
Elaboración de previsiones económicas: el potencial de Python

Introducción
La previsión económica supone una tarea bastante compleja y que requiere mucho tiempo, aunque permite analizar posibles movimientos futuros a partir de datos pasados. Analizando los datos históricos y los indicadores económicos actuales, especulamos hacia dónde puede dirigirse la economía. Supone una habilidad muy útil. Con ayuda de esta, podemos tomar mejores decisiones en los negocios, en la inversión y en la política económica.
Usando Python y datos económicos, desde la recopilación de información hasta la creación de modelos predictivos, podemos desarrollar esta herramienta. Esta realizará análisis y también hará predicciones para el futuro.
Los mercados financieros suponen un barómetro revelador de la economía que reacciona al menor cambio. El resultado puede ser previsible o inesperado. Veamos algunos ejemplos en los que los indicadores hacen fluctuar este barómetro.
Si el PIB aumenta, los mercados suelen reaccionar positivamente. Cuando aumenta la inflación, se esperan disturbios. El desempleo baja: suele ser una noticia positiva, aunque no siempre. Balanza comercial, tipos de interés: cada indicador se refleja en el sentimiento del mercado.
Como demuestra la práctica, resulta más probable que los mercados reaccionen a las expectativas de la mayoría de los agentes que al resultado real. "Compre rumores, venda hechos": esta vieja máxima bursátil es la que mejor capta la esencia de lo que está ocurriendo. Además, la ausencia de cambios significativos puede provocar más volatilidad en el mercado que las noticias inesperadas.
La economía es un sistema complejo: todo está interconectado y un factor influye en otro. Un cambio en un indicador puede iniciar una reacción en cadena. Así que nuestra tarea consistirá en comprender estas conexiones y aprender a analizarlas, y luego buscaremos las soluciones utilizando los recursos de Python.
Configuración del entorno: importación de las bibliotecas necesarias
Entonces, ¿qué necesitaremos? Para empezar, Python. Si aún no lo tiene instalado, vaya a python.org, descárguelo e instálelo. Además, no se olvide de marcar la casilla "Add Python to PATH" durante el proceso de instalación.
El siguiente paso serán las bibliotecas. Las bibliotecas amplían enormemente las capacidades básicas de nuestras herramientas. Necesitaremos:
- pandas - para trabajar con datos.
- wbdata - para interactuar con el Banco Mundial. Con esta biblioteca, obtendremos los últimos datos económicos.
- MetaTrader 5 - lo necesitaremos para interactuar directamente con el propio mercado.
- CatBoostRegressor de catboost - una pequeña inteligencia artificial manual.
- train_test_split y mean_squared_error de sklearn - estas bibliotecas nos ayudarán a valorar la eficiencia de nuestro modelo.
Para instalar todo lo que necesitamos, abra un símbolo del sistema y escriba:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
¿Está todo instalado? ¡Magnífico! Ahora escribiremos nuestras primeras líneas de código:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
En esta fase, hemos preparado todas las herramientas necesarias. Vamos a continuar.
Trabajo con la API del Banco Mundial: descargamos los indicadores económicos
Ahora entenderemos cómo se obtienen los datos económicos del Banco Mundial.
Primero crearemos un diccionario con los códigos de los indicadores:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
} Cada uno de estos códigos permitirá acceder a un tipo específico de datos.
A continuación, iniciaremos un ciclo que recorrerá todo el código:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
En este código trataremos de obtener los datos para cada indicador. Si lo hemos logrado, lo pondremos en la lista. Si no ha funcionado: imprimiremos el error y seguiremos adelante.
Luego reuniremos todos los datos en un gran DataFrame:
data = pd.concat(data_frames, axis=1) En esta fase deberíamos disponer de todos los datos económicos.
El siguiente paso consistirá en guardar todo lo que obtengamos en un archivo para poder utilizarlo más tarde para los fines que necesitemos:
data.to_csv('economic_data.csv', index=True) Así de fácil, acabamos de desviar un montón de datos del Banco Mundial.
