのリバースを実行してエラー勾配を分散できます。
前と同様に、CriticとActorのパラメータの相互調整を防ぐために、リバースパスを実行する前に、Criticの訓練モードをオフにし、操作の実行後に再びオンにします。
Result.Update(0, reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Actorに対して2種類のバックパスを実行していることに注意してください。まず、誤差勾配をデータ前処理ユニット全体に分散します。これにより、Criticの要件に基づいて畳み込み層のフィルターを微調整できるようになります。次に、特定の行動を選択する際の意思決定ブロックを調整するために、リバースパスを実行します。この順序で操作を実行することが非常に重要です。意思決定ブロックのパラメータを調整した完全なフォワードパスの後、データ予備処理ブロックの誤差勾配も書き換えられます。この場合、追加のリターンパスを呼び出してもプラスの効果はありません。さらに、悪影響を与える可能性もあります。
この段階で、CriticパラメータとActorパラメータを更新しています。しなければならないのは、自動エンコーダのパラメータを更新することだけです。ここではすべてが非常に簡潔です。Criticの潜在状態データを参照値として渡し、モデルを介してバックワードパスを実行します。
//--- Autoencoder study Result.AssignArray(CriticResult); if(!Autoencoder.backProp(Result, critic, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
訓練サイクルの反復の最後に、両方のCriticのターゲットモデルを更新し、訓練の進行状況をユーザーに通知します。
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練方法の最後は非常に一般的なものです。
- コメント欄をクリア
- 訓練結果を表示
- EAの作業の終了を初期化
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
訓練EAの完全なコードと使用されるすべてのプログラムは添付ファイルにあります。ここには、テストEAのコードも含まれています。これは、前の記事からほとんど変更せずに引き継がれています。EAコードでは、通過した軌跡を維持しながらエントロピーコンポーネントのみが削除されています。
これでEAの構築作業は完了し、実行された作業のテストとモデルの訓練に進みます。
私の意見では、この作業により、メインメモリとOpenCLコンテキストの間でかなり多くの回数のデータ交換が繰り返されました。これは、報酬関数の動作コンポーネントを決定するブロックで顕著です。ここで考えるべきことがあります。これがモデル訓練の全体的なパフォーマンスにどのような影響を与えるかを見てみましょう。
3.検証
行動誘導ActorCriticアルゴリズムの実装に関して非常に素晴らしい作業をおこなってきました。そして今度は結果を確認するときが来ました。以前と同様に、モデルは2023年の最初の5か月間EURUSD H1で訓練されました。すべての指標パラメータがデフォルトで使用されます。初期残高は10,000米ドルです。
最初の段階では、300個のランダムパスの訓練セットが作成され、75万を超える個別のセットの「状態 → 行動 → 新しい状態 → 報酬」データが得られました。ここで「ランダムパス」について言及したことに注意してください。この段階では事前訓練済みモデルはありません。ストラテジーテスターをパスするたびに、「..\BAC\Research.mq5」EAは新しいモデルを生成し、それにランダムなパラメータを入力します。したがって、そのようなモデルの動作はパラメータと同様にランダムになります。この段階では、サンプルをデータベースに保存するためのパスの最小収益性のレベルを制限しませんでした。
サンプルを収集した後、モデルの初期訓練を実行します。これをおこなうには、「..\BAC\Study.mq5」EAを500,000回反復してモデル訓練を実行します。
モデルの最初の訓練の後、Actorの方策の確率性が非常に強く感じられると言わざるを得ません。これは、個々のパスの結果の広範な広がりに反映されています。
第2段階では、パラメータを完全に検索して、ストラテジテスターの最適化モードで300回の反復で訓練データ収集EAを再起動します。今回は、最小収益レベルをプラスの結果(0またはわずかに高い)に制限します。その結果、比較的少数の結果が追加されました(15~20パス)。
初期訓練後にデータ収集EAを実行する場合、すべてのパスで同じ事前訓練済みモデルが使用されることに注意してください。結果の広がり全体は、Actorの方策の確率論によるものです。
次に、モデルの訓練プロセスを同じ500,000回繰り返し実行します。
