
Volumetrische neuronale Netzwerkanalyse als Schlüssel zu zukünftigen Trends

In einer Zeit, in der der gesamte Handel mehr und mehr automatisiert wird, ist es nützlich, sich an die Axiome der Händler aus der Vergangenheit zu erinnern. Einer von ihnen behauptet, das Volumen sei der Schlüssel zu allem. Die technische Analyse und die Volumenanalyse wären in der Tat nützlich und sehr interessant, um sie als Merkmale in das maschinelle Lernen einzuspeisen. Vielleicht ergibt sich daraus bei richtiger Interpretation ein Ergebnis. In diesem Artikel wird der Ansatz zur Analyse des Handelsvolumens und volumenbasierter Merkmale unter Verwendung der LSTM-Architektur bewertet.
Unser System analysiert Volumenanomalien und sagt künftige Kursbewegungen voraus. Die wichtigsten Merkmale des Systems sind die Erkennung anormaler Volumina, das Clustering von Volumina und das Modelltraining direkt über das Bündel von Python + MetaTrader 5.
Wir werden auch einen umfassenden Backtest mit Visualisierung der Ergebnisse durchführen. Das Modell erweist sich als besonders effizient für den stündlichen Zeitrahmen des russischen Aktienmarktes, was durch die Ergebnisse der Tests mit historischen Daten der Sberbank-Aktie im letzten Jahr bestätigt wird. In diesem Artikel werde ich die Architektur des Systems, die Grundsätze seiner Funktionsweise und die praktischen Ergebnisse seiner Anwendung eingehend untersuchen.
Aufschlüsselung des Codes: Von Daten zu Vorhersagen
Lassen Sie uns in die Tiefe gehen und versuchen, ein System zu entwickeln, das wirklich versteht, was jetzt mit den Mengen passiert. Beginnen wir mit einfachen Dingen - der Art und Weise, wie wir Daten empfangen und verarbeiten. Einerseits ist es nicht kompliziert - die Daten herunterladen und arbeiten... Aber der Teufel steckt wie immer im Detail.
Datenquelle: Vertiefung
Nachfolgend finden Sie unsere Datenladefunktion.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Sie scheint ziemlich einfach zu sein. Ich verwende absichtlich copy_rates_range anstelle des einfacheren copy_rates_from. Dies ist notwendig, um bei der Arbeit mit illiquiden Instrumenten keine Nullperioden zu verlieren.
Im weiteren Verlauf beginnen wir, mit Merkmalen und Indikatoren zu arbeiten.
Vorverarbeitung: Die Kunst der Datenaufbereitung
Verschwenden wir keine Zeit mit der Auswahl der Merkmale, sondern konzentrieren wir uns auf einige der offensichtlichsten.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
Die Auswahl von Merkmalen ist wie das Stimmen eines Orchesters. Jede Funktion hat ihre eigene Rolle und ihren eigenen spezifischen Klang in der Datensymphonie. Schauen wir uns unser Basiseinstellung an.
Die erste ist die einfachste: Wir nehmen einen gleitenden Durchschnitt des Volumens. Das Durchschnittsvolumen mit der Periode von 5 fängt die geringsten Schwankungen auf, während die Periode von 20 auf viel stärkere Volumentrends reagiert.
Interessant könnte auch das Verhältnis des Volumens zu seinem Durchschnitt sein. Bei einem starken Sprung in der Zukunft kommt es sehr oft zu einem kräftigen Kursimpuls.
Wir betrachten auch das Kursmomentum und das Volumenmomentum der letzten 24 Balken.
Es gibt ein noch interessanteres Merkmal, die sogenannte Volumenvolatilität. Ich würde diese Sache als Indikator für die Nerven des Marktes bezeichnen. Wenn die Volatilität des Volumens zunimmt, kann dies ein Hinweis auf einen starken Markteintritt ernsthafter Marktteilnehmer sein.
Die Korrelation von Preis und Volumen wird in unserem Modell ebenfalls berücksichtigt. Am Ende werden wir uns all diese Zeichen live ansehen und unsere neu erstellten Indikatoren visualisieren.
Engpass bei der Leistung
Um eine Überlastung des Systems zu vermeiden, können wir Datenstapelverarbeitung und parallele Datenverarbeitung einsetzen. Mit anderen Worten: Wir teilen die Daten in kleine Teile auf und verarbeiten sie parallel.
