
Gradient Boosting (CatBoost) für die Entwicklung von Handelssystemen. Ein naiver Zugang
Einführung
Gradient boosting (Gradientenverstärkung) ist ein leistungsfähiger Algorithmus für maschinelles Lernen. Die Methode erzeugt ein Ensemble von schwachen Modellen (z.B. Entscheidungsbäume), in denen (im Gegensatz zu Bagging) Modelle sequentiell und nicht unabhängig (parallel) aufgebaut werden. Das bedeutet, dass der nächste Baum aus den Fehlern des vorhergehenden lernt, dann wird dieser Prozess wiederholt, wodurch sich die Anzahl der schwachen Modelle erhöht. Dadurch entsteht ein starkes Modell, das unter Verwendung heterogener Daten verallgemeinert werden kann. In diesem Experiment habe ich die von Yandex entwickelte Bibliothek CatBoost verwendet. Sie ist zusammen mit XGboost und LightGBM eine der beliebtesten Bibliotheken.
Der Zweck des Artikels besteht darin, das Erstellen eines auf maschinellem Lernen basierenden Modells zu demonstrieren. Der Erstellungsprozess besteht aus den folgenden Schritten:
- Daten empfangen und vorverarbeiten
- das Modell anhand der vorbereiteten Daten trainieren
- das Modell in einem nutzerdefinierten Strategietester testen
- Portierung des Modells auf MetaTrader 5
Die Python-Sprache und die MetaTrader 5-Bibliothek werden zur Vorbereitung der Daten und zum Training des Modells verwendet.
Datenvorbereitung
Der Import verlangt folgende Python-Module:
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
Dann folgt die Initialisierung der globalen Variablen:
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
Diese Parameter sind für das Weitere verantwortlich:
- look_back — Tiefe der analysierten Historie
- ma_period — Periodenlänge des gleitenden Durchschnitts zur Berechnung von Preisschritten
- symbol — welche Symbol-Preise vom MetaTrader 5 Terminal geladen werden sollen
- markup — Spread-Weite für den nutzerdefinierten Tester
- timeframe — Zeitrahmen der zu ladenden Daten
- start, stop — Datenbereich
Lassen Sie uns eine Funktion schreiben, die direkt Rohdaten abruft und einen Datenrahmen mit den für das Training erforderlichen Spalten erstellt:
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
Die Funktion erhält die Schlusskurse für den angegebenen Zeitraum und berechnet den gleitenden Durchschnitt, woraufhin sie die Inkremente (die Differenz zwischen den Preisen und dem gleitenden Durchschnitt) berechnet. Im letzten Schritt berechnet sie zusätzliche Spalten mit Zeilen, die per look_back rückwärts in die Historie verschoben werden, d.h. sie fügt dem Modell zusätzliche (nachlaufende) Merkmale hinzu.
Beispiel: Bei look_back = 10 enthält der Datenrahmen 10 zusätzliche Spalten mit Preisinkrementen:
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
Die gelbe Hervorhebung zeigt an, dass jede Spalte den gleichen Datensatz hat, jedoch mit einem Offset. Somit ist jede Zeile ein separates Trainingsbeispiel.
Erstellen von Trainingsetiketten (Zufallsstichproben)
Bei den Schulungsbeispielen handelt es sich um Reihe von Merkmalen und den entsprechenden Kennzeichnungen. Das Modell muss bestimmte Informationen ausgeben, die das Modell vorhersagen lernen muss. Betrachten wir die binäre Klassifikation, bei der das Modell die Wahrscheinlichkeit vorhersagen wird, mit der das Trainingsbeispiel als Klasse 0 oder 1 bestimmt wird. Nullen und Einsen können für die Handelsrichtung: Kauf oder Verkauf verwendet werden. Mit anderen Worten, das Modell muss lernen, die Richtung eines Handels für die gegebenen Umgebungsparameter (eine Reihe von Merkmalen) vorherzusagen.