サンプルの収集とモデルの訓練は、目的の結果が得られるまで数回繰り返されるか、サンプルの収集とモデルの訓練の次の反復で進歩が得られない場合は極小値に達します。
以前に収集されたパスは、サンプルデータベースコレクションEAの次回の実行時に削除されないことに注意してください。新しいものはファイルの最後に追加されます。MaxReplayBuffer定数が「..\BAC\Trajectory.mqh」ファイルに追加され、大きすぎる例のデータベースが蓄積されるのを防ぎます。この定数は、パスの最大数を指定します(ファイルサイズではありません)。バッファがいっぱいになると、古いパスが削除されます。この定数を使用して、機器の技術的能力に応じてサンプルデータベースのサイズを調整することをお勧めします。
#define MaxReplayBuffer 500
サンプルデータベースの更新とモデルの訓練を7回ほど繰り返した後、訓練時間間隔で利益を生み出すことができるモデルを取得することができました。提示されたグラフは、資本増加の傾向を明確に示しています。ただし、不採算分野も存在します。


5か月の訓練期間にわたって、EAは株式の最大ドローダウン8.41%で16%の利益を獲得しました。バランスシートでは、ドローダウンはわずかに低くなり、6.68%となりました。合計99件の取引がおこなわれ、そのうち51.5%が利益を上げて終了しました。利益を上げた取引の数は、利益を出さなかった取引の数とほぼ同じです。ただし、勝ち取引の平均は負け取引の平均よりも50%近く大きくなります。プロフィットファクターは1.53で、回収率指標もほぼ同水準となりました。
ただし、ストラテジーテスターだけでなく、将来使用できるようにモデルを訓練します。したがって、訓練セット外のデータでモデルをテストすることは、私たちにとってより重要です。2023年6月の履歴データで同じモデルをテストしました。他のすべてのテストパラメータは変更されませんでした。


新しいデータでモデルをテストした結果は、訓練セットの結果と同等です。EAは1か月で3%を少し超える利益を上げました。これは、訓練サンプルの5か月での16%に匹敵します。11件の取引がおこなわれましたが、これは訓練サンプルの対応する指標よりも低かったです。残念ながら、収益性の高い取引の割合も訓練サンプルよりも低く、わずか36.4%でした。ただし、利益を上げた取引の平均は、損失を出した取引の平均のほぼ6倍です。おかげでプロフィットファクターは3.12まで上昇しました。
結論
この記事では、行動誘導ActorCriticモデルを訓練するための別のアルゴリズムを検討しました。Soft Actor-Critic法と同様、これはActor-Criticアルゴリズムの大きなファミリーに属し、Soft Actor-Critic法の使用に代わるものです。考慮されたアルゴリズムの利点には、連続行動空間で確率モデルと確定モデルの両方を訓練できる機能が含まれます。この手法の使用には、訓練済みモデルの構築に制限はありません。
この記事の実践的な部分では、提案されたアルゴリズムはMQL5を使用して実装されました。実装の効率はテスト結果によって確認されます。
もう一度言っておきますが、紹介されているプログラムはすべて、テクノロジーの使用の可能性を示しているだけです。実際の金融市場で使用する準備はできていません。EAは、実際の市場で発売される前に、改良し、追加のテストをおこなう必要があります。
リンク
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13024
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
<3
ありがとうございます。
皆さん、こんにちは。私はこのバージョンを持っていますが、3-4サイクル(データベース収集-トレーニング-テスト)した後、テストではただの直線を与えるようになりました。取引は開きません。トレーニングはすべての回500 000反復を行った。そして2-3サイクルの間、両方の批評家の誤差は0になります。そしてテストでは、Test.mqhは直線を与え、取引はありません。Research.mqhのパスには、負の利益と取引のパスがあります。また、取引がなく結果がゼロのパスもある。1つのサイクルでプラスの結果が出たパスは5つしかなかった。
全般的におかしい。すべての記事でドミトリーの指示通りに厳しくトレーニングしているのに、どの記事からも結果を得ることができない。何が間違っているのか理解できない。
新しい記事Neural networks made easy (Part 51): Behavioral Actor-Criticism (BAC) が掲載されました:
著者ドミトリー・ギズリク
zip圧縮されたフォルダをダウンロードしたのですが、中に他のフォルダがたくさんありました。
可能であれば、デプロイとトレーニングの方法を説明してほしいです。
本当におめでとうございます!
ありがとうございました。