
Машинное обучение и Data Science (Часть 33): Pandas Dataframe в MQL5, упрощаем сбор данных для машинного обучения

Содержание
- Введение
- Базовые структуры данных в Pandas
- Pandas Dataframe
- Добавление данных в класс Dataframe
- Назначение CSV-файла в Dataframe
- Визуализация содержимого Dataframe
- Экспорт Dataframe в CSV-файл
- Выбор и индексация Dataframe
- Изучение и проверка Pandas Dataframe
- Методы временных рядов и преобразования данных
- Сбор данных для машинного обучения
- Обучение модели машинного обучения
- Развертывание модели машинного обучения на MQL5
- Заключение
Введение
При работе с моделями машинного обучения крайне важно иметь одну и ту же структуру данных, и желательно одни и те же значения для всех сред: обучения, проверки и тестирования. Учитывая, что модели Open Neural Network Exchange (ONNX) поддерживаются в MQL5 и MetaTrader 5, у нас есть возможность импортировать обученные извне модели в язык MQL5 и использовать их в торговых целях.
Поскольку большинство пользователей используют Python для обучения этих моделей искусственного интеллекта (ИИ), которые затем развертываются в MetaTrader 5 с помощью кода MQL5, может возникнуть огромная разница в организации данных, и зачастую даже значения в одной и той же структуре данных могут немного отличаться, что связано с разницей в двух технологиях.

В этой статье мы будем имитировать библиотеку Pandas, доступные в языке Python. Это одна из самых популярных библиотек, особенно полезная при работе с большими объемами данных.
Поскольку эта библиотека используется специалистами по обработке данных для подготовки и обработки данных, используемых в машинном обучении, мы стремимся создать в MQL5 ту же площадку для работы с данными, что и в Python.
Базовые структуры данных в Pandas
Библиотека Pandas предоставляет два типа классов для обработки данных.
- Series (серии) - одномерный маркированный массив для хранения данных любого типа, например, целых чисел, строк, объектов и т. д..
s = pd.Series([1, 3, 5, np.nan, 6, 8])
- Dataframe (фрейм данных) - двумерная структура данных, которая хранит такие данные, как двумерный массив или таблицу со строками и столбцами.
Поскольку класс данных series в pandas является одномерным и больше похож на массив или вектор в MQL5, мы не будем с ним работать. Наше внимание сосредоточено на двумерном Dataframe.
Pandas DataFrame
Опять же, эта структура данных хранит такие данные, как двумерный массив или таблицу со строками и столбцами, в MQL5 у нас может быть двумерный массив, но наиболее практичным двумерным объектом, который мы можем использовать для этой задачи, является матрица.
Поскольку теперь мы знаем, что в основе Pandas Dataframe лежит двумерный массив, мы можем реализовать подобную основу в нашем классе Pandas на языке MQL5.
Файл: pandas.mqh
class CDataFrame { public: string m_columns[]; //An array of string values for keeping track of the column names matrix m_values; // A 2D matrix CDataFrame(); ~CDataFrame(void); }
Нам нужен массив с именем m_columns для хранения имен столбцов для каждого столбца в Dataframe. В отличие от других библиотек для работы с данными, таких как Numpy, Pandas обеспечивает удобство хранения данных для человека, отслеживая имена столбцов.
Pandas Dataframe в Python поддерживает различные типы данных, такие как целые числа, строки, объекты и т. д.
import pandas as pd df = pd.DataFrame({ "Integers": [1,2,3,4,5], "Doubles": [0.1,0.2,0.3,0.4,0.5], "Strings": ["one","two","three","four","five"] })
Мы не собираемся реализовывать эту же гибкость в нашей библиотеке MQL5, поскольку цель этой библиотеки — помочь нам при работе с моделями машинного обучения, где переменные типов данных float и double являются наиболее полезными.
Поэтому обязательно сделаем преобразование (целые числа, long, ulong и т. д.) в значения типа данных double и кодируем все имеющиеся (строковые) переменные перед их подключением к классу Dataframe, поскольку все переменные будут принудительно переведены в тип данных double.
Добавление данных в класс Dataframe
Теперь, когда мы знаем, что матрица, лежащая в основе объекта Dataframe, отвечает за хранение всех данных, давайте реализуем способы добавления в нее информации.
В Python вы можете просто создать новый Dataframe и добавить в него объекты, вызвав метод;
df = pd.DataFrame({
"first column": [1,2,3,4,5],
"second column": [10,20,30,40,50]
})
Из-за синтаксиса языка MQL5 мы не можем иметь класс или метод, который бы вел себя подобным образом. Давайте реализуем метод, известный как Insert.
Файл: pandas.mqh
void CDataFrame::Insert(string name, const vector &values) { //--- Check if the column exists in the m_columns array if it does exists, instead of creating a new column we modify an existing one int col_index = -1; for (int i=0; i<(int)m_columns.Size(); i++) if (name == m_columns[i]) { col_index = i; break; } //--- We check if the dimensiona are Ok if (m_values.Rows()==0) m_values.Resize(values.Size(), m_values.Cols()); if (values.Size() > m_values.Rows() && m_values.Rows()>0) //Check if the new column has a bigger size than the number of rows present in the matrix { printf("%s new column '%s' size is bigger than the dataframe",__FUNCTION__,name); return; } //--- if (col_index != -1) { m_values.Col(values, col_index); if (MQLInfoInteger(MQL_DEBUG)) printf("%s column '%s' exists, It will be modified",__FUNCTION__,name); return; } //--- If a given vector to be added to the dataframe is smaller than the number of rows present in the matrix, we fill the remaining values with Not a Number (NaN) vector temp_vals = vector::Zeros(m_values.Rows()); temp_vals.Fill(NaN); //to create NaN values when there was a dimensional mismatch for (ulong i=0; i<values.Size(); i++) temp_vals[i] = values[i]; //--- m_values.Resize(m_values.Rows(), m_values.Cols()+1); //We resize the m_values matrix to accomodate the new column m_values.Col(temp_vals, m_values.Cols()-1); //We insert the new column after the last column ArrayResize(m_columns, m_columns.Size()+1); //We increase the sice of the column names to accomodate the new column name m_columns[m_columns.Size()-1] = name; //we assign the new column to the last place in the array }
Мы можем парсить новую информацию в Dataframe следующим образом:
#include <MALE5\pandas.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDataFrame df; vector v1= {1,2,3,4,5}; vector v2= {10,20,30,40,50}; df.Insert("first column", v1); df.Insert("second column", v2); }
В качестве альтернативы мы можем предоставить классу-конструктору возможность получать матрицу и имена ее столбцов.
CDataFrame::CDataFrame(const string &columns, const matrix &values) { string columns_names[]; //A temporary array for obtaining column names from a string ushort sep = StringGetCharacter(",", 0); if (StringSplit(columns, sep, columns_names)<0) { printf("%s failed to obtain column names",__FUNCTION__); return; } if (columns_names.Size() != values.Cols()) //Check if the given number of column names is equal to the number of columns present in a given matrix { printf("%s dataframe's columns != columns present in the values matrix",__FUNCTION__); return; } ArrayCopy(m_columns, columns_names); //We assign the columns to the m_columns array m_values = values; //We assing the given matrix to the m_values matrix }
Мы также можем добавить новую информацию в класс Dataframe следующим образом:
void OnStart() { //--- matrix data = { {1,10}, {2,20}, {3,30}, {4,40}, {5,50}, }; CDataFrame df("first column,second column",data); }
Я предлагаю вам использовать метод Insert для добавления данных в класс Dataframe, а не любой другой метод для этой задачи.