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Die Funktion add_labels setzt zufällig (im Bereich zwischen min und max) die Dauer jeder Transaktion in Balken fest. Indem Sie die maximale und minimale Dauer ändern, ändern Sie die Abtastfrequenz des Deals. Wenn also der aktuelle Preis höher ist als der nächste 'zufällige' Balken, handelt es sich um ein Verkaufskennzeichnung (1). Im umgekehrten Fall ist die Kennzeichnung 0. Sehen wir uns an, wie der Datensatz nach Anwendung der obigen Funktion aussieht:
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
Die Spalte 'labels' wurde hinzugefügt, die die Nummer der (Handels-) Klasse (0 oder 1) für den Kauf bzw. Verkauf enthält. Nun hat jedes Trainingsbeispiel oder jeder Satz von Merkmalen (hier sind es 10) eine eigene Kennzeichnung, die angibt, unter welchen Bedingungen Sie kaufen und unter welchen Bedingungen Sie verkaufen sollten (d.h. zu welcher Klasse es gehört). Das Modell muss in der Lage sein, sich diese Beispiele zu merken und zu verallgemeinern — diese Fähigkeit wird später besprochen.
Einen nutzerdefinierten Tester entwickeln
Da wir ein Handelssystem schaffen, wäre es schön, einen Strategietester für zeitnahe Modellprüfungen zu haben. Unten finden Sie ein Beispiel für einen solchen Tester:
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
Die Testerfunktion akzeptiert einen Datensatz und ein 'Markup' (optional) und prüft den gesamten Datensatz, ähnlich wie es im MetaTrader 5 Tester gemacht wird. Ein Signal (Kennzeichnung) wird bei jedem neuen Balken geprüft, und wenn sich die Kennzeichnung ändert, wird der Handel rückgängig gemacht. Somit dient ein Verkaufssignal als Signal, eine Kaufposition zu schließen und eine Verkaufsposition zu eröffnen. Lassen Sie uns nun den obigen Datensatz testen:
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
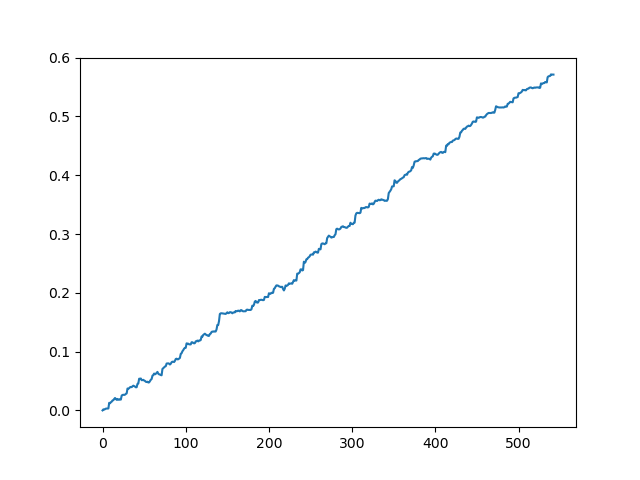
Testen des Originaldatensatzes ohne Spread
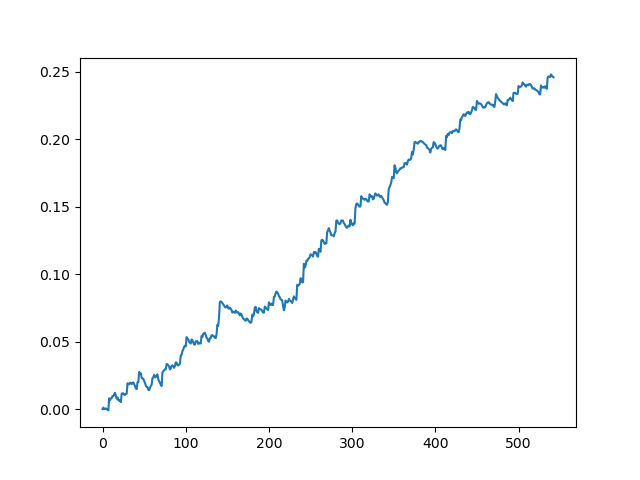
Testen des Originaldatensatzes mit einem Spread von 70 Punkten bei 5 Dezimalstellen
Dies ist eine Art idealisiertes Bild (wir wollen, dass das Modell so funktioniert). Da die Kennzeichnungen in Abhängigkeit von einer Reihe von Parametern, die für die minimale und maximale Lebensdauer der Geschäfte verantwortlich sind, nach dem Zufallsprinzip ausgewählt werden, werden die Kurven immer unterschiedlich sein. Dennoch werden sie alle ein gutes Punktwachstum (entlang der Y-Achse) und eine unterschiedliche Anzahl von Positionen (entlang der X-Achse) aufweisen.
