
Построение экономических прогнозов: потенциальные возможности Python

Введение
Экономическое прогнозирование – довольно сложная и трудоемкая задача. Оно позволяет анализировать возможные будущие движения, используя прошедшие данные. Анализируя исторические данные и текущие экономические индикаторы, мы предполагаем, куда возможно двинется экономика. Это довольно полезный навык. С его помощью мы можем принимать более взвешенные решения в бизнесе, в инвестициях, и в экономической политике.
Используя Python и экономические данные, начиная со сбора информации и заканчивая созданием прогнозных моделей, мы будем разрабатывать данный инструмент. Он будет должен анализировать и так же делать прогнозы на будущее.
Финансовые рынки являются показательным барометром экономики. Они реагируют на малейшие изменения. Результат может быть как предсказуемым, так и неожиданным. Рассмотрим примеры, когда показатели заставляют этот барометр колебаться.
Если ВВП растет, рынки обычно реагируют позитивно. При росте инфляции, обычно ожидаются волнения. Безработица понизилась, — обычно это позитивная новость, но не всегда. Торговый баланс, процентные ставки — каждый показатель отражается на настроении рынка.
Как показывает практика, рынки чаще реагируют не на фактический результат, а на ожидания большинства игроков. "Покупай слухи, продавай факты" — эта старая биржевая мудрость наиболее точно отражает суть происходящего. Также отсутствие весомых изменений может вызвать более большую волатильность на рынке, чем неожиданные новости.
Экономика — сложная система. Здесь все взаимосвязано и один фактор влияет на другой. Изменение одного показателя может запустить цепную реакцию. Понять эти связи, научиться их анализировать — вот наша задача, и искать решения мы будем с помощью инструмента Python.
Настройка окружения: импорт необходимых библиотек
Итак, что нам понадобится? Для начала — Python. Если он у вас еще не установлен, заходите на python.org, скачивайте и устанавливайте. Также не забудьте установить галочку "Add Python to PATH" в процессе установки.
Следующий шаг — библиотеки. Библиотеки значительно расширяют базовые возможности нашего инструмента. Нам понадобится:
- pandas — понадобится нам в работе с данными.
- wbdata — для взаимодействия с Всемирным банком. С помощью этой библиотеки мы будем получать самые свежие экономические данные.
- MetaTrader 5 — понадобится нам для взаимодействия непосредственно с самим рынком.
- CatBoostRegressor из catboost — небольшой ручной искусственный интеллект.
- train_test_split и mean_squared_error из sklearn — эти библиотеки помогут нам оценить, насколько эффективна наша модель.
Чтобы установить всё необходимое, откройте командную строку и вводите:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
Всё установилось? Отлично! Теперь давайте напишем наши первые строчки кода:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
На данном этапе мы подготовили все необходимые инструменты. Будем двигаться дальше.
Работа с API Всемирного банка: загрузка экономических индикаторов
Теперь разберемся как мы будем получать экономические данные из Всемирного банка.
Сначала мы создаем словарь с кодами индикаторов:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # Рост ВВП
'FP.CPI.TOTL.ZG': 'Inflation', # Инфляция
'FR.INR.RINR': 'Real interest rate', # Реальная процентная ставка
# ... и еще куча других умных показателей
} Каждый из этих кодов открывает доступ к определенному типу данных.
Двигаемся дальше. Мы запускаем цикл, который пройдет по всему коду:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
В данном коде мы пытаемся получить данные для каждого индикатора. Если получилось, — складываем в список. Не получилось, — печатаем ошибку и идем дальше.
После этого мы собираем все наши данные в один большой DataFrame:
data = pd.concat(data_frames, axis=1) На данном этапе мы должны получить все экономические данные.
Следующим шагом мы сохраняем все полученное в файл, чтобы потом можно было использовать в нужных нам целях:
data.to_csv('economic_data.csv', index=True) Вот так просто мы только что выкачали кучу данных из Всемирного банка.
