
Die Verwendung von Assoziationsregeln in der Forex-Datenanalyse

Einführung in das Konzept der Assoziationsregeln
Der moderne algorithmische Handel erfordert neue Analyseansätze. Der Markt verändert sich ständig, und die klassischen Methoden der technischen Analyse sind nicht mehr in der Lage, die komplexen Marktverhältnisse zu erkennen.
Ich arbeite seit langem mit Daten und habe festgestellt, dass viele erfolgreiche Ideen aus verwandten Bereichen kommen. Heute möchte ich meine Erfahrungen mit der Verwendung von Assoziationsregeln im Handel weitergeben. Diese Methode hat sich in der Einzelhandelsanalytik bewährt und ermöglicht es uns, Zusammenhänge zwischen Käufen, Transaktionen, Preisbewegungen und zukünftigem Angebot und Nachfrage zu erkennen. Was wäre, wenn wir sie auf den Devisenmarkt anwenden würden?
Die Grundidee ist einfach: Wir suchen nach stabilen Mustern des Preisverhaltens, Indikatoren und deren Kombinationen. Wie oft folgt zum Beispiel ein Anstieg des EURUSD auf einen Rückgang des USDJPY? Oder welche Bedingungen gehen starken Bewegungen am häufigsten voraus?
In diesem Artikel werde ich den gesamten Prozess der Erstellung eines Handelssystems auf der Grundlage dieser Idee zeigen. Wir werden:
- Historische Daten mit MQL5 sammeln
- Die Daten mit Python analysieren
- Signifikante Muster finden
- Sie in Handelssignale verwandeln
Warum gerade dieser Stapel? MQL5 eignet sich hervorragend für die Arbeit mit Börsendaten und die Automatisierung des Handels. Python wiederum bietet leistungsstarke Werkzeuge für die Analyse. Aus meiner Erfahrung kann ich sagen, dass eine solche Kombination für die Entwicklung von Handelssystemen sehr effektiv ist.
Der Code wird eine Menge interessanter Dinge enthalten, insbesondere im Bereich der Anwendung von Assoziationsregeln auf Forex.
Erhebung und Aufbereitung historischer Devisendaten
Es ist äußerst wichtig für uns, alle erforderlichen Daten zu sammeln und aufzubereiten. Nehmen wir die H1-Daten der wichtigsten Währungspaare für die letzten zwei Jahre (seit 2022) als Grundlage.
Jetzt werden wir ein MQL5-Skript erstellen, das die benötigten Daten sammelt und im CSV-Format exportiert:
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Datenverarbeitung in Python
Nach der Bildung eines Datensatzes ist es wichtig, die Daten richtig zu behandeln.
Zu diesem Zweck habe ich die spezielle Klasse ForexDataProcessor geschaffen, die sich um die ganze schmutzige Arbeit kümmert. Werfen wir einen Blick auf die wichtigsten Komponenten.
Wir werden mit dem Laden der Daten beginnen. Unsere Funktion arbeitet mit stündlichen Daten für die wichtigsten Währungspaare - EURUSD, GBPUSD, USDJPY und USDCHF. Die Daten sollten im CSV-Format vorliegen und die wichtigsten Preismerkmale enthalten.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Nach dem erfolgreichen Laden beginnt der interessanteste Teil - die Berechnung der technischen Indikatoren. Hier verlasse ich mich auf ein ganzes Arsenal an bewährten Instrumenten. Gleitende Durchschnitte helfen, Trends von unterschiedlicher Dauer zu erkennen. Der SMA(50) fungiert oft als dynamische Unterstützung oder Widerstand. Der RSI-Oszillator mit einer klassischen Periode von 14 eignet sich gut zur Bestimmung von überkauften und überverkauften Marktzonen. Der MACD ist unverzichtbar, um Schwung- und Umkehrpunkte zu erkennen. Bollinger Bänder geben ein klares Bild der aktuellen Marktvolatilität.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
Die Diskretisierung der Daten verdient besondere Aufmerksamkeit. Alle kontinuierlichen Werte müssen in klare Kategorien unterteilt werden. In diesem Zusammenhang ist es wichtig, eine goldene Mitte zu finden - eine zu steile Aufteilung erschwert die Suche nach Mustern, und eine zu enge Aufteilung führt zum Verlust wichtiger Marktnuancen. Um zum Beispiel den Trend zu bestimmen, funktioniert eine einfachere Einteilung besser - nach der Position des Preises im Verhältnis zum Durchschnitt:
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Auch Kerzenmuster erfordern einen besonderen Ansatz. Auf der Grundlage der statistischen Analyse unterscheide ich Doji bei der Mindestgröße des Kerzenkörpers, Long_Bullish und Long_Bearish bei extremen Kursbewegungen. Anhand dieser Klassifizierung lassen sich Momente der Marktunentschlossenheit und starke Impulsbewegungen klar erkennen.