Panorama de los principales indicadores económicos que debemos analizar
Si es usted principiante, puede que le cueste un poco entender la multitud de datos y cifras. Vamos a desglosar los indicadores clave para facilitar el proceso:
- El crecimiento del PIB sería algo así como las ganancias de un país. Los indicadores al alza son positivos para el país, mientras que los indicadores a la baja son negativos.
- La inflación es el aumento del precio de los servicios y bienes.
- El tipo de interés real: si sube, encarece los préstamos.
- Exportaciones e importaciones: lo que un país vende y compra. Si hay más ventas más grandes, será positivo.
- Cuenta corriente: cuánto dinero deben a un país los demás países. Las cifras más elevadas indicarán que el estado goza de buena salud financiera.
- La deuda pública son los préstamos que pesan sobre el gobierno. Cuanto más pequeñas sean las cifras, mejor será el indicador.
- Desempleo: cuántas personas están en paro. Cuanto menor sea, mejor.
- Crecimiento del PIB per cápita: indica si la persona media se está enriqueciendo o no.
En el código, tendrá el aspecto siguiente:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
} Cada indicador posee su propia importancia. Por separado, no nos dirán mucho, pero juntos ofrecen una imagen más completa. También debemos señalar que los indicadores se influyen mutuamente. Por ejemplo, un bajo nivel de desempleo suele ser una buena noticia, pero puede provocar un aumento de la inflación; o un crecimiento alto del PIB puede no ser tan positivo si se produce a costa de enormes deudas.
Por eso usaremos el aprendizaje automático, que ayuda a considerar todas estas relaciones complejas, además de acelerar enormemente el procesamiento de la información y filtrar los datos. No obstante, usted también tendrá que esforzarse por comprender el proceso.
Procesamiento y estructuración de los datos del Banco Mundial
Obviamente, a primera vista, la mase de datos del Banco Mundial puede parecer algo difícil de entender. Por ello, para facilitar el trabajo y el análisis, recopilaremos los datos en una tabla.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
A continuación, tomaremos cada indicador e intentaremos obtener datos para él. Puede haber problemas con indicadores individuales, escribiremos sobre ello y seguiremos adelante. A continuación, recopilaremos los datos individuales en un gran DataFrame.
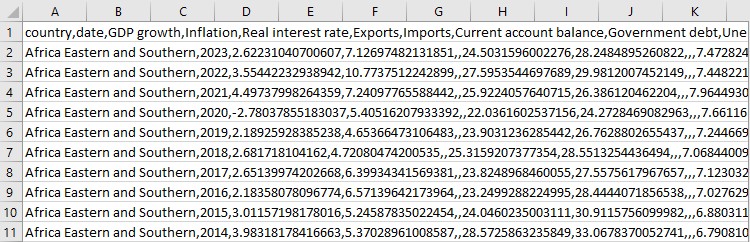
Pero no nos detendremos ahí. Ahora viene la parte divertida.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe()) Veamos lo que tenemos. ¿Qué indicadores existen? ¿Qué aspecto tienen las primeras filas de datos? Es como ver por primera vez un puzzle ya montado: ¿está todo en su sitio? Y luego guardaremos todo eso en un archivo CSV.
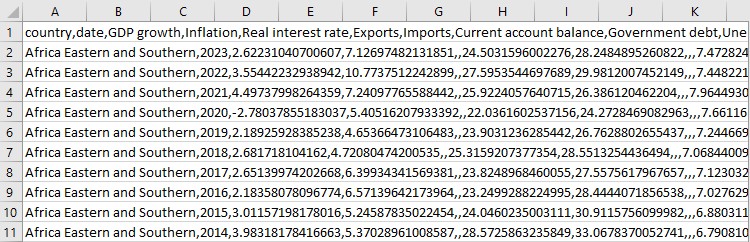
Y por último, veamos un poco de estadística. Promedios, máximos, mínimos. Es como un examen superficial: ¿está todo en orden con nuestros datos? Así, amigos, es como convertimos un montón de números dispares en un esbelto sistema de datos. Ahora disponemos de todas las herramientas necesarias para un análisis económico serio.
Introducción a MetaTrader 5: estableciendo una conexión y obteniendo los datos
Ahora hablemos de MetaTrader 5. En primer lugar, tendremos que establecer una conexión. Esto es lo que parece:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
El siguiente paso importante será la obtención de los datos. En primer lugar, deberemos comprobar qué pares de divisas están disponibles:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols] Una vez ejecutado el código anterior, obtendremos una lista de todos los pares de divisas disponibles. A continuación, tendremos que descargar los datos históricos de las cotizaciones de cada par disponible:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df ¿Y qué ocurre en este código que hemos introducido? Hemos ordenado a MetaTrader que descargue los datos de los últimos 1.000 días de cada instrumento comercial. Luego estos datos se cargarán en una tabla.
Los datos descargados recogen con gran detalle todo lo sucedido en el mercado de divisas en los últimos tres años. Ahora podemos analizar las cotizaciones obtenidas y buscar patrones. En principio, las posibilidades resultan prácticamente ilimitadas.
Preparación de datos: combinación de indicadores económicos y datos de mercado
En esta fase, nos ocuparemos directamente de procesar los datos. Tendremos dos sectores separados: el mundo de los resultados económicos y el mundo de los tipos de cambio. Nuestro reto será reunir estos sectores.
Empezaremos con nuestra función de preparación de datos. En nuestra tarea general, este código será el siguiente:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Ahora vamos a desglosarlo por pasos. En primer lugar, crearemos una copia de los datos del par de divisas. ¿Para qué? Siempre resulta mejor trabajar con una copia de los datos que con el original. En caso de error, no tendremos que volver a crear el archivo original.
Ahora viene lo divertido. Añadiremos dos nuevas columnas: 'close_diff' y 'close_corr'. La primera muestra cuánto ha variado el precio de cierre en comparación con el día anterior. Así sabremos si hay un cambio positivo o negativo en el precio. La segunda supone la correlación del precio de cierre consigo mismo, pero con un desplazamiento de un día. ¿Para qué sirve esto? En realidad, es la forma más cómoda de ver la similitud entre el precio de hoy y el de ayer.
A continuación, empezará la parte difícil: intentaremos añadir indicadores económicos a nuestros datos sobre divisas. Así es como empezaremos a combinar nuestros datos en una única construcción. Luego repasaremos todos nuestros indicadores económicos e intentaremos encontrarlos en los datos del Banco Mundial. Si encontramos uno, genial, lo añadiremos a nuestros datos de divisas. Si no, pues no pasa nada. Simplemente escribiremos una advertencia y seguiremos adelante.
Después de todo esto, es posible que sigamos teniendo filas con datos que falten. Simplemente las borraremos.
Veamos ahora cómo aplicar esta función:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data) Tomaremos cada par de divisas y le aplicaremos nuestra función escrita. El resultado será un conjunto de datos terminado para cada par. Habrá un conjunto distinto para cada par, pero todos estarán montados sobre el mismo principio.
¿Sabe qué es lo más importante de este proceso? Estamos creando algo nuevo. Estamos tomando distintos datos económicos y tipos de cambio en tiempo real y creando algo organizado a partir de ello. Por separado puede parecer caótico, pero al ponerlos juntos podemos identificar patrones.
Y ahora tendremos un conjunto de datos listo para analizar. Podemos buscar secuencias en él, hacer predicciones, sacar conclusiones. No obstante, deberemos identificar aquellas características que sean realmente dignas de mención. En el mundo de los datos, no hay detalles sin importancia. Cada paso en la preparación de los datos podría ser crucial para el resultado final.
Aprendizaje automático en nuestro modelo
El aprendizaje automático supone un proceso largo y complejo. CatBoost Regressor - esta función seguirá desempeñando un papel importante. Así es como lo utilizaremos:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Todos los parámetros son importantes. 1000 iteraciones: - número de veces que el modelo se ejecutará sobre los datos. Velocidad de aprendizaje 0,1 - no es necesario fijar una velocidad alta de una vez, aprenderá gradualmente. Profundidad 8 - búsqueda de conexiones complejas. RMSE - forma de estimar los errores. Entrenar un modelo lleva cierto tiempo. Mostraremos ejemplos y evaluaremos las respuestas correctas. CatBoost funciona especialmente bien con distintos tipos de datos. Es decir, no se limita a un estrecho abanico de funciones.
Para la previsión de divisas, haremos lo siguiente:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}") Una parte de los datos se destinará al entrenamiento, mientras que la otra se destinará a la validación. Es como en la escuela: primero estudiamos y luego hacemos el examen.
Dividiremos los datos en dos partes. ¿Para qué? Una parte para aprender, la otra para probar, dado que necesitaremos validar el modelo sobre datos con los que aún no ha trabajado.
Tras el entrenamiento, el modelo intentará realizar una predicción. El error RMS mostrará lo bien que ha salido. Menos error, mejor predicción. CatBoost destaca porque mejora de forma constante. Aprender de los errores, esa es igualmente su seña de identidad.
Por supuesto, CatBoost no es un programa automático: necesita buenos datos. De lo contrario, si tenemos datos ineficaces en la entrada, los tendremos en la salida. Pero con los datos adecuados, el resultado será positivo. Ahora, la partición de los datos. Hemos mencionado que necesitamos cotizaciones para la validación. Esto será el aspecto en el código:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) El 50% de los datos se destinará a las pruebas. No los barajaremos: es importante mantener el orden temporal de los datos financieros.
La creación y el entrenamiento del modelo es la parte más interesante. Aquí es donde CatBoost demostrará sus capacidades al máximo:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
El modelo devora ávidamente los datos, buscando patrones. Cada iteración supone un paso hacia una mejor comprensión del mercado.
Y ahora llega el momento de la verdad. Evaluación de la precisión:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
El error cuadrático medio también es un punto importante en nuestro trabajo. Demuestra cuánto se equivoca el modelo. Cuanto más pequeño sea el error, mejor. Esto nos permitirá evaluar la calidad de este programa. Recuerde que en el trading no hay garantías definitivas. Pero con CatBoost, el proceso será más eficaz. Él ve cosas que a nosotros se nos escapan, y con cada predicción, el resultado mejorará.
Previsión del valor futuro de los pares de divisas
La previsión de los pares de divisas consiste en trabajar con probabilidades. A veces obtendremos un resultado positivo y a veces sufriremos pérdidas. Lo más importante es que el resultado final cumpla con nuestras expectativas.
En nuestro código, la función de previsión trabajará sobre las probabilidades. He aquí cómo realiza los cálculos:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
En primer lugar, separaremos los datos ya disponibles de los previstos. A continuación, dividiremos los datos en dos partes: una para el entrenamiento y otra para la validación. El modelo aprenderá de unos datos, mientras que lo probaremos con otros. Tras el entrenamiento, el modelo realizará predicciones. Vamos a observar cuánto ha errado utilizando el error cuadrático medio. Cuanto menor sea el número, mejor será la predicción.
Pero lo más interesante será analizar las cotizaciones en busca de posibles movimientos futuros de los precios. Tomaremos los datos de los últimos 30 días y pediremos al modelo que prediga lo que ocurrirá a continuación. Parece una situación en la que recurrimos a las predicciones de analistas experimentados. Y ahora, hablemos de la visualización. Desgraciadamente, aún no existe una visualización explícita de los resultados en nuestro código. Pero la añadiremos y veremos cómo puede quedar:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
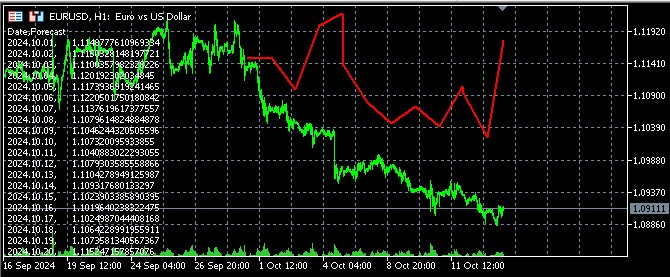
Este código crearía un gráfico para cada par de divisas. Visualmente, estará construido de forma lineal. Cada punto será el precio previsto para un día concreto. Estos gráficos están diseñados para ver posibles tendencias; se ha trabajado con una enorme cantidad de datos, a menudo demasiado complejos para el ciudadano de a pie. Si la línea apunta hacia arriba, la divisa se encarecerá. ¿Y si cae? Deberemos prepararnos para una bajada de los tipos.

Recuerde que las predicciones no suponen ninguna garantía. El mercado puede introducir sus propios cambios. Pero con una buena visualización, al menos sabremos a qué atenernos. Al fin y al cabo, en esta situación tendremos hecho un análisis cualitativo.
También hemos implementado un código para visualizar los resultados de las previsiones en MQL5, usando la apertura de un archivo y la muestra de las previsiones en Comment:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
Y así es como se verá el pronóstico en el terminal:
Interpretación de los resultados: análisis de la influencia de los factores económicos en los tipos de cambio
Veamos ahora cómo interpretar los resultados a partir de nuestro código. Hemos reunido miles de hechos dispares en datos organizados que también deberemos analizar.
Empezaremos con un puñado de indicadores económicos, desde el crecimiento del PIB hasta las tasas de desempleo. Cada factor tendrá su propia repercusión en el fondo del mercado. Los indicadores individuales tendrán su propio impacto, pero en conjunto estos datos afectarán a los tipos de cambio finales.
Por ejemplo, el PIB. En nuestro código, estará representado por varios indicadores:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
El crecimiento del PIB suele fortalecer la moneda. ¿Por qué? Porque las noticias positivas atraen a los jugadores que buscan una oportunidad de invertir capital para obtener mayores beneficios. Los inversores apuestan por economías en crecimiento, lo cual aumenta la demanda de sus divisas.
Pero la inflación ('FP.CPI.TOTL.ZG': ) supone una llamada de atención para los tráders. Cuanto mayor sea la tasa de inflación, más rápido disminuirá el valor del dinero. Una inflación elevada suele debilitar la moneda, por la sencilla razón de que los servicios y bienes empiezan a resultar muy caros en la nación en cuestión.
Resulta interesante observar la balanza comercial:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Estos indicadores son como una balanza. Si las exportaciones superan a las importaciones, el país recibirá más divisas, lo que suele fortalecer la moneda nacional.
Vamos ahora a analizar esto en el código. CatBoost Regressor será nuestra herramienta principal. Es como un director de orquesta experimentado que oye todos los instrumentos a la vez y entiende cómo influyen unos en otros.
Esto es lo que podemos añadir a la función forecast para comprender mejor la influencia de los factores:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions Esto nos mostrará qué factores han resultado más importantes para la previsión de cada par de divisas. Podemos resultar que el factor clave para el euro es el tipo de interés del BCE, mientras que para el yen será la balanza comercial de Japón. Ejemplo de muestra de datos:
Interpretación para EURUSD:
1. Price Trend: La previsión muestra una tendencia al alza para los próximos 30 días.
2. Volatility: The predicted price movement shows low volatility.
3. Key Influencing Factor: The most important feature for this forecast is 'low'.
4. Economic Implications:
- If GDP growth is a top factor, it suggests strong economic performance is influencing the currency.
- High importance of inflation rate might indicate monetary policy changes are affecting the currency.
- If trade balance factors are crucial, international trade dynamics are likely driving currency movements.
5. Trading Implications:
- Upward trend suggests potential for long positions.
- Lower volatility might allow for wider stop-losses.
6. Risk Assessment:
- Always consider the model's limitations and potential for unexpected market events.
- Past performance doesn't guarantee future results.
Pero recuerde que en economía no existen las respuestas fáciles. A veces las divisas se fortalecen contra todo pronóstico, y a veces caen sin motivo aparente. El mercado vive con frecuencia de expectativas y no de la realidad actual.
Otro punto importante es el desfase temporal. Los cambios en la economía no se reflejan de inmediato en el tipo de cambio. Es como gobernar un enorme navío: giras el timón, pero el barco no cambia de rumbo al instante. En nuestro código, utilizaremos datos diarios, pero algunos indicadores económicos se actualizarán con menos frecuencia. Y esto puede introducir algún sesgo en las previsiones. En última instancia, interpretar los resultados es tanto un arte como una ciencia. Nuestro modelo es una herramienta poderosa, pero las decisiones siempre las toman los humanos. Use estos datos con prudencia y ¡que sus predicciones sean acertadas!
Búsqueda de patrones no evidentes en los datos económicos
El mercado de divisas es como un enorme parqué. No solo no se caracteriza por movimientos de precios predecibles, sino que además hay acontecimientos especiales que aumentan la volatilidad y la liquidez en el momento. Estos son los acontecimientos globales.
En nuestro código, nos basaremos en indicadores económicos:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
} Pero, ¿qué hacer cuando surja un imprevisto, digamos como una pandemia o una crisis política?
Ahí es donde sería útil algún tipo de "índice de imprevistos". Imagina que añadimos a nuestro código algo así:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Esto nos permitiría considerar acontecimientos globales repentinos y su decadencia gradual.
Pero lo interesante es: ¿cómo influirá esto en las predicciones? A veces, los acontecimientos mundiales pueden desbaratar por completo nuestras expectativas. Por ejemplo, en tiempos de crisis, las monedas "seguras" como el dólar estadounidense o el franco suizo pueden fortalecerse en contra de toda lógica económica.
En momentos así es cuando desciende la productividad de nuestro modelo. Y aquí es importante no dejarse llevar por el pánico, sino adaptarse a la situación. ¿Quizá deberíamos reducir temporalmente el horizonte de previsión o dar más peso a los datos recientes?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Recuerde: en el mundo de las divisas, como en el baile, lo más importante es saber adaptarse al ritmo, aunque a veces ese ritmo cambie de la forma más inesperada.
Cazando anomalías: cómo encontrar patrones no evidentes en los datos económicos
Ahora hablaremos de la parte divertida: encontrar los tesoros ocultos en nuestros datos, como si fuéramos detectives, salvo que en vez de pruebas, tendremos números y gráficos.
Ya estamos usando bastantes indicadores económicos en nuestro código, pero, ¿y si existen conexiones no evidentes entre ellos? Vamos a intentar encontrarlas!
Para empezar, podemos fijarnos en las correlaciones entre los distintos indicadores:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Pero eso sería solo el principio. La verdadera magia comenzará cuando empecemos a buscar dependencias no lineales. Por ejemplo, podría ocurrir que una variación del PIB afecte al tipo de cambio no inmediatamente, sino con un retraso de varios meses.
Vamos entonces a añadir algunas métricas "desplazadas" a nuestra función de preparación de datos:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Nuestro modelo ahora podrá captar las dependencias con un desfase de 3 y 6 meses.
Pero lo divertido será encontrar patrones que no sean obvios en absoluto. Por ejemplo, podría resultar que el tipo de cambio del euro esté extrañamente correlacionado con las ventas de helados en EE.UU. (es una broma, pero la idea se entiende).