Два предыдущих обсуждаемых метода полезны при подготовке наборов данных; нам также нужна функция для загрузки данных, присутствующих в наборе.
Назначение CSV-файла в Dataframe
Метод чтения CSV-файла и присвоения значений Dataframe является одной из самых полезных функций Pandas при работе с библиотекой на Python.
df = pd.read_csv("EURUSD.PERIOD_D1.csv")
Давайте реализуем этот метод в нашем классе MQL5;
bool CDataFrame::ReadCSV(string file_name,string delimiter=",",bool is_common=false, bool verbosity=false) { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI|(is_common?FILE_IS_COMMON:FILE_ANSI),delimiter); //Open a csv file ResetLastError(); if(handle == INVALID_HANDLE) //Check if the file handle is ok if not return false { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); return false; } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(m_columns,column+1); m_columns[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); //add a value to the matrix column++; //--- if(FileIsLineEnding(handle)) //At the end of the each line { rows++; mat_.Resize(rows,column); //Resize the matrix to accomodate new values column = 0; } } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Reading a CSV file... record [%d]",rows); rows_total = rows; FileClose(handle); //Close the file after reading it } mat_.Resize(rows_total-1,mat_.Cols()); m_values = mat_; return true; }
Ниже описано, как можно прочитать CSV-файл и напрямую назначить его Dataframe.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Визуализация содержимого Dataframe
Мы рассмотрели, как можно добавлять информацию в Dataframe, но крайне важно иметь возможность кратко заглянуть в Dataframe, чтобы понять, что он из себя представляет. В большинстве случаев вы будете работать с большими фреймами данных, которые часто требуют повторного обращения к Dataframe для исследования.
В Pandas есть метод head, который возвращает первые n строк для объекта Dataframe в зависимости от позиции. Этот метод полезен для быстрой проверки того, содержит ли ваш объект правильный тип данных.
При вызове метода head в ячейке Jupyter Notebook со значениями по умолчанию в выходных данных ячейки отображаются пять первых строк Dataframe.
Файл: main.ipynb
df = pd.read_csv("EURUSD.PERIOD_D1.csv") df.head()
Результат
| Open | High | Low | Close | |
|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 |
Аналогичную функцию для этой задачи можно реализовать на MQL5.
void CDataFrame::Head(const uint count=5) { // Calculate maximum width needed for each column uint num_cols = m_columns.Size(); uint col_widths[]; ArrayResize(col_widths, num_cols); for (uint col = 0; col < num_cols; col++) //Determining column width for visualizing a simple table { uint max_width = StringLen(m_columns[col]); for (uint row = 0; row < count && row < m_values.Rows(); row++) { string num_str = StringFormat("%.8f", m_values[row][col]); max_width = MathMax(max_width, StringLen(num_str)); } col_widths[col] = max_width + 4; // Extra padding for readability } // Print column headers with calculated padding string header = ""; for (uint col = 0; col < num_cols; col++) { header += StringFormat("| %-*s ", col_widths[col], m_columns[col]); } header += "|"; Print(header); // Print rows with padding for each column for (uint row = 0; row < count && row < m_values.Rows(); row++) { string row_str = ""; for (uint col = 0; col < num_cols; col++) { row_str += StringFormat("| %-*.*f ", col_widths[col], 8, m_values[row][col]); } row_str += "|"; Print(row_str); } // Print dimensions printf("(%dx%d)", m_values.Rows(), m_values.Cols()); }
По умолчанию функция отображает пять первых строк в нашем Dataframe.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Результаты
GI 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | Open | High | Low | Close | RH 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | DI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | EI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | CI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | FE 0 12:37:02.984 pandas test (Volatility 75 Index,H1) (1000x4)
Экспорт Dataframe в CSV-файл
После сбора всех различных типов данных в Dataframe нам необходимо экспортировать их за пределы MetaTrader 5, где происходят все процедуры машинного обучения.
Файл CSV удобен, когда дело доходит до экспорта данных, тем более, что мы будем использовать библиотеку Pandas для импорта CSV-файла на языке Python.
Давайте сохраним извлеченный нами из CSV-файла Dataframe обратно в CSV-файл.
На языке Python.
df.to_csv("EURUSDcopy.csv", index=False) Результатом является CSV-файл EURUSDcopy.csv.
Ниже представлена реализация этого метода на MQL5.
bool CDataFrame::ToCSV(string csv_name, bool common=false, int digits=5, bool verbosity=false) { FileDelete(csv_name); int handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|(common?FILE_COMMON:FILE_ANSI),",",CP_UTF8); //open a csv file if(handle == INVALID_HANDLE) //Check if the handle is OK { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return (false); } //--- string concstring; vector row = {}; vector colsinrows = m_values.Row(0); if (ArraySize(m_columns) != (int)colsinrows.Size()) { printf("headers=%d and columns=%d from the matrix vary is size ",ArraySize(m_columns),colsinrows.Size()); DebugBreak(); return false; } //--- string header_str = ""; for (int i=0; i<ArraySize(m_columns); i++) //We concatenate the header only separating it with a comma delimeter header_str += m_columns[i] + (i+1 == colsinrows.Size() ? "" : ","); FileWrite(handle,header_str); FileSeek(handle,0, SEEK_SET); for(ulong i=0; i<m_values.Rows() && !IsStopped(); i++) { ZeroMemory(concstring); row = m_values.Row(i); for(ulong j=0, cols =1; j<row.Size() && !IsStopped(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == m_values.Cols() ? "" : ","); } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Writing a CSV file... record [%d/%d]",i+1,m_values.Rows()); FileSeek(handle,0,SEEK_END); FileWrite(handle,concstring); } FileClose(handle); return (true); }
Ниже описано, как использовать этот метод.
void OnStart() { CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Assign a csv file into the dataframe df.ToCSV("EURUSDcopy.csv"); //Save the dataframe back into a CSV file as a copy }
Результатом является создание CSV-файла с именем EURUSDcopy.csv.
Теперь, когда мы обсудили создание Dataframe, вставку в него значений, импорт и экспорт данных, давайте рассмотрим методы выбора данных и индексации.
Выбор и индексация Dataframe
Периодически крайне важно иметь возможность разрезать, выбирать или получать доступ к определенным частям Dataframe. Например, при использовании модели для составления прогнозов вам может потребоваться доступ только к последним значениям (последней строке) в фрейме данных, в то время как во время обучения вам может потребоваться доступ к некоторым строкам, расположенным в начале фрейма.
Доступ к столбцу
Чтобы получить доступ к столбцу, мы можем реализовать оператор индекса, который принимает строковые значения в нашем классе.
vector operator[] (const string index) {return GetColumn(index); } //Access a column by its name
Когда функция GetColumn получает имя столбца, она возвращает вектор его значений при его нахождении.