Am Ende der Verarbeitung werden alle Währungspaare zu einem einzigen Datenfeld mit einer gemeinsamen Zeitskala zusammengefasst. Dieser Schritt ist von grundlegender Bedeutung - er eröffnet die Möglichkeit, nach komplexen Beziehungen zwischen verschiedenen Instrumenten zu suchen. Jetzt können wir sehen, wie sich der Trend eines Paares auf die Volatilität eines anderen Paares auswirkt oder wie sich Kerzenmuster auf das Handelsvolumen des gesamten Marktes beziehen.
Implementierung des Apriori-Algorithmus in Python
Nach der Aufbereitung der Daten gehen wir zur entscheidenden Phase über - der Implementierung des Apriori-Algorithmus, um Assoziationsregeln in unseren Finanzdaten zu finden. Wir passen den Apriori-Algorithmus, der ursprünglich für die Analyse von Marktkörben entwickelt wurde, für die Arbeit mit Zeitreihen von Währungspaaren an.
Im Zusammenhang mit dem Devisenmarkt ist eine „Transaktion“ ein Satz von Zuständen verschiedener Indikatoren und Währungspaare zu einem bestimmten Zeitpunkt. Zum Beispiel:- EURUSD_Trend = Uptrend
- GBPUSD_RSI_Zone = Overbought
- USDJPY_Volatility_Zone = High
Der Algorithmus sucht nach häufig vorkommenden Kombinationen solcher Zustände, auf deren Grundlage dann Handelsregeln gebildet werden.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Anpassung von Assoziationsregeln für die Analyse von Währungspaaren
Bei meiner Arbeit an der Anpassung des Apriori-Algorithmus für den Devisenmarkt bin ich auf interessante Herausforderungen gestoßen. Obwohl diese Methode ursprünglich für die Analyse von Einkäufen in Geschäften entwickelt wurde, erschien mir ihr Potenzial für Forex vielversprechend.
Die Hauptschwierigkeit bestand darin, dass sich der Devisenmarkt grundlegend von einem normalen Einkauf in einem Geschäft unterscheidet. Im Laufe der Jahre, in denen ich an den Finanzmärkten tätig war, habe ich mich daran gewöhnt, mit ständig wechselnden Preisen und Indikatoren umzugehen. Aber wie wendet man einen Algorithmus an, der normalerweise nur nach Verbindungen zwischen Bananen und Milch auf Supermarktquittungen sucht?
Als Ergebnis meiner Experimente entstand ein System von fünf Messgrößen. Ich habe jedes von ihnen gründlich getestet.
„Support“ erwies sich als eine sehr schwierige Kennzahl. Einmal hätte ich beinahe eine Regel mit hervorragender Leistung in ein Handelssystem aufgenommen, aber die Unterstützung betrug nur 0,02. Zum Glück habe ich es rechtzeitig bemerkt - in der Praxis würde eine solche Regel nur einmal in hundert Jahren greifen!
„Confidence“ erwies sich als einfacher. Wenn man am Markt arbeitet, lernt man schnell, dass selbst eine Wahrscheinlichkeit von 70 % ein ausgezeichneter Indikator ist. Die Hauptsache ist, dass man mit den verbleibenden 30 % der Risiken klug umgeht. Wir sollten das Risikomanagement immer im Auge behalten. Ohne sie werden Sie einen Rückschlag oder sogar einen Abfluss erleiden, selbst wenn Sie einen Gral in den Händen halten.
„Lift“ ist zu meinem Lieblingsindikator geworden. Nach Hunderten von Teststunden ist mir ein Muster aufgefallen: Regeln mit einem Lift von über 1,5 funktionieren tatsächlich auf dem realen Markt. Diese Entdeckung hatte einen tiefgreifenden Einfluss auf meine Herangehensweise an die Signalsortierung.
Der Umgang mit „Leverage“ erwies sich als lustig. Zuerst wollte ich sie ganz aus dem System ausschließen, weil ich sie für nutzlos hielt. Aber während einer besonders volatilen Marktphase half es, die meisten falschen Signale auszusortieren.
