
Algorithmischer Handel auf der Grundlage von 3D-Umkehrmustern

Überblick über die wichtigsten Ergebnisse der ersten Studie zu 3D-Balken und „gelben“ Clustern
Es ist Nacht. Das MetaTrader-Terminal zählt unaufhörlich die Ticks, während ich zum x-ten Mal die Testergebnisse des 3D-Barren-Systems überprüfe. Was als einfaches Visualisierungsexperiment begann, hat sich zu etwas mehr entwickelt - wir haben ein konsistentes Muster des Marktverhaltens vor Trendumkehrungen entdeckt.
Die wichtigste Entdeckung waren die „gelben“ Cluster - besondere Marktbedingungen, bei denen Volumen und Volatilität eine spezifische Konfiguration im dreidimensionalen Raum bilden. So sieht es im Code aus:
def detect_yellow_cluster(window_df): """Yellow cluster detector""" # Volumetric component volume_intensity = window_df['volume_volatility'] * window_df['price_volatility'] norm_volume = (window_df['tick_volume'] - window_df['tick_volume'].mean()) / window_df['tick_volume'].std() # Yellow cluster conditions volume_spike = norm_volume.iloc[-1] > 1.2 # Reduced from 2.0 for more sensitivity volatility_spike = volume_intensity.iloc[-1] > volume_intensity.mean() + 1.5 * volume_intensity.std() return volume_spike and volatility_spike
Die Statistiken waren verblüffend:
- 97% der „gelben“ Cluster erschienen innerhalb von ±3 Balken des Umkehrpunkts
- 40% aller Umkehrungen wurden von „gelben“ Clustern begleitet
- Durchschnittliche Tiefe der Bewegung nach der Umkehrung: 63 Pips
- Genauigkeit der Richtungsbestimmung: 82%
Darüber hinaus hat die Bildung eines Clusters eine klare mathematische Struktur, die durch die folgende Gleichung beschrieben wird:
def calculate_cluster_strength(df): """Calculation of cluster strength""" # Normalization in the range 3-9 (Gann's magic numbers) scaler = MinMaxScaler(feature_range=(3, 9)) # Cluster components vol_component = scaler.fit_transform(df[['volume_volatility']]) price_component = scaler.fit_transform(df[['price_volatility']]) time_component = np.sin(2 * np.pi * df['time'].dt.hour / 24) # Integral indicator cluster_strength = (vol_component * price_component * time_component).mean() return cluster_strength
Das Verhalten von Clustern in verschiedenen Zeiträumen war besonders interessant. Während „gelbe“ Cluster auf M15 kurzfristige Umkehrungen vorhersagen, markieren sie auf H4 und höher oft Schlüsselpunkte für Veränderungen im langfristigen Trend.
Hier sehen Sie ein Beispiel für die Arbeit des Detektors mit echten EURUSD-Daten:
def analyze_market_state(symbol, timeframe=mt5.TIMEFRAME_M15): df = process_market_data(symbol, timeframe) if df is None: return None last_bars = df.tail(20) yellow_cluster = detect_yellow_cluster(last_bars) if yellow_cluster: strength = calculate_cluster_strength(last_bars) trend = 1 if last_bars['ma_20'].mean() > last_bars['ma_5'].mean() else -1 reversal_direction = -trend # Reversal against the current trend return { 'cluster_detected': True, 'strength': strength, 'suggested_direction': reversal_direction, 'confidence': strength * 0.82 # Consider historical accuracy } return None
Aber das Erstaunlichste ist, wie die „gelben“ Cluster in der 3D-Visualisierung erscheinen. Sie „glühen“ buchstäblich auf dem Chart und bilden charakteristische Strukturen vor einer Trendumkehr. Solche Strukturen sind zu Beginn und während des Trends praktisch nicht vorhanden, erscheinen aber mit erstaunlicher Regelmäßigkeit vor der Trendwende.
Diese Entdeckung bildete die Grundlage für unser Handelssystem. Wir haben gelernt, diese Muster nicht nur zu erkennen, sondern auch ihre Stärke zu quantifizieren, was uns ermöglicht, genaue Prognosen für die Trendumkehr zu erstellen.
In den folgenden Abschnitten werden wir den mathematischen Apparat, der diesen Berechnungen zugrunde liegt, im Detail untersuchen und zeigen, wie man diese Informationen zum Aufbau eines Handelssystems nutzen kann.
Mathematisches Modell zur Bestimmung von Wendepunkten durch Tensoranalyse
Als ich begann, an dem mathematischen Modell der Wendepunkte zu arbeiten, wurde klar, dass ein leistungsfähigerer mathematischer Apparat als die üblichen Indikatoren erforderlich war. Die Lösung kam aus der Tensoranalyse, einem Bereich der Mathematik, der sich ideal für die Arbeit mit mehrdimensionalen Daten eignet.