Обзор ключевых экономических индикаторов для анализа
Если вы являетесь новичком, могут возникнуть небольшие трудности в понимании множества данных и цифр. Разберем основные показатели для облегчения процесса:
- Рост ВВП — это своеобразный заработок страны. Растущие показатели являются позитивом, падающие — соответственно негативно влияют на страну.
- Инфляция — это подорожание услуг и товаров.
- Реальная процентная ставка — если она растет, это приводит к удорожанию кредитов.
- Экспорт и импорт — что страна продает и покупает. Позитивным являются более большие продажи.
- Текущий счет — сколько денег стране должны другие страны. Более большие цифры говорят о хорошем финансовом состоянии государства.
- Госдолг — это кредиты, висящие на государстве. Чем меньше цифры, тем лучше.
- Безработица — сколько людей без работы. Меньше — лучше.
- Рост ВВП на душу населения — богатеет средний житель или нет.
В коде это выглядит так:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
} Каждый показатель имеет свою важность. Однако, по отдельности они мало что говорят, но вместе дают более полную картину. Также нужно отметить, что показатели влияют друг на друга. Например, низкая безработица обычно является хорошей новостью, но она может привести к росту инфляции. Или высокий рост ВВП может быть не так позитивен, если он достигается за счет огромных долгов.
Поэтому мы и используем машинное обучение, оно помогает учесть все эти сложные связи. Оно значительно ускоряет процесс обработки информации, и фильтрует данные. Однако вам также нужно будет приложить усилия, чтобы разобраться в сути процесса.
Обработка и структурирование данных Всемирного банка
Конечно, на первый взгляд множество данных Всемирного банка может показаться очень трудоемким процессом для понимания. Для облегчения работы и анализа мы соберем данные в таблицу.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Далее мы берем каждый индикатор и пытаемся получить для него данные. Могут возникнуть проблемы с отдельными индикаторами, мы пишем об этом и идем дальше. Затем отдельные данные собираем в один большой DataFrame.
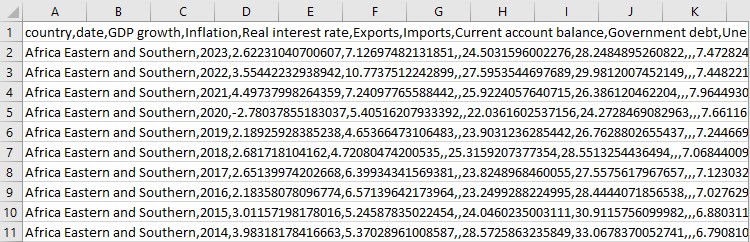
Но мы на этом не останавливаемся. Дальше начинается самое интересное.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe()) Мы смотрим, что у нас получилось. Какие индикаторы есть? Как выглядят первые строки данных? Это как первый взгляд на собранный пазл: всё ли на месте? А потом мы сохраняем всё это добро в CSV файл.
И напоследок — немного статистики. Средние значения, максимумы, минимумы. Это как беглый осмотр: всё ли в порядке с нашими данными? Вот так, друзья, мы превращаем кучу разрозненных цифр в стройную систему данных. Теперь у нас есть все инструменты для серьезного экономического анализа.
Введение в MetaTrader 5: установка соединения и получение данных
Теперь давайте поговорим о MetaTrader 5. Для начала нам нужно установить соединение. Вот как это выглядит:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
Следующий важный шаг — получение данных. Сначала нужно проверить, какие вообще валютные пары доступны:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols] После того, как вышеуказанный код будет исполнен, мы получим список всех доступных валютных пар. Далее нам необходимо загрузить исторические данные котировок для каждой доступной пары:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df Что происходит в этом коде, который мы ввели? Мы дали команду MetaTrader загрузить данные за последние 1000 дней по каждому торговому инструменту. После этого эти данные загружаются в таблицу.