„Conviction“ wurde als letztes hinzugefügt, nachdem ich in den Foren recherchiert hatte. Das hat mir geholfen zu verstehen, wie wichtig dieser Indikator für die Beurteilung der tatsächlichen Bedeutung der gefundenen Muster ist.
Das Überraschendste für mich war, wie der Algorithmus unerwartete Verbindungen zwischen verschiedenen Währungspaaren findet. Wer hätte zum Beispiel gedacht, dass bestimmte Muster im EURUSD die Entwicklung des USDJPY so genau vorhersagen können? In den 9 Jahren, in denen ich auf dem Markt tätig war, habe ich viele der Beziehungen, die der Algorithmus entdeckt hat, nicht bemerkt. Obwohl Pair-Trading, Basket-Trading und Arbitrage einst meine Domäne waren, erinnere ich mich noch an die Zeiten, als cmillion gerade anfing, seine auf den gegenseitigen Bewegungen von Paaren basierenden Roboter zu entwickeln.
Jetzt setze ich meine Forschung fort und teste neue Kombinationen von Indikatoren und Zeiträumen. Der Markt ist in ständiger Bewegung, und jeder Tag bringt neue Entdeckungen. In der nächsten Woche plane ich, die Ergebnisse der Tests des Systems mit jährlichen Daten sowie die ersten Live-Ergebnisse des Algorithmus beim Live-Demohandel zu veröffentlichen. Dort gibt es mehrere sehr interessante Erkenntnisse.
Um ehrlich zu sein, habe ich nicht einmal erwartet, dass dieses Projekt so weit gehen würde. Alles begann als einfaches Experiment mit Data Mining und dem Versuch, alle Marktbewegungen für die Bedürfnisse von Klassifizierungsalgorithmen starr zu klassifizieren, und entwickelte sich schließlich zu einem vollwertigen Handelssystem. Ich glaube, ich beginne gerade erst, das wahre Potenzial dieses Ansatzes zu verstehen.
Merkmale der Implementierung für Forex
Gehen wir noch einmal kurz auf den Code selbst zurück. Unser Code enthält mehrere wichtige Anpassungen des Algorithmus für die Verarbeitung von Finanzdaten:
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Diese Gruppierung trägt dazu bei, aussagekräftigere Kombinationen von Indikatoren zu finden und die Komplexität der Berechnungen zu verringern.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Wir wählen nur Regeln mit einer starken statistischen Signifikanz (Lift > 1,5) und obligatorischer Einbeziehung von Trendindikatoren oder RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
Die gewichtete Punktzahl hilft, die Regeln nach ihrem potenziellen Nutzen für den Handel einzustufen.
Visualisierung der gefundenen Assoziationen
Nachdem wir die Assoziationsregeln gefunden haben, sollten wir sie richtig visualisieren und analysieren. Zu diesem Zweck habe ich die spezielle Klasse ForexRulesVisualizer entwickelt, die mehrere Möglichkeiten der visuellen Analyse der gefundenen Muster bietet.
Verteilung der Regelmetriken
Der erste Schritt der Analyse besteht darin, die Verteilung der wichtigsten Metriken der gefundenen Regeln zu verstehen. Der Verteilungsgraph von „Support“, „Confidence“, „Lift“ und „Leverage“ hilft, die Qualität der gefundenen Regeln zu bewerten und ggf. die Algorithmusparameter anzupassen.
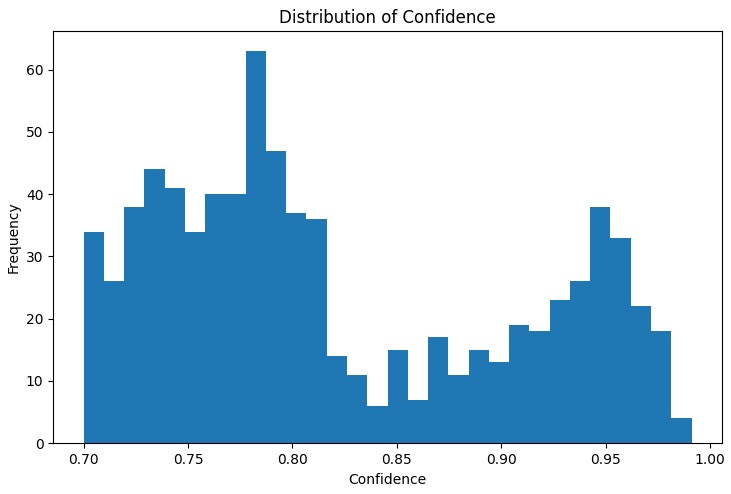
Ein besonders nützliches Instrument war das interaktive Netzdiagramm, das die Zusammenhänge zwischen den verschiedenen Marktbedingungen deutlich macht. In diesem Diagramm sind die Knoten die Indikatorzustände (z. B. „EURUSD_Trend=Uptrend“ oder „USDJPY_RSI_Zone=Overbought“), und die Ränder stellen die gefundenen Regeln dar, wobei die Dicke der Ränder proportional zum „Lift“-Wert ist.
