
经济预测:探索 Python 的潜力

概述
经济预测是一项相当复杂和耗费精力的任务。它允许我们使用过去的数据分析未来可能的走势。通过分析历史数据和当前经济指标,我们可以推测经济可能走向何方。这是一个非常有用的技能。在它的帮助下,我们可以在商业、投资和经济政策方面做出更明智的决定。
我们将使用 Python 和经济数据开发这个工具,从收集信息到创建预测模型。它将对未来进行分析和预测。
金融市场是经济的良好晴雨表。它们对最细微的变化都会做出反应。结果可能是可预测的,也可能是出乎意料的。让我们看看读数导致气压计波动的例子。
当 GDP 增长时,市场通常会做出积极反应。当通货膨胀上升时,通常会出现动荡。当失业率下降时,这通常被视为好消息。然而,也可能有例外。贸易平衡、利率 —— 每个指标都会影响市场情绪。
实践表明,市场往往不会对实际结果做出反应,而是对大多数参与者的期望做出反应。“买谣言,卖事实” —— 这句古老的股市智慧最准确地反映了正在发生的事情的本质。此外,缺乏重大变化可能会导致市场波动比意外消息更大。
经济情况是一个复杂的系统。这里的一切都是相互关联的,一个因素会影响另一个因素。一个参数的变化可能会引发连锁反应。我们的任务是理解这些联系并学会分析它们。我们将使用 Python 工具寻找解决方案。
设置环境:导入必要的库
那么,我们需要什么?首先要说的是 —— Python。如果您尚未安装,请访问 python.org。另外,在安装过程中不要忘记选中 “将 Python 添加到 PATH” 框。
下一步是库,库极大地扩展了我们工具的基本功能。我们需要:
- pandas —— 用于处理数据。
- wbdata —— 用于与世界银行互动。借助这个库,我们将能获得最新的经济数据。
- MetaTrader 5 —— 我们需要它直接与市场本身进行互动。
- 来自 catboost 的 CatBoostRegressor —— 一个小型手工制作的 AI。
- sklearn 中的 train_test_split 和 mean_squared_error —— 这些库将帮助我们评估模型的有效性。
要安装所需的一切,请打开命令提示符并输入:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
一切都准备好了吗?非常好!现在让我们编写第一段代码文本:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
我们已经准备好所有必要的工具,我们继续吧。
使用世界银行 API:加载经济指标
现在,让我们来弄清楚我们将如何从世界银行获得经济数据。
首先,我们创建一个包含指标代码的字典:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
每个代码都提供对特定类型数据的访问。
让我们继续吧,我们启动一个循环来遍历全部代码:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
在这里,我们尝试获取每个指标的数据。如果有效,我们就会将其放入列表。如果失败,则打印错误并继续。
之后,我们将所有数据收集到一个大数据帧中:
data = pd.concat(data_frames, axis=1) 在这个阶段,我们需要获取所有的经济数据。
下一步是将我们收到的所有内容保存到一个文件中,以便我们以后可以将其用于我们需要的目的:
data.to_csv('economic_data.csv', index=True) 我们刚刚从世界银行下载了一堆数据,就是这么简单。
主要经济指标分析概述
如果你是一个新手,理解大量的数据和数字可能会有点困难。让我们来看看使这一过程更容易的主要指标:
- GDP 增长对于一个国家来说是一种收入。增长的指标是积极的,而下降的指标对国家有负面影响。
- 通货膨胀是商品和服务价格的上涨。
- 实际利率 —— 如果上升,贷款成本就会更高。
- 进出口显示了一个国家的买入和卖出情况。更高的销售额被视为一个积极的发展。
- 经常账户余额 —— 其他国家欠某个国家的钱数额。数字越高,表明一个国家的财政状况越好。
- 政府债务代表一个国家的贷款。数字越小越好。
- 失业 —— 有多少人失业。少即是好。
- 人均 GDP 的增长表明普通人是否变得更加富裕。
代码如下所示:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
每个指标都有其自身的重要性。单独来看,它们意义不大,但综合起来,它们却能提供更完整的画面。还应注意的是,这些指标相互影响。例如,低失业率通常是个好消息,但它可能会导致更高的通货膨胀。或者,如果以巨额债务为代价来实现 GDP 的高增长,可能就不会那么积极。
这就是为什么我们使用机器学习,因为它可以帮助我们考虑所有这些复杂的关系。它大大加快了信息处理和数据排序的过程。然而,你也需要付出一些努力来理解这个过程。
处理和构建世界银行数据
当然,乍一看,世界银行丰富的数据似乎是一项艰巨的任务。为了使工作和分析更容易,我们将在表格中收集数据。
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
接下来,我们获取每个指标并尝试获取其数据。个别指标可能存在问题,我们会写下来并继续前进。然后,我们将单个数据收集到一个大的数据帧(DataFrame)中。
但我们并不止步于此。现在,最有趣的部分开始了。
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
我们看看我们取得了什么成就。有哪些指标?第一行数据是什么样的?这就像第一次看到一个完整的谜题:一切都准备好了吗?然后我们将所有这些内容保存到 CSV 文件中。
最后,是一些统计数据。平均值、最高值、最低值。这就像一次快速检查 —— 我们的数据一切正常吗?这就是我们如何将一堆不同的数字转换为一个连贯的数据系统。我们现在拥有进行严肃经济分析的所有工具。
MetaTrader 5 简介:建立连接并接收数据
现在我们来讨论一下 MetaTrader 5。首先我们需要建立连接。它看起来是这样的:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
下一个重要步骤是获取数据。首先,我们需要检查可用的货币对:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
执行上述代码后,我们将获得所有可用货币对的列表。接下来,我们需要下载每个可用货币对的历史报价数据:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
我们输入的代码中发生了什么?我们指示 MetaTrader 下载每种交易工具过去 1000天 的数据。在此之后,数据被加载到表中。
下载的数据包含了过去三年货币市场发生的一切,非常详细。现在,可以分析收到的报价并找到模式。这里的可能性几乎是无限的。
数据准备:结合经济指标和市场数据
在这个阶段,我们将直接进行数据处理。我们有两个独立的部分:经济指标世界和汇率世界。我们的任务是将这些部分整合在一起。
让我们从数据准备函数开始。在我们的一般任务中,此代码将如下所示:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
现在让我们一步一步来。首先,我们创建货币对数据的副本。为什么呢?使用数据副本总是比使用原始数据更好。如果出现错误,我们将不必再次创建原始文件。
现在,最有趣的部分来了。我们添加了两个新列:“close_diff” 和 “close_corr”。第一列显示收盘价与前一天相比变化了多少。通过这种方式,我们将知道价格是正向还是负向变化。第二列是收盘价与自身的相关性,但有一天的偏移。这是为了什么呢?事实上,这只是了解今天的价格与昨天的价格有多相似的最方便的方法。
现在最难的部分来了:我们试图将经济指标添加到我们的货币数据中。这就是我们开始将数据整合到一个结构中的方式。我们浏览了所有的经济指标,并试图在世界银行的数据中找到它们。如果我们找到它,很好,我们会将其添加到我们的货币数据中。如果没有,那也无所谓。我们只是写一个警告,然后继续前进。
经过这一切,我们可能会留下大量缺失的数据。我们只是删除它们。
现在让我们看看如何应用此函数:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
我们选取每对货币并将我们编写的函数应用于它。在输出时,我们为每一个货币对获得一个现成的数据集。每对都有单独的一套,但它们都是根据相同的原理组装的。
你知道这个过程中最重要的是什么吗?我们正在创造一些新的东西。我们采用不同的经济数据和实时汇率数据,并从中创造出连贯的东西。单独来看,它们可能看起来很混乱,但当放在一起时,我们可以识别出模式。
现在我们有了一个现成的数据集用于分析。我们可以在其中寻找序列,做出预测并得出结论。然而,我们需要确定真正值得关注的迹象。在数据的世界里,没有不重要的细节。数据准备的每一步都对最终结果至关重要。
我们模型中的机器学习
机器学习是一个相当复杂且耗费精力的过程。CatBoost Regressor —— 该函数稍后将发挥重要作用。以下是我们如何使用它:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
这里的每个参数都很重要。1000 次迭代是模型遍历数据的次数。学习率(learning_rate) 0.1 —— 不需要立即设置很高的速度,我们应该逐步学习。深度(depth) 8 —— 寻找复杂的联系。RMSE —— 这是我们评估错误的方式。训练一个模型需要一定的时间。我们展示示例并评估正确答案。CatBoost 尤其适用于不同类型的数据。它并不局限于狭窄的功能范围。
为了预测货币,我们采取以下措施:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
一部分数据用于训练,另一部分用于测试。这就像上学:首先你学习,然后你参加考试
我们把数据分成两部分。为什么呢?一部分用于训练,另一部分用于测试。毕竟,我们需要在尚未使用的数据上测试模型。
训练后,模型试图进行预测。均方根误差显示了它的工作效果。误差越小,预测越好。CatBoost 以其不断改进而闻名。它从错误中学习。
当然,CatBoost 不是一个自动程序,它需要良好的数据。否则,我们在输入时会得到无效的数据,在输出时也会得到无效的数据。但有了正确的数据,结果就会是积极的。现在我们来谈谈数据划分。我提到过我们需要报价来进行验证。代码是这样的:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 50% 的数据用于测试。不要混合它们 —— 保持金融数据的时间顺序很重要。
创建和训练模型是最有趣的部分。CatBoost 在这里充分展示了其功能:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
该模型贪婪地吸收数据,寻找模式。每次迭代都是朝着更好地了解市场迈出的一步。
现在是关键时刻。准确度评估:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
均方根误差也是我们工作中的一个重要问题。这表明该模型错误的程度。少即是好。这使我们能够评估该程序的质量。请记住,交易中没有最终的保证。但有了 CatBoost,这个过程就更加高效了。它看到了我们可能会错过的东西。随着每次预测的进行,结果都有所改善。
预测货币对的未来价值
预测货币对是基于概率的。有时我们会得到积极的结果,有时我们会遭受损失。最重要的是,最终结果符合我们的期望。
在我们的代码中,“预测”函数处理概率。它执行计算的方式如下:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
首先,我们将现有数据与预测数据分开。然后我们将数据分为两部分:用于训练和测试。模型从一组数据中学习,然后我们在另一组数据上进行测试。训练后,模型进行预测。我们看看使用均方根误差的错误程度。数字越低,预测越好。
但最有趣的是对未来可能价格走势的报价分析。我们使用过去 30 天的数据,让模型预测接下来会发生什么。这看起来像是我们求助于经验丰富的分析师的预测。至于可视化...不幸的是,该代码还没有提供任何显式的结果可视化。但是让我们添加它并看看它是什么样子:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
此代码将为每个货币对创建一个图表。从视觉上看,它是线性构建的。每个点都是特定日期的预测价格。这些图表旨在显示可能的趋势,已经使用了大量数据,对普通人来说往往太复杂了。如果这条线朝上,货币将变得更加昂贵。下降呢?那就为汇率下降做好准备吧。
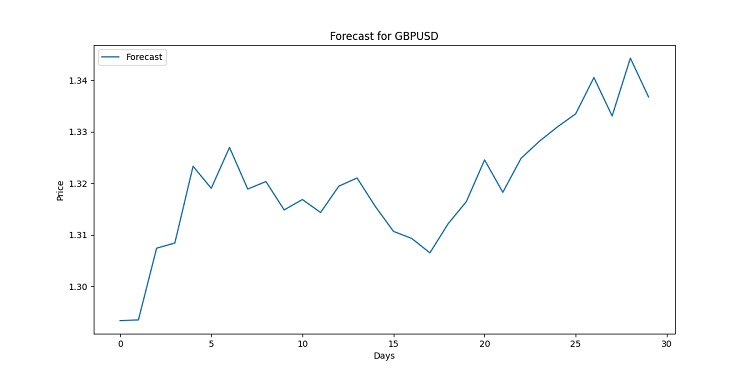
请记住,预测不是保证。市场可能会做出自己的改变。但有了良好的可视化,你至少会知道会发生什么。毕竟,在这种情况下,我们有一个高质量的分析触手可及。
我还编写了一段代码,通过打开一个文件并将预测输出到注释,在 MQL5 中可视化预测结果:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
终端中的预测结果如下:
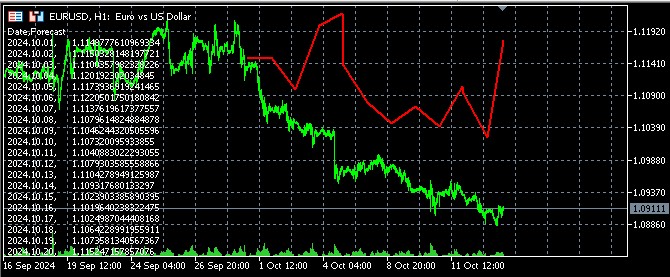
结果的解释:经济因素对汇率的影响分析
现在,让我们仔细看看如何根据代码解释结果。我们已经将数千个不同的事实收集到有组织的数据中,这些数据也需要进行分析。
首先,我们拥有一系列经济指标 —— 从 GDP 增长到失业率。每个因素对市场背景都有自己的影响。个别指标有其自身的影响,但这些数据共同影响最终汇率。
以 GDP 为例。在代码中,它由几个指标表示:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
GDP 增长通常会使货币走强。为什么呢?因为积极的消息吸引了寻求投资机会以进一步增长的投资者。投资者被不断增长的经济体所吸引,对其货币的需求也在增加。
相反,通货膨胀('FP.CPI.TOTL.ZG':'Inflation' )对交易员来说是一个令人担忧的信号。通货膨胀率越高,货币价值下降得越快。高通胀通常会削弱货币,仅仅是因为服务和商品在相关国家开始变得更加昂贵。
看看贸易平衡很有趣:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
这些指标就像天平。如果出口超过进口,该国将获得更多的外汇,这通常会使本国货币走强。
现在让我们看看如何在代码中分析它。CatBoost Regressor 是我们的主要工具。就像一位经验丰富的指挥家,它能同时听到所有乐器的声音,并理解它们是如何相互影响的。
以下是您可以添加到预测函数中的内容,以更好地了解因素的影响:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
这将向我们展示哪些因素对每种货币对的预测最重要。事实可能会证明,对欧元而言,关键因素是欧洲央行的利率,而对日元而言,则是日本的贸易平衡。数据输出示例:
EURUSD 的解释:
1.价格趋势:预测显示未来 30 天呈上升趋势。
2.波动性:预测的价格走势显示波动性较低。
3.关键影响因素:此次预测最重要的特征是“低”。
4.经济影响:
- 如果 GDP 增长是首要因素,则表明强劲的经济表现正在影响货币。
- 通货膨胀率的高度重要性可能表明货币政策的变化正在影响货币。
- 如果贸易平衡因素至关重要,国际贸易动态可能会推动货币走势。
5.交易影响:
- 上升趋势表明有可能建立多头头寸。
- 较低的波动性可能允许更大范围的止损。
6.风险评估:
- 始终考虑模型的局限性和意外市场事件的可能性。
- 过去的表现并不能保证未来的结果。
但请记住,经济学中没有简单的答案。有时一种货币会不顾一切地走强,有时则会无缘无故地下跌。市场往往依赖于预期,而不是当前的现实。
另一个关键点是时间延迟。经济的变化不会立即反映在汇率上。这就像驾驶一艘大船 —— 你转动方向盘,但船不会立刻改变航向。在代码中,我们使用每日数据,但一些经济指标的更新频率较低。这可能会给预测带来一些误差。最终,解释结果既是一门科学,也是一门艺术。模型是一个强大的工具,但决策总是由人做出的。明智地使用这些数据,希望你的预测准确!
在经济数据中寻找不明显的模式
外汇市场是一个巨大的交易平台。它的特点不是可预测的价格变动,但除此之外,还有一些特殊事件会增加当前的波动性和流动性。这些都是全球性事件。
在我们的代码中,我们依赖于经济指标:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
但是,当意外发生时该怎么办呢?例如,疫情或是政治危机?
某种 “惊异指数” 在这里会很有用。想象一下,我们在代码中添加这样的内容:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
这将使我们能够考虑到突发的全球事件及其逐渐减弱。
但这里最有趣的问题是这如何影响预测。有时,全球事件可能会完全颠覆我们的预期。例如,在危机期间,美元或瑞士法郎等“安全”货币可能会违背经济逻辑而走强。
在这种情况下,我们模型的生产率会下降。在这里,重要的是不要恐慌,而是要适应。也许值得暂时缩短预测范围或为最近的数据增加更多权重?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
记住:在货币的世界里,就像在跳舞一样,最重要的是能够适应节奏。即使这种节奏有时会以最意想不到的方式变化!
寻找异常:如何在经济数据中发现不明显的模式
现在让我们来谈谈最有趣的部分 —— 在我们的数据中寻找隐藏的宝藏。这就像当侦探,只是我们没有证据,只有数字和图表。
我们的代码中已经使用了相当多的经济指标。但是,如果它们之间存在一些不明显的联系呢?让我们尝试找到它们吧!
首先,我们可以看看不同指标之间的相关性:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
然而,这仅仅是开始。当我们开始寻找非线性关系时,真正的魔力就开始了。例如,GDP 的变化可能不会立即影响汇率,而是需要几个月的时间。
让我们在数据准备函数中添加一些“平移”指标:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
现在我们的模型将能够捕获延迟 3 个月和 6 个月的依赖关系。
但最有趣的是寻找完全不明显的模式。例如,欧元汇率可能与美国冰淇淋销量存在奇怪的相关性(这是一个笑话,但你明白我的意思)。
为了达到这样的目的,可以使用特征提取方法,例如 PCA(主成分分析):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
这些“隐藏模式”可能是更准确预测的关键。
也不要忘记季节性。一些货币的表现可能因一年中的不同时间而异。将月份和星期几的信息添加到您的数据中 —— 您可能会发现一些有趣的东西!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
记住,在数据的世界里,总是有发现的空间。保持好奇心,进行实验,谁知道呢,也许你会发现这种模式会改变交易世界。
结论:算法交易中的经济预测前景
我们从一个简单的想法开始 —— 我们能否根据经济数据预测汇率走势?我们发现了什么?事实证明,这个想法有一些优点。但这并不像乍一看那么简单。
我们的代码大大简化了经济数据的分析。我们学会了从世界各地收集信息,处理信息,甚至让计算机做出预测。但请记住,即使是最先进的机器学习模型也只是一种工具。它是一个非常强大的工具,但仍然只是一个工具。
我们了解了 CatBoost Regressor 如何发现经济指标和汇率之间的复杂关系。这使我们能够超越人类的能力,大大减少处理和分析数据所花费的时间。但即使是这样一个伟大的工具也无法 100% 准确地预测未来。
为什么呢?因为经济是一个取决于多种因素的过程。今天每个人都在关注油价,而明天整个世界可能会被一些意想不到的事件颠覆。我们在讲“惊异指数”的时候提到过这种效应。这正是它如此重要的原因。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15998
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

从这里开始。关于这个问题的一篇旧文章。
到目前为止,我能从苍蝇身上得到的最多的信息就是今天的数据((((
我不明白的是,MQ 是做什么的?
这就是上文作者发出的信号。
这个信号纯粹是为了测试 Sber 上的一个模型。但我从未测试过它,它只是货币市场基金中的货币而已。基本上,我自己不对我的模型进行交易,我无法摆脱改进和发展的想法)))),不断有新的改进想法)而在证券交易所,我主要投资股票,长期而言,我在MOEX上购买股票作为非REZ,在KASE上购买Kazbirji指数公司的股票。
到目前为止,我们能从苍蝇身上得到的最好信息就是今天的数据((((
据我所知,他们收集的是与监控相连的账户数据?即使一切都是诚实的,那也只是沧海一粟。
在我看来,更值得信赖的是 CFTC 的数据,即使它不是现货,而是带有期权的期货。那里有自 2005 年以来的历史数据,虽然形式不是很方便,但可能有一些 Python 应用程序接口。
当然,这取决于您,我只是谈谈我的看法。
这个信号纯粹是为了测试 Sber 上的一个模型。但我从未对其进行过测试,它只是货币市场基金中的货币而已。基本上,我自己不对我的模型进行交易,因为我无法摆脱改进和发展的想法)))),不断有新的改进想法)而在证券交易所,我主要投资股票,长期而言,我在 MOEX 上购买非雷茨股票,在 KASE 上购买 Kazbirji 指数公司的股票。
信息有出入,不对您构成任何索赔