В загруженных данных есть все, что происходило на валютном рынке в течение трех последних лет, в мельчайших деталях. Теперь, полученные котировки можно анализировать и искать закономерности. В принципе, возможности тут практически ничем не ограничены.
Подготовка данных: объединение экономических показателей и рыночных данных
На данном этапе мы займемся непосредственно обработкой данных. У нас есть два отдельных сектора: мир экономических показателей и мир валютных курсов. Наша задача — свести эти секторы вместе.
Начнем с нашей функции подготовки данных. Данный код будет следующим в нашей общей задаче:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Теперь разберем это по шагам. Для начала, мы создаем копию данных о валютной паре. Зачем? Всегда лучше работать с копией данных, а не с оригиналом. В случае ошибки, нам не придется еще раз создавать оригинальный файл.
Теперь самое интересное. Мы добавляем два новых столбца: 'close_diff' и 'close_corr'. Первый показывает, насколько изменилась цена закрытия по сравнению с предыдущим днем. Так мы узнаем положительный или отрицательный сдвиг в цене. Второй — это корреляция цены закрытия с самой собой, но со сдвигом на один день. Для чего это? На самом деле, это просто самый удобный способ понять, насколько сегодняшняя цена похожа на вчерашнюю.
Дальше начинается самое сложное, — мы пытаемся добавить экономические показатели к нашим данным о валюте. Так мы начинаем объединять наши данные в одну конструкцию. Мы проходимся по всем нашим экономическим индикаторам и пытаемся найти их в данных Всемирного банка. Если находим — отлично, добавляем к нашим данным о валюте. Если нет — ну что ж, бывает. Мы просто пишем предупреждение и идем дальше.
После всего этого у нас могут остаться строки с пропущенными данными. Мы их просто удаляем.
Теперь давайте посмотрим, как мы применяем эту функцию:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data) Мы берем каждую валютную пару и применяем к ней нашу написанную функцию. На выходе получаем готовый набор данных для каждой пары. Для каждой пары будет отдельный набор, но все они собраны по одному и тому же принципу.
Знаете, что самое важное в этом процессе? Мы создаем что-то новое. Мы берем разные экономические данные и живые данные о валютных курсах и создаем из них нечто упорядоченное. По отдельности они могут показаться хаотичными, но собрав их вместе, мы можем выявить закономерности.
И вот теперь у нас есть готовый набор данных для анализа. Мы можем искать в нем последовательности, строить прогнозы, делать выводы. Однако, нам нужно будет выявлять те признаки, которые действительно заслуживают внимания. В мире данных нет неважных деталей. Каждый шаг в подготовке данных может оказаться решающим для конечного результата.
Машинное обучение в нашей модели
Машинное обучение — это довольно сложный и трудоемкий процесс. CatBoost Regressor — эта функция далее сыграет немаловажную роль. Вот как мы его используем:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Каждый параметр тут важен. 1000 итераций — столько раз модель пройдется по данным. Скорость обучения 0.1 — не нужно ставить сразу большую скорость, учимся постепенно. Глубина 8 — ищем сложные связи. RMSE — так оцениваем ошибки. Обучение модели занимает определенное время. Показываем примеры, оцениваем правильные ответы. CatBoost особенно хорошо работает с разными типами данных. То есть он не ограничен узким кругом функций.
Для прогноза валют делаем так:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}") Одна часть данных для обучения, другая для проверки. Как в школе: сначала учишься, потом экзамен
Данные делим на две части. Зачем? Одна часть для обучения, другая для проверки. Так как нам нужно будет проверять модель на данных, с которыми она еще не работала.
После обучения модель пробует предсказывать. Среднеквадратичная ошибка показывает, насколько хорошо получилось. Меньше ошибка —лучше прогноз. CatBoost примечателен тем, что постоянно улучшается. Учится на ошибках, в этом тоже ее отличительная особенность.