Применение
Print("Close column: ",df["Close"]);
Результаты
2025.01.27 16:16:19.726 pandas test (EURUSD,H1) Close column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.09321,1.09156,1.09188,1.09236,1.09315,1.09511,1.09107,1.07913,1.08258,1.08142,1.08211,1.08551,1.0845,1.08392,1.08529,1.08905,1.08818,1.08959,1.09396,1.08986,
Индексация loc
Такая индексация помогает получить доступ к группе или строкам и столбцам с помощью меток или логического массива.
В Pandas на языке Python.
df.loc[0] Результаты.
Open 1.09381 High 1.09548 Low 1.09003 Close 1.09373 Name: 0, dtype: float64
В MQL5 это можно реализовать в виде обычной функции.
vector CDataFrame::Loc(int index, uint axis=0) { if(axis == 0) { vector row = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Rows() + index; if(index < 0 || index >= (int)m_values.Rows()) { printf("%s Error: Row index out of bounds. Given index: %d", __FUNCTION__, index); return row; } return m_values.Row(index); } else if(axis == 1) { vector column = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Cols() + index; //--- Check bounds if(index < 0 || index >= (int)m_values.Cols()) { printf("%s Error: Column index out of bounds. Given index: %d", __FUNCTION__, index); return column; } return m_values.Col(index); } else printf("%s Failed, Unknown axis ",__FUNCTION__); return vector::Zeros(0); }
Я добавил аргумент axis, чтобы получить возможность выбора между получением строки (вдоль оси 0) и столбца (вдоль оси 1).
Когда эта функция получает отрицательное значение, она обращается к элементам в обратном порядке, значение индекса -1 является последним элементом в Dataframe (последняя строка при оси=0, последний столбец при оси=1).
Применение
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); Print("First row",df.Loc(0)); //--- Print("Last 5 items in df\n",df.Tail()); Print("Last row: ",df.Loc(-1)); Print("Last Column: ",df.Loc(-1, 1)); }
Результаты
RM 0 09:04:21.355 pandas test (EURUSD,H1) | Open | High | Low | Close | IN 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GP 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | NS 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | IE 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | IG 0 09:04:21.355 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | NJ 0 09:04:21.355 pandas test (EURUSD,H1) (1000x4) EO 0 09:04:21.355 pandas test (EURUSD,H1) First row[1.09381,1.09548,1.09003,1.09373] JF 0 09:04:21.355 pandas test (EURUSD,H1) Last 5 items in df DN 0 09:04:21.355 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] JK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] PR 0 09:04:21.355 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] OO 0 09:04:21.355 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] FK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]] EM 0 09:04:21.355 pandas test (EURUSD,H1) Last row: [1.21444,1.21774,1.21101,1.21203] QM 0 09:04:21.355 pandas test (EURUSD,H1) Last Column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.00063,…]
Метод iloc
Функция Iloc, представленная в нашем классе, выбирает строки и столбцы Dataframe по целочисленным позициям, аналогично методу iloc, в Pandas в языке Python.
Этот метод возвращает новый Dataframe, который является результатом операции разрезания.
Реализация в MQL.
CDataFrame Iloc(ulong start_row, ulong end_row, ulong start_col, ulong end_col);
Применение
df = df.Iloc(0,100,0,3); //Slice from the first row to the 99th from the first column to the 2nd df.Head();
Выходные параметры
DJ 0 16:40:19.699 pandas test (EURUSD,H1) | Open | High | Low | LQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | PM 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | EI 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | DE 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | FQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | GS 0 16:40:19.699 pandas test (EURUSD,H1) (100x3)
Метод at
Метод возвращает одно значение из Dataframe.
Реализация в MQL.
double CDataFrame::At(ulong row, string col_name) { ulong col_number = (ulong)ColNameToIndex(col_name, m_columns); return m_values[row][col_number]; }
Применение.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.At(0,"Close")); //Returns the first value within the Close column }
Результаты.
2025.01.27 16:47:16.701 pandas test (EURUSD,H1) 1.09373
Метод iat
Метод позволяет нам получить доступ к одному значению в Dataframe по позиции.
Реализация в MQL.
double CDataFrame::Iat(ulong row,ulong col) { return m_values[row][col]; }
Применение
Print(df.Iat(0,0)); //Returns the value at first row and first colum
Результаты.
2025.01.27 16:53:32.627 pandas test (EURUSD,H1) 1.09381
Удаление столбцов из Dataframe с помощью метода drop
Иногда случается, что в нашей таблице данных есть нежелательные столбцы или мы хотим удалить некоторые переменные в целях обучения. Функция сброса может помочь в решении этой задачи.
Реализация в MQL.
CDataFrame CDataFrame::Drop(const string cols) { CDataFrame df; string column_names[]; ushort sep = StringGetCharacter(",",0); if(StringSplit(cols, sep, column_names) < 0) { printf("%s Failed to get the columns, ensure they are separated by a comma. Error = %d", __FUNCTION__, GetLastError()); return df; } int columns_index[]; uint size = column_names.Size(); ArrayResize(columns_index, size); if(size > m_values.Cols()) { printf("%s failed, The number of columns > columns present in the dataframe", __FUNCTION__); return df; } // Fill columns_index with column indices to drop for(uint i = 0; i < size; i++) { columns_index[i] = ColNameToIndex(column_names[i], m_columns); if(columns_index[i] == -1) { printf("%s Column '%s' not found in this DataFrame", __FUNCTION__, column_names[i]); //ArrayRemove(column_names, i, 1); continue; } } matrix new_data(m_values.Rows(), m_values.Cols() - size); string new_columns[]; ArrayResize(new_columns, (int)m_values.Cols() - size); // Populate new_data with columns not in columns_index for(uint i = 0, count = 0; i < m_values.Cols(); i++) { bool to_drop = false; for(uint j = 0; j < size; j++) { if(i == columns_index[j]) { to_drop = true; break; } } if(!to_drop) { new_data.Col(m_values.Col(i), count); new_columns[count] = m_columns[i]; count++; } } // Replace original data with the updated matrix and columns df.m_values = new_data; ArrayResize(df.m_columns, new_columns.Size()); ArrayCopy(df.m_columns, new_columns); return df; }
Применение
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); CDataFrame new_df = df.Drop("Open,Close"); //drop the columns and assign the dataframe to a new object new_df.Head(); }
Результаты
II 0 19:18:22.997 pandas test (EURUSD,H1) | High | Low | GJ 0 19:18:22.997 pandas test (EURUSD,H1) | 1.09548000 | 1.09003000 | EP 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09810000 | 1.09361000 | CF 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09973000 | 1.09606000 | RL 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09869000 | 1.09542000 | MR 0 19:18:22.998 pandas test (EURUSD,H1) | 1.10396000 | 1.09513000 | DH 0 19:18:22.998 pandas test (EURUSD,H1) (1000x2)
Теперь, когда у нас есть функции для индексации и выбора некоторых частей Dataframe, давайте реализуем несколько функций Pandas, которые помогут нам в исследовании и проверке данных.
Изучение и проверка Pandas Dataframe
Функция tail
Метод отображает последние несколько строк Dataframe.