Diese einfache Technik beschleunigt die Datenverarbeitung um ein Vielfaches und hilft auch, Probleme mit Speicherlecks bei großen Datenmengen zu vermeiden.
Im nächsten Teil des Artikels werde ich auf den interessantesten Teil eingehen - wie das System abnormale Volumina erkennt und was dann geschieht.
Auf der Suche nach den „schwarzen Schwänen“: Wie erkennt man anomale Volumen?
Wir haben alle davon gehört, was abnormale Volumina sind und wie man sie in einem Chart erkennen kann. Vielleicht kann jeder erfahrene Händler sie erkennen. Aber wie können wir diese Erfahrung in den Code einbinden? Wie lässt sich die Logik der Suche nach solchen Bänden formalisieren?
Auf der Suche nach Anomalien
Nach einer Reihe von Experimenten entschied sich meine Forschung in diesem Bereich für die Isolation Forest Methode. Warum diese Methode? Nun, klassische Methoden wie z-Scores oder Perzentilwerte können eine lokale Anomalie, eine kleine, übersehen, aber wichtig sind nicht die absoluten oder prozentualen Werte, sondern die Mengen, die sich vom Rest abheben - und aus dem allgemeinen Kontext herausfallen.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Natürlich wäre es besser, mit den Parametern herumzuspielen, und eine noch bessere Lösung wäre es, alle Modelleinstellungen mit Algorithmen wie BGA auszuwählen. Ich habe den Wert auf den in Lehrbüchern empfohlenen Wert von 0,05 gesetzt, was 5 % Anomalien entspricht. Aber der reale Markt ist viel lauter, als man sich vorstellen kann. Deshalb wurde die Messlatte ein wenig höher gelegt. Es ist auch nützlich, die Anomalien mit eigenen Augen zu sehen, und zwar in Verbindung mit den Kursbewegungen (wir werden weiter unten auf dieses Thema zurückkommen).
Clustering: Muster finden
Anomalien reichen für eine gute Vorhersage nicht aus. Wir brauchen auch eine Clusterung der Volumes. Wir konzentrieren uns auf die folgende Clustering-Option:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Die für das Clustering gewählten Merkmale sind recht einfach. Ich denke, es wäre seltsam, nur die eigentlichen Volumina selbst zu clustern, warum sollten wir sonst unsere Merkmale und Indikatoren erstellen? Die Anzahl der Merkmale sowie die Volumenindikatoren könnten jedoch verbessert werden.
Die drei Cluster wurden gewählt, weil ich alle Volumina bedingt in „Hintergrund- oder Akkumulationsvolumina“, „Lauf- und Bewegungsvolumina“ und „extreme Bewegungsvolumina“ unterteilen würde.
Unerwartete Funde
Die Auswertung der Daten ergab mehrere Muster und Sequenzen, z. B. folgt auf abnormale Volumina die dritte Gruppe von Volumina, dann folgt das aktive Volumen, und erst danach bewegen sich die Kurse in die eine oder andere Richtung.
Dies zeigt sich vor allem in den ersten Stunden nach Eröffnung der Börsensitzung. Hier wäre es sinnvoll, eine Heatmap der Cluster und der damit verbundenen Kursbewegungen zu erstellen.
Neuronales Netz: Wie man eine Maschine trainiert, den Markt zu lesen
Da ich schon seit langem mit neuronalen Netzen arbeite, wäre es sinnvoll, ein neuronales Netz auf unsere Volumenanalyse anzuwenden. Ich habe die LSTM-Architektur noch nicht ausprobiert, aber ich habe mich schließlich dazu entschlossen, nachdem ich Beispiele dieser Architektur in anderen Bereichen gesehen habe.
Schauen wir die uns genauer an.
Architektur: Weniger ist mehr
Einfacher ist besser. Ich habe mir eine erstaunlich einfache Architektur ausgedacht:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
Auf den ersten Blick sieht die gesamte Architektur sehr primitiv aus, nur zwei LTSM-Schichten und eine lineare Schicht. Aber die Kraft liegt in der Einfachheit. Denn wenn wir ein umfangreicheres Netz mit tieferem Lernen aufbauen, kommt es leider zu einer Überanpassung. Ursprünglich habe ich ein viel komplexeres Netz aufgebaut - mit drei LSTM-Schichten, zusätzlichen voll verbundenen Schichten und einer komplexen Dropout-Struktur. Die Ergebnisse waren beeindruckend... Auf Testdaten. Doch sobald das Netz auf den realen Langzeitmarkt traf, brach alles zusammen. Das heißt, wir haben eine Überanpassung festgestellt.
Kampf gegen Überanpassung
Die Überanpassung ist das größte Problem bei modernen neuronalen Netzen. Das neuronale Netz ist hervorragend in der Lage, Beziehungen in Testdatenbereichen zu erkennen, ist aber unter realen Marktbedingungen völlig verloren. Hier ist, wie ich versuche, dieses Problem speziell in der vorgestellten Architektur zu lösen:
- Eine einzige Ebene kann die Komplexität der Beziehung zwischen Volumen und Preis nicht bewältigen.
- Drei Ebenen können Verbindungen finden, wo es sie eigentlich nicht gibt.
Die Größe der versteckten Schicht wird wie üblich gewählt - 64 Neuronen. Es wäre vielleicht besser, mehr Neuronen zu verwenden. In Zukunft, wenn ich eine funktionierende Lösung zur Bekämpfung der Überanpassung vorstelle, werden wir eine komplexere Architektur mit mehr Neuronen verwenden können.
Eingangsdaten: Die Kunst der Merkmalsauswahl
Schauen wir uns die Eingabemerkmale für das Training an:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Wir können viel mit der Menge der Merkmale experimentieren. Wir können technische Indikatoren, Preisderivate, Volumenderivate, Preis- und Volumenderivate hinzufügen, was immer wir wollen. Aber bedenken Sie, dass mehr Funktionen nicht immer die Qualität der Prognosen verbessern. Und jedes scheinbar logische Merkmal kann sich in Wirklichkeit als bloßes Rauschen in den Daten erweisen.
Die Kombination von „volume_cluster“ und „is_anomaly“ sieht hier interessant aus. Einzeln betrachtet sind die Funktionen bescheiden, aber in der Synergie sind sie sehr interessant. Wenn anormale Volumina in bestimmten Clustern auftreten, hat dies ungewöhnliche Auswirkungen auf die Prognosen.
Unerwartete Entdeckung
Das System erwies sich in Zeiten starker Kursbewegungen als besonders effektiv. Er zeigt sich auch in Momenten, die die meisten Händler als unlesbar bezeichnen würden, d.h. in Seitwärtsmärkten und während Konsolidierungen. In diesen Momenten sieht das System zur Analyse von Anomalien und Volumenclustern, was unserem Blick nicht zugänglich ist.
Im nächsten Abschnitt werde ich darüber sprechen, wie sich dieses System im realen Handel bewährt hat und konkrete Beispiele für Signale geben.
Von der Prognose zum Handel: Signale in Gewinne wandeln
Jeder algorithmische Händler weiß: Ein einfaches Prognosemodell ist nicht ausreichend. Sie muss zu einer funktionierenden Handelsstrategie entwickelt werden. Doch wie lässt sich unser Modell in der Praxis anwenden? Lassen Sie uns das herausfinden. Im nächsten Teil des Artikels werden Sie nicht nur trockene Theorie finden, sondern echte Praxis, mit echtem Test-Handel, Stärkung des Algorithmus, Verbesserung des Kampfes gegen Überanpassungen, aber für jetzt, werden wir mit dem üblichen theoretischen Teil unserer Forschung auskommen.
Anatomie der Handelssignale
Bei der Entwicklung einer Handelsstrategie ist die Generierung von Handelssignalen einer der wichtigsten Punkte. Bei meiner Strategie werden die Signale auf der Grundlage von Modellvorhersagen generiert, die die erwartete Rendite für den nächsten Zeitraum widerspiegeln.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Auswahl der Signalschwelle
Einerseits können wir den Schwellenwert einfach über 0 setzen. In diesem Fall werden wir viele Signale generieren, die jedoch aufgrund von Spreads, Provisionen und Marktrauschen verrauscht sein werden. Dieser Ansatz kann zu einer großen Anzahl von Fehlsignalen führen, was sich negativ auf die Effizienz der Strategie auswirkt.
Die vernünftigste Entscheidung scheint daher darin zu bestehen, den Schwellenwert für die prognostizierte Rentabilität auf 0,1 %-0,2 % anzuheben. Auf diese Weise können wir den größten Teil des Rauschens ausschalten und die Auswirkungen von Provisionen reduzieren, da Signale nur dann erzeugt werden, wenn es signifikante vorhergesagte Preisänderungen gibt.
signal_threshold = 0.001 # Threshold 0.1%
Anlegen von Signalen unter Berücksichtigung der Verschiebung
Sobald die Signale erzeugt sind, werden sie auf die Preise angewandt, wobei eine Vorwärtsverschiebung um 24 Perioden berücksichtigt wird. Dies ermöglicht es uns, die Zeitspanne zwischen einer Handelsentscheidung und ihrer Umsetzung zu berücksichtigen.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Eine Verschiebung um 24 Perioden bedeutet, dass das zum Zeitpunkt t erzeugte Signal auf den Preis zum Zeitpunkt t + 24 angewendet wird. Dies ist wichtig, weil Handelsentscheidungen in der Realität nicht sofort umgesetzt werden können. Dieser Ansatz ermöglicht eine realistischere Bewertung der Effizienz der Handelsstrategie.
Berechnung der Rentabilität der Strategie
Die Rentabilität der Strategie wird als das Produkt aus dem verschobenen Signal und der Preisänderung berechnet:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Wenn das Signal gleich 1 ist, ist die Rentabilität der Strategie gleich der Preisänderung (price_change). Wenn das Signal gleich -1 ist, entspricht die Rentabilität der Strategie der negativen Preisänderung (-price_change). Wenn das Signal gleich 0 ist, ist die Rentabilität der Strategie gleich Null.
Die Verschiebung der Signale um 24 Perioden ermöglicht es uns also, die Verzögerung zwischen einer Handelsentscheidung und ihrer Umsetzung zu berücksichtigen, was die Bewertung der Effizienz der Strategie realistischer macht.
Die goldene Mitte
Nach wochenlangen Tests habe ich mich auf einen Schwellenwert von 0,1 % geeinigt. Hier ist der Grund dafür:
- Bei diesem Schwellenwert erzeugt das System recht häufig Signale
- Etwa 52-63% der Handelsgeschäfte sind profitabel
- Der durchschnittliche Gewinn pro Handelsgeschäfte beträgt etwa das 2,5-fache der Provision
Die ungewöhnlichste Entdeckung ist, dass die meisten falschen Signale auch in zeitlichen Clustern konzentriert werden können. Wenn Sie möchten, können Sie einen solchen Zeitfilter in Erwägung ziehen, und wir werden ihn später im nächsten Teil des Artikels betrachten.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Risikomanagement
Die Logik des Positionserwerbs und die Logik der Verwaltung offener Handelsgeschäfte (Unterstützung von Handelsgeschäften während des Handels) stellen eine separate Geschichte dar. Einerseits ist die naheliegendste Lösung, feste Stop-Loss‘ und Take-Profits zu verwenden, aber der Markt ist zu unvorhersehbar und dynamisch, als dass sich Verlust- und Gewinngrenzen mit gewöhnlicher formaler Logik beschreiben ließen.
Unsere Lösung ist recht trivial - wir nutzen die prognostizierte Volatilität, um dynamisch die Stop-Loss‘ zu setzen:
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Auch dieser Ansatz muss weiter getestet werden. Es ist auch möglich, das Risikoanalysemodell VaR anzuwenden, um Stop-Loss‘ und Take-Profits nach diesem alten, aber zuverlässig wirksamen System auszuwählen.
Unerwartete Funde
Eine interessante Erkenntnis ist, dass eine Reihe von aufeinander folgenden Signalen sehr starke Bewegungen vorhersagen kann. Problematisch wird es auch, wenn die Marktvolatilität im Durchschnitt sehr stark ansteigt, dann reicht unser Schwellenwert für effektives Handeln nicht mehr aus. Wie Sie sehen, sind die Perioden des Drawdowns in der Grafik genau mit hoher Volatilität verbunden... Aber für uns ist das kein Problem! Wir werden dieses Problem im nächsten Abschnitt lösen und beseitigen.
Visualisierung und Protokollierung: Wie man verhindert, in Daten zu ertrinken
Es ist auch sehr wichtig, dass wir das Protokollierungssystem nicht vergessen. Im Allgemeinen ist alles, was mit Ausdrucken, Protokollen, Ausgaben und Programmkommentaren zu tun hat, in der Debugging-Phase wichtig. Auf diese Weise können Sie die Quelle von Problemen in Ihrem Code sehr schnell und effizient finden.
Protokollierungssystem: Details Angelegenheit
Das Protokollierungssystem basiert auf einem einfachen, aber effizienten Format:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
Was ist daran so schwierig, werden Sie vielleicht fragen. Ich entdeckte dieses Format nach mehreren schmerzhaften Erfahrungen, als ich nicht verstehen konnte, warum das System eine Position zu einem bestimmten Zeitpunkt eröffnete.
Jetzt hinterlässt jede Aktion des Systems eine eindeutige Spur in den Protokollen. Ich achte auch darauf, die Momente zu protokollieren, die mit abnormalen Mengen zusammenhängen:
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
Wir brauchen auch eine Visualisierung. Die Erfahrung des manuellen Handels hat eine starke Gewohnheit hinterlassen - alles visuell zu beobachten, wenn man sich die Daten auf die gleiche Weise ansieht, wie man sich die gewöhnlichste Grafik ansieht. Hier ist unser Visualisierungscode:
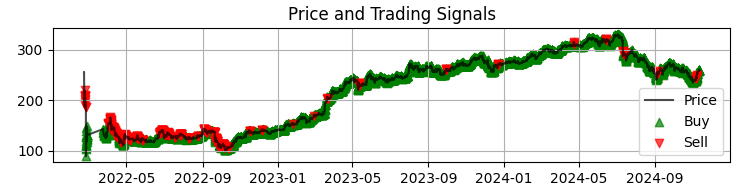
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
Unser erstes Chart ist das häufigste Chart der Sber-Preise mit den erhaltenen Modellsignalen. Außerdem ergänzen wir die Signale, indem wir diejenigen Kerzen hervorheben, bei denen ein anormales Volumen vorliegt. Dies hilft uns, die Momente zu verstehen, in denen das System den Markt perfekt liest, wie ein offenes Buch.
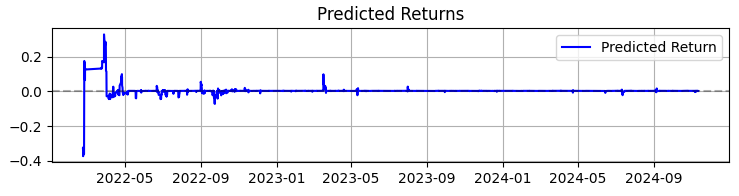
Das zweite Chart zeigt die prognostizierte Rendite. Hier können wir deutlich sehen, dass vor starken Bewegungen der ausgewählten Vermögenswerte oft eine sehr starke Serie von Prognosen beginnt. Dies legt den Gedanken nahe, ein System zu schaffen, das sich auf diese besondere Beobachtung stützt. Natürlich wird die Zahl der Transaktionen sinken, aber wir streben nicht nach Quantität, sondern nach Qualität, nicht wahr?
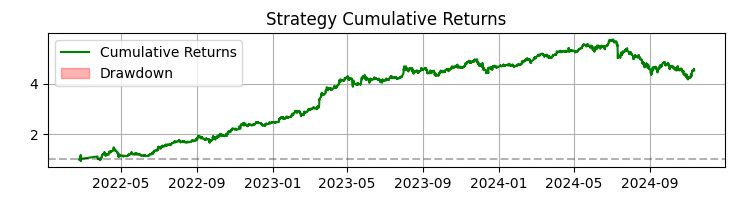
Das dritte Chart zeigt die kumulierte Rendite mit hervorgehobenen Drawdowns.
Von der Theorie zur Praxis: Ergebnisse und Perspektiven
Fassen wir die Ergebnisse des Systembetriebs zusammen - nicht nur trockene Zahlen, sondern Erkenntnisse, die jedem helfen können, der sich für die Volumenanalyse im Handel interessiert.
Erstens spricht der Markt tatsächlich zu uns durch Handelsumsatz und -volumen. Aber diese Sprache ist viel komplexer, als Sie sich vielleicht vorstellen. Ich persönlich bin der Meinung, dass klassische Methoden wie VSA schnell veralten und mit der ebenso rasanten Entwicklung des Marktes nicht mehr Schritt halten können. Die Muster werden immer komplexer und die Volumen bilden sehr komplizierte Muster, die mit bloßem Auge kaum zu erkennen sind.
Insgesamt kann ich als Ergebnis meiner fast dreijährigen Erfahrung mit maschinellem Lernen nur kurz zusammenfassen, dass der Markt von Jahr zu Jahr komplexer wird und auch die Algorithmen, die darauf arbeiten und mit ihrem OrderFlow teilweise Trends und Kumulationen bilden, werden immer komplexer. Vor uns liegt der Kampf der neuronalen Netze - der Kampf der Maschinen um den Markt, der bestimmt, wer die effizientere Maschine ist.
Ich möchte die Arbeit an dem System zusammenfassen und nicht nur die Zahlen, sondern auch die wichtigsten Erkenntnisse mitteilen, die für alle nützlich sein können, die mit der Volumenanalyse arbeiten.
Über 365 Tage mit SBER-Aktien zeigte das System beeindruckende Ergebnisse:
- Gesamtrendite: 365,0% pro Jahr (ohne Hebelwirkung)
- Anteil der profitablen Handelsgeschäfte: 50.73%
Aber diese Zahlen sind nicht das Wichtigste. Noch wichtiger ist, dass sich das System als widerstandsfähig gegenüber einer Vielzahl von Marktbedingungen erwiesen hat. Er funktioniert sowohl bei einem Trend als auch bei einer Seitwärtsbewegung gleichermaßen gut, wenngleich sich die Art der Signale merklich ändert.
Als besonders interessant erwies sich das Systemverhalten in Zeiten hoher Volatilität. Gerade dann, wenn die meisten Händler es vorziehen, sich aus dem Markt herauszuhalten, findet das neuronale Netz die klarsten Muster im Volumenstrom. Vielleicht liegt das daran, dass die institutionellen Akteure in solchen Momenten deutlichere „Spuren“ ihres Handelns hinterlassen.
Was mich dieses Projekt gelehrt hat- Maschinelles Lernen im Handel ist keine Zauberpille. Der Erfolg stellt sich nur ein, wenn man den Markt genau kennt und die Funktionen sorgfältig ausarbeitet.
- Einfachheit ist der Schlüssel zur Nachhaltigkeit. Jedes Mal, wenn ich versuchte, das Modell durch Hinzufügen neuer Schichten oder Funktionen zu verkomplizieren, wurde das System immer anfälliger.
- Die Volumina müssen im Kontext analysiert werden. Anomale Mengen oder Cluster allein bedeuten wenig. Die Magie beginnt, wenn wir ihre Interaktion mit anderen Faktoren betrachten.
Was kommt als Nächstes?
Das System wird ständig weiterentwickelt. Ich arbeite derzeit an einigen Verbesserungen:
- Adaptive Anpassung der Parameter in Abhängigkeit von der Marktphase
- Integration von Streaming-Aufträgen für eine genauere Analyse
- Ausweitung auf andere Instrumente des russischen Marktes
Der Quellcode des Systems ist in den Anhängen verfügbar. Ich würde Verbesserungsvorschläge begrüßen. Es wäre besonders interessant, die Erfahrungen derjenigen zu erfahren, die versuchen, das System an andere Instrumente anzupassen.
Schlussfolgerung
Abschließend möchte ich anmerken, dass die wertvollste Entdeckung der letzten Monate für mich die Anpassung klassischer Ansätze, wie die heute besprochene volumetrische Analyse, an neue Technologien wie maschinelles Lernen, neuronale Netze und Big Data war.
Wie sich herausstellt, ist die Erfahrung früherer Generationen lebendig und lebendig. Unsere Aufgabe ist es, diese Erfahrungen zu verdauen, zu destillieren und aus der Sicht unserer Generation von Händlern unter Verwendung der neuesten Technologien zu verbessern. Und natürlich dürfen wir nicht hinter der Moderne zurückbleiben: Quanten-Maschinenlernen, Quanten-Algorithmen für Preis- und Mengenprognosen sowie multidimensionale Merkmale für das maschinelle Lernen liegen vor uns. Ich habe bereits versucht, den Markt für den 20-Qubit-Quanten-Supercomputer von IBM zu analysieren. Die Ergebnisse sind interessant, und ich werde Ihnen in künftigen Artikeln sicher davon berichten.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16062
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.