Конечно, CatBoost не является автоматической программой. Ему нужны хорошие данные. Иначе — неэффективные данные на входе, неэффективные данные на выходе. Но с правильными данными — результат является положительным. Теперь о разделении данных. Я же упоминал, что нам необходимы котировки для проверки. Вот как это выглядит в коде:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 50% данных уходит на тестирование. Не перемешиваем — важно сохранить временной порядок для финансовых данных.
Создание и обучение модели – самая интересная часть. Тут CatBoost максимально демонстрирует свои возможности:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Модель жадно поглощает данные, ищет закономерности. Каждая итерация — шаг к лучшему пониманию рынка.
А теперь момент истины. Оценка точности:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
Среднеквадратичная ошибка — тоже важный момент в нашей работе. Она показывает, насколько модель ошибается. Чем меньше, тем лучше. Это позволяет нам оценить качество работы данной программы. Помните, в трейдинге нет окончательных гарантий. Но с CatBoost процесс проходит эффективнее. Он видит то, что мы можем пропустить. И с каждым прогнозом результат улучшается.
Прогнозирование будущих значений валютных пар
Прогнозирование валютных пар — это работа с вероятностями. Иногда мы получаем положительный результат, а иногда терпим убытки. Главное, чтобы конечный результат был удовлетворяющим нашим ожиданиям.
В нашем коде над вероятностями работает функция forecast. Вот как она проводит вычисления:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
Сначала мы отделяем уже доступные данные от прогнозируемых данных. Затем делим данные на две части: для тренировки и для проверки. Модель учится на одних данных, а мы проверяем её на других. После обучения модель делает предсказания. Мы смотрим, насколько она ошиблась, используя среднеквадратичную ошибку. Чем меньше число, тем лучше прогноз.
Но самое интересное — это анализ котировок на возможные будущие движения цены. Мы берем последние 30 дней данных и просим модель предсказать, что будет дальше. Похоже на ситуацию когда мы прибегаем к прогнозам опытных аналитиков. А теперь о визуализации. К сожалению, в вашем коде пока нет явной визуализации результатов. Но давайте добавим ее и посмотрим, как это могло бы выглядеть:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Этот код создал бы график для каждой валютной пары. Визуально он построен линейно. Каждая точка — предсказанная цена на определенный день. Данные графики призваны увидеть возможные тренды, проделана работа с огромным массивом данных, зачастую слишком сложным для обычного человека. Если линия направлена вверх, валюта будет дорожать. Падает вниз? Готовьтесь к снижению курса.
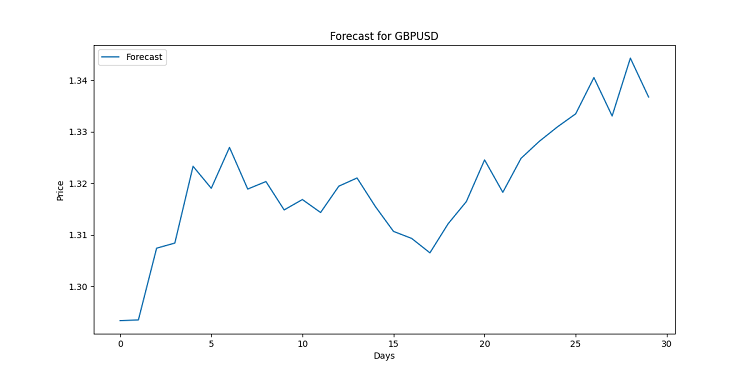
Помните, прогнозы — это не гарантия. Рынок может внести свои изменения. Но с хорошей визуализацией вы хотя бы будете знать, чего ожидать. Ведь в данной ситуации у нас под руками качественно проделанный анализ.
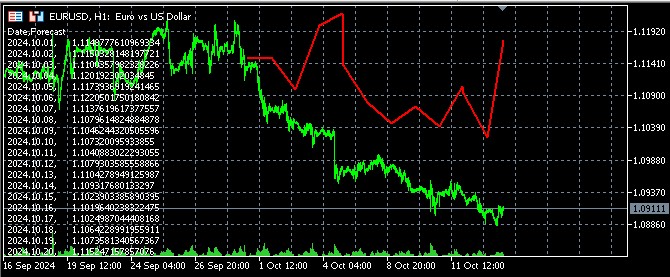
Также я сделал код для визуализации результатов прогноза в MQL5, через открытие файла и вывода прогнозов в Comment:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/ru/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/ru/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Имя файла с прогнозом //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Пропускаем заголовок string header = FileReadString(file_handle); comment += header + "\n"; // Читаем данные из файла while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Находим соответствующий бар на графике и устанавливаем значение прогноза int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Создает стрелку | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // ID графика const string name="Arrow", // имя стрелки const int sub_window=0, // номер подокна datetime time=0, // время точки привязки double price=0, // цена точки привязки const uchar arrow_code=252, // код стрелки const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // положение точки привязки const color clr=clrRed, // цвет стрелки const ENUM_LINE_STYLE style=STYLE_SOLID, // стиль окаймляющей линии const int width=3, // размер стрелки const bool back=false, // на заднем плане const bool selection=true, // выделить для перемещений const bool hidden=true, // скрыт в списке объектов const long z_order=0) // приоритет на нажатие мышью { //--- установим координаты точки привязки, если они не заданы ChangeArrowEmptyPoint(time, price); //--- сбросим значение ошибки ResetLastError(); //--- создадим стрелку if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": не удалось создать стрелку! Код ошибки = ", GetLastError()); return(false); } //--- установим код стрелки ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- установим способ привязки ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- установим цвет стрелки ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- установим стиль окаймляющей линии ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- установим размер стрелки ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- отобразим на переднем (false) или заднем (true) плане ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- включим (true) или отключим (false) режим перемещения стрелки мышью //--- при создании графического объекта функцией ObjectCreate, по умолчанию объект //--- нельзя выделить и перемещать. Внутри же этого метода параметр selection //--- по умолчанию равен true, что позволяет выделять и перемещать этот объект ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- скроем (true) или отобразим (false) имя графического объекта в списке объектов ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- установим приоритет на получение события нажатия мыши на графике ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- успешное выполнение return(true); } //+------------------------------------------------------------------+ //| Проверяет значения точки привязки и для пустых значений | //| устанавливает значения по умолчанию | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- если время точки не задано, то она будет на текущем баре if(!time) time=TimeCurrent(); //--- если цена точки не задана, то она будет иметь значение Bid if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
А вот как прогноз выглядит в терминале:
Интерпретация результатов: анализ влияния экономических факторов на курсы валют
Теперь рассмотрим более подробно интерпретацию результатов, опираясь на ваш код. Мы собрали тысячи разрозненных фактов в упорядоченные данные, которые тоже нуждаются в анализе.
Начнем с того, что у нас есть куча экономических показателей — от роста ВВП до уровня безработицы. Каждый фактор имеет свое влияние на рыночный фон. Отдельно взятые показатели влияют по своему, но вместе эти данные влияют на конечные курсы валют.
Возьмем, к примеру, ВВП. В вашем коде он представлен несколькими показателями:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
Рост ВВП обычно укрепляет валюту. Почему? Потому что позитивные новости привлекают игроков, ищущих возможность для вложения капитала с целью дальнейшего прироста. Инвесторы тянутся к растущим экономикам, повышая спрос на их валюту.
А вот инфляция ( 'FP.CPI.TOTL.ZG': 'Inflation' ) — это тревожный сигнал для трейдеров. Чем выше инфляция, тем быстрее падет ценность денег. Высокая инфляция обычно ослабляет валюту, по простой причине того, что услуги и товары начинают сильно дорожать в рассматриваемом государстве.
Интересно посмотреть на торговый баланс:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Эти показатели — как весы. Если экспорт перевешивает импорт, то страна получает больше иностранной валюты, что обычно укрепляет национальную валюту.
Теперь о том, как мы это анализируем в коде. CatBoost Regressor — наш главный инструмент. Он как опытный дирижер, который слышит все инструменты сразу и понимает, как они влияют друг на друга.
Вот что можно добавить в функцию forecast , чтобы лучше понять влияние факторов:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Топ-10 важных факторов
return future_predictions Это покажет нам, какие факторы оказались наиболее важными для прогноза каждой валютной пары. Может оказаться, что для евро ключевой фактор — это ставка ЕЦБ, а для йены — торговый баланс Японии. Пример вывода данных:
Interpretation for EURUSD:
1. Price Trend: The forecast shows a upward trend for the next 30 days.
2. Volatility: The predicted price movement shows low volatility.
3. Key Influencing Factor: The most important feature for this forecast is 'low'.
4. Economic Implications:
- If GDP growth is a top factor, it suggests strong economic performance is influencing the currency.
- High importance of inflation rate might indicate monetary policy changes are affecting the currency.
- If trade balance factors are crucial, international trade dynamics are likely driving currency movements.
5. Trading Implications:
- Upward trend suggests potential for long positions.
- Lower volatility might allow for wider stop-losses.
6. Risk Assessment:
- Always consider the model's limitations and potential for unexpected market events.
- Past performance doesn't guarantee future results.
Но помните, в экономике нет простых ответов. Иногда валюта укрепляется вопреки всем прогнозам, а иногда падает без видимых причин. Рынок часто живет ожиданиями, а не текущей реальностью.
Еще один важный момент — временной лаг. Изменения в экономике не сразу отражаются на курсе валют. Это как управлять огромным кораблем — вы поворачиваете штурвал, но корабль меняет курс не мгновенно. В вашем коде мы используем ежедневные данные, но некоторые экономические показатели обновляются реже. Это может вносить некоторую погрешность в прогнозы. В конечном счете, интерпретация результатов — это не меньше искусство, чем наука. Ваша модель — это мощный инструмент, но решения всегда принимает человек. Используйте эти данные мудро, и пусть ваши прогнозы будут точными!
Поиск неочевидных паттернов в экономических данных
Валютный рынок — это огромная торговая площадка. Он и так не отличается предсказуемыми движениями цены, но кроме этого есть особые события, повышающие в моменте волатильность и ликвидность. Это и есть глобальные события.
В нашем коде мы опираемся на экономические показатели:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
} Но что делать, когда случается что-то непредвиденное? Например, пандемия или политический кризис?
Тут бы пригодился какой-нибудь "индекс неожиданности". Представьте, мы добавляем в наш код что-то вроде:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Это позволило бы нам учитывать внезапные глобальные события и их постепенное затухание.
Но самое интересное: как это влияет на прогнозы? Иногда глобальные события могут полностью перевернуть наши ожидания. Например, во время кризиса "безопасные" валюты вроде доллара США или швейцарского франка могут укрепляться вопреки экономической логике.
В такие моменты у нашей модели падает продуктивность. И тут важно не паниковать, а адаптироваться. Может быть, стоит временно уменьшить горизонт прогнозирования или добавить больше веса недавним данным?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Помните: в мире валют, как и в танце, главное - уметь подстраиваться под ритм. Даже если этот ритм иногда меняется самым неожиданным образом!
Охота за аномалиями: как находить неочевидные паттерны в экономических данных
А теперь давайте поговорим о самом интересном — о поиске скрытых сокровищ в наших данных. Знаете, это как быть детективом, только вместо улик у нас цифры и графики.
В нашем коде мы уже используем довольно много экономических показателей. Но что если между ними есть какие-то неочевидные связи? Давайте попробуем их найти!
Для начала, можно посмотреть на корреляции между различными показателями:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Но это только начало. Настоящая магия начинается, когда мы начинаем искать нелинейные зависимости. Например, может оказаться, что изменение ВВП влияет на курс валюты не сразу, а с задержкой в несколько месяцев.
Давайте добавим в нашу функцию подготовки данных несколько "сдвинутых" показателей:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Теперь наша модель сможет уловить зависимости с задержкой в 3 и 6 месяцев.
Но самое интересное — это поиск совсем неочевидных паттернов. Например, может оказаться, что курс евро странным образом коррелирует с объемом продаж мороженого в США (это шутка, но вы поняли идею).
Для таких целей можно использовать методы выделения признаков, например, PCA (Principal Component Analysis):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1] Эти "скрытые паттерны" могут оказаться ключом к более точным прогнозам.
Не забывайте также о сезонности. Некоторые валюты могут вести себя по-разному в зависимости от времени года. Добавьте в свои данные информацию о месяце и дне недели — возможно, вы обнаружите что-то интересное!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Помните, в мире данных всегда есть место для открытий. Будьте любопытны, экспериментируйте, и кто знает — может быть, именно вы найдете тот самый паттерн, который перевернет мир трейдинга.
Заключение: перспективы экономического прогнозирования в алготрейдинге
Мы начали с простой идеи: можно ли предсказать движение валютных курсов, опираясь на экономические данные? И что мы выяснили? Оказывается, эта идея имеет под собой почву. Но это не так просто, как кажется на первый взгляд.
Наш код — это как весомое облегчение процесса для анализа экономических данных. Мы научились собирать информацию со всего мира, обрабатывать её, и даже заставили компьютер делать прогнозы. Это довольно продуктивный труд. Но помните, даже самая продвинутая модель машинного обучения — это всего лишь инструмент. Очень мощный инструмент, но всё же инструмент.
Мы увидели, как CatBoost Regressor может находить сложные взаимосвязи между экономическими показателями и курсами валют. Это дает нам выйти за рамки человеческих возможностей и весомо сократить время потраченное на обработку и анализ данных. Но даже он не может предсказать будущее со стопроцентной точностью.
Почему? Потому что экономика — это процесс, зависящий от множества факторов. Сегодня все следят за ценами на нефть, а завтра весь мир может перевернуть какое-нибудь неожиданное событие. Мы упоминали данный эффект говоря о "индексе неожиданности". Вот именно поэтому он так важен.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Берите отсюда. Старая статья по теме.
Пока что максимум что получается вытащить с мухи - это текущие данные на сегодня(((
я вот не пойму, чем вообще занимается компания MQ?
это сигнал автора, который выше
Этот сигнал был сделан чисто под тест одной модели на Сбере. Но я ее так и не протестировал, валются просто так в фонде денежного рынка уже. В основном я не торгую сам по своим моделям, не могу оторваться от идей по улучшениям и разработки))))Постоянно идут новые идеи по улучшению) А на бирже в основном инвестирую в акции, на долгосрок, покупаю акции на MOEX как нерез, и на KASE компании индекса Казбиржи
Пока что максимум что получается вытащить с мухи - это текущие данные на сегодня(((
Насколько понимаю, там данные собираются по подключенным к мониторингу счетам? Даже если там всё честно, то это же капля в море.
Имхо, больше доверия вызывают данные от CFTC, даже если это не спот а фьючерсы с опционами. Там есть история с 2005 года точно, хотя и в не очень удобной форме, но наверняка есть какие-то API для Python.
Решать конечно вам, всего лишь поделился своим мнением.
Этот сигнал был сделан чисто под тест одной модели на Сбере. Но я ее так и не протестировал, валются просто так в фонде денежного рынка уже. В основном я не торгую сам по своим моделям, не могу оторваться от идей по улучшениям и разработки))))Постоянно идут новые идеи по улучшению) А на бирже в основном инвестирую в акции, на долгосрок, покупаю акции на MOEX как нерез, и на KASE компании индекса Казбиржи
там несоответствие информации, к Вам никаких претензий