Реализация в MQL5.
matrix CDataFrame::Tail(uint count=5) { ulong rows = m_values.Rows(); if(count>=rows) { printf("%s count[%d] >= number of rows in the df[%d]",__FUNCTION__,count,rows); return matrix::Zeros(0,0); } ulong start = rows-count; matrix res = matrix::Zeros(count, m_values.Cols()); for(ulong i=start, row_count=0; i<rows; i++, row_count++) res.Row(m_values.Row(i), row_count); return res; }
Применение.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.Tail()); }По умолчанию функция возвращает 5 последних строк Dataframe.
GR 0 17:06:42.044 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] MG 0 17:06:42.044 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] KQ 0 17:06:42.044 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] DK 0 17:06:42.044 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] MO 0 17:06:42.044 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]]
Функция info
Функция очень полезна для понимания структуры Dataframe, типов данных, использования памяти и наличия ненулевых значений.
Ниже представлена ее реализация на MQL5.
void CDataFrame::Info(void)
Результаты.
ES 0 17:34:04.968 pandas test (EURUSD,H1) <class 'CDataFrame'> IH 0 17:34:04.968 pandas test (EURUSD,H1) RangeIndex: 1000 entries, 0 to 999 LR 0 17:34:04.968 pandas test (EURUSD,H1) Data columns (total 4 columns): PD 0 17:34:04.968 pandas test (EURUSD,H1) # Column Non-Null Count Dtype OQ 0 17:34:04.968 pandas test (EURUSD,H1) --- ------ -------------- ----- FS 0 17:34:04.968 pandas test (EURUSD,H1) 0 Open 1000 non-null double GH 0 17:34:04.968 pandas test (EURUSD,H1) 1 High 1000 non-null double LS 0 17:34:04.968 pandas test (EURUSD,H1) 2 Low 1000 non-null double IH 0 17:34:04.968 pandas test (EURUSD,H1) 3 Close 1000 non-null double FJ 0 17:34:04.968 pandas test (EURUSD,H1) memory usage: 31.2 KB
Функция describe
Эта функция предоставляет описательную статистику для всех числовых столбцов в Dataframe. Предоставляемая им информация включает среднее значение, стандартное отклонение, количество, минимальное значение и максимальное значение столбцов, не говоря уже о 25%, 50% и 75% процентилях каждого столбца.
Ниже представлена реализация функции в MQL5.
void CDataFrame::Describe(void)
Применение
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Print(df.Tail()); df.Describe(); }
Результаты.
MM 0 18:10:42.459 pandas test (EURUSD,H1) Open High Low Close JD 0 18:10:42.460 pandas test (EURUSD,H1) count 1000 1000 1000 1000 HD 0 18:10:42.460 pandas test (EURUSD,H1) mean 1.104156 1.108184 1.100572 1.104306 HM 0 18:10:42.460 pandas test (EURUSD,H1) std 0.060646 0.059900 0.061097 0.060507 NQ 0 18:10:42.460 pandas test (EURUSD,H1) min 0.959290 0.967090 0.953580 0.959320 DI 0 18:10:42.460 pandas test (EURUSD,H1) 25% 1.069692 1.073520 1.066225 1.069950 DE 0 18:10:42.460 pandas test (EURUSD,H1) 50% 1.090090 1.093640 1.087100 1.090385 FN 0 18:10:42.460 pandas test (EURUSD,H1) 75% 1.142937 1.145505 1.139295 1.142365 CG 0 18:10:42.460 pandas test (EURUSD,H1) max 1.232510 1.234950 1.226560 1.232620
Получение формы Dataframe и столбцов, присутствующих в Dataframe
В библиотеке Pandas в Python есть такие методы, как pandas.DataFrame.shape, который возвращает форму Dataframe, и pandas.DataFrame.columns, который возвращает столбцы, присутствующие в Dataframe.
В нашем классе мы можем получить доступ к этим значениям из глобальной матрицы m_values следующим образом.
printf("df shape = (%dx%d)",df.m_values.Rows(),df.m_values.Cols());
Результаты.
2025.01.27 18:24:14.436 pandas test (EURUSD,H1) df shape = (1000x4)
Методы временных рядов и преобразования данных
В этом разделе мы реализуем некоторые методы, часто используемые для преобразования данных и анализа изменений, происходящих между строками Dataframe с течением времени.
Методы, обсуждаемые в этом разделе, наиболее часто используются при проектировании функций.
Метод shift()
Метод сдвигает индекс на указанное количество периодов и часто используется в данных временного ряда для сравнения значения с предыдущим или будущим значением.
Реализация в MQL5.
vector CDataFrame::Shift(const vector &v, const int shift) { // Initialize a result vector filled with NaN vector result(v.Size()); result.Fill(NaN); if(shift > 0) { // Positive shift: Move elements forward for(ulong i = 0; i < v.Size() - shift; i++) result[i + shift] = v[i]; } else if(shift < 0) { // Negative shift: Move elements backward for(ulong i = -shift; i < v.Size(); i++) result[i + shift] = v[i]; } else { // Zero shift: Return the vector unchanged result = v; } return result; }
vector CDataFrame::Shift(const string index, const int shift) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Shift(v, shift); }
Когда этой функции присваивается положительное значение индекса, она перемещает элементы вперед, создавая запаздывающую версию заданного вектора или столбца.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_lag_1 = df.Shift("Close", 1); //Create a previous 1 lag on the close price df.Insert("Close lag 1",close_lag_1); //Insert this new column into a dataframe df.Head(); }
Выходные параметры
EP 0 19:40:14.257 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | NO 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | PR 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | ES 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | PS 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | PP 0 19:40:14.257 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | QO 0 19:40:14.257 pandas test (EURUSD,H1) (1000x5)
Однако при получении отрицательной функции функция создает будущую переменную для данного столбца. Это очень полезно для создания целевых переменных.
vector future_close_1 = df.Shift("Close", -1); //Create a future 1 variable df.Insert("Future 1 close",future_close_1); //Insert this new column into a dataframe df.Head();
Выходные параметры
CI 0 19:43:08.482 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | Future 1 close | GJ 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | 1.09399000 | MR 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | 1.09805000 | FM 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | 1.09742000 | IH 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | 1.09757000 | OK 0 19:43:08.483 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | 1.10297000 | GG 0 19:43:08.483 pandas test (EURUSD,H1) (1000x6)
Метод pct_change()
Эта функция вычисляет процентное изменение между текущим и предыдущим элементом. Она обычно используется в финансовых данных для расчета доходности.
Ниже показана ее реализация в классе DataFrame.
vector CDataFrame::Pct_change(const string index) { vector col = GetColumn(index); return Pct_change(col); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Pct_change(const vector &v) { vector col = v; ulong size = col.Size(); vector results(size); results.Fill(NaN); for(ulong i=1; i<size; i++) { double prev_value = col[i - 1]; double curr_value = col[i]; // Calculate percentage change and handle division by zero if(prev_value != 0.0) { results[i] = ((curr_value - prev_value) / prev_value) * 100.0; } else { results[i] = 0.0; // Handle division by zero case } } return results; }
Применение.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_pct_change = df.Pct_change("Close"); df.Insert("Close pct_change", close_pct_change); df.Head(); }
Результаты.
