
Construção de previsões econômicas: potencialidades do Python

Introdução
A previsão econômica é uma tarefa bastante complexa e trabalhosa. Ela permite analisar possíveis movimentos futuros com base em dados históricos. Ao analisar dados históricos e indicadores econômicos atuais, é possível supor para onde a economia pode estar se movendo. Essa é uma habilidade bastante útil. Com ela, podemos tomar decisões mais bem fundamentadas nos negócios, nos investimentos e na política econômica.
Com o uso do Python e de dados econômicos, desde a coleta de informações até a criação de modelos preditivos, vamos desenvolver essa ferramenta. Ela deverá ser capaz de analisar e fazer previsões para o futuro.
Os mercados financeiros funcionam como um barômetro representativo da economia. Eles reagem às menores mudanças. O resultado pode ser tanto previsível quanto inesperado. Vamos observar exemplos em que os indicadores fazem com que esse barômetro oscila.
Se o PIB cresce, os mercados geralmente reagem positivamente. Com o aumento da inflação, normalmente se esperam turbulências. A queda do desemprego geralmente é uma notícia positiva, mas nem sempre. A balança comercial, as taxas de juros — cada indicador influencia o humor do mercado.
Na prática, os mercados reagem mais às expectativas da maioria dos participantes do que aos resultados reais. Compre no boato, venda no fato" — esse velho ditado do mercado — reflete com precisão a essência do que acontece. Às vezes, a ausência de mudanças relevantes pode gerar mais volatilidade no mercado do que uma notícia inesperada.
A economia é um sistema complexo. Tudo nela está interligado, e um fator influencia o outro. A mudança em um único indicador pode desencadear uma reação em cadeia. Compreender essas conexões e aprender a analisá-las é nossa missão, e para isso buscaremos soluções com a ajuda da ferramenta Python.
Configuração do ambiente: importação das bibliotecas necessárias
Então, do que vamos precisar? Para começar, do Python. Se ainda não estiver instalado, acesse python.org, faça o download e instale o programa. Não se esqueça de marcar a opção "Add Python to PATH" durante a instalação.
O próximo passo é as bibliotecas. Elas expandem significativamente as funcionalidades básicas da nossa ferramenta. Precisaremos de:
- pandas: para trabalhar com os dados.
- wbdata: para interagir com o Banco Mundial. Com essa biblioteca, obteremos os dados econômicos mais atualizados.
- MetaTrader 5 : será necessário para a interação direta com o próprio mercado.
- CatBoostRegressor da catboost: uma pequena inteligência artificial feita à mão.
- train_test_split e mean_squared_error do sklearn : essas bibliotecas vão nos ajudar a avaliar a eficiência do nosso modelo.
Para instalar tudo o que é necessário, abra o terminal e digite:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
Tudo instalado? Ótimo! Agora vamos escrever nossas primeiras linhas de código:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
Neste ponto, preparamos todas as ferramentas necessárias. Vamos seguir em frente.
Trabalhando com a API do Banco Mundial: carregando indicadores econômicos
Agora vamos entender como obteremos os dados econômicos do Banco Mundial.
Primeiro, criamos um dicionário com os códigos dos indicadores:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
} Cada um desses códigos dá acesso a um tipo específico de dado.
Vamos em frente. Rodamos um laço que percorre todos os códigos:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
Neste código, tentamos obter os dados de cada indicador. Se funcionar, os salvos na lista. Se houver erro, imprimimos o erro e seguimos.
Depois disso, reunimos todos os nossos dados em um único grande DataFrame:
data = pd.concat(data_frames, axis=1) Neste ponto, devemos ter todos os dados econômicos reunidos.
O próximo passo é salvar tudo o que foi obtido em um arquivo, para podermos usar depois conforme nossas necessidades:
data.to_csv('economic_data.csv', index=True) E assim, de forma simples, acabamos de extrair um monte de dados do Banco Mundial.
Análise dos principais indicadores econômicos
Se você for iniciante, pode ter alguma dificuldade para entender a quantidade de dados e números. Vamos destrinchar os principais indicadores para facilitar o processo:
- Crescimento do PIB: é como se fosse o salário do país. Indicadores em alta são positivos, e queda afeta negativamente o país.
- Inflação: é o aumento dos preços de serviços e produtos.