Training des Modells CatBoost
Lassen Sie uns nun direkt zur Ausbildung des Modells übergehen. Zunächst teilen wir den Datensatz in zwei Beispiele auf: Training und Validierung. Dies dient dazu, die Überanpassung des Modells zu reduzieren. Während das Modell weiterhin mit Teilstichproben für das Training trainiert und versucht, den Klassifizierungsfehler zu minimieren, wird derselbe Fehler auch mit den Teilstichproben für die Validierung gemessen. Wenn der Unterschied in diesen Fehlern groß ist, spricht man von einer Überanpassung des Modells. Umgekehrt weisen enge Werte auf ein korrektes Training eines Modells hin.
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
Teilen wir die Daten in zwei gleich lange Datensätze auf, nachdem wir die Trainingsbeispiele zufällig gemischt haben. Als Nächstes erstellen und trainieren wir das Modell:
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
Das Modell benötigt eine Reihe von Parametern, von denen in diesem Beispiel nicht alle gezeigt werden. Sie können in der Dokumentation nachschlagen, wenn Sie eine Feinabstimmung des Modells vornehmen möchten, was in der Regel nicht erforderlich ist. CatBoost funktioniert gut "out of the box" mit minimaler Feinabstimmung.
Hier ist eine kurze Beschreibung der Modellparameter:
- Iterationen — die maximale Anzahl von Bäumen im Modell. Das Modell erhöht die Anzahl der schwachen Modelle (Bäume) nach jeder Iteration, stellen Sie also sicher, dass Sie einen ausreichend großen Wert einstellen. Aus meiner Praxis sind 1000 Iterationen für dieses spezielle Beispiel normalerweise mehr als genug.
- Tiefe — die Tiefe jedes Baumes. Je geringer die Tiefe, desto gröber ist das Modell — es werden weniger Positionen ausgegeben. Eine Tiefe zwischen 6 und 10 scheint optimal zu sein.
- learning_rate — Gradientenschrittwert; dies ist das gleiche Prinzip, das in neuronalen Netzen verwendet wird. Ein sinnvoller Bereich von Parametern ist 0,01 - 0,1. Je niedriger der Wert, desto länger braucht das Modell zum Trainieren. Aber in diesem Fall kann es bessere Varianten finden.
- custom_loss, eval_metric — die zur Bewertung des Modells verwendete Metrik. Die klassische Metrik für die Klassifizierung ist "Genauigkeit" (accuracy).
- use_best_model — bei jedem Schritt bewertet das Modell die "Genauigkeit", die sich im Laufe der Zeit ändern kann. Dieses Flag erlaubt es, das Modell mit dem geringsten Fehler zu speichern. Andernfalls wird das bei der letzten Iteration erhaltene Modell gespeichert.
- task_type — ermöglicht das Training eines Modells auf einer GPU (CPU wird standardmäßig verwendet). Dies ist nur im Falle sehr großer Daten relevant; in anderen Fällen wird das Training auf GPU-Kernen langsamer durchgeführt als auf dem Prozessor.
- early_stopping_rounds — das Modell hat einen eingebauten Überanpassungsdetektor, der nach einem einfachen Prinzip arbeitet. Wenn die Metrik während der angegebenen Anzahl von Iterationen nicht mehr abnimmt/zuwächst (die "Genauigkeit" hört auf zu steigen), dann beendet sich das Training.
Nachdem das Training begonnen hat, wird der aktuelle Zustand des Modells bei jeder Iteration in der Konsole angezeigt:
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
Im obigen Beispiel wurde das Training bei Iteration 180 durch eine erkannte Überanpassung beendet. Außerdem zeigt die Konsole Statistiken für die Teilstichprobe Training (Lernen) und die Teilstichprobe Validierung (Test) sowie die gesamte Modell-Trainingszeit an, die nur 20 Sekunden betrug. Bei der Ausgabe erhielten wir die beste Genauigkeit bei der Trainings-Unterstichprobe 1,0 (was dem idealen Ergebnis entspricht) und die Genauigkeit von 0,78 bei der Validierungs-Unterstichprobe, was schlechter ist, aber immer noch über 0,5 liegt (was als zufällig betrachtet wird). Die beste Iteration ist 165 — dieses Modell wird gespeichert. Jetzt können wir in unserem Tester testen:
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X - ist der Quelldatensatz mit Merkmalen, aber ohne Kennzeichnung. Um die Kennzeichnungen zu erhalten, ist es notwendig, sie aus dem trainierten Modell zu erhalten und die Wahrscheinlichkeiten 'p' der Zuordnung zur Klasse 0 oder 1 vorherzusagen. Da das Modell die Wahrscheinlichkeiten für zwei Klassen erzeugt, da wir nur 0 oder 1 benötigen, erhält die Variable 'p2' nur Wahrscheinlichkeiten in der ersten Dimension (0). Außerdem werden die Kennzeichnungen im Originaldatensatz durch die vom Modell vorhergesagten Kennzeichnungen ersetzt. Hier sind die Ergebnisse im Tester:
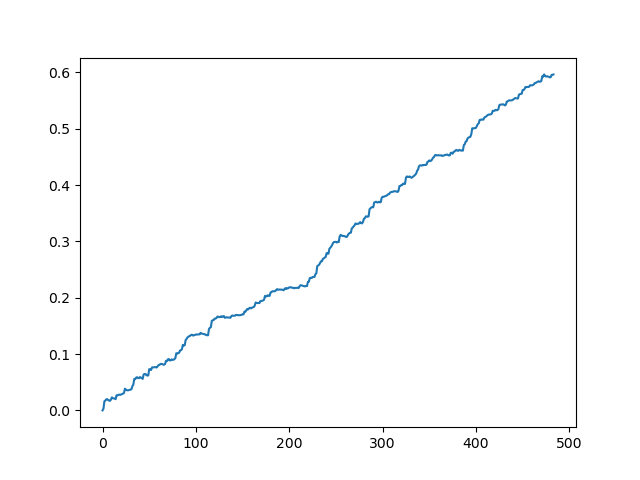
Ein ideales Ergebnis nach der Bemusterung von Gewerken
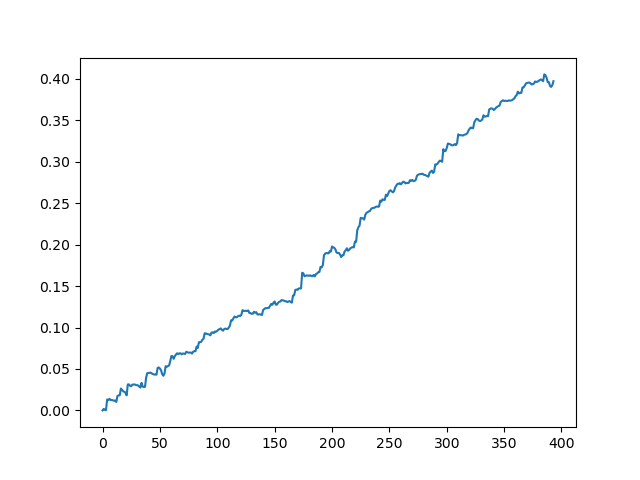
Das erhaltene Ergebnis vom Ausdruck des Modells
Wie Sie sehen können, hat das Modell gut gelernt, d.h. es hat sich die Schulungsbeispiele gemerkt und ein besser als zufälliges Ergebnis auf dem Validierungssatz gezeigt. Kommen wir nun zum letzten Schritt: Exportieren des Modells und Erstellen eines Handelsroboters.
Portierung des Modells auf MetaTrader 5
Die Python API des MetaTrader 5 ermöglicht den Handel direkt aus einem Python-Programm heraus, so dass eine Portierung des Modells nicht notwendig ist. Ich wollte jedoch meinen nutzerdefinierten Tester überprüfen und mit dem Standard-Strategie-Tester vergleichen. Außerdem kann die Verfügbarkeit eines kompilierten Bot in vielen Situationen bequem sein, einschließlich der Verwendung auf einem VPS (in diesem Fall müssen Sie Python nicht installieren). Daher habe ich eine Hilfsfunktion geschrieben, die ein fertiges Modell in einer MQH-Datei speichert. Die Funktion ist wie folgt:
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc')
Der Funktionscode sieht seltsam und umständlich aus. Das trainierte Modellobjekt wird in die Funktion eingegeben, die das Objekt dann im Format von C++ speichert:
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
Dann wird eine Zeichenfolge erstellt, und der C++-Code wird mit Standard-Python-Funktionen in MQL5 geparst:
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
Die Funktion 'ApplyCatboostModel' aus dieser Bibliothek wird nach den obigen Änderungen eingefügt. Sie gibt das berechnete Ergebnis im Bereich zwischen (0;1) zurück, basierend auf dem gespeicherten Modell und dem übergebenen Feature-Vektor.
Danach müssen wir den Pfad zum Ordner \\Include des MetaTrader 5 Terminals angeben, in dem das Modell gespeichert werden soll. Auf diese Weise wird das Modell nach der Einstellung aller Parameter mit einem Klick trainiert und sofort als MQH-Datei gespeichert, was sehr bequem ist. Diese Option ist auch deshalb gut, weil dies eine gängige und beliebte Praxis ist, um Modelle in Python zu trainieren.
Schreiben eines Bot-Handels in MetaTrader 5
Nachdem wir ein CatBoost-Modell trainiert und gespeichert haben, müssen wir einen einfachen Bot zum Testen schreiben:
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
Verbinden Sie nun die gespeicherte cat_model.mqh und MT4Orders.mqh vom fxsaber.
Die Parameter look_back und MA_period müssen genau so gesetzt werden, wie sie beim Training im Python-Programm angegeben wurden, sonst wird ein Fehler geworfen.
Außerdem überprüfen wir bei jedem Balken das Signal des Modells, in das der Vektor der Inkremente (Differenz zwischen dem Preis und dem gleitenden Durchschnitt) eingegeben wird:
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
Die Logik der Positionseröffnung ähnelt der nutzerdefinierten Testerlogik, aber sie wird im Stil von mql5 + MT4Orders ausgeführt:
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
Testen des Bot mit maschinellem Lernen
Der kompilierte Bot kann mit dem standardmäßigen Strategietester des MetaTrader 5 getestet werden. Wählen Sie einen geeigneten Zeitrahmen (der mit dem im Modelltraining verwendeten übereinstimmen muss) und Eingaben look_back und MA_period, die auch mit den Parametern aus dem Python-Programm übereinstimmen sollten. Überprüfen wir das Modell in der Trainingsphase (Trainings- + Validierungsteilstichproben):
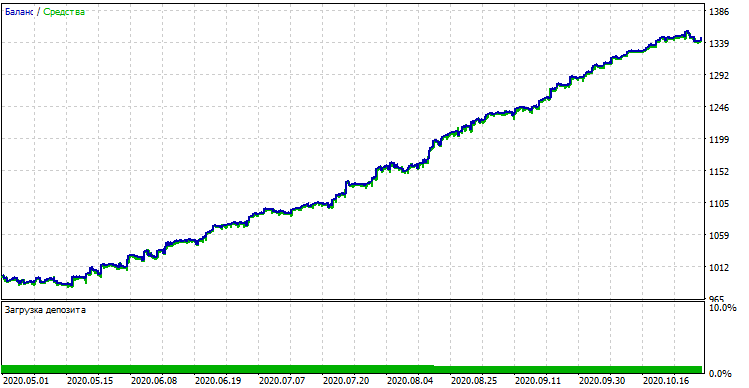
Modellleistung (Trainings- + Validierungsteilstichproben)
Wenn wir das Ergebnis mit dem im nutzerdefinierten Tester erzielten Ergebnis vergleichen, sind diese Ergebnisse bis auf einige Abweichungen beim Spread gleich. Testen wir nun das Modell mit absolut neuen Daten vom Jahresanfang:
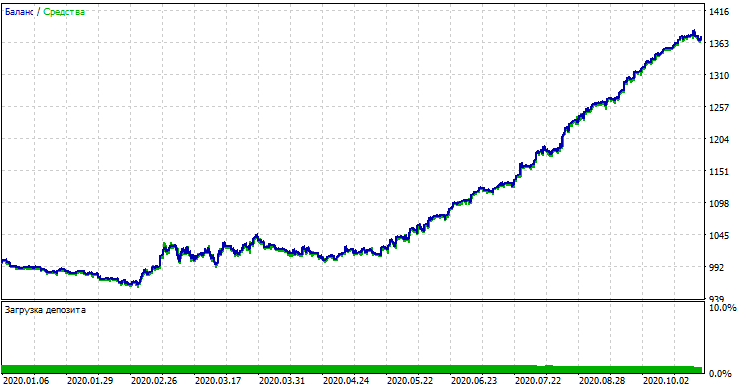
Leistung des Modells mit neuen Daten
Das Modell schnitt bei neuen Daten signifikant schlechter ab. Ein solch schlechtes Ergebnis hängt mit objektiven Gründen zusammen, die ich versuchen werde, näher zu beschreiben.
Von naiven Modellen zu aussagekräftigen Modellen (weitere Forschung)
Der Artikel mit der Überschrift besagt, dass wir "den naiven Zugang" verwenden. Er ist aus den folgenden Gründen naiv:
- Das Modell enthält keine früheren Daten über Muster. Die Identifizierung von Mustern wird vollständig durch Gradient boosting durchgeführt, dessen Möglichkeiten jedoch begrenzt sind.
- Das Modell verwendet eine Zufallsstichprobe von Transaktionen, so dass die Ergebnisse in verschiedenen Trainingszyklen unterschiedlich ausfallen können. Dies ist nicht nur ein Nachteil, sondern kann auch als Vorteil angesehen werden, da diese Eigenschaft den Brute-Force-Ansatz ermöglicht.
- In der Ausbildung sind keine Merkmale der Allgemeinbevölkerung bekannt. Man wusste nie, wie sich das Modell bei neuen Daten verhalten wird.
Mögliche Wege zur Verbesserung der Modellleistung (wird in einem separaten Artikel behandelt):
- Auswahl von Modellen nach einem externen Kriterium (z.B. Leistung bei neuen Daten)
- Neue Ansätze für Datenprobenahme und Modelltraining, Klassifikator-Stapelung
- Auswahl von Merkmalen anderer Art, basierend auf a priori-Wissen und/oder Annahmen
Schlussfolgerung
Dieser Artikel befasst sich mit dem ausgezeichneten Modell des maschinellen Lernens mit dem Titel CatBoost: Wir haben die Hauptaspekte im Zusammenhang mit dem Modellaufbau und dem Training der binären Klassifikation bei Problemen der Zeitreihenvorhersage erörtert. Wir haben ein Modell vorbereitet und getestet sowie als fertiger Roboter in die MQL-Sprache portiert. Python- und MQL-Anwendungen sind unten angefügt.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/8642
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Verwendung von Kryptographie mit externen Anwendungen
Verwendung von Kryptographie mit externen Anwendungen
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
prices.dropna()Am Ende hat es nicht funktioniert. Das Archiv enthielt immer noch Nan-Werte. Das Problem wurde durch einfaches Löschen von Zeilen gelöst.
Ich scheine die Ergebnisse des Python-Testers nicht reproduzieren zu können. Der MT5-Tester reproduziert nicht die Ergebnisse für den gleichen Zeitraum im Python-Tester.
Ansonsten habe ich das Modell wie beschrieben portiert.
Ich habe cat_model.mqh und cat_trader.mql5 (kompiliert zu .ex5).
Aber die Ergebnisse sehen anders aus.
Hier können Sie den Code für das Modell sehen. Beachten Sie MA_Period, Look_Back, etc. Dann sehen Sie sich die Gewinnkurve des Python-Code-Testers an. Dann sehen Sie sich die MT5-Eingaben, Einstellungen und Ergebnisse des Strategietesters an.
Ich scheine die Ergebnisse des Python-Testers nicht reproduzieren zu können. Der MT5-Tester ist nicht reproduzieren die Ergebnisse für den gleichen Zeitraum in Python-Tester.
Ansonsten habe ich das Modell wie beschrieben portiert.
Ich habe cat_model.mqh und cat_trader.mql5 (kompiliert zu .ex5).
Aber die Ergebnisse sehen anders aus.
Hallo, möglicherweise gibt es einen Unterschied zwischen der Art und Weise, wie das Modell geparst wurde, als der Artikel geschrieben wurde, und wie es jetzt geschieht. CatBoost könnte die Codelogik des endgültigen Modells in den neuen Versionen geändert haben, also müssen Sie es herausfinden.
Ich halte es für sehr wahrscheinlich, dass dies ein Problem sein könnte.
Ich habe ein paar Änderungen vorgenommen:
Ich habe den Code geändert, um die mqh entsprechend der Chart-Zeit der Daten zu speichern.
Ich änderte die mqh, um für jeden Zeitrahmen unterschiedlich zu sein, so dass es möglich ist, alle Zeitrahmen trainiert und bereit für die Verwendung im EA zu haben.
Ich habe den EA so geändert, dass er alle trainierten Dateien für die Analyse und die Erzeugung von Signalen verwendet.
Alle Dateien sind angehängt, damit Sie sie sich ansehen können, falls möglich.
Wenn Sie den Code verbessern könnten, wäre ich Ihnen sehr dankbar.
Die Strategie und auch das Modelltraining sind extrem verbesserungswürdig, wenn möglich, wäre ich für Hilfe dankbar.
Ich habe ein paar Änderungen vorgenommen:
Ich habe den Code geändert, um die mqh entsprechend der grafischen Zeit der Daten zu speichern.
Ich habe die mqh so geändert, dass sie für jede Chart-Zeit unterschiedlich ist, so dass alle Chart-Zeiten trainiert werden können und bereit sind, im EA verwendet zu werden.
Ich habe den EA so geändert, dass er alle trainierten Dateien für die Analyse und die Erzeugung von Signalen verwendet.
Ich habe alle Dateien angehängt, damit Sie sie analysieren können, falls möglich.
Wenn Sie den Code verbessern können, wäre ich Ihnen sehr dankbar.
die Strategie und auch die Ausbildung des Modells braucht extreme Verbesserung, wenn möglich helfen, danke.