IM 0 19:49:59.858 pandas test (EURUSD,H1) | Open | High | Low | Close | Close pct_change | CO 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | DS 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.02377186 | DD 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.37111857 | QE 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.05737444 | NF 0 19:49:59.858 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.01366842 | NJ 0 19:49:59.858 pandas test (EURUSD,H1) (1000x5)
Метод diff()
Эта функция вычисляет разницу между текущим и предыдущим элементом последовательности. Ее часто используют для поиска изменений с течением времени.
vector CDataFrame::Diff(const vector &v, int period=1) { vector res(v.Size()); res.Fill(NaN); for(ulong i=period; i<v.Size(); i++) res[i] = v[i] - v[i-period]; //Calculate the difference between the current value and the previous one return res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Diff(const string index, int period=1) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Diff(v, period); }
Применение
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector diff_open = df.Diff("Open"); df.Insert("Open diff", diff_open); df.Head(); }
Выходные параметры
GS 0 19:54:10.283 pandas test (EURUSD,H1) | Open | High | Low | Close | Open diff | HM 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | OQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.00297000 | QQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.00023000 | FF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.00062000 | LF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.00663000 | OI 0 19:54:10.283 pandas test (EURUSD,H1) (1000x5)
Метод rolling()
Этот метод обеспечивает удобный способ вычислений в скользящем окне, он полезен, например, для тех, кто хочет рассчитать значения в течение определенного времени (периода); вычислить скользящие средние значения переменных в Dataframe.
Файл: main.ipynb Язык: Python
df["Close sma_5"] = df["Close"].rolling(window=5).mean() df
В отличие от других методов, он требует создания двумерной матрицы, заполненной разделенными вдоль строк окнами. Поскольку нам затем нужно применить полученную двумерную матрицу к некоторым математическим функциям по нашему выбору, нам может понадобиться создать отдельную структуру только для этой задачи.
struct rolling_struct { public: matrix matrix__; vector Mean() { vector res(matrix__.Rows()); res.Fill(NaN); for(ulong i=0; i<res.Size(); i++) res[i] = matrix__.Row(i).Mean(); return res; } };
Мы можем создать функции для заполнения матричной переменной matrix__.
rolling_struct CDataFrame::Rolling(const vector &v, const uint window) { rolling_struct roll_res; roll_res.matrix__.Resize(v.Size(), window); roll_res.matrix__.Fill(NaN); for(ulong i = 0; i < v.Size(); i++) { for(ulong j = 0; j < window; j++) { // Calculate the index in the vector for the Rolling window ulong index = i - (window - 1) + j; if(index >= 0 && index < v.Size()) roll_res.matrix__[i][j] = v[index]; } } return roll_res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ rolling_struct CDataFrame::Rolling(const string index, const uint window) { vector v = GetColumn(index); return Rolling(v, window); }
Теперь мы можем использовать эту функцию для вычисления среднего значения окна и многих других математических функций по нашему усмотрению.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_sma_5 = df.Rolling("Close", 5).Mean(); df.Insert("Close sma_5", close_sma_5); df.Head(10); }
Результаты.
RP 0 20:15:23.126 pandas test (EURUSD,H1) | Open | High | Low | Close | Close sma_5 | KP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | QP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | nan | HP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | nan | GO 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | nan | RR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09615200 | CR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10431000 | 1.10495000 | 1.10084000 | 1.10297000 | 1.09800000 | NS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10616000 | 1.10828000 | 1.10326000 | 1.10453000 | 1.10010800 | JS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11262000 | 1.11442000 | 1.10459000 | 1.10678000 | 1.10185400 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11529000 | 1.12088000 | 1.11139000 | 1.11350000 | 1.10507000 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11765000 | 1.12029000 | 1.11249000 | 1.11594000 | 1.10874400 | RO 0 20:15:23.126 pandas test (EURUSD,H1) (1000x5)
Вы можете сделать гораздо больше с скользящей структурой и добавить больше формул для всех математических операций, которые вы хотите применить к скользящему окну. Больше математических функций для матриц и векторов можно найти здесь.
На данный момент я реализовал несколько функций, которые можно применить к скользящей матрице;
- Std() для расчета стандартного отклонения данных в определенном окне.
- Var() для расчета дисперсии окна.
- Skew() для расчета асимметрии всех данных в определенном окне.
- Kurtosis() для расчета эксцесса всех данных в определенном окне.
- Median() для расчета медианы всех данных в определенном окне.
Это всего лишь несколько полезных функций, скопированных из библиотеки Pandas в Python. Теперь давайте посмотрим, как можно использовать эту библиотеку для подготовки данных для машинного обучения.
Мы собираемся собрать данные в MQL5, экспортировать их в CSV-файл, который будет импортирован в скрипт Python, обученная модель будет сохранена в формате ONNX, модель ONNX будет импортирована и развернута в MQL5 с тем же подходом к сбору и хранению данных.
Сбор данных для машинного обучения
Соберем около 20 переменных и добавим их в класс Dataframe.
- Значения открытия, максимума, минимума и закрытия (OHLC).
CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close);
Эти функции важны, поскольку они помогают вывести больше характеристик. Они просто являются основой всех моделей, которые мы видим на рынке.
- Поскольку Форекс работает 5 дней в неделю, сложим значения закрытия за предыдущие 5 дней (запаздывающие значения закрытия). Эти данные могут помочь моделям ИИ понять закономерности, возникающие с течением времени.
int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); }
Теперь в Dataframe общее количество переменных достигло 9.
- Ежедневное процентное изменение цены закрытия (для определения ежедневных изменений цены закрытия).
vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change);
- Поскольку мы работаем на дневном таймфрейме, давайте добавим дисперсию за 5 дней, чтобы зафиксировать закономерности изменчивости в течение скользящего 5-дневного периода.
vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5);
- Мы можем добавить дифференциальные характеристики, которые помогут уловить волатильность и движение цен между значениями OHLC.
df.Insert("open_close",open-close); df.Insert("high_low",high-low);
- Мы можем добавить среднюю цену, надеясь, что это поможет моделям уловить закономерности в самих значениях OHLC.
df.Insert("Avg price",(open+high+low+close)/4);
- Наконец, мы можем добавить несколько индикаторов. Я собираюсь использовать подход к сбору данных по индикаторам, который обсуждался в этой статье. Пожалуйста, не стесняйтесь использовать любой другой подход к сбору индикаторных данных, если этот вам не подходит.
BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values
Всего у нас 21 переменная.
df.Head();
Результаты.