Para ello podemos utilizar técnicas de extracción de características como el PCA (análisis de componentes principales):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1] Estos "patrones ocultos" pueden ser clave a la hora de realizar predicciones más precisas.
Y no se olvide tampoco de la estacionalidad. Algunas divisas pueden comportarse de forma diferente según la época del año. Añada la información del mes y el día de la semana a sus datos: ¡puede que encuentre algo interesante!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Recuerde que siempre hay espacio para el descubrimiento en el mundo de los datos. Sea curioso, experimente y, quién sabe, tal vez halle el patrón que ponga patas arriba el mundo del trading.
Conclusión: perspectivas de previsión económica en el trading algorítmico
Hemos empezado con una idea sencilla: ¿podemos predecir los movimientos de las divisas basándonos en los datos económicos? ¿Y qué hemos descubierto? Resulta que esta idea tiene cierta validez, pero no es tan fácil como parece a primera vista.
Nuestro código es como un alivio significativo respecto al proceso de análisis de los datos económicos. Hemos aprendido a recopilar información de todo el mundo, a procesarla e incluso a hacer que un ordenador realice predicciones. Ha sido una labor bastante productiva. Pero recuerde que incluso el modelo de aprendizaje automático más avanzado no supone más que una herramienta: una herramienta muy poderosa, pero sigue siendo una herramienta.
También hemos visto cómo CatBoost Regressor puede encontrar relaciones complejas entre indicadores económicos y los tipos de cambio. Esto nos permite ir más allá de las capacidades humanas y reducir considerablemente el tiempo dedicado a procesar y analizar los datos. Sin embargo ni siquiera esa herramienta puede predecir el futuro con un 100% de exactitud.
¿Por qué? Porque la economía es un proceso que depende de muchos factores. Hoy todo el mundo está pendiente de los precios del petróleo, y mañana el mundo entero podría dar un vuelco por algún evento inesperado. Hemos mencionado este efecto al hablar del "índice sorpresa", por eso es tan importante.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15998
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Tómalo de aquí. Un viejo artículo sobre el tema.
Hasta ahora, lo más que puedo sacar de la mosca son los datos actuales a fecha de hoy((((
Lo que no entiendo es, ¿qué hace MQ?
Es la señal del autor de arriba.
Esta señal se hizo puramente para probar un modelo en Sber. Pero nunca lo he probado, es sólo la moneda en el fondo del mercado monetario ya. Básicamente yo no comercio a mí mismo en mis modelos, no puedo escapar de las ideas sobre las mejoras y el desarrollo)))) Hay constantemente nuevas ideas sobre la mejora) Y en la bolsa invierto principalmente en acciones, a largo plazo, compro acciones en MOEX como un no-rez, y en KASE de Kazbirji empresas de índice.
Hasta ahora, lo mejor que podemos sacar de la mosca son los datos actuales de hoy((((
Por lo que tengo entendido, ¿recopilan datos sobre las cuentas conectadas a la vigilancia? Incluso si todo es honesto, es una gota en el océano.
Imho, más digno de confianza son los datos de la CFTC, incluso si no es al contado, pero los futuros con opciones. Hay una historia allí desde 2005, aunque no en una forma muy conveniente, pero probablemente hay algunas API para Python.
Depende de usted, por supuesto, sólo compartir mi opinión.
Esta señal se hizo puramente para probar un modelo en Sber. Pero nunca lo he probado, es sólo la moneda en el fondo del mercado monetario ya. Básicamente yo no comercio a mí mismo en mis modelos, no puedo escapar de las ideas sobre las mejoras y el desarrollo)))) Hay constantemente nuevas ideas sobre la mejora) Y en la bolsa invierto principalmente en acciones, a largo plazo, compro acciones en MOEX como un no-rez, y en KASE de las empresas del índice Kazbirji.
hay una discrepancia de información allí, no hay reclamaciones a usted