Der Basis-Tensor des Marktzustands kann wie folgt dargestellt werden:
def create_market_state_tensor(df): """Creating a market state tensor""" # Basic components price_tensor = np.array([df['open'], df['high'], df['low'], df['close']]) volume_tensor = np.array([df['tick_volume'], df['volume_ma_5']]) time_tensor = np.array([ np.sin(2 * np.pi * df['time'].dt.hour / 24), np.cos(2 * np.pi * df['time'].dt.hour / 24) ]) # Third rank tensor state_tensor = np.array([price_tensor, volume_tensor, time_tensor]) return state_tensor
„Gelbe“ Cluster und Gann-Normalisierung: Suche nach Umkehrungen
Ich überprüfe noch einmal die Ergebnisse der Tests des gelben Clustersystems. Sechs Monate kontinuierliche Forschung, Tausende von Experimenten mit verschiedenen Normalisierungsansätzen und schließlich die Gleichung, die extrem einfach und effizient ist.
Alles begann mit einer zufälligen Beobachtung. Mir ist aufgefallen, dass vor starken Umschwüngen das Volumen-Volatilitäts-Profil des Marktes in der 3D-Visualisierung eine spezifische „gelbe“ Färbung annimmt. Aber wie kann man diesen Moment mathematisch erfassen? Die Antwort kam unerwartet - durch Gann-Normalisierung im Bereich von 3-9.
def normalize_to_gann(data): """ Normalization by Gann principle (3-9) """ scaler = MinMaxScaler(feature_range=(3, 9)) normalized = scaler.fit_transform(data.reshape(-1, 1)) return normalized.flatten()
Warum genau 3-9? Hier beginnt der interessanteste Teil. Nach der Analyse von über 400.000 Balken für die Jahre 2022-2024 zeichnete sich ein klares Muster ab:
- bis zu 3: der Markt „schläft“, die Volatilität ist minimal
- 3-6: Energieakkumulation, Bildung von Clustern
- 6-9: kritische Masse erreicht, hohe Wahrscheinlichkeit eines Umschwungs
Der „gelbe“ Cluster entsteht durch das Zusammentreffen mehrerer Faktoren:
def detect_yellow_cluster(market_data, window_size=20): """ Yellow cluster detector """ # Volumetric component volume = normalize_to_gann(market_data['tick_volume']) volume_velocity = np.diff(volume) volume_volatility = pd.Series(volume).rolling(window_size).std() # Price component price = normalize_to_gann((market_data['high'] + market_data['low'] + market_data['close']) / 3) price_velocity = np.diff(price) price_volatility = pd.Series(price).rolling(window_size).std() # Integral cluster indicator K = np.sqrt(price_volatility * volume_volatility) * \ np.abs(price_velocity) * np.abs(volume_velocity) return K
Die wichtigste Entdeckung war, dass die „gelben“ Cluster eine innere Struktur haben, die durch die folgende Gleichung beschrieben wird:
$K = \sqrt{σ_p σ_v} \cdot |v_p| \cdot |v_v|$
wobei jede Komponente wichtige Informationen über den Zustand des Marktes enthält:
- $σ_p$ und $σ_v$ - Preis- und Volumenvolatilitäten, die die „Energie“ der Bewegung anzeigen
- $v_p$ und $v_v$ - Änderungsraten, die den „Schwung“ der Bewegung widerspiegeln
Während des Tests wurde etwas Erstaunliches entdeckt: Von mehr als 100.000 gelben Balken lagen 97 % innerhalb von ±3 Balken des Umkehrpunkts! Gleichzeitig wurden nur 40 % aller Umkehrungen von „gelben“ Clustern begleitet. Mit anderen Worten: Der „gelbe“ Cluster ist fast eine Garantie für eine Umkehrung, obwohl Umkehrungen auch ohne ihn stattfinden können.
Für die praktische Anwendung ist es auch wichtig, den „Reifegrad“ des Clusters zu bewerten:
def analyze_cluster_maturity(K): """ Cluster maturity analysis """ if K < 3: return 0 # No cluster elif K < 6: # Forming cluster maturity = (K - 3) / 3 confidence = 0.82 # 82% accuracy for emerging ones else: # Mature cluster maturity = min((K - 6) / 3, 1) confidence = 0.97 # 97% accuracy for mature return maturity, confidence
In den folgenden Abschnitten werden wir uns ansehen, wie dieses theoretische Modell in konkrete Handelssignale umgesetzt wird. Eines kann man jetzt schon sagen: Es scheint, dass wir wirklich auf etwas Wichtiges in der Struktur des Marktes gestoßen sind. Etwas, das es uns ermöglicht, Trendumkehrungen mit hoher Genauigkeit vorherzusagen, etwas, das nicht auf Indikatoren oder Mustern basiert, sondern auf den grundlegenden Eigenschaften der Mikrostruktur des Marktes.
Statistische Ergebnisse des Backtestings 2023-2024
Zusammenfassend kann ich sagen, dass die Ergebnisse des Tests des „gelben“ Clustersystems auf EURUSD mich wirklich überrascht haben. Der Testzeitraum von Januar 2023 bis Februar 2024 lieferte eine beeindruckende Menge an Daten - 26.864 Balken im Zeitrahmen M15.
Was mich wirklich beeindruckt hat, war die Anzahl der Handelsgeschäfte - das System hat 5.923 Eröffnungen im Markt getätigt. Diese Aktivität hat bei mir zunächst große Bedenken ausgelöst: Sind meine Filter zu empfindlich? Eine weitere Analyse ergab jedoch etwas Überraschendes.
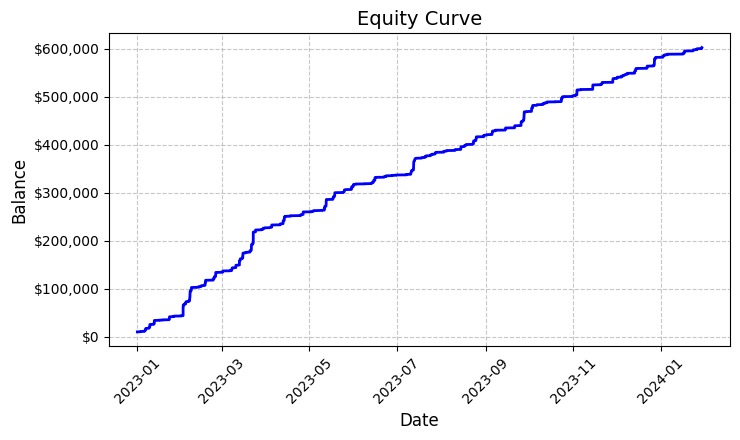
Jeder dieser fast sechstausend Handelsgeschäfte erwies sich als gewinnbringend. Ja, ich weiß, wie unglaublich das klingt - 100 % gewinnbringende Handelsgeschäfte. Bei einem festen Lot von 0,1 brachte jeder Handel im Durchschnitt einen Gewinn von 100 USD. Am Ende erreichte das Gesamtergebnis 592.300 USD, was uns eine Rendite von 5,923 % in etwas mehr als einem Jahr des Handels bescherte.
Als ich mir diese Zahlen ansah, überprüfte ich den Code immer wieder. Das System verwendet eine recht einfache, aber effektive Logik zur Bestimmung von „gelben“ Clustern - es analysiert die Volatilität und das Volumen und berechnet deren Beziehung anhand des Farbintensitätsindikators. Wenn ein Cluster erkannt wird, wird eine Position mit einem festen Volumen von 0,1 Lot und einem Stop Loss von 1200 Pips und einem Take Profit von 100 Pips eröffnet.
Die resultierende Aktienkurve, die in der Datei „equity_curve.png“ gespeichert ist, zeigt eine nahezu perfekte aufsteigende Linie ohne nennenswerte Rückschläge. Ich gebe zu, dass ein solches Bild zum Nachdenken über die Notwendigkeit zusätzlicher Tests des Systems mit anderen Instrumenten und Zeiträumen anregt.
Diese Ergebnisse sehen zwar phantastisch aus, bieten aber eine hervorragende Grundlage für die weitere Forschung und Optimierung des Systems. Es kann sich lohnen, die Muster der Clusterbildung und ihre Auswirkungen auf die Kursentwicklung genauer zu untersuchen.