PG 0 11:32:21.371 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | DD 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15620000 | 1.15660000 | 1.15030000 | 1.15080000 | nan | nan | nan | nan | nan | nan | nan | 0.00540000 | 0.00630000 | 1.15347500 | nan | nan | nan | nan | nan | nan | nan | JN 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15100000 | 1.15130000 | 1.14220000 | 1.14280000 | 1.15080000 | nan | nan | nan | nan | -0.69516858 | nan | 0.00820000 | 0.00910000 | 1.14682500 | nan | nan | nan | nan | nan | nan | nan | ID 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14300000 | 1.15360000 | 1.14230000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | nan | 0.72628631 | nan | -0.00810000 | 0.01130000 | 1.14750000 | nan | nan | nan | nan | nan | nan | nan | ES 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15070000 | 1.15490000 | 1.14890000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | -0.05212406 | nan | 0.00020000 | 0.00600000 | 1.15125000 | nan | nan | nan | nan | nan | nan | nan | LJ 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14820000 | 1.14900000 | 1.13560000 | 1.13870000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | -1.02564103 | 0.00002596 | 0.00950000 | 0.01340000 | 1.14287500 | nan | nan | nan | nan | nan | nan | nan | HG 0 11:32:21.371 pandas test (EURUSD,H1) (10000x22)
Давайте на секунду взглянем на набор данных.
df.Info();
Выходные параметры
FN 0 12:18:01.745 pandas test (EURUSD,H1) <class 'CDataFrame'> QE 0 12:18:01.745 pandas test (EURUSD,H1) RangeIndex: 10000 entries, 0 to 9999 NL 0 12:18:01.745 pandas test (EURUSD,H1) Data columns (total 21 columns): MR 0 12:18:01.745 pandas test (EURUSD,H1) # Column Non-Null Count Dtype DI 0 12:18:01.745 pandas test (EURUSD,H1) --- ------ -------------- ----- CO 0 12:18:01.745 pandas test (EURUSD,H1) 0 open 10000 non-null double GR 0 12:18:01.746 pandas test (EURUSD,H1) 1 high 10000 non-null double LK 0 12:18:01.746 pandas test (EURUSD,H1) 2 low 10000 non-null double JF 0 12:18:01.747 pandas test (EURUSD,H1) 3 close 10000 non-null double QS 0 12:18:01.748 pandas test (EURUSD,H1) 4 close lag_1 9999 non-null double JO 0 12:18:01.748 pandas test (EURUSD,H1) 5 close lag_2 9998 non-null double GH 0 12:18:01.748 pandas test (EURUSD,H1) 6 close lag_3 9997 non-null double KD 0 12:18:01.749 pandas test (EURUSD,H1) 7 close lag_4 9996 non-null double FP 0 12:18:01.749 pandas test (EURUSD,H1) 8 close lag_5 9995 non-null double EL 0 12:18:01.750 pandas test (EURUSD,H1) 9 close pct_change 9999 non-null double ME 0 12:18:01.750 pandas test (EURUSD,H1) 10 var close 5 days 9996 non-null double GI 0 12:18:01.751 pandas test (EURUSD,H1) 11 open_close 10000 non-null double ES 0 12:18:01.752 pandas test (EURUSD,H1) 12 high_low 10000 non-null double LF 0 12:18:01.752 pandas test (EURUSD,H1) 13 Avg price 10000 non-null double DI 0 12:18:01.752 pandas test (EURUSD,H1) 14 bb_lower 9981 non-null double FQ 0 12:18:01.753 pandas test (EURUSD,H1) 15 bb_middle 9981 non-null double NQ 0 12:18:01.753 pandas test (EURUSD,H1) 16 bb_upper 9981 non-null double QI 0 12:18:01.753 pandas test (EURUSD,H1) 17 ATR 14 9986 non-null double CF 0 12:18:01.753 pandas test (EURUSD,H1) 18 macd histogram 9975 non-null double DO 0 12:18:01.754 pandas test (EURUSD,H1) 19 macd main 9975 non-null double FR 0 12:18:01.754 pandas test (EURUSD,H1) 20 macd signal 9992 non-null double FF 0 12:18:01.754 pandas test (EURUSD,H1) memory usage: 1640.6 KB
Наши данные занимают около 1,6 МБ памяти, имеется множество нулевых (nan) значений, которые приходится отбрасывать.
CDataFrame new_df = df.Dropnan(); new_df.Head();
Выходные параметры
JO 0 12:18:01.762 pandas test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/10000 JR 0 12:18:01.766 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | FQ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.23060000 | 1.23900000 | 1.20370000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | 1.22350000 | -1.32412673 | 0.00005234 | 0.01590000 | 0.03530000 | 1.22200000 | 1.16702297 | 1.20237000 | 1.23771703 | 0.01279286 | -1.19628486 | 0.02253736 | 1.21882222 | OJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21540000 | 1.22120000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | -0.27990450 | 0.00008191 | 0.00410000 | 0.01190000 | 1.21430000 | 1.17236514 | 1.20446500 | 1.23656486 | 0.01265000 | -1.19925638 | 0.02076585 | 1.22002222 | IO 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21040000 | 1.21390000 | 1.20730000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | -0.16511186 | 0.00010988 | 0.00110000 | 0.00660000 | 1.21022500 | 1.17774730 | 1.20631000 | 1.23487270 | 0.01253571 | -1.20115162 | 0.01898171 | 1.22013333 | QP 0 12:18:01.766 pandas test (EURUSD,H1) | 1.20840000 | 1.20840000 | 1.19490000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | -0.48788555 | 0.00008624 | 0.00500000 | 0.01350000 | 1.20377500 | 1.17941845 | 1.20699500 | 1.23457155 | 0.01292857 | -1.20208086 | 0.01689692 | 1.21897778 | DJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21000000 | 1.21930000 | 1.20900000 | 1.21330000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 0.82266910 | 0.00001558 | -0.00330000 | 0.01030000 | 1.21290000 | 1.18119695 | 1.20804500 | 1.23489305 | 0.01360714 | -1.20198373 | 0.01586072 | 1.21784444 | MS 0 12:18:01.766 pandas test (EURUSD,H1) (9975x21)
Мы можем сохранить этот Dataframe в CSV-файл.
string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8);
Обучение модели машинного обучения
Начнем с импорта библиотек, которые могут нам понадобиться, в Python Jupyter Notebook.
Файл: main.ipynb
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler from sklearn.model_selection import train_test_split import skl2onnx from sklearn.metrics import r2_score sns.set_style("darkgrid")
Мы импортируем данные и присваиваем их Pandas Dataframe.
df = pd.read_csv("EURUSD.dailytf.data.csv")
Создадим целевую переменную.
df["future_close"] = df["close"].shift(-1) # Shift the close price by one to get df = df.dropna() # drop nan values caused by the shift operation
Теперь, когда у нас есть целевая переменная для задачи регрессии, давайте разделим данные на обучающую и тестовую выборки.
X = df.drop(columns=[ "future_close" # drop the target veriable from the independent variables matrix ]) y = df["future_close"] # Train test split X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=False)
Мы устанавливаем значение перемешивания на false, чтобы можно было решить эту задачу как задачу временного ряда.
Затем заворачиваем модель линейной регрессии в Pipeline и обучаем ее.
pipe_model = Pipeline([ ("scaler", RobustScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train) # Training a Linear regression model
Выходные параметры
Чтобы оценить имеющуюся у нас модель, я решил спрогнозировать цель на основе данных обучения и тестирования, добавил эту информацию в Pandas Dataframe, а затем построил график результата с помощью Seaborn и Matplotlib.