Heatmap der Interaktionen zwischen Währungspaaren 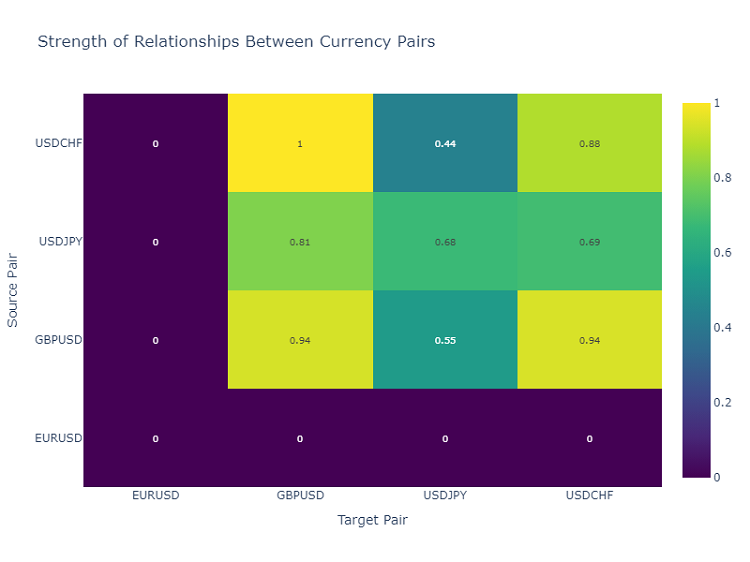
Um die Beziehungen zwischen Währungspaaren zu analysieren, verwende ich eine Heatmap, die die Stärke der Beziehungen zwischen verschiedenen Instrumenten anzeigt. Auf diese Weise lassen sich Paare ermitteln, die sich am häufigsten gegenseitig beeinflussen, was für den Aufbau eines diversifizierten Handelsportfolios von entscheidender Bedeutung ist.
Erstellung von Handelssignalen
Sobald wir die Assoziationsregeln gefunden und visualisiert haben, besteht der nächste wichtige Schritt darin, sie in Handelssignale umzuwandeln. Zu diesem Zweck habe ich die Klasse ForexSignalGenerator entwickelt, die den aktuellen Zustand des Marktes analysiert und auf der Grundlage der gefundenen Regeln Handelssignale erzeugt.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Bewertung der Stärke von Regeln
Nach langen Experimenten mit der Visualisierung der Regeln ist es nun an der Zeit für den schwierigsten Teil - die Erstellung echter Handelssignale. Ich gebe zu, dass mich diese Aufgabe ganz schön ins Schwitzen gebracht hat. Es ist eine Sache, schöne Muster in Charts zu finden, und eine ganz andere, sie in ein funktionierendes Handelssystem zu verwandeln.
Ich habe beschlossen, ein separates Modul ForexSignalGenerator zu erstellen. Zuerst wollte ich nur Signale nach den strengsten Regeln erzeugen, aber ich habe schnell gemerkt, dass alles viel komplizierter ist. Der Markt verändert sich ständig, und eine Regel, die gestern gut funktioniert hat, kann heute nicht mehr funktionieren.
Ich musste ernsthaft versuchen, die Stärke der Vorschriften zu bewerten. Nach mehreren erfolglosen Versuchen habe ich ein skalierendes System entwickelt. Ich hatte die größten Schwierigkeiten bei der Auswahl der Verhältnisse - ich habe wahrscheinlich Dutzende von Kombinationen ausprobiert. Am Ende habe ich mich darauf geeinigt, dass „Lift“ 40 % der Endbewertung ausmacht (dies ist ein wirklich wichtiger Indikator), „Confidence“ 30 %, „Support“ 20 % und „Leverage“ 10 %.
Interessanterweise wurden oft die stärksten Signale erzielt, wenn die Regel eine Trendkomponente enthielt. Ich habe sogar einen besonderen Bonus von 20 % auf die Stärke solcher Regeln hinzugefügt, und die Praxis hat gezeigt, dass dies gerechtfertigt ist.