- Taxa de juros real: se aumenta, os empréstimos ficam mais caros.
- Exportação e importação: o que o país vende e compra. Quanto mais vendas, melhor.
- Conta corrente: indica quanto outros países devem ao país. Valores mais altos indicam uma boa situação financeira.
- Dívida pública: são os empréstimos contraídos pelo governo. Quanto menores os números, melhor.
- Desemprego: quantas pessoas estão sem trabalho. Quanto menor, melhor.
- Crescimento do PIB per capita: o cidadão médio está ficando mais rico ou não.
No código isso aparece assim:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
} Cada indicador tem sua importância. Sozinhos, dizem pouca coisa, mas juntos formam um panorama mais completo. Também é importante lembrar que eles se influenciam. Por exemplo, desemprego baixo costuma ser uma boa notícia, mas pode provocar aumento na inflação. Ou um forte crescimento do PIB pode não ser tão positivo se vier com endividamento excessivo.
Por isso utilizamos o aprendizado de máquina, que ajuda a considerar todas essas conexões complexas. Ele acelera o processamento da informação e filtra os dados. No entanto, é preciso se esforçar para entender a essência do processo.
Tratamento e estruturação dos dados do Banco Mundial
É claro que, à primeira vista, a grande quantidade de dados do Banco Mundial pode parecer um processo bastante trabalhoso de entender. Para facilitar o trabalho e a análise, vamos reunir os dados em uma tabela.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Em seguida, pegamos cada indicador e tentamos obter seus dados. Pode haver problemas com indicadores específicos, registramos isso e seguimos em frente. Depois, reunimos os dados individuais em um único grande DataFrame.
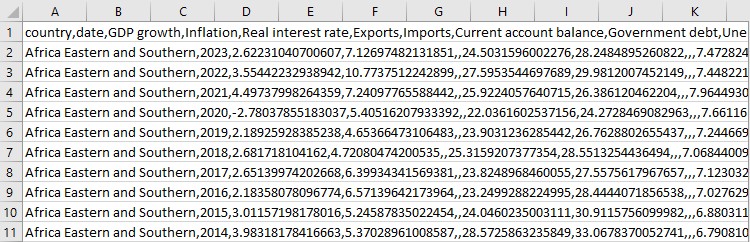
Mas não paramos por aí. É aí que começa a parte mais interessante.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe()) Observamos o que conseguimos. Quais indicadores temos? Como estão as primeiras linhas dos dados? É como dar a primeira olhada em um quebra-cabeça montado: está tudo no lugar? E depois salvamos todo esse material em um arquivo CSV.
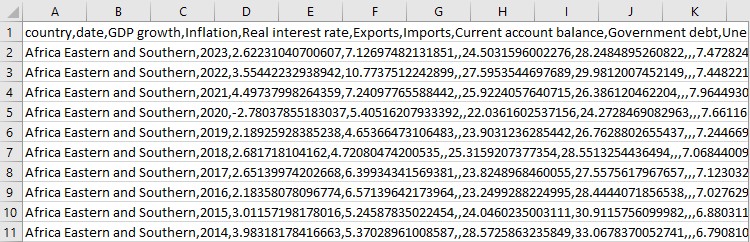
E para finalizar, um pouco de estatística. Médias, valores máximos e mínimos. É como uma inspeção rápida: nossos dados estão organizados? É assim, meus amigos, que transformamos um monte de números soltos em um sistema de dados organizado. Agora temos todas as ferramentas para uma análise econômica séria.
Introdução ao MetaTrader 5: conectando e obtendo dados
Agora vamos falar sobre o MetaTrader 5. Para começar, precisamos estabelecer a conexão. Veja como isso funciona:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
O próximo passo importante é obter os dados. Primeiro é necessário verificar quais pares de moedas estão disponíveis:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols] Depois que o código acima for executado, teremos uma lista de todos os pares de moedas disponíveis. Em seguida, precisamos carregar os dados históricos de cotações para cada par disponível:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df O que acontece nesse código que digitamos? Nós demos o comando para o MetaTrader carregar os dados dos últimos 1000 dias para cada instrumento de negociação. Depois disso, esses dados são carregados em uma tabela.
Nos dados carregados está tudo o que aconteceu no mercado cambial nos últimos três anos, com o máximo de detalhes. Agora, as cotações obtidas podem ser analisadas e usadas para buscar padrões. No geral, as possibilidades aqui são praticamente ilimitadas.
Preparação dos dados: unindo indicadores econômicos e dados do mercado
Neste ponto, vamos trabalhar diretamente com o processamento dos dados. Temos dois setores separados: o mundo dos indicadores econômicos e o mundo das taxas de câmbio. Nossa tarefa é unir esses dois setores.
Vamos começar com nossa função de preparação de dados. Este código será o próximo passo na nossa tarefa geral:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Agora vamos analisar isso passo a passo. Primeiro, criamos uma cópia dos dados da paridade cambial. Por quê? Sempre é melhor trabalhar com uma cópia dos dados, e não com o original. Em caso de erro, não precisaremos gerar novamente o arquivo original.
Agora vem a parte mais interessante. Adicionamos duas novas colunas: 'close_diff' e 'close_corr'. A primeira mostra quanto o preço de fechamento mudou em relação ao dia anterior. Assim, descobrimos se houve um deslocamento positivo ou negativo no preço. A segunda é a correlação do preço de fechamento com ele mesmo, mas com um deslocamento de um dia. Para que serve isso? Na verdade, é a forma mais prática de entender o quanto o preço de hoje se parece com o de ontem.
Depois, começa a parte mais difícil, que é tentarmos adicionar os indicadores econômicos aos nossos dados cambiais. Assim, unimos nossos dados em uma única estrutura. Percorremos todos os nossos indicadores econômicos e os buscamos nos dados do Banco Mundial. Se encontramos algum, ótimo, adicionamos aos dados cambiais. Se não, paciência. Apenas emitimos um aviso e seguimos em frente.
Após tudo isso, podem restar linhas com dados ausentes. Simplesmente as removemos.
Agora vamos ver como aplicamos essa função:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data) Pegamos cada par de moedas e aplicamos a função que escrevemos. O resultado é um conjunto de dados pronto para cada par. Cada par terá seu próprio conjunto, mas todos são estruturados segundo o mesmo princípio.
Sabe qual é o ponto mais importante desse processo? Estamos criando algo novo. Pegamos dados econômicos diversos e dados em tempo real das taxas de câmbio e transformamos isso em algo organizado. Isoladamente, eles podem parecer caóticos, mas ao reuni-los, conseguimos identificar padrões.
E agora temos um conjunto de dados pronto para análise. Podemos buscar sequências, construir previsões, tirar conclusões. No entanto, precisamos identificar as características que realmente merecem atenção. No mundo dos dados, não existem detalhes insignificantes. Cada etapa na preparação dos dados pode ser decisiva para o resultado final.
Aprendizado de máquina em nosso modelo
O aprendizado de máquina é um processo bastante complexo e trabalhoso. O CatBoost Regressor é um exemplo de função que desempenhará um papel importante mais adiante. Veja como o utilizamos:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Todos os parâmetros aqui são relevantes. O modelo passará pelos dados 1.000 vezes. A taxa de aprendizado é 0,1 — não se deve usar uma taxa alta logo de início, pois aprendemos aos poucos. A profundidade 8 indica que procuramos relações mais complexas. O RMSE é a métrica utilizada para avaliar os erros. O treinamento do modelo leva algum tempo. Apresentamos exemplos e avaliamos as respostas corretas. O CatBoost funciona especialmente bem com diferentes tipos de dados. Ou seja, ele não está limitado a um conjunto restrito de funções.
Para fazer a previsão das moedas, procedemos assim:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}") Uma parte dos dados é usada para o aprendizado, outra para o teste. Como na escola: primeiro você aprende, depois faz a prova.
Dividimos os dados em duas partes. Por quê? Uma parte para o aprendizado, outra para a verificação. Isso porque precisamos testar o modelo com dados que ele ainda não viu.
Após o treinamento, o modelo tenta fazer previsões. O erro quadrático médio mostra quão bem ele se saiu. Quanto menor o erro, melhor a previsão. O CatBoost se destaca por estar sempre se aprimorando. Ele aprende com os próprios erros, o que é uma de suas principais características.
Claro, o CatBoost não é um programa automático. Ele precisa de bons dados para funcionar adequadamente. Dados ineficazes na entrada resultam em saídas igualmente ruins. Porém, com dados adequados, o resultado é positivo. Quanto à divisão dos dados, Já mencionei que precisamos de cotações para testar. Veja como isso aparece no código:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 50% dos dados são utilizados para teste. Não embaralhamos os dados, pois é importante manter a ordem temporal dos dados financeiros.
A criação e o treinamento do modelo são a parte mais interessante. Aqui, o CatBoost mostra todo o seu potencial:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
O modelo absorve os dados com avidez, procurando padrões. Cada iteração é um passo em direção a um entendimento mais refinado do mercado.
E agora vem o momento da verdade. Avaliação de precisão:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
O erro quadrático médio também é um ponto essencial no nosso trabalho. Ele mostra quão errado o modelo está. Quanto menor, melhor. Isso nos permite avaliar a qualidade do funcionamento do programa. Lembre-se de que no trading não há garantias definitivas. No entanto, o CatBoost torna o processo mais eficaz. Ele enxerga o que podemos deixar passar. E o resultado melhora a cada previsão.
Previsão de valores futuros das paridades cambiais
Prever pares de moedas é trabalhar com probabilidades. Às vezes temos um bom resultado, outras vezes enfrentamos prejuízos. O principal é que o resultado final atenda às nossas expectativas.
No nosso código, quem trabalha com probabilidades é a função forecast. Veja como ela realiza os cálculos:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
Primeiro, separamos os dados já disponíveis dos que vamos prever. Depois, dividimos os dados em duas partes: uma para treinamento, outra para teste. O modelo aprende com uma parte, e nós o avaliamos com a outra. Após o treinamento, o modelo faz previsões. Verificamos o quanto ele errou, usando o erro quadrático médio. Quanto menor o valor, melhor a previsão.
Mas o mais interessante é a análise das cotações em busca de possíveis movimentos futuros de preço. Pegamos os dados dos últimos 30 dias e pedimos ao modelo para prever o que vem a seguir. É parecido com quando recorremos às previsões de analistas experientes. Agora, sobre a visualização. Infelizmente, no seu código ainda não há uma visualização explícita dos resultados. Mas vamos adicioná-la e ver como isso poderia ser:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Esse código geraria um gráfico para cada par de moedas. Visualmente ele é construído de forma linear. Cada ponto é o preço previsto para um determinado dia. Esses gráficos servem para identificar possíveis tendências, com base em um grande volume de dados que, muitas vezes, é complexo demais para uma pessoa comum interpretar. Se a linha sobe, a moeda tende a se valorizar. Se cai, prepare-se para a queda da cotação.

Lembre-se, previsões não são garantias. O mercado pode mudar tudo. Mas com uma boa visualização, ao menos você saberá o que esperar. Afinal, neste caso, temos uma análise bem feita nas mãos.
Também criei um código para visualizar os resultados da previsão no MQL5, através da abertura do arquivo e exibição das previsões usando o Comment:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
E aqui está como a previsão aparece no terminal:

Interpretação dos resultados: análise da influência dos fatores econômicos nas taxas de câmbio
Agora vamos analisar os resultados com mais profundidade, com base no seu código. Reunimos milhares de fatos dispersos em dados organizados, que também precisam ser analisados.
Comecemos com o fato de que dispomos de uma série de indicadores econômicos, desde o crescimento do PIB até o nível de desemprego. Cada fator exerce sua influência sobre o cenário de mercado. Individualmente, eles têm efeitos distintos, mas juntos afetam as taxas finais de câmbio.
Vejamos, por exemplo, o PIB. No seu código, ele aparece com vários indicadores:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
O crescimento do PIB geralmente fortalece a moeda. Por quê? Porque notícias positivas atraem investidores em busca de oportunidades de aplicar capital visando crescimento futuro. Investidores tendem a procurar economias em expansão, o que aumenta a demanda por sua moeda.
Já a inflação ( 'FP.CPI.TOTL.ZG': 'Inflation' ) é um sinal de alerta para os traders. Quanto maior a inflação, mais rápido o dinheiro perde valor. A inflação elevada costuma enfraquecer a moeda, simplesmente porque os serviços e produtos ficam muito mais caros no país analisado.
É interessante observar a balança comercial:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Esses indicadores funcionam como uma balança. Se as exportações superam as importações, o país recebe mais moeda estrangeira, o que geralmente fortalece sua própria moeda.
Agora sobre como analisamos isso no código. O CatBoost Regressor é nossa principal ferramenta. Ele funciona como um maestro experiente, que ouve todos os instrumentos ao mesmo tempo e entende como cada um influencia os demais.
Veja o que pode ser adicionado à função forecast para entender melhor a influência dos fatores:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions Isso nos mostrará quais fatores foram mais importantes para a previsão de cada par de moedas. Para o euro, o fator-chave pode ser a taxa de juros do BCE, e para o iene, a balança comercial do Japão. Exemplo de saída dos dados:
Interpretation for EURUSD:
1. Price Trend: The forecast shows a upward trend for the next 30 days.
2. Volatility: The predicted price movement shows low volatility.
3. Key Influencing Factor: The most important feature for this forecast is 'low'.
4. Economic Implications:
- If GDP growth is a top factor, it suggests strong economic performance is influencing the currency.
- High importance of inflation rate might indicate monetary policy changes are affecting the currency.
- If trade balance factors are crucial, international trade dynamics are likely driving currency movements.
5. Trading Implications:
- Upward trend suggests potential for long positions.
- Lower volatility might allow for wider stop-losses.
6. Risk Assessment:
- Always consider the model's limitations and potential for unexpected market events.
- Past performance doesn't guarantee future results.
Mas lembre-se, na economia não existem respostas simples. Às vezes a moeda se valoriza contrariando todas as previsões, e outras vezes cai sem motivo aparente. O mercado frequentemente se movimenta com base em expectativas, não necessariamente na realidade atual.
Outro ponto importante é o atraso temporal. Mudanças na economia não se refletem imediatamente nas taxas de câmbio. É como manobrar um navio gigantesco: mesmo girando o leme, o navio demora a mudar de direção. Em nosso código, usamos dados diários, mas alguns indicadores econômicos são atualizados com menos frequência. Isso pode introduzir erro nas previsões. No fim das contas, interpretar resultados é uma arte e uma ciência. Embora o modelo seja uma ferramenta poderosa, quem toma as decisões é sempre o ser humano. Use esses dados com sabedoria e tenha previsões precisas!
Buscando padrões não óbvios nos dados econômicos
O mercado de câmbio é uma gigantesca arena de negociações. Ele já não é conhecido por movimentos previsíveis, mas existem eventos especiais que aumentam, momentaneamente, a volatilidade e a liquidez. Isso e são os eventos globais.
No nosso código, nos baseamos em indicadores econômicos:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
} Mas o que fazer quando acontece algo inesperado? Como uma pandemia ou uma crise política?
Aqui seria útil algum tipo de "índice de surpresa". Imagine se adicionássemos ao nosso código algo como:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Isso nos permitiria considerar eventos globais inesperados e seu enfraquecimento gradual.
Mas o mais interessante: como isso impacta as previsões? Às vezes, eventos globais podem virar nossas expectativas de cabeça para baixo. Por exemplo, durante uma crise, moedas consideradas “seguras” como o dólar americano ou o franco suíço W podem se valorizar mesmo contra a lógica econômica.
Em tais momentos a produtividade do nosso modelo cai. E aqui é importante não entrar em pânico, mas sim se adaptar. Talvez seja hora de reduzir temporariamente o horizonte de previsão ou dar mais peso aos dados recentes?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Lembre-se: no mundo das moedas, como na dança, o mais importante é saber se ajustar ao ritmo. Mesmo que esse ritmo mude da forma mais inesperada!
Caçando anomalias: como encontrar padrões não óbvios nos dados econômicos
E agora vamos falar sobre o mais empolgante: a busca por tesouros escondidos em nossos dados. É como ser um detetive, só que, em vez de pistas, temos números e gráficos.
No nosso código, já usamos um bom número de indicadores econômicos. Mas e se houver relações ocultas entre eles? Vamos tentar encontrá-las!
Para começar, podemos olhar para as correlações entre diferentes indicadores:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Mas isso é só o começo. A verdadeira mágica acontece quando começamos a buscar dependências não lineares. Por exemplo, pode ser que o impacto do PIB sobre a taxa de câmbio não seja imediato, mas com um atraso de alguns meses.
Vamos adicionar à nossa função de preparação de dados alguns indicadores "defasados":
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Agora nosso modelo será capaz de captar relações com atrasos de 3 e 6 meses.
Mas o mais interessante é buscar padrões realmente não óbvios. Por exemplo, pode acontecer de o euro apresentar uma correlação estranha com o volume de vendas de sorvete nos EUA (é uma piada, mas você entendeu a ideia).
Para esses casos, podemos usar técnicas de extração de características, como PCA (Análise de Componentes Principais):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1] Esses “padrões ocultos” podem ser a chave para previsões mais precisas.
Não se esqueça também da sazonalidade. Algumas moedas podem se comportar de maneira diferente de acordo com a época do ano. Adicione aos seus dados informações sobre o mês e o dia da semana — você pode descobrir algo interessante!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Lembre-se: no mundo dos dados, há sempre espaço para descobertas. Seja curioso, experimente e, quem sabe, talvez você seja o responsável por encontrar aquele padrão que transformará o mundo do trading.
Conclusão: perspectivas da previsão econômica no algotrading
Começamos com uma ideia simples: seria possível prever o movimento das taxas de câmbio com base em dados econômicos? E o que descobrimos? Acontece que essa ideia tem fundamento. Mas não é tão simples quanto parece à primeira vista.
Nosso código é como um grande alívio no processo de análise de dados econômicos. Aprendemos a reunir informações de todo o mundo, processá-las e até fazer o computador gerar previsões. É um trabalho bastante produtivo. Mas lembre-se: mesmo o modelo de aprendizado de máquina mais avançado ainda é apenas uma ferramenta. Uma ferramenta muito poderosa, mas ainda assim uma ferramenta.
Vimos como o CatBoost Regressor pode encontrar conexões complexas entre indicadores econômicos e taxas de câmbio. Isso nos permite ir além das capacidades humanas e reduzir significativamente o tempo gasto em processamento e análise de dados. Mas nem mesmo ele consegue prever o futuro com 100% de precisão.
Por quê? Porque a economia é um processo que depende de inúmeros fatores. Hoje, todos estão de olho no preço do petróleo, e amanhã um evento inesperado pode virar o mundo de cabeça para baixo. Mencionamos esse efeito quando falamos do “índice de surpresa”. É exatamente por isso que ele é tão importante.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15998
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Veja a partir daqui. Um artigo antigo sobre o assunto.
Até o momento, o máximo que posso obter da mosca são os dados atuais de hoje((((
O que eu não entendo é: o que o MQ faz?
Esse é o sinal do autor acima.
Esse sinal foi criado exclusivamente para testar um modelo na Sber. Mas eu nunca o testei, ele já é apenas moeda no fundo do mercado monetário. Basicamente, eu não negocio com meus modelos, não posso me afastar de idéias sobre melhorias e desenvolvimento ()))). Há constantemente novas idéias sobre melhorias). E na bolsa de valores, eu invisto principalmente em ações, a longo prazo, eu compro ações no MOEX como uma não-rez, e no KASE de empresas do índice Kazbirji.
Até o momento, o melhor que podemos obter da mosca são os dados atuais para hoje((((
Pelo que entendi, eles coletam dados sobre as contas conectadas ao monitoramento? Mesmo que tudo seja honesto, é uma gota no oceano.
Na minha opinião, os dados da CFTC são mais confiáveis, mesmo que não sejam à vista, mas futuros com opções. Há um histórico desde 2005, embora não em uma forma muito conveniente, mas provavelmente há algumas APIs para Python.
Depende de você, é claro, estou apenas compartilhando minha opinião.
Esse sinal foi criado exclusivamente para testar um modelo na Sber. Mas eu nunca o testei, ele já é apenas moeda no fundo do mercado monetário. Basicamente, não negocio com meus modelos, não posso me afastar de idéias de melhorias e desenvolvimento ()))). Há constantemente novas idéias de melhoria). E na bolsa de valores, invisto principalmente em ações, a longo prazo, compro ações no MOEX como uma não-rez e no KASE de empresas do índice Kazbirji.
Há uma discrepância de informações aqui, sem reclamações para você.