# Preparing the data for plotting train_pred = pipe_model.predict(X_train) test_pred = pipe_model.predict(X_test) train_data = pd.DataFrame({ 'Index': range(len(y_train)), 'True Values': y_train, 'Predicted Values': train_pred, 'Set': 'Train' }) test_data = pd.DataFrame({ 'Index': range(len(y_test)), 'True Values': y_test, 'Predicted Values': test_pred, 'Set': 'Test' }) # figure size 750x1000 pixels fig, axes = plt.subplots(2, 1, figsize=(7.5, 10), sharex=False) # Plot Train Data sns.lineplot(ax=axes[0], data=train_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[0], data=train_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[0].set_title(f'Train Set: True vs Predicted Values | Acc = {r2_score(y_train, train_pred)}', fontsize=14) axes[0].set_ylabel('Values', fontsize=12) axes[0].legend() # Plot Test Data sns.lineplot(ax=axes[1], data=test_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[1], data=test_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[1].set_title(f'Test Set: True vs Predicted Values | Acc = {r2_score(y_test, test_pred)}', fontsize=14) axes[1].set_xlabel('Index', fontsize=12) axes[1].set_ylabel('Values', fontsize=12) axes[1].legend() # Final adjustments plt.tight_layout() plt.show()
Результаты
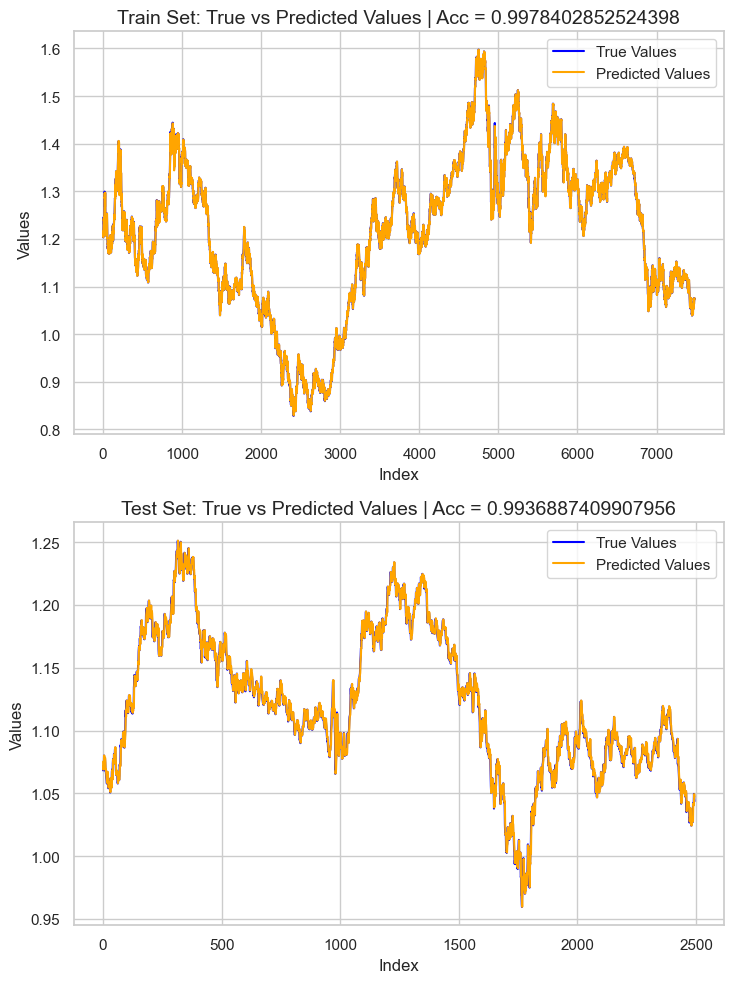
Результатом является переобученная модель с оценкой r2 приблизительно 0,99. Это не слишком хороший знак для модели. Давайте проверим важность признаков, чтобы увидеть, какие признаки оказывают положительное влияние на модель, а те, которые оказывают отрицательное влияние на модель, будут удалены при их обнаружении.
# Extract the linear regression model from the pipeline lr_model = pipe_model.named_steps['LR'] # Get feature importance (coefficients) feature_importance = pd.Series(lr_model.coef_, index=X_train.columns) # Sort feature importance feature_importance = feature_importance.sort_values(ascending=False) print(feature_importance)
Результаты
macd main 266.706747 close 0.093652 open 0.093435 Avg price 0.042505 close lag_1 0.006972 close lag_3 0.003645 bb_upper 0.001423 close lag_5 0.001415 bb_middle 0.000766 high_low 0.000201 bb_lower 0.000087 var close 5 days -0.000179 ATR 14 -0.000185 close pct_change -0.001046 close lag_4 -0.002636 close lag_2 -0.003881 open_close -0.004705 high -0.008575 low -0.008663 macd histogram -5504.010453 macd signal -5518.035201 dtype: float64
Наиболее информативной особенностью была macd main, в то время как macd histogram и macd signal были наименее информативными переменными для модели. Отбросим все значения с отрицательной важностью признаков, переобучим модель и снова посмотрим на точность.
X = df.drop(columns=[ "future_close", # drop the target veriable from the independent variables matrix "var close 5 days", "ATR 14", "close pct_change", "close lag_4", "close lag_2", "open_close", "high", "low", "macd histogram", "macd signal" ])
pipe_model = Pipeline([ ("scaler", MinMaxScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train)
Точность повторно обученной модели оказалась очень схожей с точностью предыдущей модели. Модель все еще была переобученной. Пока это не так важно. Перейдем к экспорту модели в формат ONNX.
Развертывание модели машинного обучения на MQL5
В советнике мы начинаем с добавления модели в качестве ресурса, чтобы ее можно было скомпилировать с программой.
Файл: LR model Test.mq5
#resource "\\Files\\EURUSD.dailytf.model.onnx" as uchar lr_onnx[]
Импортируем все необходимые библиотеки: Pandas, ta-lib (для индикаторов) и Linear Regression (для загрузки модели).
#include <Linear Regression.mqh> #include <MALE5\pandas.mqh> #include <ta-lib.mqh> CLinearRegression lr;
Инициализируем модель линейной регрессии в функции OnInit.
int OnInit() { //--- if (!lr.Init(lr_onnx)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Преимущество использования этой пользовательской библиотеки Pandas заключается в том, что нам не нужно начинать писать код с нуля, чтобы снова собрать данные. Достаточно просто скопировать использованный код, вставить его в основной советник и внести в него небольшие изменения.
void OnTick() { //--- CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close); int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); } vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change); vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5); df.Insert("open_close",open-close); df.Insert("high_low",high-low); df.Insert("Avg price",(open+high+low+close)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values df.Info(); CDataFrame new_df = df.Dropnan(); new_df.Head(); string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8); }
Изменения включают:
Изменение необходимого нам размера данных. Нам больше не нужно 10 000 баров, нам нужно всего лишь около 30 баров, поскольку период индикатора MACD равен 26, период полос Боллинджера равен 20, а период ATR равен 14. Присвоив значение 30, мы фактически оставляем некоторое пространство для вычислений.
Функция OnTick иногда может быть очень быстрой и взрывной, нам не нужно переопределять переменные каждый раз при получении нового тика.
Нам не нужно сохранять данные в CSV-файл, нам просто нужно назначить последнюю строку Dataframe вектору для включения в модель.