Auch bei der Analyse der aktuellen Marktlage musste ich hart arbeiten. Zunächst habe ich einfach die aktuellen Werte der Indikatoren mit den Bedingungen der Regeln verglichen. Aber dann wurde mir klar, dass ich den breiteren Kontext berücksichtigen muss. Ich habe zum Beispiel den allgemeinen Trend der letzten Zeiträume, den Stand der Volatilität und sogar die Tageszeit überprüft.
Derzeit analysiert das System etwa 20 verschiedene Parameter für jedes Währungspaar. Einige der Muster, die ich gefunden habe, haben mich wirklich überrascht.
Natürlich ist das System noch lange nicht perfekt. Manchmal ertappe ich mich bei dem Gedanken, dass ich grundlegende Faktoren hinzufügen muss. Ich habe dies jedoch auf einen späteren Zeitpunkt verschoben. Zunächst möchte ich die aktuelle Version fertigstellen.
Signalsortierung und -aggregation
Während der Entwicklung des Systems wurde mir schnell klar, dass es nicht ausreicht, einfach nur Regeln zu finden - wir brauchen eine strenge Kontrolle der Qualität der Signale. Nach einigen erfolglosen Geschäften wurde klar, dass das Sortieren vielleicht noch wichtiger ist als das Finden von Mustern selbst.
Ich habe mit einem einfachen Schwellenwert für die Mindestregelstärke begonnen. Zuerst hatte ich den Wert auf 0,5 gesetzt, aber ich bekam immer wieder falsch positive Ergebnisse. Nach zwei Testwochen habe ich den Wert auf 0,7 erhöht, und die Situation hat sich merklich verbessert. Die Zahl der Signale ist um etwa ein Drittel zurückgegangen, aber ihre Qualität hat deutlich zugenommen.
Die zweite Sortierstufe entstand nach einem besonders ärgerlichen Vorfall. Es gab eine Regel mit hervorragender Performance, nach der ich eine Position eröffnete, aber der Markt ging genau in die entgegengesetzte Richtung. Als ich anfing, der Sache nachzugehen, stellte sich heraus, dass andere Regeln zu diesem Zeitpunkt entgegengesetzte Signale gaben. Seitdem überprüfe ich die Konsistenz und öffne nur, wenn mehrere Regeln in dieselbe Richtung weisen.
Der Umgang mit der Volatilität erwies sich als interessant. Ich habe festgestellt, dass das System in ruhigen Zeiten wie ein Uhrwerk funktioniert, aber sobald der Markt lebhafter wird, beginnen die Probleme. Also habe ich einen dynamischen Filter von ATR hinzugefügt. Wenn die Volatilität in den letzten 20 Tagen über dem 75. Perzentil liegt, erhöhen wir die Anforderungen an die Stärke der Regeln um 20 %.
Der schwierigste Teil war die Überprüfung der widersprüchlichen Signale. Es kommt vor, dass einige Regeln zum Kauf, andere zum Verkauf raten, und alle Regeln haben gute Parameter. Ich habe verschiedene Ansätze ausprobiert, mich aber schließlich für eine einfache Lösung entschieden: Wenn es signifikante Widersprüche in den Signalen gibt, lassen wir diese Situation aus. Auf diese Weise verlieren wir zwar einige Chancen, aber wir verringern die Risiken erheblich.
Nächsten Monat werde ich die Sortierung nach der Zeit hinzufügen. Ich habe festgestellt, dass die Regeln zu bestimmten Zeiten deutlich schlechter funktionieren. Dies gilt insbesondere in Zeiten geringer Liquidität und bei der Veröffentlichung wichtiger Nachrichten. Ich denke, dass dies den Prozentsatz der erfolgreichen Abschlüsse weiter erhöhen dürfte.
Testergebnisse
Nach mehreren Monaten der Entwicklung des Systems stand ich vor einer wichtigen Frage: Wie kann ich die Stärke jeder gefundenen Regel richtig bewerten? Auf dem Papier sah alles ganz einfach aus, aber der reale Markt offenbarte schnell alle Schwächen des ursprünglichen Ansatzes.
Nach langen Experimenten bin ich zu einem System von Gewichtungen für verschiedene Faktoren gekommen. Ich habe „Lift“ zum Hauptbestandteil gemacht (40 % Einfluss) - die Praxis hat gezeigt, dass dies ein wirklich kritischer Indikator ist. „Confidence“ erhält 30 % - schließlich bedeutet das Vertrauen in die Regel auch viel. „Support“ und „leverage“ haben ein geringeres Gewicht erhalten - sie wirken eher wie Filter.
Die Signalsortierung erwies sich als eine andere Geschichte. Zuerst habe ich versucht, nach allen Regeln der Kunst zu handeln, aber ich habe meinen Fehler schnell erkannt. Ich musste also ein mehrstufiges Sortiersystem einführen. Zunächst sortieren wir schwache Regeln auf der Grundlage einer Schwelle einer Mindeststärke aus. Dann prüfen wir, ob das Signal durch mehrere Regeln bestätigt wird - einzelne Regeln sind in der Regel weniger zuverlässig.
Als besonders wichtig erwies sich die Berücksichtigung der Volatilität. In ruhigen Zeiten funktionierte das System einwandfrei, aber sobald die Volatilität sprunghaft anstieg, nahm die Zahl der Fehlsignale drastisch zu. Ich musste dynamische Filter hinzufügen, die mit zunehmender Volatilität strenger werden.
Die Erprobung des Systems dauerte fast drei Monate. Ich habe eine zweijährige Historie für vier große Paare erstellt. Die Ergebnisse waren ziemlich unerwartet. Zum Beispiel zeigte USDJPY die beste Performance mit 65% profitable Handelsgeschäfte und einem RR 1,6. Aber GBPUSD war enttäuschend - nur 58 % mit RR 1,4.
Interessanterweise zeigten Regeln mit einem „Lift“ über 2,0 und einem „Confidence“ über 0,8 durchweg die besten Ergebnisse für alle Paare. Offensichtlich sind diese Niveaus wirklich Schwellenwerte einer natürlichen Signifikanz auf dem Forex-Markt.
Weitere Verbesserungen
Derzeit sehe ich mehrere Möglichkeiten zur Verbesserung des Systems. Erstens müssen die Parameter der Vorschriften dynamischer gestaltet werden - der Markt verändert sich, und das System muss sich anpassen. Zweitens mangelt es eindeutig an der Berücksichtigung der Makroökonomie und des Nachrichtenhintergrunds. Ja, es wird das System verkomplizieren, aber die möglichen Vorteile sind es wert.
Die Anwendung von adaptiven Filtern scheint besonders interessant zu sein. Unterschiedliche Marktphasen erfordern eindeutig unterschiedliche Systemeinstellungen. Im Moment ist es noch sehr grob implementiert, aber ich sehe schon mehrere Möglichkeiten, es zu verbessern.
Nächste Woche werde ich mit dem Testen einer neuen Version mit dynamischer Optimierung der Positionsgrößen beginnen. Vorläufige Ergebnisse auf der Grundlage historischer Daten sehen vielversprechend aus, aber der reale Markt wird, wie immer, seine eigenen Anpassungen vornehmen.
Schlussfolgerung
Die Verwendung von Assoziationsregeln im algorithmischen Handel eröffnet interessante Möglichkeiten, nicht offensichtliche Marktmuster zu finden. Der Schlüssel zum Erfolg liegt hier in der richtigen Datenaufbereitung, der sorgfältigen Auswahl der Regeln und einem gut durchdachten Signalerzeugungssystem.
Es ist wichtig, daran zu denken, dass jedes Handelssystem eine ständige Überwachung und Anpassung an sich ändernde Marktbedingungen erfordert. Assoziative Regeln sind ein leistungsfähiges Analyseinstrument, aber sie müssen in Verbindung mit anderen technischen und fundamentalen Analysemethoden eingesetzt werden.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16061
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Offenbar wird davon ausgegangen, dass der Leser bereits Kenntnisse über eine solche Methode hat, und wenn nicht?
Ich verstehe vor allem die erwähnten Kennzahlen nicht:
Lift ist zu meinem Lieblingsindikator geworden. Nach Hunderten von Teststunden ist mir ein Muster aufgefallen - Regeln mit einem Lift von über 1,5 funktionieren auf dem realen Markt wirklich. Diese Entdeckung hat meine Herangehensweise an die Filterung von Signalen stark beeinflusst.
Wenn ich die Methode richtig verstanden habe, wird in Quantensegmenten nach korrelierenden Signalen gesucht. Aber ich habe den nächsten Schritt nicht verstanden. Was ist das Ziel? Ich nehme an, dass die resultierenden Regeln mit dem Ziel verglichen und anhand der Metriken bewertet werden.
Wenn ja, entspricht dies meiner Methode, und es ist interessant, Leistung und Effizienz zu bewerten.