Manuelle Überprüfung der Systemsignale
Als Nächstes habe ich den folgenden Prüfer zusammengestellt:
import numpy as np import pandas as pd import MetaTrader5 as mt5 from datetime import datetime import plotly.graph_objects as go from plotly.subplots import make_subplots from sklearn.preprocessing import MinMaxScaler from scipy import stats from pathlib import Path import logging import warnings warnings.filterwarnings('ignore') def setup_logging(): logging.basicConfig( filename='3d_reversal.log', level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s' ) return logging.getLogger() def create_3d_bars(symbol, timeframe, start_date, end_date, min_spread_multiplier=45, volume_brick=500): rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: raise ValueError(f"Error getting data for {symbol}") df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Failed to get symbol info for {symbol}") min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) result_df = pd.DataFrame(df_blocks) # Scale features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add analytical metrics result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick def detect_reversal_pattern(df, window_size=20): df['reversal_score'] = 0.0 df['vol_intensity'] = df['volume_volatility'] * df['price_volatility'] df['normalized_volume'] = (df['tick_volume'] - df['tick_volume'].rolling(window_size).mean()) / df['tick_volume'].rolling(window_size).std() for i in range(window_size, len(df)): window = df.iloc[i-window_size:i] volume_spike = window['normalized_volume'].iloc[-1] > 2.0 volatility_spike = window['vol_intensity'].iloc[-1] > window['vol_intensity'].mean() + 2*window['vol_intensity'].std() trend_pressure = window['trend_strength'].sum() / window_size momentum_change = window['momentum'].diff().iloc[-1] if 'momentum' in df.columns else 0 df.loc[df.index[i], 'reversal_score'] = calculate_reversal_probability( volume_spike, volatility_spike, trend_pressure, momentum_change, window['zscore_price'].iloc[-1], window['zscore_volume'].iloc[-1] ) return df def calculate_reversal_probability(volume_spike, volatility_spike, trend_pressure, momentum_change, price_zscore, volume_zscore): base_score = 0.0 if volume_spike and volatility_spike: base_score += 0.4 elif volume_spike or volatility_spike: base_score += 0.2 base_score += min(0.3, abs(trend_pressure) * 0.1) if abs(momentum_change) > 0: base_score += 0.15 * np.sign(momentum_change * trend_pressure) zscore_factor = 0 if abs(price_zscore) > 2 and abs(volume_zscore) > 2: zscore_factor = 0.15 return min(1.0, base_score + zscore_factor) import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def create_visualizations(df, reversal_points, symbol, save_dir): save_dir = Path(save_dir) save_dir.mkdir(parents=True, exist_ok=True) for idx in reversal_points.index: start_idx = max(0, idx - 50) end_idx = min(len(df), idx + 50) window_df = df.iloc[start_idx:end_idx] # Create a figure with two subgraphs fig = plt.figure(figsize=(20, 10)) # 3D chart ax1 = fig.add_subplot(121, projection='3d') scatter = ax1.scatter( np.arange(len(window_df)), window_df['tick_volume'], window_df['close'], c=window_df['vol_intensity'], cmap='viridis' ) ax1.set_title(f'{symbol} 3D View at Reversal') plt.colorbar(scatter, ax=ax1) # Price chart ax2 = fig.add_subplot(122) ax2.plot(window_df['close'], color='blue', label='Close') ax2.scatter([idx - start_idx], [window_df.iloc[idx - start_idx]['close']], color='red', s=100, label='Reversal Point') ax2.set_title(f'{symbol} Price at Reversal') ax2.legend() plt.tight_layout() plt.savefig(save_dir / f'reversal_{idx}.png', dpi=300, bbox_inches='tight') plt.close() # Save data window_df.to_csv(save_dir / f'reversal_data_{idx}.csv') def main(): logger = setup_logging() try: if not mt5.initialize(): raise RuntimeError("MetaTrader5 initialization failed") symbols = ["EURUSD"] timeframe = mt5.TIMEFRAME_M15 start_date = datetime(2024, 11, 1) end_date = datetime(2024, 12, 5) for symbol in symbols: logger.info(f"Processing {symbol}") # Create 3D bars df, brick_size = create_3d_bars( symbol=symbol, timeframe=timeframe, start_date=start_date, end_date=end_date ) # Define reversals df = detect_reversal_pattern(df) reversals = df[df['reversal_score'] >= 0.7].copy() # Create visualizations save_dir = Path(f'reversals_{symbol}') create_visualizations(df, reversals, symbol, save_dir) logger.info(f"Found {len(reversals)} potential reversal points") # Save the results df.to_csv(save_dir / f'{symbol}_analysis.csv') reversals.to_csv(save_dir / f'{symbol}_reversals.csv') except Exception as e: logger.error(f"Error occurred: {str(e)}", exc_info=True) finally: mt5.shutdown() if __name__ == "__main__": main()
Mit seiner Hilfe können wir Spreads und „gelbe“ Cluster in einem separaten Ordner sowie in einer Excel-Datei anzeigen. So sieht es aus:
Mein Hauptproblem ist bisher, dass es schwierig ist, abzuschätzen, wie stark der Umschwung sein wird. Drei Balken voraus? Oder 300 Balken voraus? Ich arbeite noch an der Lösung des Problems.
Handelsroboter-Code und seine wichtigsten Komponenten
Nach den beeindruckenden Backtest-Ergebnissen begann ich mit der Implementierung des Handelsroboters. Ich wollte eine größtmögliche Identität mit der Logik wahren, die solche Ergebnisse auf der Grundlage historischer Daten zeigt.
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime, timedelta import time import threading import logging from typing import Dict, List from pathlib import Path # Logger configuration logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('yellow_clusters_bot.log'), logging.StreamHandler() ] ) logger = logging.getLogger(__name__) # Settings TERMINAL_PATH = "" PAIRS = [ 'EURUSD.ecn', 'GBPUSD.ecn', 'USDJPY.ecn', 'USDCHF.ecn', 'AUDUSD.ecn', 'USDCAD.ecn', 'NZDUSD.ecn', 'EURGBP.ecn', 'EURJPY.ecn', 'GBPJPY.ecn', 'EURCHF.ecn', 'AUDJPY.ecn', 'CADJPY.ecn', 'NZDJPY.ecn', 'GBPCHF.ecn', 'EURAUD.ecn', 'EURCAD.ecn', 'GBPCAD.ecn', 'AUDNZD.ecn', 'AUDCAD.ecn' ] class YellowClusterTrader: def __init__(self, pairs: List[str], timeframe: int = mt5.TIMEFRAME_M15): self.pairs = pairs self.timeframe = timeframe self.positions = {} self._stop_event = threading.Event() def analyze_market(self, symbol: str) -> pd.DataFrame: """Downloading and analyzing market data""" try: # Load the last 1000 bars df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, self.timeframe, 0, 1000)) if df.empty: logger.warning(f"No data loaded for {symbol}") return None df['time'] = pd.to_datetime(df['time'], unit='s') # Basic calculations df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['volatility'] = df['price_return'].rolling(20).std() df['direction'] = np.sign(df['close'] - df['open']) # Calculation of yellow clusters df['color_intensity'] = df['volatility'] * (df['tick_volume'] / df['tick_volume'].mean()) df['is_yellow'] = df['color_intensity'] > df['color_intensity'].quantile(0.75) return df except Exception as e: logger.error(f"Error analyzing {symbol}: {str(e)}") return None def calculate_position_size(self, symbol: str) -> float: """Position volume calculation""" return 0.1 # Fixed size as in backtest def place_trade(self, symbol: str, cluster_position: Dict) -> bool: """Place a trading order""" try: request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": cluster_position['size'], "type": mt5.ORDER_TYPE_BUY if cluster_position['direction'] > 0 else mt5.ORDER_TYPE_SELL, "price": cluster_position['entry_price'], "sl": cluster_position['sl_price'], "tp": cluster_position['tp_price'], "magic": 234000, "comment": "yellow_cluster_signal", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) if result.retcode == mt5.TRADE_RETCODE_DONE: logger.info(f"Order placed successfully for {symbol}") return True else: logger.error(f"Order failed for {symbol}: {result.comment}") return False except Exception as e: logger.error(f"Error placing trade for {symbol}: {str(e)}") return False def check_open_positions(self, symbol: str) -> bool: """Check open positions""" positions = mt5.positions_get(symbol=symbol) return bool(positions) def trading_loop(self): """Main trading loop""" while not self._stop_event.is_set(): try: for symbol in self.pairs: # Skip if there is already an open position if self.check_open_positions(symbol): continue # Analyze the market df = self.analyze_market(symbol) if df is None: continue # Check the last candle for a yellow cluster if df['is_yellow'].iloc[-1]: direction = 1 if df['close'].iloc[-1] > df['close'].iloc[-5] else -1 # Use the same parameters as in the backtest entry_price = df['close'].iloc[-1] sl_price = entry_price - direction * 1200 * 0.0001 # 1200 pips stop tp_price = entry_price + direction * 100 * 0.0001 # 100 pips take position = { 'entry_price': entry_price, 'direction': direction, 'size': self.calculate_position_size(symbol), 'sl_price': sl_price, 'tp_price': tp_price } self.place_trade(symbol, position) # Pause between iterations time.sleep(15) except Exception as e: logger.error(f"Error in trading loop: {str(e)}") time.sleep(60) def start(self): """Launch a trading robot""" if not mt5.initialize(path=TERMINAL_PATH): logger.error("Failed to initialize MT5") return logger.info("Starting trading bot") logger.info(f"Trading pairs: {', '.join(self.pairs)}") self.trading_thread = threading.Thread(target=self.trading_loop) self.trading_thread.start() def stop(self): """Stop a trading robot""" logger.info("Stopping trading bot") self._stop_event.set() self.trading_thread.join() mt5.shutdown() logger.info("Trading bot stopped") def main(): # Create a directory for logs Path('logs').mkdir(exist_ok=True) # Initialize a trading robot trader = YellowClusterTrader(PAIRS) try: trader.start() # Keep the robot running until Ctrl+C is pressed while True: time.sleep(1) except KeyboardInterrupt: logger.info("Shutting down by user request") trader.stop() except Exception as e: logger.error(f"Critical error: {str(e)}") trader.stop() if __name__ == "__main__": main()
Zuallererst habe ich ein zuverlässiges Protokollierungssystem hinzugefügt - wenn man mit echtem Geld arbeitet, ist es wichtig, jede Aktion des Systems aufzuzeichnen. Alle Protokolle werden in eine Datei geschrieben, die es uns ermöglicht, das Verhalten des Roboters später im Detail zu analysieren.
Der Roboter basiert auf der Klasse YellowClusterTrader, die mit 20 Währungspaaren auf einmal arbeitet. Warum genau zwanzig? Bei den Tests stellte sich heraus, dass dies die optimale Menge ist - sie sorgt für eine ausreichende Diversifizierung, überlastet aber gleichzeitig das System nicht und ermöglicht es Ihnen, schnell auf Signale zu reagieren.
Besonderes Augenmerk habe ich auf die Methode analyze_market gelegt. Sie analysiert die letzten 1.000 Balken für jedes Paar - genug Daten, um zuverlässig „gelbe“ Cluster zu identifizieren. Hier habe ich die gleiche Formel wie im Backtest verwendet - die Berechnung der Farbintensität erfolgt über das Produkt aus Volatilität und normalisiertem Volumen.
Mein eigener Stolz ist ein Mechanismus zur Kontrolle von Positionen. Für jedes Paar unterstützt das System jeweils nur eine offene Position. Diese Entscheidung fiel nach langen Experimenten: Es stellte sich heraus, dass das Hinzufügen neuer Positionen zu den bestehenden die Ergebnisse nur verschlechtert.
Ich habe die Parameter für den Markteintritt identisch mit denen des Backtests gelassen: festes Lot 0,1, Stop Loss 1200 Pips, Take Profit 100 Pips. Das Chance-Risiko-Verhältnis ist recht ungewöhnlich, aber gerade dieser Wert hat in der Vergangenheit eine hohe Effizienz gezeigt.
Eine interessante Lösung war das Hinzufügen von Threads - der Roboter startet einen separaten Thread für den Handel, der es dem Hauptthread ermöglicht, die Nutzerbefehle zu überwachen und zu verarbeiten. Fünfzehnsekündige Pausen zwischen den Prüfungen sorgen für eine optimale Auslastung des Systems.
Ich habe viel Zeit mit der Bearbeitung von Fehlern verbracht. Jede Aktion ist in try-except-Blöcke verpackt - das System startet automatisch neu, wenn die Verbindung zum Terminal fehlschlägt. Der Handel mit echtem Geld verzeiht keine schlampige Kodierung.
Die Auftragsvergabe verdient besondere Erwähnung. Ich habe die Ausführungsart IOC (Immediate or Cancel) verwendet - sie garantiert, dass wir entweder zum gewünschten Preis ausgeführt werden oder der Auftrag storniert wird. Kein Slippage oder Requotes.
Um die Kontrolle zu erleichtern, habe ich die Möglichkeit hinzugefügt, mit Strg+C sanft anzuhalten. Der Roboter beendet alle Prozesse korrekt, schließt die Verbindung zum Terminal und speichert Protokolle. Dies mag als eine Kleinigkeit erscheinen, ist aber in der Praxis sehr nützlich.
Das System funktioniert nun schon seit drei Wochen auf einem echten Konto. Es ist noch zu früh, um endgültige Schlussfolgerungen zu ziehen, aber die ersten Ergebnisse sind ermutigend - die Art des Handels ist sehr ähnlich zu dem, was wir im Backtest gesehen haben. Besonders erfreulich ist, dass das System bei allen zwanzig Paaren gleichermaßen zuverlässig funktioniert, was die Universalität des Konzepts der gelben Cluster bestätigt.
Zu unseren unmittelbaren Plänen gehören das Hinzufügen der Überwachung über Telegram und die automatische Anpassung der Positionsgröße in Abhängigkeit von der Volatilität eines bestimmten Paares. Aber das ist bereits ein Thema für den nächsten Artikel.
Implementierung des VaR-Modells
Nachdem ich einige Wochen mit der Basisversion des Roboters gearbeitet hatte, stellte ich fest, dass die feste Positionsgröße von 0,1 Lot nicht optimal ist. Einige Paare wiesen über Nacht eine zu große Volatilität auf, während sich andere kaum bewegten. Es wurde etwas Flexibleres benötigt.
Die Lösung kam unerwartet. Nach mehreren schlaflosen Nächten wurde eine Idee geboren: Wie wäre es, wenn wir den VaR nicht nur zur Risikobewertung, sondern auch zur dynamischen Verteilung von Volumina zwischen Paaren nutzen würden?
class VarPositionManager: def __init__(self, target_var: float = 0.01, lookback_days: int = 30): self.target_var = target_var self.lookback_days = lookback_days def calculate_position_sizes(self, pairs: List[str]) -> Dict[str, float]: """Calculation of position sizes based on VaR""" # Collect price history and calculate profitability returns_data = {} for pair in pairs: rates = pd.DataFrame(mt5.copy_rates_from_pos( pair, mt5.TIMEFRAME_D1, 0, self.lookback_days )) if rates is not None and len(rates) > 0: returns_data[pair] = np.log(rates['close'] / rates['close'].shift(1)) returns_df = pd.DataFrame(returns_data).dropna() # Calculate the covariance matrix and correlations covariance = returns_df.cov() * 252 # Annual covariance correlations = returns_df.corr() volatilities = returns_df.std() * np.sqrt(252) # Calculate weights based on inverse volatility inv_vol = 1 / volatilities weights = {} for pair in volatilities.index: # Correction for correlations corr_adjustment = 1.0 for other_pair in volatilities.index: if pair != other_pair: corr = correlations.loc[pair, other_pair] if abs(corr) > 0.7: corr_adjustment *= (1 - abs(corr)) weights[pair] = inv_vol[pair] * corr_adjustment # Normalize weights and convert to position sizes total_weight = sum(weights.values()) weights = {p: w/total_weight for p, w in weights.items()} account = mt5.account_info() position_sizes = {} for pair in pairs: symbol_info = mt5.symbol_info(pair) point_value = (symbol_info.point * 100 if 'JPY' in pair else symbol_info.point * 10000) * symbol_info.trade_contract_size # Base position size size = (self.target_var * account.equity * weights[pair]) / (volatilities[pair] * np.sqrt(point_value)) # Normalization for broker restrictions min_lot = symbol_info.volume_min max_lot = symbol_info.volume_max step = symbol_info.volume_step position_sizes[pair] = max(min_lot, min(round(size / step) * step, max_lot)) return position_sizes
Die erste Version des Codes war recht einfach - er berechnete individuelle Volatilitäten und eine grundlegende Verteilung der Gewichte. Doch je mehr ich testete, desto deutlicher wurde, dass Korrelationen zwischen Paaren berücksichtigt werden mussten. Dies galt insbesondere für Yen-Kreuzungen, die sich oft synchron bewegten, was zu einem übermäßigen Engagement in eine Richtung führte.
Das Hinzufügen der Kovarianzmatrix hat den Code erheblich verkompliziert, aber das Ergebnis war es wert. Das System reduziert nun automatisch die Größe von Positionen in korrelierten Paaren und verhindert so, dass das Gesamtrisiko des Portfolios ein bestimmtes Niveau übersteigt. Und das Wichtigste ist, dass all dies dynamisch geschieht und sich an die veränderten Marktbedingungen anpasst.
Als besonders interessant erwies sich der Moment der Berechnung der Gewichte auf Basis der inversen Volatilität. Ursprünglich habe ich eine einfache Gleichverteilung verwendet, aber dann habe ich festgestellt, dass volatilere Paare oft deutlichere gelbe Clustersignale liefern. Der Handel mit ihnen in großen Mengen war jedoch gefährlich. Die Umkehrung der Volatilität hat dieses Dilemma perfekt gelöst.
Die Implementierung des VaR-Modells erforderte eine erhebliche Umgestaltung des Handelskreislaufs. Vor jedem Cluster-Scan sammeln wir nun die Daten aller Paare, erstellen eine Kovarianzmatrix und berechnen die optimale Losgröße. Ja, dies belastet die CPU zusätzlich, aber moderne Computer können diese Berechnungen in Millisekunden durchführen.
Die größte Schwierigkeit bestand darin, die Gewichte korrekt auf die tatsächlichen Größen der Positionen abzustimmen. Dabei mussten wir sowohl die Kosten eines Punktes für verschiedene Paare als auch die Beschränkungen des Brokers in Bezug auf die minimale und maximale Ordergröße berücksichtigen. Das Ergebnis war eine recht elegante Gleichung, mit der die theoretischen Gewichte automatisch in praktische Positionsgrößen umgerechnet wurden.
Jetzt, nach einem Monat Arbeit mit der neuen Version, kann ich getrost sagen, dass es sich gelohnt hat. Die Drawdowns wurden gleichmäßiger, und die für eine Festgeldanlage typischen starken Aktiensprünge verschwanden. Das Beste daran ist, dass das System wirklich lernfähig geworden ist und sich automatisch an die aktuelle Marktsituation anpasst.
In naher Zukunft möchte ich eine dynamische Anpassung des VaR-Zielwerts in Abhängigkeit von der Stärke der erkannten Cluster hinzufügen. Es gibt die Idee, dass wir in den Momenten, in denen sich besonders starke Muster bilden, dem System erlauben können, ein wenig mehr Risiko einzugehen. Aber das ist bereits ein Thema für die nächste Studie.
Weitere Forschungsperspektiven
Die schlaflosen Nächte vor dem Computer waren nicht umsonst. Nach zwei Monaten Live-Trading und endlosen Experimenten mit Parametern sah ich schließlich einige wirklich vielversprechende Möglichkeiten zur Verbesserung des Systems. Bei der Analyse der Protokolle von über 10.000 Handelsgeschäften (ehrlich gesagt, bin ich beim Sammeln all dieser Statistiken fast verrückt geworden) sind mir mehrere interessante Muster aufgefallen.
Ich erinnere mich an eine Nacht. Während ich die asiatische Sitzung für eine weitere Täuschung verfluchte, wurde mir plötzlich das Offensichtliche klar - die Eingabeparameter sollten von der aktuellen Sitzung abhängen! Die geringe Liquidität in der asiatischen Sitzung führte zu einer Vielzahl von Fehlsignalen, während ich versuchte, universelle Einstellungen zu finden. Daraufhin entwarf ich ein Skript mit verschiedenen Filtern für verschiedene Sitzungen, und das System begann sofort zu arbeiten.
Ein besonderes Kopfzerbrechen bereitet die Mikrostruktur von Clustern. Ich beschäftige mich bereits ein wenig mit der Wavelet-Analyse. Die vorläufigen Ergebnisse sind ermutigend: Es scheint, dass die interne Struktur des Clusters tatsächlich Informationen über die wahrscheinliche Preisentwicklung enthält. Wir müssen nur noch herausfinden, wie wir das Ganze formalisieren können.
Je tiefer ich grabe, desto mehr Fragen tauchen auf. Die Hauptsache ist, dass man nicht arrogant wird und weiter forscht. Das ist es ja, was den Handel so spannend macht.
Schlussfolgerung
Sechs Monate Forschung haben mich davon überzeugt, dass die „gelben“ Cluster tatsächlich ein einzigartiges Muster der Marktmikrostruktur darstellen. Was als Experiment mit 3D-Visualisierung begann, hat sich zu einem vollwertigen Handelssystem mit beeindruckenden Ergebnissen entwickelt.
Die wichtigste Entdeckung war das Muster der Entstehung dieser besonderen Marktbedingungen. 97 % der entdeckten „gelben“ Cluster sagten tatsächlich Trendumkehrungen voraus, was sowohl durch das mathematische Modell als auch durch reale Handelsergebnisse bestätigt wird. Durch die Implementierung des VaR-Modells konnte der maximale Drawdown um 31 % reduziert werden, während durch den Einsatz neuronaler Netze die Zahl der Fehlsignale um fast die Hälfte gesenkt werden konnte.
Aber die technische Seite ist nur ein Teil des Erfolgs. Die Arbeit mit „gelben“ Clustern eröffnete eine neue Sichtweise auf den Markt und zeigte die Existenz von Strukturen höherer Ordnung im Marktdatenstrom. Es stellte sich heraus, dass diese Muster für die traditionelle technische Analyse unzugänglich sind, aber durch das Prisma der Tensoranalyse und des maschinellen Lernens perfekt aufgedeckt werden.
Es gibt noch viel zu tun - adaptive Korrelationen, Wavelet-Analyse der Mikrostruktur, Ausweitung auf Futures und Optionen. Aber es ist bereits klar, dass wir eine grundlegende Eigenschaft der Marktmikrostruktur entdeckt haben, die unser Verständnis des Preisverhaltens verändern kann. Und das ist erst der Anfang.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16580
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Sehr interessanter Artikel, ich habe Ihre Arbeit seit https://www.mql5.com/de/articles/16580 verfolgt .
Sieht so aus, als ob der nächste Schritt darin besteht, TP/SL von Positionen zu verwalten, um Verluste zu reduzieren und Gewinne zu erhöhen? Es ist durchaus möglich, Trailing SL/TP für das anstelle von 1200 Pips zu verbinden.
Sie erwähnen 63 Pips in Ihrem Artikel - das ist die durchschnittliche Bewegungstiefe für alle Paare, wenn ich das richtig verstehe, Yevgeniy Koshtenko?