Мы можем обернуть эти строки кода в отдельную функцию, чтобы с ними было проще работать.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values CDataFrame new_df = df_.Dropnan(); //Drop NaN values return new_df.Loc(-1); //return the latest row }
Именно так мы изначально собирали данные для обучения. Некоторые из признаков, присутствующих в этой функции, по разным причинам не попали в финальную модель. Нам пришлось от них отказаться, аналогично тому, как мы от них отказались в скрипте Python.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values df_ = df_.Drop( //"future_close", "var close 5 days,"+ "ATR 14,"+ "close pct_change,"+ "close lag_4,"+ "close lag_2,"+ "open_close,"+ "high,"+ "low,"+ "macd histogram,"+ "macd signal" ); CDataFrame new_df = df_.Dropnan(); return new_df.Loc(-1); //return the latest row }
Вместо того, чтобы удалять столбцы, как в приведенной выше функции, в первую очередь разумно удалить код, используемый для их создания. Это может сократить ненужные вычисления, которые могут замедлить программу, когда нужно вычислить много характеристик, чтобы их можно было быстро удалить.
На данный момент мы будем придерживаться метода Drop.
После вызова метода Head() для просмотра содержимого Dataframe был получен следующий результат:
PM 0 15:45:36.543 LR model Test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/30 HI 0 15:45:36.543 LR model Test (EURUSD,H1) | open | close | close lag_1 | close lag_3 | close lag_5 | high_low | Avg price | bb_lower | bb_middle | bb_upper | macd main | GK 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04057000 | 1.04079000 | 1.04057000 | 1.02806000 | 1.03015000 | 0.00575000 | 1.04176750 | 1.02125891 | 1.03177350 | 1.04228809 | 0.00028705 | QI 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04079000 | 1.04159000 | 1.04079000 | 1.04211000 | 1.02696000 | 0.00661000 | 1.04084750 | 1.02081967 | 1.03210400 | 1.04338833 | 0.00085370 | PL 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04158000 | 1.04956000 | 1.04159000 | 1.04057000 | 1.02806000 | 0.01099000 | 1.04611250 | 1.01924805 | 1.03282750 | 1.04640695 | 0.00192371 | JR 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04795000 | 1.04675000 | 1.04956000 | 1.04079000 | 1.04211000 | 0.00204000 | 1.04743000 | 1.01927184 | 1.03382650 | 1.04838116 | 0.00251595 | CP 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04675000 | 1.04370000 | 1.04675000 | 1.04159000 | 1.04057000 | 0.01049000 | 1.04664500 | 1.01938012 | 1.03447300 | 1.04956588 | 0.00270798 | CH 0 15:45:36.543 LR model Test (EURUSD,H1) (5x11)
У нас есть 11 особенностей. Столько же особенностей можно увидеть на модели.
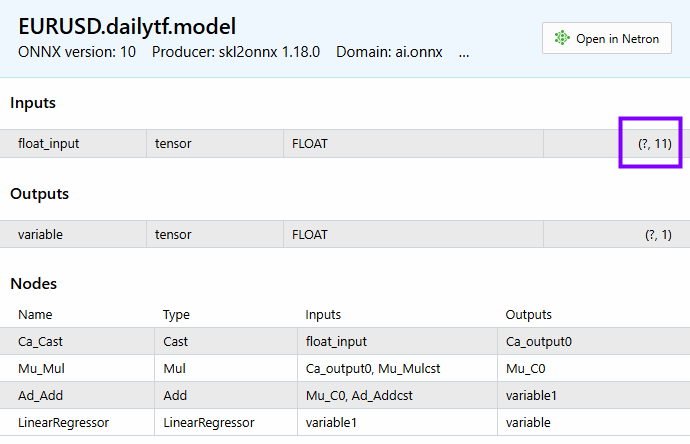
Ниже показано, как можно получить окончательные прогнозы модели.
void OnTick() { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); }
Неразумно выполнять весь сбор данных и расчеты модели на каждом тике, нам нужно рассчитывать их при открытии нового бара на графике.
void OnTick() { if (isNewBar()) { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); } }
Я разработал простую стратегию, позволяющую открывать позицию на покупку всякий раз, когда прогнозируемая цена закрытия выше текущей цены bid, и открывать позицию на продажу всякий раз, когда прогнозируемая цена закрытия ниже текущей цены ask.
Ниже представлены результаты тестирования в тестере стратегий с 1 ноября 2024 года по 25 января 2025 года.
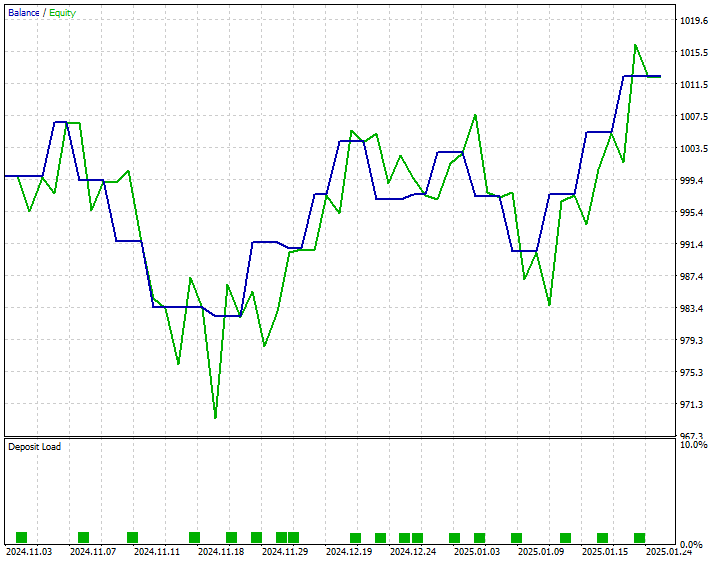
Заключение
Теперь импортировать сложные модели ИИ в MQL5 и использовать их в MetaTrader 5 стало намного проще. Однако синхронизировать модель со структурой данных, аналогичной той, которая использовалась для обучения, по-прежнему непросто. В этой статье я представил пользовательский класс CDataframe, который поможет нам при работе с двумерными данными в среде, похожей на среду в библиотеке Pandas, которая хорошо знакома сообществу специалистов по машинному обучению и специалистам по данным, имеющим опыт работы с Python.
Я надеюсь, что библиотека Pandas в MQL5 окажется полезной и значительно облегчит нам жизнь при работе со сложными ИИ-данными в MQL5.
Оставайтесь с нами и вносите свой вклад в разработку алгоритмов машинного обучения для языка MQL5 в этом GitHub-репозитории.
Таблица вложений
| Имя файла | Описание/использование |
|---|---|
| Experts\LR model Test.mq5 | Советник для развертывания окончательной модели линейной регрессии. |
| Include\Linear Regression.mqh | Библиотека, содержащая весь код для загрузки модели линейной регрессии в формате ONNX. |
| Include\pandas.mqh | Содержит все пользовательские методы Pandas для работы с данными в классе Dataframe. |
| Scripts\pandas test.mq5 | Скрипт, отвечающий за сбор данных для машинного обучения. |
| Python\main.ipynb | Файл jupyter notebook со всем кодом для обучения модели линейной регрессии, использованной в этой статье. |
| Files\ | Эта папка содержит модель линейной регрессии в моделях ONNX и CSV-файлы для обучения моделей ИИ. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17030
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования